基于机器学习的线上实验课程资源挖掘
2022-06-10张思松
张思松
(铜陵学院实验教学管理处,安徽 铜陵 244061)
近年来,各学科的在线课程平台如雨后春笋般涌现在人们眼前,其中也包括实验课程[1].在广阔而开放的平台上,大量的课程资源、不受时域限制的学习方式受到广大用户的喜爱和追捧[2].在线课程平台在为广大用户提供众多实验课程资源,以及知识共享的学习环境的前提下,可挖掘用户的学习行为、学习体验和用户的学习偏好等信息.对用户学习信息的有效挖掘,并充分分析用户行为,对于实验课程设计和教学形式的调整具有指导意义[3-5],同时可对用户的学习效果进行评估并提出学习意见,使用户在实验课程的学习过程中获得最佳学习感受,通过课程学习改进原有学习方式,使学习更高效.
想要从在线平台海量实验课程资源中筛选出需要的实验课程,对于用户而言较为困难,普遍采用的选择方法是根据他人的选课经验及课程评价对课程进行筛选,结果却未必令人满意.如何从海量资源中寻找出有用信息,已成为数据挖掘领域的研究重点.
通过数据挖掘方法实现数据中有用信息的获取,已被应用于各个领域.郭鹏等[6]以提高教学质量为目的,提出了基于聚类和关联方法的学生成绩挖掘和分析方法,利用聚类方法离散化处理成绩信息,根据关联方法挖掘课程间关联关系,并对课程关系图进行绘制,该方法使数据挖掘结果的准确度有所提高,但该方法的数据挖掘过程较为复杂.蔡柳萍等[7]以提高大数据挖掘效率为目的,研究了基于稀疏表示和特征加强的数据挖掘方法,通过对数据特征分类,特征提取,并结合数据在类中的分布进行加权完成数据挖掘,但该方法的数据挖掘准确度不高.因此,本文提出基于机器学习的线上实验课程资源挖掘,根据用户搜索路径通过机器学习对其行为信息进行挖掘.基于用户的搜索频率分析其兴趣偏好,为用户推荐符合其偏好的实验课程信息,实现线上实验课程资源的个性化推荐.
1 线上实验课程资源挖掘
1.1 构建线上实验课程结构
线上实验课程的组织结构同样用章节划分,数个大章节构成全部实验课程,各大章节下分为几个小节,数个知识点组成各小节.线上实验课程教学过程中,PC 端通过Web 页面形式展示给用户,移动端则通过用户端程序展示给用户,不同登录方式导致实验课程的组织结构存在差异.当用户通过PC 端登录时,学习场所固定且基本能够保持长时间的学习,所以采用以节为单元的学习方式开设实验课程,各节中所涵盖的Web 页面最少为1 页.移动端用户更适合选取碎片化学习方式,并将学习时间控制在15 min 之内,因此,实验课程的组织结构需遵循独立性及整体性[8].由于知识点的逻辑结构更具有整体性,更符合客户端用户的课程结构需求.线上实验课程的组织结构如图1 所示.
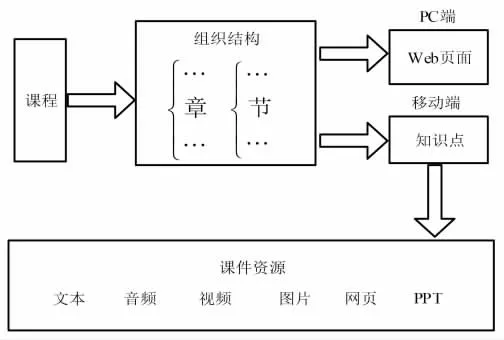
图1 在线实验课程组织结构Fig.1 Organizational structure of online experimental courses
实验课程的课件资源通常以文本、视频、图片等形式存在,PC 端登录的用户以Web 页面形式进行实验课程学习,每次学习一个小节,学习时间大概在40 min,移动端则以知识点的形式学习,每次学习一个知识点,时间大约15 min.在线实验课程资源包涵盖了实验课程目录、知识点、考试内容、课件内容等方面信息,课程的目录信息归并在course.xml 中,包含各节全部知识点,知识点中所需的文本、图片等资源的搜索路径存储在知识点文件中,实验课程测试内容存储在考试文件中,包含测试题目、测试答案和涉及的相关知识点等,课件资源存储在课件文件中.用户通过点击文件的方式即可完成实验课程的在线学习.
1.2 基于机器学习的课程资源文件解析
针对在线实验课程资源文件并非完全格式化文件结构的特点,通过机器学习方法实现课程资源文件的解析.同类事件聚类结果的好坏往往由该类事件的评分标准决定,本文以函数值的方式对其进行界定[9],通过迭代方式使分类准确度获得有效提升.产生项对、文件聚类、确定文件事件模板三个阶段构成文件解析全过程.
1.2.1 项对生成 将空格作为拆分符对文件进行细分,将其划分为字符串,数量为N,文件的项即是一个字符串,项对包含两个项,第一项分别与其后所有项组合生成项对,数量为N-1 个,分别为(1,2)、(1,3)、(1,4)、…、(1,N),第二项同样分别与其后所有项组合生成项对,数量为N-2 个,分别为(2,3)、(2,4)、…、(2,N),以此类推,直至第N-1 项与最后项生成项对(N-1,N),以上为文件的全部项对.针对所有文件信息,遍历其内全部项,两两生成项对,用项对对各文件信息进行更换.
1.2.2 文件聚类 文件解析的关键是对文件进行聚类,对隶属于同类的文件事件进行归类,并生成相同文件事件模板是聚类的根本目标[10].本文采用机器学习的聚类方法实现文件聚类.
对原始文件分组,个数为k,生成文件项对,针对各文件,求解某一组至其他组的潜在函数值,其表达式为

式(1)中:A 为文件,r∈R(A)为文件项对,涵盖项对r的文件在A 中的个数用N(r,A)表示,涵盖项对r的文件在A 中的比值表示为.
通过该函数值可判断文件位置是否发生改变,当函数值增加,对文件分组消息进行替换,随着函数值不断增大,继续进行迭代,直至文件函数值不再变化,终止迭代,文件聚类的最后分类结果即是当下分组数.
1.2.3 生成文件 事件模板建立文件的信息签名是生成文件事件模板的首要任务,实施办法是:对各文件的各项使用次数进行记录,消息签名是以使用次数大于50%的项作为备选,文件事件备选项由各文件的备选项构成,各类别的文件事件模板则是使用次数最多的文件事件备选.
1.3 聚类结果评价指标
本文以准确率(Precision)、F_measure、Rand index 指标来衡量聚类结果优劣[11].
1.3.1 准确率指标 准确率是搜索文件数与待搜索文件总数的比值,用于判断聚类结果是否为最佳分类.S 表示数据的隶属类别,可将其视为NS集合中准备检索的项,Ak为簇,其大小表示为Nk,Ak中S 的个数表示为Nsk准确率可表达为

根据本文的聚类评价要求,可替换为

式(3)中:准确分类为正例的数量表示为TP,即将类似数据归为同一簇,未实现准确分类为正例的数量FP,即将差异性数据归为同一簇.
1.3.2 F_measure 指标 F_measure 的表达式为
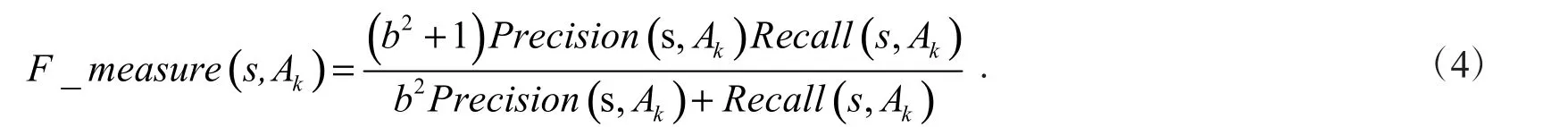
Recall 的求解公式可描述为

根据聚类评价要求,将其替换为

式(6)中:未实现正确分类为负例的数量表示为FN,即同类数据归为不同簇.
1.3.3 Rand index 指标Rand index 的表达式为
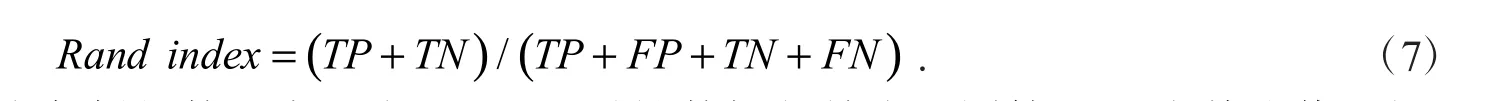
式(7)中:准确归类为负例的数量表示为TN,即差异性数据归并为不同簇,[0,1]为其取值区间,Rand index 取值越趋近于1,表明聚类结果与聚类评判标准越接近,聚类效果越好,越与实际相一致.
1.4 在线个性化智能推荐服务管理器
管理器(Agent)作为在线实验课程平台的智能化服务模块,其功能是依据用户当下搜索路径,实现感兴趣数据集的挖掘.当用户访问在线实验课程平台时,平台会向Agent 传送代表用户身份的标识以及用户推荐申请,Agent 对用户标识和推荐申请进行处理后,将信息向推荐服务器端发送,服务器端则根据用户标识识别用户身份、兴趣偏好等信息,通过资源推荐算法获取用户感兴趣的推荐内容,再将推荐内容传递给Agent,Agent 对其加权后,向在线平台发送前N 个推荐内容,由在线平台展示给用户.协同过滤技术是常使用的推荐方法,是对用户搜索行为的往期数据进行分析,获得与该用户的兴趣偏好具有较高相似性的用户集合,推荐内容即为该集合中用户最喜好的内容.该技术通过三个步骤实现实验课程资源的推荐,分别为数据描述、挖掘相邻用户、感兴趣数据集生成.
推荐服务器依据标志信息识别Agent,向Agent 传递推荐内容的同时,也将自身的标志信息传递给Agent,Agent 根据权值选择推荐服务器,权值高的N 个推荐服务器可接收推荐申请,该服务器的权值是随着用户偏好及在线平台类型呈动态改变. 平台的初始推荐服务器端权值具有一致性,Agent 的职责是向服务器传送推荐申请,并接收推荐内容,求解各个实验课程的加权值,将前N 个推荐内容显示给用户,根据被推荐课程中含有的标识可识别推荐服务器.Agent 会对用户搜索行为进行监督, 实时掌握推荐内容的访问状况,当用户访问或购买推荐内容时,Agent 会进行登记,依据服务器的登记次数实时改变其权值.H 为某服务器的登记次数,Wg为其权值,可描述为

针对u 用户,i 为实验课程资源,资源i 的预估值可表示为

当推荐服务器具有较高登记率时, 推荐内容中更易包含该服务器所推荐的文件事件模板所包含实验课程资源,不断对权值更新,可使推荐内容更加精准,满足用户偏好[12].
获取感兴趣数据集需对以下问题进行综合分析:
第一:对当下用户的搜索页面而言,需对各个具有高搜索频率的内容建立关联规则.
第二:判断用户是否搜索过备选Web 页.
第三:判断用户当下点击窗口是否与推荐内容相关.
第四:基于用户当下点击窗口Web 页面,备选URL 需选择与之具有链接关系的Web 页面.
1.5 实验课程资源推荐
根据用户对实验课程资源的搜索模式,获取用户感兴趣数据集的切实可行方法[13].在对课程资源文件进行解析时生成项对,通过求解潜在函数值并建立信息签名的基础上,实现文件事件模板的输出.基于最小支持度将偶尔搜索项剔除,将搜索频率较高类型的文件事件模板作为集合,通过该集合生成聚集树.基于机器学习的线上实验课程资源挖掘方法通过聚集树实现用户搜索路径关联规则的挖掘, 用户推荐内容是由推荐度因子决定,该因子则是将关联规则的置信度与距离参数相乘而得.
本文利用滑窗采样方式得到用户当下搜索路径,实现用户检索行为的及时掌握,达到向用户推荐资源的目的[14].设定W 为滑窗尺寸,通过W 大项向W+1 项检索建立关联规则集,利用滑窗大小为W 的现下用户搜索路径与聚集树的子搜索路径进行匹配[15],将全部W+1 大小的搜索频率较高的搜索路径检索出来.
聚集树的关联规则挖掘算法:
SW为在当下滑窗遮掩下的用户搜索路径,Tree_TF表示聚集树,支持度最低值为ρmin,置信度最低值为σmin,将以上各参数均作为算法输入,GL 表示关联规则集,将其作为输出.在Tree_TF中挖掘与SW相适应,且W+1 大小的搜索路径SW+1的备用大项集;针对第i 个备用大项,,如果则关联规则为,对其置信度σ进行求解;如果,则.针对各个备选项,其支持度可描述为

在求得关联规则集的基础上,再利用推荐度参数,获取推荐集,算法流程如下:
SCOREmin表示推荐度参数最低值,与关联规则集合GL 一并作为算法输入,Recommend 表示推荐集,以之作为输出.
(3)begin
(5)begin
(10)end.
2 实验分析
以某在线实验课程平台采集的用户行为信息作为数据集,数据集中含有20 名用户的15 门实验课程的学习记录、课程评价信息.数据集包含500 条数据,将其中400 条数据作为训练数据,100 条作为测试数据.
分别采用本文方法、文献[6]的成绩挖掘方法、文献[7]的基于稀疏和特征加权的挖掘方法对线上实验课程资源进行挖掘,生成推荐列表,分析三种方法在不同列表长度下的数据挖掘准确率,验证本文方法的数据挖掘能力,实验结果如图2 所示.
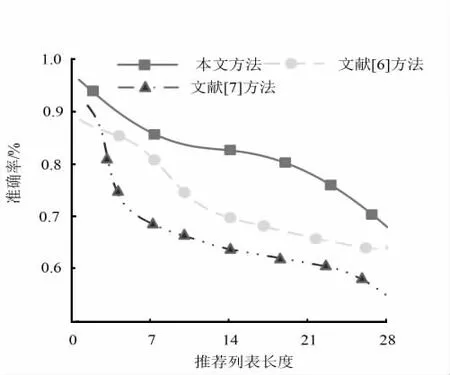
图2 数据挖掘准确率对比Fig.2 Comparison of data mining accuracy
分析图2可知,随着推荐列表长度的不断扩大,三种方法的数据挖掘准确率均呈现下降趋势,文献[7]方法的准确率下降趋势最大,文献[6]方法降低幅度小于文献[7]方法,本文方法的准确率始终高于其他两种方法,当列表长度为14 时,本文方法与文献方法的准确率差值最大,准确率一直下降的原因在于列表长度增加,推荐列表中会包含更多与用户偏好关联性较小的实验课程,降低用户满意度.实验结果表明,推荐列表长度对于课程资源挖掘效果至关重要,列表长度为14 时可体现出最佳挖掘效果.
为验证本文方法针对新用户的实验课程资源挖掘效果,以在线平台的新用户为研究对象,采用本文方法对其进行实验课程资源挖掘,推荐列表长度设置为14,先从数据集中获取该用户的好友,该用户对实验课程的评分为好友课程评分平均值,通过平均绝对误差(MAE)及均方误差(RMSE)及准确率指标验证本文方法的资源推荐效果,实验结果如图3 所示.
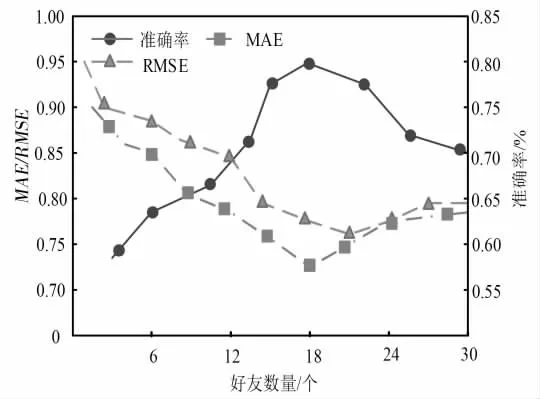
图3 新用户实验课程资源推荐效果Fig.3 Recommendation effect of newuser experiment course resources
分析图3可知,当用户好友个数不断增多,MAE、RMSE 值呈下降趋势,准确率指标呈上升趋势,当用户好友数为18 时,MAE 值开始变大,当好友数达到21 时,RMSE 值也开始上升,当目标用户好友数量位于15 至21 之间时,MAE 和RMSE、准确率指标可分别取到最低值、最高值,由此可知,基于好友的课程评价可实现目标用户对实验课程评价结果的预估,目标用户的最佳好友量为15 至21 个.
以数据集中编号为3324***5502,专业信息为软件工程的用户为例,通过与文献[6]方法、文献[7]方法对比,分析三种方法的在线实验课程资源挖掘效果,实验结果如表1 所示.

表1 在线实验课程资源挖掘结果Tab.1 Resource mining results of online experimental course
根据表1可知,采用3 种方法对线上实验课程资源进行挖掘时,文献[6]方法、文献[7]方法挖掘的课程资源中与用户兴趣偏好90%相关的资源数目较少,更多的是60%相关的资源,本文方法挖掘的课程资源中与用户兴趣偏好90%相关的资源比例最大,其次是80%相关,最后是60%相关的资源.实验结果表明,本文方法的实验课程资源挖掘更贴近用户的兴趣偏好,资源挖掘准确性较高,能力更显著.
3 小结
以某在线实验课程平台采集的用户数据信息为研究对象,研究本文方法对在线实验课程资源的挖掘能力.在推荐列表长度不同时,分析三种方法的数据挖掘准确率;并采用本文方法向在线平台的新用户推荐实验课程资源,通过分析MAE、RMSE、准确率指标验证本文方法的资源挖掘效果;最后给出编号为3324***5502,软件工程专业用户的课程资源挖掘结果.实验结果表明:推荐列表长度影响课程资源挖掘效果,为体现最佳挖掘效果,最佳推荐列表长度应设定为14.好友的课程评价可实现目标用户对实验课程评价结果的预估,且15 至21 个好友更为适合.本文方法的实验课程资源挖掘更贴近用户的兴趣偏好,资源挖掘准确性较高,能力更显著.
