一种利用CNN-BiGRU和多头注意力的语音分离技术
2022-06-11王振中
王振中,高 勇
(四川大学,四川 成都 610065)
0 引言
语音分离一词最初源于Cherry在1953年提出的“鸡尾酒会问题”(Cocktail Party Problem),即在鸡尾酒会那样的声音环境中,听者也能毫不费力地在其他人的说话声和环境噪声的包围中听到一个人的说话内容,因此语音分离问题通常也被叫作“鸡尾酒会问题”,而语音分离的目的是将两个及以上的语音信号从它们的混合语音信号中分离出来。
目前的语音分离方法可分为单通道语音分离方法和阵列语音分离方法。本文着重研究单通道两个说话人的语音分离技术,单通道语音分离技术主要包括盲源分离技术(Blind Source Separation,BSS)、计算机听觉场景分析(Computational Auditory Scene Analysis,CASA)以及基于深度学习的语音分离技术。在这些算法中,将深度学习技术引入到语音分离中已成为当前主流模式,可大幅度提升语音分离的性能[1-4]。
文献[5]和文献[6]提出了深度聚类(Deep Clustering,DPCL)的方法,主要解决与说话人无关的语音分离问题。该方法把混叠语音中的每个时频单元结合其上下文信息映射到一个新的嵌入空间,并在这个嵌入空间上进行聚类,使得在这一空间中属于同一说话人的时频单元距离较小,因此可以聚类到一起。传统的DPCL算法在训练阶段通过将对数幅度谱特征输入到双向长短期记忆网络(Bidirectional Long Short-Term Memory,BLSTM)嵌入空间网络中,在分离阶段通过使用K-均值聚类算法来对混合语音信号进行分离。然而,如果直接将高维的幅度谱信息数据输入到神经网络进行训练,那么将会导致神经网络训练减慢,并造成数据冗余,但如果将高维的信息先输入到卷积神经网络(Convolutional Neural Network,CNN)中,可以从混合语音信号的幅度谱中提取特征并降低幅度谱 的维度。
本文提出了一种基于卷积神经网络级联双向门控循环网络(Convolutional Neural Network Cascades Bidirectional Gated Recurrent Network,CNNBiGRU)和多头自注意力机制的深度聚类语音分离算法。首先在训练阶段,使用CNN从混合语音信号的幅度谱中提取特征并降低幅度谱的维度;其次利用BiGRU来捕获语音信号中的时间特征以实现时间建模;再次通过多头自注意力机制,更好地利用上下文之间的信息,减少序列信息的丢失,强化幅度谱之间的依赖性,提高语音分离的性能,同时针对神经网络中的“失活”问题,本文提出了一种局部线性可控的激活函数,即改进的双曲正切函数(Etanh);最后在分离阶段,利用高斯混合聚类算法(Gaussian Mixture Model,GMM)对混合语音信号进行分离。在公开中文数据集中得到的实验结果表明,相比基线的深度聚类模型[5],该算法的分离效果在客观指标上均有明显提高,并且主观听感上清晰度和可懂度较好。
1 深度聚类模型
聚类是一种无监督的机器学习算法,可以有效地将实例分组到不同的簇[7]。传统的深度聚类模型[5]是假设时频单元(Time-Frequency,T-F)中存在合理的区域,可以定义为一个源在其中占主导地位的矩阵。而深度聚类的目的是估计每个时频单元的掩码,首先使用神经网络(BLSTM)将T-F表示为高维嵌入向量,其次通过附加的聚类过程(K-均值聚类)来估计二进制掩码。
在深度聚类中,输入信号的对数梅尔谱特征的特征向量表示为Xm=Xt,f,m∈{1,2,…,N},其中X表示由元素m所索引的特征向量,m通常是指音频信号时频指数(t,f)的总数,t代表信号帧的时间索引,f代表信号帧的频率索引,Xt,f表示一个时频单元。聚类的目的是在元素m中找到输入X的理想划分,以分离混合信号。Y={ym,c}代表混合信号的目标嵌入结果,元素m被映射到c个类别上,只有当第c个类别中包含元素m时,有ym,c=1,以此得到理想亲和矩阵A=YYT。其中当i和j属于同一个聚类时,Ai,j=1,其他情况时,Ai,j=0。
为了估计分区,使D维的嵌入空间B=fθ(X)∈RN×D,聚类由参数θ决定,以此将嵌入向量聚类形成更接近目标的分区{1,2,…,N}。在聚类中,B=fθ(X)是通过BiGRU网络和多头自注意机制训练得出的关于输入语音信号特征X的函数。深度聚类中将嵌入空间B作为一个N×N的矩阵来表示亲和矩阵=BBT。
对于每个输入X,让来匹配理想亲和矩阵并以此进行优化嵌入。从而可以通过最小化估计的亲和矩阵与理想亲和矩阵之间的距离得到训练时的损失函数:
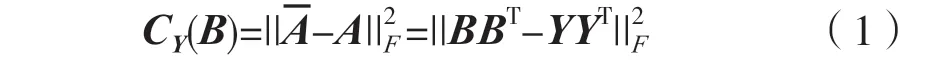
在分离阶段,首先从测试信号中提取T-F,计算最后一层的输出即嵌入向量矩阵;其次利用K-均值算法估计出理想的二值掩码,将估计出的理想二值掩码乘以混合语音信号的时频单元;最后用短时傅里叶逆变换和重叠相加的方法分离出原始的语音信号。
2 本文提出的改进算法
2.1 门控循环单元
门控循环单元(Gated Recurrent Unit,GRU)网络是LSTM网络的一种变体,它较LSTM网络的结构更加简单,计算量更小,而且效果也很好,同时它既具有LSTM能够保留长期序列信息的能力,又能够减少梯度消失的问题。GRU中只有两个门,即更新门和重置门,而BiGRU模型包含前向传播、后向传播两个GRU模型,相比GRU具有更高的分类和识别精度。综上考虑,本文采用双向GRU网络,该网络可从前、后两个方向全面捕捉语音语义特征,能够在一定程度上消除传统GRU中输入信息的顺序对最终状态的额外影响。
2.2 多头自注意力机制
目前,注意力机制模型在机器翻译、图像描述、文本摘要中被广泛应用。自注意力机制是注意力机制的变体,它可以减少对外部信息的依赖,更擅长捕捉序列数据或特征的内部相关性。在语音信号处理中,注意力机制可以赋予语音数据中的每个语音特征不同权重,能够更好地为重要信息分配权重,从而更加准确地理解语音序列的语义。本文中所使用的多头自注意力机制算法[8-10],通过利用多头自注意机制从多个子空间中获取全局序列信息,并挖掘语音中包含的内在特征,其结构如图1所示。

图1 多头自注意力机制结构
多头自注意力机制算法的计算过程:首先将输入转换为键值K、查询值Q和数值V这3个矩阵,平行注意力头数h用来处理矩阵的不同部分;其次计算缩放点乘注意力机制的注意力分值。具体的表达式为:

式中:查询矩阵Q∈Rn×d;键矩阵K∈Rn×d;数值矩阵V∈Rn×d;d为隐藏层节点的数量;n为输入长度。
在此基础上,多头自注意力机制的注意力得分计算过程如下:

式中:WO,,,都为参数矩阵;h为平行注意力层数或头数。注意这里要做h次,也就是所谓的多头,经过大量实验验证,最终得出本文中h为2时语音分离效果最佳。
2.3 激活函数的优化
神经网络的收敛速度、收敛效果往往两者不可兼得,为了改善神经网络的收敛速度和效果,现针对激活函数进行分析。ReLU激活函数收敛速度较快,但其负半轴导数恒为0,在语音分离任务中导致收敛效果不佳;tanh激活函数在语音分离任务中收敛效果较好,但其收敛速度较慢。因此借鉴tanh激活函数的泰勒级数思想,本文提出了Etanh激活函数。Etanh激活函数是考虑了tanh和ReLU激活函数各自的优点,得到局部线性可控的新激活函数,为了函数和导函数的连续性,局部线性可控函数选择使用tanh函数进行改进,新激活函数为:

式中:α,β,γ分别代表偏差补差因子。Etanh(x)通过调整参数α可以实现可控局部线性的范围,β可以控制函数近似不同斜率的线性函数和函数上限值,γ可以控制函数在负半轴的函数斜率和函数下限值,为了使Etanh(x)函数中的tanh(α·x)函数局部近似ReLU函数,当且仅当α·β=1情况下成立。图2中展示了不同的α值时Etanh(x)函数的曲线,横纵坐标分别代表x轴和y轴。从图2中可以看出不同的α值情况下线性范围的区域变换情况,在本文中α=0.1,β=10,γ=1.58时语音分离效果最佳,其中γ值的选取是让Etanh(x)函数的负半轴更近似于tanh函数的负半轴,而α和β值的选取是受语音分离后的语音质量所影响。

图2 不同的α值时Etanh(x)函数的曲线
2.4 本文提出的深度聚类网络结构
相比于基线的深度聚类语音分离算法[5],本文提出的基于CNN-BiGRU和多头自注意力机制的深度聚类语音分离方法的网络模型结构如图3所示。

图3 本文算法的语音分离结构
本文使用混合语音信号的对数梅尔谱作为输入特征。本文算法首先通过CNN挖掘语音信号中的局部空间结构信息,有效地提取语音的低维特性;其次利用BiGRU来捕获语音信号中的时间特征以实现时间建模;最后通过多头自注意力机制,更好地利用上下文之间的信息,捕获序列数据之间的内部相关性,强化幅度谱之间的依赖性,提高语音分离的性能。
3 实验与结果分析
3.1 实验设置与评价指标
关于语音分离的实验一般在开源的英文数据集上展开,数据集语种类型比较单一。为了验证本文语音分离系统针对不同语种的语音样本都有良好的分离效果,实验采用DiDiSpeech中文语音数据库[11]来进行验证。该数据集是由滴滴公司联合天津大学和杜克昆山大学在Interspeech会议上公开发布的开源语音数据库。该数据集包括500个说话人,每个说话人约有100条WAV格式的语音,每条语音持续时间为3~6 s,采样率48 kHz,在数据预处理时将其降采样到8 kHz。实验所使用的训练数据集是从DiDiSpeech数据集中随机挑选混合成的4 000条语音,验证集为400条语音,从中分别随机选出男性与男性说话人混合语音50条,男性与女性说话人混合语音50条,女性与女性说话人混合语音50条。说话人语音之间的信号干扰比为-2.5~2.5 dB。实验中所有的语音信号被降采样到8 kHz,然后进行帧长为256、帧移为64的短时傅里叶变换(Short-Time Fourier Transform,STFT),分析窗为Hanning窗,网络结构为3层CNN和4层BiGRU,隐藏层节点数为600,聚类向量深度为40,STFT输出的为混合语音信号的对数梅尔谱特征。
语音分离的目标是提高语音信号的语音质量或者提高语音信号的清晰度。为了评估本文提出的算法,主要采用信失比(Signal to Distortion Ratio,SDR)、信伪比(Signal to Artifact Ratio,SAR)、信干比(Signal to Interference Ratio,SIR)、语音质量感知评估(Perceptual Evaluation of Speech Quality,PESQ)和短时客观可懂度(Short-Time Objective Intelligibility,STOI)作为分离算法[12-14]评价指标。SDR反映分离算法的综合分离效果,SIR反映分离算法对干扰信号的抑制能力,SAR反映分离算法对引入的噪声的抑制能力,三者的数值越大,表示语音信号的分离效果越好。而PESQ和STOI两者得分值越高,表示语音质量越好。
3.2 激活函数的性能分析
为了验证Etanh对语音分离性能的影响,本文从语音分离系统中激活函数的耗时和语音分离性能两方面进行比较,其中PESQ和STOI是评估分离后语音质量的客观评价标准,两者得分值越高,表示语音质量越好。激活函数鲁棒性分析如表1 所示。

表1 3种激活函数的性能对比
由表1分析可知,改进后的Etanh相比于tanh和ReLU,PESQ、STOI得分都有明显提升,其中PESQ值分别提高了0.32,0.34,STOI值分别提高了0.14,0.15。表1中第3列给出的是3种激活函数在使用英伟达2080的GPU同时训练时,平均每次迭代所需时间。由表1可知,3种激活函数的耗时在同一级别,Etanh函数比tanh函数降低了0.21 s,比ReLU函数降低了0.12 s。实验结果验证了Etanh激活函数在一定程度上更有利于神经网络的学习,语音分离性能有一定提升。
3.3 实验结果分析
为了验证本文算法的优劣性,将基于置换不变训练(utterance-level Permutation Invariant Training,uPIT)的语音分离算法[15]和文献[5]提出的语音分离算法中的结果与本文的模型进行性能对比,结果如表2、图4和图5所示。其中,整体上得到的计算值是男性与男性、男性与女性、女性与女性共150条语音计算得到的平均值。

表2 不同算法的SDR、SAR、SIR平均值对比

图4 不同算法的STOI平均值

图5 不同算法的PESQ平均值
通过表2、图4、图5中的数据可以发现,本文算法与uPIT算法相比,男性和男性的SDR值提高了3.465 7,SAR值提高了0.757 9,SIR值提高了8.121;男性与女性的SDR值提高了4.312 5,SAR值提高了1.062 5,SIR值提高了8.206 3;女性与女性的SDR值提高了4.076 6,SAR值提高了0.019 2,SIR值提高了8.248;整体上SDR值提高了3.946 4,SAR值提高了0.647 3,SIR值提高了8.187 9。本文算法与文献[5]相比,男性与男性的SDR值提高了2.367 6,SAR值提高了1.454 5,SIR值提高了3.132 4;男性与女性的SDR值提高了0.983 1,SAR值提高了0.819 2,SIR值提高了1.280 9;女性与女性的SDR值提高了2.093 6,SAR值提高了1.493 8,SIR值提高了2.405;整体上SDR值提高了1.791 9,SAR值提高了1.223 2,SIR值提高了2.257 1。综上分析可知,本文算法的各项评价指标,SDR平均值、SAR平均值、SIR平均值、STOI平均值和PESQ平均值均优于uPIT算法和文献[5]算法。
3.4 语音信号时域波形分析
将获得的混合语音信号使用本文算法进行语音分离,并与文献[5]进行对比,图6为时域语音波形对比结果。如图6所示,可以观察到文献[5]算法和本文算法的时域语音波形对比结果,图中区别最明显的区域部分均使用椭圆标记出来。可以看出本文算法的分离效果优于文献[5]算法,并且分离后的语音主观听感上清晰度和可懂度较好,这表明本文算法在一定程度上可以更好地应用于工程实践环境中。


图6 文献[5]算法和本文算法分离的语音波形对比结果
4 结语
本文提出了一种基于CNN-BiGRU和多头自注意力机制的深度聚类语音分离算法。本文算法以对数梅尔谱作为输入特征,通过CNN-BiGRU网络结构来捕获混合语音信号的空间和时间特征,再通过多头自注意力机制,更好地利用上下文之间的信息,减少序列信息的丢失,最后通过高斯混合聚类算法对混合语音进行分离。实验结果表明,本文提出的语音分离算法模型具有参数少、速度快等优势,并且各项评价指标以及分离出的时域波形均明显优于基线的深度聚类算法,这证明了本文算法模型的合理性和有效性,可以更好地应用到工程实践环境中。
目前本文算法只考虑了两个说话人的语音分离情况,而在智能家居或者在其他工程应用环境中,实际情况下可能不止2个人在同时说话,所以在接下来的研究工作中,将会考虑到3个或3个以上说话人的语音分离情况,同时也将继续验证该激活函数在多数场景下的性能以及适应性,并进一步提升语音分离的性能。
