结合关键帧提取的视频- 文本跨模态实体分辨双重编码方法
2022-06-10曾志贤曹建军翁年凤蒋国权范强
曾志贤, 曹建军, 翁年凤, 蒋国权, 范强
(1.国防科技大学 计算机学院, 湖南 长沙 410003; 2.国防科技大学 第六十三研究所, 江苏 南京 210007)
0 引言
近年来,随着视频分享软件的崛起,如快手、抖音、微视等,现实生活中产生了越来越多的视频- 文本数据。在这种情况下,如何对大量的视频- 文本信息进行实体分辨以满足人们对不同模态信息的需求,面临巨大挑战。跨模态实体分辨针对不同模态数据间的模态鸿沟和语义鸿沟问题,采用共同嵌入空间、语义对齐、语义关联等方法,旨在从不同模态数据中识别出对同一客观实体的描述。视频- 文本作为多模态数据的重要组成部分,应该得到足够的关注和广泛的研究。
现有的视频- 文本跨模态实体分辨方法主要包含传统方法和深度学习相关的方法。传统方法主要是基于关键字搜索的方法,该方法对每个视频通过人工标记的方法预先标记与视频内容密切相关的关键词,然后利用与文本单模态检索相同的方法进行跨模态实体分辨。然而,传统方法不仅始终无法脱离人工标注的过程,而且由于人工标注的关键字通常是独立的和非结构化的,导致关键字中几乎没有关于视频的细粒度特征,例如红色的轿车、穿着蓝色球衣的男运动员等,对视频- 文本跨模态实体分辨性能提高有限。在深度学习相关的方法中,一般应用人工神经网络构建跨模态间的语义关联,进行跨模态实体分辨。
由于深度学习强大的非线性学习能力,深度学习相关的跨模态实体分辨方法已经成为主流方法。该方法一般将不同模态的数据映射至共同嵌入空间,进行跨模态相似度的度量。根据采用的相似度度量的粒度不同,可以分为两类。第1类将视频和文本在共同空间中用一个全局向量表示,进行跨模态语义相似度度量。文献[9]应用词向量和句向量、二维卷积、三维卷积分别对文本、图像和视频进行全局编码,然后在共同空间学习跨模态数据统一表征。文献[10,12]提出一种双重编码方法,该方法首次采用一种多级编码方法,通过挖掘视频和文本中全局、局部和时序特征信息,形成各模态数据的编码表示,进而学习不同模态数据的统一表征。然而,虽然该类方法与传统方法相比,在性能上有了很大提升,但是该类方法忽略了视频和文本中的细粒度信息,不能进行跨模态间的细粒度语义对齐,导致性能提升有限。为解决这个问题,第2类主要采用与图像- 文本中细粒度处理相似的方法,对视频中的每一帧和文本描述中的每个词进行细粒度的语义对齐。文献[16]首次将图注意力机制应用于构建视频和文本模态内的语义关联,并在共同空间中进行多级语义对齐。尽管视频- 文本跨模态实体分辨中的第1类双重多级编码方法和第2类细粒度语义对齐属于不同类型,但其本质都是利用模态中不同层级的信息进行跨模态语义对齐。
然而,现有的视频- 文本跨模态实体分辨方法在对视频处理中均采用均匀取帧的方法,这种方法抽取的帧集合通常缺少视频中的某些关键信息,不足以表征视频的全部内容,同时由于均匀取帧的方法抽取的帧数较多,也增加了模型的复杂度。
为解决以上问题,本文提出一种结合关键帧提取的视频- 文本跨模态实体分辨双重编码方法(DEIKFE)。首先,设计关键帧提取算法,在充分保留视频信息的同时降低取帧数量;然后,通过双重编码方法提取视频和文本的多级特征编码表示,采用共同空间学习的方法学习视频和文本跨模态数据的统一表征。本文的主要贡献如下:
1)提出了一种结合关键帧提取的视频- 文本跨模态实体分辨双重编码模型。设计关键帧提取算法提取关键帧,利用双重编码方法对视频和文本数据进行多级编码,提高实体分辨性能。
2)首次将关键帧提取方法与现有的视频- 文本跨模态实体分辨相结合,设计关键帧集合相似度最小化的关键帧提取方法,在充分保留视频信息的同时降低所需帧的数量,提高现有方法的性能,证明了关键帧提取的有效性。
3)与现有的方法进行对比,结合关键帧提取的视频- 文本跨模态实体分辨双重编码模型取得了最好的性能,证明了该方法的优越性。
1 问题描述
视频集={,,…,,…,},其中表示集合中第个视频,为视频集中视频的个数,的关键帧集合特征表示为={,,…,,…,},为第个视频中提取的关键帧数量,关键帧按在视频中的时序排列,为视频中第个关键帧的特征表示。文本集={,,…,, …,},其中表示文本集中第个文本描述,为文本集合中文本描述的数量,={,, …,, …,},为该文本描述中所包含的词数量,为文本中第个单词的特征表示。
视频- 文本跨模态实体分辨的目的是构建视频集与文本集的对应关系,即(,)={〈,〉|∈,∈,↔},其中↔表示两个模态数据与,是对同一客观实体的描述。
2 方法描述
如图1所示,结合关键帧提取的视频- 文本跨模态实体分辨双重编码模型主要包含视频关键帧提取、视频多级编码、文本多级编码和共同空间学习4部分。其中,关键帧提取方法为本文设计的方法,采用相似度最小化方法提取视频关键帧集合表示,该集合为原视频帧集合的子集;视频和文本编码方法采用与文献[11]相同的双重编码模型,提取视频和文本由粗糙到精细不同层级的特征表示;共同空间学习采用强负样本三元组损失进行网络参数优化,实现视频- 文本的跨模态语义关联。下面对4部分进行详细介绍。
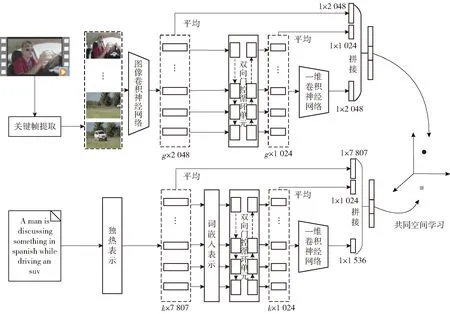
图1 结合关键帧提取的视频- 文本跨模态实体分辨双重编码模型Fig.1 DEIKFE for video-text cross-modal entity resolution
2.1 视频关键帧提取
视频关键帧提取的目的是在尽可能减少视频帧的情况下保留视频原有的语义信息,即提取视频中相似度差异最大的帧,同时保留对视频信息的表征。因此,本文设计了基于相似度最小化的关键帧提取方法。表1所示为视频帧提取算法结果示例。
设视频中的所有帧可以表示为={,,…,,…,},其中为视频中帧的数量,为视频中的第帧表示,初始关键帧集合为空集′={},选择的下一关键帧可以表示为′。假定关键帧集合中的第1帧从视频中随机选取,则下一关键帧的选择过程可以通过(1)式计算求得:
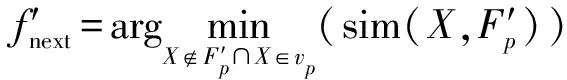
(1)
式中:sim(,′)的计算可以通过(2)式求得,
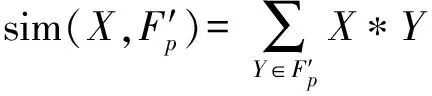
(2)
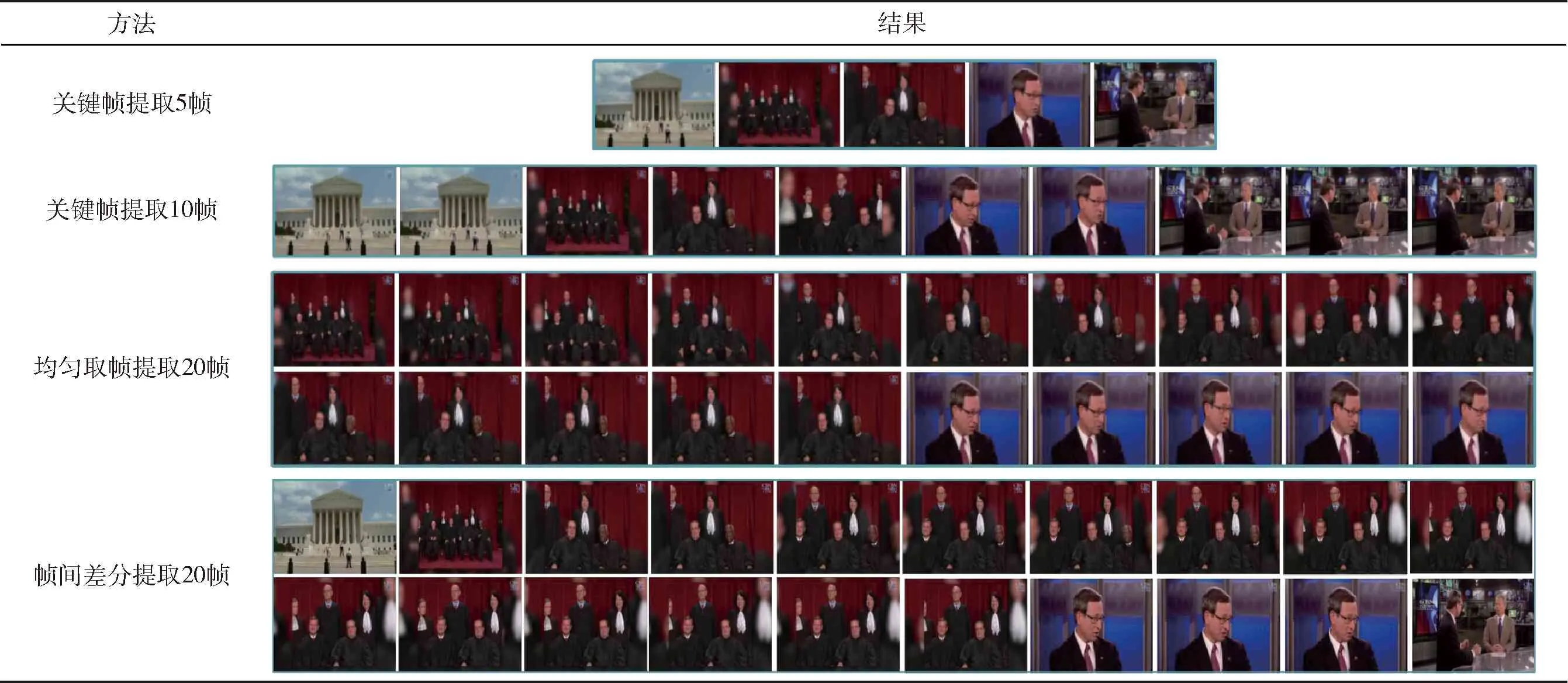
表1 视频帧提取算法结果示例
表示当前选中的视频帧,表示关键帧集合中的一帧, *表示皮尔逊相关系数计算,计算结果为帧间相似性大小,帧间相似性的值越大,表示越相似,如(3)式所示:
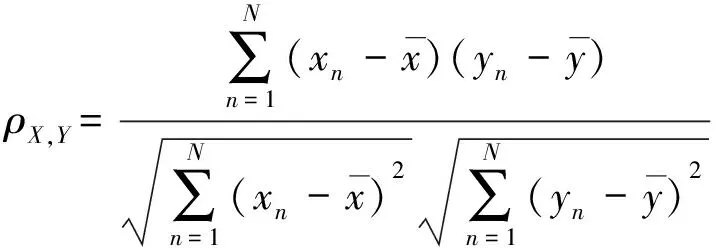
(3)
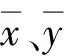
′=′∪{′}
(4)
求视频关键帧集合的过程如算法1所示。
相似度最小化的关键帧提取方法。
输入:视频中的所有帧={,, …,, …,},关键帧集合′,关键帧数量。
输出:视频关键帧集合′={′,′, …,′, …,′}
Begin
初始化:′={};
for=1:
{if==1
{从视频中随机抽取第1帧为关键帧′,更新′={′},并在视频中移除该帧=-{′};
}
else
{根据(2)式计算中每一帧与关键帧集合的相似度;根据(1)式挑选下一帧关键帧′;更新′=′+{′},并在视频中移除该帧=-{′};
}
}
对′中的关键帧,按在视频中的时序进行排序,得出视频关键帧集合′={′,′,…,′,…,′}
End
为更直观地比较本文设计的关键帧提取算法与现有常用取帧方法之间的差异,直观感受关键帧提取算法的优越性,表1列举一个视频例子,分别给出应用关键帧提取算法提取5帧和10帧,以及均匀取帧和帧间差分法——改进的帧间差分和高斯模型(IDM)提取20帧的效果。IDM中,设帧间差的阈值为065。从表1中可以看出:均匀取帧容易缺失视频中某些场景的帧,导致在表征视频原有内容时出现信息缺失的问题;IDM在提取帧时由于无平移不变性,容易导致视频中具有位移的场景重复帧较多,而且在具有较复杂场景的视频中容易出现缺帧和漏帧的情况;与之相比,本文设计的关键帧提取算法能够有效提取表征视频信息的关键帧,而且在关键帧数量比较大但又不过大时,如取10帧,存在可以记录视频中连续的动作等序列化信息的帧。
2.2 视频多级编码
如图1所示,视频多级编码方法提取了视频3个层级的特征信息,分别为全局、局部和时序相关的特征。给定视频关键帧集合′,对于视频帧的特征提取,一般采用在ImageNet数据集中预训练的卷积神经网络(CNN)ResNet或在视频数据集中预训练的三维CNN对视频进行特征提取,形成视频的特征表示,如(5)式所示:
={,,…,,…,}=(′)
(5)
221 视频全局特征编码
在全局特征编码上,现有的一般方法均采用均匀池化或加权求和的方法,保持与文献[11]的一致性,采用均匀池化的方法求视频的全局特征表示,如(6) 式所示:
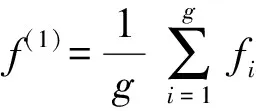
(6)
2.2.2 视频序列化特征编码
现有的大量工作已经证实,双向长短时记忆(Bi-LSTM)网络、双向门控循环单元(Bi-GRU)网络能够有效地处理时序问题。因此,本文采用Bi-GRU网络学习视频序列化语义信息,该方法比Bi-LSTM网络参数少,需要的训练数据也更少,且效果更好。该网络包含一个前向GRU网络和一个反向GRU网络,每个GRU皆由GRU单元构成,对于每个GRU单元,其递归更新的过程可以表示为(7)式~(10)式:
=(·[-1,])
(7)
=(·[-1,])
(8)
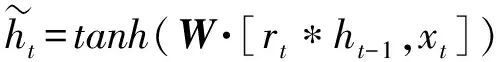
(9)
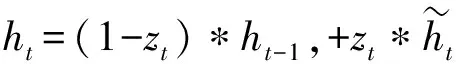
(10)
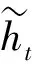
Bi-GRU网络的输出可以表示为={,,…,,…,},其中表示为第帧对应输出的特征表示,可以表示为GRU前向门与后向门的输出的组合,如(11)式~(13)式:
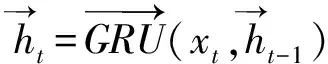
(11)
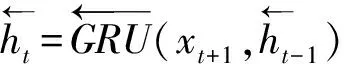
(12)

(13)
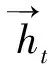
通过双向门控循环单元,可以生成每一帧之间的序列化表示,然后利用平均池化的方法获得视频的序列化特征表示,如(14)式所示:
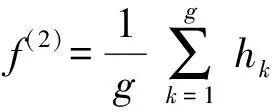
(14)
223 视频局部特征编码
由于视频的序列化特征表示只是视频关键帧序列化特征的平均,关注点在于视频的时序特征。因此,有必要提取视频中的局部特征,在提取方法上采用与文本分类处理相似的一维CNN。
在细节处理上,为了从不同大小的视角提取视频关键帧的细粒度特征,分别设计不同大小的一维CNN。设卷积核的大小为×1,其中为卷积核第1维大小,即视觉感知大小,分别设置=2,3,4,5的4个卷积核,以利于在不同视角关注特征,其中每个卷积核的步长为2,输入维度为×1 024,输出大小为×512,对输出采用非线性激活函数进行非线性映射,然后采用最大池化的方法将特征压缩为512。对于每个卷积核的输出进行拼接,形成视频局部特征表示,如(15)式和(16)式所示:
=max-pooling((1-dCNN()))
(15)
=[,,,]
(16)
式中:[,,,]表示拼接,即前后元素相连接,如=[01, 02],=[03, 04],=[05, 06],=[07, 08];=[01, 02, 03, 04, 05, 06, 07, 08]。
224 视频多级编码表示
由于视频全局、序列化、局部特征编码为视频不同层级特征的编码,对视频具有不同的表征作用。因此,采用将三者拼接的方式获得视频多级特征编码表示,如(17)式所示:
l=[,,]
(17)
2.3 文本多级编码
文本多级编码方法与视频多级编码方法是对称的,但也有些许不同,下面对不同之处进行描述。
文本的全局特征为词的独热表示的平均,采用传统的词袋模型,词的多少决定了全局特征维度的大小,如在图1中,表示有7 807个已知且统计的词;文本的序列化特征通过Bi-GRU提取,在词嵌入的处理上,采用文献[25]在30 M的Flick图像- 文本标签数据集中预训练的词向量模型;文本局部特征采用3个(分别取值2,3,4)的一维 CNN。最后,通过将不同层级的特征进行拼接形成文本的多级特征编码表示,如(18)式所示:
l=[,,]
(18)
2.4 共同空间学习
由于视频和文本的多级编码表示不在同一维度空间,不能直接进行相似度的度量和比较。因此,首先分别采用全连接网络将两个模态的数据映射至一个同维度的共同嵌入空间。如(19)式、(20)式所示:
()=(l)
(19)
()=(l)
(20)
对于映射到同一空间中的视频和文本数据,网络模型优化目标是使得配对的视频- 文本跨模态相似度尽可能大,而不配对的视频- 文本相似度尽可能小,最大限度地学习模态间的语义关联。因此,在跨模态语义关联学习上,采用与VSE++相同的损失函数对模型参数进行优化,该损失只关注在每个批处理中最强的负样本,而不关注其他负样本,即强负样本三元组损失函数,如(21)式所示:
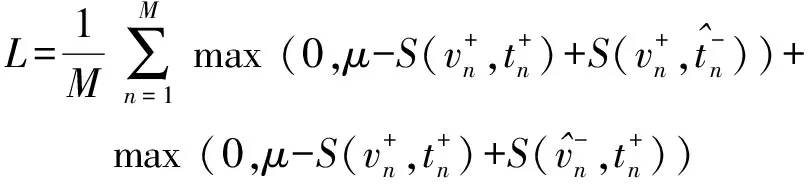
(21)

3 实验
3.1 实验环境及参数设置
实验环境如下:操作系统CentOS 7 64,GPU Nvidia Tesla P40,显存24 GB,开发环境Python 3.6.5、Torch 1.6.0。
实验中,批处理大小为128,阈值=0.2,Bi-GRU隐藏单元向量维度为512,嵌入共同空间的维度为2 048,词袋模型中只统计词频不小于5的单词。与文献[25]相同,学习率为0.000 1,采用随机梯度下降的Adam优化器,并且设置在验证误差连续3个epochs不下降的情况下,学习率减半,即除以2,在连续10个epochs验证精度不提升的情况下,提前终止训练,最多训练50个epochs。
为验证关键帧提取的帧数对跨模态实体分辨性能的影响,分别取值为5、10、15、20。
3.2 数据准备
为验证DEIKFE的有效性,选择在视频- 文本跨模态实体分辨中广泛使用的MSR-VTT(Microsoft Research-Videoto Text)数据集和VATEX数据集进行实验验证。
3.2.1 MSR-VTT数据集
MSR-VTT数据集包含10 000个网络视频,其中每个视频都标注了20条英文文本描述,总计200 000条文本描述。实验中,与文献[10,33]相同,选取6 537个视频及其文本描述作为训练集,497个视频及其文本描述作为验证集,余下的2 990个视频及其文本描述作为测试集。采用ResNet152进行特征提取,并选取pool5层输出的2 048维向量作为视频帧的特征表示。
3.2.2 VATEX数据集
原始的VATEX数据集中,训练集包含25 991个视频,验证集包含3 000个视频,测试集包含6 000个视频,其中每个视频都包含10个中文文本描述和10个英文文本描述。由于原始的6 000个测试集视频并未公布其对应的文本描述,实验中与文献[10,33]相同,原始数据集的训练集不变,将3 000个测试视频随机等分,即1 500个视频及其文本描述作为验证集,1 500个视频及其文本描述作为测试集。由于只能获取该数据集I3D的特征表示,统计特征维度为×1 024,其中≤32,而且绝大多数都落在32,因此采用重复补全的方法,将所有维度都扩充为32×1 024,同样采用关键帧提取方法对其进行处理。此时,视频全局特征表示和Bi-GRU输入特征维度均为1 024。
3.3 评价指标
实验采用两种检索任务用于验证DEIKFE的有效性:1)视频匹配文本,在测试集中随机选取一个视频,检索测试集中与之匹配的文本;2)文本匹配视频,在测试集随机选取一个文本,检索测试集中与之匹配的视频。
为了便于进行实验对比,采用与文献[10,30,33]相同的评价指标,包含R@、R@sum和MedR。下面对这些指标进行详细介绍。
R@:为局部性能指标,表示根据查询返回的结果中,相似度排名前(top-)中是否存在正确结果,可以用(22)式表示:
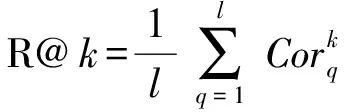
(22)
式中:表示查询的数量;表示查询结果,如果在排名前中存在正确结果则为1,否则为0。实验中的取值为1、5、10。
R@sum:为总体性能指标,表示所有取值的R@之和。可以用(23)式表示。
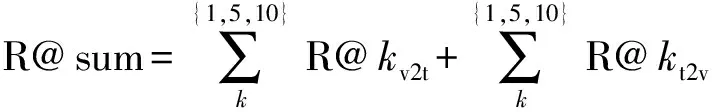
(23)
式中:v2t表示视频查询文本;t2v表示文本查询视频。
MedR:表示测试集中所有查询所得的正确结果相似度排名中位数的平均,体现了半数结果的排名情况。
3.4 实验结果与分析
实验与现有采用双重编码的5种方法进行对比,这些方法皆采用均匀取帧的方法,下面加以详细介绍。
VSE:采用CNN和长短时记忆(LSTM)对视频帧和文本进行特征提取,对提取的特征求平均,利用全连接层将其映射至共同空间,采用三元组损失进行语义关联度量。
VSE++:特征提取和处理方式与VSE相同,不同在于改进了损失函数,采用强负样本三元组损失进行语义关联度量。
RNF:通过融合文本特征、视觉特征、动作特征和语音特征等多模态信息,并将正样本的排名数融入强负样本三元组损失进行语义相似度度量。
W2VV:采用词向量工具和GRU网络对文本进行编码,采用CNN和视频标签对视频进行编码,而后在共同空间进行语义关联学习。
Dual Encoding:采用双重编码方法对视频和文本进行全局、局部和序列化特征的编码,在共同空间中进行语义关联学习。
为了对比分析方便,根据视频和文本编码粒度对方法进行分类:1)采用全局特征编码的方法:VSE、VSE++;2)采用全局和序列化编码的方法:RNF、W2VV;3)采用多级编码的方法:Dual Encoding、DEIKFE;4)结合关键帧提取和多级编码的方法:DEIKFE。
DEIKFE以及所有对比方法的结果如表2和表3所示。IDM为采用IDM进行关键帧提取的结果。
对比分析表2和表3可知:
结合关键帧提取与多级编码的DEIKFE在所有性能指标上都达到了最优,优于其他对比方法:与同样采用均匀取帧的多级编码Dual Encoding对比,结合关键帧提取后,DEIKFE在MSR-VTT和VATEX两个数据集中总体性能分别提升9.22%、2.86%;与采用IDM对比,在MSR-VTT和VATEX两个数据集中总体性能分别提升了4.56%、2.80%。分析其中原因可知,虽然采用均匀取帧的多级编码Dual Encoding能够同时构建视频和文本全局、局部和序列化特征,但是在视频帧提取上,均匀取帧导致视频信息缺失,实体分辨性能下降,而IDMIDM虽然优于均匀取帧,但是由于该方法对差分阈值的设定非常敏感,导致该方法不能尽可能多地提取视频信息出现缺帧和漏帧的情况,性能提升有限。以上结果分析充分表明,结合关键帧提取的多级编码方法能够有效地提高实体分辨的性能。采用多级编码的方法要优于只采用全局、局部和序列化中的一种或者两种组合的特征编码方法。采用多级编码的Dual Encoding、DEIKFE优于VSE、VSE++、RNF、W2VV。分析可知,通过将视频和文本不同层级的特征进行拼接,可以充分地表征模态数据信息,而采用其中的一种或者两种都不足以表征完整的信息,导致性能下降。
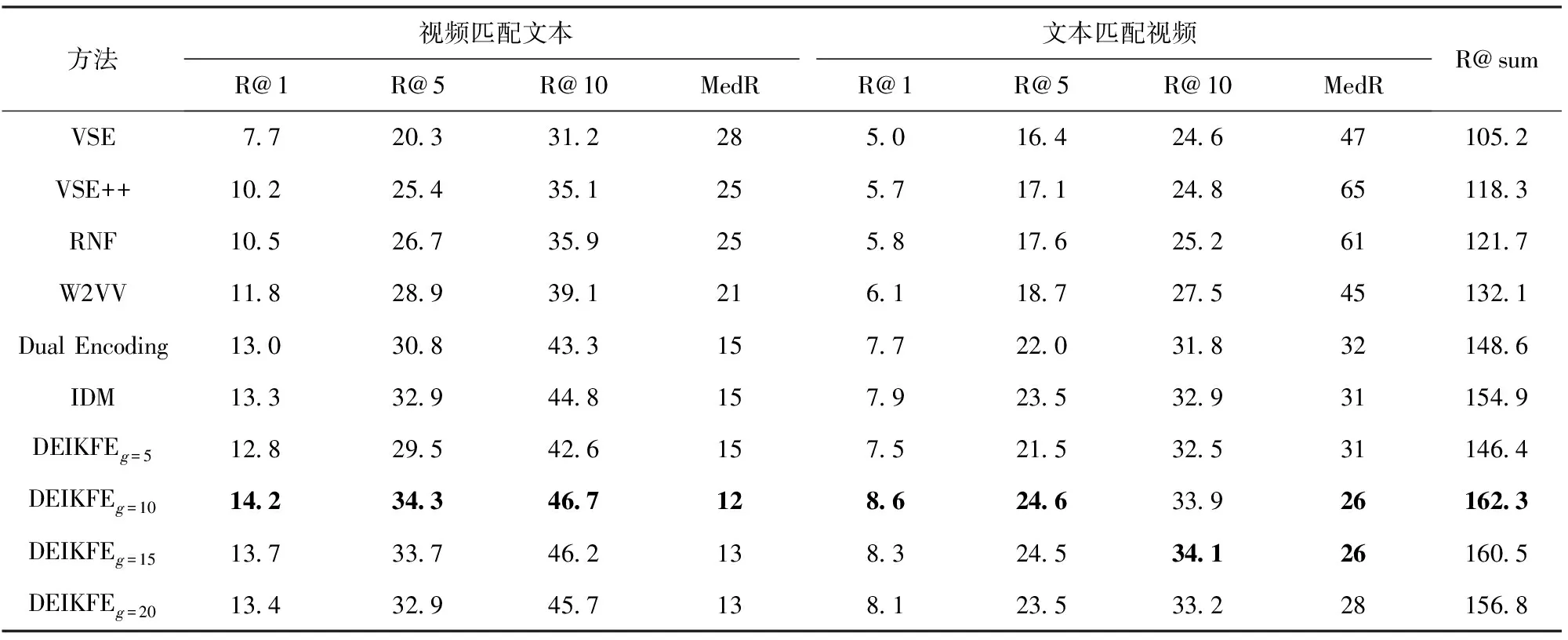
表2 MSR-VTT数据集上跨模态实体分辨结果对比Tab.2 Comparison of cross-modal entity resolution results on MSR-VTT
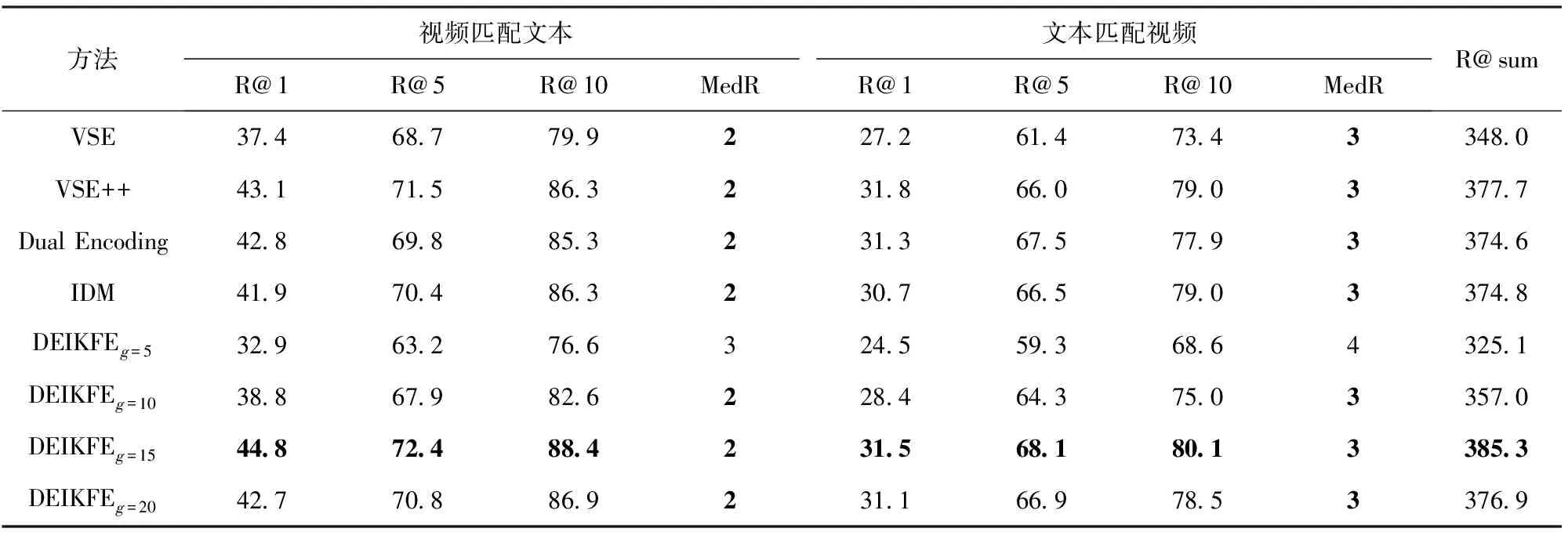
表3 VATEX数据集上跨模态实体分辨结果对比Tab.3 Comparison of cross-modal entity resolution results on VATEX dataset
当取值为10和15时,DEIKFE分别在MSR-VTT和VATEX数据集中的性能达到最优。分析在不同关键帧数量下的结果可知,当关键帧数量较小时,即使能够提取出视频中不同场景的信息,但是却不能记录下视频中的时序特征,对于动作理解的缺失,如跑步的先后动作,导致实体分辨性能降低;而当关键帧数量过多时,虽然能够记录下视频中的时序特征,但是由于存在大量的冗余信息,导致模型训练复杂度增大,而且在求平均过程中冗余信息大的特征所占权重大,而某些关键的特征可能因为无冗余而被忽略;只有当关键帧数量适中时,才能完整地记录下视频中的全局、局部和序列化特征,提高模型的性能。
为更直观地分析DEIKFE跨模态实体分辨的效果,表4和表5给出了DEIKFE在MSR-VTT数据集上文本匹配视频与视频匹配文本的例子,表中列出了与查询视频或文本相似度排名前3的文本描述或视频对应的关键帧。对于每个查询文本,有且仅有1个与之匹配的视频,表中蓝色方框为与文本描述相匹配的视频,红色方框为与文本描述不匹配的视频;对于每个查询视频,表中蓝色字体为正确的句子,红色字体为错误匹配的结果。从表4中可以看出,在相似度排名前3的结果中,不论是文本匹配视频还是视频匹配文本,跨模态数据语义上都具有极高的相似性,表明DEIKFE模型能够有效地构建视频与文本之间的语义关联关系,达到跨模态实体分辨的目的。

表4 MSR-VTT数据集文本查询结果示例
4 结论
本文针对现有的视频文本跨模态实体分辨存在的问题,提出一种结合关键帧提取的视频- 文本双重编码方法。通过实验验证其有效性,得出如下主要结论:
1)采用多级特征的编码方法整合了全局、局部和序列化特征,要优于仅采用其中一种或者两种特征的组合。
2)结合关键帧提取的视频- 文本跨模态实体分辨双重编码方法要优于未采用关键帧提取的方法。
3)提取足够的关键帧,使其既能够充分表示视频中不同场景的信息,也能保留视频原有的时序相关的特征信息,又不存在冗余,提高了视频- 文本跨模态实体分辨的性能。

表5 MSR-VTT数据集视频查询结果示例
本文研究结论对未来的相关研究工作具有实际应用价值,在以后的视频- 文本跨模态实体分辨研究中,应在考虑整合视频和文本多级特征编码的同时,结合本文提出的关键帧提取方法,或者设计性能更好的关键帧提取方法,以达到更佳的性能。
