改进RetinaNet的遮挡目标检测算法研究
2022-06-09阳珊,王建,胡莉,刘波,赵皓,3
阳 珊,王 建,胡 莉,刘 波,赵 皓,3
1.西南科技大学 信息工程学院,四川 绵阳 621010
2.深圳市朗驰欣创科技股份有限公司,广东 深圳 518000
3.中国科学技术大学 信息科学技术学院,合肥 230026
目标检测作为计算机视觉中的一项基本任务,以识别给定图片中存在目标的类别和位置为目的,已被广泛应用于各个领域,如人脸检测、行人检测、自动驾驶。近年来,随着深度学习技术的不断发展,基于深层卷积神经网络的目标检测方法层出不穷,主流的算法大致可分为两类:两阶段目标检测器(two-stage)[1-2]和一阶段目标检测器(one-stage)[3-4],前者将目标检测任务分为两步进行,较后者而言,结构更为复杂,计算开销巨大,速度相对较慢,但相应的其检测精度也更高。一阶段目标检测器得益于其高实时性,使其更容易在移动终端部署,故越来越多的学者投身于one-stage目标检测的研究。YOLO[5-6]作为一阶段目标检测器的开山鼻祖,将物体检测看作回归问题,基于单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。随后SSD[7-8]系列算法的提出,进一步提升了一阶段目标检测器的实时性。
不同的网络结构提出,使得分类和回归预测精度不断提升,实时性也在不断提高。事实上,损失函数对模型的学习也至关重要,在Smooth L1之后,为提高回归精度,提出了IoU loss[9]、GIoU[10]以及DIoU[11]一系列损失。但对于重叠目标场景,无论是网络结构还是损失函数,目前的研究都相对较少。目标检测任务中的重叠可分为两类:一种是非目标物体的遮挡,这类遮挡常见的解决方式为通过增加样本数量来提高模型的鲁棒性,另一种是目标间的遮挡,通常需要提高网络模型的辨别能力,对损失函数或网络结构进行针对性改进。
本文针对目标密集场景目标识别率不高,基于固定经验阈值的NMS算法,导致预测框不准确的问题,提出一种改进回归损失函数与动态非极大值抑制的目标检测框架。
1 RetinaNet
RetinaNet[12]作为主流的one-stage目标检测算法,采用ResNet+FPN作为骨干网络提取特征,其网络部分结构与FPN中提到的结构并不完全一致,它使用特征金字塔的P3、P4、P5、P6、P7,其中前3层与FPN中产生方式一样,通过上采样和横向连接拼接产生,P6在特征层P5上再通过了3×3卷积核卷积得到,而P7则是在P6的基础上添加RELU激活函数,然后再通过3×3卷积核卷积得到。FPN上选用的Anchor感受野从32×32到512×512,每层之间的长度为两倍关系。每层金字塔有9个不同长宽比例和尺寸大小的Anchor,可适应不同尺度的目标。分类子网络和回归子网络的参数不共享,但网络结构相似,都是小型FCN网络,利用金字塔层作为输入,连接4个3×3的卷积层,再进行分类和回归预测。分类损失函数是RetinaNet的亮点之一,Focal Loss基于交叉熵损失函数进行改进,减小负样本的权重,提高正样本的权重,旨在解决类别不平衡的问题,取得了不错的检测效果。
2 D-RetinaNet
遮挡对目标检测器存在两个方面影响:第一,非目标物体对目标的遮挡会带来目标信息的缺失,进而导致漏检;而目标之间的相互遮挡,往往会引入大量的干扰信息,导致虚检。第二,重叠使模型对NMS的阈值选取更为敏感,如图1所示,目标周围存在大量其他同类别目标时,其预测框的回归会向其他目标偏移,导致目标的预测框定位不准确,且如果NMS阈值选取过小,周围的预测框将被过滤掉,但该框又是正确的预测,NMS阈值选取过大,会带来更多的虚检。针对以上两个问题,本文基于RetinaNet目标检测框架,从回归定位损失函数和非极大值抑制后处理算法两个方面进行改进,提出D-RetinaNet,利用结合排斥因子Rep的GIoUloss替换SmoothL1回归损失函数,降低候选边框向邻近真值偏移概率。并在回归子网络最后一层添加一个同步的density预测Head,并将预测值作为NMS方法的动态阈值,可有效缓解目标之间的相互遮挡导致模型学习不准确的问题。

图1 遮挡示意图Fig.1 Sketch of occluded target
2.1 损失函数改进
RetinaNet原文采用Smooth L1回归损失函数,虽取得了不错的效果,但Smooth L1将边界框的四个坐标值独立地进行损失计算,并简单相加,忽视了坐标值之间的关联性。并且实际评价框的指标是计算预测框与真值框的IoU,具有相同大小Smooth L1(x)损失的多个检测框,IoU差异可能很大,如图2。而IoU Loss可以较好地改善这一点,但它也存在其他缺点,比如预测框和目标框相离时IoU损失值为0,无法对预测框进行优化。此外,两框相交面积相等时,损失值相同,无法判断预测框和目标框的相交情况。因此无法准确衡量定位信息,可能降低模型的检测性能。
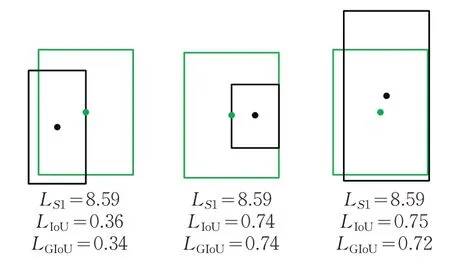
图2 损失值对比图Fig.2 Diagram of comparative analysis of loss
针对上述问题,使模型更能适应Anchor Box比例分布不均的情况,采用GIoU损失作为边界框回归预测的损失函数,GIoU计算示意图见图3,计算式如式(1)、(2):
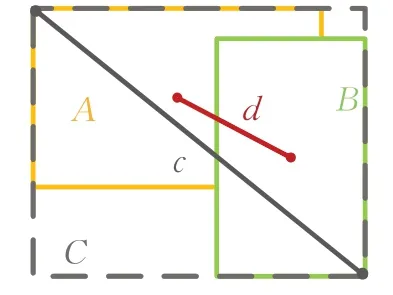
图3 GIoU示意图Fig.3 Sketch map of GIoU
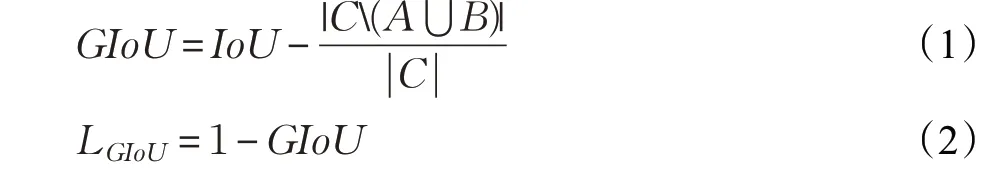
A、B分别代表两个锚框和目标框,C代表可同时覆盖A、B的最小矩形。通过计算C中没有覆盖A和B的面积占整个C总面积的比值,再用A与B的IoU减去这个比值,得到GIOU。
同时为提高模型对遮挡物体的检测性能,在GIoU Loss基础上加入一项排斥因子[13],用于增大预测框与周围其他目标框间的距离,防止预测框向其他目标框回归。排斥因子定义如式(3)~(6),这里预测框和其他目标框的度量距离不使用IoU,避免预测框足够大时,导致损失值下降。

2.2 密度估计分支
针对后处理算法NMS的过滤阈值单一,难以适应样本多变的场景,在回归分支最后一层增加一个密度预测分支,用于预测目标间的遮挡程度[14],将预测的密度值应用到NMS中,提高它的辨别能力,使其可自适应复杂多变的场景,减少假阳性和漏检,提高检测精度[15]。该分支的结构简单,与回归分支共享网络参数,仅在回归子网络最后一层添加一个同步的density预测Head,由3×3卷积核和sigmoid激活层构成,几乎不增加网络的参数量,能保证模型训练速度,网络结构如图4所示。
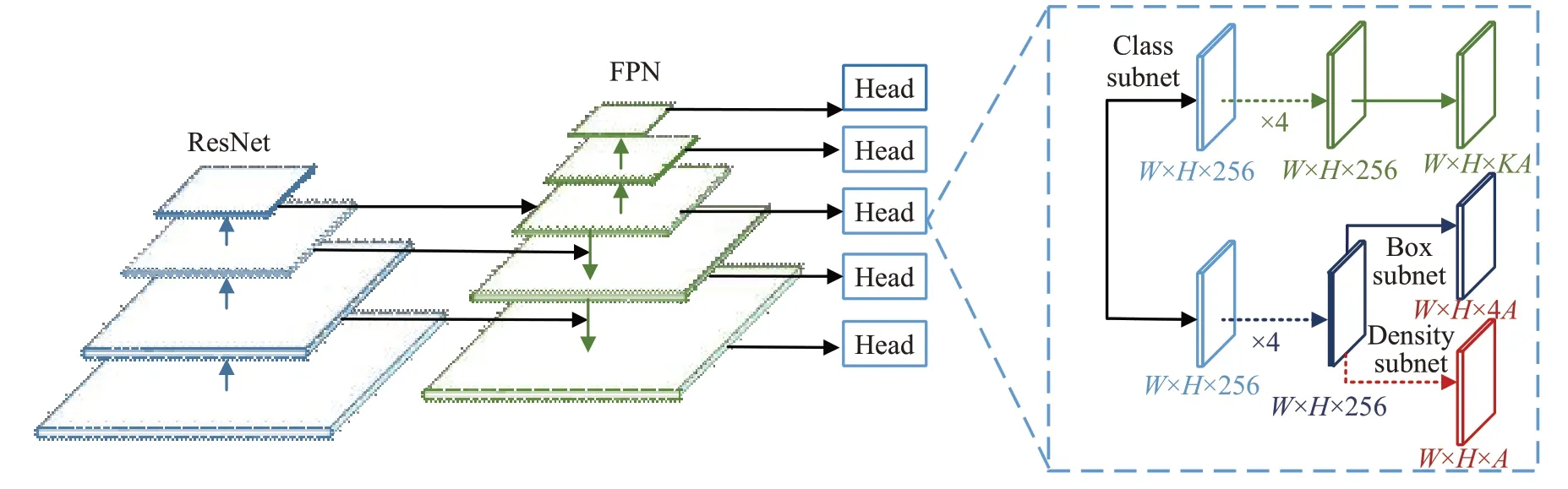
图4 网络结构图Fig.4 Schematic diagram of network structure
对每个位置预测密度,通过计算与目标框G与周围其他目标框的IoU,取最大的IoU值对预测值进行监督,式(8)为NMS算法阈值计算方式。密度估计损失函数选用简单的smoothl1损失,如式(9),将其看作回归任务进行学习。
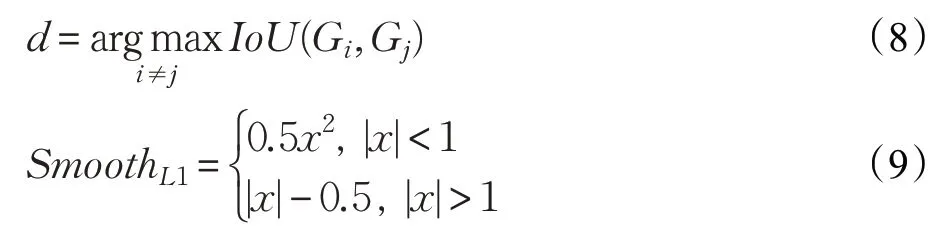
图5为使用密度d作为非极大值抑制的筛选阈值和传统算法阈值的对比,可以看出D-NMS随着迭代次数变化不断调整阈值,而传统NMS阈值始终保持不变。输入图片各个位置的目标重叠程度不同,不断调整的阈值显然更能适应场景的多变。
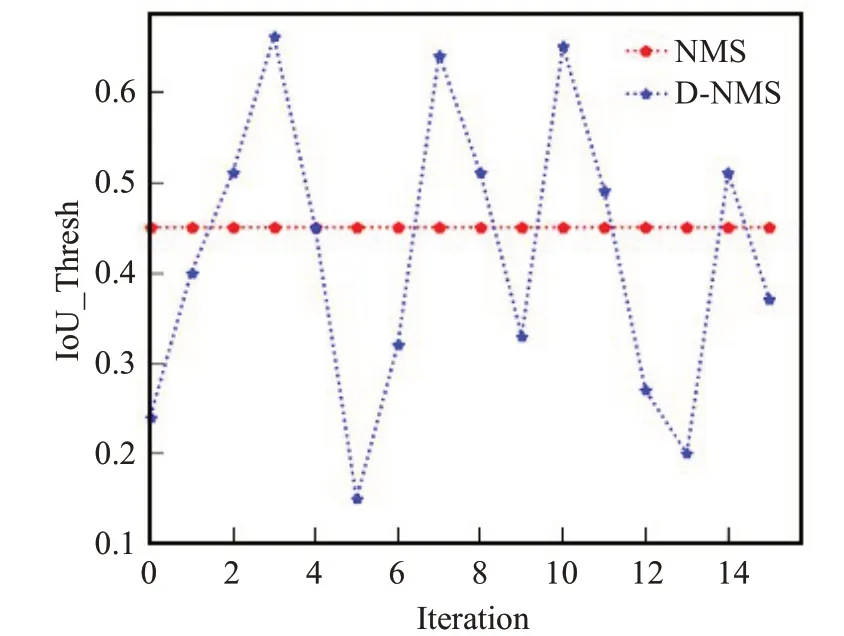
图5 不同NMS方法阈值变化图Fig.5 Threshold changes of different NMS methods
3 实验
3.1 数据集
本实验在PASCAL VOC和自制建筑垃圾数据集上进行训练和测试。PASCAL采用VOC07+12(train+val)训练进行,测试集采用VOC07 test。自制数据集利用Intel Real Sense采集到130张原始图片,通过翻转、添加噪声、Mixup和Random Erase的方式对原始图像进行增广,最后得到847张图片,增广后的图片如图6所示。

图6 数据集增广效果图Fig.6 Data augumention
并参照VOC的标注格式,利用LabelImg标注软件进行标签标记,数据集划分为训练集542张,验证集135张和测试集170张。由于建筑垃圾部分类别差距十分小,拆卸后的砖块颜色和形状与木材非常相似,容易混淆。将其分为3个类别,包括Plastic、Wood、Concrete。建筑垃圾存在大量长条状的木材和塑料等,导致模型对垃圾的定位效果不高,故数据处理时,利用K-means方法对数据集中的先验框聚类[16],分别得到三组长宽比和缩放比用于生成Anchor box。
3.2 评估标准
本文采用mAP(mean average precision)评估网络模型检测性能,计算公式如下:
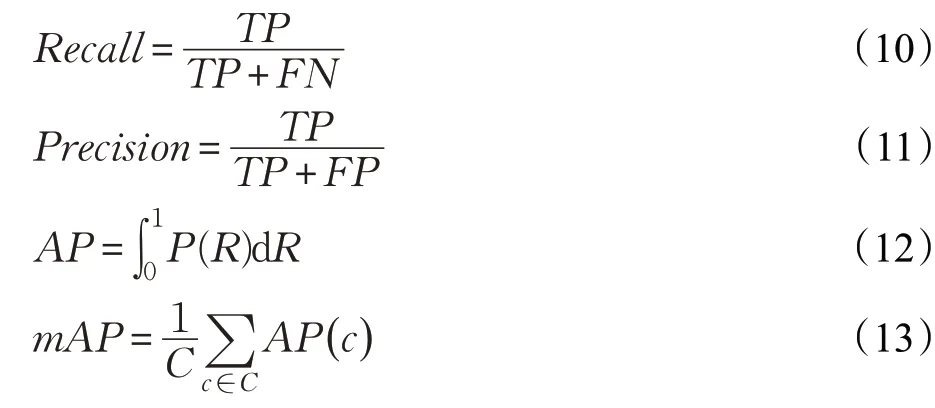
其中,C表示数据集类别数,c表示某一类别,Recall表示召回率,表示样本中的正样本有多少被预测正确了,Precision为精确度,表示预测为正的样本中有多少是真正的正样本。TP则为正样本被分为正的数量,FN为把正样本错误地预测为负的数量,FP表示把负样本错误地预测为正的数量。故TP+FN为全部正样本数量,TP+FP为全部被分为正样本的数量。
TP和FP根据IoU(intersetion over union)阈值定义,TP为与真值框IoU大于该阈值的预测,反之则为FP。IoU计算公式如下:

3.3 对比实验
对比表1分析可知,替换损失函数为Rep-GIoU Loss,利用预测的密度引导NMS后,在PASCAL VOC上本文算法平均准确率可达到82.9%,比RetinaNet提高1.3个百分点,且检测速度几乎不变。对比SSD和YOLOv3,检测精度分别提高6.1个百分点和4.2个百分点。FCOS作为Anchor-free目标检测方法可达到79.1%准确率,高性能目标检测器EfficientDet[17]准确率为78.9%,都低于本文提出方法准确率。
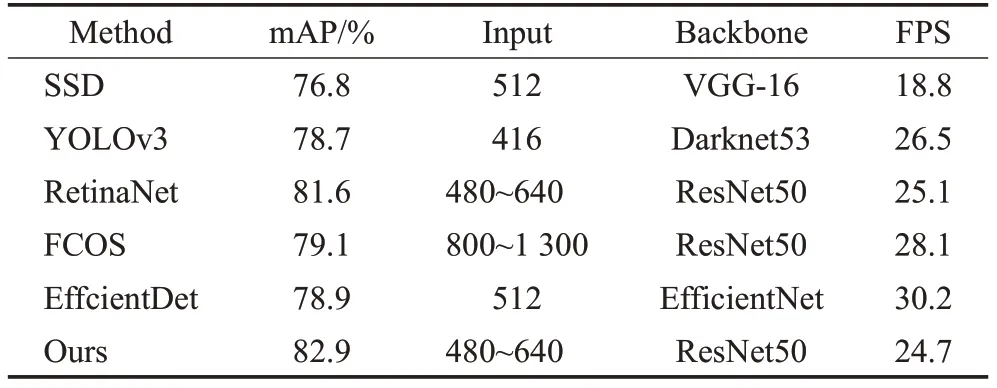
表1 不同目标检测算法对比Table 1 Comparison of different target detection algorithms
对比分析表2可以看出,改进后的D-RetinaNet各类别目标检测精度都有提升,包括部分小目标类别(如bird、Aeroplane)。表3对大中小目标检测效果进行对比,PASCAL VOC数据集中较多的类别不存在小目标,中、大目标占比更大,可以看出各尺度目标检测精度都有提升,改进后的小目标mAP提高了0.8个百分点。
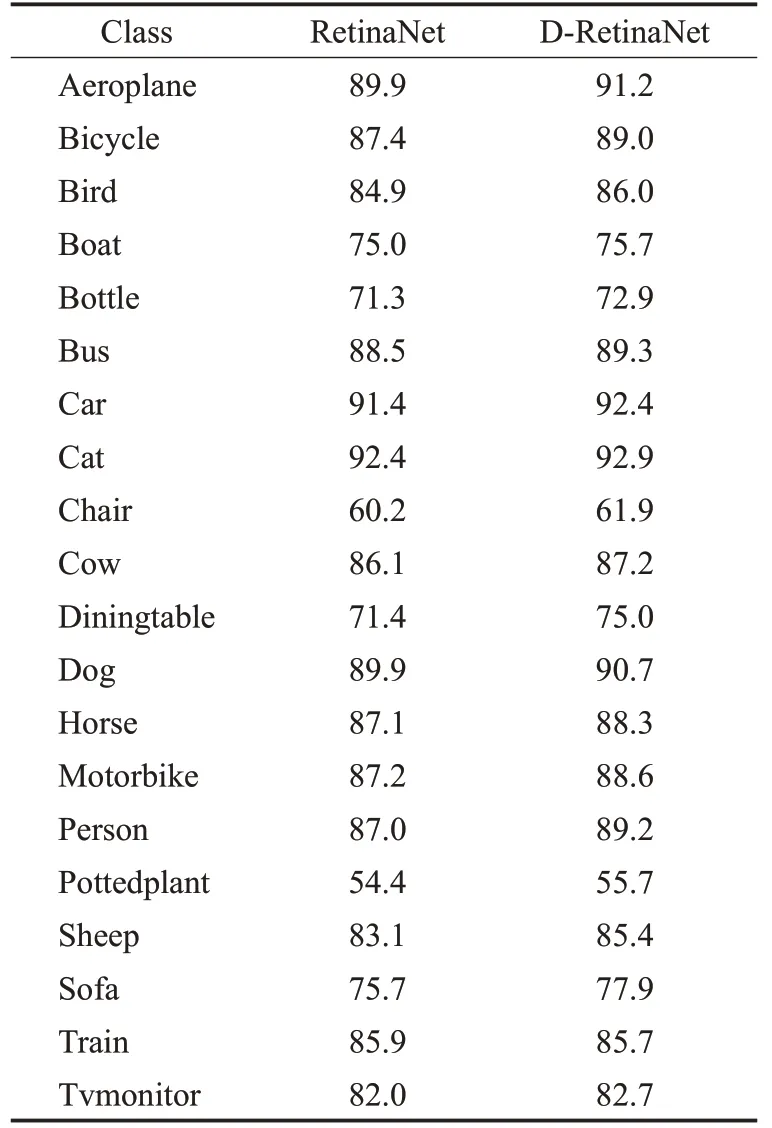
表2 各个类别的AP对比Table 2 AP for each category %

表3 不同尺度目标检测精度对比Table 3 Comparison of different scale objects %
对比分析表4可得,相比传统的NMS算法,本文提出的Density-NMS提高了1.3个百分点,可达到与Soft-NMS[18]相当的准确率。但Soft-NMS牺牲了边界框的高置信度,在保留更多真阳性预测框的同时也保留了更多的假阳性预测框。总体来看,本文算法的综合性能是最优的。
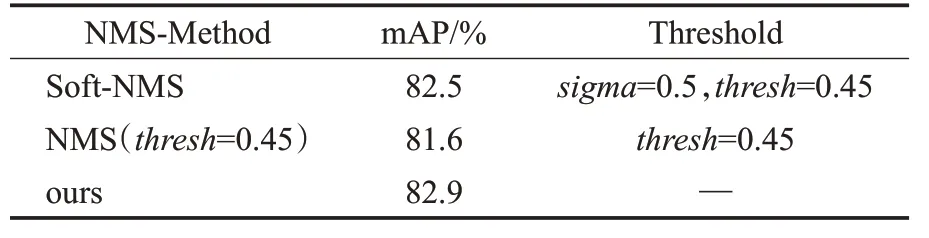
表4 不同NMS算法对比Table 4 Comparison of different NMS algorithms
同时,本文在自制建筑垃圾数据集上对比了Retina-Net和改进后算法,检测结果如表5。RetinaNet模型可达到92.3%的准确率,而改进后的D-RetinaNet可达到95.1%,提高了2.8个百分点。

表5 自制数据集效果对比Table 5 Comparison of self-made data sets
3.4 消融实验
表6对每个模块的贡献进行了分析,可以看出改进后的GIoU损失的引入,将模型的平均准确率提高了2.5个百分点,将模型的平均准确率提高了2.5个百分点,同时Density_NMS的加入也进一步提高了检测准确率,最终可达到95.1%准确率。检测效果如图7所示。由检测图可以看出,被遮挡目标的检测效果有所提高,且对小目标的识别效果也不错。

图7 检测结果对比图Fig.7 Comparison of detect results

表6 各模块贡献Table 6 Contribution of each module
3.5 实验配置
全部实验运行环境为Ubuntu系统,显存为24 GB,GPU为NVIDIA GeForce GTX TiTan X,利用CUDA10.1和CUDNNv7.6.5,加快GPU运算,编译器为Pycharm。
在模型训练中,Smooth Ln(x)中的常参数σ设置为0.5,类别置信度阈值为0.3,损失函数中α设置为0.5,训练效果最好。IoU人工设定阈值为0.45,初始学习率为0.01,权重衰减为0.005,预防数据过拟合。选择SGD优化器优化模型,Batch_size为12,损失最小为0.18和0.22。
4 结语
本文提出D-RetinaNet检测算法,在保证了检测速度几乎不变的同时,提高了RetinaNet算法对遮挡目标的检测性能。基于GIoU loss添加排斥因子Rep,加强网络模型对遮挡目标的学习,提高了模型的识别能力。Density预测模块的构建不仅提高了后处理算法NMS的辨别能力,提高检测器的检测性能,使更多的准确预测框得以保留。同时可辅助回归分支更好地完成回归任务。实验结果表明,D-RetinaNet在PASCAL VOC和自制数据集上的平均精度较RetinaNet分别提高了1.3个百分点和2.8个百分点。其中遮挡目标的精度提升更为显著,验证了改进GIoU loss和密度预测模块的有效性。目前损失函数更倾向于回归得到一个相对较大的检测框,将来会针对该问题进一步研究,获得更加贴合的预测框。
