基于BERT的数控机床故障领域命名实体识别
2022-06-14褚燕华蒋文王丽颖张晓琳王乾龙
褚燕华, 蒋文, 王丽颖, 张晓琳, 王乾龙
(内蒙古科技大学信息工程学院, 包头 014010)
近年来,随着智能制造的快速发展与云计算时代的到来,“互联网+工业”逐渐成为学者的研究重点。互联网时代对工业发展提出了更高的要求,同时数控机床设备的检修与诊断面临着更加严峻的难题,克服难题离不开对故障数据的分析和利用。随着工厂信息化发展,机械工厂中积累了大量的数控机床故障记录。仅从记录中深入挖掘数控机床故障信息,很难加以分析和应用,形成满足用户需求的知识,帮助用户找到解决方案。因此,需要通过自然语言处理技术对原始文本进行信息抽取。命名实体识别是信息抽取的主要任务之一,旨在从输入的文本序列中识别出目标实体,是信息检索、舆情分析与知识图谱构建等自然语言处理任务中的基础性工作。
开放领域的实体识别技术较为成熟,垂直领域诸如数控机床故障领域研究鲜少,实体识别存在一些挑战。例如,数控机床故障领域的公开数据集匮乏;该领域数据专业化程度高,缺乏统一的规范和标准;针对该领域的研究较少,现存研究大部分针对数控机床特定部件存在的故障[1-2]。
作为自然语言处理领域研究的热点,命名实体识别的算法也不断地被领域内专家所优化,其发展经历了早期的基于词典和规则的方法,到传统机器学习的方法,到近年来使用较广泛的基于深度学习的方法共3个阶段。
第一阶段是基于词典或规则的方法,依赖于领域专家手工制定的规则系统,结合命名实体库,对每条规则进行权重辅助,然后通过实体与规则的相符情况来进行类型判断。规则往往依赖具体语言领域和文本风格,可扩展性难,难以覆盖所有的语言现象,并且时间效率低、可移植性弱。
第二阶段是基于机器学习的方法,通过数学统计进行建模,例如,Yusup等[3]针对圣训中叙述者名称的命名实体识别提出支持向量机方法(support vector machines,SVM);Lay等[4]将隐马尔科夫模型(hidden markov model,HMM)应用于缅甸语言命名识别任务;Pati等[5]采用条件随机域方法对马拉地语文本进行命名实体识别;识别效果得到提升,时间效率提高,而这些方法对人工标注的语料库的依赖性高,仍需要大量人力参与。
第三阶段是深度学习方法,对语料库的依赖性低,泛化性好,逐渐成为主流。为修正长短期记忆网络(long short-term memory,LSTM)识别结果,Qin等[6]使用CRF模型对LSTM输出结果进行约束。Zhao等[7]将BiLSTM-CRF模型对电力领域名词进行命名实体识别,郑彦斌等[8]基于双向门控循环单元(bidrectional gated recurrent unit,BiGRU)与CRF结合的模型识别东盟十国中文新闻数据中的实体。由于BiLSTM能学习上下文的特征,提升了实体识别效果,从而BiLSTM-CRF模型逐渐成为各领域的命名实体识别任务主流模型。Li等[9]采用BiLSTM-CRF模型识别铁路事故和故障分析报告中的实体;肖瑞等[10]针对中医文本领域提出了词级别的BiLSTM-CRF命名实体识别模型,识别效果得到提升,但是词向量的语义表征能力弱,削弱了识别效果。
Peters等[11]提出引入预训练语言模型可以提高词向量的表征能力,从而提升实体识别效果。近年来所提出的Word2vec[12]、ELMO(embeddings from language models)[13]、GPT(generative pre-training)[14]、BERT[15]预训练语言模型中,BERT模型在命名实体识别效果比其他模型更为理想,例如,崔竞烽等[16]在菊花古典诗词领域采用BERT命名实体识别模型优于其他实体识别模型;田梓函等[17]使用BERT-CRF模型取得较好的实体识别效果,但是文本特征提取程度较浅。
针对上述问题,本文研究在数控机床故障领域引入了BERT-BiLSTM-CRF模型进行命名实体识别,与其他模型进行了对比实验,发现该模型在数控机床故障语料中召回率和F1均有提升,各实体识别F1差值小,相比其他模型受数据不均衡性影响小。对数控机床故障领域的命名实体方法进行研究,并提出一种性能较好的实体识别模型,以期为数控机床故障领域知识图谱构建提供理论基础。
1 BERT-BiLSTM-CRF模型
1.1 模型结构
模型主要由三部分构成,分别是BERT编码层、BiLSTM交互层和CRF推理层。将数控机床故障文本序列输入到BERT编码层进行预训练,得到每个字的向量,生成向量矩阵,将得到的向量矩阵输入到BiLSTM交互层进行编码,最终通过CRF推理层进行解码,获取概率最大的标签序列,得到每个字符的类别。模型结构如图1所示。

h为BiLSTM输出的隐藏向量;O表示非实体位置;B表示实体起始位置;I表示实体除起始外的位置图1 BERT-BiLSTM-CRF模型结构Fig.1 BERT-BiLSTM-CRF model structure
1.2 BERT编码层
BERT编码层的任务为将文本序列映射成向量矩阵。相比传统循环神经网络,BERT模型拓宽了词向量的泛化能力,通过双向预训练学习上下文信息,模型结构如图2所示。

CLS为classification,用于分类问题;SEP为separator,用于分割句子;Trm为Transformer编码单元;E为嵌入向量图2 BERT预训练语言模型Fig.2 BERT pre-trained language model
输入文本序列时,在开始和结尾添加[CLS]和[SEP]。输入向量包含词嵌入、段嵌入、位置嵌入。词嵌入将输入的字符转换成固定维度的向量,段嵌入用于区分不同句子,位置嵌入有助于解决Transformer无法对输入序列顺序性编码的问题。
Transformer编码单元是BERT最重要的部分。单个Transformer块由自注意力机制和前馈神经网络两部分组成,从整体上处理序列而不是依赖过去隐藏状态,从而允许并行运算,减少训练时间,提高了性能。
编码单元最重要的模块是自注意力部分,计算公式为

(1)
式(1)中:Q、K、V分别为输入向量矩阵;dk为输入向量维度;QKT用于计算输入字向量之间的关系。
此外,Transformer将多个自注意力层连接起来,增大注意力单元的表示子空间,同时通过降低维度减少计算消耗:
MultiHead(Q,K,V)=Concat (head1,
head2,…, headk)W0
(2)

(3)

Transformer中加入了残差网络和层归一化,以改善梯度消失问题与加快收敛,计算公式为

(4)
FFN=max(0,xW1+b1)W2+b2
(5)
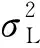
与传统预训练语言模型不同,BERT是一个多任务模型,由遮掩语言模型(masked language model,MLM)和下一句预测(next sentence predict,NSP)两个任务构成。遮掩语言模型遮盖住句子里部分词,让模型对其进行预测。具体过程是在输入的文本序列中随机掩盖15%的词,其中80%以[MASK]替换,10%以随机词替换,10%的词保持不变。下一句预测判断两句之间的关系,其处理过程对部分句子随机替换,通过上一句预测两句是否为上下句关系。与其他预训练语言模型相比,BERT能够充分利用词上下文信息来获得更好的词分布式表示。
1.3 BiLSTM交互层
BiLSTM交互层的任务是将BERT编码层得到的向量矩阵作为输入,捕捉序列中上下文信息,提取文本特征。采用循环神经网络(recurrent neural network,RNN)的改进模型长短期记忆网络,是为了解决一般的RNN长期依赖,即梯度消失和梯度爆炸问题。LSTM主要由输入门、遗忘门、输出门构成,输入门决定了当前时刻网络的输入有多少保存到单元状态,遗忘门决定了上一时刻的单元状态有多少保留到当前时刻单元状态,输出门控制当前时刻单元状态有多少输出,单元结构如图3所示。
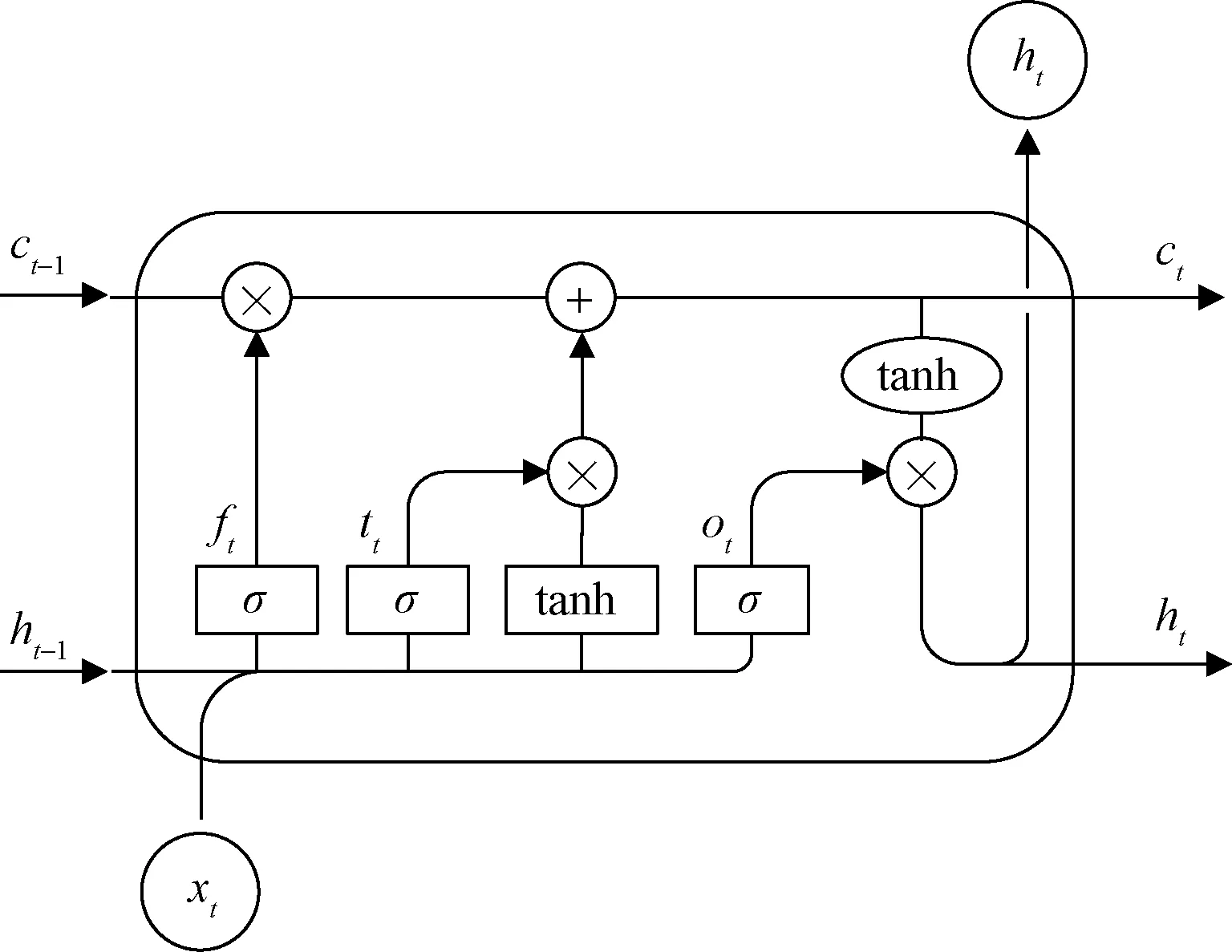
it、ft、ot、ct、ht分别为在t时刻的输入门状态、遗忘门状态、输出 门状态、细胞状态、隐藏状态;σ为sigmoid函数;⊗为点乘运算; tanh为正切函数图3 LSTM单元结构Fig.3 LSTM unit structure
LSTM计算公式为
ft=σ(Wf[ht-1,xt]+bf)
(6)
it=σ(Wi[ht-1,xt]+bi)
(7)
ot=σ(Wo[ht-1,xt]+bo)
(8)
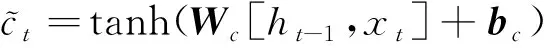
(9)
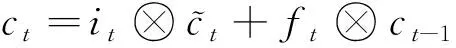
(10)
ht=ot⊗tanhct
(11)
式中:W为权重矩阵。


(12)
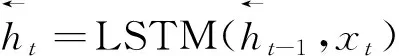
(13)
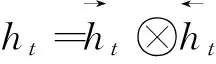
(14)
1.4 CRF推理层
CRF推理层采用BiLSTM交互层输出结果作为输入,通过训练过程中学习的转移矩阵,获取前后标签之间的依赖关系,从而生成全局最优标签序列。CRF标记过程形式化为
Et,yt=Wsht+bs
(15)

(16)
式中:Ws和bs为可学习参数;ht为上一层输入结果;S(X,y)为输入序列X=(x1,x2, …,xn)与句子标签序列y=(y1,y2, …,yn)的匹配分数;Et,yt为第t个字符标为yt个标签的概率;T为转移矩阵,如Tt,k表示由标签t到标签k的转移概率。
通过Softmax函数进行概率计算,计算公式为

(17)
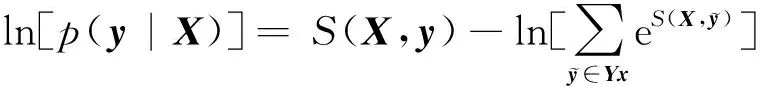
(18)
预测过程中,由式(19)输出整体概率最大的一组标签序列作为最优序列,即y*为最终数控机床故障领域实体识别标注结果。
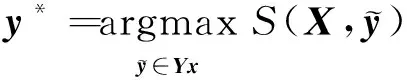
(19)
2 实验
2.1 实验数据
实验数据来自某机械工厂,包含了工厂内数控机床设备故障的整体记录。对数据集进行清洗和整理,获得10 148条有效数据,部分语料如表1所示。
依据标注策略对数据进行实体标注,将标注好的语料按6∶2∶2比例进行划分,即6 088条训练集,2 029条验证集、2 031条测试集。数据集中不同实体个数如表2所示。

表1 部分语料展示

表2 数据集实体个数
2.2 标注策略
数控机床故障领域的命名需要有一套命名规范,而数控机床需要系统化的机械知识作为基础,仅依靠通用知识是难以进行有效标注。常用机械故障领域实体类型为设备和故障,而设备的定义范围广泛,剥离了设备内部构件之间的关系,所以本文研究对设备进行细分类,定义实体类型为部件、零件、故障。从定义上看,故障实体显然比前两者更容易区分,而部件与零件实体边界模糊,若未经过机械知识的学习,难以区分两者。对此,本文研究对目标实体进行详细定义,如表3所示。
结合实体定义,采用BIO标注方法进行人工标注,其中B、I、O定义参考1.1节。预测实体位置的也需要预测其实体类型,因此待预测标签包含7种,分别为B-Par、I-Par、B-Spa、I-Spa、B-Fau、I-Fau与O,标注形式如表4所示。

表3 数控机床故障领域实体定义

表4 实体标注形式
2.3 实验设置
采用Intel xeon Gold619版本CPU,NVIDIA GeForce RTX 2080Ti版本GPU,11G显存,编译环境python3.7,Tensorflow-gpu1.12.0。BERT采用base版本,优化器为Adam,其他超参数设置如表5所示。

表5 BERT-BiLSTM-CRF模型超参数设置
2.4 评价指标
采用命名实体识别常用评价指标,即准确率P、召回率R和综合评价指标F1对衡量实体识别结果的性能,具体计算公式为

(20)
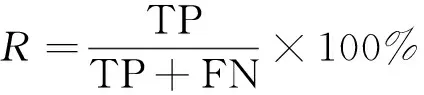
(21)
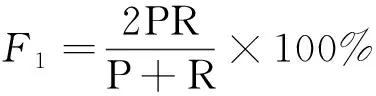
(22)
式中:TP为预测正确的实体数量;FP为预测无关的实体数量;FN为未能预测到的实体数量。
2.5 实验结果与分析
通过对比几种数控机床故障领域命名实体识别方法的实验效果,以此评估本文方法的有效性。
为了验证BiLSTM-CRF模型的性能,对主流模型进行了40轮实验。从表6可看出,BiLSTM-CRF模型识别效果比仅使用BiLSTM层的识别效果好,主要原因是CRF可以捕捉标签之间的约束关系。BiGRU相对BiLSTM参数减少,但在数控机床故障领域的提取特征能力仍不足。在对比实验模型中,BiLSTM-CRF模型准确率与F1高于其他模型,整体识别效果较为理想。
在BiLSTM-CRF模型上引入BERT预训练语言模型,为验证模型性能,分别对基于BERT的模型进行了10轮实验。从实验结果表7可看出,该组模型识别效果较主流模型得到明显提升,主要原因为BERT预训练语言模型能够获取上下文的双向特征。BERT-BiLSTM-CRF模型在各项实体识别指标上优于其他模型,进一步表现了BiLSTM-CRF在实体识别领域上具有的优势,同时说明了BERT与BiLSTM-CRF互补作用性强。
为了使所提出模型的实体识别效果得到更直观的表示,将各个实体识别结果列出(表8)。由实验结果来看,部件的实体识别各项指标均优于其他实体,F1达到了87.19%,主要原因在于部件是语料中标注最多的实体类别,并且专业化程度高,特征明显。由实验结果可以看出,故障的实体识别效果均差于其他两类,主要原因是故障专业程度低,特征不明显,并且本身存在实体数目少、种类繁多、情况复杂、部分存在歧义、缩略词干扰等情况。

表6 主流模型命名实体识别结果

表7 基于BERT的模型命名体识别结果
为了验证所提出模型在各个实体识别上具有的优势,对比BiLSTM、BiLSTM-CRF、BERT-BiLSTM-CRF 3种模型在每个实体上的F1,如图4所示。BiLSTM-CRF识别效果明显优于BiLSTM模型,所提出模型在部件、零件、故障的实体识别F1比BiLSTM模型提高大于5%,相比BiLSTM-CRF模型提高大于2%。结果表明在BiLSTM加入CRF层,可以学习标签之间的依赖关系,从而使实体识别效果更优;在BiLSTM-CRF模型上引入BERT预训练语言模型,使得字的语义信息可以联系上下文,得到更好的表示,提升了实体识别效果。BERT-BiLSTM-CRF模型在每个实体识别效果均优于其他模型,3类实体识别F1差值较小,受数据不均衡性影响小,进一步验证了该模型在数控机床故障领域命名实体识别较其他深度学习模型所具有的优势。

表8 BERT-BiLSTM-CRF对各个实体的识别结果
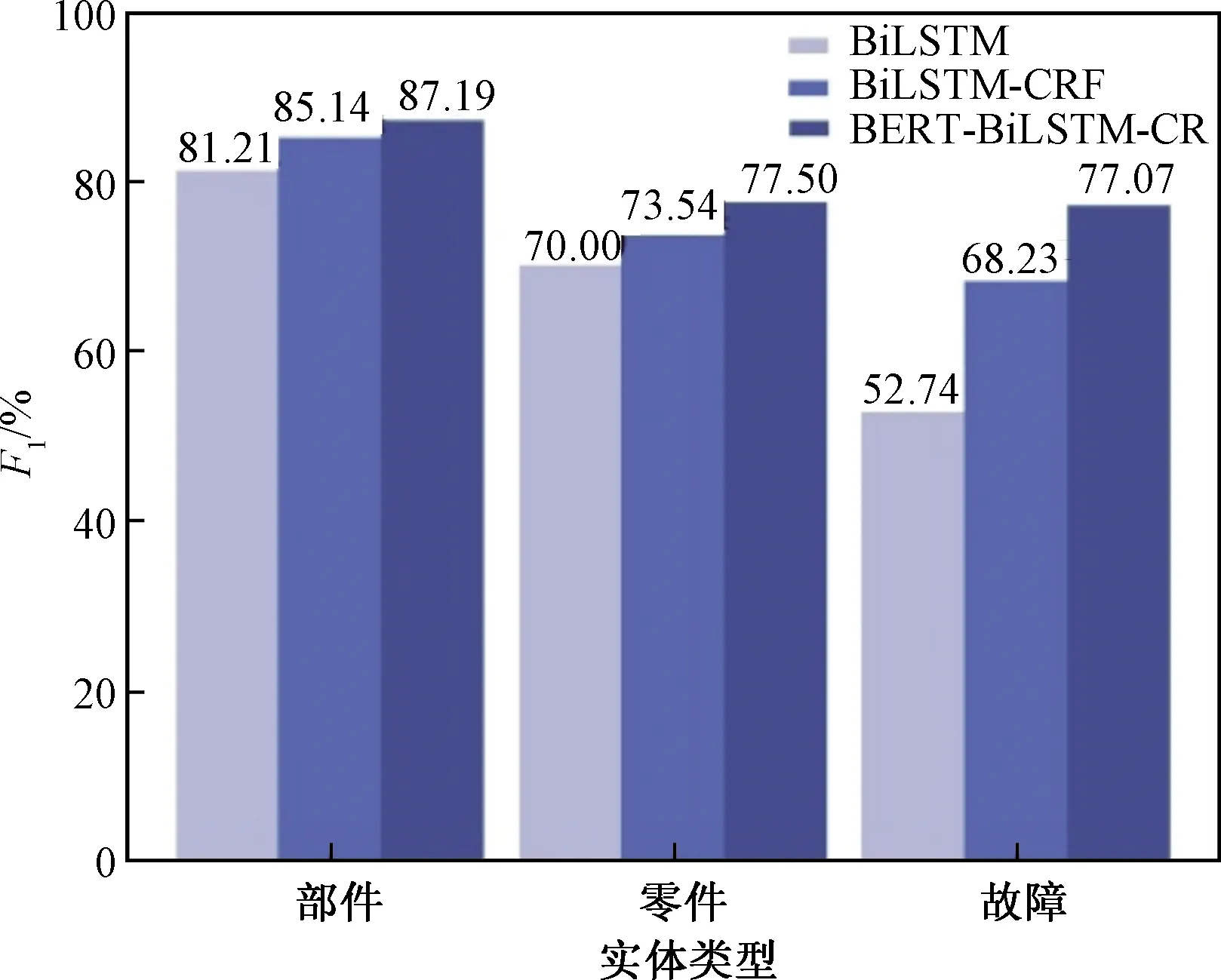
图4 3种模型各个实体上的F1Fig.4 F1 value on each entity of the three models
3 结论
针对数控机床故障领域的命名实体识别问题,制定相应的标注策略,提出BERT-BiLSTM-CRF模型。采用BERT编码层将输入序列编码成向量,使用BiLSTM交互层提取上下文特征,通过CRF推理层对实体标签进行预测。在某机械工厂故障数据集下的实验结果表明,BERT-BiLSTM-CRF模型能够有效处理命名实体识别问题,较现有模型性能好。所提出模型为数控机床故障领域的实体标注策略提供了参考,同时也为其他垂直领域的命名实体识别提供了一种有效的学习思路。数控机床故障领域的命名实体识别性能的提高,有助于构建领域内知识图谱,在未来的工作中将聚焦于数控机床故障领域的知识图谱构建。
