基于稳定同位素的消费者营养来源溯源的方法和过程
2022-06-09祝孔豪郭钰伦
王 康 祝孔豪 郭钰伦 徐 军
(中国科学院水生生物研究所, 武汉 430072)
稳定同位素分析已成为分析食物网结构的主要手段之一, 通常用来估算不同来源营养物质对消费者的贡献[1—4]。研究食物网结构涉及分析和比较物种、种群或个体在生态位空间的相对位置, 这些数据为有关摄食关系和食物网结构的推断提供了依据, 但它们不能直接反映出饮食的特征, 如通过胃内容物分析、饲养观察或粪便分析来反映[5]。由于数据的间接性质, 在解释与本文所讨论的所有分析方法相关的同位素值时, 存在各种可能的歧义来源。突发生态因子也使获得的稳定同位素数据难以进一步解释[5]: 首先, 同位素相似并不意味着生态功能相似, 因为两个个体可能具有相同的同位素生态位, 但是生态位不同。也就是说, 虽然两个不同个体的营养途径不同, 但不同的资源库可以具有相似的稳定同位素值。其次, 如果不同的资源库具有重叠的同位素值, 那么仅靠稳定同位素值可能无法溯源特定的资源库。第三, 当利用稳定同位素重建摄食关系时, 必须在时间和空间尺度上对资源库取样, 以反映出元素的同化率和组织的周转率[6]。所以, 稳定同位素数据不仅是生物之间营养关系相互作用的结果, 也是众多潜在生物和化学过程驱动的结果[7], 相关利用稳定同位素数据进行溯源的研究更需要科学的解释。
本文基于实测同位素数据集(浮游动物同位素数据集), 通过简单统计检验、营养来源先验信息的矫正, 构建系列贝叶斯模型; 通过比较模型总体性能, 及先验信息和后验分布差异等多种模型性能评价方法, 来描述消费者营养来源溯源的方法和过程。以此为应用稳定性同位素技术开展消费者营养溯源研究, 提供指导方法。
1 数据质量
1.1 测试过程
稳定同位素数据的报道, 理论上必须提供仪器校准(Calibration)和分析过程不确定性的充分信息。因此, 测试过程的监控、量化和测量精度应如实报道。在仪器分析过程中, 通常需要报道数据分析的准确度(Accuracy)、精密度(Precision)、分辨率(Resolution)和可重复性(Repeatability)[8,9]。准确度表示测量结果与真实数值之间的误差, 代表了仪器在正常运行条件下, 测定值有规则偏离真值的程度, 即测量偏差或系统误差。精密度表示测量结果的分散性, 测定数据结果越分散, 分析的精密度越低, 误差增大。可重复性表现为在改变了的测量条件下, 同一被测量物的测量结果之间的一致性。如果某一研究同位素分析在不同的时间和地点的仪器分析条件下进行, 则需要报告数据可再现水平。系统误差主要是通过仪器校准和测试人员严格操作流程来降低, 且在稳定同位素比率质谱测定中,与国际通用标准物质的“真实”值检测的偏差小于0.1‰[10]。由于研究结果报道后, 读者均未参与仪器操作和数据采集, 因此, 就研究本身的重现性(Reproducibility)而言, 同位素数据报道必须为读者提供了一种合理的评估仪器分析的不确定性的途径[8]。
因此, 在研究论文中需要报道的7个方面包括:(1)使用仪器的型号、公司名称、所在单位和实验室名称; (2)使用的国际同位素参考标准(如AIRδ15N)、仪器校准的国际标准物质(Standard reference materials, 如USGS41)及其标准值(“真值”)[11];(3)用于检测仪器分析过程中的工作标准物质(Working reference material)的类型、重复测量数、平均值和标准差(以附表形式报告)。工作标准物质通常是按照一定样品检测加入, 用于监控仪器分析过程中的准确度和精密度变化, 及基线漂移特征;通常选用与测试样品同类物质(如肌肉组织和骨骼组织等), 由执行分析的实验室自行制备或购买, 且在多个实验室进行过对比测试[11]; (4)样品本身的重复测定结果, 用以反映研究样品本身的测试精密度,包括分析的重复率(如10%)、重复样本数、平均值和标准差(以附表形式报告); (5)如果测试过程间隔了较长的时间或者更换分析测试仪器, 则需要报道不同时间和(或)地点的(1)—(4)相关内容。(6)标准不确定(Standard uncertainty), 用来反映数据分析整体误差, 采用统计平方公差法(Root-Sum-Squares),计算上述全部引起测试误差的整体特征[12]。(7)基于稳定同位素比率质谱分辨率多为小于0.1‰, 因此数据报道过程有效数字保留至十万分位(如-23.57‰)。
1.2 原始数据
研究论文数据存储指的是长期的存储学术研究论文的数据, 数据来源包括自然科学、社会科学和生命科学领域。得益于信息科技的发展[13], 数据可以大量且长时间的存储。现在, 越来越多的国际期刊和研究机构要求发表的论文必须将论文中的数据存储在公开的存储数据库中。其核心优势:(1)提高论文关注度, 便于其他学者引用、跟踪和对比研究; (2)验证该研究的重现性和真实性; (3)降低学术成本, 提升数据使用效率。因此, 建议原始的稳定同位素及研究中所报道的相关数据以附表形式发表[14]; 在正文中以表格的形式(表 1), 报道研究对象(时间、空间、物种、类群等)稳定同位素平均值和标准差的信息。
本文得益于原始数据共享的优势, 以Francis等[15]发表的湖泊浮游动物的稳定同位素研究数据集为案例(表 1), 探讨基于稳定同位素的消费者营养来源重建的整个实践过程。该数据集包含21个栖息地浮游动物和表层悬浮颗粒物、混合层下悬浮颗粒物和陆源有机碎屑三种潜在食物来源的稳定同位素数据, 及一个反映光热混合特征的环境因子。该项研究通过贝叶斯稳定同位素混合模型估计, 清晰地阐明了陆源碎屑的贡献率为<5%, 并证实了湖泊光热特征作用影响着浮游动物能量来源。
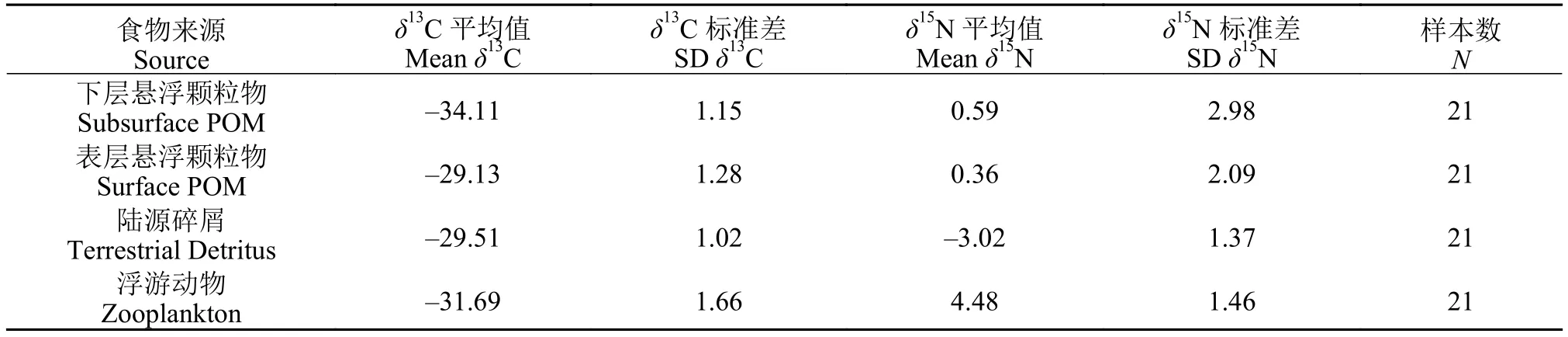
表1 浮游动物研究案例中三种食物来源与消费者的稳定同位素特征Tab. 1 Stable isotope characteristics of three potential diet sources and zooplankton
1.3 简单统计检验
在满足稳定同位素测量分析过程的准确度和精密度的前提下, 通常数据的分析假设, 例如随机、独立、正态、等方差、稳定等及野外或控制实验的平衡设计也同样重要。在同位素技术应用于食物网研究的早期, 许多稳定同位素数据的使用是基于简单统计来定性推论从消费者或食物资源的相对关系[16—19]。因此, 简单的统计检验对稳定同位素技术在食物网研究中的应用打下了至关重要的基础, 也是现在生态学的一个基本组成部分。
依据中心极限定理, 即不同概率分布的随机变量(独立与否非必要), 且均值和方差有限, 那么当样本容量趋于无穷大时, 随机变量之和的一个简单变换就可以服从正态分布[20]。因此, “算术平均数是对真值的最大似然估计”这个假设成立(高斯分布定理)。稳定同位素的自然属性符合这种假设(图 1A),因此在稳定同位素的各类模型研究中, 均使用标准差和平均值来开发模型, 且在从个体到生态系统的整合过程中, 各个层次依然遵循整体分布假设(图 1B)。需要指出的是, 根据以往统计经验, 样本容量必须达到30以上, 中心极限定理才能保证成立[20]; 但是,在实际研究中, 较低的样本容量经常导致数据分布特征不能满足统计假设; 而高样本容量大幅增加采样和分析成本, 也需要研究人员权衡。
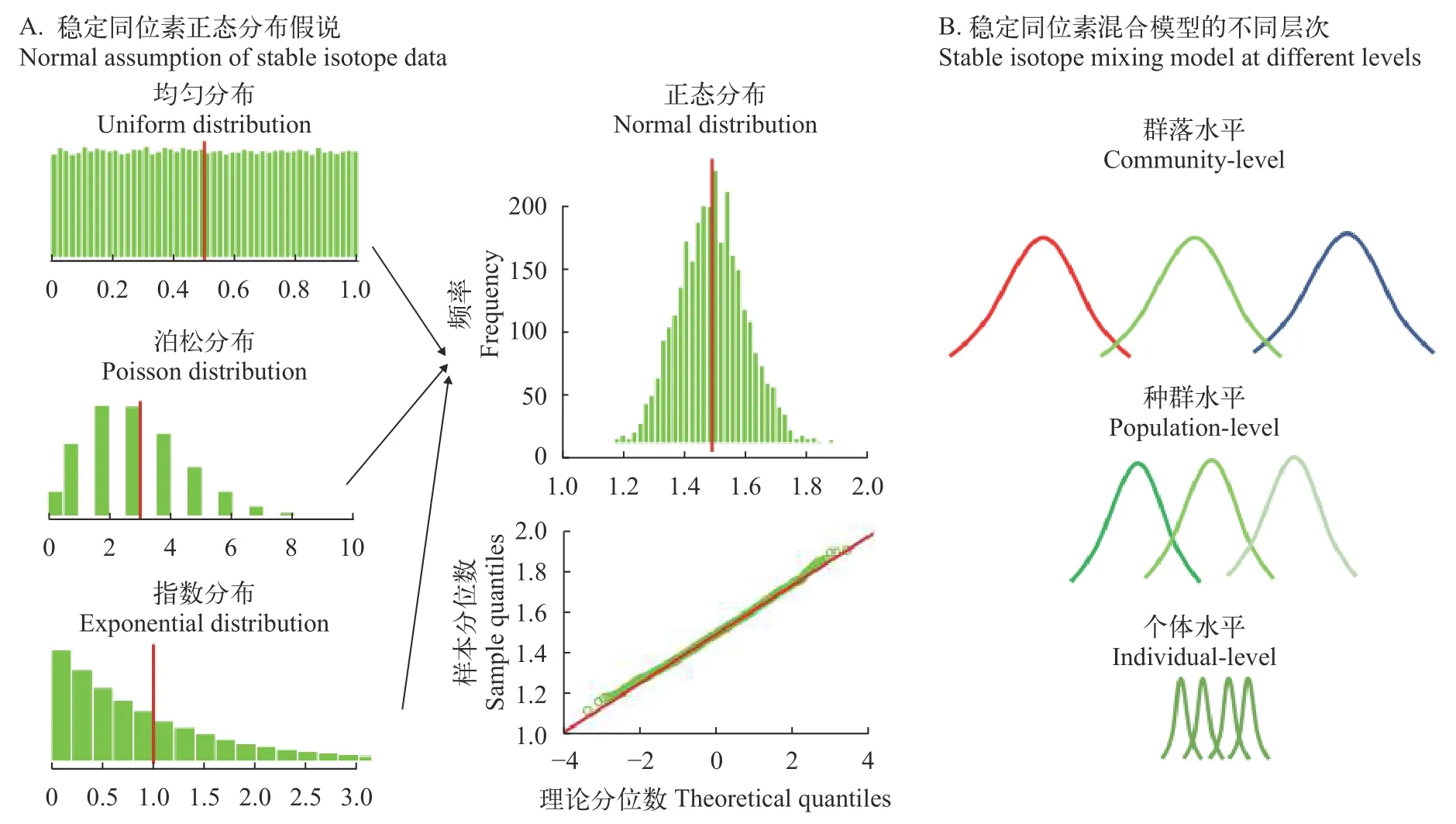
图1 稳定同位素正态分布假设(A)与多层次混合特征(B)Fig. 1 Normal assumption (A) and mixing through different ecological levels (B)
首先, 对各类食物来源和消费者的稳定同位素,进行正态分布和方差齐性检验。在对多个因变量(例如δ13C和δ15N)同时进行分析时, 常常假设因变量组合成的向量服从一个多元正态分布(Multivariate normality; 检验方法Royston test with post hoc Shapiro-Wilk test), 即随机误差必须为相互独立的正态随机变量[21]。多元方差齐性是指不同样本的方差大体相同(Homogeneity of Multi-variances; 检验方法Bartlett’s Test)。如果方差非齐性, 则会掩盖掉均值的差异信息, 影响第一类风险且导致错误的结论[21]。需要指出的是,F检验对正态型的偏离具有一定的稳健性, 但对方差分析的偏离性较为敏感。
其次, 对各类食物来源和消费者的稳定同位素,进行多变量方差分析(Multivariate analysis of variance, MANOVA), 用于检测研究的食物来源及消费者之间是否有差异以及差异是否显著。由于在样本获得过程中无法避免的差异, 及诸多无法控制的因素, 因此对各类食物来源和消费者的稳定同位素进行比较(如δ13C和δ15N), 进一步判断样本间差异主要是随机误差造成的, 还是本质不同或环境效应引起的[22]。
最后, 参数检验都基于正态和方差齐性假设,可获得更多且可比性强的结论。但是, 特别是在野外生态学调查中, 不可能总是获得满足上述这两个假设的数据; 如果强行采用参数检验就会造成错误。因此, 在上述两个假设不成立时, 亦可利用中位数进行检验, 即非参数检验; 或使用合理的数据转换方法把数据转换为正态分布。值得注意的是,许多统计方法虽然假定数据满足正态, 但是当样本量大于15或20的时候就对正态条件不敏感了; 但是如果样本量小于15且数据不满足正态分布, 相关统计结果失真, 需要特别注意结论准确性。
以湖泊浮游动物的稳定同位素研究为例, 经过多元正态分布检验和方差齐性分析, 该数据集中变量均为正态分布;δ13C方差齐性, 但δ15N方差非齐性(Bartlett’s test,P=0.004)。对δ15N进行更稳健的替代检验发现方差非齐性(Levene’s test,P=0.0429)。再进一步, 对δ15N进行更加稳健的非参替代检验发现方差齐性(Fligner-Killeen test,P=0.09377)。进一步进行多元单因素方差分析, 结果表明3种潜在食物来源表现出一种或一种以上的稳定同位素显著差异(图 2), 适合进一步分析消费者的食物来源。
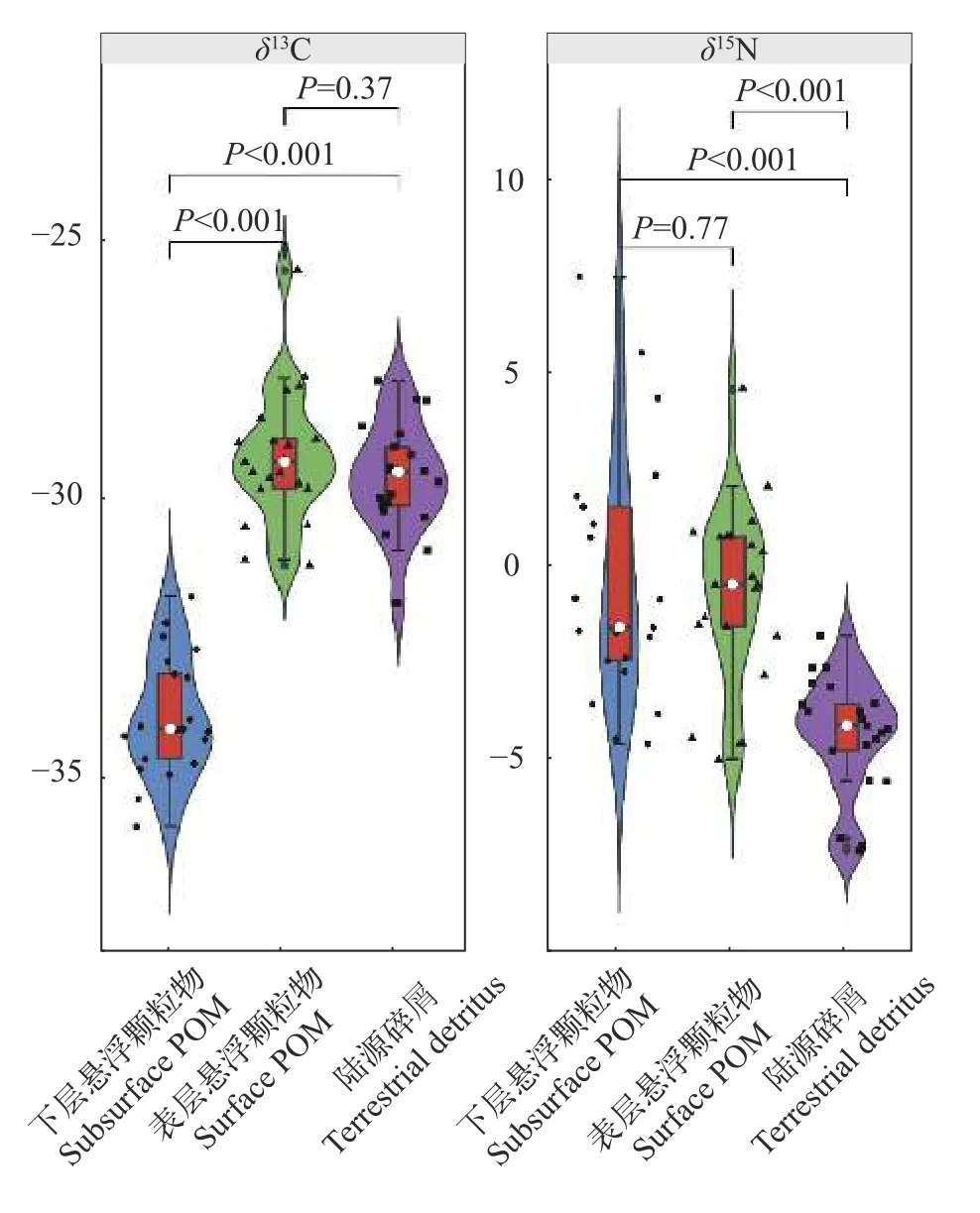
图2 三种潜在食物来源的稳定同位素多元单因素方差分析结果Fig. 2 Multivariate ANOVA of stable isotopes for three potential diet sources
2 同位素空间分析
2.1 营养富集指数
稳定同位素技术在应用时需充分考虑引起稳定同位素在机体内分馏的因素。例如, 稳定氮同位素(δ15N)在相邻两个营养级间所产生的富集因子(Δδ15N)在3‰—5‰, 而δ13C值在相邻营养级间富集因子(Δδ13C)仅为0.4‰—1.0‰[23]。营养富集指数获取方法有两种: 一种是在室内严格控制的条件下,测量实验对象与其单一食物源之间稳定氮同位素的差值; 另一种方法是选用野外生态系统中食源相对简单的生物, 测量其组织与食源间的稳定氮同位素的差值。室内实验控制了实验对象和饵料组成,但在室内条件下生物的代谢活动、消化吸收率和饵料组成等均与其自然生态系统下存在较大差异,很难获取动物在自然状态下真实的营养级富集因子[24]。同时在野外生态系统中, 不同的物种、不同的采样部位和不同栖息环境下稳定同位素的富集都存在差异, 又需要更多的室内试验来得到特定营养级富集因子[24]。
针对这种情况, 许多研究者采用基线营养级富集因子的统计平均值或几个统计平均值并用, 可提供一种最接近富集因子真实状态的近似值[25], 从而更好地估算该种类的食源组成。Caut等[25]于2009年收集了66种期刊290个物种的营养级富集因子, 并按种类、生境和组织进行了分类归纳, 表 2显示鱼类各组织与食物之间的δ13C和δ15N的营养级富集因子的均值和标准误, 在难以获取准确的营养级富集因子的情况下可采用相关数据代替[26]。
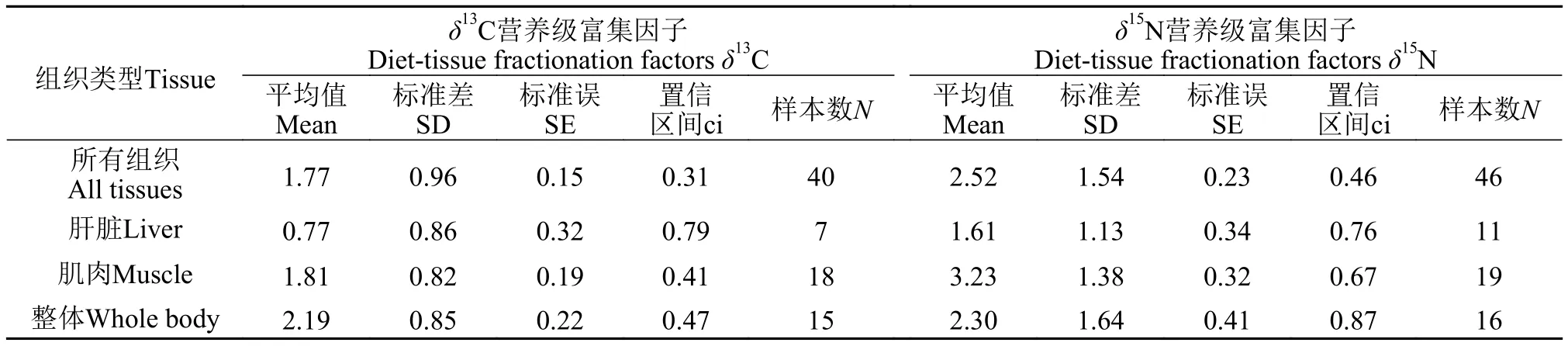
表2 鱼类各组织与其食源之间稳定碳、氮同位素的营养级富集因子Tab. 2 Stable carbon and nitrogen isotopes fractionation factor of birds between the organizations and the food
2.2 同位素空间构建与检验
在运行模型之前, 必须检查消费者稳定性同位素数据是否绝大多数落入潜在营养来源确定的混合多边形中。尽管通过营养富集因子校正后的稳定同位素混合空间(图 3), 可以初步进行判断, 但是由于贝叶斯混合模型的数学性质, 即使这些结果不成立, 也会获得方程的解[5,27]。因此, 必须检查消费者稳定性同位素数据是否绝大多数落入多种营养来源确定的同位素混合空间中[28]。此外, 同位素混合空间中营养来源和消费者同位素之间的共线性,及不同营养来源之间的差异水平等情况, 可会导致统计上多种营养来源贡献的等效解决方案, 也需尽量避免[5,27]。如果没有, 那么必须考虑工作假设中存在一个问题: 在测量过程中出现错误, 或者在分析中忽略了消费者的重要来源。由于贝叶斯建模包含不确定性(本例中为均值和标准偏差), 因此可以使用另一个贝叶斯建模工具来准确确定哪些样本属于混合多边形[28,29]。在进一步模型中, 应舍弃不属于混合多边形的消费者样本。
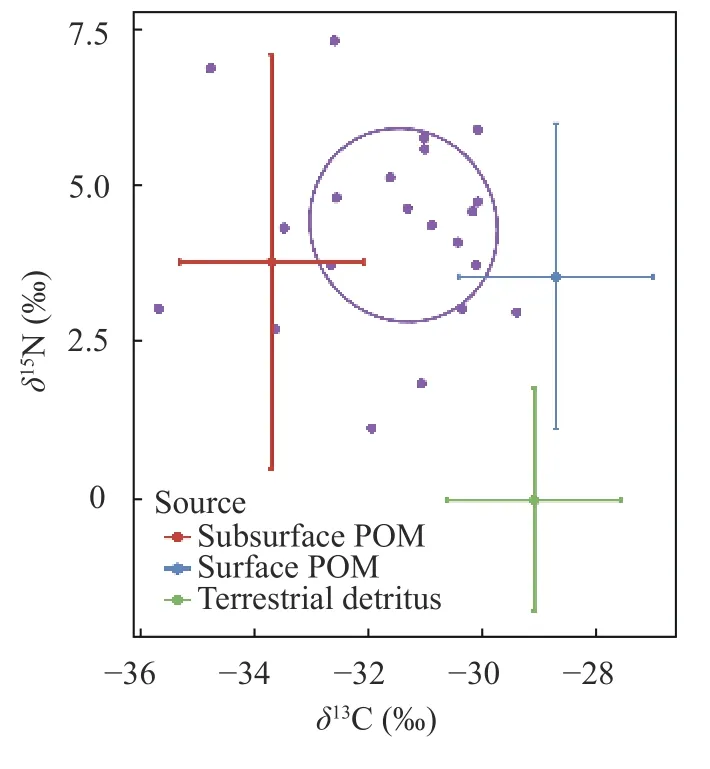
图3 营养富集因子校正后的稳定同位素混合空间Fig. 3 Trophic enrichment factor corrected isospace
以湖泊浮游动物的稳定同位素研究为例, 通TEF校准, 结合多元单因素方差分析, 结果表明三种潜在食物来源表现出一种或一种以上的稳定同位素显著差异(P<0.05), 且共线性特征不显著(图 2),适合进一步分析消费者的食物来源。
由图 4所示(等值线颜色深浅显示了概率轮廓),本研究数据总体质量高。图 4A-C则显示了消费者浮游动物同位素值的变化将如何影响食物来源混合模型可以合理解决的概率[28]。多边形5%概率轮廓以外的浮游动物样品将不再用于混合模型构建,从图 4B中的示例中可以观察到此问题的实例, 其中3个样本(7、19、21号个体)位于指定的潜在源之外, 模型结果证实了这一点(图 4C), 表示样本在多边形内只有5%以下的机会, 因此模型解释程度低,在后续建模分析中予以剔除。图 4D-F则显示了消费者浮游动物同位素值的变化将如何影响营养来源混合模型低估风险的概率[29], 消费者浮游动物样品落入风险区的概率总体低于50%, 未出现高于95%概率的样本。
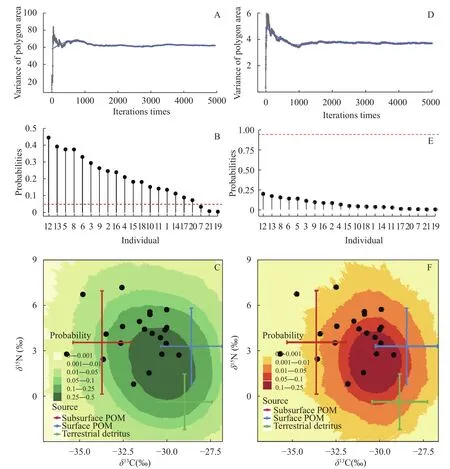
图4 混合多边形迭代模型Fig. 4 Mixing polygon simulation
需要强调的是, 如果在上述统计方法检验过程中, 发现较多的样本不适用于建模, 则必须考虑研究假设中是否存在测量过程的错误、消费者的重要食物来源被忽略或营养富集因子使用不合理等问题[28]。
2.3 源合并
在利用稳定同位素混合模型量化食物来源对消费者的贡献过程中, 一个常见问题是来源过多,模型量化可信度下降。解决这一问题通常有两类方法。一种是通过先验信息, 即对消费者摄食信息或生态系统中食物资源信息, 进行相似分类组合,以便简化科学问题, 控制来源数量, 提高模型量化的可信度, 降低不确定性。合并的基本原则为, 来源聚类的同位素特征没有显著差异, 且来源具有合理的关系, 组合来源具有一定的生态功能意义[30]。另一种方式是, 先使用混合模型获得来源贡献的所有可能量化结果, 根据每个来源的可能的贡献范围,对功能相关的食物来源组合的贡献进行概括, 以此获得对研究问题有益的总体来源量化结果[31]。源合并评估流程如下(图 5), 由于湖泊浮游动物的稳定同位素研究的来源仅为3种, 因此不对源合并进行讨论。
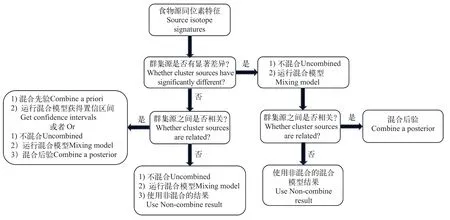
图5 源合并评估流程图Fig. 5 Diagram of Source combination
3 同位素混合模型
3.1 常用模型
利用稳定同位素质量平衡方程计算食物源的相对贡献比例的基本模型构成如下:
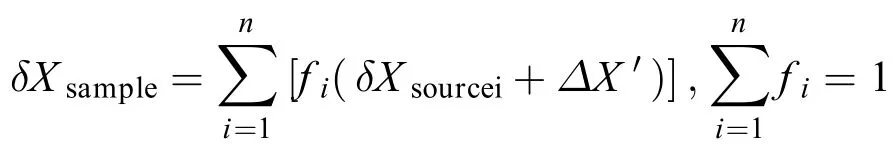
式中,δXsample表示消费者稳定同位素X(如δ13C或δ15N)的相对含量;fi为第i个食源的贡献率;δXsourcei表示第i个食源的稳定同位素X的相对含量;ΔX′为所测定的稳定同位素X在食源与机体之间的营养级富集因子[32,33]。
从公式可知, 测定样本和食源的n种稳定同位素可以确定n+1种食源的贡献率。例如, 将测定的样本和食源的2种稳定同位素值(δ13C和δ15N)代入质量平衡方程可确定3种食源的贡献。此外, 公式中引入了营养级富集因子ΔX, 成为获得食物来源比例的一个重要不确定性因素。
在大多数情况下, 消费者营养来源重建需要面临更多食物源问题, 即n种同位素值和>n+1种食物源, 因此需要更为复杂的模型来计算每种食物源的贡献比例范围[34]。应用较多的一种模型为线形混合模型, 它依据资源贡献范围(0—100%)内, 在各组合不同增量变化下, 在较小可容忍范围内的潜在食物资源贡献的频率和范围[35]。混合模型只对食物来源和消费者使用均值同位素特征, 并不直接考虑食物来源和消费者的变异性, 包括采样和测量误差。
另一类发展较多的模型为贝叶斯混合模型(如MixSIR、SIAR和MixSIAR)。它通过综合先验信息, 整合不确定因素(如多种食物来源、富集因子和同位素比率多变性等), 引入“取样-重要性-再取样(Sampling-importance-resampling, SIR)”的运算法则, 进行食源贡献率的后验概率检验, 提高了数据分析的精度[36,37]。
新的分析方法的出现, 也导致了一些关于哪种方法是最适合应用于稳定同位素数据的争论[38,39]。争论主要集中在哪种分析方法是“正确的”或“错误的”, 但是, 识别不同方法最适合的问题类型或许才是问题的关键。同样, 每种稳定同位素分析方法也具有明显的优点和缺点, 并且每一种方法都适合于特定的情况。
3.2 先验信息
当观测到的数据样本量或代表性有限时, 贝叶斯模型提供了将观测到的数据与其他“先验”信息相结合的能力, 即当有新数据可用时, 会更新先前的估计值。随着当前掌握的信息不断被更新, 形成了科学的“学习周期”。尽管使用胃肠含物来评估营养来源有一定的局限性[40], 但是对摄食关系依然提供了重要的先验信息, 此外还包括环境中食物源的丰度、生物量和消费者的摄食行为习性等, 均可作为重要的先验信息, 以提高混合模型预测的准确性[41]。
但是贝叶斯混合模型有一个特点, 如果先验信息误差较小, 则混合模型的后验结果会反映先验信息的分布趋势和数据离散特点; 如果先验信息误差较大, 则导致混合模型的后验结果存在更多不确定性, 逐渐接近没有先验信息模型的估算结果, 分析的准确性也会下降[30]。因此, 在开展此类研究前,需要投入大量的时间和精力进行数据收集和分析,了解哪些数据满足了前期的假定条件, 这样才能保证分析的准确性。
本研究展示了3个营养来源贡献的先验信息(图 6), 包括默认先验(右侧)和信息先验(左侧), 针对3种营养来源, 包括表层悬浮颗粒物、混合层下悬浮颗粒物和陆源有机碎屑。默认先验的营养来源贡献由均值为零、标准偏差为1的正态分布混合确定。信息先验是基于浮游动物的食性分析数据,3种来源质量比例均值分别为10%、80%和10%, 依据上述方法获得营养来源边际贡献水平较大的分布特征。在进一步建模分析中, 本研究采用信息先验的情景来分析浮游动物数据集。
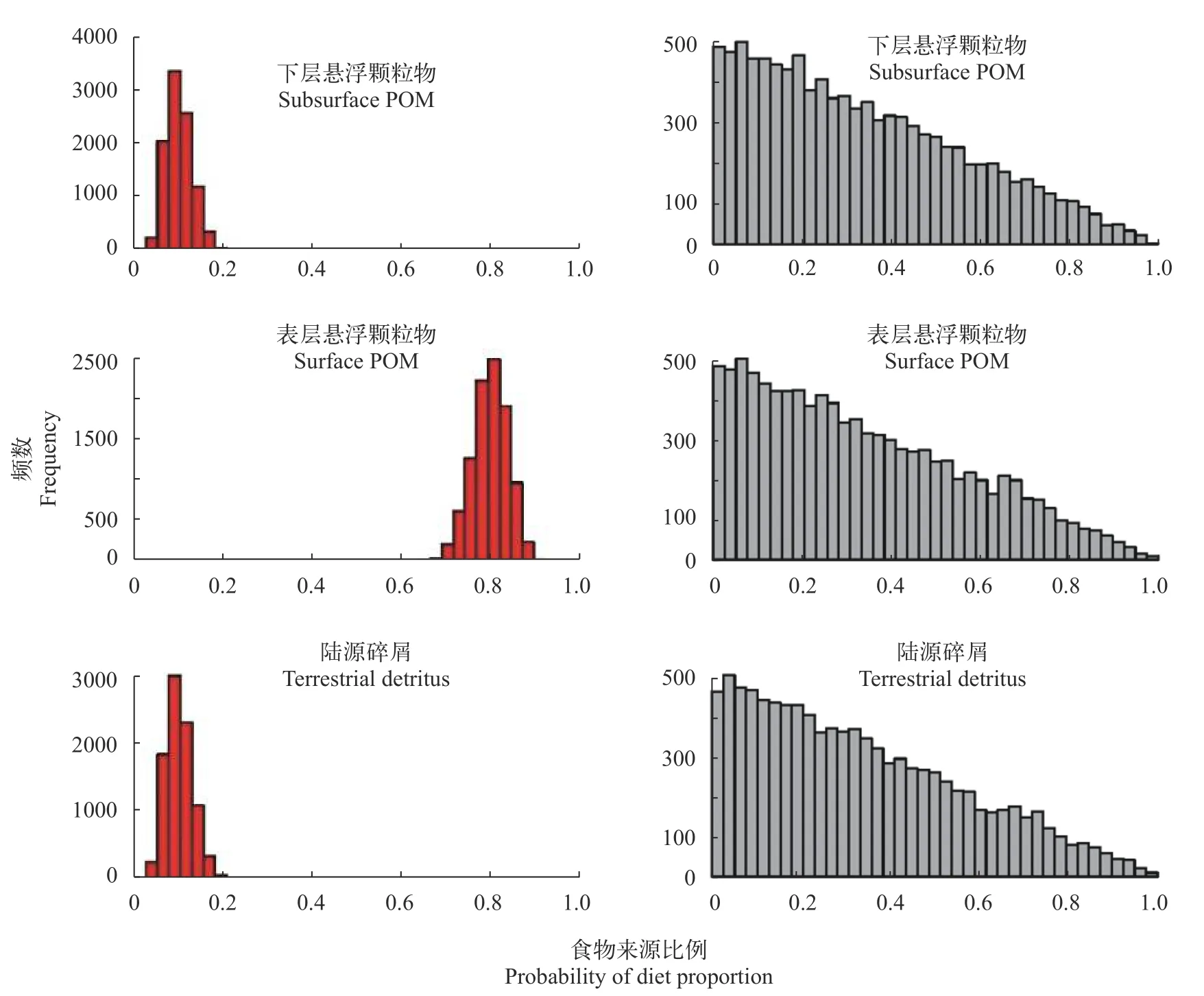
图6 先验信息的不同情景Fig. 6 Priori information of two scenarios
3.3 模型选择
本研究使用R包simmr[42]来拟合所有的同位素贝叶斯混合模型(iter=50000, burn=1000, thin=10,n.chain=4), 并使用JAGS(Just Another Gibbs Sampler)从后验分布中提取样本。通过马氏链(Markov chain,MCMC)轨迹图检验法、Geweke检验法和Gelman检验法等多种方法诊断了马氏链的收敛性, 进一步估计有关参数或者进行其他统计推断。
3.4 后验分布检验与分析
贝叶斯混合模型在输出结果中纳入了食物来源和消费者的变异性, 及采样和测量误差, 其主要的统计数据是消费者营养来源的概率分布(图 7),而不是消费者同位素值的预测。为避免输出单一结果对真值造成误判, 输出结果的报道必须为读者提供消费者营养源的概率分布, 而不是单一的数值(如平均值或中位数), 以包含实验过程中的不确定性。输出结果的可利用性与后验分布的收敛程度相关, 收敛程度越大, 数据分布越集中, 其可信性也越高[36]。此外在某些情况下, 还应该提供后验分布的统计边界, 贝叶斯混合模型可提供95%的置信区间。
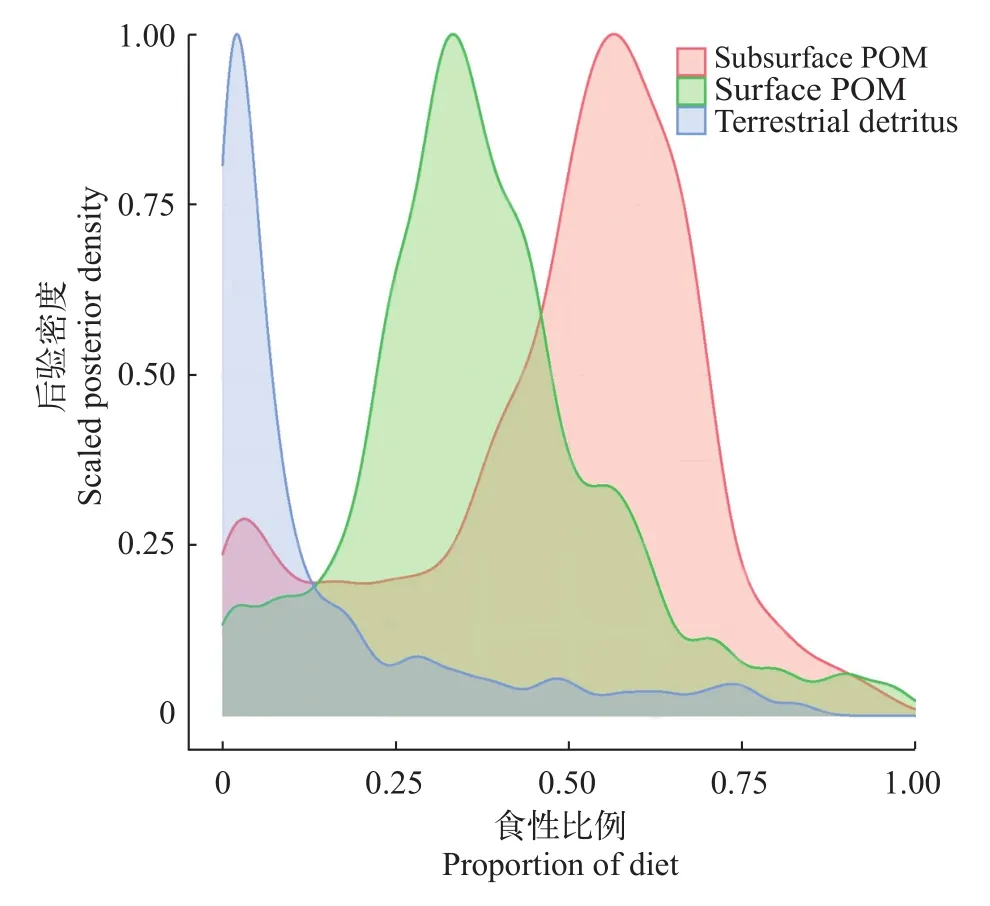
图7 消费者营养来源贡献的后验信息Fig. 7 Posteriori information of consumer
本研究展示了基于贝叶斯混合模型的湖泊浮游动物摄食三种营养来源的后验分布, 结果显示陆源碎屑的贡献率为<5%, 证实了湖泊光热特征作用影响着浮游动物能量来源, 并重新构建了陆源营养对水生消费者的贡献程度。
4 结论
通过以上案例, 本文综述了消费者营养来源重建的过程, 阐明了消费者营养来源重建过程中的诸多技术问题[27]。原始数据的规范化测试与简单的统计检验, 为研究人员提供合理的评估仪器分析的不确定性的途径, 并且能够提高数据质量、剔除异常数据; 同位素空间的分析, 有助于检验数据质量是否符合建模需要; 能够准确反映摄食关系的先验信息以及对后验分布的合理解读, 不仅可以提高混合模型预测的准确性, 更能最大限度溯源消费者的营养来源(图 8)。
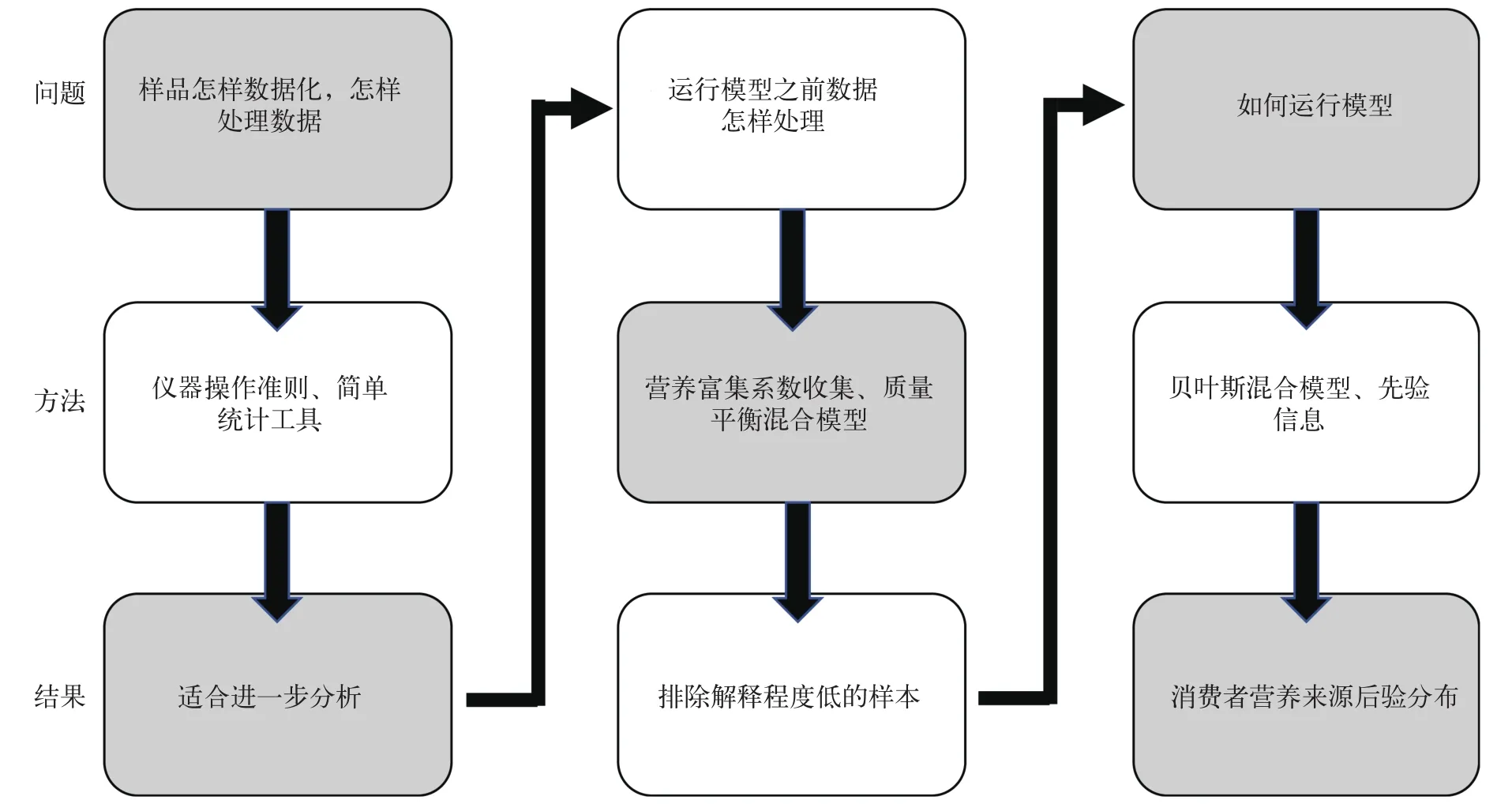
图8 稳定同位素数据分析与营养来源重建流程图Fig. 8 Summary diagram of the logical steps in stable analysis and dietary reconstruction
本文没有涉及在解释同位素数据集中许多相关的其他类型的信息(如营养鉴别因子、同位素选择途径、组织周转率和脂质去除等), 因为其他综述已经对此类问题进行了深入的讨论[7,43—49]。本文的目标是提供方法, 概述目前用于回答有关消费者营养溯源问题的分析方法。无论何种方式的分析方式, 稳定性同位素数据只能间接反映能量和营养物质在食物网中的流动, 并不能直接提供生物之间功能关系的明确信息。营养鉴别因子、食性先验信息和组织周转率等经验数据的获取依然需要大量的野外和室内的实验支撑[7]。此外根据具体研究, 在实践过程中, 评价指标多种多样, 且分别刻画了相对“真实模型”的信息损失。由于真实模型的未知性, 这些评价只能反应现有模型构建过程中相对较好的性能, 具体问题仍需具体分析。
附表1 华东中南部山区纯淡水鱼类名录Attached table 1 The freshwater fishes in central and southern mountainous areas of East China
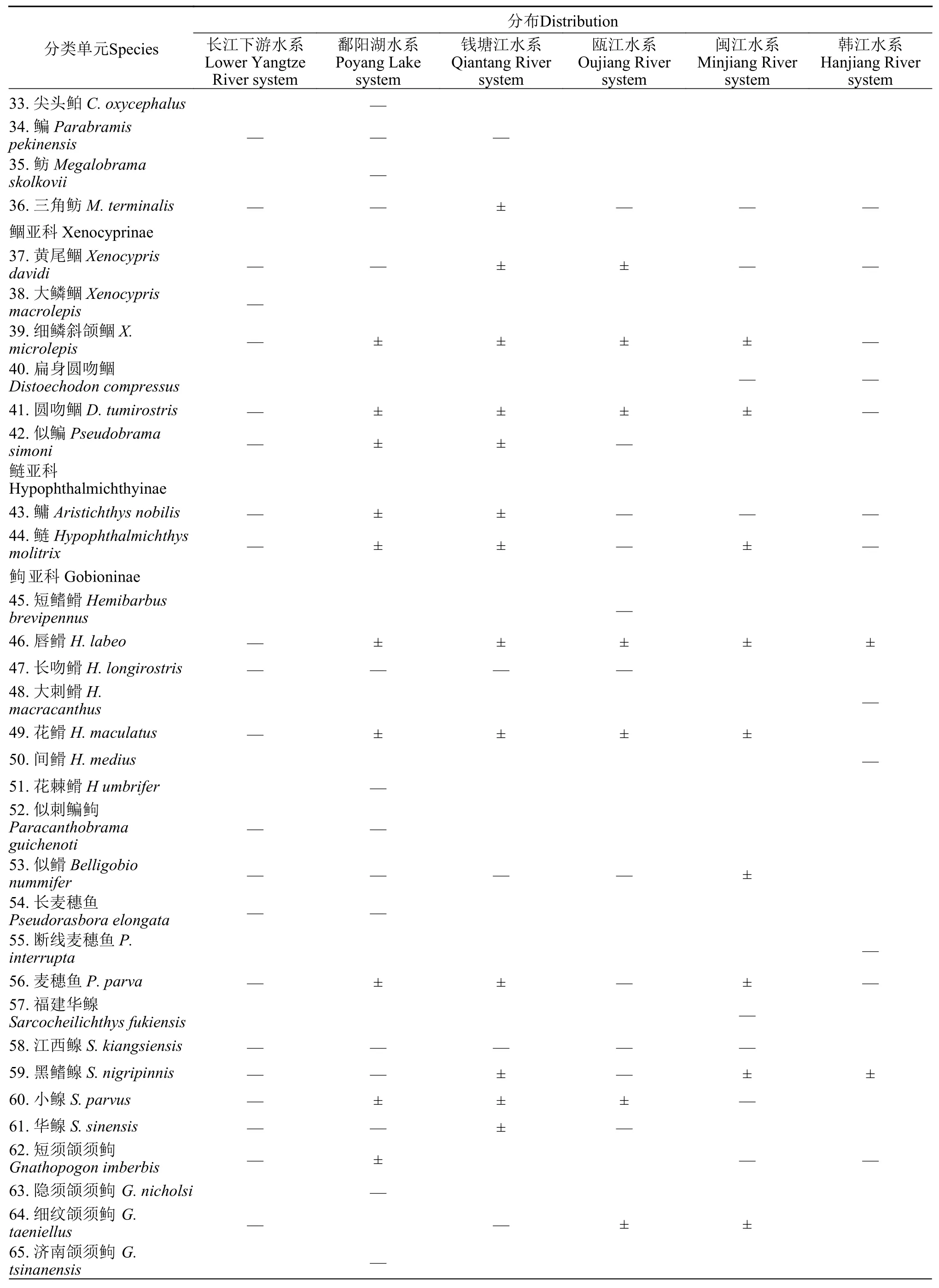
续附表1

续附表1
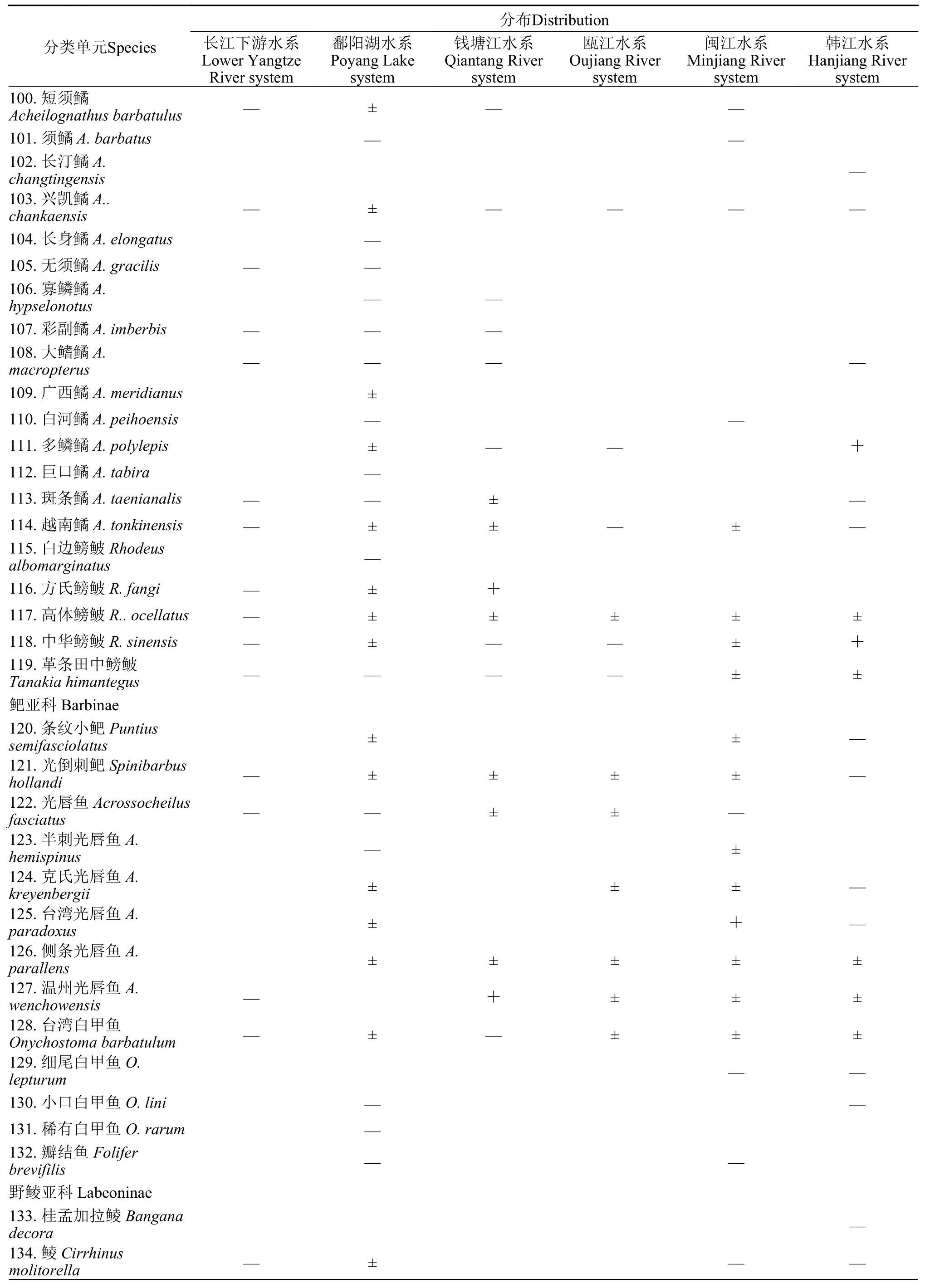
续附表1

续附表1

续附表1
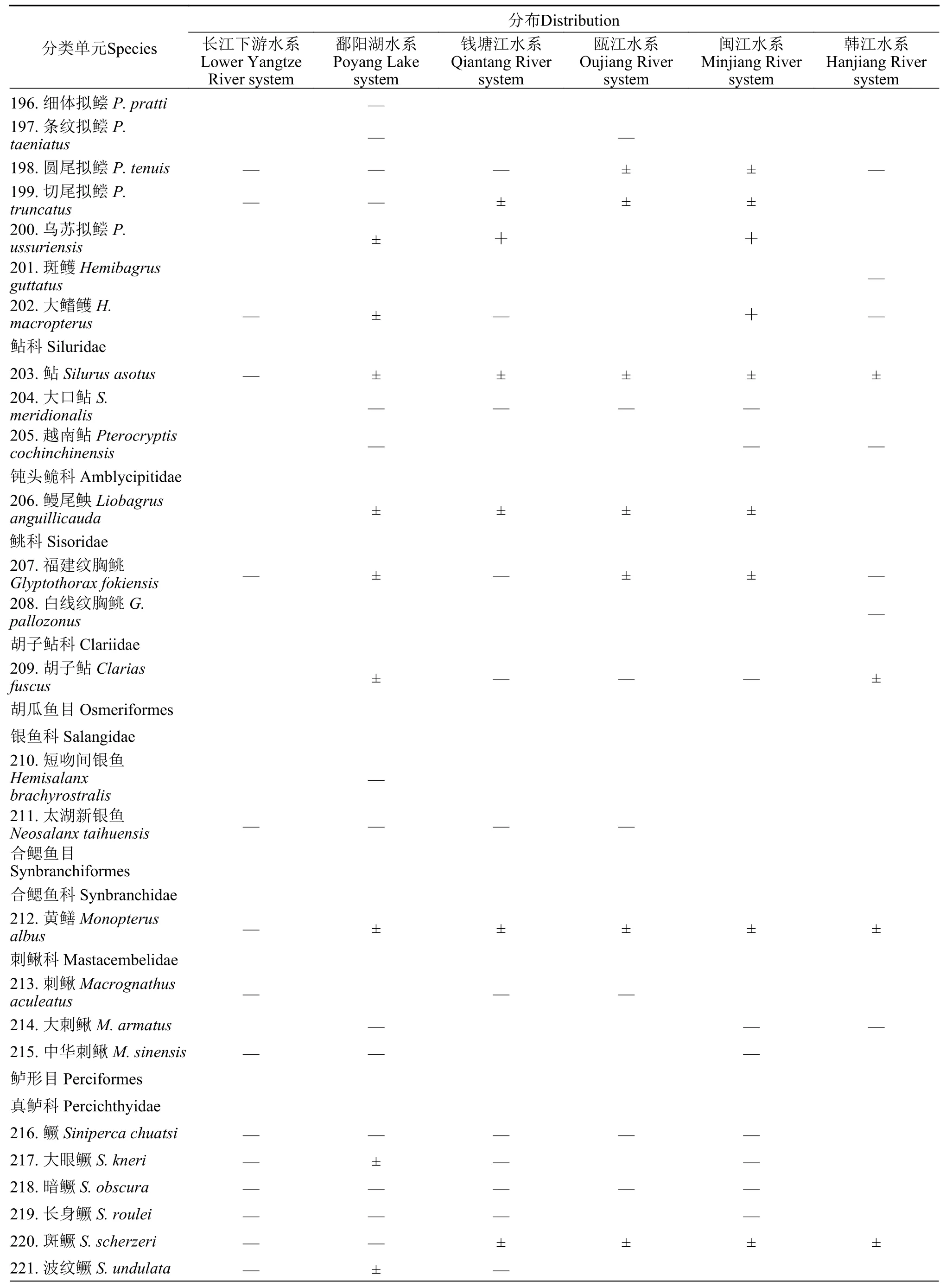
续附表1

续附表1
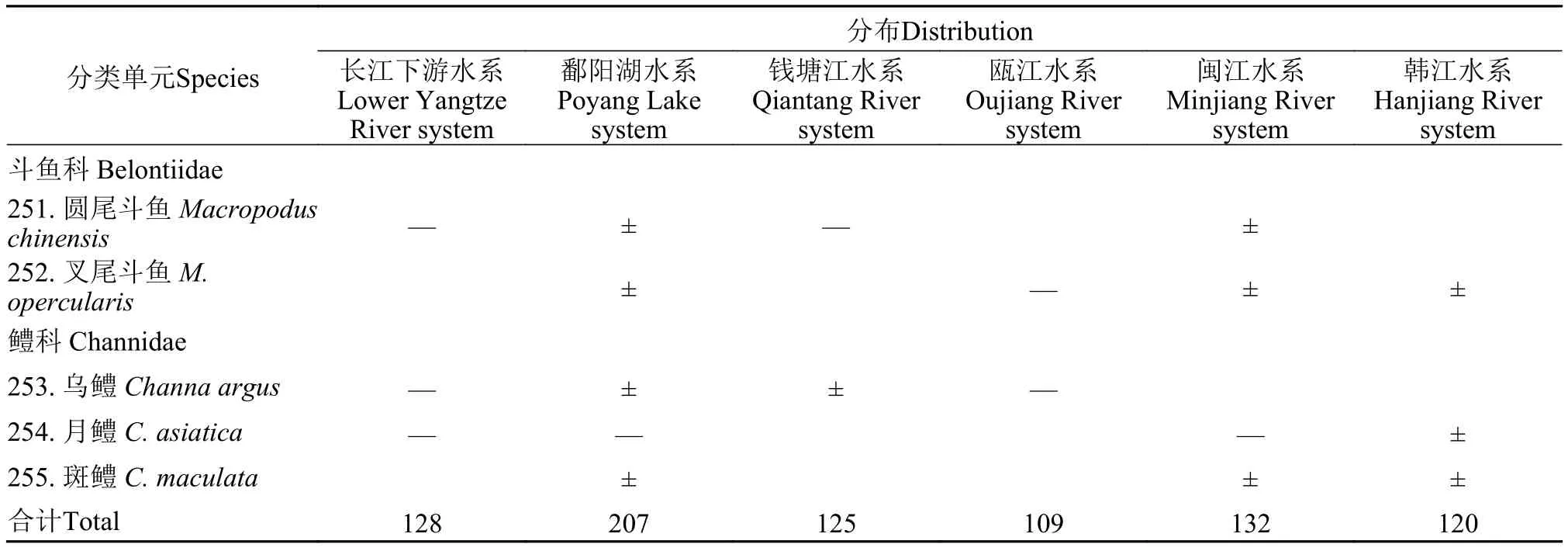
续附表1
