融入特征融合与特征增强的SSD目标检测
2022-06-09刘建政崔学荣李传秀
刘建政,梁 鸿,崔学荣,钟 敏,李传秀
中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580
目标检测是计算机视觉领域的一个重要研究方向。特别是近几年来随着深度学习卷积神经网络(convolutional neural network,CNN)的应用,基于卷积神经网络的目标检测算法在精度与速度上都得到了显著发展。目前主流目标检测算法主要分为两类,一类是基于回归的一阶段目标识别算法,如SSD[1]、DSSD[2]、DSOD[3]、RSSD[4]、FSSD[5]、YOLO[6]等模型,另一类是基于候选区域的两阶段目标识别算法,如R-CNN[7]、SPPnet[8]、Mask-RCNN[9]、Fast R-CNN[10]、Faster R-CNN[11]、R-FCN[12]、ZBD13]
等模型。通常两阶段目标检测算法具有更高的精度,一阶段目标检测算法具有实时处理的能力,但是会牺牲精度。无论是一阶段目标检测算法还是两阶段目标检测算法,CNN都发挥着至关重要的作用。
一阶段目标检测器由于其速度与精度的平衡性,得到了广泛关注。在这些目标检测算法中,SSD在精度和速度上都是相对比较优秀的一阶段目标检测算法,目前多数新提出的单级目标探测器都以它为基线。SSD先通过基础网络进行特征提取,然后通过辅助结构中的特征层来提取具有更多语义信息的高层特征映射。它使用了多个卷积层来进行目标检测,这大大提高了检测精度。当然,SSD也有它的缺点,一是Conv4_3是一个浅层,语义信息少,缺乏足够的信息来判断较小的对象;二是SSD只增加了几个辅助卷积层,没有充分利用提取到的特征映射,不够具有代表性。
为了提高SSD检测算法对小目标的检测精度,文献[2]在SSD模型上充分利用深浅层特征信息,结合残差网络,提出了DSSD模型,但是该方法在特高检测精度的同时极大地降低了检测速度。文献[14]提出了SNIP算法,该算法主要思想是借鉴多尺度训练(multiscale training,MST)的思想,并且只对尺寸在指定范围内的目标回传损失,对小目标检测效果显著。文献[15]提出的Feature-Fused SSD算法借鉴了特征金字塔[16](FPN)的思想,利用融合高层的语义信息去感知低层的语义信息。RFBNet[17]将RFB(receptive field block)模块与SSD网络结合,有效增大了感受野(receptive field),提高检测精度。
本文通过在SSD基础上引入设计的特征融合模块和特征增强模块来提高SSD对于小目标的检测精度。一般来说,较深层次的高层次特征对分类子任务的判别能力更强,而较浅层次的低层次特征对目标定位回归子任务的判别能力更强。此外,低层特征更适合于表现简单的对象,而高层特征更适合表现复杂的对象。
本文设计了一对特征融合模块(feature integration block,FIB)将骨干网提取的特征分别进行融合,然后再通过特征增强模块(feature enhancement block,FEB),充分利用深层特征层语义信息以提升浅层特征网络对小目标的表征能力。此外,本文还将SSD辅助结构中简单的卷积层使用本文设计的特征增强模块进行替换,最后增加浅层特征映射默认先验框数量。结果表明本文设计的网络模型(FIENet)对小目标具有更强的检测能力,如bird、bottle、chair、plant类检测精度有较大的提高,整体目标的平均检测精度(mAP)相较于其他检测算法也有很大提升。
1 网络结构设计
1.1 SSD
SSD是一种经典的一阶段目标检测算法,其结构如图1所示,基本的SSD模型是以VGG16[18]网络作为基础模型,在此基础上添加了辅助结构,即多个卷积层和池化层。为了充分利用特征映射信息来提高检测精度,加入RPN网络的特征金字塔的检测方式以通过选取不同的卷积层的特征图来增强检测效果,如图2中的8×8特征映射(b)和4×4特征映射(c),这样的好处是比较大的特征映射用来检测较小的目标,比较小的特征映射用来检测较大目标。在训练过程中,SSD只需要一个输入图像和图像中每个检测物体的真实标记框。
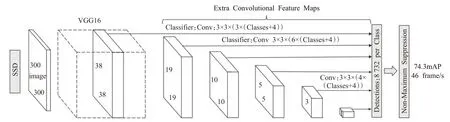
图1 SSD网络结构Fig.1 SSD model structure
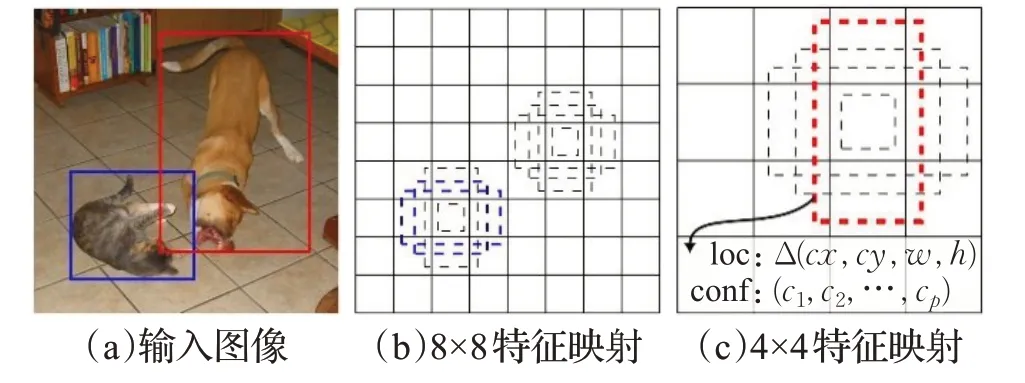
图2 匹配过程Fig.2 Matching process
SSD采用FasterR-CN中的Anchor boxes机制,在特征图的各个单元设置不同长宽比的默认先验框,使用先验框和目标检测框进行偏差计算,提高检测精度,在图2中可以看到每个单元使用了4个不同尺寸的先验框,输入图片中的猫和狗其长宽比不同,网络会分别采用最适合它们形状的先验框来进行训练,(c)中的loc表示边界框的定位信息,包含(cx,cy,w,h)4个值,分别表示边界框的中心坐标以及宽高,conf表示每个类别的置信度,如PASCALVOC数据集中有20类,则会有对应的21(p=21)个c值,包含了背景类;SSD继续沿用了YOLO9000[19]的回归思想,提升了目标检测的速度。
骨干网络VGG16用于特征提取,其结构中各层参数如表1所示。卷积过程如图3所示,图3中的数字如300×300×64,其中的300×300表示为当前特征图大小,64表示上层通道数(滤波器个数)。特征图卷积过程如图4所示。
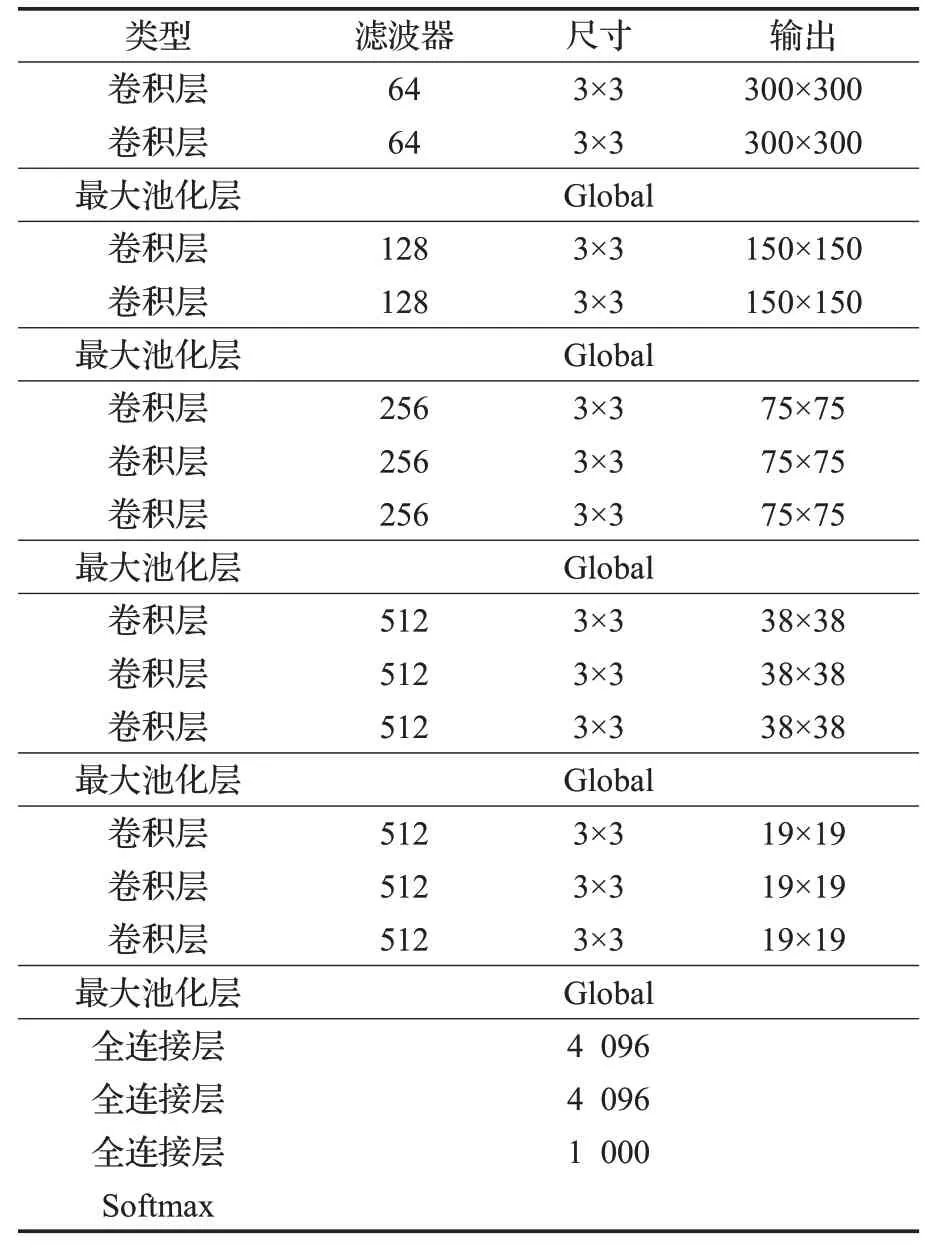
表1 VGG16结构各层参数Table 1 Parameters of each layer of VGG16 structure
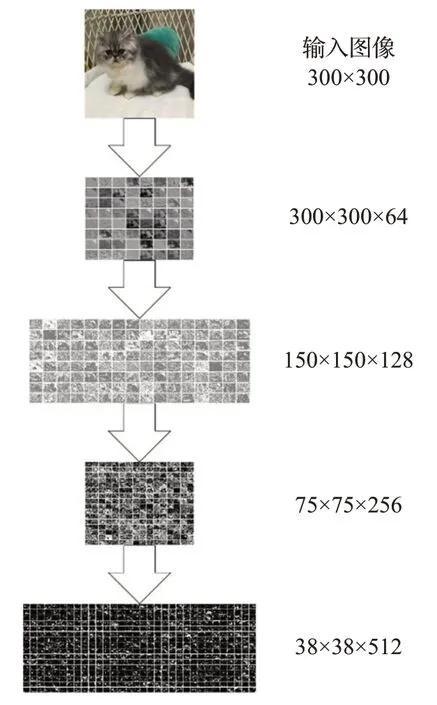
图3 卷积层仿真演示Fig.3 Convolution layer simulation demonstration
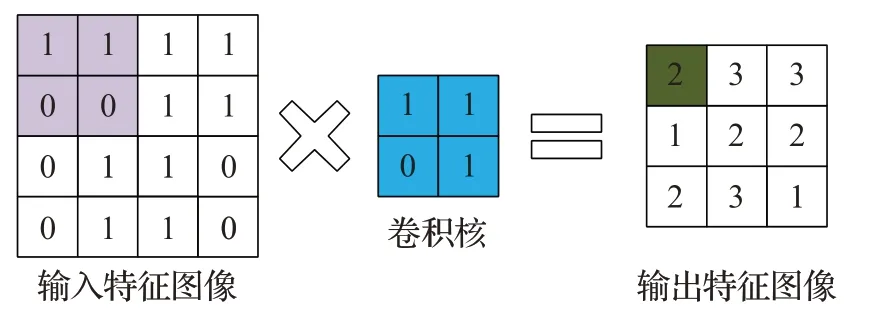
图4 图卷积过程演示Fig.4 Demonstration of graph convolution process
1.2 基于SSD的改进算法
本文提出的FIENet是基于SSD网络模型的改进,其整体网络结构如图5所示。SSD中的骨干网络VGG-16没有批量归一化层,本文在骨干网上增加了批量归一化层,使得梯度更新更加稳定。卷积神经网络中的浅层网络特征映射尺寸大、感受野小、细节特征信息丰富,对目标定位回归子任务的判别能力更强,适合于小目标等表现简单的对象。深层网络特征映射尺寸小、感受野大、语义特征信息丰富,对分类子任务的判别能力更强。因此对深浅层特征层进行融合可以提高浅层增强网络对小目标的检测能力。原始的SSD仅关联了Conv4_3、Conv10_2和Conv11_2特征层的4个默认先验框,以及Conv4_3、Conv11_2特征层的6个默认先验框,由于浅层的特征映射对于小目标检测至关重要,因此在Conv4_3这样的浅层特征映射中添加更多的默认先验框,可以提高小目标检测性能。针对SSD网络模型特点,本文首先提出了一对特征融合模块,该模块将深浅层特征信息进行充分融合来提高网络模型对小目标的检测能力;然后提出了特征增强模块,其中FI代表特征融合模块,FE代表特征增强模块对融合的特征以及深层特征进行增强,也相对加深了网络的深度和宽度,最后在浅层Conv4_3上设置了6个默认先验框。
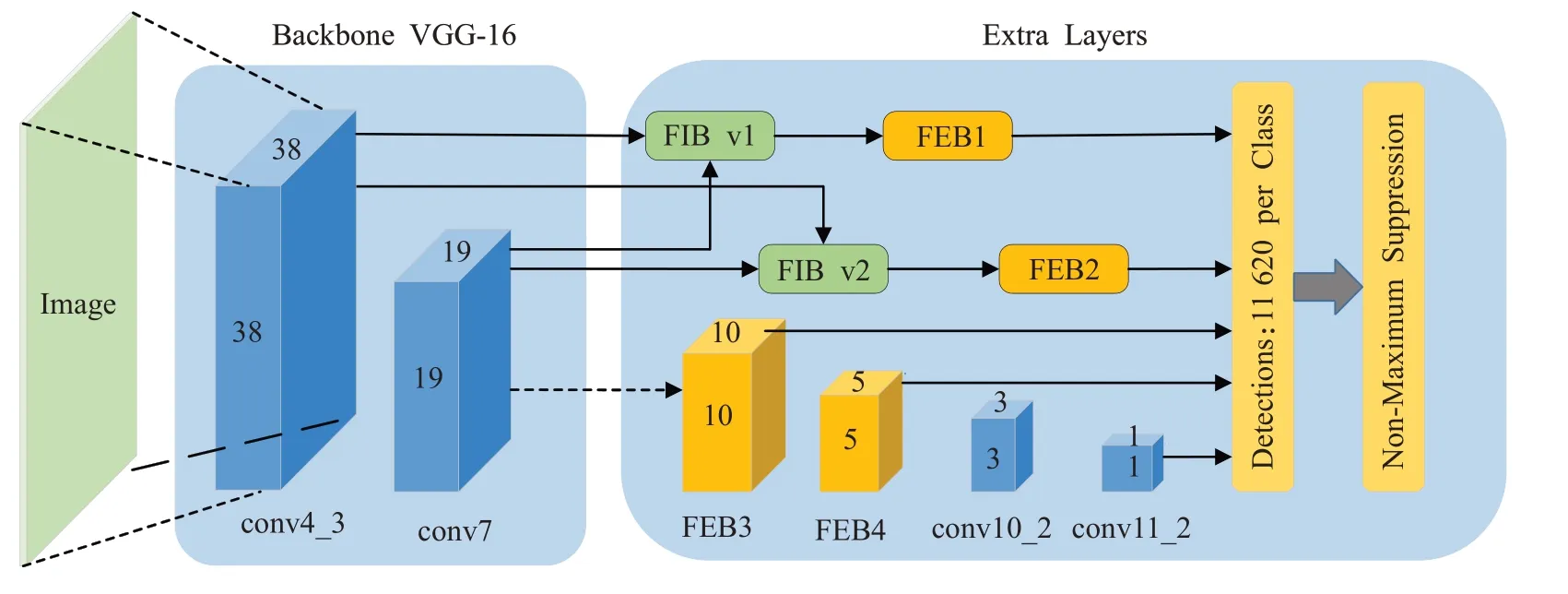
图5 FIENet网络结构Fig.5 FIENet structure
FIENet模型中的6个检测特征层参数如表2所示。
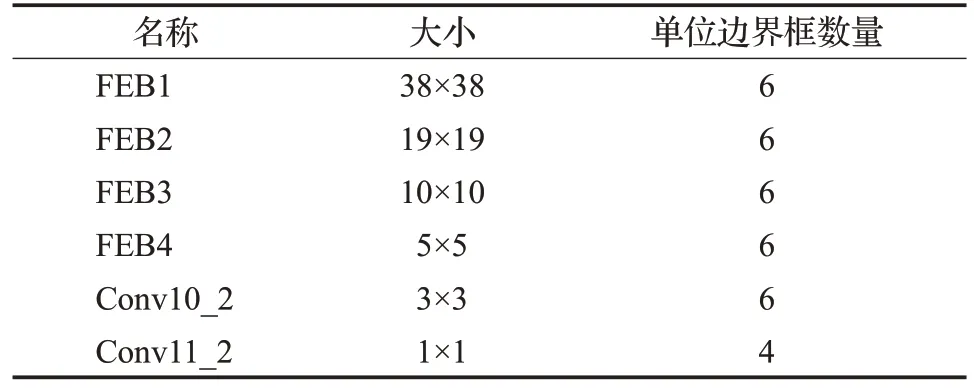
表2 FIENet检测层参数Table 2 Parameters of FIENet detection layer parameters
2 SSD算法改进
2.1 特征融合
在原始的SSD中,较浅的层,如Conv4_3,具有丰富的细节信息,但是没有充分的语义信息,为了充分利用高层特征层中具有平移不变性的特征语义信息,本文设计了特征融合模块(feature integration block,FIB),如图6所示,使用一对特征融合模块对Conv4_3和Fc7两个特征层进行连接,建立两个特征层之间的联系,整个特征融合模块使用了Conv4_3和Fc7的特征映射来丰富和补充彼此,在增加了不同层之间特征映射关系的同时,也保留了相对完整的语义信息,提高网络对小目标的检测准确率,增强浅层网络对小目标的检测能力。通过核大小为11的卷积层,即使用padding=0的11卷积核在这些特征图上做卷积操作,调整通道大小。
图6(a)中,对于两个具有不同通道数的输入:X1∈RC×H×W、X2∈RC×H×W,分别使用11和33的卷积进行通道变换,分别产生Y v1∈RC×H×W、Y v2∈RC×H×W:
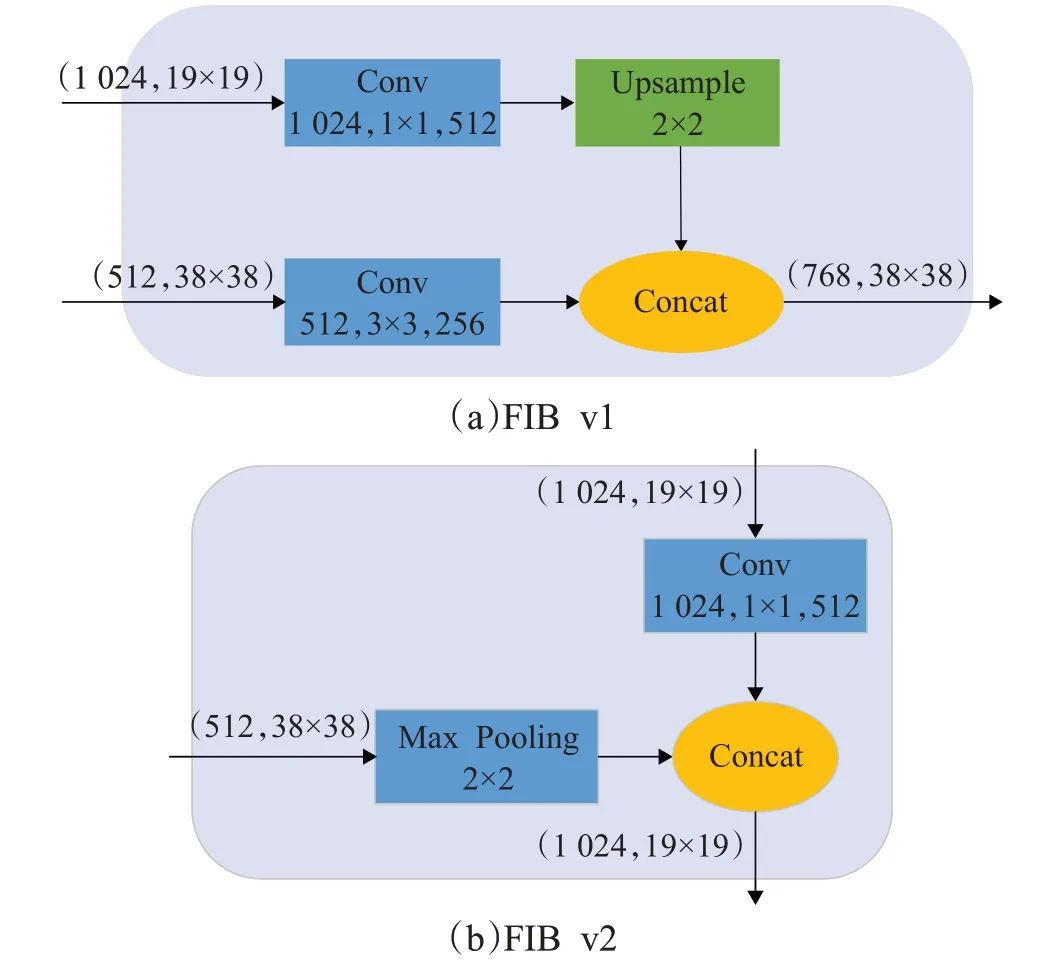
图6 特征融合模块Fig.6 Feature integration block(FIB)

其中,CBR(X)表示对输入进行一个Conv+BN+ReLU操作,然后对Yv11进行下采样操作产生U1∈RC×H×W:

FIv1(图6(a))接收两个尺寸不同的特征映射,对于Fc7的特征映射通过上采样操作使得其特征图与Conv4_3尺寸相同,然后进行连接操作。FIv2(图6(b))中,Conv4_3特征层通过池化得到与Conv7相同的特征映射尺寸,然后进行连接操作。这提高了小目标检测精度,也在一定程度解决了重复框问题。然后将融合结果通过后续的特征增强模块。
使用梯度加权类激活映射方法对Conv4_3、FC7以及特征融合后的特征映射进行展示,如图7所示。其中(b)、(c)、(d)、(e)中的左图为灰度图,中图为热力图,右图为热力图与原图融合结果展示。从图中可以看出,(b)中的细节信息丰富,(c)中语义信息丰富,将两个特征层进行融合后得到的特征映射的热力图为(d)、(e)。(d)的细节信息少于(b),语义信息多于(b);(d)的语义信息少于(c),细节信息多于(c);(e)与(d)相类似。
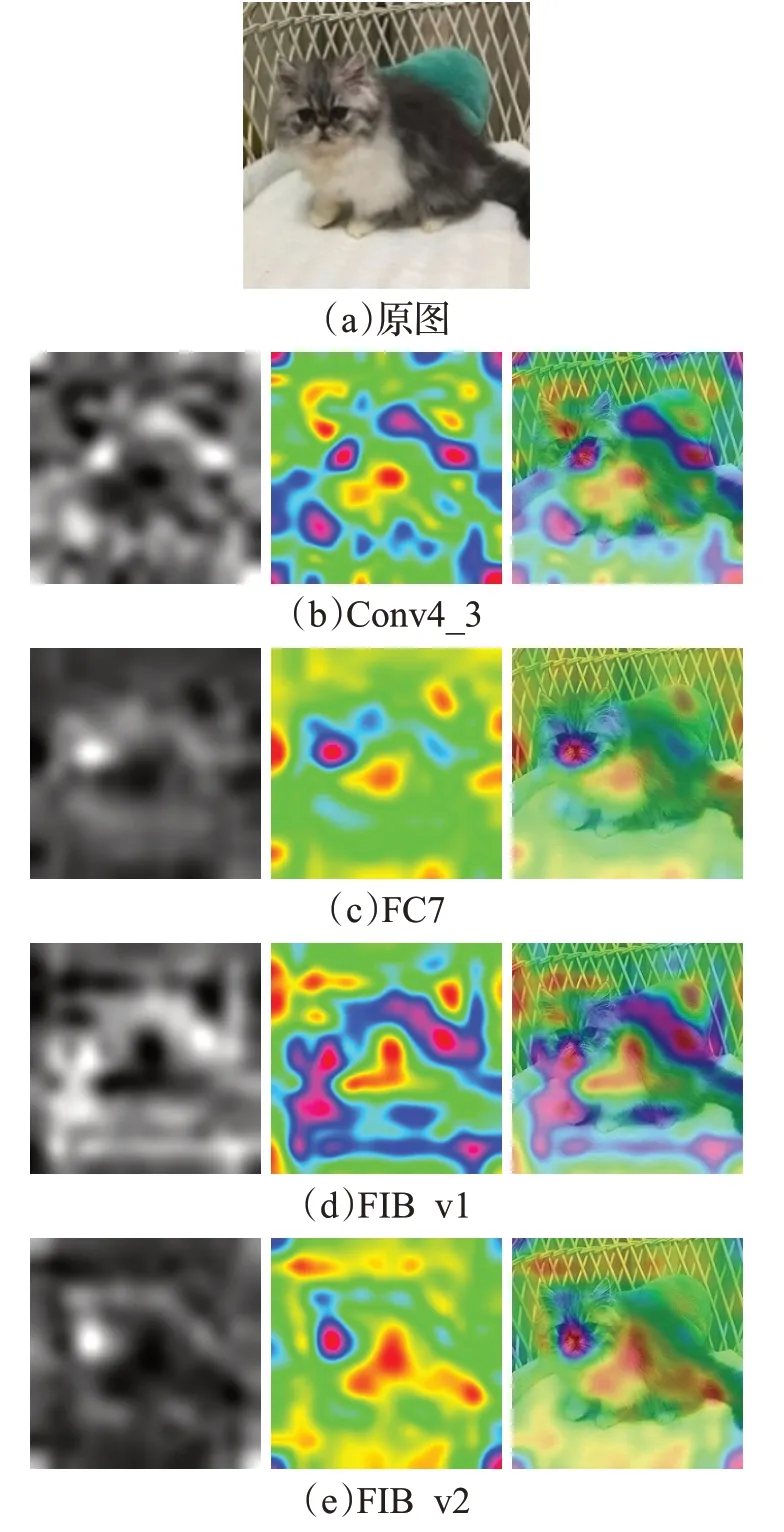
图7 特征融合过程仿真演示Fig.7 Simulation demonstrationof feature integration process
2.2 特征增强
对于辅助结构,SSD只增加了一些额外的卷积层,本文认为这些卷积层不够具有代表性,先前的研究工作[20-21]已经证明加深网络的深度以及加宽网络的宽度在一定程度上可以提高网络的性能,但是这在一定程度上会使得网络的训练变得越来越困难,主要原因是因为会出现梯度消失或梯度爆炸的问题。受残差网络(Res2Net[22])和注意力机制(attention)的启发,在融入注意力机制[23]的残差模块(res2 Block)基础上设计了特征增强模块(feature enhancement block,FEB),如图8所示。
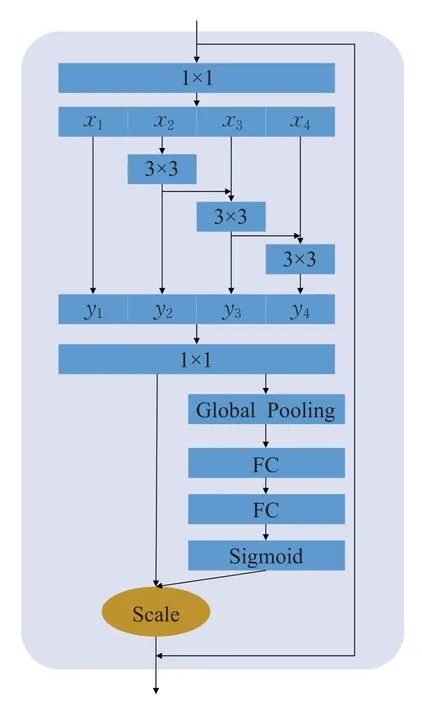
图8 特征增强模块Fig.8 Feature enhancement block(FEB)
Res2 block通过增加块内的感受野,而不是一层一层地捕获图像中更细粒度的不同级别的尺度,从而提高CNN检测和管理图像中物体的能力。文献[24]证明较大的感受野可以学习很多的上下文信息,文献[25]提出SENet,如图9所示,通过学习的方式自动获取到每个特征通道的重要程度,根据loss去学习特征权重,使得有效的特征映射权重大,无效或者效果小的特征映射权重小,从而达到更好的训练效果。
在图9中,其Ftr是一个传统的卷积变换,X代表输入,W、H为特征映射的长和宽,C为通道数。U表示为一个C×H×W的特征映射。
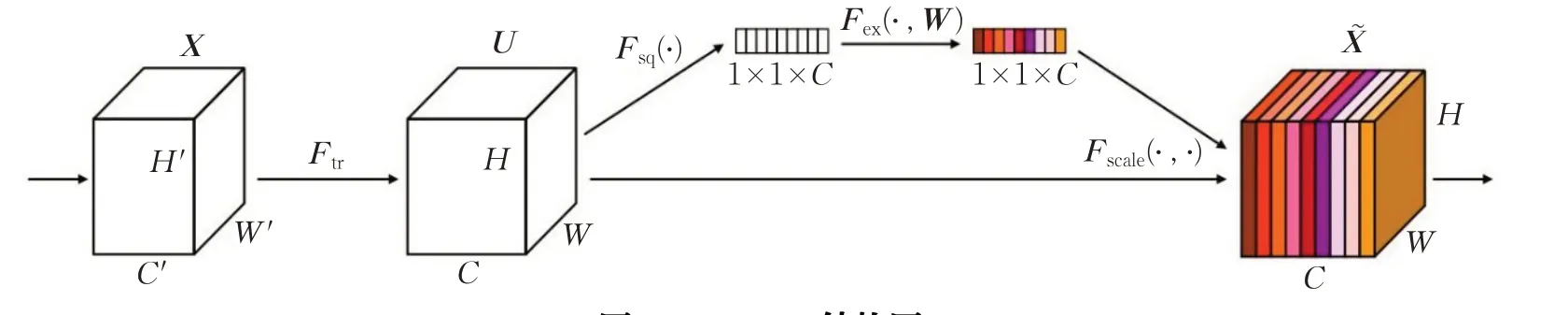
图9 SEBlock结构图Fig.9 Structure of SEBlock
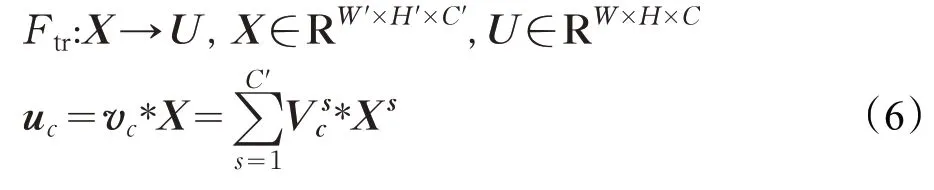
其中,u c表示U中的第c个二维矩阵,v c表示第c个卷积核,X s表示第s个输入。
经过挤压操作Fsq()·后,变成了一个1×1×C(s)的特征向量,特征向量的值由U确定。

本文提出的特征增强模块对残差模块(res2 block)进行了修改,使用Mish[26]激活函数而不是ReLU[27]函数进行激活。常用的激活函数曲线如图10所示。激活函数的主要作用是引入非线性因素,提供网络的非线性建模能力,使得神经网络具备分层的非线性特征映射学习能力。从图10中可以看到,对于x∈R,ReLU函数为:
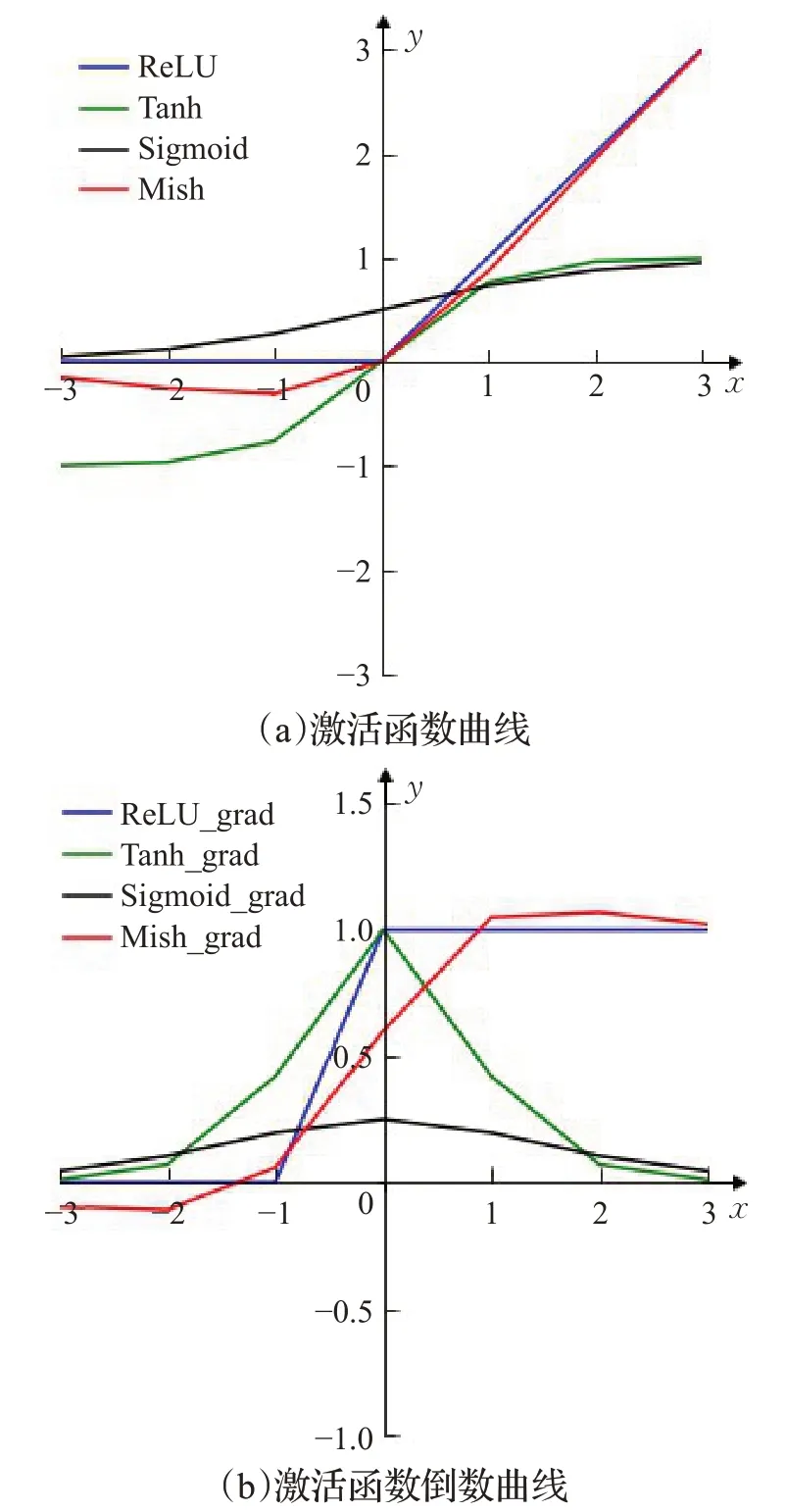
图10 四种常用激活函数图像Fig.10 Shapes of four activate functions
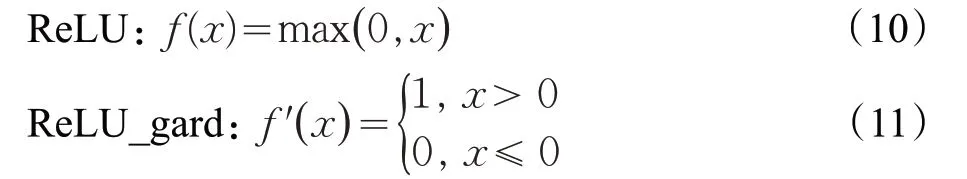
当x<0时,ReLU硬饱和,当x>0时,不存在饱和问题,可以保持梯度不衰减,以缓解梯度消失问题。但是在训练过程中,部分x会落入硬饱和区域,导致无法更新其对应权重,影响网络的收敛性。Mish激活函数对于x<0的输入可以获得轻微值,而不是ReLU函数中的硬饱和,可以得到更好的梯度流,并且平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。对于x∈R:
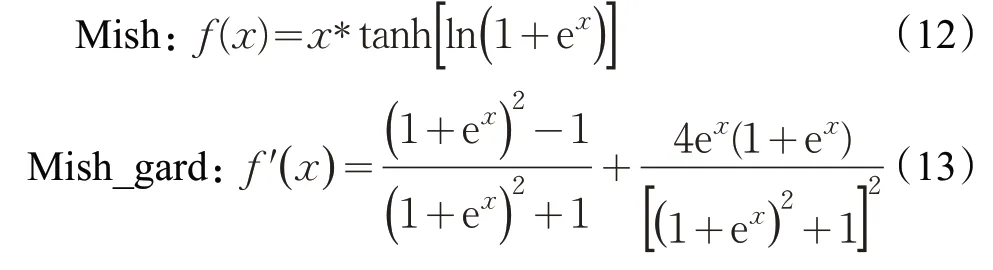
在特征增强模块中,输入特征图的通道数通过11的卷积分成4份,最后级联起来。通道间采用残差连接,每个通道的卷积深度不同,感受野不同,语义信息不同,输入特征信息经过不同的通道后级联起来可以综合各个深度的语义信息和细节信息,进一步增强细节语义信息,将有利于检测不同尺度的目标,提高了对小目标的检测精度。然后通过注意力机制,把每个通道内的特征值相加然后再平均,其后的两个全连接层组成一个瓶颈结构来构建通道间的相关性,使得特征具有更多的非线性,在减少参数量和计算量的同时可以更好地拟合通道间复杂的相关性,通过一个Sigmoid函数获得0~1之间的一维权重,最后通过缩放(scale)操作使不同通道乘上各自的权重,增加对关键通道的注意力。特征增强模块深化了整个网络,这在一定程度上提高了网络的检测准确率;而且结构间采用残差连接,也就是“skip connection”,来自深层的梯度能直接畅通无阻地通过,去到上一层,使得浅层的网络层参数等到有效的训练,解决了梯度消失以及梯度爆炸的问题,优化了网络性能。
结合2.1节中的特征融合模块,改进后的模型(FIENet)较SSD模型的特征层细节信息与语义信息结合后更丰富,小目标检测准确率有较大幅度提升,对小目标bird、bottle、chair、plant检测精度分别提升了3.6%、9.5%、5.4%、5.5%。验证深浅层特征层融合能够提高小目标检测能力,特征增强模块对深层特征进行了加强,使得整体检测精度(mAP)也有了很大提升,由于Conv10_2,Conv11_2特征层的特征映射尺寸过小,且包含语义信息较强,因此不再需要通过特征增强模块,而是直接用于检测。
使用梯度加权类激活映射方法对特征增强前后的特征映射进行对比,仿真结果演示如图11所示。图(a)为特征增强前特征映射演示,(b)为特征增强后特征映射演示。(a)、(b)中的左图为灰度图,中图为热力图,右图为热力图与原图融合结果展示。从仿真结果可以得出特征增强后的特征映射中重要的特征信息更加明显,有助于提高目标检测精度。
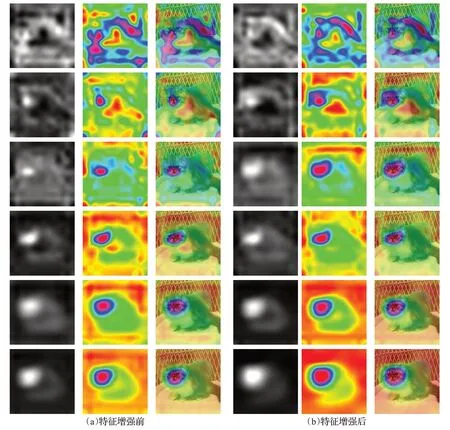
图11 特征增强过程演示Fig.11 Simulation demonstration of feature enhancementprocess
2.3 先验框数量调整
在SSD网络模型中,将Conv4_3、FC7、Conv8_2、Conv9_2、Conv10_2、Conv11_2六个特征层用于最后的检测。特征图先验框的个数预测依次为(4,6,6,6,4,4)。Liu等[28]研究表明,低级特征对小目标检测至关重要。因此,在浅层Conv4_3的特征映射中添加更多的先验框,将先验框个数设置为6,那么检测精度,特别是对于小目标的检测精度,往往会提高。
3 实验
本文在2个公共数据集上进行实验来验证模型的有效性,PASCALVOC[29]公共数据集,MSCOCO[30]公共数据,分别进行了20和80个对象类别的实验。使用VGG-16作为实验的基础网络。新添加的卷积层的权重初始化方式为MSRA方法[31]。本文使用NVIDIA Tesla P100 GPU进行实验训练,使用NVIDIA GTX1080Ti进行测试,代码框架为pytorch0.4。
3.1 PASCAL VOC数据集
在这个实验中,在PASCAL VOC2007和PASCAL VOC2012训练集的联合上训练本文模型,然后在VOC2007测试集上进行测试。VOC数据集为20个类别,可分为4个大类别:person(人)、animal(动物)、vehicle(交通工具)、indoor(室内),类别特征如图12所示,具体类别在3.2节中进行了实验。

图12 类别特征Fig.12 Class feature
实验中使用两种不同的输入大小:300×300和512×512。对于300×300,本文的batchsize设置为32,使用预热策略对前5个阶段进行训练,逐步将学习率从10-6提高到10-3。初始学习率为4×10-3,在150和250轮时学习率迭代下降(除以10),共训练300轮。对于512×512,batchsize设置为32,其余超参数不变。训练过程中损失函数变化如图13所示。
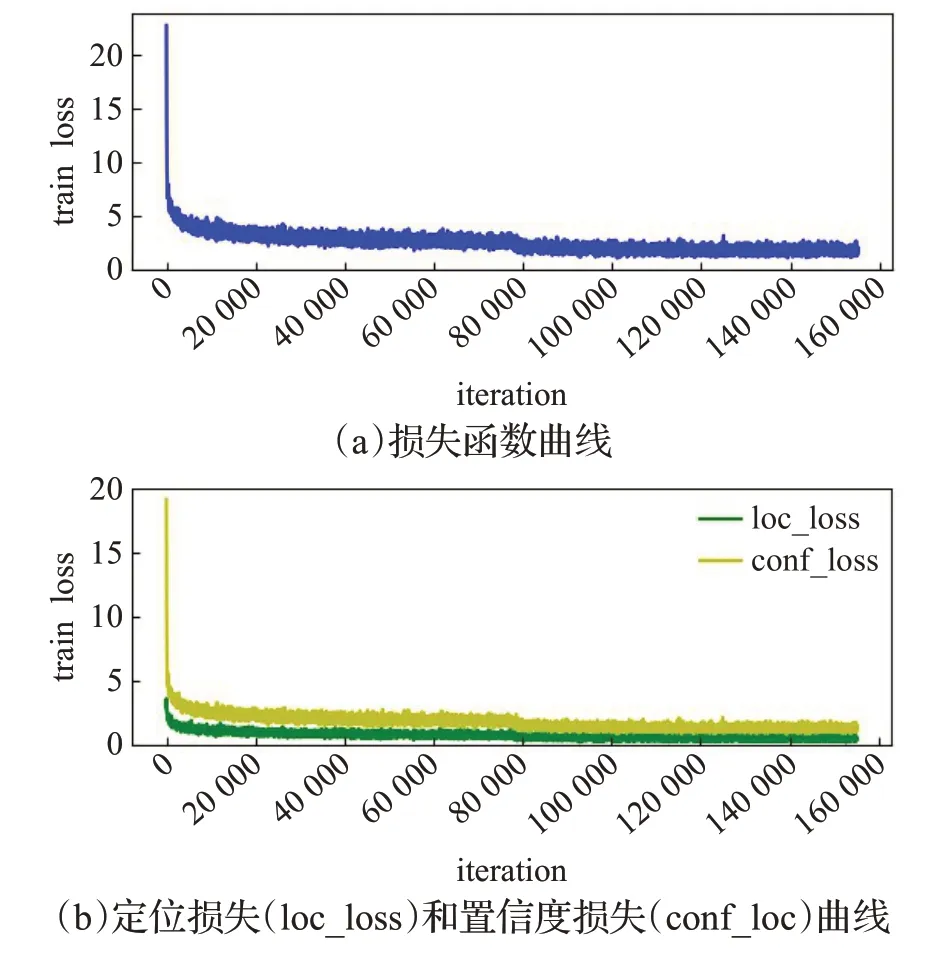
图13 训练过程收敛曲线Fig.13 Training loss curve
本文将FIENet与其他几种单阶段目标检测器进行比较,统计结果如表3所示。当输入图像大小为300×300时,检测精度(mAP)比SSD高3.1个百分点,此外,本文方法具有很快的推理速度,它可以以78 frame/s的速度运行。对于较大的输入大小(512×512),FIENet仍然比SSD准确率高2.5个百分点。
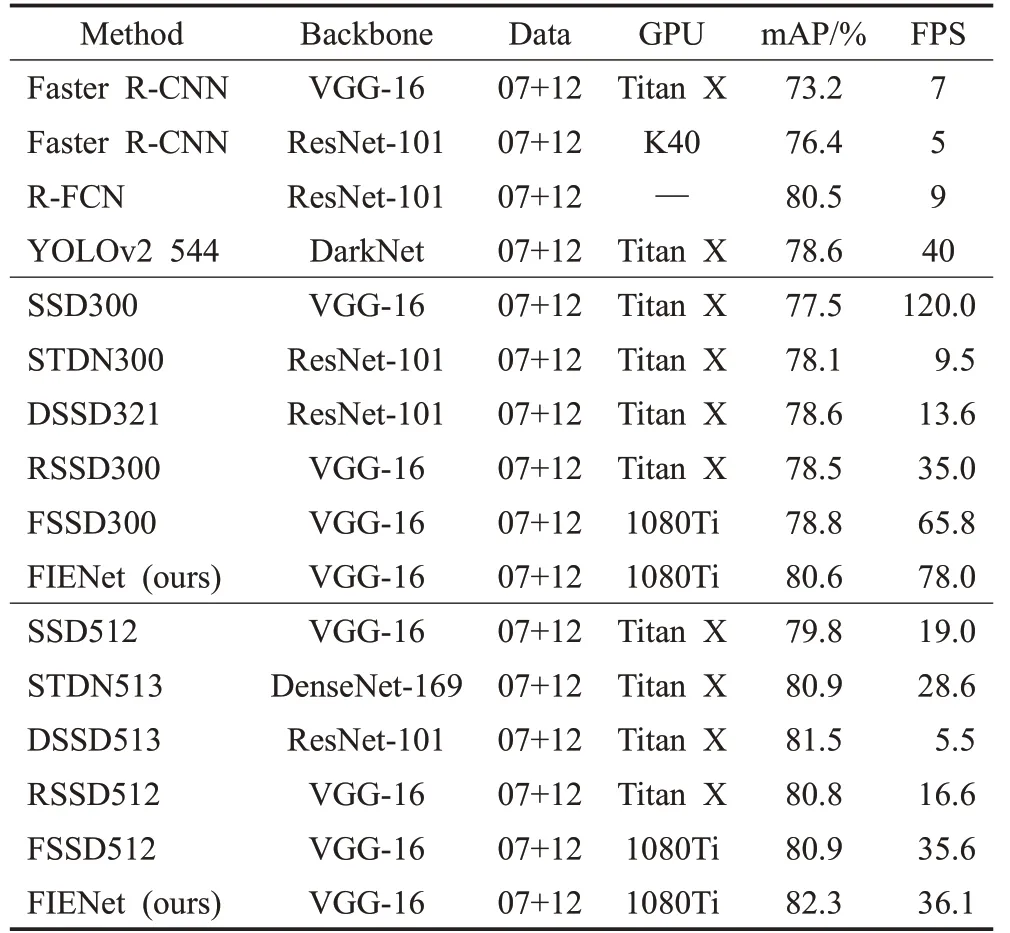
表3 PASCAL VOC数据集测试结果Table 3 PASCAL VOC data set test results
本文随机选取了Pascal VOC2007测试数据集中的图片对算法的检测效果与SSD目标检测模型进行对比,结果如图14所示,相对于SSD网络模型的检测,本文模型在小目标的检测效果更为显著。

图14 SSD算法与FIENet算法数据集上的对比结果Fig.14 Comparison between SSD model and FIENet
3.2 PASCAL VOC单个类别测试结果
本文在PASCAL VOC2007公共数据集上进行验证实验,将每一类目标检测精度与多个一阶段目标检测算法进行比较,实验统计结果如表4所示。结果表明本文设计的模型在多个类别上均优于SSD目标检测模型,对于小目标boat、bottle、chair、plant检测精度分别提升了6.0、9.5、5.4、5.5个百分点。
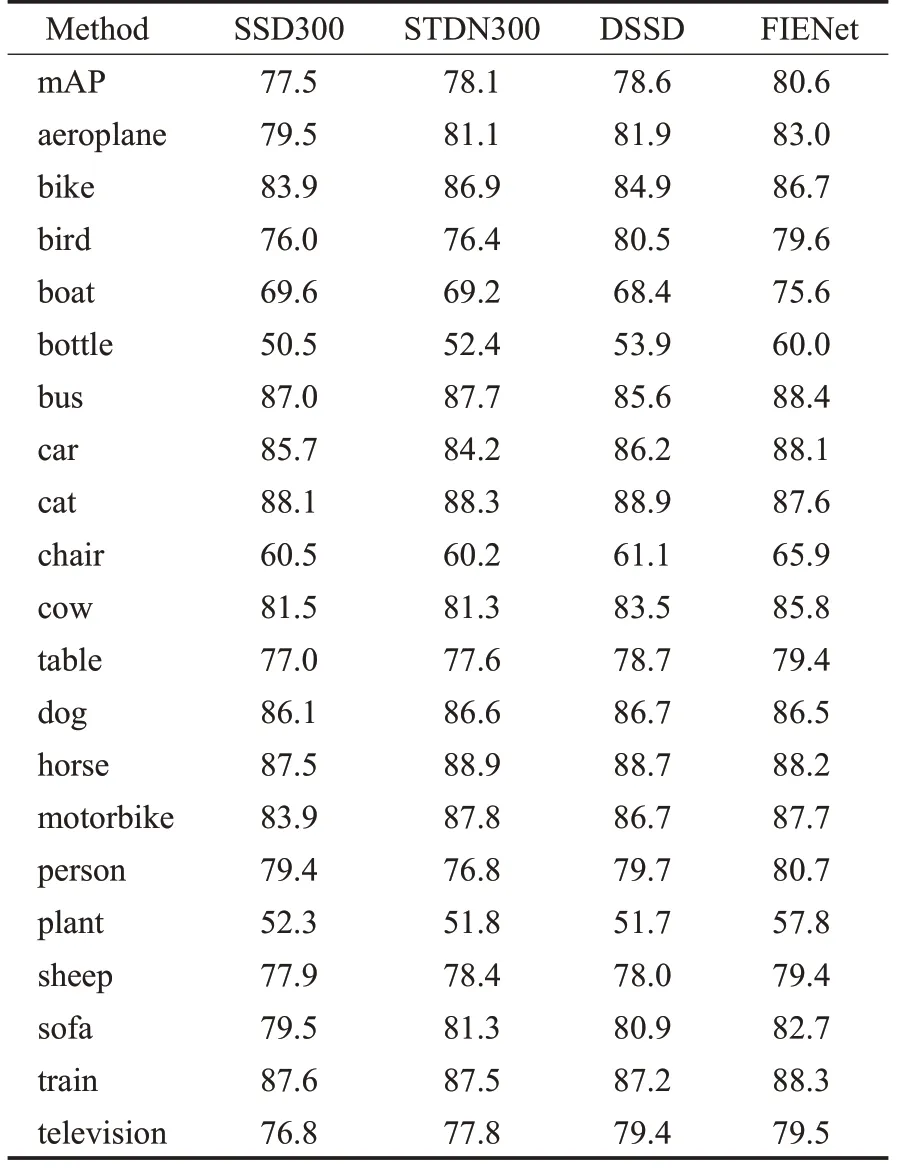
表4 PASCAL VOC2007测试集单个类别测试结果Table 4 Test results of single category of PASCAL VOC2007 test set %
3.3 消融实验
为了进一步验证FIENet中本文设计策略的有效性,在PASCAL VOC 2007数据集上运行具有不同设置的模型,进行了消融实验,并将评估结果记录在表5中。将先验框数量分别设置为(6,6,6,6,4,4)。首先只在浅层使用本文提出的特征融合模块,mAP是78.5%。然后将特征增强模块只用于浅层特征融合模块(FEB1,FEB2)之后,准确率上升了0.9个百分点。将特征增强模块只用于深层(FEB3,FEB4)之后,准确率上升了0.8个百分点。将特征增强模块同时用于浅层和深层之后,准确率上升了2.3个百分点。最后是完整的FIENet网络,mAP达到80.6%,验证了FIENet中设计策略的有效性。
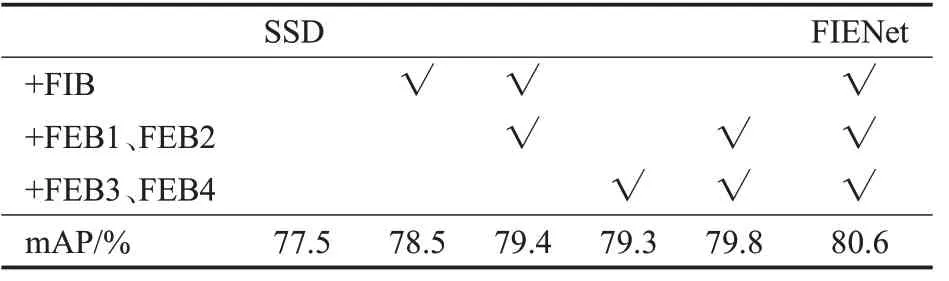
表5 融入不同模块算法效果对比Table 5 Comparison of algorithm effects of different settings
3.4 MS COCO数据集实验结果
为了进一步验证本文所提出的模型,在MS COCO数据集上进行了实验。使用train_val 35k集合(train set+val35k set)进行训练,它是来自训练集(train_set)的80 000张图像和来自验证集(val_set)的40 000张图像的随机35个子集的结合,并将批大小(batchsize)设置为32。由于COCO中的对象比PASCAL VOC中的对象小,保留了减少默认框大小的原始SSD策略。在训练开始时,仍然采用预热策略,在前5个阶段逐步将学习率从10-6提高到10-3,然后在80和100个阶段后将其降低10倍,最后到120轮训练结束。
结果汇总在表6中。在表中将本文提出的FIENet与多个先进的目标检测算法进行了对比。本文的模型取得了29.4%的AP,大大超过了SSD300的25.1%的AP。特别是当IOU=0.5时,AP值达到54.1%。
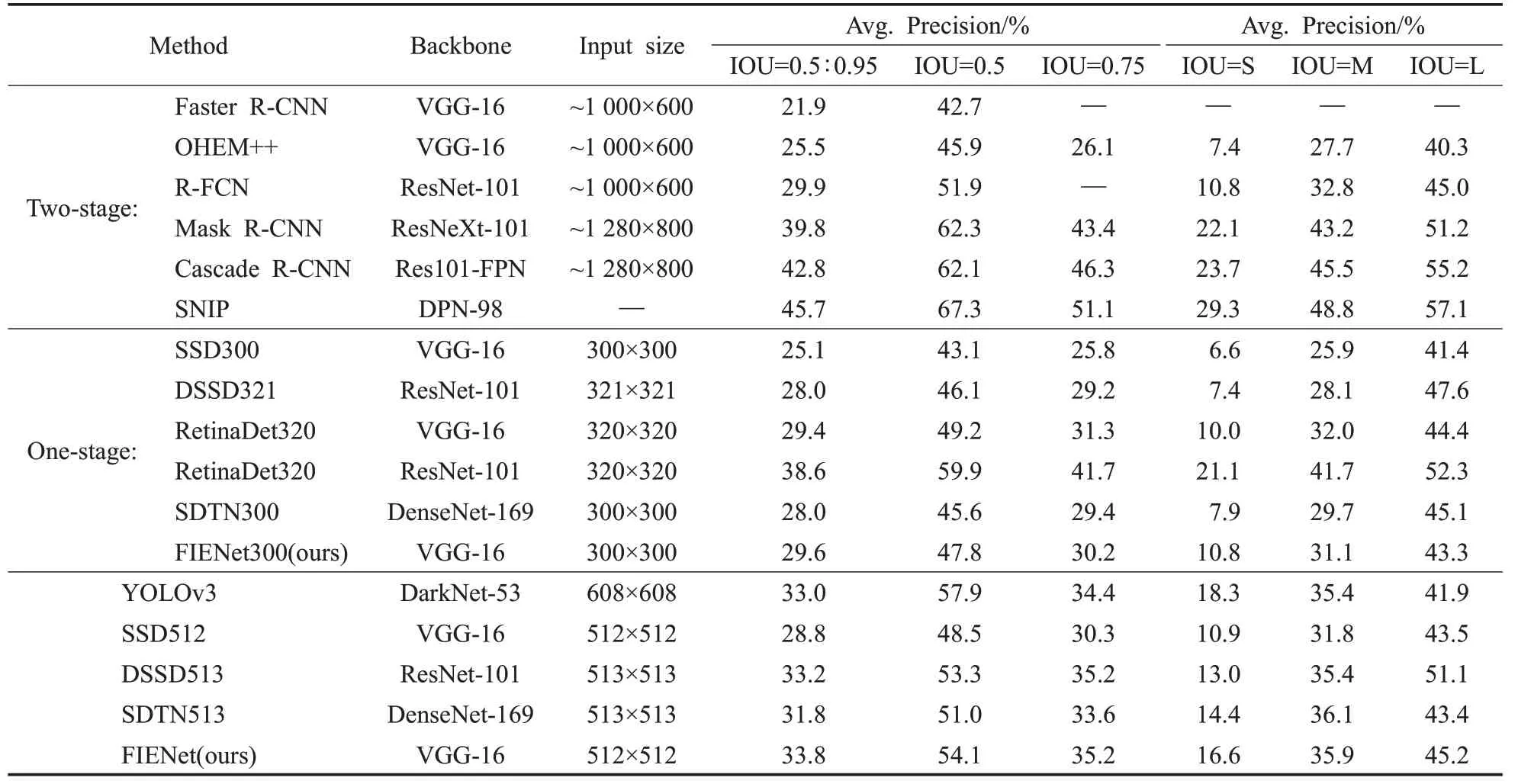
表6 MS COCO数据集检测结果Table 6 Detection results of MS COCO data set
对于较大的512输入,本文方法获得了33.8%的AP,超越大多数更强大主干和更大输入尺寸的目标检测器。例如可变形R-FCN的AP为37.5%,FPN的Faster R-CNN的AP为36.2%。
4 结论
本文提出了一种准确、高效的基于SSD的one-stage目标检测器,有效地提高了检测精度。本文中设计了特征融合模块(FIB)和特征增强模块(FEB),特征融合模块对浅层特征进行融合;特征增强模块对增强轻量级网络的特征表示进行增强。特征映射模块采用了残差结构,加快了检测速度;融入了注意力机制,自动获取到每个特征通道的重要程度。通过在Pascal VOC数据集上和MSCOCO数据集的对比实验证明本文模型在提高小目标准确率的同时,可以保持较高的运行速度。实验结果表明本文模型达到了实时高精度检测目标的效果。
