人群计数研究综述
2022-06-09卢振坤刘绍航
卢振坤,刘 胜,钟 乐,刘绍航,张 甜
广西民族大学 电子信息学院,南宁 530000
随着人口增长,许多场景下人群数量过大容易发生事故。著名的上海外滩踩踏事件后果惨重,最终造成36人死亡、49人受伤。另外演唱会、体育馆、火车站、地铁站等地方人口流量较大,需运用人群计数系统实时检测人群的数量和分布,控制人口流动,避免出现意外。人群计数领域在公共安防、智慧城市建设和视频监控上应用广泛,因此,研究这一领域具有重要的现实意义。
过去,研究人员采用基于检测、回归等传统方法估计人群数量。基于整体检测的方法用哈尔小波[1]、方向梯度直方图(histogram of oriented gradient,HOG)[2]、Shapelet[3]训练器,用支持向量机(support vector machine,SVM)[4]、提高算法[5-6]、随机森林、集群[7]等算法来完成人群计数任务的检测或分类。基于回归的方法通过特征提取和回归建模展开,特征提取包括前景提取、像素统计[8]、纹理提取[9]、边缘提取等,提取特征后用不同的回归算法计数,这两种方法在稀疏场景下效果良好,但是不适用高密度场景。相比传统方法,基于卷积神经网络的计数方法分为直接回归法[10]和密度图法。CNN拥有强大的网络,输出密度图后用损失函数来提高精度,用优化器来减少计算复杂度,在处理跨场景、多尺度、部分遮挡等问题时,展现出独特的优势。根据常见的网络模型,可以分为尺度感知计数模型、上下文感知计数模型、多任务计数模型、注意力感知计数模型等类型,本文将重点分析这几种计数模型。TransCrowd采用ViT来研究人群计数任务,试图用其他方法代替CNN,相比基于CNN的弱监督人群计数方法提高了网络性能,这次尝试在人群计数领域具有非凡的意义。
本文查阅了相关文献,论述了人群计数领域的研究进展,对基于传统方法、基于CNN方法和新提出的基于ViT方法的人群计数进行了综述,提出当前研究方向上亟待解决的问题。
本文贡献如下:(1)梳理了人群计数领域的传统方法、基于CNN的方法和基于ViT的方法,对比不同方法的优劣,总结了当前方法的特点和研究现状,阐述了人群计数的发展进程。(2)介绍了常用数据集,系统性回顾了计数网络的发展历程,比较模型在常用数据集上的评价指标,指明研究人员下一步改进方向。(3)首次在综述中引入基于ViT的弱监督人群计数方法,为未来该领域研究提供一个新思路。
1 基于传统方法的人群计数
1.1 基于检测的方法
早期人群计数方法大多是基于检测,用特定的检测器提取特征来实现计数目标。特征提取方法可分为基于整体的和基于局部两种。基于整体的检测方法适用于低密度人群,在高密度人群中效果不理想。为了解决这个问题,研究者提出基于局部的提取特征方法[11-13],其目的不是检测一个完整的行人对象,而是检测行人的部位。研究发现,在大多数密集人群场景中,使用局部特征比使用全局特征可以大大提高计数性能。许多研究工作[14-17]是基于局部特征的,近来Laradji等人[18]和Liu等人[19]继续致力于基于检测的方法。前者不需要估计目标的大小和形状,而是提出了一种新的损失函数,建议网络仅使用点级注释输出每个目标实例的单个属性。后者避免了昂贵成本的边界框,仅使用点的监督信息来训练模型。与基于整体特征的检测相比,部分局部检测的鲁棒性更好,但在高密度场景中同样收效甚微。基于检测的计数方法在稀疏场景中有着出色的检测精度,虽然为了适应高密度、复杂的场景做了许多尝试,但是效果仍然有待提高。
1.2 基于回归的方法
基于检测的方法在极端密集的人群和高背景杂波的情况下并不成功,为了克服这个问题,研究人员试图通过回归来计数,从中学习从局部图像斑块中提取的特征与它们的计数之间的映射[20-22],避免了对检测器的依赖。基于回归模型方法的主要思想是先从图像中提取前景区域,提取多个特征,然后选择合适的回归模型进行训练,最后从测试样本中预测人口密度。过程如图1所示。当全局和局部特征被提取出来,不同的回归技术,如线性回归[23]、分段线性回归[24]、岭回归[25]、高斯过程回归和神经网络[26]用来学习从低级特征到人群数量的映射。与基于检测的方法类似,回归方法也可以分为基于整体[27-29]和基于块[30-33]两类。基于整体的回归方法难以处理大尺度和密度变化,而基于块的回归方法包含更多图像的局部信息,受尺度和密度变化的影响较小。通过回归技术来实现可以有效地解决个体遮挡和特征跟踪的问题,使用人群的整体描述来估计人群密度。相比于基于检测的方法受到了高密度场景的限制,基于回归的方法不需要明确的界限和个体的跟踪,能够较有效地估计更复杂场景的人群密度,但是计算过程也相对复杂。
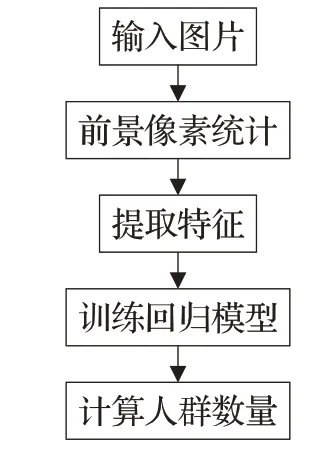
图1 基于回归模型的人群计数过程Fig.1 Flow chart of pixel statistical algorithm
1.3 基于密度图的方法
虽然早期的方法能较好解决遮挡和杂波问题,但大多数方法忽略了重要的空间信息,因为它们是对全局计数的回归。随着研究的深入,Lempitsky和Zisserman[34]提出的密度图概念引起了研究者的广泛关注。Lempitsky等人提出了一种估计图像密度的新方法,将局部像素特征学习线性映射到对应的目标密度图。该方法可用于训练一个回归模型,模型在学习过程中基于图像的像素点提取特征,直接学习从像素点特征到目标密度分布图的映射关系。它的目标为生成这样的密度图,不仅包含了密度信息还附带了图像中目标空间分布信息,同时该密度图中任意区域的积分给出了该区域对象的数量,所以还可以通过区域密度求和得到任意区域的目标数目。通过学习图像到密度图的映射,避免了对检测器的依赖。Rodriguez等人[35]证实使用密度图计数可以极大地提高计数性能。由于密度图既能反映人群的空间分布信息,又能提高计数精度,基于密度图的回归逐渐成为一种流行的分类。
传统的人群计数方法依赖于多源和手工制作的表示,只适用于稀疏场景,在部分遮挡、前景透视、多尺度和跨场景等情况下,效果不尽人意。CNN在各种计算机视觉任务中的成功应用,使得许多基于CNN的方法被用来解决人群计数问题。
2 基于卷积神经网络的人群计数
2.1 尺度感知计数网络
2.1.1 单分支结构
Wang等人[36]和Fu等人[37]最早在人群计数领域中使用CNN,Wang等人提出了一个端到端的CNN回归模型直接预测人群数量,能从极度密集人群的图像中统计人数。架构中采用了AlexNet网络[38],其完全连接层被用于预测计数的单个神经元层取代。此外,为了减少图像不相关背景的错误响应,训练数据增加了附加的样本,其真实数值设为零。AlexNet网络不适用于跨场景计数,因此准确度不高。
为了克服跨场景的难题,Zhang等人[39]整理了现有方法,改进了AlexNet网络提出的单分支计数模型CrowdCNN,最先应用人群密度图。如图2(a)所示,通过交替训练两个目标函数:人群计数和密度估计,对这些目标函数进行交替优化,可以获得更好的局部最优解。如图2(b)所示,为了使该网络适应新场景,达到跨场景计数的目的,使用与目标场景相似的训练样本对网络进行微调。图2(b)提出了一种结合透视信息生成真实密度图的方法,使网络能够执行透视归一化,从而提高比例和透视变化的鲁棒性。此外,他们引入了一个新的数据集WorldExpo’10,用于评估跨场景人群计数。
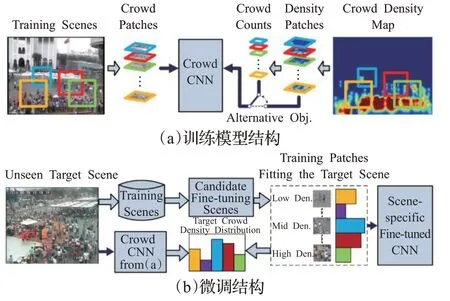
图2 CrowdCNN计数网络Fig.2 Architecture of CrowdCNN
2.1.2 多分支结构
目标遭受严重遮挡时,透视问题导致拍摄角度差异大,目标尺度变化不均匀。一般情况下,靠近摄像机的人群有完整的细节信息,远离摄像机的人群细节信息缺失。此外,手工制作的图像特征(scale-invariant feature transform,SIFT[40])通常在遮挡和大尺度变化情况下鲁棒性较差。
为了解决多尺度的问题,Boominathan等人[41]把一个深层网络和一个浅层网络相结合,提出双分支结构计数模型CrowdNet。但是当目标尺度很小时,深层网络结构很难提取目标特征。受到Boominathan等人的启发,有人提出改进VGG16模型[42]作为双分支结构,把VGG前10层作为主干网络,如图3所示。为了解决尺度变换的问题,用浅层网络(Branch_S,BS)提取低级语义信息,深层网络(Branch_D,BD)提取高级语义信息。并使用1×1卷积层对提取的特征图进行处理。以获得最终的人群密度预测。通过引入多分支网络,用不同尺寸的卷积核提取不同尺度的特征,可以有效解决多尺度问题。
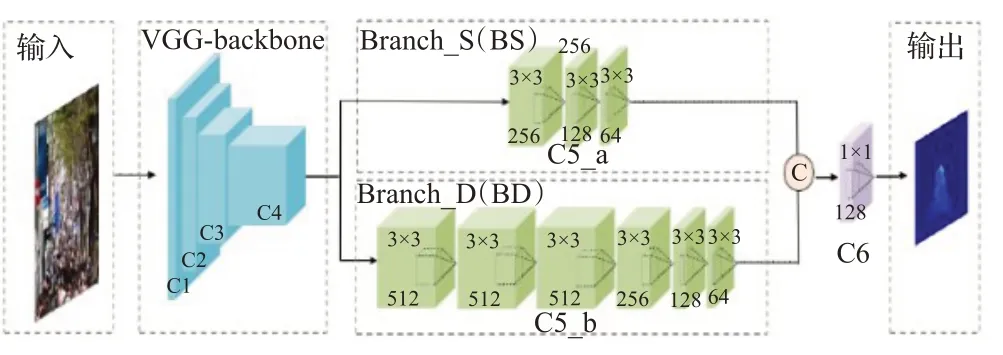
图3 基于VGG主干的双分支网络Fig.3 Double branch network based on VGG backbone
人群计数领域不断创新,逐渐衍生许多基于CNN的多分支网络模型,适用于稀疏、密集场景。由于图像中人群密度分布极不均匀,研究人员利用多列卷积神经网络来提取不同尺度的头部特征。通过多分支网络,使用不同尺寸的感受野提取不同尺度特征,可有效解决多尺度问题。
Zhang等人[43]为了解决多尺度问题,在2016年提出多列卷积神经网络(multi-column CNN,MCNN),其网络结构如图4所示。MCNN允许输入图像有任意大小的分辨率,利用具有不同大小感受野的滤波器提取特征,舍弃固定高斯核,采用自适应高斯核来生成高质量密度图,减少视角变化引起的目标大小不一致导致的计数误差。MCNN每列所学习的特征,能够适应由于透视效果或图像分辨率[44]形成的目标尺寸变化。MCNN模型通过1×1卷积层加权平均[45]融合CNN多列的特征图来预测人群的密度图。MCNN还引入了新的数据集ShanghaiTech,该数据集已成为人群计数领域的经典数据集之一。
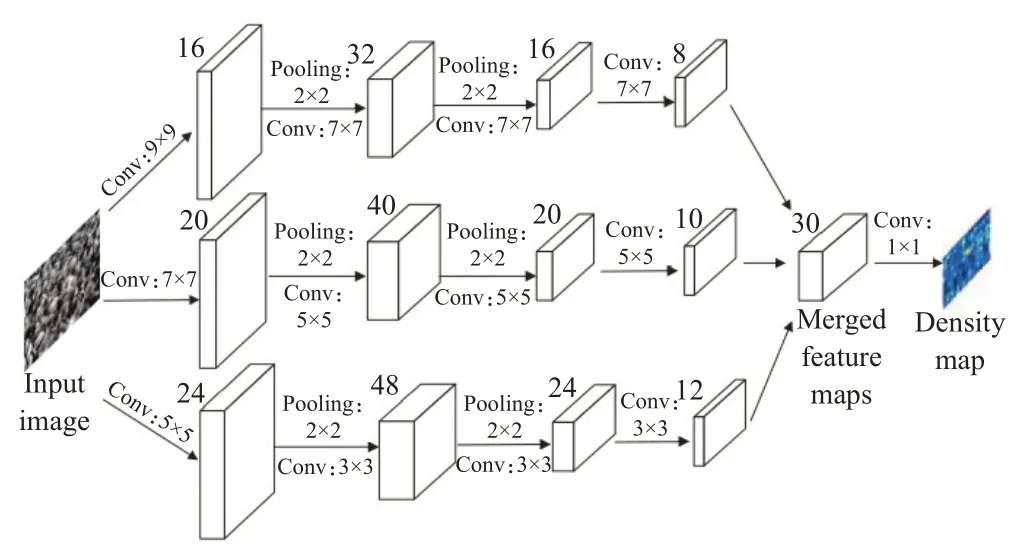
图4 多列人群计数网络Fig.4 Structure of multi-column crowd counting network
Sam等人[46]在多列卷积神经的基础上,提出了基于块的选择结构,即多列选择卷积神经网络(switch convolution neural network,Switch-CNN),计数模型如图5所示。Switch-CNN能有效利用场景中的局部人群密度变化。此网络由三个不同体系结构的CNN回归器和一个分类器(Switch)组成,为输入图片块选择最佳回归器。输入图像被分成9个不重叠的小块,每个小块是图像的1/3。选择分类器与多个CNN回归器交替训练,准确地将块传递给特定回归器,这个模型拥有人群分析的显著性能:(1)模拟大尺度变化的能力强;(2)合理利用人群场景中密度的局部变化[47]。Switch-CNN有一个缺陷,一旦分支选择错误将会严重影响计数准确度。
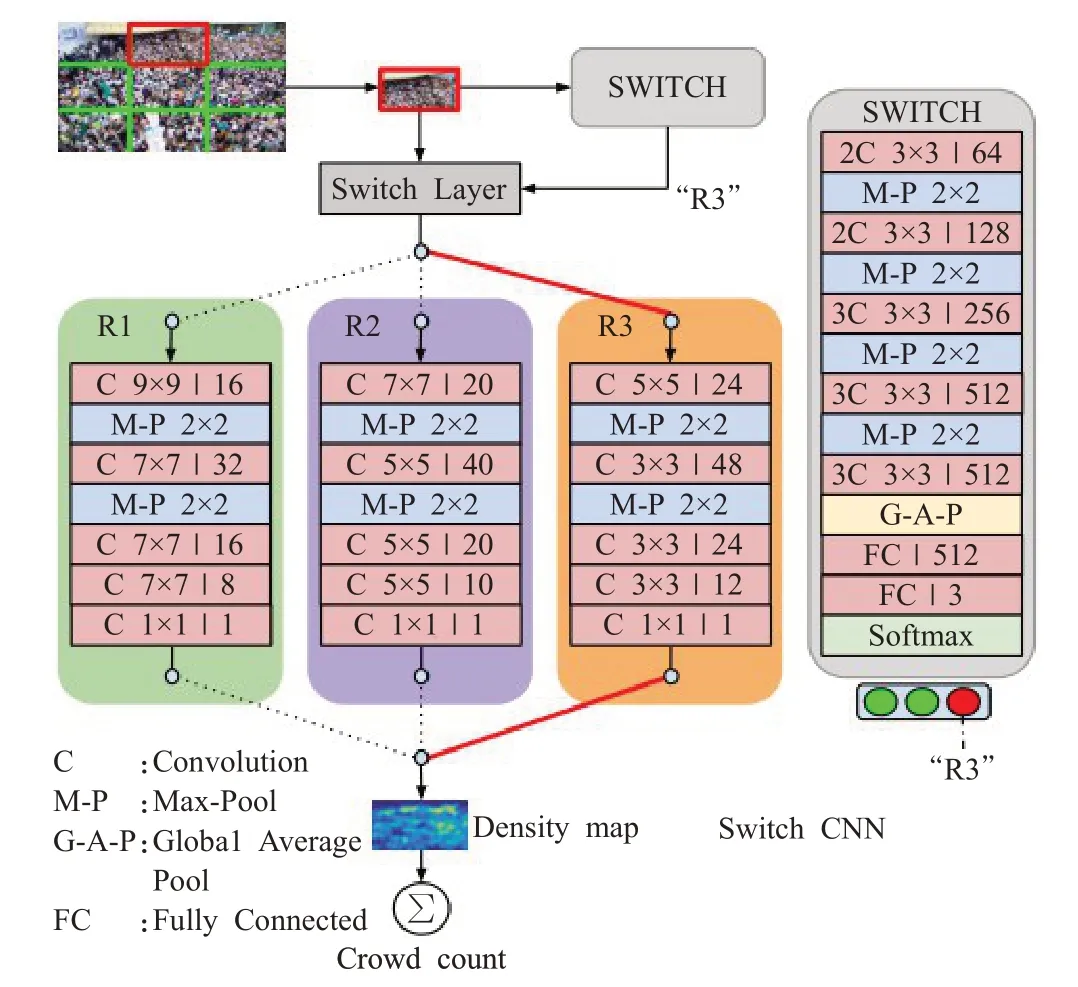
图5 Switch-CNN结构Fig.5 Structure of Switch-CNN
Cheng等人[48]分析MCNN、CSRNet[49]、BSAD[50]和ic-CNN[51]四个网络,发现有的多列体系结构没有监督体系来指导学习不同尺度的特征,而且列间存在大量冗余参数。为了解决这两个问题,Cheng等人提出了一种新的多列互学习策略(multi-column mutual learning,McML)来提高多列网络的学习性能,如图6所示。McML使用互信息来近似表示来自不同列的特征之间的尺度相关性,通过最小化列间的互信息,还可以引导每列聚焦不同的图像尺度信息。McML的核心思想是相互学习。许多网络模型同时更新多个列的参数,但McML依次优化更新每个列,直至收敛。每一列学习过程中,先估计列间的互信息作为先验知识来指导参数更新。McML借助列与列之间的互信息,交替地使每一列都受到其他列的引导,从而学习不同的图像比例和分辨率。结果显示,这种互学习方案可以显著减少冗余参数的数量,避免过拟合。
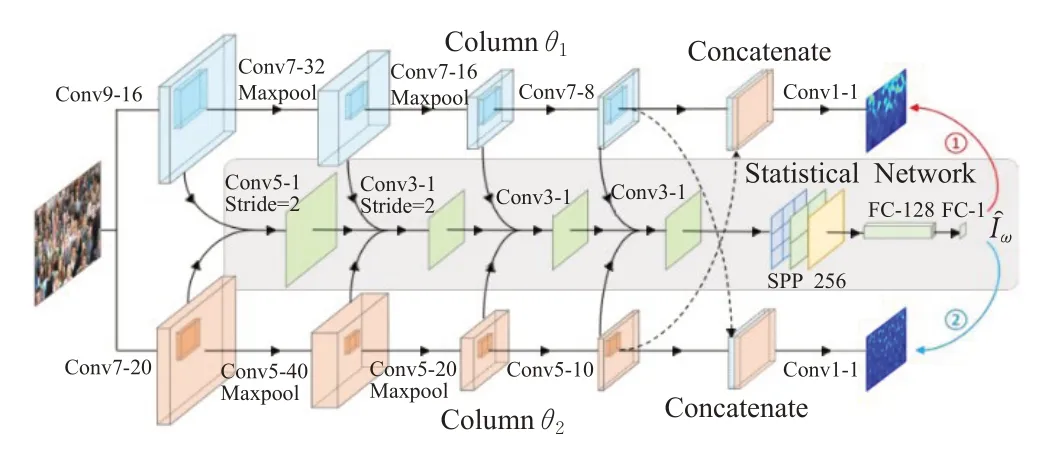
图6 多列互学习(McML)网络结构Fig.6 Structure of McML
除了上述文献,还有很多研究试图解决变尺度问题。Chen等人[52]使用多列卷积网络架构和梯度融合进行人群计数。Deb和Ventura[53]使用多列扩张卷积网络聚合来融合不同层次的特征。但是,多列网络仍然存在一些固有的缺点,如计算量大、实时计数困难、生成的密度图清晰度不够高。因此,一些研究者开始研究如何利用单一网络融合多尺度特征。Liu等人[54]利用侧向连提出了单列计数网络,该系统由多个专用模块、四个残差接的特征金字塔网络融合高级特征和低级特征。Wang等人[55]由融合模块(用于多尺度特征提取)、一个金字塔池模块(用于信息融合)和一个亚像素卷积模块(用于分辨率恢复)组成。Dai等人[56]使用密集扩张卷积块提取尺度连续变化的信息。Kang和Chan[57]采用图像金字塔法进行多尺度采样。Gao等人[58]通过引入前/背景分割来约束密度图。一些研究者也使用类似Inception的模块来提取密度图,如Zeng等人[59]引入了不同核大小的多尺度来提取不同层次的特征。图像中人头尺度的巨大跨度一直是人群计数的一个主要问题。目前的大多数解决方案都是基于多尺度的特征融合。本节提到的这些方法只是简单地将特征叠加在一起,而不使用权重信息。
2.2 上下文感知计数网络
多分支结构方法[43,46,60]在高密度复杂场景中效果显著,不过,这些方法容易在高密度人群图像情况下过低计数,在低密度人群图像情况下过高计数。多分支计数网络的分支之间缺少联系,平均各分支结果生成的密度图质量不高。于是有研究者提出,用图像的上下文语义来指导计数过程。该方法主要利用人群场景的上下文和语义信息对密度图进行约束,减少特征信息丢失,以获得更好的性能,适用于稀疏、密集场景,不过它的结构往往比较复杂。
前面提过MCNN[43]采用自适应高斯核来提高密度图的质量,计数性能的一个关键就是密度图质量。由于研究人员在语义分割[61]、场景解析[62]和视觉显著性[63]中使用上下文信息取得了突出效果,为了解决上述问题,Sindagi等人[64]提出了上下文金字塔卷积神经网络模型(contextual pyramid CNN,CP-CNN)。通过结合人群图像的全局和局部上下文信息来生成高质量的人群密度图。如图7所示,其结构由4个模块组成。全局上下文估计器(global context estimator,GCE)是一个基于VGG 16的CNN,它对全局上下文进行编码,通过训练对输入图像进行密度级别分类。局部上下文估计器(local context estimator,LCE)对局部上下文信息进行编码,作用也是对输入图像进行密度级别分类。密度图估计器(density map estimator,DME)借鉴了文献[43]的网络架构,将输入图像转换为一组高维特征图。融合卷积神经网络(fusion-CNN,F-CNN)将这些特征图和GCE与L2CE提供的上下文信息相融合。与现有方法相比,CP-CNN的突破是生成了质量更好的密度图,计数误差更低,并通过优化对抗损失和像素欧几里德损失的加权组合,F-CNN以端到端的方式与DME一起训练。
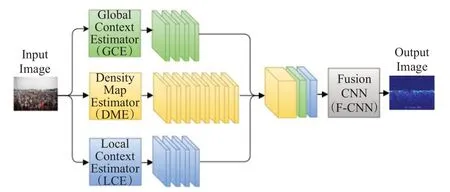
图7 CP-CNN结构Fig.7 Structure of CP-CNN
为解决密度估计图中目标的空间信息丢失问题,郝晓亮等人[65]提出基于上下文特征重聚合的人群计数网络(context-aware feature reaggregation network for crowd counting,CFRNet),CFRNet由三个模块构成,算法结构如图8所示。特征提取器(feature extraction network,FEN)用于提取特征。上下文特征增强模块(context-aware feature enhance block,CFEB)引入空洞卷积层,强化提取的特征,为了同时兼顾小尺度的人群信息,池化操作用空洞卷积层替换。多尺度特征融合结构(multi-scale feature fusion model,MSFM)融合特征图后,进一步增强特征,最后输出高质量的密度图。CFRNet通过二次聚合增强后的特征,提高了算法性能。
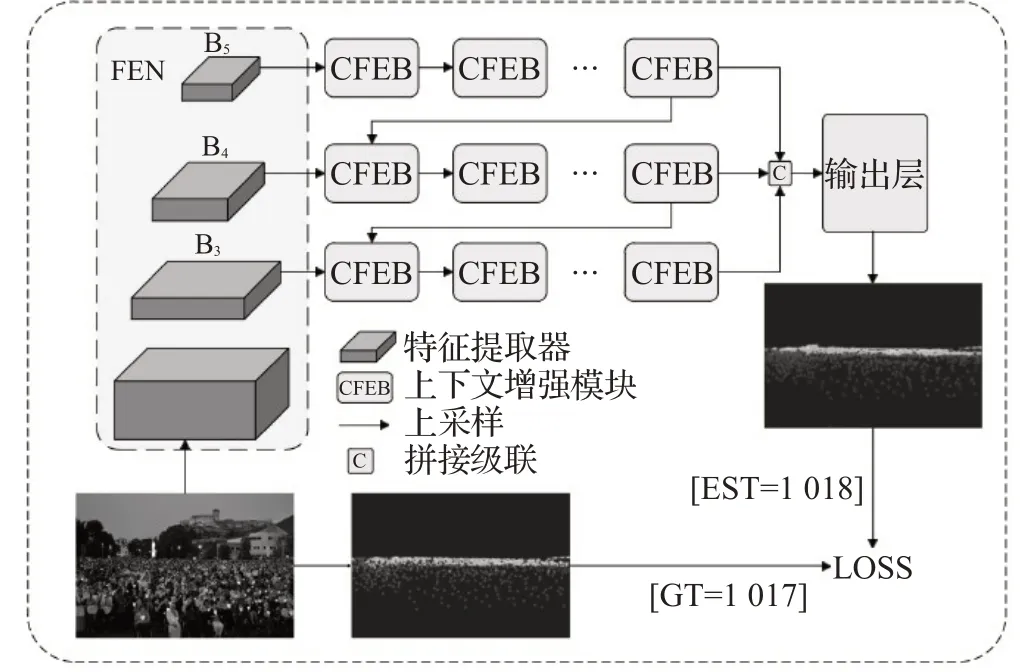
图8 CFRNet算法结构Fig.8 CFRNet algorithm structure
除了上述的工作,Shang等人[66]并没有直接根据整幅图像计算人群数量,而是使用重叠区域的共享计算来估计最终的个体数量。Liu等人[67]将多个接收域大小和每个图像位置的特征结合起来,然后使用端到端可训练网络对其进行训练。最后,该网络输出高质量的密度图。
2.3 多任务计数网络
考虑到尺度问题是实现更高精度的限制因素,一些基于CNN的方法通过多列或多分辨率网络专门解决尺度变化的问题。尽管这些方法显示出了对尺度变化的鲁棒性,但它们在训练中仍然受到尺度的限制,并且学习广义模型的能力不足。最近,多任务学习在计算机视觉任务中取得较好的效果,例如将密度估计与分类、检测、分割等任务相结合,表现出了更好的性能,而且还适用于稀疏、拥挤嘈杂的场景。基于多任务的方法通常设计有多个子网,所以与单列网络相比,不同的任务可能会有对应的分支。综上所述,多任务体系结构可以看作是多列和单列的交叉融合,但又不同于任何一种。
在估计密度图的部分方法中,池化层的存在降低了输出密度图的分辨率,从而影响了在全分辨率密度图上的回归。这导致关键细节的丢失,尤其是在包含大尺度变化的图像中。文献[68-70]成功把级联卷积网络应用于多任务中,Sindagi等人[71]为了解决现存问题,提出了一种新的端到端的级联神经网络,以级联方式学习两个相关子任务:人群计数分类(也叫高级先验)和密度图估计,其网络结构如图9所示。级联网络具有对应于两个子任务的两个阶段,第一阶段是学习高级先验,该阶段的卷积层和空间金字塔池化层,用于处理任意尺寸的图像,末端是全连接层,交叉熵误差作为该阶段的损失层。高级先验学习将计数分类不同的组,这些到组的类标签是基于图像中出现的人数。通过利用计数标签,高阶先验能够粗略估计出整个图像中不受尺度变化影响的人数,从而使网络能够学习到差异更大的全局特征。第二阶段是密度图估计,该阶段由一组卷积层组成,其中分数阶卷积层对前一层的输出进行上采样,来解决池化层产生的细节损失问题,标准像素欧几里德损失作为该阶段的损失层。两个阶段共享一组卷积特征,共享网络由两个卷积层组成,每层后面有一个参数校正线性单元激活函数。
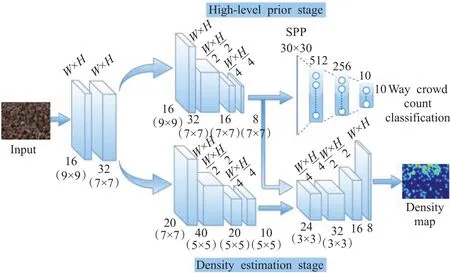
图9 Sindagi等人提出的级联网络结构Fig.9 Cascading network structure proposed by Sindagi et al.
除上述文献以外,还有许多研究尝试把多任务学习应用到人群计数领域。
(1)CMTL[71]。将人群计数分类和密度图估计结合到端到端的级联框架中。
(2)Decidenet[72]。分别通过生成基于检测和回归的密度图来预测人群数量。它可以自动切换检测模式和回归模式,在网络中采用注意力模块来分配相关权重,从而选择合适的模式。如果用多列网络来实现模式转变可能会产生大量的参数,用多任务学习则避免了这个问题。
(3)ACSCP[73]。ACSCP引入了一种对抗性损失使模糊密度图变得清晰。此外,还设计了一个尺度一致性正则化器,以保证跨尺度模型的标定和不同尺度路径之间的协同。
(4)CL[74]。同时完成人群计数,密度图估计和定位三个任务,这三个任务相互关联,使得深度CNN中优化的损失函数是可分解的。
(5)ATCNN[75]。把几何属性、语义属性和数字属性这三种异构属性作为辅助任务来实现人群计数任务。
(6)NetVLAD[76-77]。是一个多尺度多任务框架,把从输入图像中捕获的多尺度特征集合成一个紧密的特征向量。此外,为了网络提高性能,底层使用了“深度监督”来提供额外的信息。
2.4 注意力感知计数网络
多尺度问题造成了位于不同景深的目标尺寸区别过大,人群计数模型的建模能力需要进一步强化,而加入注意力机制可适用于不同尺度、复杂强度和视角变化等场景。Hossain等人[78]为了解决尺度变化问题,在受到Chen等人[79]的启示后,提出了多分支的尺度感知注意力网络(scale-aware attention network,SAAN),其结构如图10所示。这是人群计数领域第一次引入注意力机制。该网络中的注意力扮演着与Switch-CNN[46]中的“开关”(即密度分类器)类似的角色。SAAN有四个模块,全局尺度注意力(global scale attentions,GSA)和局部尺度注意力(local scale attention,LSA)分别提取图像密度的全局上下文信息和局部上下文信息。此外,GSA根据注意力评分把图像密度分成3个等级,LSA将生成三个像素级注意力图。生成多尺度特征提取器(multiscale feature extractor,MFE)借鉴了MCNN[43]的多分支网络,旨在从输入图像中提取多尺度特征。融合网络(fusion network,FN)从图像中提取特征图,为输入图像生成最终的密度图。与Switch-CNN和CP-CNN相比,SAAN运用注意力机制进行尺度选择的方式更灵活,不过它的计算量大、参数多、训练时间长。
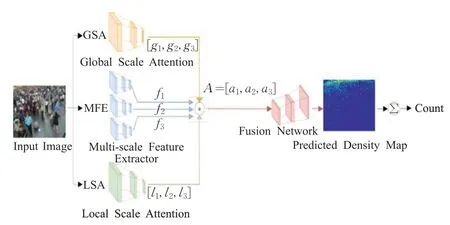
图10 SAAN结构Fig.10 Architecture of SAAN
尽管基于CNN的人群计数结果取得了显著进步,但在高拥挤场景中,会受到遮挡、背景噪声的干扰。为解决这个问题,Liu等人[80]提出了加入注意力的可形变卷积网络,称为ADCrowdNet,如图11所示。它采用两个级联网络:AMG(attention map generator)和DME(density map estimator),AMG是基于完全卷积架构的分类网络,用于生成注意力图,而DME是基于可变形卷积层的多尺度网络,用于生成密度图。由于加入了注意力,可形变卷积添加了方向参数,卷积核在注意力引导下,提高了建模能力,更好地适应视角失真和人群分布差异,提高了高拥挤场景中人群密度图的质量。卷积核在训练DME之前,用人群图片和背景图片来训练AMG模块,接着用训练好的AMG来生成输入图片的注意力图。然后,用输入图片和相应注意力图之间的像素积来训练DME模块。AME前端使用前10层训练好的VGG-16模型[40]提取低级特征,后端使用多尺度可形变卷积层,采用多个空洞率不同的空洞卷积层扩大感受野,来应对不同尺度的人群分布。
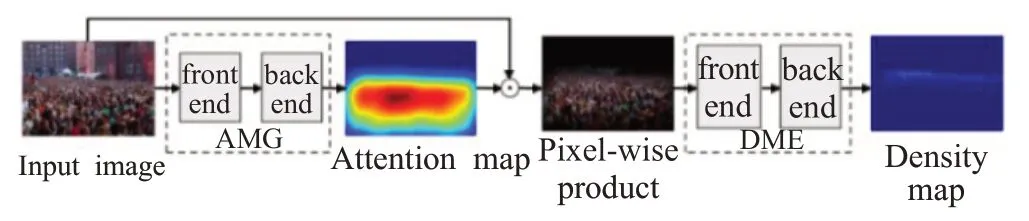
图11 ADCrowdNet结构Fig.11 Architecture of ADCrowdNet
数据驱动型的计数网络效果显著,不过容易高估或低估不同密度区域的人数,从而降低整体计数精度。为了克服这个问题,Jiang等人[81]提出了一种方法,能够处理不同密度分布的拥挤场景。网络结构由密度注意力网络(density attention network,DANet)和注意力尺度网络(attention scaling network,ASNet)组成,如图12所示。DANet为ASNet提供了与不同密度级别的区域相关的注意力掩码。ASNet生成比例因子,这些比例因子有助于微调相应局部区域的总体人群计数,然后将它们乘以注意力掩码,以输出单独的基于注意力的密度图。这些密度图相加得到最终的密度图。此外,该方法还提出了一种新的自适应金字塔损失函数(adaptive pyramid loss,APLoss)来分层计算子区域的估计损失,从而减轻了训练偏差,提高了计数网络的泛化能力。
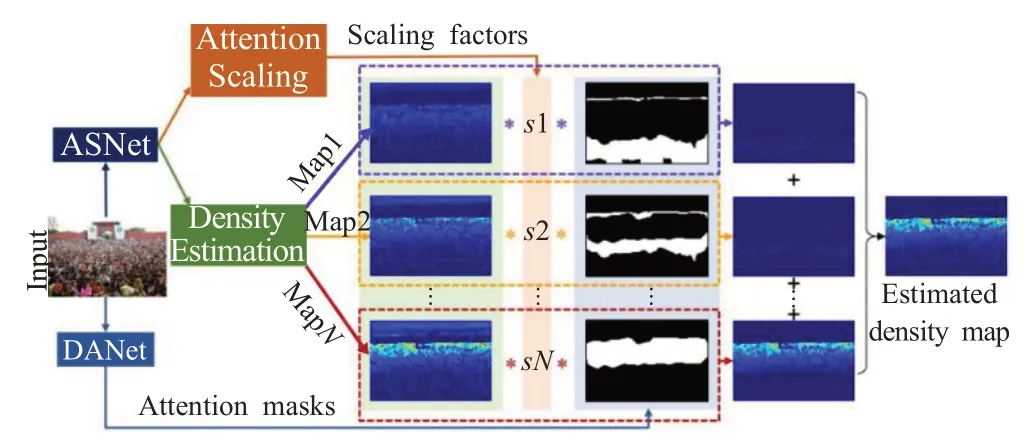
图12 Jiang等人提出的网络结构Fig.12 Network structure proposed by Jiang et al.
此外,还有许多研究尝试把注意力机制应用到人群计数领域。
(1)MSAN。Varior等人[82]使用多分支尺度感知注意力来解决图像中头部尺度变化较大的问题。该网络用不同层次的分支在多个尺度上预测相应的密度图,最后利用软注意机制融合之前预测的多尺度密度图,还引入了一个尺度感知的损失函数来指导网络在不同阶段的训练,这对大规模变化的场景有明显的改善。
(2)SCAR。Gao等人[83]注意到现有的人群统计方法大多只关注人群的局部外貌特征,而忽略了大量的上下文信息和注意力信息。因此,提出了一个SCAR(spatialchannel-wise attention regression network)框架,该框架包括一个SAM(spatial-wise attention model)和一个CAM(channel-wise attention model)。SAM对整个输入图像进行编码,以获得大范围的上下文信息,从而更准确地预测密度图。CAM从信道中提取出最具识别力的特征,使网络模型对噪声背景更加稳健。最后,将两个注意力网络的信息进行整合,得到一个融合的密度图。
(3)SFANet[84]。针对场景中人头尺度变化大、背景噪声强的问题,提出了一种带有注意力的双路径多尺度融合网络用于人群计数。他们以VGG-16网络为前端进行特征提取,以双路径多尺度融合网络为后端生成密度图。
(4)Attend To Count[85]。提出了一种融合计数注意力机制的人群计数的自适应模型。该模型较好地利用了粗网络、细网络和光滑网络的多分支进行预测。粗网络以原始图像为输入,经过多列网络后输出粗糙密度图。Fine网络通过层与层之间的连续融合得到一个微调的密度图区域。最后,Smooth网络将两个密度图结合,得到最终的密度图。
基于注意力的方法受到了人脑认知机制的启发,并在许多人工智能的领域得到了证明。人群计数中的注意力机制可以显著提高模型在不同尺度、复杂强度和视角变化等复杂场景的计数性能。当然,这一领域的研究还有待进一步深入。
综上所述,本节对主要的人群计数机制进行了一个系统性的陈述,分析了它们的优势、劣势和适用场景。如表1所示。

表1 人群计数机制的对比分析Table 1 Comparative analysis of crowd counting mechanisms
上述分析可知,计数模型的结构在不断发展,为了解决多尺度问题和跨场景问题,计数网络由单分支结构升级成多分支结构,网络结构的建模能力得到进一步巩固。虽然提高了计数准确度,但是也使得网络结构越来越复杂、参数多、计算量增加,降低了模型的计数效率。为了应对这些难题,研究者尝试把多分支结构用单分支结构代替,通过引入创新的CNN模型来降低模型复杂度和提高计数准确度,这将是人群计数领域以后的发展趋势。上下文感知计数网络、多任务计数网络和注意力感知计数网络等CNN技术可以有效解决多尺度、跨场景和背景噪声等问题,生成更优质的密度图,提高计数精度。
3 基于ViT的人群计数
主流的人群计数方法通常利用卷积神经网络来回归密度图,需要点级标注,点级标注耗费财力和人力,因此研究人员倾向于更经济的标记方式,仅依赖计数级注释的弱监督计数方法应运而生。目前的弱监督计数方法采用CNN通过图像端到计数端来回归人群的总数。然而,基于CNN的弱监督方法的内在限制是上下文建模的接受域有限。因此,这些方法不能达到令人满意的性能,限制了实际应用。Transformer是自然语言处理中一种流行的序列到序列预测模型,它包含全局接受域,显示出比CNN架构更出色的优势。这意味着Transformer架构更适合弱监督计数任务,因为该任务的目标是直接在整个图像上预测人群总数。
Liang等人[86]提出了TransCrowd,它从基于Vi T的序列计数的角度重新表述了弱监督人群计数问题。TransCrowd能够利用ViT的自注意力机制有效地提取语义人群信息。此外,这是研究人员首次采用ViT进行人群计数研究,并且取得显著效果。如图13所示,TransCrowd分为两种类型:Trans Crowd-Token和TransCrowd-GAP。TransCrowd-Token利用一个额外的可学习标签来表示计数,TransCrowd-GAP采用Transformerencoder输出序列中所有项的全局平均池化(global average pooling,GAP),来获得池化的视觉标记。然后,回归标记或池化的视觉标记被送到回归总部生成预测计数。事实证明,与TransCrowd-Token相比,TransCrowd-GAP能够获得更合理的注意力权重,获得更高的计数精度,收敛速度更快。
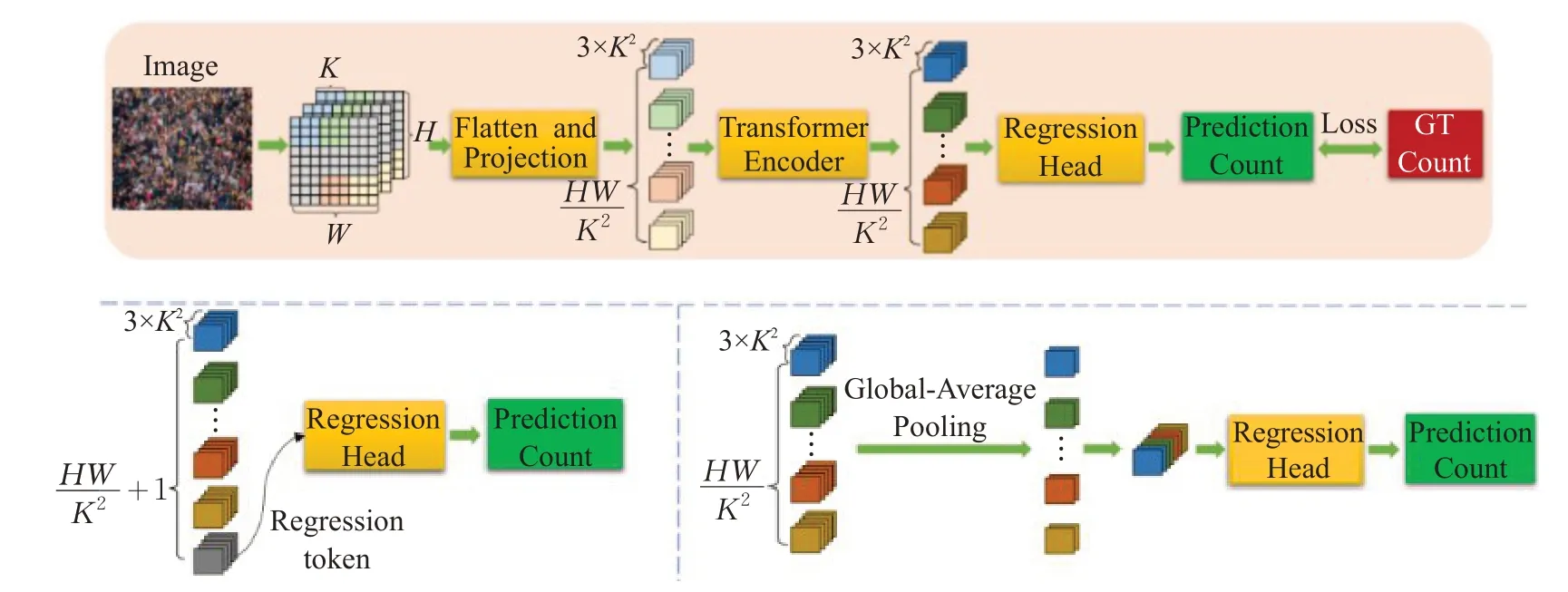
图13 TransCrowd的网络结构Fig.13 Architecture of TransCrowd
4 人群计数分析
4.1 评价标准
为了验证神经网络模型的鲁棒性和准确度,分别引入了量化标准均方误差(mean squared error,MSE)和平均绝对误差(mean absolute error,MAE),公式如下:
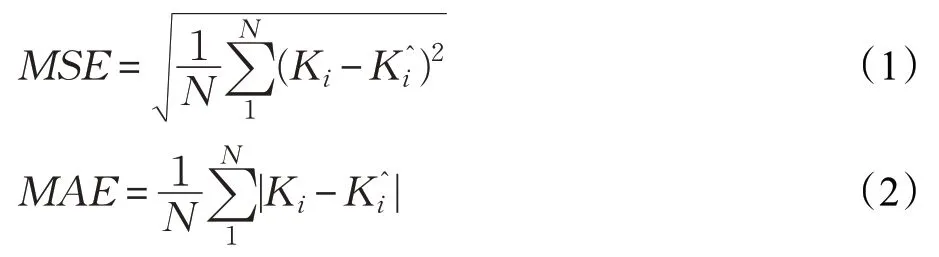
MSE越小则鲁棒性越好,MAE越小则准确度越高。N表示测试图片的总数,K i表示第i张图像的实际真实人数,K^i表示第i张图像的估计人数。通过这两个常用的指标,可以反映一个模型的优劣。
4.2 数据集和结果分析
人群计数领域出现了一批经典数据集,使得研究人员创建了泛化能力更好的模型。相比于早期低密度的数据集,当前的数据集关注高密度人群场景,能有效应对尺度变化、杂乱和遮挡的问题。下面将介绍UCSD[87]、WorldExpo’10、ShanghaiTech[43]、UCF_CC_50[88]这几个数据集。
(1)UCSD dataset。UCSD[46]是人群计数领域的第一批数据集之一,其是由视频监控在加州大学圣地亚哥分校的人行道上收集的。原始视频以30 frame/s捕获,帧大小为740×480,随后被下采样至238×158和10 frame/s。视频的前2 000帧(200 s)用于真实注释,作为数据集。在人行道上选择了一个感兴趣区域每隔5帧人工标注一次,剩余帧中的行人位置通过线性插值来估计。该数据集分为训练集和测试集,总共包含49 885个行人实例。训练集包含索引为600到1 399的帧,测试集包含剩余的1 200个图像。该数据集人群稀疏,平均每帧15个人左右,数据集是从单一场景收集的,所以图像之间的场景视角没有变化。
(2)WorldExpo’10 dataset。为解决单一场景问题,Zhang等人[39]引入了一个数据集用于跨场景人群计数WorldExpo’10。该数据集来自2010年上海世博会,其中包括108个监控摄像头捕获的1 132个带注释的视频序列,通过鸟瞰式摄像机收集视频,丰富了场景类型。数据集总共标注了3 980帧分辨率为576×720的图像,标记行人199 923个。数据集被分成两部分,来自103个场景中的1 127个1 min长的视频序列被视为训练和验证集。测试集来自5个不同场景,每个测试场景中有120个标记帧,两个帧之间的间隔为30 s。人数变化范围从1到220,因此该数据集不适用于极度密集场景。
(3)ShanghaiTech dataset。彭超等人[45]引入了一个新的大规模人群计数数据集,该数据集由1 198张图像和330 165个注释头组成,是带注释人数最多的数据集之一。它包含两个部分:A和B。A部分的482张图片是从互联网随机下载的,而B部分图像来源于上海街道。与B部分相比,A部分的密度图像要大得多。这两个部分又进一步划分为训练集和测试集。A部分的训练和测试分别有300和182幅图像,而B部分的训练和测试分别有400和316幅图像。该数据集的图像具有不同场景类型和不同密度级别,不过不同密度级别的图像数量并不一致,使得训练和测试倾向于低密度级别。
(4)UCF_CC_50。该数据集是第一个真正具有挑战性的数据集,由公开可用的网络图像创建。为了丰富场景类型的多样性,收集了音乐会、示威、体育场、马拉松等不同标记的图像。它包含了50张不同分辨率的图像,平均每张图像有1 280个人。在整个数据集中总共标记了63 075个人,图像上人的数量从94到4 543不等,这表明在图像上存在很大的差异。这个数据集的唯一缺点是用于训练和测试的图像数量有限。考虑到低数量的图像,定义了一个交叉验证协议来训练和测试,其中数据集被分成10个集合,并执行5倍的交叉验证。这个数据集挑战很大,当前基于CNN的最先进方法在这个数据集上的结果效果不佳。
如图14所示,是数据集的样本,从左至右分别是UCSD、UCF_CC_50、WorldExpo’10、Shanghai Tech A和ShanghaiTech B。

图14 不同数据集的样本Fig.14 Samples of different data sets
下面是不同计数网络在不同数据集上的性能对比,如表2所示。
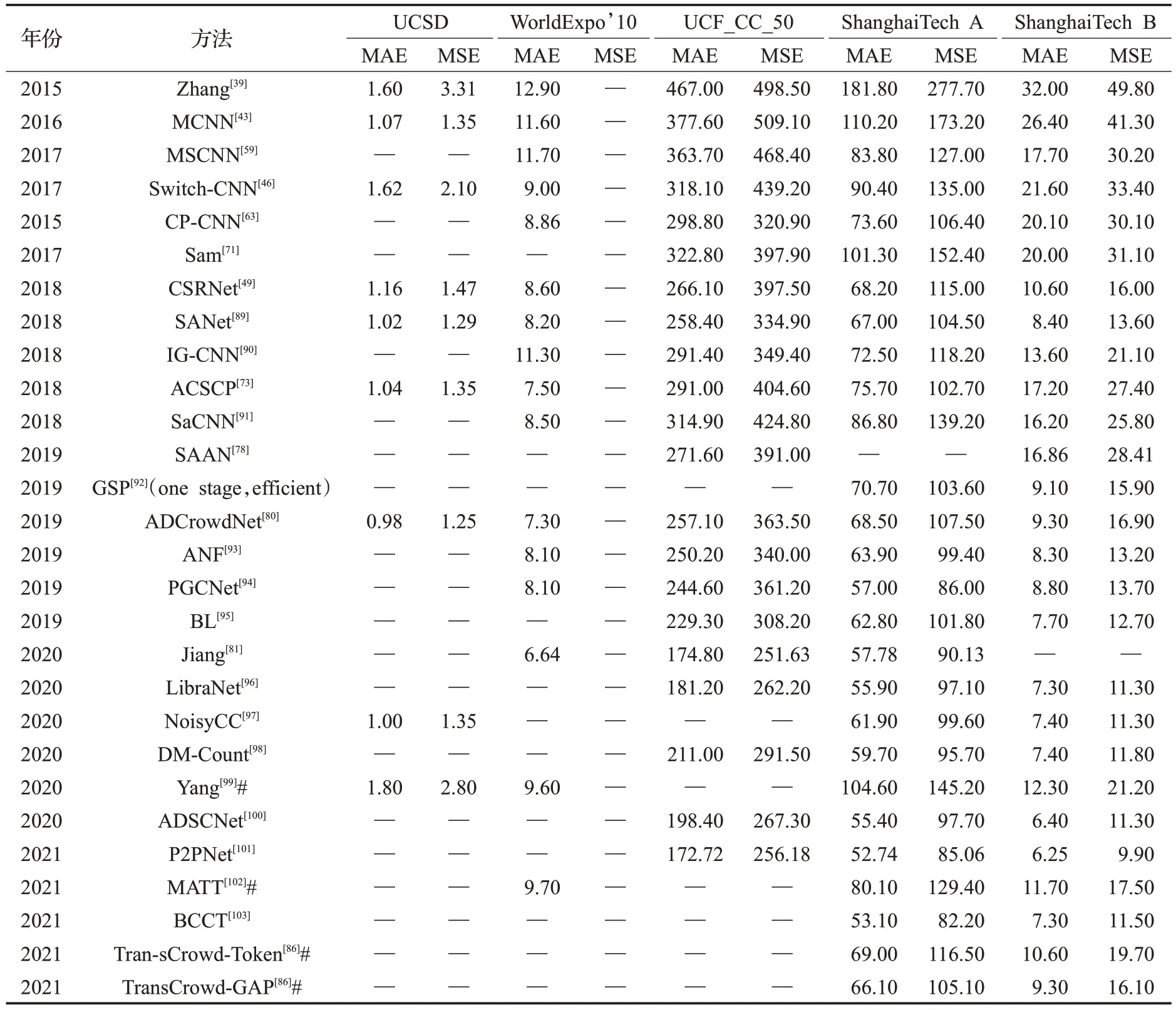
表2 不同计数网络在不同数据集上的性能对比Table 2 Performance comparison of different counter networks on different data sets
表2罗列了部分人群计数网络在4个主流人群数据集上的结果。CSCC[39]是单分支结构,MCNN[43]、Switch-CNN[46]、CSRNet[49]、MSCNN[89]和IG-CNN[91]是多分支结构,经过对比可知,多分支结构相比单分支结构有更强的提取特征能力,其计数性能也优于单分支结构。CP-CNN[71]是上下文感知结构,在多列的基础上增加了全局上下文感知模块和局部上下文感知模块,增强了计数精度。文献[78,80-85]在密度估计的基础上引入了注意力机制,增强了网络结构的鲁棒性,提高了网络的泛化能力和计数精度。文献[70-77]是多任务模型,经过对比,多任务模型比单任务模型计数效果更好。TransCrowd-Toke和TransCrowd-GAP[86]是TransCrowd提出的基于ViT的弱监督计数方法。如前所述,尽管基于ViT的弱监督计数方法性能不如全监督计数方法,但相比其他基于CNN的弱监督计数方法[101-103]展示了独特的优越性。表2的实验结果表明,计数精度甚至与部分全监督计数方法相当。
5 结语
本文对人群计数领域的传统方法、基于CNN和基于ViT三种方法进行了系统性的介绍和分析,通过分析,可得到以下几点结论:
(1)数据集的场景由单一化逐渐演变成多样化,跨场景、高度拥挤和遮挡的图像也能用模型训练并取得较好效果,图像分辨率不断提高,数据图像数量不断扩大。
(2)基于CNN的方法在人群计数领域发展迅猛,研究成果丰富。CNN强大的学习能力以及提取特征能力提高了估计准确率,大大推动了这个领域的发展。多列结构模型复杂、参数多,目前很多研究人员仍然重点研究单列结构。同时,引入新的损失函数来优化模型依然是研究热点。
(3)Transformer是自然语言处理中的一种预测模型,Transrowd[43]利用Transformer的自注意机制可以有效地提取语义群体信息,突破了基于CNN的弱监督计数方法的部分限制,还采用了比CNN更经济的标注方式,降低了成本。
(4)遮挡、透视失真、光照、极端天气等问题依然是人群计数领域需要克服的困难,今后研究人员可以尝试攻克这些特殊情况的计数问题,并且建立相应数据集。
本文回顾了人群计数领域的方法,介绍了常用的数据集、评价指标以及计数网络,分析了该领域的发展趋势,希望能给后续研究提供帮助。
