Python环境下利用Selenium与JavaScript逆向技术爬虫研究
2022-06-11时春波李卫东秦丹阳张海啸吴峥嵘
时春波 李卫东 秦丹阳 张海啸 吴峥嵘


摘 要:针对使用调试检测、数据加密等技术的网站,解析工具Beautiful Soup难以对网页进行解析爬取数据。本研究基于Python环境,结合JavaScript逆向技术、Beautiful Soup网页解析等网络爬虫技术,利用中间人攻击工具Mitmproxy(man-in-the-middle attack proxy)在本地指定设备端口开启本地代理,拦截并修改网页响应。同时,运用Web自动化工具Selenium来启动浏览器,设置使用代理服务器,连接到本地Mitmproxy代理,访问被修改的响应网页进行网页调试和解析,并对加密数据进行还原,解决网络爬虫中调试检测和数据加密难题,从而爬取数据。
關键词:网络爬虫;JavaScript逆向技术;网络代理;Selenium
中图分类号:TP393.092 文献标志码:A 文章编号:1003-5168(2022)10-0020-04
DOI:10.19968/j.cnki.hnkj.1003-5168.2022.10.004
Research on Crawler Using Selenium and JavaScript Reverse
Technology in Python Environment
SHI Chunbo LI Weidong QIN Danyang ZHANG Haixiao WU Zhengrong
(College of Information Science and Engineering, Henan University of Technology, Zhengzhou 450001, China)
Abstract:For websites that use debugging detection, data encryption and other technologies,the parsing tool beautiful soup is difficult to parse web pages and crawl data Based on the python environment, combined with JavaScript reverse technology,beautiful soup web page parsing and other web crawler technologies,this study uses the man in the middle attack proxy (mitmproxy) to open the local proxy at the local designated device port,intercept and modify the web page response,and uses the web automation tool selenium to start the browser,set up the proxy server and connect to the local mitmproxy proxy.Visit the modified middle note to debug and analyze the web page,restore the encrypted data,solve the problem of debugging and data encryption in web crawler,and then crawl data.
Keywords:web crawler; JavaScript reverse technology;network agent;Selenium
0 引言
随着网络技术的迅速发展,万维网成为大量信息的载体,如何有效提取并利用这些海量信息成为一个巨大挑战。爬虫技术就是在这样背景下诞生的,其不仅在搜索引擎领域得到广泛应用,在大数据分析、商业等领域也得到了大规模应用。随着网络反爬虫技术[1]的发展,爬取数据也越来越困难。本研究针对网络爬虫中调试检测和数据加密等反爬虫技术,使用Python爬虫技术,结合Selenium和JavaScript逆向技术,加入Mitmproxy进行网页响应拦截和修改,解决网络爬虫中调试检测和数据加密难题,从而爬取数据。
1 相关网络爬虫技术
1.1 Python爬虫技术
网络爬虫[2]又称网络蜘蛛、网络机器人,是一种按照一定规则自动浏览、检索网页信息的程序或脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取出来。通过对抓取到的数据进行处理,从而提取出有价值的信息。
网络爬虫可分为三大类,分别是通用网络爬虫、聚焦网络爬虫和增量式网络爬虫。通用网络爬虫是搜索引擎的重要组成部分,须遵守Robots协议。在应用过程中,通用网络爬虫一般会从初始UR开始,获取初始页面的代码,同时会从代码提取所需的URL,并将其放入列表中,直到其满足停止条件;增量式网络爬虫是指对已下载网页采取增量式更新方式,只爬取新产生或发生变化的网页,能够在一定程度上保证所爬取数据的时效性;聚焦网络爬虫是面向特定需求的一种网络爬虫程序,与通用网络爬虫技术相比,其在网页抓取时会对网页内容进行筛选和处理,尽量保证仅抓取需要的相关信息。但在应用过程中,其程序的编写更加复杂。聚焦网络爬虫极大地节省了硬件和网络资源,能够在海量数据中快速抓取有效数据,并从有效数据中获取用户需要的信息,且能够筛选和处理与主题无关的信息。由于保存的页面数量少且更新速度快,其能够更好地满足特定人群对特定领域信息的需求。
Python是一种面向对象、解释型、弱类型的脚本语言,也是一种功能强大且完善的通用型语言。相比于其他编程语言(如Java、C、C++等),Python的代码非常简单,提供了许多网络爬虫模块和库。这些类库包括文件I/O、GUI、网络编程、数据库访问、文本操作等绝大部分应用场景,具有很好的扩展性。随着大数据、人工智能技术的流行,Python的应用领域将更加广泛。
1.2 Mitmproxy代理工具
Mitmproxy是一组工具,可为HTTP/1、HTTP/2和WebSocket提供交互式的、具有SSL/TLS功能的拦截代理。其功能包括:能够完成拦截并动态修改HTTP、HTTPS的请求和响应;保存完整的HTTP对话,并进行转发和分析;转发HTTP会话客户端;转发以前录制的服务器的HTTP响应;反向代理模式将流量转发到指定服务器;使用Python对HTTP流量进行脚本化更改等功能。
1.3 Selenium测试框架
Selenium[3]是一个开源的、可移植的Web测试框架,支持多种操作系统、浏览器和编程语言,还支持并行测试执行,在减少时间的同时提高了测试效率。Selenium Web驱动程序不需要安装服务器,通过测试脚本直接与浏览器进行交互。网络爬虫中使用Selenium驱动程序是为了解决Requests无法执行JavaScript代码的问题[4]。通过驱动浏览器自动执行自定义脚本,模拟人工使用浏览器的操作[5],如跳转、输入、点击、下拉等,进而获取网页渲染后的结果。
1.4 JavaScript逆向技术
当获取网页的HTML代码后,部分网站运用调试检测和数据加密等反爬虫技术,这些技术会阻碍下一步的网页解析和运用,此时需要运用JavaScript逆向技术[6]来解析JavaScript代码,解决网络数据抓取时所遇到的调试检测和数据加密等问题。
2 相关网络反爬虫技术
在相关网络爬虫技术发展的同时,反爬虫技术[7]也在不断发展,目前反爬虫技术主要使用以下基本策略。
2.1 User-Agent控制请求
User-Agent中可以携带用户设备信息,包括浏览器、操作系统、CPU等信息。通过在服务器中设置user-agent白名单,确保只有符合条件的user-agent才能访问服务器。而网络爬虫技术可以通过伪造头部信息来访问服务器。
2.2 IP限制
通过设置服务器访问阈值,将短时间内访问量超过阈值的IP地址加入黑名单中,禁止其访问服务器,从而达到反爬虫的目的。网络爬虫能够利用IP代理来更换IP,从而能够继续访问服务器。
2.3 Session访问限制
Session是用户请求服务器的凭证,在服务器端根据短时间内的访问量来判断是否为网络爬虫,将疑似网络爬虫的Session禁用。通过网络爬虫技术可以注册多个账号,使用多个Session轮流对服务器进行访问,避免Session被禁用。
2.4 验证码
在用户登录或访问某些重要信息时,可以使用图片验证码、短信验证码、数值计算验证码、滑动验证码、图案标记验证码等检测用户的状态。该方法能够有效阻挡网络爬虫,区分程序和正常用户,使正常用户可以正常访问服务器,而网络爬虫因无法识别验证码,使其不能访问服务器。
2.5 动态加载数据
通过JavaScript技术动态加载数据,网络爬虫在静态页面中无法获得数据。网络爬虫技术能够通过抓包的形式获取URL,模拟请求。
2.6 数据加密
在前端请求服务器前,将相关参数进行加密,使用加密后的参数请求服务器,在服务器端进行相关解码操作,而网络爬虫无法进行模拟请求服务器。由于加密算法是写在JavaScript代码中,网络爬虫能够找到并破解。
3 Python环境下Selenium与JavaScript逆向爬虫技术的应用
使用Mitmproxy开启本地代理,进行网页响应拦截。首先,创建addons.py文件。使用mitmweb-s addons.py命令启动Mitmproxy并加载自定义脚本addons.py,修改网页响应,绕过网站检测(见图1)。定义脚本文件代码如下所示。
def response(slef,flow:mitmproxy.http.HTTPFlo-w):
if 'www.aqistudy.cn' in flow.request.url:
flow.response.text=flow.response.text.replace("window.navigator.webdriver", "false")
flow.response.text=flow.response.text.replace("debugger","")
其次,設置Firefox浏览器驱动器的环境:Firefox_options=webdriver.FirefoxOptions()。设置浏览器Firefoxd代理方式为使用本地代理,其代码如下所示。
proxy_ip=“本地ip”
# 设置浏览器代理端口
ff_profile.set_preference("network.proxy.type",1)
ff_profile.set_preference("network.proxy.http",p-roxy_ip)
ff_profile.set_preference("network.proxy.http_p-ort",int(8080))
ff_profile.set_preference("network.proxy.ssl",p-roxy_ip)
ff_profile.set_preference("network.proxy.ssl_po-rt",int(8080))
ff_profile.set_preference("network.proxy.ftp",pr-oxy_ip)
ff_profile.set_preference("network.proxy.ftp_p-ort",int(8080))
最后,创建Firefox浏览器驱动器启动Firefox[8](见图2)。相关代码如下所示。
browser=webdriver.Firefox(options=ff_profile)
4 以某环境质量监测网站进行技术方法测试
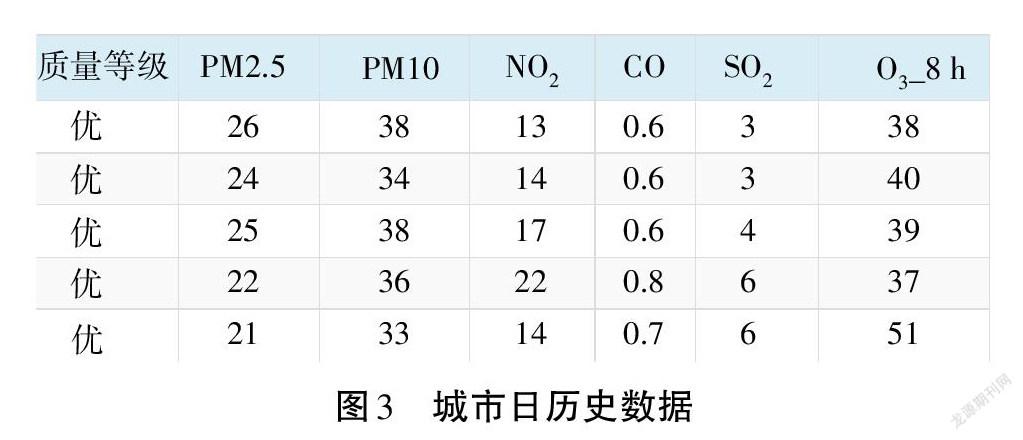
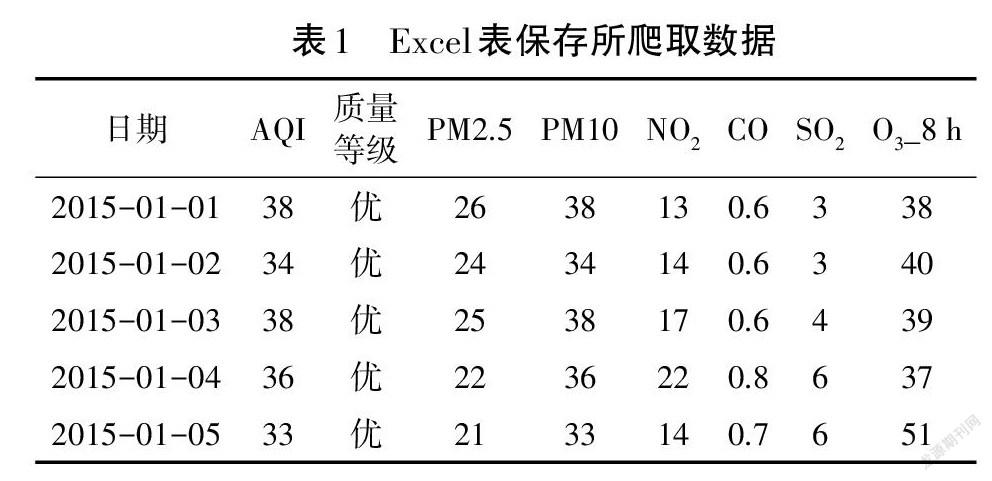
针对某环境质量监测网站,首先使用逆向爬虫技术解决该网站爬虫调试中检测和数据加密难题,然后使用网站解析工具BeautifulSoup对网页结构和属性等进行网页解析[9]。图3为该网站空气质量历史数据,根据其详细信息页面的<table>标签,通过select()获取<table>整个标签内容,调用函数Workbook()抽取所需要数据保存至Excel表[10-11](见表1)。
5 结语
本研究以某空气质量监测反爬虫分析平台为例,基于Python环境,利用Selenium、JavaScript逆向爬取数据技术,与中间人攻击工具Mitmproxy开启本地代理相结合,解决了网页无法进行调试的问题,从而突破网站的反爬虫技术爬取到相关空气质量监测数据。该方法能够有针对性地分析并找到目标网站反爬虫技术漏洞进行数据爬取,从而保证网络爬虫数据抓取的顺利进行。
参考文献:
[1] 周毅,宁亮,王鸥,等.基于Python的网络爬虫和反爬虫技术研究[J].现代信息科技,2021(21):149-151.
[2] 张俊威,肖潇.基于Python爬虫技术的网页数据抓取与分析研究[J].信息系统工程,2021(2):155-156.
[3] 忽爱平,范伊红,李阳,等.基于Selenium的网络爬虫的设计与实现[J].无线互联科技,2021(17):39-40.
[4] 李晨昊.基于BeautifulSoup+requests和selenium爬虫网页自动化处理的实现和性能对比[J].现代信息科技,2021(16):10-12,18.
[5] 许景贤,林锦程,程雨萌.Selenium框架的反爬虫程序设计与实现[J].福建电脑,2021(1):26-29.
[6] 王朝阳,范伊红,李梦丹,等.Python环境下的JavaScript逆向技术分析[J].无線互联科技,2021(17):97-98.
[7] 张宝刚.基于Python的网络爬虫与反爬虫技术的研究[J].电子世界,2021(4):86-87.
[8] 沈熠辉.以Selenium为核心的亚马逊爬虫与可视化[J].福建电脑,2021(12):43-46.
[9] 樊涛,赵征,刘敏娟.基于Selenium的网络爬虫分析与实现[J].电脑编程技巧与维护,2019(9):155-156,170.
[10] 李晓宇,徐勇,汪倩,等.基于Selenium的淘宝商品评论爬虫算法[J].信息与电脑(理论版),2020(12):62-64.
[11] 龙学磊,田萌,徐英,等.网络爬虫在科技文献检索中的应用[J].现代信息科技,2021(24):150-152.
