V-SLAM深度学习闭环检测研究进展与展望
2022-06-09伍宣衡王忠美
高 贵,伍宣衡,王忠美,郑 良
1.湖南工业大学 轨道交通学院,湖南 株洲 412000
2.西南交通大学 地球科学与环境工程学院,成都 610000
3.中国电子科技集团公司 第十五研究所,北京100083
在过去几十年科技发展过程中,移动机器人的研究与应用技术愈发成熟,同步定位与建图(simultaneous localization and mapping,SLAM)是指搭载特定传感器的移动载体在无环境先验信息的条件下,在移动的过程中将环境模型建立出来并估计出所移动轨迹,故SLAM技术旨在将移动机器人放在未知位置和环境中能实现精准定位并同时建立起与环境相一致的地图[1],这也是实现移动机器人完全自主的核心所在。经典SLAM系统架构主要由传感器数据的读取、视觉里程设计(visual odometry,VO)、后端优化、闭环检测和地图构建五个部分组成[2],通过所搭载摄像头传感器来感知外界环境的SLAM系统称之为视觉SLAM(visual-SLAM,V-SLAM),其在自动驾驶、家用扫地机器人和物流仓库移动小车等场景中都有广泛的应用[3],闭环检测作为V-SLAM中的重要一环,其作用是在移动机器人的定位过程中可以正确识别之前所访问的地方,且当传感器晃动或运动过程中的突发情况等导致轨迹丢失时,正确的闭环检测可以对SLAM系统进行重定位并减少在前端视觉里程所带来的的漂移误差[4],从而提高地图精度。在SLAM中影响闭环检测性能的因素有很多,如环境条件、光照、季节、机器视点和移动的过程中动态目标导致特征遮挡等都有可能对闭环检测产生影响。
1 传统闭环检测方法
传统闭环检测都依赖于人工设计的特征,其实质是将当前图像与先前位置的图像进行匹配,相似图像常用特征点来进行匹配,例如采用SIFT(scale invariant feature transform)[5]、SURF(speeded up robust features)[6]、FAST(features from accelerated segment test)[7]和ORB(oriented FAST and rotated BRIEF)[8]等算法提取图像局部特征。为减少图像匹配间的计算量,有研究学者开发出了基于视觉单词包(bag of visual word,BoVW)[9]和费希尔向量(Fisher vector,FV)等[10-11]的闭环检测方法。基于BoVW的闭环检测分为两种:一种是离线训练词汇模式用来生成固定大小的词汇[12]在已知的环境中移动,这种方式尽管可以降低计算的成本,但闭环检测的实时性不强,故另一种方式是在线训练BoVW的词汇[13],使其可在真实环境中工作。同时在闭环检测中也可以利用图像的全局特征来进行检测,例如使用图像的GIST(generalized search tree)[14]来提取图像的全局特征等。传统闭环检测中对于图像特征提取后的匹配有多种方式,例如在FAB-MAP(fast appearance-based mapping)[15]中引入BoVW,由于对局部图像特征的提取中所用的SIFT和SURF等描述子具有尺度不变性,因此FAB-MAP在闭环检测中有较好的性能。Zhang等人提出一种在线学习二值图像特征的方法用来改进基于BoVW的闭环检测[16],通过线性判别分析出最小和最大化类内间距来优化二值图像特征。梁志伟等人提出一种利用混合高斯模型所建立的视觉词典的概率模型[17],将基于BoVW的图像用概率向量表示,并利用贝叶斯滤波器[18]来提高闭环检测的准确率和特征匹配的速度。Cummins等人[19-20]提出在FAB-MAP方法中应用Chow-Liu树[21]描述词与词之间的相关性来提高闭环检测的搜索速度。在Cummins等人研究的基础上Maddern等人[22]提出了基于FAB-MAP的CAT-SLAM(continuous appearance-based trajectory simultaneous localisation and mapping)方法,与FAB-MAP相比较,其CAT-SLAM的闭环检测效果更好。总结并分析多数学者的研究,发现传统闭环检测算法有以下几个缺点:
(1)基于传统方式的BoVW等算法完全依赖于外观,没有使用到几何信息,故在闭环检测过程中容易将相似图像误判为闭环。
(2)传统方式的闭环检测算法对特征点的提取和匹配较为耗时,而SLAM系统所输入数据是一个时间序列图像,若在图像的特征点提取和匹配上花费较多时间,则会导致整个SLAM系统行动缓慢。
(3)在特征缺失或无明显纹理信息的场景中,由于特征点数的急剧缺失可能导致闭环检测失效。
(4)在复杂环境中容易受到光照季节、机器视点变化和动态目标等影响,从而使得移动机器人闭环检测的精确度大为下降。
2 基于深度学习的V-SLAM闭环检测方法
随着深度学习技术在图像识别、分类等各种计算机视觉和机器视觉领域的不断发展[23],在SLAM中的应用也得到广泛关注,主要体现在三个方面:基于深度学习的前端视觉里程设计运用、基于深度学习的闭环检测和基于语义信息的地图构建。许多学者开始在移动机器人的闭环检测上也采用深度学习方法进行了探索,在V-SLAM的闭环检测中,将当前帧与之前所有帧进行图像相似度匹配对比的工作也可以在深度学习中理应有所运用,但目前深度学习在SLAM的闭环检测上并没有得到广泛应用。在复杂环境中影响闭环检测的因素主要有:光照、季节的变化、机器视点的变化和动态目标对特征的遮挡等,因此本文根据所解决的三个主要方向问题,对于现有应用在闭环检测中的不同深度学习方法进行梳理总结,具体包括基于卷积神经网络(convolutional neural network,CNN)[24]的闭环检测、基于无监督式自动编码器[25]的闭环检测和基于语义信息的闭环检测[26]三种,如图1所示为近些年基于深度学习的闭环检测方法。
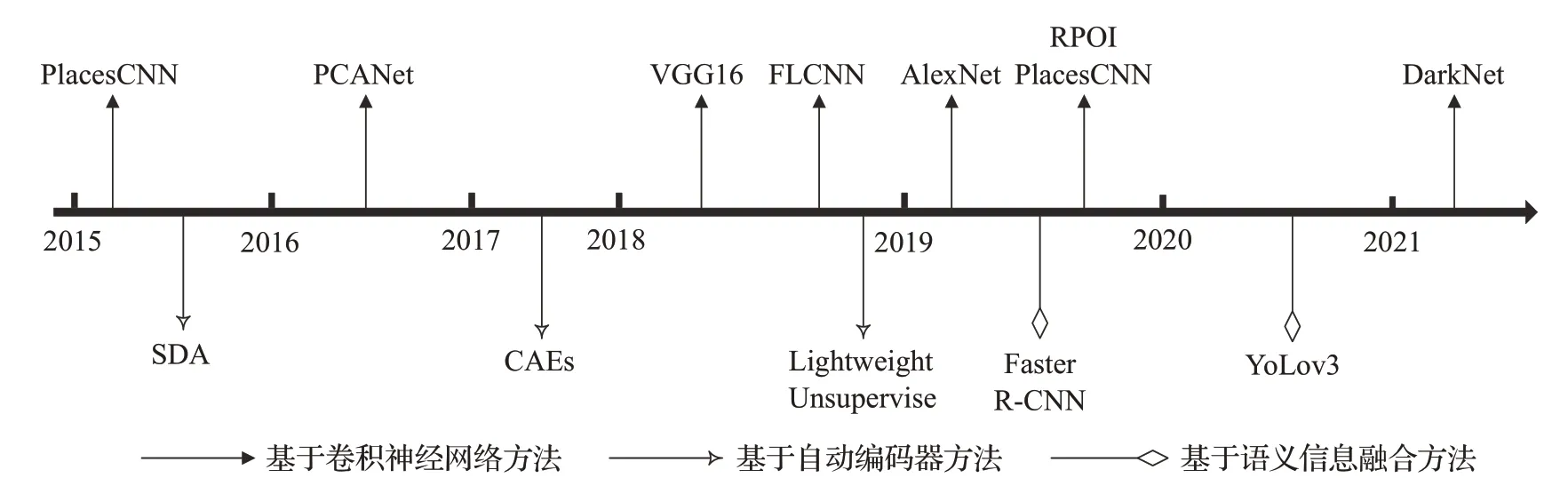
图1 基于深度学习的闭环检测方法Fig.1 Loop closure detection method based on deep learning
2.1 基于卷积神经网络的V-SLAM闭环检测
基于卷积神经网络的深度学习主要是使用多个卷积层来提取图像特征,并使用池化层对选取的特征进行降维,经过卷积神经网络所提取出的图像特征相比于传统的人工视觉特征提取更能有效表示图像的语义特征。如图2所示为基于卷积神经网络的闭环检测结构示意图。
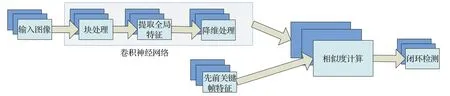
图2 基于卷积神经网络闭环检测示意图Fig.2 Schematic diagram of loop closure detection based on convolutional neural network
CNN的研究最早是围绕图像分类问题所展开的,并在ILSVRC(ImageNet large scale visual recognition challenge)-2010上取得巨大的突破,在闭环检测方面,Hou等人将CNN用于V-SLAM的闭环检测算法中[27],后有研究者将其称之为PlaceCNN(place convolutional neural network,PlaceCNN)的V-SLAM闭环检测算法,该算法使用一个开放性的深度学习框架Caffe(convolutional architecture for fast feature embedding)[28]提取基于CNN的图像深度特征,并在Places数据集[29]上得到验证,与传统方法相比,其对光照敏感性更弱、鲁棒性更强,由于所提取的场景特征维度高,难以满足V-SLAM闭环检测的实时性要求。
基于PlaceCNN的闭环检测是结合深度学习与V-SLAM闭环检测的一个开创性的初步方式,在此基础上Xia等人提出利用主成分分析网络(principal component analysis network,PCANet)提取图像特征[30]的闭环检测方法,PCANet是一个基于CNN的简化深度学习模型[31],主要是由主成分分析(principal component analysis,PCA)、二进制哈希编码和分块直方图三部分组成。经验证后与CNN相比,在特征提取时间上强于CNN,并且由于该网络结构简单和训练时间短特点,可以在V-SLAM的实时上有所突破,但在一个场景中训练的图像数量不够时,CNN的鲁棒性强于PCANet。
针对PlaceCNN的V-SLAM闭环检测算法的实时性差的问题,何元烈等人提出了一种快速、精简的卷积神经 网 络(fast and lightweight convolution neural,FLCNN)[32]。FLCNN使用修正线性单元(rectified linear unit,Relu)作为激活函数。由于闭环检测中每帧图像都是带有时间序列标签,使得相邻两帧图像中相似度较高,很容易造成错误的闭环检测,为了解决相邻帧图像的相似性所引起的干扰,FLCNN设置一个阈值来限定图像间的相似度,该网络的模型结构如图3所示。
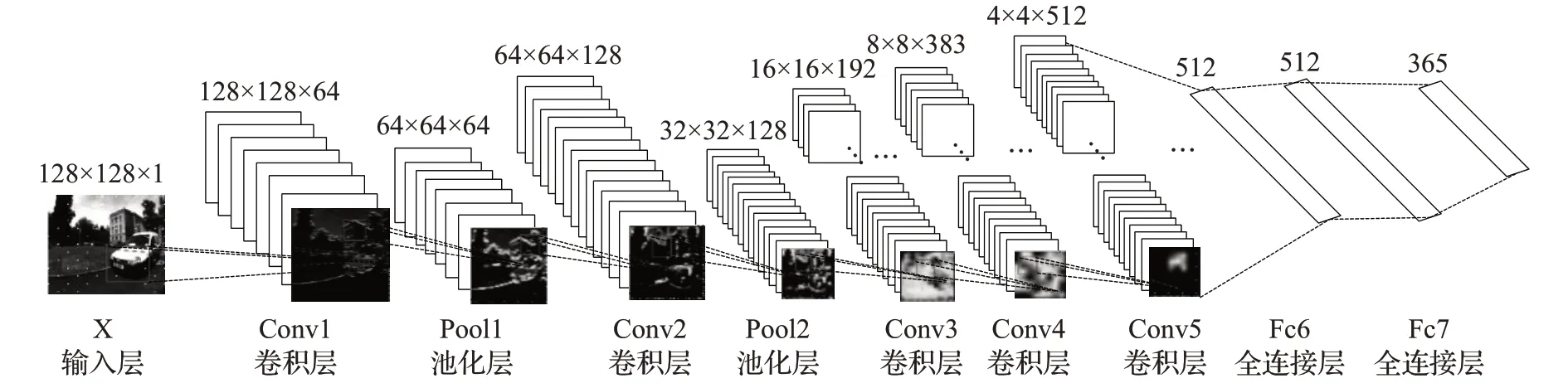
图3 FLCNN模型结构图Fig.3 FLCNN model structure diagram
在该网络模型中,所使用的数据集是Places365-Standard[33],且与PlaceCNN相比在特征匹配上速度快,算法的时间复杂度远小于PlaceCNN,其V-SLAM的闭环检测时间也有所提高,但是当闭环检测场景存在大量分散目标时,其平均准确度低于PlaceCNN,且对视点变化敏感。
基于卷积神经网络的闭环检测方法普遍使用了图像的全局特征,虽然在复杂光环境下对闭环检测有较强的鲁棒性,但在移动机器人实际运动场景中的视角变化明显情况下,闭环检测鲁棒性较差。为了提高闭环检测算法对场景中外观和视角变化的鲁棒性,潘锡英等人提出基于图像感兴趣区域(region proposal of interest,RPOI)的移动机器人闭环检测算法[34],该算法的特征提取主要是经过两个步骤,先是利用多尺度感兴趣算法得到图像的RPOI,然后利用CNN提取RPOI的图像特征。对RPOI的匹配时采用了粗匹配和细匹配两种匹配方式,粗匹配的对象是从改进的CNN最后两个全连接层之间的隐藏层中提取出一个48位的二值特征向量,该过程使用了汉明距离来匹配小范围的感兴趣区域,缩短了闭环检测算法的时间。细匹配是在粗匹配的基础上通过双向匹配原则计算出感兴趣区域中的余弦相似性,该算法可以在光照和视角变化的情况下对于移动机器人的闭环检测具有一定的鲁棒性,但在复杂场景规模较大时,实时性不好。
随着移动机器人运动时长的增加,传感器所传入的帧数不断累积,卷积神经网络在闭环检测中的计算时间也逐渐增长。为了解决该问题,张学典等人将VGG16(visual geometry group16)网络模型用于闭环检测上提取图像的全局特征,并提出一种改进的自适应粒子滤波器方法来解决计算时间增长问题[35]。原VGG(visual geometry group)模型所输出的结果是图像分类[36],故不适合用来描述图像的特征,因此选取VGG16网络中最后的池化层作为闭环检测中图像的全局特征描述子,并将所提取的特征向量用PCA进行降维处理,其VGG16结构如图4所示。
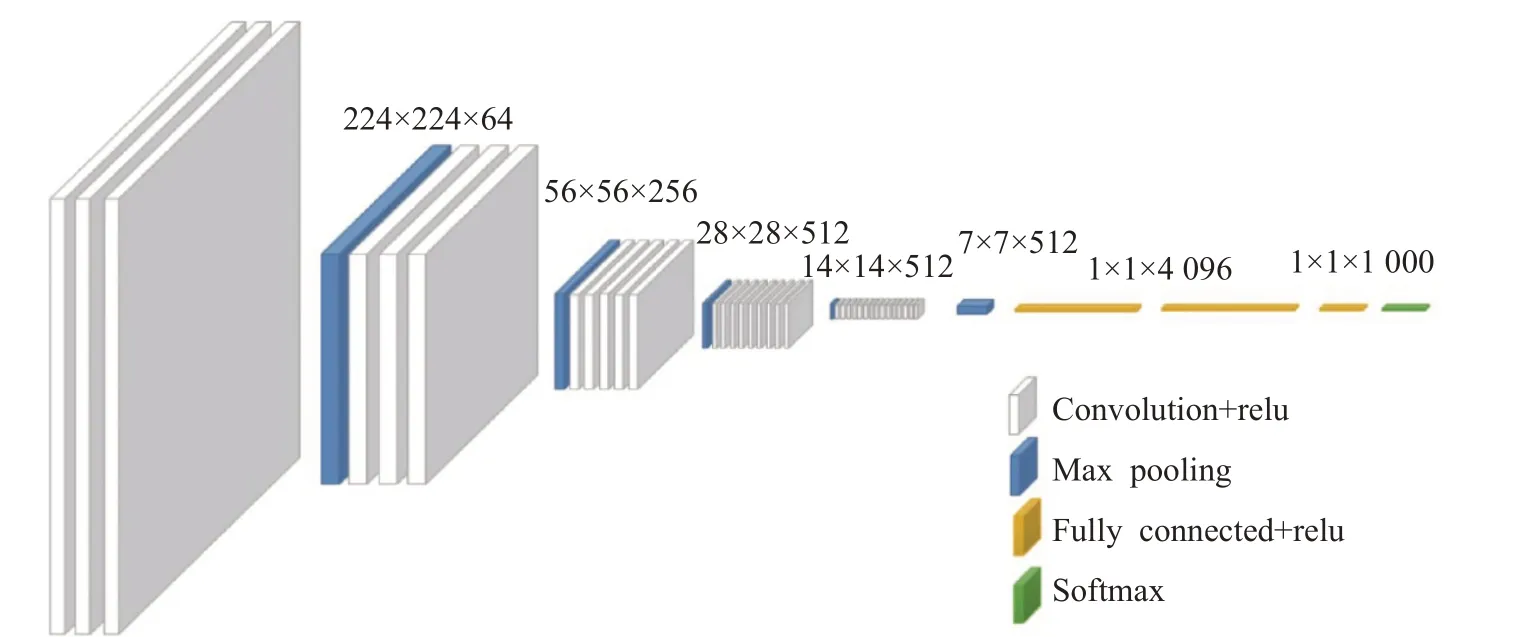
图4 VGG16模型结构图Fig.4 VGG16 model structure diagram
在闭环检测中,机器人的位置移动和相机镜头远近的调节使得图像具有丰富的尺度特征,而普通的卷积神经网络缺少对尺度特征的提取。针对这个问题,Chen等人提出了多尺度深度特征融合的闭环检测[37],在AlexNet模型的基础上,使用了空间金字塔池(spatial pyramid pooling,SPP)[38]来提取多尺度特征。SPP弥补前期对输入图像的切割或压缩等处理所引起的图像信息丢失现象,解决了输入图像大小不一所造成的缺陷并把每一个特征图都从不同的角度进行特征提取后再聚合,显示了算法的鲁棒性特点,SPP层作为特征融合的结构如图5所示。
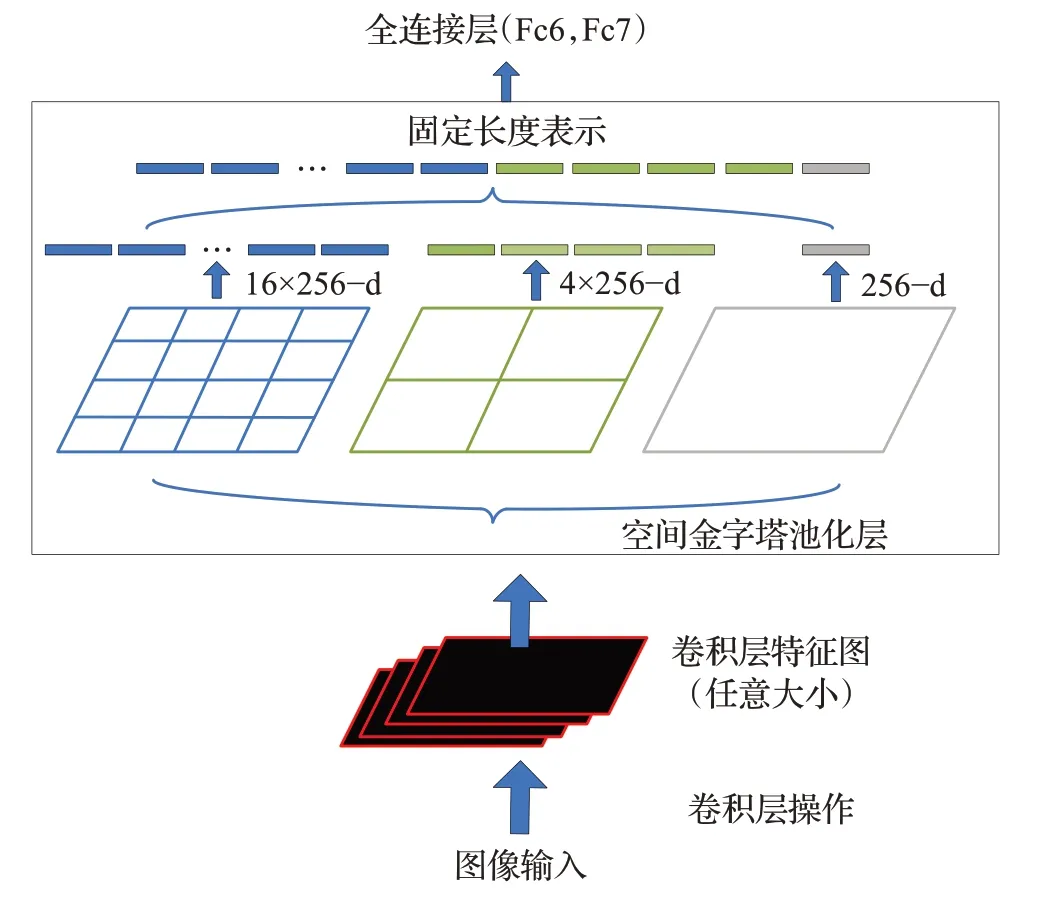
图5 SPP作为特征融合层结构图Fig.5 SPP as a feature fusion layer structure diagram
最后由于考虑到每个特征在闭环检测具有不同的效应,因此定义了特征的可区分性权重,根据特征点对场景的可区分性来对每个特征点赋予一个权重,并在决策层中计算相似度用来对闭环检测进行检验,提高了闭环检测的精确度。经验证表明基于多尺度深度特征融合的闭环检测算法具有更高的准确率和召回率,并对光照变化具有较强的鲁棒。郭纪志等人通过对DarkNet网络框架的损失函数改进[39],得到一个提取区分度好且维度更低的特征描述子,提升大规模复杂场景下视觉闭环检测的性能,通过自编码器的降维处理提高了执行效率,并在光照变化明显的场景下提高了闭环检测的速度。
对于上述的几种基于卷积神经网络的V-SLAM闭环检测方法性能比较分析如表1所示。
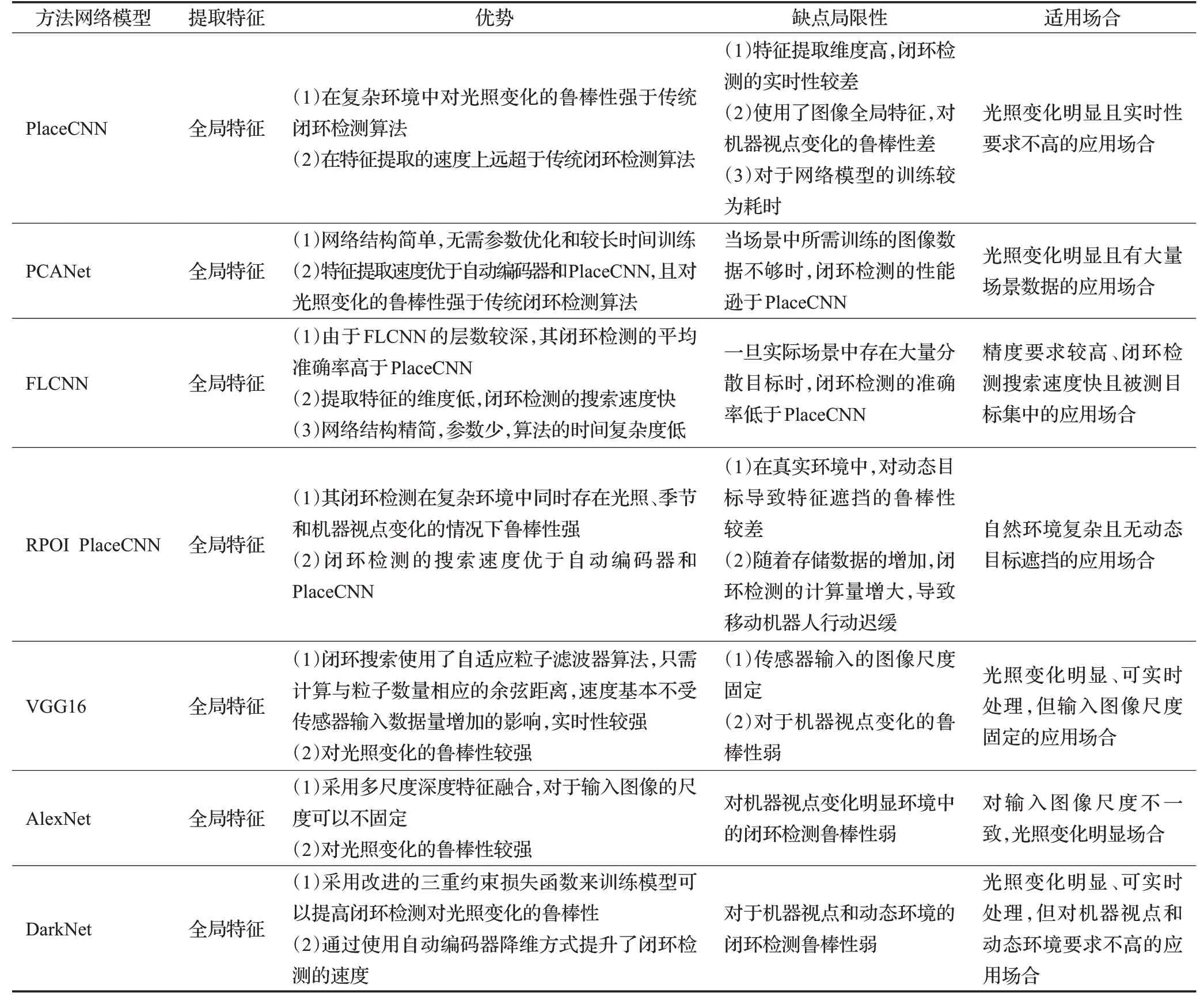
表1 基于卷积神经网络的闭环检测方法比较Table 1 Comparison of loop closure detection methods based on convolutional neural network
通过对基于卷积神经网络V-SLAM闭环检测的研究,可以发现所解决的方向都是关于复杂环境中的光照变化较为明显的因素,这是因为卷积神经网络通常由多层构成,可以学习输入图像的抽象表示特征,但是每层对于光照变化下闭环检测的精确度各不相同,因此需要经过实验找到适合的卷积和池化层。但是由于在闭环及检测的过程中,需要预先对模型进行训练,且所用场景数据都是需要进行大量的人工标注,倘若在预先训练数据中的闭环数量不够时,闭环检测的精度则会下降。
2.2 基于自动编码的无监督深度神经网络V-SLAM闭环检测
深度学习卷积神经网络在移动机器人的视觉闭环检测中依赖于有监督学习,需要大量的人工标记数据,于是Gao等人提出了一种应用在V-SLAM闭环检测中深度神经网络的无监督学习方式[40],利用堆叠式自动编码器(stacked denoising auto-encoder,SDA)以无监督的学习方式训练,方法如图6所示。该自动编码器是一种不利用类标签的非线性特征的提取方法,由于闭环检测的数据是通过前端的摄像头传感器实时传入,为了训练闭环检测的结构,因此对传统的自动编码器进行了改进。

图6 方法结构示意图Fig.6 Schematic diagram of method structure
堆叠式自动编码器把每一层当作一个简单的自动编码器进行预训练和堆叠,可大幅度提高训练的效率。在TUM公共数据[41]集上进行实验,得到的实际移动机器人的轨迹如图7(a)所示,在真实轨迹的基础上提取111个关键帧,其中正确的闭环检测如图7(b)用红线表示。
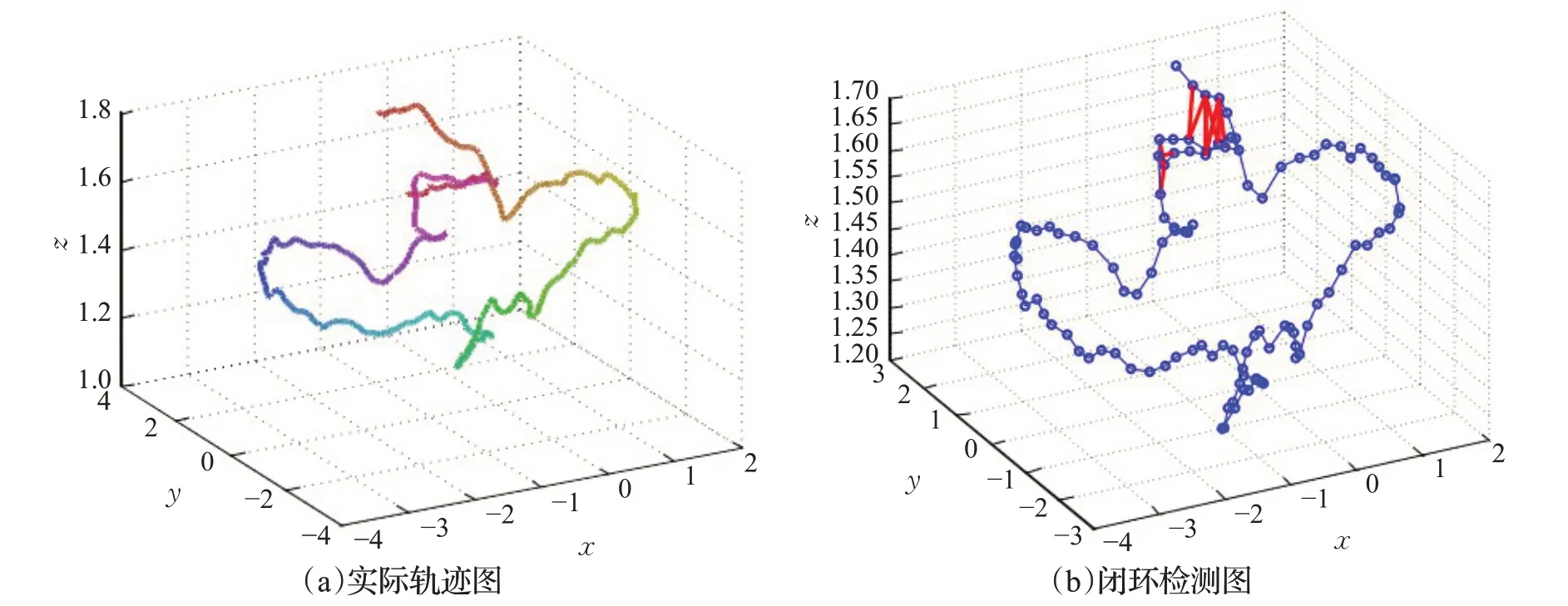
图7 真实移动轨迹和闭环检测Fig.7 Real movement trajectory and loop closure detection
在开放的数据集上测试验证了该方法的可行性,在视觉闭环检测中能达到一个较高的精确度,为可视化SLAM系统提供了一种替代方法。但是Gao等人所提出的方法中使用暴力似匹配方法[42]在对关键帧进行图像匹配比较时耗时严重,且存在感知混叠的问题,这样可能会导致错误的循环和不正确的地图估计。与经典的闭环检测方法FAB-MAP 2.0[43]相比,堆叠式自动编码器的性能与之相当,但是提取特征的速度慢,且所使用的模型学习重建一个改变随机像素的图像,在定位位置时,必须要求视点不变,因此通过训练一个无监督的模型来重建一个已经被改变的图像并模拟该模型在实际中所遇到的视点变化可能在闭环检测中更加有作用。
对于图像的空间局部特性上,张云洲等人采用栈式卷积自动编码器(stacked convolutional autoencoder,CAEs)[44],在该模型中对于编码器部分采用卷积神经网络类似的方式,解码则是一个反卷积操作的过程,这样在以较低维度的向量表征图像特征的同时,提高了闭环检测的精度,但是在闭环搜索的过程中,需要逐一比较闭环与非闭环之间的特征差异,在对闭环搜索上需要耗费较长的时间,且对于差异性较小的非闭环容易造成误判。
针对基于卷积神经网络的闭环检测存在特征提取慢和闭环检测时间久问题,Merrill等人[45]在自动编码器的基础上,利用单应性的多视图几何[46]和HOG(histogram of oriented gradient)[47]的不变性设计一种应用在嵌入式视觉闭环检测中新的无监督深度神经网络结构,通过自动编码器缓解光照对检测的影响。该方法在Places数据集中表现良好,随着更多数据的传入可以对模型进行调整,局限性在于对相似物体的区分能力较弱,位置定位精度低,但对场景的识别能力较好。
2.3 基于融合语义信息的闭环检测
目前也有研究学者在深度学习中使用基于语义对象和场景分类进行闭环检测,语义分割根据可用的对象类别对每个图像像素进行分类,图像中具有相同对象类别标签的所有像素被分在一起,并用相同的颜色表示,因此带有语义信息的地图使得移动机器人能够对环境有一个高层次的理解[48]。
在实际中移动机器人是时时运动的,绝大多数时刻都是处于一个动态的场景中。在移动机器人运动的过程中,有物体从摄像头前经过,在一定程度上会给移动机器人的视觉闭环检测带来干扰,导致在同一场景下的相似度降低。故为了提高在动态场景中移动机器人的闭环检测的精确度和检测速度,Hu等人提出了一种融合语义信息的闭环检测[49],针对基于BoVW模型的传统闭环检测方法的不足,利用Faster R-CNN模型[50]来提取场景的语义信息,语义信息与BoVW模型的融合方法可以解决BoVW模型不匹配的问题。这里的融合是BoVW模型中的特征点相似度与Faster R-CNN模型提取的语义相似度加权和,之所以使用语义信息是因为可以更合理地检查两帧图像之间的相似关系。直接使用余弦公式来计算语义相似度和特征相似度是比较难直接融合处理,故Hu等人是采用阈值法先对语义信息相似度进行过滤处理,再将语义相似度进行二值化。然后利用融合公式对语义相似度进行融合,如式(1)所示即为语义融合公式:

其中,Q A,B代表语义信息融合后的A和B图像相似度,Y A,B是用阈值法过滤后的语义相似度,S A,B是基于BoVW模型的特征相似度。
基于BoVW模型的特征向量在特征点层面可以衡量两帧图像的相似性,而语义信息相似度主要可以在动态环境中提高整体相似度,鲁棒性好,因此用加权后的语义向量可以从更宏观的语义层面来评估两幅图像的相似度,两种方法的结合充分利用了目标对象的几何外观信息,使得闭环检测在不影响准确率的基础上提高了召回率,并且该方法应用在非闭环场景中,融合后的语义相似度与仅使用特征点的相似度差异不大,使得闭环和非闭环场景的区分度增强,这样在闭环检测中提高其准确率。但是随着移动机器人的运动,其轨迹也会增加,从而导致闭环检测的时间会延长,故对于大规模场景地图的构建这块,可以考虑采用语义信息,缩减闭环检测的时间。
由于在动态环境中闭环检测存在着检测失效并且语义地图信息使用不充分问题,在SLAM的地图构建中的闭环检测可以减少累计误差和起到重定位的功能,除此之外,关于在动态室内环境下的闭环检测时易出现感知混叠的检测问题,所谓的感知混叠就是在不同的地方出现相似的特征,感知混叠是基于外观的闭环检测方法失效的主要原因之一,许多基于BoVW的方法只考虑真实的闭环检测的相似特征,故郑冰清等人提出了一种在视觉SLAM中采用融合语义信息应用在闭环检测和语义地图构建上[51],先使用YOLOv3深度神经网络[52]对闭环检测中的关键帧进行二维图像的语义标注,然后在此基础上对随机场景模型中的语义标注信息与场景分割的聚类信息进行融合并构建语义地图,闭环检测是基于关键帧的语义标注信息,通过将运动特征点去除的思路对BoVW模型进行改进,从而在动态环境中去除特定动态目标实现高精度的闭环检测。在该方法中使用YOLOv3目标检测算法对关键帧的场景目标进行检测和边框提取,通过关键帧的位姿、语义标注信息和特征点向量集进行场景的闭环检测,如图8所示为基于融合语义信息的闭环检测算法流程图。
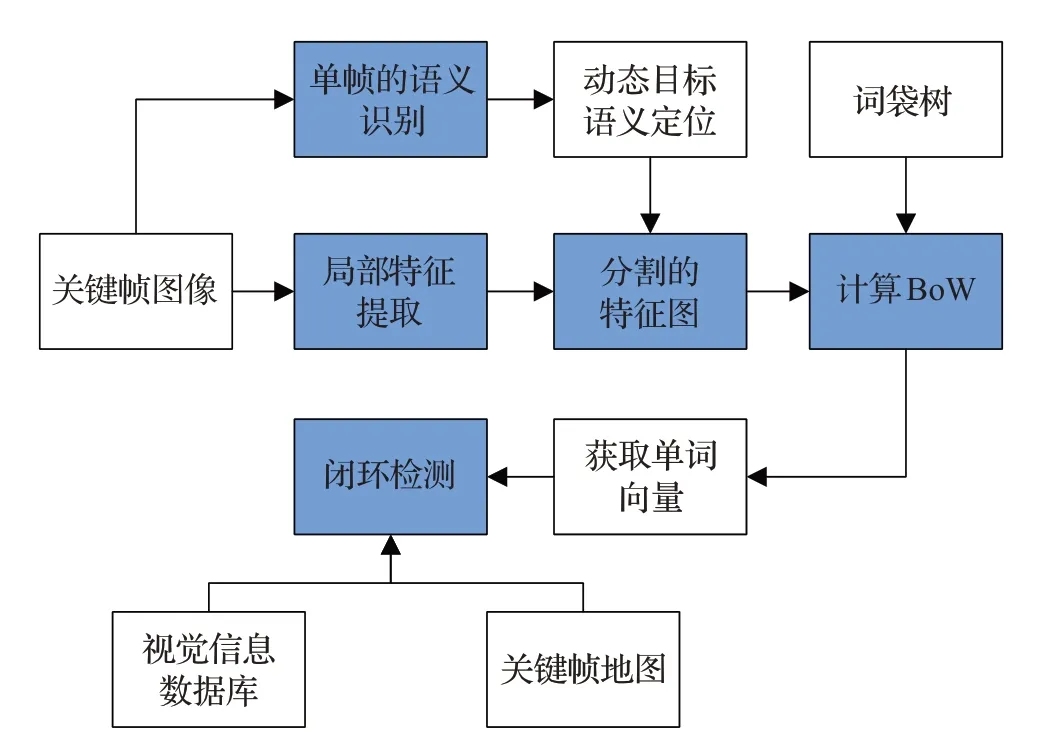
图8 基于融合语义信息的闭环检测算法流程图Fig.8 Flow chart of loop closure detection algorithm based on fusion of semantic information
虽然Hu等人提出的融合语义信息的闭环检测是在BoVW模型和Faster R-CNN模型中采用权重调整的方式,但在关键帧的跟踪和地图的构建上所实现的计算量较大,故考虑到在室内的运动物体单一且都是以人为主,这样可以针对特定环境中的目标进行语义检测并通过去除运动目标从而提高闭环检测的鲁棒性,值得注意的是在低动态或静态场景下,该方法的闭环检测效果与传统BoVW方法效果相似,甚至在某些数据集上没有传统方法好,这是因为在某些数据集的场景中不包括动态物体出现在闭环中。因此在动态环境下使用语义信息融合的闭环检测比静态加权的闭环检查算法好且可以起到重定位的效果。
通过总结和比较基于自动编码的无监督深度神经网络和基于融合语义信息的V-SLAM闭环检测方法,可以发现这两类方法多数是解决机器视点变化和应用在动态环境中,具体的方法比较性能如表2所示。
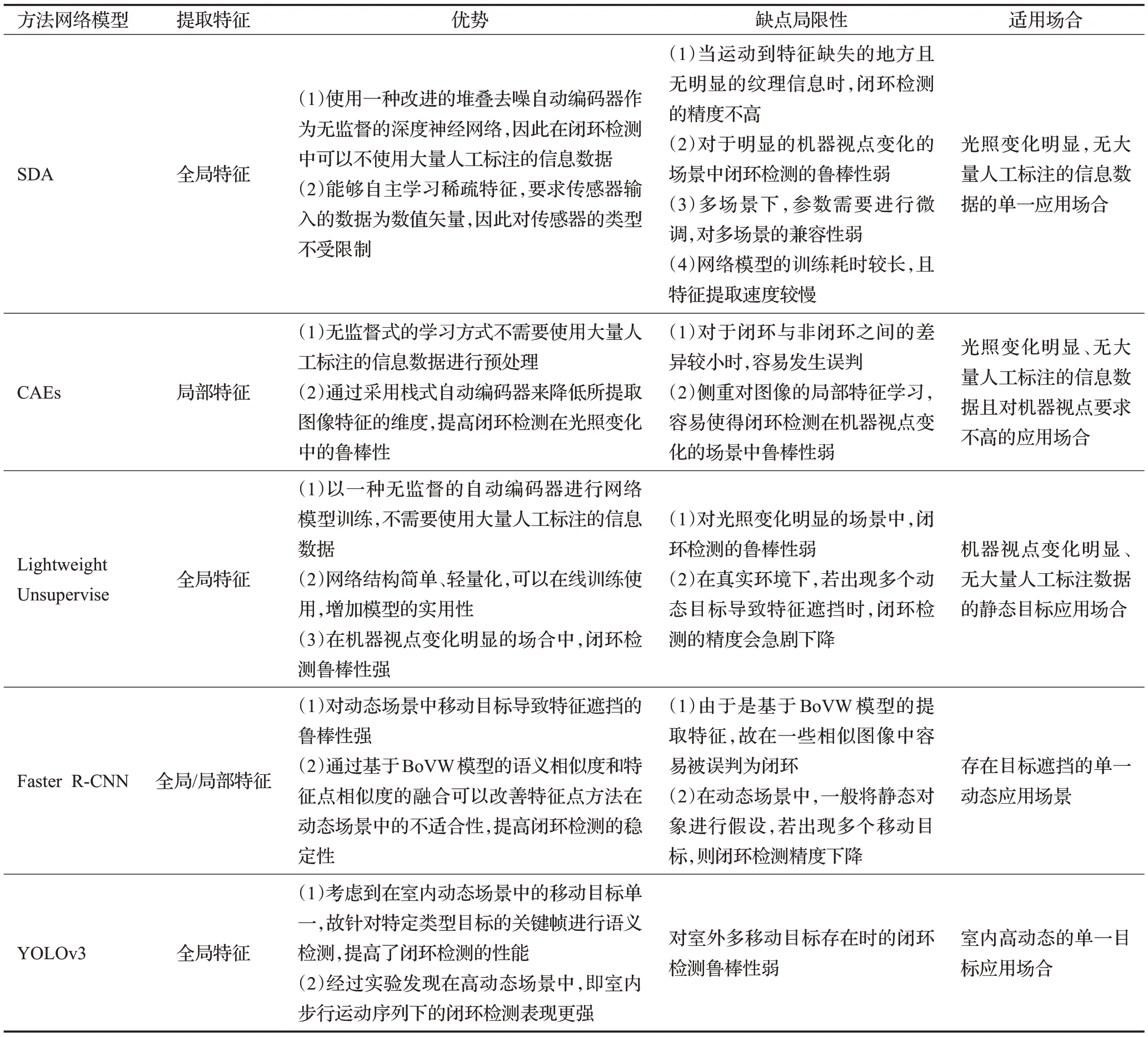
表2 两类相关V-SLAM闭环检测方法的性能比较Table 2 Performance comparison of two kinds of correlated V-SLAM loop closure detection methods
多数基于语义信息的闭环检测采用与信息融合的方式,通过对动态环境中的移动目标进行语义标注,然后进行特定的预训练,主要是依赖于所检测的场景数据之间的关联和场景描述。但是通过比较发现,该类型的动态环境主要是适用在单一移动目标,一旦出现若干个移动目标,则对闭环检测的鲁棒性会造成较大影响。
3 闭环检测的性能评价
综上所述对于每种不同的深度学习算法应用在VSLAM闭环检测中各有优缺点,表3所示为基于卷积神经网络、基于自动编码器和基于语义信息的闭环检测三类方法的总结表。

表3 基于三类方式的闭环检测表Table 3 Loop closure detection table based on three types of methods
可以发现基于深度学习的闭环检测算法都是针对解决复杂环境中某一类型的影响因素,目前还没有哪种算法可以将所有影响因素都可以更好地解决,这个也是后续值得关注的地方所在。
在闭环检测中对于其性能指标的评价主要有:准确率-召回率、计算时间。由于在闭环检测中会出现感知混叠的问题,例如可能会出现同一个地方拍摄的照片在不同时刻由于受到光照等影响导致图像看起来不一样,这个就是假阴性(false negative)[53],另一个是两个不同的地方所拍摄的照片看起来相似即假阳性(false positive)。如图9所示为两个例子图像。

图9 两个假阳性与假阴性示例图Fig.9 Two examples of false positive and false negative graphs
故在闭环检测中对此的分类结果如表4所示。

表4 闭环检测分类结果Table 4 Loop closure detection classification results
因此在闭环检测中,存在真阳性(true positive,TP)、假阳性(false positive,FP)、假阴性(false negative,FN)和真阴性(true negative,TN)这四个指标,故在闭环检测中的数据集统计这四个值并希望TP和TN的值高,FP和FN的值尽量低,故对此用准确率(Precision)来计算其TP在TP和FP中的概率,召回率(Recall)来计算TP在TP和FN中的概率。
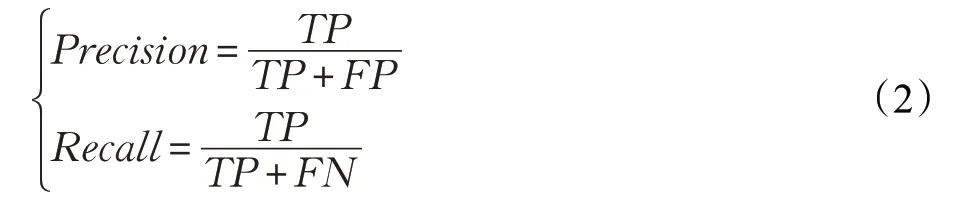
在闭环检测中的准确性就是在检测出所有的闭环中真实的闭环概率,召回率即在所有真实的闭环中能够正确地被检测出来的闭环概率。这两者之间存在一种矛盾的关系,即当随着闭环检测召回率增大时,其准确率会随之下降,这是因为当提高闭环检测算法中的某个阈值时,使得检测算法变得更为严谨,这样所检测出的闭环个数会减少,准确率得以提高,但是正因为所检测的闭环个数下降,可能导致原来是闭环的地方有被遗漏,导致其召回率下降。如果选择宽松的算法配置环境,这样算法所检测出来的闭环的个数会增加,故其召回率会提高,但是这很容易出现一些不是闭环的情况也被算法检测出来,所以准确率下降。值得注意的是在VSLAM中,研究者所注重的更多的是闭环检测的准确率,对召回率相对来说宽松些,希望在召回率较大的同时其准确率可以保持好的表现,故采用准确率—召回率曲线来反应闭环检测中的综合性能指标,且对于数据集的使用如表5所示。
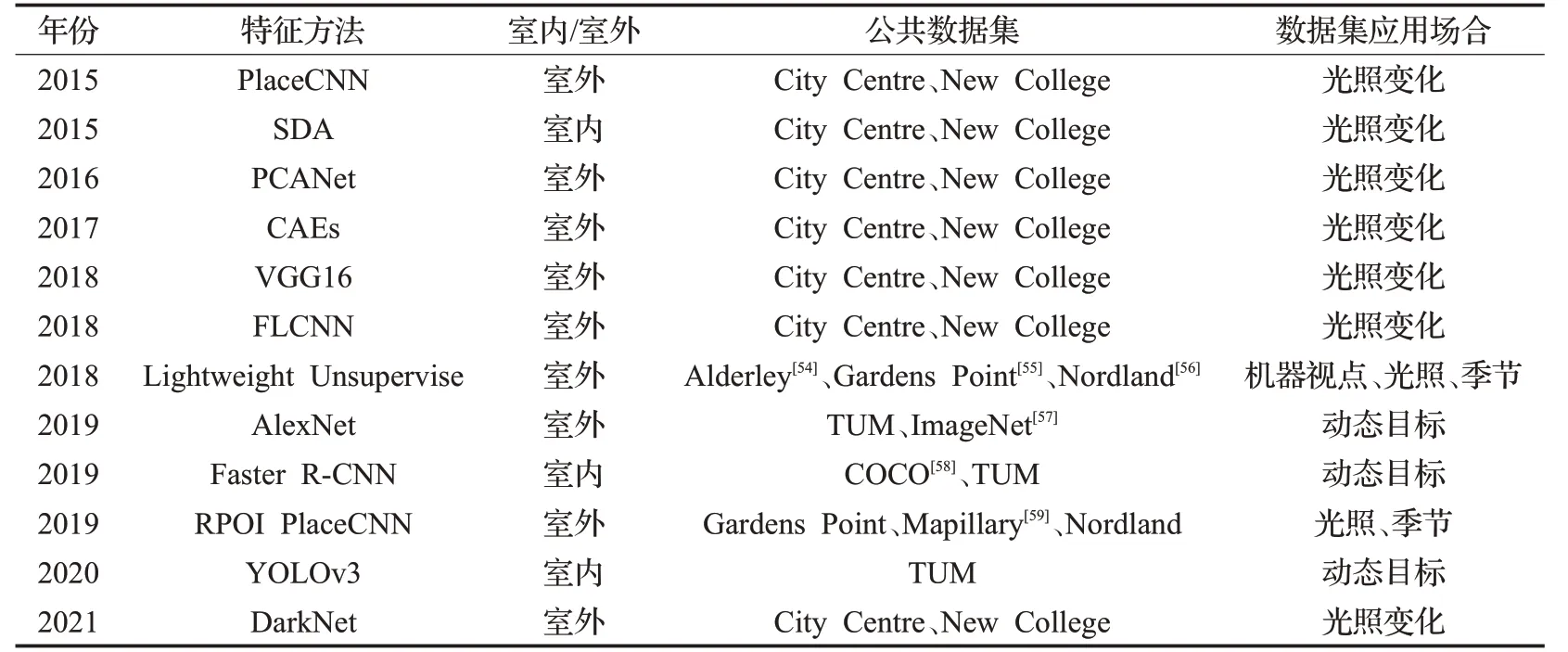
表5 闭环检测中不同深度学习方法数据集Table 5 Data sets of different deep learning methods in loop closure detection
每种数据集都是针对不同的适用环境,例如Nordland数据集由四个通过挪威的火车旅行的时间同步视频组成。每段时长约9 h的序列中每一个都对应于不同的季节,除了季节性变化之外,图像还包含由于火车的飞快速度所造成的图像极度模糊。而Gardens Point数据集则是包括三次穿越澳大利亚布里斯班的QUT校园。在这个数据集中,有两个白天遍历和一个夜晚遍历校园的图像数据,主要是针对不同光照变化场景下的校园图像。
深度学习在闭环检测上的应用绝大多数做的实验都是与传统的人工设计特征方法做比较,例如BoVW、GIST和FAB-MAP等,极少数会将其所提出方法与其他深度学习方法进行实验比较,少数会在之前深度学习的方法基础进行改进后比较,正如在PlaceCNN的基础上Xia等人提出用PCANet来提取闭环检测的图像特征,在City Centre和New College这两个公共数据集进行实验,如图10所示为基于PCANet方法的闭环检测准确率-召回率曲线图。
从图10中可以看出基于PCANet的闭环检测方法不仅与传统的人工设计特征BoVW和GIST进行比较,还与基于PlaceCNN和自动编码器的深度学习方法做了对比研究,通过两种数据集表明,随着召回率的增加,基于PCANet的闭环检测准确率要优于其他几种闭环检测算法。除此之外在计算效率上,根据Xia等人的实验结果显示基于PCANet的闭环检测计算效率要快于其他的算法。在对深度卷积网络应用在闭环检测中,Xia等人曾经还将所流行的数种卷积网络应用在闭环检测中并进行了相互间的对比,例如:AlexNet、CaffeNet和GoogLeNet[60]等,所用的实验平台是搭载Intel Xeon E5-2603 1.8 GHz处理器和39 GB内存,发现在City Centre和New College两个公共数据集所得的特征准确率和平均处理时间如表6所示[61]。

表6 部分闭环检测特征准确率和平均处理时间Table 6 Feature accuracy and average processing time of partially loop closure detection

图10 两个数据集上的准确率-召回率曲线图Fig.10 Accuracy-recall rate curve on two data sets
在研究闭环检测中的所有算法无外乎是围绕感知偏差和感知变异两方面来处理,因此在对闭环检测的算法实现上主要是考虑处理的哪个方面,正如郑冰清等人所提出在视觉SLAM闭环检测使用融合语义信息[51]、张括嘉等人将语义信息和拓扑关系相结合的方法[62],这样的处理目的是为了使得移动机器人可以在动态环境中的闭环检测有更好的鲁棒性。与目前所提出的一些进步的开源V-SLAM系统,例如基于BoVW和PlaceCNN等更多的是依赖于静态环境假设,相比较起来可能在静态环境中其鲁棒性没有前者强或与之相平,但是在室内中动态环境下其准确率-召回率和系统算法运行的时间都要远优于前者。闭环检测的目的是减少系统误差,使之对于后端优化方法可以更好地配合起来,故如何设计一个合理的闭环检测依旧是一个值得研究的问题所在。表7所示为各类基于深度学习方式的V-SLAM闭环检测比较。

表7 各类基于深度学习方式的V-SLAM闭环检测比较Table 7 Comparison of various types of V-SLAM loop closure detection based on deep learning methods
表7中√的个数越多,对应算法的闭环检测时间越快。通过比较各种基于深度学习的闭环检测算法,发现绝大多数算法都会与基于PlaceCNN和基于SDA的闭环检测算法进行性能比较,主要比较闭环检测精确度、特征提取速度和闭环搜索三个方面,且大多数算法都会用到City Centre和New College两个公共数据集。因此本文将基于PlaceCNN和基于SDA的闭环检测算法作为基准,对本文提到的部分闭环检测算法进行性能等级划分,划分的结果如表7所示。基于SDA的闭环检测算法的闭环搜索时间比PlaceCNN快。但是值得注意的是并排比较不同论文的结果不是最佳的方式,因为这些实验是在不同的配置环境下完成的。尽管如此,考虑到参考文献中提出的算法与基准算法比较的环境相同,因此本文还是采用这种通用基准比较方式对闭环检测算法进行性能比较,以便读者对它们的大致情况有一个粗略的了解。从表7可以看出在特征提取上采用YOLOv3的时间较快,而使用基于VGG16的闭环检测使用了自适应粒子滤波器算法,只需计算与粒子数量相应的余弦距离,速度基本不受传感器输入数据量增加的影响,故在闭环搜索上速度较快。
4 V-SLAM闭环检测的未来研究展望
移动机器人的闭环检测从传统方法到深度学习的过程中,目前研究的难点问题主要集中在以下三个方面:
(1)在自然环境变化中提高闭环检测的鲁棒性。闭环检测不仅受到自然环境中的光照、季节等变化的影响,还面临恶劣环境中的大雾或者下雨等其他自然因素所造成的感知混叠的难点问题,感知混叠是引起基于外观的闭环检测失效的主要因素之一。如何缓解基于深度学习的闭环检测方法中存在的感知混叠难点问题是一个开放性课题。目前采用多传感器融合的方式来提高自然变化中闭环检测的精确度和稳定性是一个趋势所在。
(2)在动态环境中有效处理多种视觉目标所造成的闭环检测失效的影响。在动态场景中,如果移动目标的特征点过大并在关键帧中占据较大比重,那么一旦在不同场景中再次检测到相同的移动目标,将会很容易被误判为闭环。其次,若多个目标在不同场景中所出现的次数不同,会引起关键帧中的特征点不匹配,从而导致在相同场景中漏判为闭环。这些都是在实际环境中多视觉目标检测对闭环检测造成的难点问题。
(3)将SLAM闭环检测算法嵌入到移动机器人的SLAM系统,并要求达到移动机器人的实时性操作。SLAM不是各部分算法的简单拼接,而是一个完整的系统,其中移动机器人一直处于实时运行状态,虽然VSLAM中的闭环检测和地图构建是并行运行的,但随着移动机器人的运动时长增加,视觉传感器所传输的图像数据增加,构建的地图尺度也扩大,因此闭环检测的帧与帧之间的对比消耗时间增多,这对闭环检测算法的时间复杂度和空间复杂度都是一个考验。
虽然目前对闭环检测在自然环境变化、多目标和实时性等难点问题的研究颇多,但是在实际作用中的效果还有待提升。随着对移动机器人应用要求的不断提高,机器人系统的协同运作、系统轻量化和高性能计算将成为未来关注的课题。在移动机器的未来应用中,多移动机器人系统的协同运作的研究对移动机器人的应用具有重要意义。协同运作的多移动机器人系统可在大型、危险和较为复杂的场景中代替人执行关键性的特殊任务。如何将SLAM的闭环检测运用到移动机器人的协同系统中也是未来的一种研究趋势。由于SLAM的闭环检测所接受到的输入数据是一种视频流的方式,因此要想高效处理输入数据,且不应占用较大的计算资源,则需要利用高性能的计算设备来实现更高精度的闭环检测。此外对于SLAM系统应该朝着轻量化方向发展,可以运用到各种设备中。
5 结语
本文以基于深度学习的V-SLAM闭环检测为背景,首先阐述现有的V-SLAM闭环检测深度学习方法,通过梳理发现每种不同的深度学习方法都是针对于传统方法的局限性进行解决,例如对于光照和季节变化敏感所导致的检测失效等。
从所回顾的文献中可以发现基于深度学习的闭环检测方法具有较强的鲁棒性,但是否是真实的闭环检测依旧是一个开发性问题,同时基于深度学习的算法计算量较大,在真实环境中可能还存有移动机器人的视角变化等因素,因此在闭环检测的研究中未来还存在许多方法。
最后随着深度学习的快速发展,利用深度学习解决SLAM中的闭环检测已然是一个新兴的研究方向,在移动机器人上可能不只有一种传感器,还可能利用多种传感器来进行多源信息融合,这样可以提高SLAM闭环检测的鲁棒性,目前在理论上的实现是远超于实践,故SLAM的闭环检测在未来发展中具有更多的意义,要想展示出真正意义上的自主定位和地图构建,在解决现实方案中有着巨大的发展空间。
