基于LSTM-XGboost组合的超短期风电功率预测方法
2022-06-14王愈轩梁沁雯章思远刘尔佳黄永章
王愈轩, 梁沁雯, 章思远, 刘尔佳, 黄永章
(华北电力大学电气与电子工程学院, 北京 102206)
相较于其他可再生能源,风电的技术成熟度较高且适用于规模化应用,风能近年来大力发展,截至2020年底中国风电发电量达到4 665亿kW·h,由于风电出力的随机波动性和间歇性[1],大规模风电并网给电网安全稳定运行带来了挑战,因此,有效挖掘影响风电采集数据特征信息,提高风电功率的预测精度对于电网安全稳定运行具有重要的意义[2]。
针对风电功率预测问题,目前已有不少中外学者开展相关研究,按方法大致可以分为单一模型预测和组合模型预测。常见的单一模型方法有主要有支持向量机(support vector machine, SVM)[3],BP神经网络(back propagation neural network,BPNN)[4]、卷积神经网络(convolutional neural networks, CNN)[5]、长短期记忆网络(long short-term memory,LSTM)[6]、极限梯度提升 (extreme gradient boosting,XGboost)[7]等。单一模型由于预测误差较大,在实际应用中受限,组合模型通过融合其他算法在数据特征处理及预测性能上的优势,进一步提升是模型的预测精度,因而被广泛应用于各类时序预测问题当中。常见的组合预测方法有模态分解法、最优加权组合法、误差倒数法等[8-10]。文献[11]基于互补集合经验模态分解法(complementary ensemble empirical mode decomposition, CEEMD),将风电功率进行分解,建立各分量差分自回归滑动平均(auto-regressive moving average model,ARIMA)预测模型,构建了CEEMD-ARIMA组合的预测模型。文献[12]基于集成经验模态分解(EEMD)方法分解风电功率特征,然后使用自适应布谷鸟算法(automatic cuckoo search,ACS)改进的最小二乘支持向量机(least squares support vector machines,LSSVM)模型进行预测,构建了EEMD-ACS-LSSVM组合的短期预测模型。文献[13]基于自适应智能灰色系统(automatic adaptive intelligent gray system,SAIGM)和遗传算法优化核极限学习机(kernel based extreme learning machine,KELM)构建了SAIGM-KELM组合的预测模型。文献[14]采用CNN对风电数据进行特征提取,并将其作为梯度提升学习(light gradient boosting machine, lightGBM)模型的数据输入,构建了CNN-lightGBM组合的短期预测模型。文献[15]通过注意力模型(attention models,AM)优化LSTM网络的权重, 构建了AM-LSTM组合的超短期风电功率预测模型。文献[16]分别建立LSTM和lightGBM预测模型,然后基于最优加权组合方法构建了组合预测模型。
综上所述,组合模型因其精度高被广泛应用于风电功率预测问题当中,因此,探索其他形式的组合模型在风电功率中的预测仍需深入研究。
有鉴于此,现提出一种基于LSTM-XGboost组合的超短期风电功率预测方法。首先,基于风电场采集的气象数据,采用皮尔逊相关系数法筛选与风电功率强相关的气象数据,建立风电功率预测模型数据集;然后,将归一化处理的数据集作为LSTM和XGboost的模型输入,分别构建LSTM和XGboost的超短期风电预测模型,在此基础上,采用误差倒数法对LSTM和XGboost的预测数据进行加权构建组合预测模型;最后,以未来4 h风电功率变化为预测目标,结合张家口某示范工程风电场实际运行数据验证组合模型的有效性,为超短期风电功率预测问题提供了一种新的预测方法。
1 气象数据与风电功率相关性
气象数据是影响风电功率变化的主要原因,分析气象数据与风电功率的相关性有利于量化不同气象数据对风电功率的影响程度。常见的气象数据包括风速、风向、空气密度、温度、气压等。采用皮尔逊相关系数(Pearson product-moment correlation coefficient, PPMCC),其值介于-1~1,两个样本X、Y之间皮尔逊相关系数rXY计算公式为

(1)
式(1)中:rXY为皮尔逊相关系数;n为样本X、Y的长度;xi、yi分别指样本X、Y的实际值。rXY值越接近-1表明样本X、Y具有较强的负相关,rXY数值越接近1表明样本X、Y具有较强的正相关。
2 基于LSTM-XGBoost组合模型构建及其预测流程
2.1 LSTM预测原理
LSTM被广泛应用于预测问题当中,它是一种特殊的RNN,能够在模型训练中学习长期的数据变化规律。LSTM的预测模型通过遗忘门控制信息保留,输入门控制信息输入,输出门控制信息输出来完成预测任务[17],其原理结构图如图1所示。
LSTM学习网络训练过程为
ft=ε(gf[ht-1,xt]+bf)
(2)
it=ε(gi[ht-1,xt]+bi)
(3)
ot=ε(gc[ht-1,xt]+bf)
(4)
ct=ftct-1+ittanh(go[ht-1,xt]+bc)
(5)
ht=ottanh(ct)
(6)
式中:ε、tanh为激活函数;ft为遗忘门输出;it为输入门的输出;ot为输出门输出;ct为当前时刻t神经单元状态;ht为t时间步下的LSTM记忆单元的输出;gf为遗忘门权重;gi、gc为隐藏输入门权重;go为单元到输出门权重;bi为输入门参数;xt为当前t时间步的输入;bf为当前隐藏层遗忘门的偏差值;bi为当前隐藏层输入门的偏差值;bc为当前隐藏层记忆单元的偏差值。

图1 LSTM预测原理Fig.1 LSTM algorithm prediction principle
总的来说,LSTM模型控制每一个时间步下的记忆单元,决定当前时间步下保留多少上一个时间步的状态信息,以及传递多少信息给下一个时间步,LSTM模型通过控制和保护信息流的状态,得到较为准确的预测结果。
2.2 XGboost预测原理
XGboost在GBDT算法基础上对boosting进行改进建立的集成模型,其内部决策树使用的是梯度提升树。提升树的分裂结点对于方差损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,预测结果是每棵树的预测结果的累加和[18],假设存在M棵决策树,其模型输出的预测结果为

(7)

图2 树集成过程Fig.2 Tree integration process
定义XGboost的目标函数为

(8)

(9)

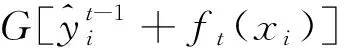
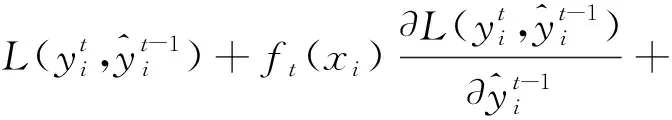


(10)

树模型的复杂度Ω(ft)计算公式为

(11)
式(11)中:γ为控制叶片数量参数;T为叶子节点数;λ为正则项参数;ωj为第j个叶子节点的权重。





(12)
通过对ωj求导等于0,可以得到ωj的表达式为

(13)
将ωj代入目标函数[式(12)]进行最后简化,过程为



(14)
由式(11)~式(14)可以看出,预测模型在迭代过程中,通过不断计算节点损失值,得到ωj和目标函数的最佳值,选择增益损失最大的叶子节点,进而得到最优预测模型。
2.3 组合模型构建

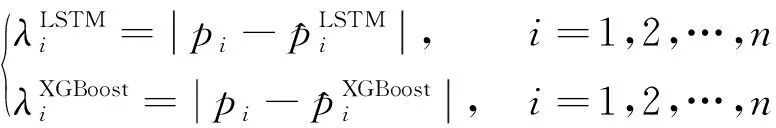
(15)



(16)
式(16)中:pi为风电功率真实值;n为预测时间段内的样本数量。
由式(16)可知,组合方法是将较大权值赋给预测误差小的模型,从而使得整体预测误差变小,进而提升模型预测精度。
2.4 组合模型预测流程
组合模型预测流程如图3所示,主要包括数据预处理、数据相关性分析、数据集划分、LSTM和XGboost 预测模型构建及其参数调试、组合模型构建、预测结果分析。其中,LSTM和XGboost预测模型构建过程、组合模型构建过程分别在2.1节、2.2节、2.3节做过相关叙述,在此不再赘述。

图3 组合模型预测流程Fig.3 Combination model forecasting process
(1)数据相关性分析。采用皮尔逊相关系数法分析气象数据与风电数据的相关性,从而更好判断不同气象数据对于风电功率预测的影响程度,通过数据特征相关性分析,筛选影响风电功率较大的数据特征,将其作为预测模型的数据输入,简化预测模型计算的工作量。
(2)数据预处理。预测数据集主要包括风电功率及其相关的气象数据,模型预测前需将数据集中的坏数据进行剔除。由于风电功率与气象数据量纲不同、数值差异性较大,需对其进行标准化处理。
(3)数据集划分。将风电功率和气象数据按比例随机划为训练集、测试集。训练集的数据用于预测模型的训练学习,然后把训练之后的模型放到测试集的数据中进行测试。
(4)参数调试。不同参数对于模型预测误差影响较大,因此需要通过调试得到最优的模型参数。LSTM模型的参数主要有学习速率(learning_rate),LSTM的隐藏层数及其神经元大小,批量大小(batch size),迭代次数等。XGboost模型的参数主要包括树最大深度(max_depth)、学习率(learning_rate)、子模型的数量(n_estimators)、损失函数(objective)、模型求解方式(booster)、L1正则项权重(reg_alpha)、L2正则项权重(reg_lambda)等。
(6)预测结果分析。选取平均绝对百分误差EMAPE、均方根误差ERMSE和平均绝对误差EMAE3种评价指标对模型的预测结果进行评估,其计算公式为

(17)

(18)

(19)

3 算例分析
3.1 数据源和计算平台
以张北某风电场2016全年实际运行数据为例,该项目总装机容量49.5 MW,采样周期为15 min,即每天96个采样点。风场地形主要以剥蚀地形的基性熔岩台地、残丘、残梁为主,山梁及丘陵顶部一般海拔标高在1 500~1 600 m,山梁、山丘呈浑圆状或长垣状,山间沟谷开阔宽缓,场区山梁、山丘多为荒坡地,低缓处为贫瘠的衣耕地。
计算平台主要配置为win10系统,Intel i7-10700@2.9 GHz,RAM 16 GB,LSTM和XGboost预测模型构建及组合模型构建工作均采用Python语言编程实现。
3.2 模型参数设置
通过测试不同的LSTM网络结构,当迭代次数在55次,且第一层隐藏层128个神经元、第二层64个神经元模型时预测误差最低,此时预测模型效果最佳。其他模型参数如表1所示。
同理,设置不同XGboost模型参数,通过搜索寻优观察模型训练、参数误差值的变化得到最优XGboost 预测模型参数,结果如表2所示。
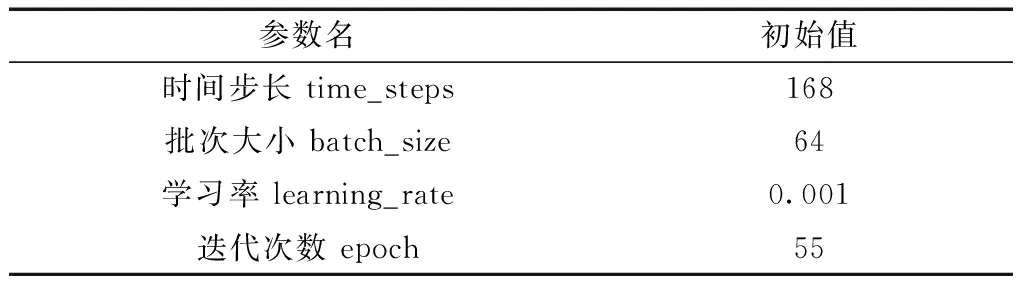
表1 LSTM预测模型参数

表2 XGboost预测模型参数
3.3 相关性结果分析
通过皮尔逊相关系数方法得到风电功率与各气象数据的相关系数,结果如表3所示。
从表3可知,风电功率与风速、空气密度、风向呈较强的正相关,其中与风速的相关性最高,相关系数高达0.853。风电功率与温度存在较强的负相关,因此,温度较低的冬天是风力发电的高峰期。将上述5个强相关的气象数据和风电功率作为后续预测模型的数据输入。

表3 风电功率与气象数据的相关系数
3.4 预测结果分析
依据《风电功率预测功能规范》对超短期风电功率预测定义为未来0~4 h内的风电功率变化[19],故选取未来4 h(16个预测点)的风电功率变化作为预测目标。风电功率变化特征复杂,大体可以分为上升、下降、低谷、高峰4个时期。为有效衡量模型在上述各个时期的预测效果,分别选取4月10日12:00—16:00(上升期)、7月10日00:00—4:00(下降期)、10月9日4:00—8:00(低谷期)、1月 10日00:00—4:00(下降期)来验证各模型的预测效果,表4展示了各时期风电功率大小的基本参数。
首先构建LSTM、XGboost、SVM、BPNN 4个单一预测模型,然后基于2.4节的方法构建LSTM-XG-boost组合模型,将上述4个时期作为各模型的预测目标进行对比分析,不同模型在各时期的预测效果如图4所示。由图4可知,相较于其他4种单一模型,LSTM-XGboost组合模型预测曲线和真实值更为接近,组合模型预测误差较小,具有更高的预测精度。组合模型能有效应对不同时期的预测任务。

表4 风电功率大小的基本参数

图4 风电功率预测曲线Fig.4 Wind power forecast curve for each period
表5为各模型在不同时期的预测误差结果。从表5的3个评价指标可知,组合模型在各时期的预测误差都是最小,其次是LSTM和XGboost模型,误差较大的是SVM和BPNN模型。以平均绝对百分误差EMAPE为例来说明组合模型在各时期与其他模型预测误差的降低幅度,相较于LSTM、XGboost、SVM、BPNN模型,上升期组合模型平均绝对百分误差EMAPE分别降低了13.73%、14.46%、48.19%、51.07%;下降期组合模型平均绝对百分误差EMAPE分别降低了15.06%、16.32%、38.74%、45.46%;低谷期组合模型平均绝对百分误差EMAPE分别降低了18.96%、21.40%、51.76%、43.03%;高峰期组合模型平均绝对百分误差EMAPE分别降低了14.00%、19.39%、52.60%、55.15%。

表5 模型预测误差对比
4 结论
针对大规模风电功率预测问题,为提高风电功率预测精度,基于组合预测理论提出了LSTM-XGboost 组合超短期风电功率预测模型。以张家口某示范工程风电场实际运行数据验证了模型的有效性,得出以下结论。
(1)相较于其他4种单一预测模型,LSTM-XGboost 组合预测模型具有更高的预测精度。
(2)LSTM-XGboost组合模型能够有效应对风电功率变化,组合模型在上升、下降、低谷、高峰4个变化时期均具有较好的跟随性,预测曲线和真实值更为接近,因此能有效满足不同的预测任务。
(3)采用误差倒数法构建的LSTM-XGboost组合模型,能够有效发挥两种单一模型的预测优势,进一步提高了模型的预测精度。
近年来,风电装机规模持续增加,伴随着数据采样周期变短,风力发电采集数据呈现规模化增长趋势,如何组合最新智能算法进一步提高风电功率预测精度是未来重点研究方向。
