基于大数据挖掘技术的终端换机预测研究
2022-06-09李京文毕佳佳
李京文, 毕佳佳
(安徽职业技术学院,安徽 合肥 230011)
近年来,随着生活水平的提升、手机品牌的不断更新,用户更换手机的频率日益频繁。移动用户更换手机终端的原因通常有被动换机、常规换机以及潜在换机等。商家要及时抓住潜在换机的用户,对这部分用户进行精准营销,推荐潜在换机用户喜欢的终端类型,提升用户的价值,提高营业收入[1]。因此,对潜在换机的用户进行准确地识别是非常有必要的。
随着用户量的增加,传统的统计分析方法已不足以分析出换机用户的规律,越来越多的人员开始将大数据挖掘技术应用到终端换机上来,不仅能提高挖掘的效率,还能提高识别的准确率。
本文从用户基本信息、消费信息、交友圈信息、上网信息等数据中进行挖掘分析,采用决策树算法C5.0[2],建立了终端换机预测模型,为手机精准营销提供有效的数据支撑。
1 总体思路
终端换机预测主要是根据移动用户的消费行为,准确预测出有潜在换机倾向的用户,将该种用户清单进行输出,并进行手机终端的精准营销。因此,预测模型首先要根据用户的历史数据确定目标用户的类别,即换机用户和非换机用户,分别用1和0进行表示。本文将终端换机预测问题转化成一个二分类模型,通过历史数据建立终端换机预测模型,将即将要换机的用户预测出来。
本文的总体思路是先对原始数据进行预处理,包括数据清洗、数据变换、特征选择等处理,之后将数据集划分为训练集和测试集,训练集采用决策树算法C5.0建立模型,并通过测试集评估结果对不同的抽样方法进行了对比,通过不断迭代优化,输出最优模型。终端换机预测模型流程图请见图1。
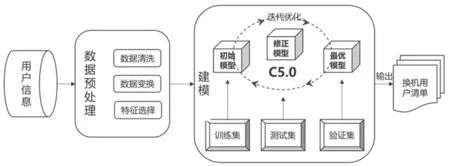
图1 终端换机预测模型的流程图
2 数据处理
2.1 数据提取
本文中所使用的数据主要提取于某运营商的真实的业务数据。主要抽取用户的基本信息、基本消费信息、上网信息、手机终端信息等,并进行初步的探索。
用户的基本信息数据中主要包含了用户入网时的基本资料,如手机号码、性别、年龄、网龄等。终端信息主要是指用户当前所用手机终端的基本信息,如手机像素、内存、历史终端使用及变更情况、平均终端更换时长等。上网信息主要包含了用户使用流量、通话次数、出账话费等信息。数据结构如表1所列,其中最后一个字段“if_hj”是用户是否换机的标志,也是本文建立终端换机模型的目标列。

表1 终端换机数据信息表

续表1 终端换机数据信息表
2.2 数据清洗
(1)缺失值处理。缺失数据会影响模型的效果,因此在建模之前需要对数据进行探索,查询出缺失值并进行处理。经探索发现,本文中的数据中只有一个字段net_age(网龄)具有极少量缺失值,由于缺失值比例很小,本文采取了直接删除法,将net_age字段缺失的记录进行删除。
(2) 异常值处理。异常值可能由于人为在输入系统的时候出现的错误,使得数据值不在正常范围内。在对异常值处理前,先对数据进行异常值检测,通常使用单变量散点图或者箱图实现,把远离正常范围的点确定为异常值。
经过分析后,原字段中只有“age”字段具有极少量异常值,范围为小于10岁和大于120岁的人群。由于有异常值的数据记录条数极少,因此本文直接删除这些异常记录。
2.3 特征工程
(1)特征构造。在数据挖掘的过程中,为了便于提取更有用的信息,挖掘更深层次的模式,提高挖掘结果的精度,需要根据数据中已有的基础特征构造出延伸特征,加入到现有的特征集合中,组成新的特征集合。
本文根据基础特征构造了3个新特征,分别是“3个月使用流量均值”“3个月出账费均值”“3个月通话次数均值”,通过平均值特征更能体现出用户的行为特点。
(2)数据离散化。在分类算法中,连续属性过多,或者连续属性的范围大、连续性高,在建模时容易产生过拟合现象[3]。过拟合现象即建立的算法模型过于拟合于训练数据集,在训练数据集上的准确率极高,而在测试集上的准确率却很低,无法对未来数据进行正确预测。
本文在探索数据分布后,将所有数据进行离散化处理。离散化规则是查看每个特征字段不同范围内的换机比例,将换机比例相近的范围归为一类,类别统一用数字表示。以“年龄”特征离散化为例,离散化过程为:
步骤1:计算不同年龄范围的换机占比分布。
其中,hj_percentage为在此年龄范围内的换机占比;hj_count为在此年龄范围中的换机人数;total_count为在此年龄范围内的所有人群。
步骤2:根据换机占比分类并归类。
根据不同年龄范围的换机占比,本文将年龄分为6类:16~20岁为第1类,20~35岁为第2类,35~45岁为第3类,45~50岁为第4类,50~60岁为第5类,60岁以上为第6类。
其他特征字段处理方式和年龄字段相同。在离散化过程中,要灵活并多次调整每次查看换机占比的当前字段的范围,最终让不同类别下的换机占比差别最大,这样会大大提高模型的准确性。
2.4 特征选择
在数据挖掘建模时,一般尽可能选择完整的数据建立模型,包括特征种类和数值完整度。然而,并不是特征越多建模效果越好。特征的好坏取决于它与目标变量的相关性和与其他变量的冗余度。因此在特征选择的时候可以“最大相关性最小冗余度”[4]为目标来进行降维。即选取的建模特征,与目标变量相关性大,特征之间相关性小、相互独立。
本文计算了各个特征与目标变量的相关性及特征之间的冗余度,将相关性较小的一些特征字段删除。对于冗余性较高的特征之间,保留其中一个特征。经过计算处理之后,对于表1中的原始特征,删除了“flow_used1”、“flow_used2”、“flow_used3”、“arpu_1”、“arpu_2”、“arpu_3”、“call_times1”、“call_times2”、“call_times3”、“MainCameraPixel”10个特征。最终利用余下的15个特征字段和1个目标变量(if_hj)建立终端换机预测模型。
3 模型建立与评估
3.1 建模方法
在模型算法选择上,本文选取了一种改进的决策树算法C5.0进行模型训练。C5.0是一种高度自动化学习过程的算法,可以实现对决策树自动剪枝,可应用于大数据集中,是一种效果较好的决策树算法。
3.2 实验结果评估与分析
本文提取的某月数据作为训练集,约300万条,用下一个月数据作为测试集,约700万条。选择C5.0分类算法在训练集上建立分类模型,然后在测试集上进行预测并计算模型性能。评估参数为查准率和查全率[5]。定义如下:

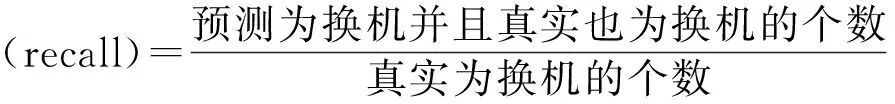
在数据挖掘中,查准率和查准率的关系是此消彼长的,但是要尽量提升两者,在其中找到一个平衡。通常采用两者的调和平均值作为评估整个模型性能的标准。
C5.0决策树模型性能结果如表2所列,其中正样本代表换机标签为1。

表2 C5.0模型验证结果
从表2中可以看出,C5.0决策树模型4在潜在换机用户的查准率和査全率上整体效果比其他模型更好。因此,本文最终采用C5.0决策树算法,训练样本取100万,正样本比例取45%建立决策树分类模型。考虑到换机营销推荐的广度,倾向保障查全率高的方式分析,同时尽可能提高查准率,据此生成本次的预测结果集。
4 结语
针对终端换机的精准营销场景,将大数据算法应用在移动通信数据中,建立终端换机预测模型。本文结合数据特点对数据进行清洗、特征工程、特征选择,采用C5.0机器学习算法建立预测模型,输出有潜在换机倾向的用户清单,为商家对手机终端的精准营销提供了辅助决策。在以后的优化中,可以添加更全的变量并通过合适的特征选择后建模,能使模型的查准率和查全率得到很大的提高。
