基于多目标遗传算法的微服务粒度识别方法
2022-06-13袁海铭
袁海铭
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
近年来,微服务架构的提出改变了应用程序创建、测试、实现及维护的方式。而微服务架构在给人们带来便捷的同时,也存在一些明显的问题。其中,如何确定微服务的适当大小(粒度),是最常被讨论的问题之一。HASSAN 等人[1]提出了微服务环境,它是一种针对微服务粒度的体系结构元建模方法,使用“切面”来定义在运行时支持粒度变化所需的适应行为。HASSELBRING 等人[2]为了达到足够的粒度,建议在整个业务服务的自包含系统中进行垂直分解。GOUIGOUX 等人[3]解释说,粒度的选择应该基于质量保证成本和部署成本之间的平衡。本文旨在利用多目标遗传算法,以敏捷方法中的用户故事这一概念作为输入,来对微服务架构的粒度划分进行研究。当前,微服务的拆分主要应用于棕地应用领域(即现有系统迁移到微服务),很少有研究针对绿地应用领域(即重新构建一个新的系统),因为将单体系统重构为微服务系统的传统观念一直影响着相关从业人员。本文研究将主要集中于构建新的微服务应用程序,即“绿地问题”。从一组功能需求开始,这些需求在产品待办事项(Product Backlog)[4]中以用户故事的形式表现出来;通过以用户故事之间的依赖关系作为输入,使用多目标遗传算法中的NSGAII 算法对微服务粒度进行识别。本文的主要贡献在于提出了用于识别微服务粒度的模型,建立分配给微服务的用户故事数量和作为应用程序一部分的微服务数量,确保微服务具有低耦合性和高内聚性。通过对比NSGAII 算法与另外三种多目标优化算法的性能指标来对算法优劣做出评价,辅助架构师做出合理的微服务拆分决策。
1 微服务粒度模型的建立
确定微服务粒度模型,可以明确对微服务粒度产生影响的相关指标有哪些,并在这些指标的基础上得出相应的目标函数。目标函数旨在最小化耦合指标和加权服务接口数指标,最大化内聚性指标。目标函数将在粒度模型提出之后定义,本文将基于微服务架构的应用程序的粒度模型表示为:

式中:MS表示一组微服务集,MS={MS1,MS2,…,MSn};而MTS是一组为MSGM计算的指标。然后:

式中:MSi是第i个微服务,US是与第i个微服务相关的用户故事集,可以给出US={US1,US2,…,USn},MTS是一组计算MSi的指标。在这种情况下,模型中计算和使用的指标对应于耦合性、内聚性以及与微服务相关的用户故事数量。这些指标的定义如下。
1.1 耦合性指标
将耦合指标定义为Coup={AIS,ADS,SIY},其中,AIS表示服务的绝对重要性,ADS表示服务的绝对依赖性,SIY表示服务的相互依赖性。这些指标是根据每个微服务的用户故事的依赖性来计算的。
AISi是至少调用一个微服务操作的客户数量。在系统层面,定义AIS向量。该向量包含每个微服务计算出的AIS值,因此在计算其系统级上的值时,可以将其定义为:ADSi是第i个微服务所依赖的其他微服务的数量。可以将其定义为:
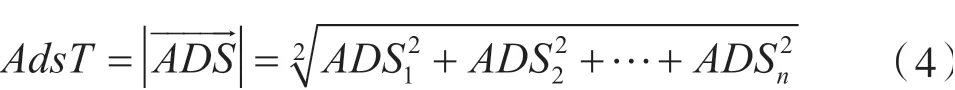
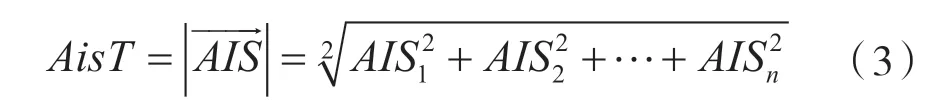
SIY定义了相互依赖的微服务对的数量除以微服务的总数量,其被定义为:
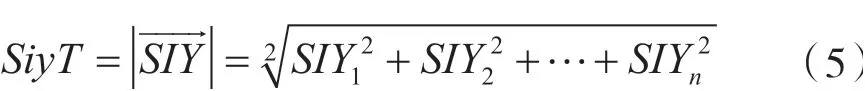
用Coup代表这三种指标的合并,可以将Coup表示为:
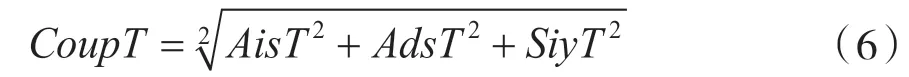
1.2 内聚性指标
同理,第i个微服务的内聚性定义为缺乏内聚性度量(LC),每个微服务的内聚度定义为缺乏内聚性度量除以作为应用一部分的微服务总数的比例。

式中:n表示微服务的数量,则Coh可以表示为:
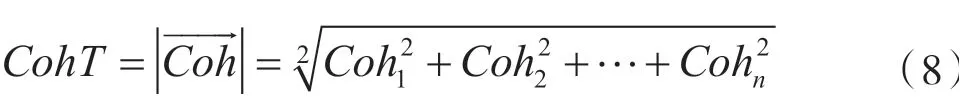
加权服务接口数量(Weighted Service Interface Count,WSIC)这一指标概念源于面向服务架构(Service-Oriented Architecture,SOA)的设计指标,它表示WSDL 文档(一种简单的XML 文档,包含一系列描述某个网络服务的定义)中定义的每个服务公开接口或操作的加权数,默认权重设置为1。对于本文的模型,用户故事与操作相关,因此将这个指标调整为与微服务相关的用户故事的数量。采用WSIC作为分配给每个微服务的用户故事数。然后将WsicT定义为与微服务相关联的最大用户故事数,可以将其表示为:
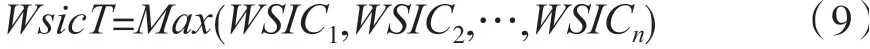
在内聚性与耦合性指标的基础上,结合加权服务接口数量,可以将目标函数表达为以下等式:
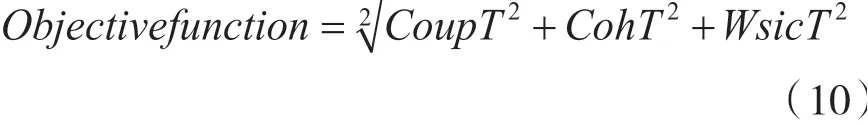
式(10)可以确定分解的结果是好是坏。一个低的目标函数值是模型想要获得的,因为模型的目标是获得一个较低缺乏内聚度量、低耦合以及较小的加权服务接口数量的解决方案,最后通过多目标优化遗传算法试图找到指标间最好的组合。
2 基于多目标搜索遗传算法的微服务识别
遗传算法由HOLLAND 等人[5]首次提出,它是具有迭代性的。在每次迭代中,选择最优的个体,每个个体都有一条染色体,与另一个个体杂交产生新的种群,产生一些突变来寻找问题的最优解。而在遗传算法中,为了解决多目标问题,将使用非支配排序遗传算法(NSGA-II)。NSGA-II 在软件重构中得到了广泛的应用。这种有效的遗传技术可以在近似最优解所在的位置搜索分布良好的帕累托前沿,最后得到一组帕累托最优解,这些解就是最后的目标解。本文的遗传算法包括自动分配或分配用户故事给微服务,考虑耦合和内聚指标,实现方法如下。
2.1 初始种群的生成
假设根据用户的需求和架构师的设计,得到一组用户故事集US={US1,US2,…,USm},这些用户故事必须分配给它们所属的微服务,有一组微服务集MS={MS1,MS2,…,MSn}以及从用户故事中包含的信息计算出的一些指标。父代染色体的定义是从用户故事分配到微服务,采用二进制编码,1 表示某个用户故事分配给一个微服务,而0 表示没有用户故事分配给微服务,由此可以得到一个分配矩阵,其中列为用户故事,行为微服务。现给出示例,假设有两个微服务MS={MS1,MS2}和5 个用户故事US={US1,US2,US3,US4,US5}的例子。矩阵如表1 所示:
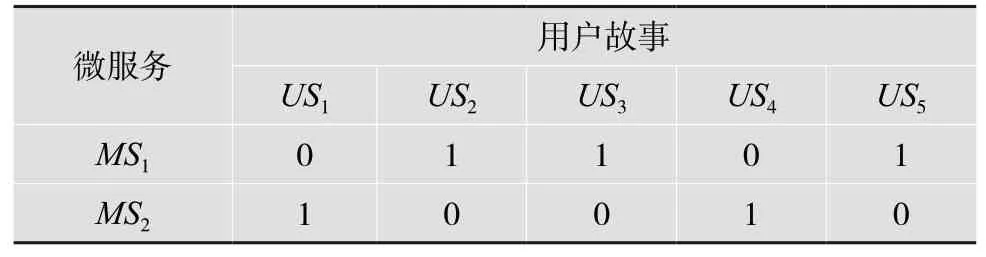
表1 用户故事与微服务对应表
通过该矩阵图可以看出,用户故事2、用户故事3、用户故事5 被分配到微服务1 中,而用户故事1、用户故事4 被分配到微服务2 中。这样一来,就可以得到父代的染色体。染色体将是每个用户故事分配给每个微服务的并集,对于本文的假设,它将是01101 10010。基于这条染色体,定义适应函数或目标函数。该目标函数基于所提出的耦合性指标、内聚性指标以及用户故事指标的组合。所使用的目标函数如下:
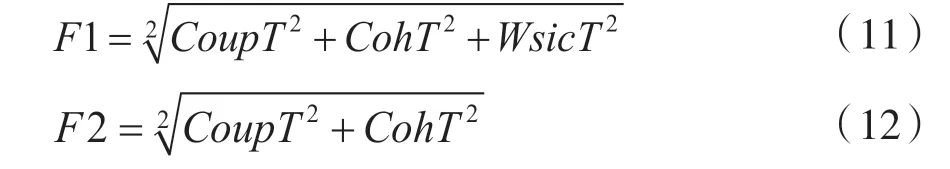
2.2 交叉算子介绍
一个不同的分配将从选定的父代生成。在这种情况下,双亲是从种群中随机选择的,为了生成子节点信息,需要从双亲节点获取信息,从分配矩阵中获取父节点的第一列,并连接母节点的最后一列,生成一个新的分配。此过程必须考虑到一个问题,即一个用户故事不能被分配两次,这意味着在分配矩阵中,每一列都只能出现一个用户故事。在实验中,将使用SBXcrossover 交叉算子。
2.3 变异方法
突变表示随机地改变一个染色体。在本文的问题中,突变表示染色体从1 到0 或者从0 到1 的改变,这意味着一个用户故事被分配到或者没有被分配到一个微服务,以及必须分配或者没有被分配到另一个微服务。因此,染色体上将有两个基因发生改变,示例如下。所获得的染色体的第七位发生突变01101 10010,突变后的染色体为01101 11010。
在这种情况下,染色体的第七位基因0 必须改为1,即矩阵中第二列中的用户故事必须分配给第二个微服务,同时从第一个微服务中取消分配。突变的染色体必须包含在群体中。这个过程是随机进行的,从种群中选择要突变的个体,也随机进行基因的突变,对于突变目标函数的值被计算并包含在总体中。
2.4 参数设置
根据NSGAII 算法的现有工作校准了关于实验的参数,将种群规模设置为25 个个体,因为根据实验,这一设置能够实现有效性和效率之间的平衡。使用0.8 作为交叉概率,0.05×log2(n)作为变异概率。将最大代数配置为200 次,搜索过程重复30 次,以减少遗传算法随机性造成的偏差。
2.5 候选微服务的获取
在CargoTracking 的示例中,通过NSGA-ii 算法的处理,使用Matlab 对算法进行编码。输入用户故事依赖,得到4 个由用户故事组成的微服务,分别如图1、图2 所示。
图1 用户故事依赖输入图
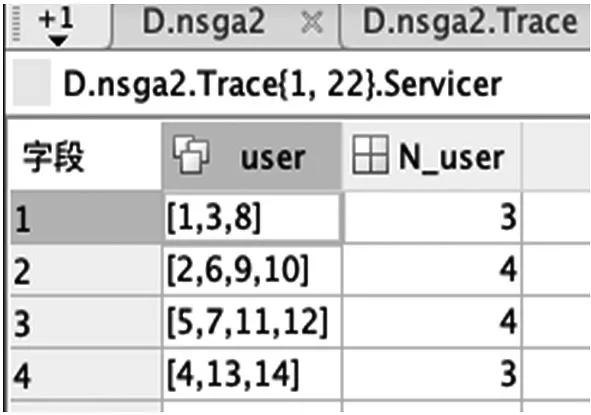
图2 微服务粒度识别结果图
3 多目标优化算法性能对比
将NSGAII 算法与另外三种主流多目标优化算法的性能指标进行对比,来比较不同多目标优化算法之间对于识别微服务粒度的效果而言的优劣程度。首先对三种算法加以简要介绍。
第一种算法是强度帕累托进化算法[6](Strength Pareto Evolutionary Algorithm 2,SPEA2)。相比于SPEA 算法,SPEA2 采用了改进的适应度分配方式。该方式充分考虑了每个个体中所支配和被支配的个体数量,并且采用了最近邻密度估计技术。这使其能够更精确地指导搜索过程,另外还有一种新的存档截断方法保证了边缘解的保留。
第二种算法是基于分解的多目标进化算法(Multi-Objective Evolutionary Algorithm Based on Decomposition,MOEA/D)[7]。该算法将一个多目标优化问题划分为多个标量优化子问题,并同时对子问题进行优化。每个子问题可仅通过运用其他几个邻近子问题的信息进行优化。通过这种方式,降低了计算复杂度,提升了算法的效率。
第三种算法是多目标粒子群算法[8](Multi-Objective Particle Swarm Optimization,MOPSO),是在粒子群优化算法的基础上实现的,其灵感来源于鸟群的编排。该算法也可被认为是一种分布式行为算法,它采用群体智能的进化技术,并由于其特殊的搜索机理以及优异的收敛特性而被广泛应用于多目标优化领域。
3.1 性能指标介绍
GD(Generational Distance) 和IGD(Inverted Generational Distance)是测量帕累托近似解和帕累托真实解之间收敛性(或紧密度)的性能指标[9]。GD 是一种误差度量,用于检查通过算法得到的帕累托近似解(PFapprox)与已知帕累托最优解(PFtrue)之间的距离。而IGD 是基于GD 的指标,其目标是评估帕累托最优解(PFtrue)到帕累托近似解(PFapprox)的距离,它的逆由GD 来考虑。
GD 和IGD 的值趋向于零,是本文研究希望得到的,因为这就表明PFapprox和PFtrue的值比较接近。HV(Hyper Volume)测量从参考点到解决方案空间前沿的目标空间面积,该指标可以分析帕累托前沿的紧密度和多样性。通过将解的前沿归一化到[0,1]来计算这个指标。具有高HV 值的帕累托前沿是最好的,因为它们的解决方案远离参考点。4 种算法性能指标的折线图与条形图如图3、图4、图5所示。
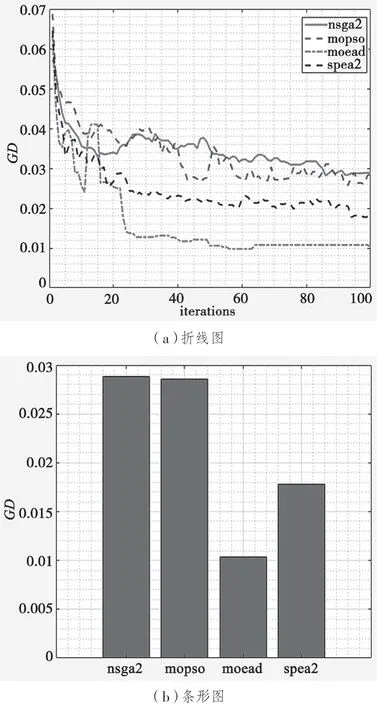
图3 基于GD 指标的算法性能对比
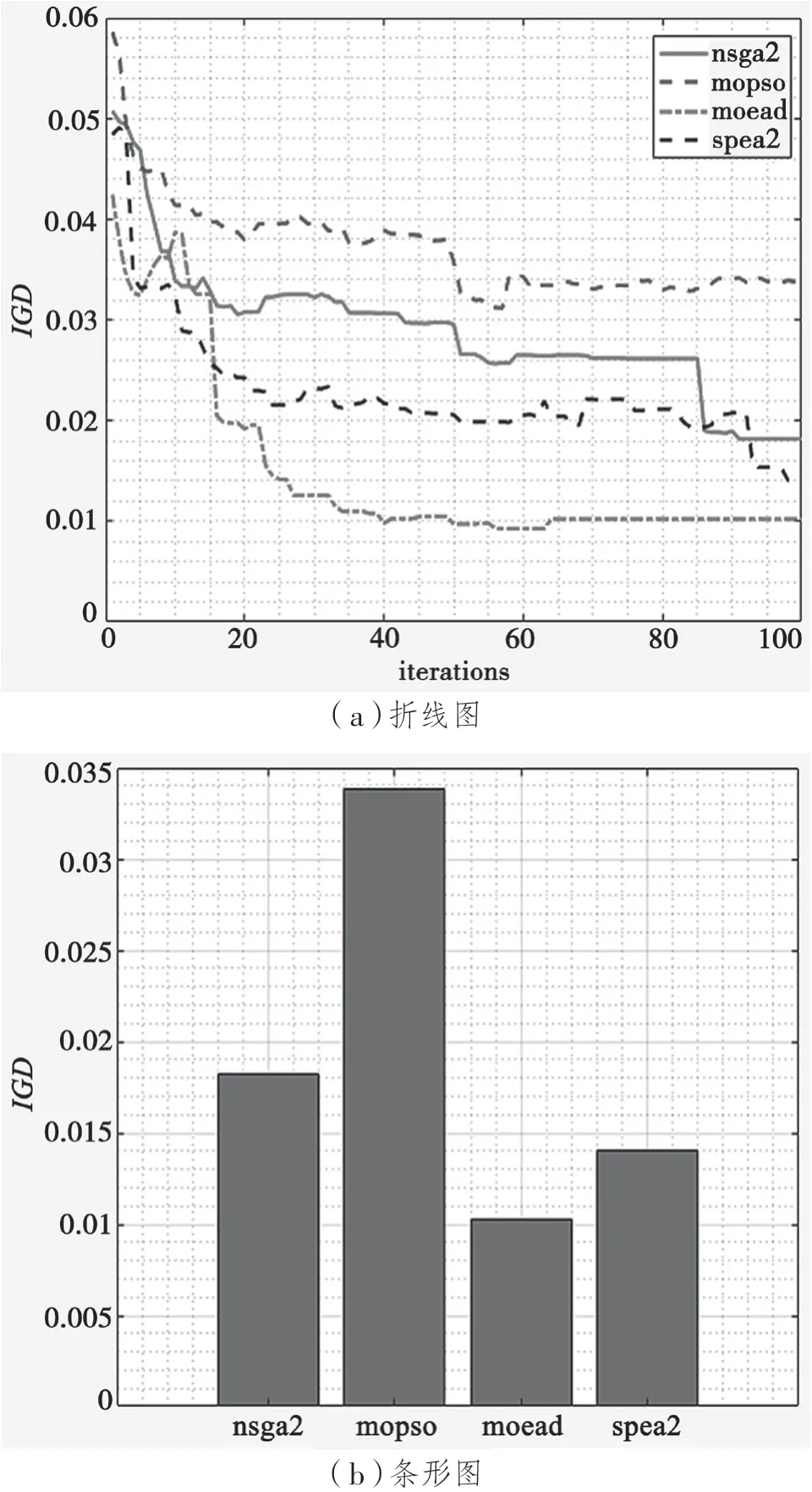
图4 基于IGD指标的算法性能对比
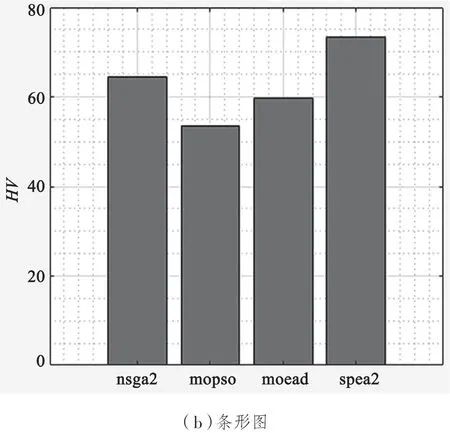
图5 基于HV 指标的算法性能对比

3.2 性能指标对比分析
为了评估不同的多目标优化算法的优劣程度,对算法的性能指标进行分析。根据上一小节描述可知,本文研究希望获得较小的GD和IGD值。因为这两个性能指标越小,说明算法的求解性能就越好。较大的HV值、高HV值同样说明算法具有较好的求解性能。
从折线图可以看出,对于GD值来说,基于分解的多目标遗传算法的性能优势优于其他三种多目标优化算法;从条形图可以看出,NSGAII 算法与MOPSO 算法的性能差异不大,差于SPEA2 算法,而MOEA/D 算法的求解性能最好。
对于IGD值来说,从折线图可以看出,MOEA/D 算法的性能优于其他三种算法;从条形图可以看出,MOEA/D 算法的求解性能最好,NSGAII 算法和SPEA2 算法的性能差异不大,而MOPSO 算法的求解性能最差。
对于HV值来说,从折线图可以看出,SPEA2算法和NSGAII 算法明显优于其他两种算法;从条形图可以看出,SPEA2 算法的求解性能最好,NSGAII 算法和MOEA/D 算法的性能差异不大,MOPSO 算法求解性能最差。
通过比较算法性能指标可得知,对于不同的性能指标,不同算法的性能表现各有差异,但总体来说,SPEA2 和NSGAII 两种多目标优化算法具有更好的表现。
4 案例研究以及实验对比
案例研究中,使用微服务架构领域的基于SpringBoot 框架的CargoTracking[10]应用程序。该应用程序是运用领域驱动设计(Domain Driven Design,DDD)进行微服务划分的经典项目。CargoTracking的重点是通过路由规范在两个地点之间进行货物的运输(由TrackingID 标识)。一旦货物可用,它就与从现有Voyages 中选择的一个货运计划相关联,然后,HandlingEvents 跟踪行程中货物的进度,完成货物的追踪,而货物交付描述了具体的运输状态、预计到达时间,以及该货物当前是否被跟踪,且在航线上。基于这一系列的业务逻辑,本文提取并提出了用户故事,如表2 所示。
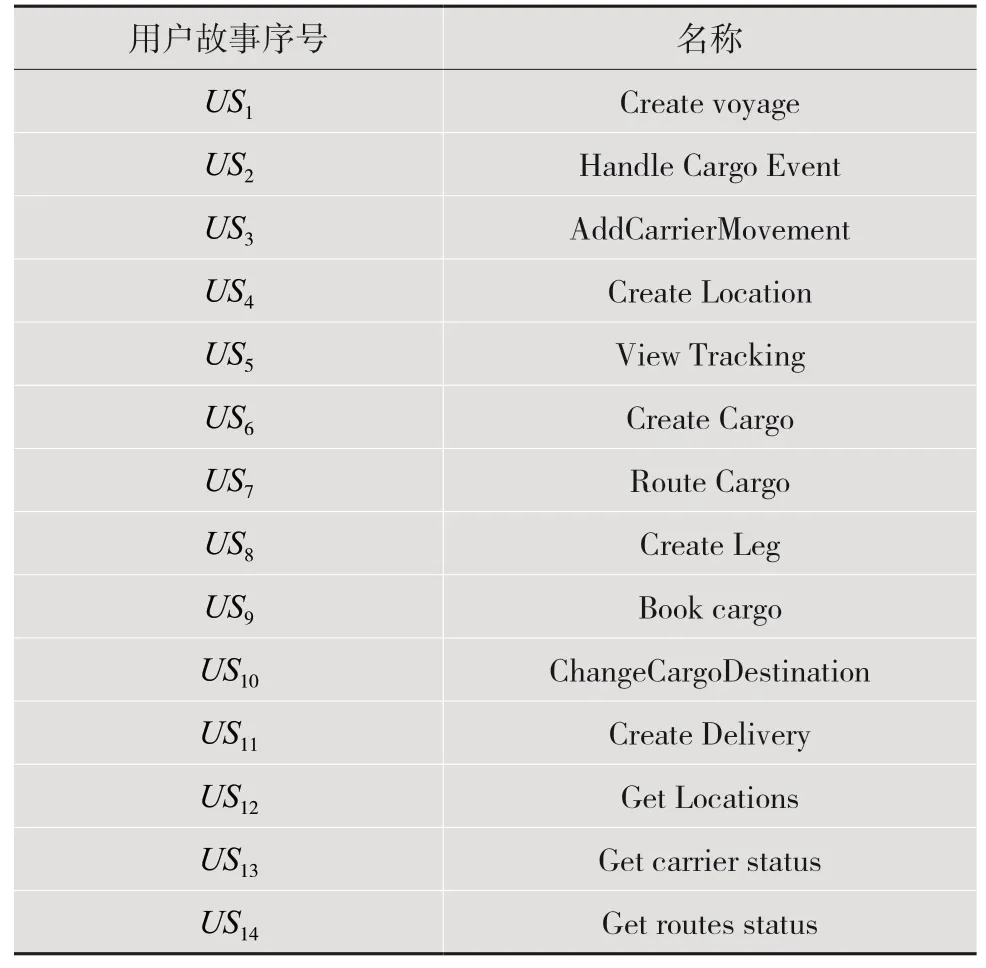
表2 用户故事列表
其中,如何识别用户故事之间的依赖,是一个比较重要的问题。本文从程序源代码中分析每个用户故事之间的调用关系,通过调用关系来识别用户故事之间的依赖。例如,要创建一个航行(voyage),必须首先获得位置(Location),这意味着用户故事1 依赖于用户故事12。其他类似的用户故事依赖如表3 所示。
以表3 中的用户故事依赖作为输入,使用NSGAII 算法对微服务粒度进行识别,识别后得到的结果如表4 所示。
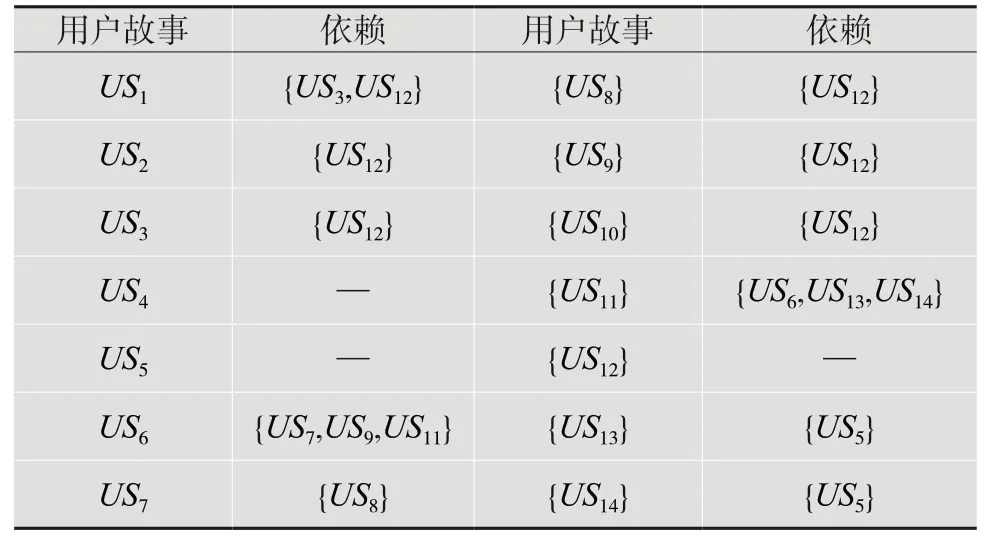
表3 用户故事依赖表
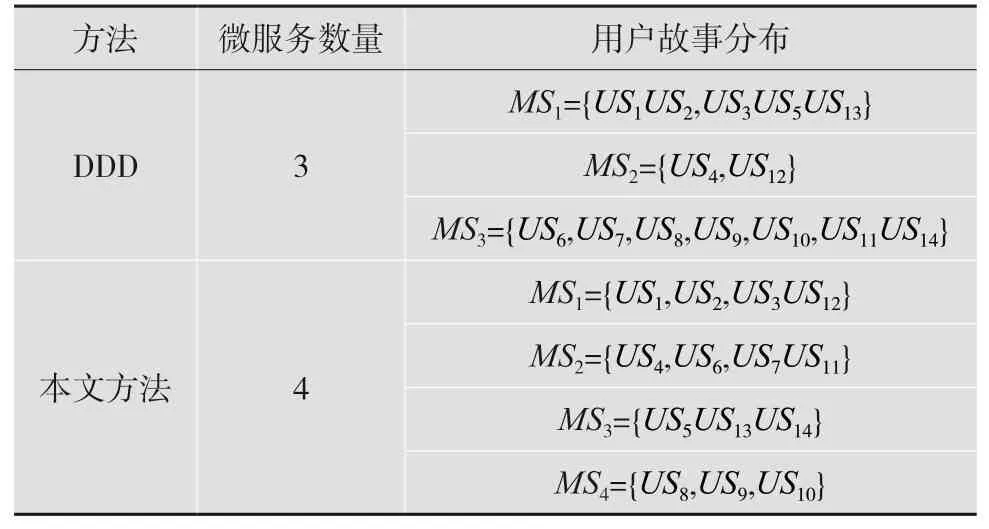
表4 用户故事分布对比表
将基于NSGAII 算法的微服务粒度识别方法与传统的微服务粒度识别方法DDD(领域驱动建模)的指标进行对比,从而选择具有更好效果的方法。指标评估如表5 所示。
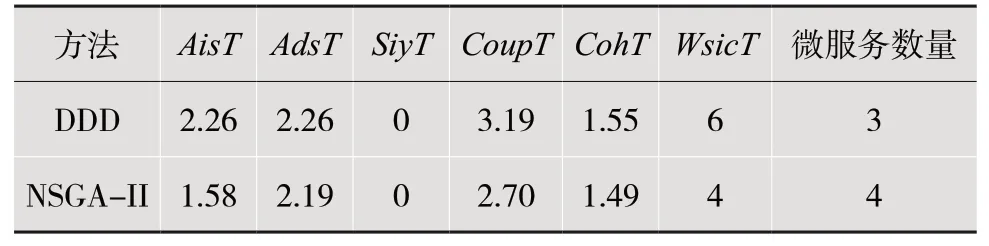
表5 指标评估表
具体评估过程为:根据用户故事之间的依赖,计算得到所提出的指标具体值,对微服务粒度的评估通过这些具体值的比较来实现。在耦合性指标中,有4 种不同类型的指标,分别是AisT,AdsT,SiyT以及这三种指标的结合CoupT,比较本文方法与DDD 方法取得的这些参数的值,具有较小AisT值、AdsT值、SiyT值以及CoupT值的方法为最优方法,因为值较小说明所识别出的微服务粒度具有较低的耦合性。在内聚性指标中,使用CohT来进行评估,比较本文方法与DDD 方法取得的CohT值,具有较大CohT值的方法为最优方法,因为值较大说明所识别出的微服务粒度具有较高的内聚性。与微服务相关的最大用户故事数指标用WsicT表示,比较本文方法与DDD 方法取得的WsicT值,具有较小WsicT值的方法为最优方法,值较小说明所识别出的微服务粒度具有较低的复杂性。
5 结 语
本文不同于以往从遗留系统中利用微服务架构这一技术,对应用程序进行重构,基于用户故事这一概念来设计一个新的微服务运用程序,并结合遗传算法中的多目标优化算法对微服务进行划分,在此基础上将本文所用的多目标优化遗传算法与另外三种算法进行对比,为企业相关架构人员利用微服务架构这一技术对系统进行设计提供了参考。但本文所对比的案例较少,未来的工作中将加入新的项目进行对比实验,对于用户故事之间的依赖将使用自动化工具进行依赖分析。
