基于3D-MobileNetv2的多目标实时跟踪框架
2022-06-10毛仁祥常建华张树益李红旭张露瑶
毛仁祥,常建华,2*,张树益李红旭,张露瑶
(1南京信息工程大学江苏省大气环境与装备技术协同创新中心,江苏 南京 210044;2南京信息工程大学江苏省气象探测与信息处理重点实验室,江苏 南京 210044)
0 引言
目标跟踪[1-3]是计算机视觉领域的重要研究内容,在视频监控、虚拟现实、人机交互、图像理解、无人驾驶等应用层面具有很大的发展潜力。70年代,随着卡尔曼滤波[4]成功应用于目标跟踪领域,目标跟踪技术引起人们的广泛关注,扩展卡尔曼滤波[5]、粒子滤波[6,7]、多模型算法等滤波方法相继出现。近年来,单目标检测与跟踪技术趋于成熟,目标检测技术与目标跟踪技术的研究热点逐渐从单目标发展为多目标。当前多目标跟踪的主要工作是在视频的第一帧设定目标矩形框,并紧跟目标物体。
由于在目标检测方面[8-16]取得了很大进展,多目标跟踪技术也发展迅速。Yu等[17]将在线多目标跟踪问题转化为马尔科夫决策中的决策问题,利用马尔科夫决策模型(MDP)跟踪目标。Wang等[18]提出了端到端的框架(LP-SSVM),通过适当的参数学习,可以获得比使用复杂运动特征方法更高的精度。Frossard等[19]提出了一种既能利用激光雷达又能利用摄像机数据的方法。Simon等[20]扩展了YOLOv2网络结构,通过在回归网络中添加一个虚分数和一个实分数来估计物体的姿态。Weng等[21]设计了一个简单的在线实时跟踪系统,其速度与有效性都非常高。但在多目标跟踪过程中,目标通常存在相互遮挡的现象,并且跟踪目标在特征上的相似性以及目标群体空间拓扑的变化成为多目标跟踪技术应用的主要挑战。此外,跟踪场景的复杂性和多样性也是制约多目标跟踪技术发展的因素。
本文将传统的状态预测与深度学习相结合,使用神经网络预测目标物体在三维空间里的状态,使用匈牙利算法逐帧进行数据关联,设计轨迹管理模块管理相应的轨迹,实现多目标跟踪。相较于传统的实时跟踪框架,不需要在图像空间中执行卡尔曼滤波。传统的实时跟踪框架可以在高帧速率下获得较好的性能,但其返回的身份切换次数相对较多,这是由于其使用的关联度量只有在估计状态不确定度比较低时才相对准确,因此在跟踪遮挡物体时存在缺陷。本文使用深度神经网络代替卡尔曼滤波,通过神经网络的集成式学习实现对遮挡物体的状态预测。
1 基于深度学习的目标跟踪
所提出框架共有3D目标检测、3D卷积神经网络预测、数据关联、状态更新以及轨迹管理五个模块,其工作流程如图1所示,使用PointRCNN进行目标检测,利用3D-MobileNet V2对目标进行预测,由匈牙利算法进行数据关联,同时设计了状态更新模块以及轨迹管理模块。状态更新模块对匹配好的目标轨迹进行状态更新,轨迹管理模块管理相应的轨迹。
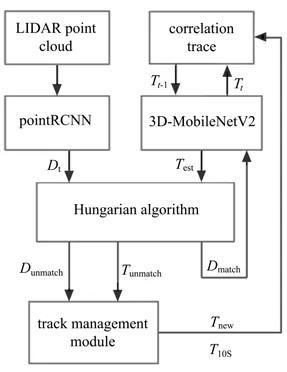
图1 目标跟踪框架流程图Fig.1 Flow chart of target tracking framework
1.1 3D标检测模块
3D目标检测模块是实时目标跟踪中不可缺失的组成部分,在测试中发现3D目标检测的效果对跟踪结果会产生较大影响,检测到的3D边界框在整个跟踪过程中发挥着重要作用。以往目标检测的主要工作是将3D雷达点云划分为等间隔的3D体素,并运用3D卷积进行3D边界框的检测,为了提高检测效率,将点云转换为鸟瞰图,并进行2D卷积。此处使用KITTI数据集上最先进的检测器PointRCNN,并直接使用其预训练模型,最终输出连续视频中每一帧的目标边界框。每个目标边界框共有8个参数,包括被检测物体的3D坐标中心(x,y,z)、长宽高(l,w,h)、航向角θ以及置信度c。
1.2 3D卷积神经网络预测模块
传统的3D实时跟踪采用卡尔曼滤波进行状态预测,卡尔曼滤波是以最小均方误差为最佳估计准则的递推估计算法,其基本思想是采用信号与噪声的状态空间模型,利用前一时刻的估计值和现时刻的观测值更新状态变量的估计,得到当前时刻的估计值。由于卡尔曼滤波比较简单,且实时性很高,因此大部分跟踪框架采用此方法进行预测,但是当被跟踪的物体长时间被遮挡时会出现跟踪丢失的情况。为了克服以上不足,此处使用3D卷积神经网络来代替卡尔曼滤波进行状态预测,用一个8维向量T=(x,y,z,l,w,h,c,θ)来表示物体的轨迹。为保持3D跟踪的实时性,选用一个轻量化的网络MobilenetV2[22],对其进行3D转换,相较于传统的MobilenetV2网络,其使用3D卷积,使网络可以提取连续帧之间的运动信息,进而实现状态预测,其整体结构见表1。
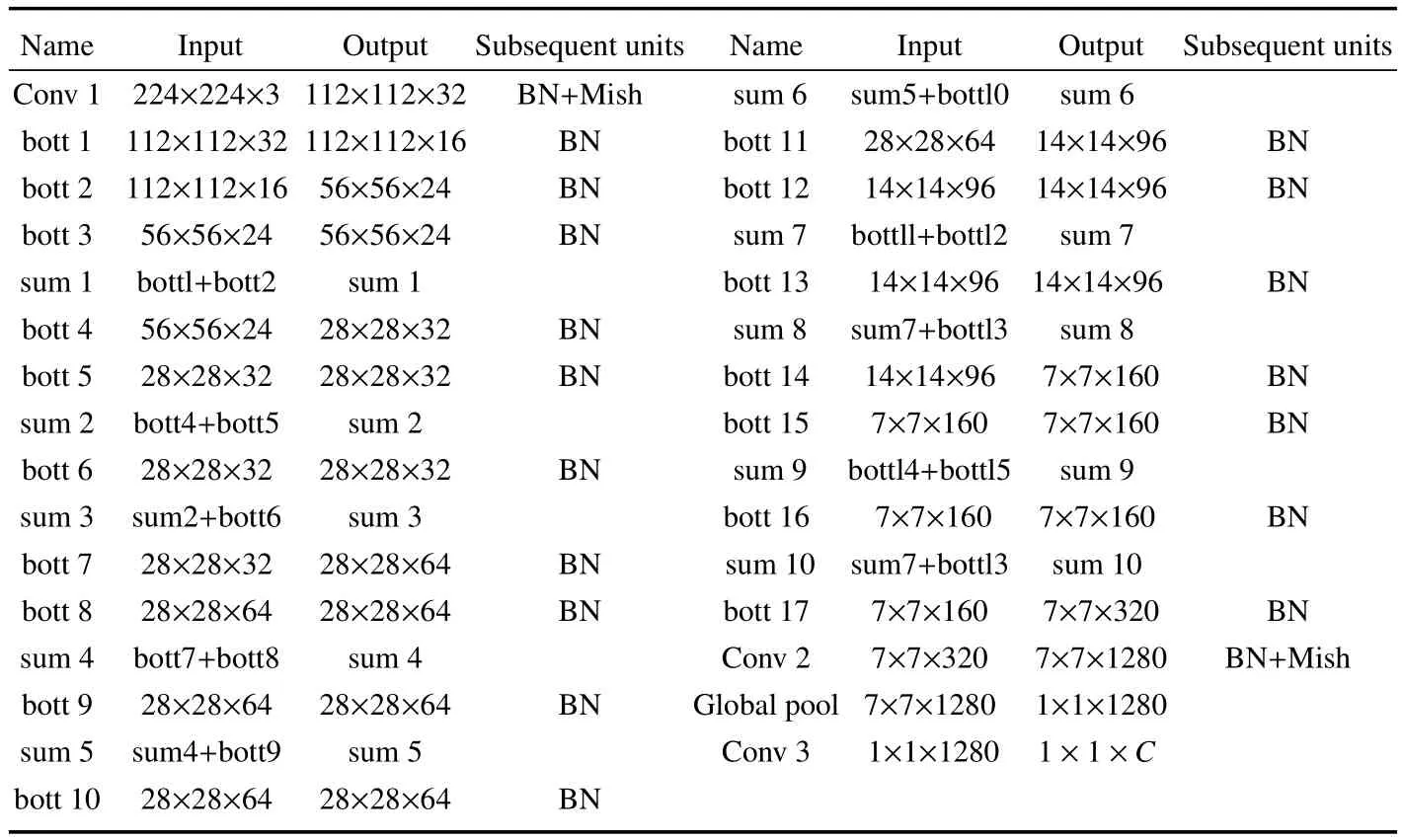
表1 3D-MobileNet V2结构表Table 1 Structure of 3D-Mobilenet V2
表2为3D-MobileNet V2的Bottleneck卷积层,在原网络基础上对每一个Bottleneck的中间卷积层加入了通道混洗来提升网络预测的准确性,每个Bottleneck共三层,在其输出后续单元加入了BatchNorm以及Mish激活函数,提升预测效率。实验测试表明通道混洗分成16组的准确性最高。此处使用均方差损失来训练网络,选取Test前面4帧的物体轨迹信息作为网络的输入,网络直接预测Test时刻的x、y、z、l、w、h、c、θ,由此得到物体当前时刻的状态估计。
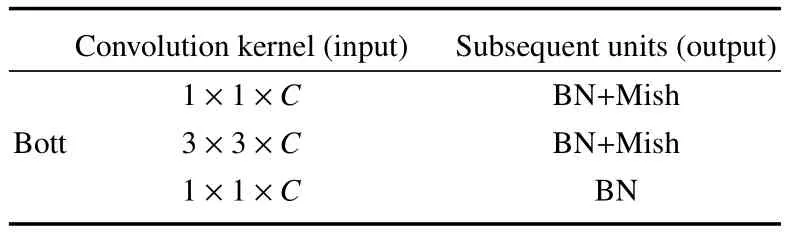
表2 Bottleneck结构表Table 2 Bottleneck structure table
1.3 数据关联模块
获取PointRCNN检测到的边界框Dti与3DMobilenet V2预测的物体轨迹Testj后,通过匈牙利算法将Dti和Testj中的物体进行交并比(IOU)匹配。选取2D IOU,使用CPython的计算过程进行加速匹配,将物体的运动轨迹对应到正确的运动轨迹上,确保后续操作的准确性。
关联算法的核心是用IOU计算边界框之间的距离,使用匈牙利算法选择出最优的关联结果,匈牙利算法利用增广路的性质,由于增广路中的匹配边总比未匹配边多一条,所以如果放弃一条增广路中的匹配边,选取未匹配边作为匹配边,则匹配的数量就会增加。匈牙利算法就是在不断寻找增广路,若找不到增广路,则说明达到了最大匹配。如图2所示:褐色的边界框代表物体在Ti帧被检测到的情况,红色和绿色代表被预测到的边界框,在预测的基础上使用匈牙利算法将预测的边界框与检测的边界框进行匹配,选择合适的物体检测边界框作为下一时刻物体跟踪的边界框,若每个预测到的边界框能够找到匹配的物体检测边界框,则跟踪成功;否则说明该物体已经离开了当前画面。如果检测的边界框找不到对应的预测边界框,则说明该物体首次出现在当前画面。在测试时,将IOU最小值设为0.1时,MOTA指标最高。因此,将IOU最小值设为0.1,IOU小于0.1将无法匹配。

图2 关联实例Fig.2 Example of association
在关联度量中,马氏距离用于计算物体检测的边界框dj和物体预测的边界框yi之间的距离。马氏距离的计算公式可表示为

式中Si为协方差矩阵,使用

来确定二者是否关联,当两者之间的距离小于等于特定阈值t,则表示二者关联,但是马氏距离依然不能很好地解决物体被长时间遮挡后关联不正确导致ID Switch的问题。
使用余弦度量距离将物体检测边界框dj通过表3 CNN网络计算对应的128维feature向量rj,余弦度量距离的计算公式可表示为

利用(3)式计算第i个被跟踪物体的所有Feature向量和第j个检测物体之间的最小距离,当两者之间的距离满足(2)式条件时表示这二者关联。
亚急性甲状腺炎是一种常见于的内分泌腺病变,直接原因为病毒感染,其发病率和人们的生活方式和环境密切相关,主要是由综合因素引起的炎症反应,常见的因素包括环境因素、内分泌因素、消化系统因素和精神因素等。临床发生亚急性甲状腺炎的原因通常为内外相互作用的结果,所以亚急性甲状腺炎的发病机制较为复杂[1]。亚急性甲状腺在诊断上存在一定的难度,为了提高诊断的准确率,减少对亚急性甲状腺炎诊断的漏诊和误诊率,必须提高诊断的准确率。临床研究发现[1],本文将选取我院2016年5月—2017年5月收治的60例亚急性甲状腺炎诊断患者的临床资料进行回顾性分析,现报告如下。
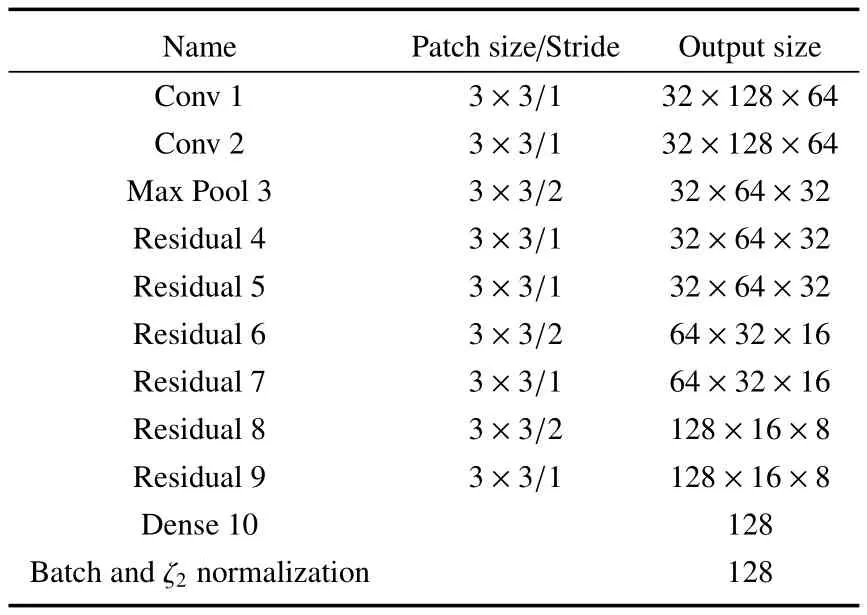
表3 CNN结构Table 3 CNN structure
1.4 状态更新模块
状态更新模块将匹配好的目标轨迹进行状态更新(Tmatch和Dmatch),更新后的值是根据Tmatch和Dmatch的不确定性加权平均确定的,其中不确定性为目标检测中的置信度与估计值之间的协方差。
1.5 轨迹管理模块
在跟踪过程中被跟踪的物体可能不再出现,并且会出现新增被跟踪的物体。所以添加轨迹管理模块以更新目标跟踪中消失和新增的轨迹。用Dunmatch代表新增加的物体,即在目标检测中无法与当前轨迹匹配的物体。为避免出现误检的情况,将只有连续存在4帧的物体定义为新增物体,其轨迹的初始状态设定为当前帧物体检测状态。此外,用Tunmatch代表离开检测范围的轨迹。为避免漏检的情况,需要持续跟踪Tunmatch轨迹4帧,如果超过4帧仍没有匹配的目标出现,则删除这个轨迹。
2 实验数据集与指标
整个模型的训练及测试都是在KITTI MOT基准上进行的,KITTI包含市区、乡村和高速公路等场景采集的真实图像数据。每张图像中最多包括15辆车和30个行人,存在各种程度的遮挡与截断。整个数据集由389对立体图像和光流图、39.2 km视觉测距序列以及超过20万张3D标注物体的图像组成。基准由21个训练视频和29个测试视频序列组成,每个序列都提供了激光雷达点云、RGB图像以及校准文件,帧数为8008与11095,分别用于训练和测试。KITTI数据集不向用户提供任何测试分割的注释,而是直接将注释保留在服务器上进行MOT的评估。在训练分割中,标注的对象和轨迹的数量分别为30601和636,分别包含汽车、行人。由于KITTI数据集没有正式的训练分割,仅使用序列1、6、8、10、12、13、14、15、16、18、19进行验证。此外,车辆在所有对象类型中实例数量最多,因此只对车辆子集求值。
选择MOT指标,用MOTA、MOTP、ML、MT来评估模型的性能。在众多ID评估指标中选择IDS作为评估标准,评估指标所代表的物理意义如下:
1)多目标跟踪准确度(MOTA):是衡量单摄像头多目标跟踪准确度的一个指标,可表示为

式中:FP表示预测为正样本,预测错误,即实际负样本,FN同理。IDS为ID转变数,是指跟踪轨迹中行人ID瞬间转换的次数,ngt指的是所有帧中ground truth对象的总数量。
2)多目标跟踪精确度(MOTP):是衡量单摄像头多目标跟踪位置误差的一个指标,可表示为

式中:ct表示第t帧物体的匹配个数,dti表示第t帧下目标与其配对位置之间的距离。
4)多数丢失数(MT):指丢失部分大于80%的跟踪轨迹数,数值越小越好。
5)ID转变数(IDS):指跟踪轨迹中行人ID瞬间转换的次数,通常能反应跟踪稳定性,数值越小越好。
3 实验结果与分析
为充分验证系统的性能,补充了受试者工作特征曲线(ROC曲线),如图3所示。ROC曲线越陡代表性能越高,其理想值为1,即AUC面积为一个正方形。一般AUC的值介于0.5~1之间,此处AUC面积为0.79,说明所提出模型能够良好地预测跟踪目标。
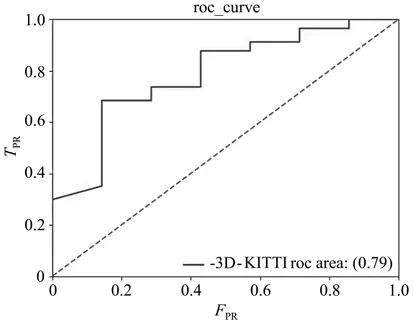
图3 目标跟踪框架ROC曲线图Fig.3 ROC curve of target tracking frame
图3所示曲线的横坐标为FPR,即假正率,可表示为

纵坐标为TPR,即真正率,可表示为

式中:F代表错误,T代表正确,P代表正样本,N代表负样本。与此对应,FP表示预测为正样本,预测错误,即实际负样本,TP、FN以及TN同理。
TPR和FPR分别在实际的正样本和负样本中观察相关概率问题,因此,无论样本是否平衡,对指标都无影响。例如,总样本中,90%是正样本,10%是负样本,准确率会存在误差。但TPR与FPR不同,TPR只关注正样本中有多少是被真正覆盖的,与其余10%负样本毫无关系。同理,FPR只关注负样本中有多少是被错误覆盖的,也与其余90%正样本毫无关系,因此可以避免样本不平衡的问题,这也是选用TPR和FPR作为AUC指标的原因。
图4为FPS与MOTA指标图,其横坐标代表模型运行的速率(FPS),纵坐标是MOTA指标,图中共展示了10种不同的目标跟踪框架。由图4可知,与DSM、MDP、FANTrack等框架相比,所提出框架无论是在速度上还是准确率上都有明显优势;与Beyondpixels、JCSTD以及Complexer-YOLO框架相比,所提出框架能较好地平衡速度与准确度,有着均衡的性能,虽然Beyondpixels框架的跟踪准确率达到了84%,然而其速度还不足5FPS,与之类似的是Complexer-YOLO框架,虽然其速度达到了100PFS,然而其跟踪准确率不足76%。所提出框架的准确率为79.22%,PFS为39,在保证跟踪精度的同时速度也较快。
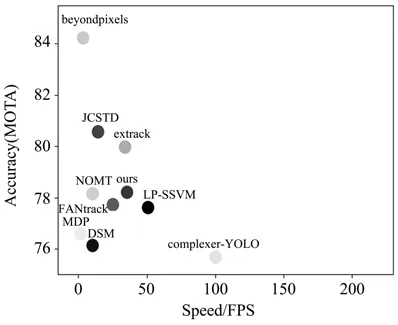
图4 FPS与MOTA指标图Fig.4 FPS and Mota index chart
将传统的状态预测与深度学习进行结合,使用神经网络预测目标物体在三维空间里的状态,通过神经网络的集成式学习达到对遮挡物体的状态预测,跟踪效果如图5所示。可以看出图中ID为1的近距离目标在跟踪过程中被准确跟踪,对于图中ID为3的较远距离目标,所提出框架也能准确跟踪,对于ID分别为2、4时跟踪过程中静止不动的目标,其ID并没有发生跳变,并且没有丢失目标,跟踪依旧准确。所提出框架可以准确跟踪目标,对静止目标不会发生跳变以及跟踪丢失的状况,并且在跟踪较远距离目标时也有良好表现。
使用KITTI MOT评估方法对KITTI数据集进行算法性能比较,如表4所示,所提出框架分别与MDP、LP-SSVM、DSM以及Complexer-YOLO框架进行了对比,可见所提出框架准确率最高,并且速度也较快,可以较好地平衡速度与准确度,具有稳定的性能。与卡尔曼预测框架相比,所提出框架在准确度、精度以及稳定性上都有较大提升。所提出框架IDS仅为16,说明其抗遮挡性良好,对遮挡比较久的物体不会造成跟踪丢失,且在对远距离物体的跟踪上也有优异的表现。

图5 KITTI数据集上跟踪效果展示图。(a)Frame 12;(b)Frame 22Fig.5 Display of tracking effect on KITTI data set.(a)Frame 12;(b)Frame 22
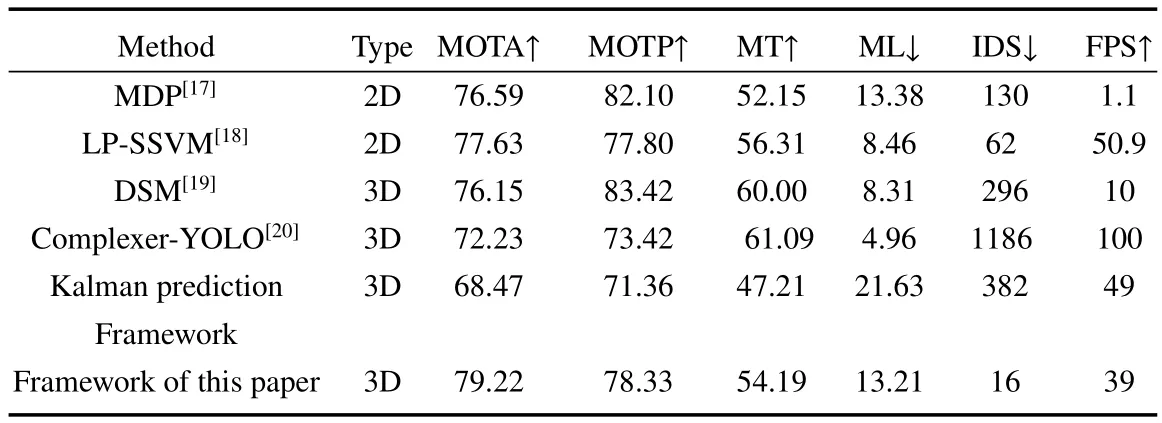
表4 使用KITTI MOT评估方法对KITTI数据集进行算法性能比较Table 4 Algorithm performance comparison of KITTI dataset using KITTI mot evaluation method
测试了不同IOU阈值对MOTA指标的影响,结果如图6,可见随着IOU阈值的增加MOTA指标在不断地减小,当IOU阈值选取为0.1时,其MOTA最高,故IOU阈值选取为0.1。
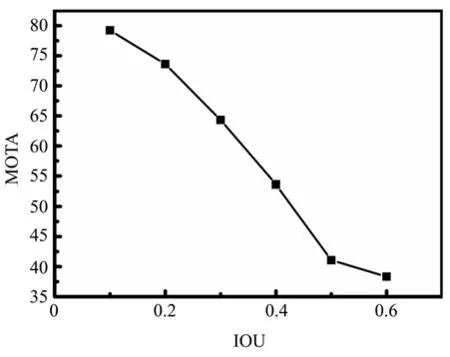
图6 IOU-MOTA测试图Fig.6 Test chart of IOU-MOTA
4 结论
设计了一个多目标实时跟踪框架,结合传统的状态预测与深度学习,利用神经网络预测目标在三维空间里的状态,并使用匈牙利算法逐帧进行数据关联,设计轨迹管理模块管理相应的轨迹,实现多目标跟踪。相较于传统的实时跟踪框架,所提出框架不需要在图像空间中执行卡尔曼滤波,用深度神经网络替代传统的卡尔曼滤波,通过神经网络的集成式学习达到对遮挡物体的状态预测,克服了传统的实时框架在遮挡物体跟踪上的缺陷。所提出框架不仅平衡了速度与准确度,具有稳定的性能,并且对于遮挡较久的物体以及远距离物体也有良好的跟踪性能。
