融入事件依存路径的事件时序关系识别
2022-06-11李良毅
李良毅
(昆明理工大学,云南 昆明 650504)
0 引言
事件时序关系识别旨在分析文中各事件发生的先后顺序,从时间角度将不同事件联系起来。有效地识别事件时序关系有助于读者理清事件脉络,快速了解事件发展趋势,能够推进信息检索、文本摘要、自动问答等任务[1,2]的研究,也被应用于医疗文本等特定领域中。为区分同一句子中的不同事件,研究者使用事件触发词来定位事件。事件关系识别作为事件抽取的下游任务,通常使用标注事件触发词的文本作为模型输入,现有研究通常聚焦于识别文中事件对的时序关系。以表1中的事件句为例,事件对应的触发词分别是“broke”“running away”与“confront”,分析可知“broke”发生在“running away”之后,因此事件对(“broke”“running away”)对应的时序关系是“before”,同理可得其余事件对的关系。

表1 事件时序关系识别示例
事件时序关系识别是一种分类任务,其特殊性在于不仅需要模型理解事件句中的文本信息,还需要模型学习到文中句法信息。句法信息有助于模型总结上下文的特定模式,理清事件逻辑,一些特殊句法甚至能在关系识别中起决定作用,但由于句法属于隐式信息,模型对于句法信息的学习较为困难。因此,本文提出一种融入事件依存路径的事件时序关系识别方法。该方法在事件表征的过程中,将事件依存路径作为额外的增强信息来强调不同文本中的句法差异,再利用传统的双向长短期记忆网络(Bi-Long Short-Term Memory,Bi-LSTM)提 取事件句的语义信息,最后提出使用特征门控将事件语义信息与句法信息进行结合。该方法显式地将事件依存路径展露给模型,以外部知识的形式将句法信息加入事件表征中,帮助模型分析文本结构,总结句法规律,通过编码后的事件句对来建立事件对之间的联系,实现对事件时序关系的准确识别。
1 研究现状
作为重要的自然语言理解任务,事件时序关系识别被纳入文本时间解析任务Tempeval[3]中,众多学者对此展开了研究。
在早期,人们通过归纳文本中的规律,提出了基于规则匹配的文本时序关系识别方法。Bethard等人[4]基于该思想,提出了使用词性、二进制码、时态等语言特征来制定匹配规则;然而,规则匹配的方法在召回率与实用性方面均不理想。随后研究者尝试使用机器学习方法来识别事件时序关系,例如,Mani等人[5]利用文本时态、实体词性、事件类型等特征,构建了最大熵分类器以实现时序关系的识别。随着机器学习的发展,统计机器学习逐渐应用于事件时序关系识别任务,如Chambers等人[6]提出了将时序识别任务划分为两个任务,首先识别出文中事件与时间表达式,其次对识别出的事件进行时序关系分类。此外,Chambers等人[7]将识别范围从部分事件扩大到全体事件与时间表达式的时序关系识别,并提出了一种联合规则匹配与机器学习的方法。
随着深度学习在众多自然语言处理任务中取得成功,神经网络模型也被大量应用于事件时序关系识别领域中,研究者通过各类神经网络结构来提升识别效果。Meng等人[8]提出了类神经图灵机的时序关系识别模型,该模型能将处理过的事件信息当作先验知识存储下来,辅助后续事件的时序关系识别。Han等人[9]提出了使用联合训练模型来识别事件时序关系,该模型同时训练事件检测与事件时序关系识别两个任务,通过孪生网络来共享编码层,并使用线性规划的方法进行逻辑推理。Han等人[10]又提出了针对特定领域的事件时序关系识别方法,统计不同事件之间的时序关系比例作为先验知识,并将其转换为线性规划问题来辅助事件时序关系识别。Zhou等人[11]针对医学文本领域,提出在训练过程中为损失函数加入基于概率软逻辑的正则化项。上述方法在事件时序关系识别领域中取得巨大成功,这些方法或使用联合模型来增强模型的阅读理解能力,或使用外部规则来辅助模型识别事件时序关系,但它们对于句法知识的利用较少。Cheng等人[12]曾提出公共根的概念,并使用事件依存路径代替文本作为输入,在不需要额外标注信息的情况下,使用Bi-LSTM模型编码事件句的最短依存路径,证明了最短依存路径在事件时序关系识别中的有效性;然而该方法仅截取了部分事件句作为输入,而丢失的上下文中包含着文本语义信息,造成识别性能不佳。因此将事件依存路径作为外部知识更有合理性与可解释性,在保留事件句原貌的情况下加入事件依存路径,可以有效地提高模型性能。
2 融入事件依存路径的事件时序关系识别
本文提出融入事件依存路径的事件时序关系识别模型,将事件依存路径转换为特定形式的连续序列,在标志位的辅助下,使用自注意力编码器对文本与句法知识进行编码,并通过Bi-LSTM提取文本的语义信息,最后利用门控结构计算事件特征。本文模型的总体框架如图1所示,由网络输入层、特征提取层与关系分类层3部分构成。其中,BERT为预训练模型,Sen1和Sen2代表输入的事件句,Input1,Input2和Input3为处理过后的输入。
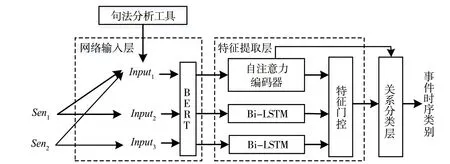
图1 事件时序关系模型框架
2.1 网络输入层
网络输入层将事件句文本预处理为适合编码的形式,再通过预训练模型实现文本到低维词嵌入矩阵的转换。
本文将事件依存路径作为外部知识融入到事件句文本中。事件依存路径是指在依存句法树中事件触发词到依存树根中最短的一条通路,图2展示了事件句S3的依存句法树,以事件“confront”为例,它所对应的事件最短依存路径应为[confront,rushed,running]。
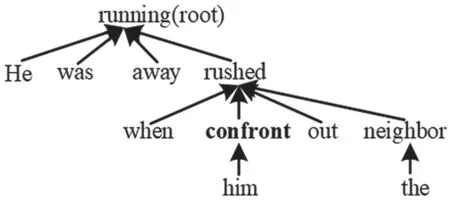
图2 依存句法树示例
S3:He was running away,when the neighbor rushed out to confront him.
受Fan等人[13]启发,本文利用标志位来表示事件的最短依存路径,将隐藏的句法信息显式地展现出来。首先通过句法解析工具得到各个事件的最短依存路径,将该路径转换为[单词<依存关系>]的模板,如S3中的依存关系路径转换为confront
将路径插入到事件句文本中,并使用
通过预训练模型BERT来获得文本对应的词嵌入矩阵,预训练模型要求输入为单个或多个句子。传统方法在编码事件对时序特征时,往往将两个事件句各自独立编码,再将两个句子的事件时序表示进行拼接,造成编码过程中事件句之间的交互较弱,因此模型将输入的两个事件句进行拼接,从拼接后的事件句来提取出全局信息。在开头加入标志位CLS为行业公认,将末尾句号替换为标志位SEP,预处理过后的事件句形式为:

式中:Sen1与Sen2为两个预处理过后的事件句,Input1为处理过后的输入。
在事件句语义的提取方面,本文沿用Bi-LSTM来编码事件语义特征,直接使用两个事件句原文作为Bi-LSTM输入,将两个事件句分别记作Input2与Input3。将上述Input1,Input2,Input3送入预训练模型BERT中,实现文本到词嵌入矩阵的转换,将转换后的向量序列分别对应记作Seq1,Seq2与Seq3。
2.2 特征编码层
特征编码层如图3所示,该结构含有句法与语义两个编码器以及一个计算事件时序表示的特征门控。特征编码层的主要任务是从各类输入的词向量序列中提取出事件的语义特征F2与句法特征F1,并权衡两种特征的重要性,计算出最适合的事件特征向量。

图3 特征编码层模块
2.2.1 语义编码器
语义编码器以事件句向量序列Seq2与Seq3作为输入,Bi-LSTM包含前向与后向LSTM,如式(2)、式(3)所示,该结构分别从前后两个方向读取输入序列,最后将前后两组向量按式(4)所示进行拼接,得到输入序列的向量表征hin,为向量序列融入上下文信息。

2.2.2 句法编码器
句法特征编码器旨在将事件依存路径加入到事件时序表征的编码过程中,建立依存句法与事件句文本的联系,丰富事件时序表征的信息。以Seq1作为句法编码器的输入,基于自注意力机制进行编码。
多头自注意力机制将输入向量Seq1进行3次不同的线性变换,将结果分别记作Q=Rlen×d,K=Rlen×d,V=Rlen×d3个矩阵,其中len代表向量序列的长度,d代表词向量维度。之后按照头的个数切分向量序列中的各个向量,每个头含有一组矩阵,自注意力机制将计算单词两两之间的关联程度,为每个头计算注意力矩阵与注意力得分,计算方式为:

式中:k´为矩阵k的转置;*为点乘。
将各头注意力得分拼接,将结果记作Att,取Att中
2.2.3 特征门控
针对特征编码器输出的语义特征与句法特征,由于模型在面对不同文本时语义与句法特征所占比重不同,因此使用门控机制来计算适合当前事件对的时序表征。将e1与e2进行拼接并记作F1,将e1´与e2´拼接并记作F2。再如式(7)所示,将F1与F2再次拼接后送入tanh激活函数,计算出当前事件对中不同特征所占比例o,依式(8)所示计算出事件对特征F3。
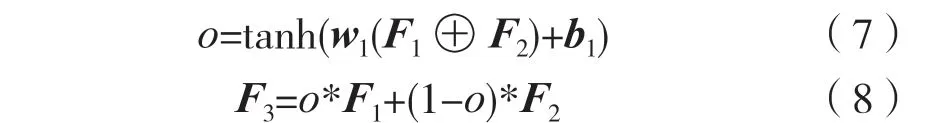
式中:w1为线性层权重矩阵;b1为偏置;*为点乘;⊕代表按最后一位拼接。
2.3 关系分类层
在给定事件特征与事件句特征后,将事件对特征F3与事件句特征c拼接,再通过归一化函数Softmax计算事件时序关系概率分布,具体计算公式为:
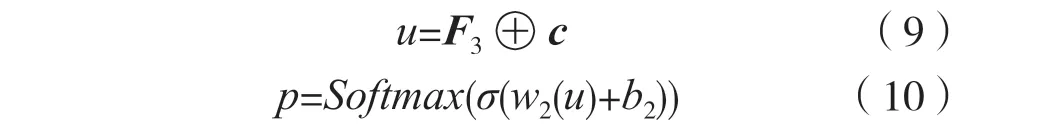
式中:σ为激活函数ReLu;p为关系的概率分布,u为最终的事件时序特征;b2为偏置。
选用交叉熵函数作为模型的损失函数:

式中:n为关系类别总数;当前时序关系属于第i类时,yi为1,否则为0;pi为Softmax函数计算的时序关系属于第i类的概率。
2.4 对抗训练过程
由于在时序关系识别任务中,常常会遇到如“Before”与“After”这类句法角色相似而语义不同的单词,相似的用法导致模型较难区分,因此本文引入对抗训练策略来增强模型的理解能力。对抗训练是Miyato等人[14]提出的一种面向文本序列的监督学习算法,通过重新编码文本向量来扰动模型的判断能力,增强模型对于词语的分辨能力。在训练过程中需要为Seq1,Seq2,Seq3进行再编码,再编码过程为:
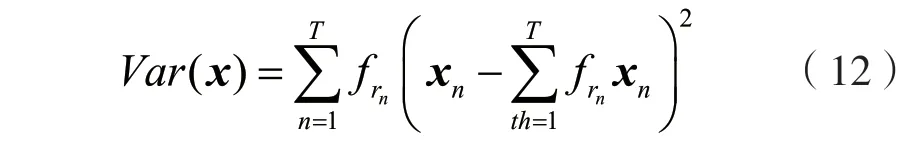
式中:X为需要加入再编码的向量序列;为再编码后的事件句向量序列;T为序列长;frn为事件句文本中第n个单词在训练集中出现的频率;xn为序列中任意词向量,当取某一固定xn时,使用th将词向量遍历。

在训练过程中为句向量序列加入扰动后,在更新参数时将梯度累加,设训练过程中存在batch个批次,按照如下操作进行模型训练:
(1)将该批次中各事件句送入网络输入层,通过预处理与预训练模型将文本转换为Seq1-3。
(2)依式(12),计算词向量对应的扰动ri。
(3)依式(13),为向量序列Seq1-3中各词向量加入扰动,将被干扰后的文本序列记作Seq1-3。
(6)在更新参数时,使用原词嵌入向量序列Seq1-3和梯度grad1更新模型参数θ。
3 实验设计与分析
3.1 数据集介绍
TimeBank-Dense(TB-Dense)是事件时序关系识别任务中使用最为广泛的数据集,已有大量工作基于该语料库进行研究。该英文数据库于2014年发布,从36篇新闻文章中抽取出事件对及对应时序关系共6 088例,并标注了事件触发词、事件句与事件之间的时序关系。TB-Dense语料库共包含6种类型的时序关系:VAGUE、AFTER、BEFORE、SIMULTANEOUS、INCLUDES与IS INCLUDED。各类事件对的具体分布情况如表2所示。
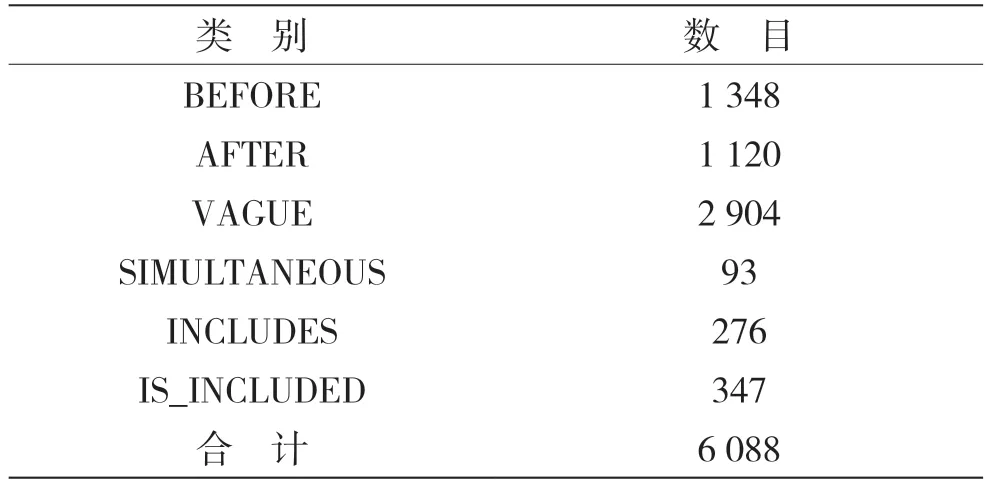
表2 TB-Dense语料库关系分布情况
3.2 实验设置
本文使用谷歌提供的BERT作为预训练模型,与其他事件时序关系方法相同,沿用Micro-F1值作为模型评价指标,选用斯坦福自然语言解析工具Standford CoreNLP作为句法分析工具来生成事件依存路径,模型的超参数设置如表3所示。

表3 参数设置
3.3 基准模型
选用近年优秀方法作为基准模型,下面对各基准模型进行简单介绍:
(1)CAEVO[7]:由Chambers等人于2014年提出的一种基于筛网式结构的方法,该结构中各个筛网由机器学习与规则匹配方法组合而成。
(2)Cheng等人方法[12]:由Cheng等人于2017年提出的一种基于Bi-LSTM的方法,该方法没有使用传统的事件句文本作为输入,转而使用事件句的最短依存路径作为输入。
(3)GCL[8]:由Meng等人于2018年提出的一种基于类神经图灵机的方法,该方法使用类神经图灵机来存储已识别的事件信息,并使用这些信息作为先验知识指导后续事件时序关系的识别。
(4)Joint Structured[9]:由Han等人于2019年提出的一种事件识别与事件时序关系识别的联合训练方法,通过共享事件编码层来丰富事件表示,增强模型理解能力,还利用支持向量机(Support Vector Machine,SVM)降低模型前后矛盾的问题。
(5)CTRL-PG[11]:由Zhou等人于2021年提出的一种面向特定领域的事件时序关系方法,提出在损失函数中加入基于概率软逻辑的正则化项。
(6)CE-TRE[15]:由Wang等人于2020年提出的一种篇章级事件时序关系抽取方法,使用自注意力机制模型融入篇章中其他事件对信息,丰富事件特征。
3.4 实验结果与分析
3.4.1 验证本文模型有效性
表4列出了本文模型与基准模型在TB-Dense数据库上的F1值比对结果。
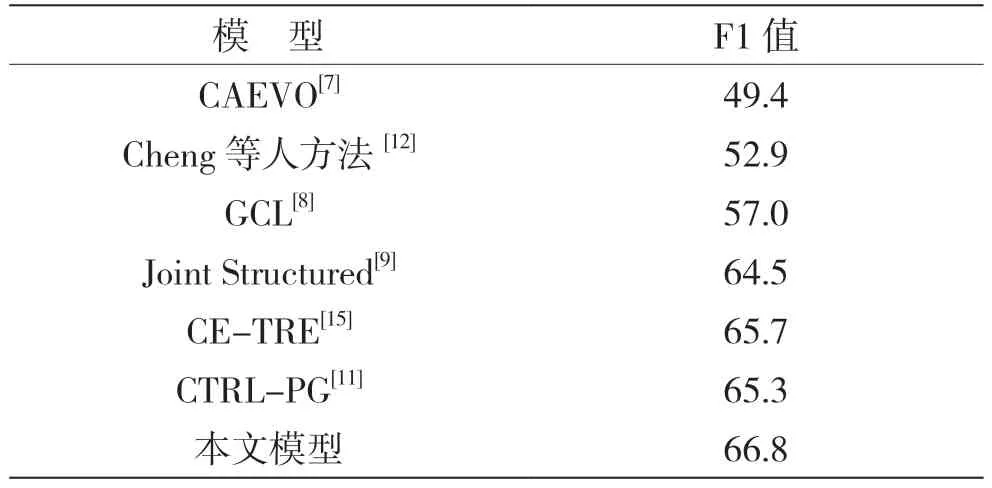
表4 不同模型在TB-Dense数据集上的实验
由表4可以看出,本文模型相较于CEAVO有着17.4%的提升,证明该任务中深度学习方法优于机器学习方法。与同样使用事件依存路径的Cheng等人方法相比,本文模型在F1值上提升了13.9%,这是因为Cheng等人方法丢弃了大量的事件上下文,而本文使用事件的最短依存路径辅助事件句文本的编码,帮助模型总结单词搭配对于时序关系的影响。本文方法与CTRL-PG都涉及外部知识辅助模型识别,CTRL-PG将领域知识转换为规则的形式,进而通过线性规划来优化识别效果。相较于固定的规则,本文将事件依存路径以文本形式加入,并通过门控计算事件特征,模型通过学习与总结事件句的依存关系,提高了文本理解能力与可解释性。与其余深度学习方法相比本文方法均具有优势,可以说明本文模型的有效性。
3.4.2 模型消融实验
为探究模型中各部分对于识别能力的影响,本文设置两个基线方法来进行消融实验,实验结果见表5。
(1)基线方法1:在本文模型中去除事件依存路径与特征门控,即在数据预处理时将事件依存路径视为空,将语义特征与句法特征拼接并视作最终的事件特征。
(2)基线方法2:在本文模型中去除门控机制,即在预处理阶段中使用事件依存路径作为外部知识,将语义特征与句法特征拼接并视作最终的事件特征。
由表5可以看出,从F1值上看,本文模型明显优于剩余方法。基准方法2相较于基准方法1,在总体F1值上提高了2.4%,其原因在于基准方法2使用了事件依存路径,增强了模型的句法分析能力。本文模型相较于基准方法2又有所提升,原因是门控机制能够参考事件句文本来动态调整事件特征,增强了模型的鲁棒性与识别能力。

表5 不同模型在TB-Dense数据集上的结果
3.4.3 探究句法信息对于模型的影响
为进一步探究加入事件路径信息对模型的影响,本实验将数据集细分为跨句事件对与同句事件对,研究在加入事件句特征前后,模型对两种事件对识别效果的变化,实验结果见表6。
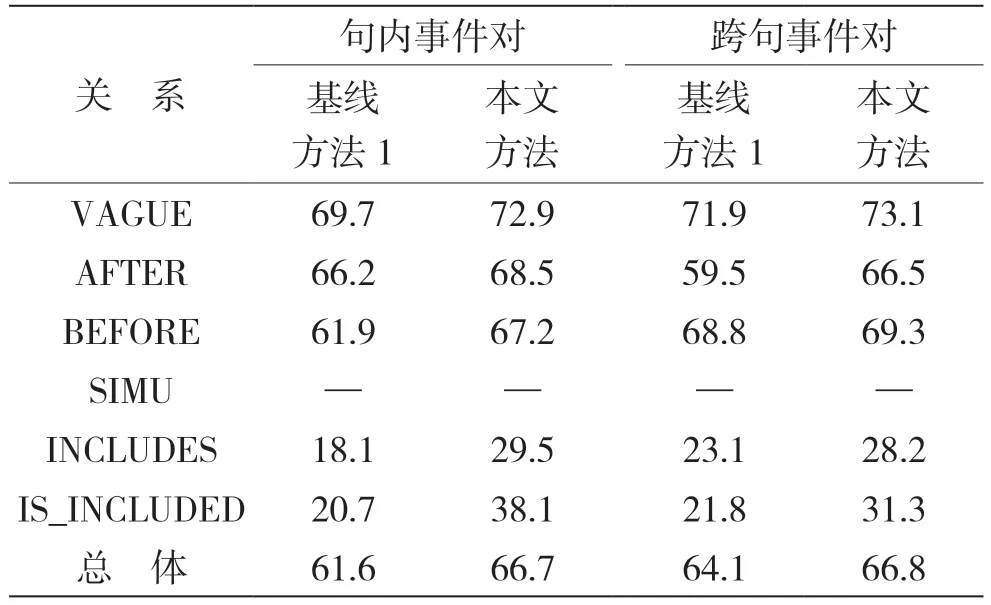
表6 TB-Dense数据集中句内与跨句事件对的F1值对比
从表6可看出,在句内事件对方面,本文方法相较基线方法1在总体F1值上提升了5.1%,在各类别上均有一定提升,跨句事件对中也有着2.7%的提升,这是因为事件最短依存路径后,模型能够通过依存句法建立事件间的联系。对比跨句事件对与句内事件对的提升效果,可以看出句内事件对的提升更加明显,分析原因是当两个事件触发词位于同一事件句时,依存句法容易建立事件对的联系,而不同事件句之间差异较大,通过句法建立联系相对困难,故跨句事件对的提升相对逊色。
3.4.4 实验样本分析
表7为TB-Dense数据集中的一个样例,在加入事件依存路径知识前,模型预测的结果是“Vague”,加入事件依存路径后,模型能够正确预测事件对的关系,两条事件依存路径分别是[has

表7 TB-Dense数据集的样例
4 结语
为在事件时序关系识别中将句法信息与文本信息结合,本文提出将事件依存路径作为外部知识融入到编码过程中。将事件依存路径视作一个连续表示序列,通过使用标志位的方法将外部知识嵌入到文本序列中,构建该序列帮助模型捕捉事件句中的句法信息;提取句向量以建立事件对间的联系,同时使用Bi-LSTM对事件句的语义进行编码;最后利用门控机制来对不同特征进行约束,丰富模型可提取的事件句文本特征。在TB-Dense数据集上的实验结果表明,该方法可以显著改善模型在事件时序关系识别模型上的性能。下一步研究拟在跨文档的时序关系任务中,尝试识别同一主题下不同文档中的事件时序关系。
