使用前缀特性的IPv6寻址算法
2022-06-09刘昕林孙凤杰
黄 萍,刘昕林,孙凤杰
1.深圳供电局有限公司 信息中心,广东 深圳 518000
2.华北电力大学 电气与电子工程学院,北京 102206
网络承载的全球IP流量持续增长[1]。为了应对日益增长的互联网流量,目前正在研究400 GB以太网标准。因此,网络节点必须以这些线速率处理数据包,这就需要IP地址寻址引擎在小于6 ns的时间内处理IPv6数据包[2]。
IP寻址任务包括识别数据包应该转发到的下一跳信息(NHI)。寻址过程包括将从包报头提取的目标IP地址与存储在称为转发信息库(FIB)的寻址表中的条目列表相匹配。FIB中的每个条目(前缀)表示由其前缀地址和前缀长度定义的网络,前缀长度表示有效前缀位的数量。虽然目的IP地址可能与FIB中的多个条目匹配,但只返回与匹配的最长前缀相关联的NHI[3]。
由于为IPv4技术的IP寻址算法和体系结构在IPv6[4-6]中的性能不佳,因此,需要专用的IPv6寻址方法来支持即将到来的IPv6流量。所以需要针对高带宽、低延迟,可伸缩性,大体量进行优化。但目前现有的方法并没有共同解决这些性能要求[7-8]。
并且,现有的为软件实现优化的解决方案在完整系统中不支持高查找率。此外,以硬件实现为目标的解决方案通常受到低吞吐量或低内存效率的影响。
因此,在这里提出了一种满足当前IPv6性能要求的可扩展的IPv6寻址算法(SHSL),其创新点如下:(1)提出了两级前缀分组,将IPv6前缀聚集在具有共同特征的组中。前缀根据它们的23个最高有效位被划分为存储单元,而这些单元存储在哈希表中。在每个bin中,前缀根据FIB前缀长度分布分组排序。(2)提出一种混合字典树(HTT),每组前缀都在HTT中编码。HTT重新考虑了多位字典树(Trie)的概念,但是根据前缀密度调整了每个级别上构建的节点数。(3)基于FPGA实现对SHSL数据结构的流水遍历,并利用片上内存来支持高查找率,同时平衡了查找延迟。
1 算法概述
SHSL包括建立有效数据结构的过程和遍历该结构的过程,即寻址算法。
SHSL将前缀聚类方法与内存高效的数据结构相结合。一种基于两级前缀分组的聚类方法,根据前缀的23个最有效位(MSBs)将前缀分为地址块bin(ABB),并根据FIB前缀长度分布将前缀分为前缀长度排序(PLS)组。ABB记录在哈希表中,而每个前缀长度排序组中的前缀则编码在HTT中。
SHSL数据结构如图1所示。N项哈希表包含M个有效地址块bin(ABB),这些地址块bin(ABB)是在对MSB上的前缀进行分割后获得的。每个有效的ABB都有一个指针指向一组K前缀长度排序(PLS)组,编码在HTTs中。
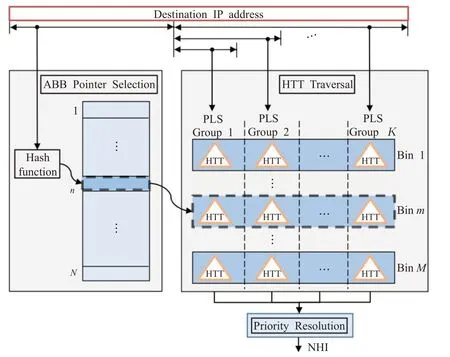
图1 数据结构示意图Fig.1 Data structure
寻址算法识别与匹配的最长前缀相关联的NHI。首先,对目标IP地址的MSB进行哈希运算,以选择ABB指针。在本例中,在哈希表中选择第m个ABB。选定的ABB指向一组由虚线矩形表示的K个HTT。其次,使用目的地IP地址的最低有效位,并行地遍历所选htt。因为每个HTT都可以保存一个与IP地址匹配的前缀,所以使用优先级解析模块来选择与最长前缀相关联的NHI。
2 两级前缀分组
两级前缀分组是一种在ABBs中对前缀进行划分,并进一步对前缀进行长度分组的聚类方法。这种聚类方法是将前缀表分组,每个组保存一部分前缀。然后HTT利用组内的前缀分布。
2.1 地址块分块
前缀在ABB中基于它们的23个最高有效位(MSB)进行分块,ABB被记录在哈希表中。
在23个MSB上前缀分块的目的与已知的IPv6地址空间分配有关。IPv6前缀是从由互联网分配号码管理局(IANA)管理的前缀块池中分配的,范围从/12到/23[9]。因为分配的前缀块很少[9],所以当前缀在23个MSB上进行分块时,会创建一些的bin。因此,在原始前缀表大小的基础上,前缀中bin的数量最多改变了两个数量级。
ABB方法利用一个完美的哈希表[8]来存储bin值,原因有两个。首先,bin值几乎是静态的,因为它们表示分配给区域互联网注册中心的地址空间,这些地址空间不太可能在短时间内更新。其次,完美的散列函数保证了O(1)时间复杂度,因为不会产生冲突。
虽然在IPv4[10-13]中,使用哈希表或直接索引表在MSB上进行寻址的想法并不新鲜,但ABB方法针对IPv6进行了优化,并通过利用已知的IPv6地址空间分配与以前的工作有所不同。
由于与ABB相关联的前缀可以重叠,因此引入前缀长度排序方法来减少重叠前缀的数量。
2.2 前缀长度排序
基于ABB前缀的PLS将IPv6分发组划分为前缀。使用此方法将前缀从/24到/64排序到K个组中。每个组包含一个连续的前缀长度范围。
根据两个原则选择每组覆盖的前缀长度范围。首先,当前缀长度占前缀总数的很大比例时,前缀长度被用作所考虑组的上限。其次,必须选择前缀长度范围,使得K组在前缀数量方面尽可能平衡。
为了说明这两个原理,图2中给出了使用实前缀表[14]对前缀长度分布的分析。图2中省略了前23个前缀长度,因为ABB方法已经基于它们的23个MSB来存储前缀。在图2中可以观察到,对于该示例,具有最大基数的前缀长度是/32和/48。将前缀长度排序的两个原则应用到这个例子中,第一组覆盖从/24到/32的前缀长度,第二组覆盖从/33到/48的第二个峰值。最后,从/49到/64的所有剩余前缀长度都保留在第三个前缀长度排序组中。
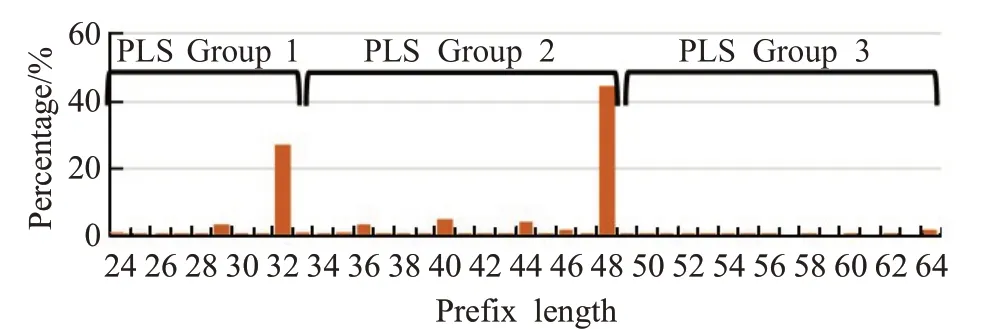
图2 3组PLS的前缀分布Fig.2 Prefix distribution of 3 PLS
第一个原则是通过将大量的前缀从可以重叠的较长前缀中分离出来,从而最小化前缀组中前缀重叠的数量。第二个原则是尽可能平衡PLS组之间前缀重叠的数量,以获得具有相对相似特性的HTT。
3 混合TRIE-TREE数据结构
提出的HTT对每个非空PLS组中的前缀进行编码。HTT数据结构经过定制,以使其形状适应所用前缀的特性。HTT结合了一个密度自适应Trie(DAT)、一个内存高效的多位Trie和一个从字典树的节点派生的leafbucket(LB)。
3.1 密度自适应Trie
提出的密度自适应Trie重新定义了多位Trie的概念。它通过调整基于前缀密度创建的节点数量来实现,前缀密度指的是Trie级别内非空节点的稀疏性,以及Trie级别内相邻节点上的前缀复制因子。
与k位Trie类似,DAT迭代地应用于从保存前缀集的二进制Trie中提取的sub-Tries。DAT在将前缀推送到叶之后对sub-Trie的叶进行编码,如图3中的虚线箭头所示。后面章节会具体介绍从二进制Trie中提取sub-Tries的方法。
DAT背后的主要思想是合并相邻的空叶或记录相同前缀的叶,如图3(a)所示,并在单个合并节点中对它们进行编码,如图3(b)所示。相比之下,k位Trie将每个sub-Trie叶编码成节点,如图3(a)所示。
为了确定是否可以合并两个相邻的叶,将计算每个叶所覆盖的前缀数,其中包括保留在叶中的前缀和保留在叶下分支中的前缀数。当合并节点覆盖的前缀数量小于某个固定阈值,即leafbucket的大小或不高于两个叶子覆盖的最大前缀数时,两个叶子被合并。
合并方法从sub-Trie的两个边缘的叶子向中心应用。例如,在图3(a)中,合并方法从与节点N0和N7相关联的叶开始。对于两个方向,此方法评估一个叶是否可以与下一个相邻叶合并。合并过程会重复,直到某个叶不能再与其相邻的下一个叶合并。否则,将从最后一个未合并的叶中重复该方法。
合并方法对合并的叶的个数有两个限制。首先,合并节点只对2的幂次的连续叶进行编码,因为合并节点覆盖的空间使用前缀表示法表示。其次,合并节点的总数受自适应Trie节点大小的限制。
通过合并方法计算的叶索引被编码在LtoH和HtoL数组中。LtoH和HtoL阵列分别保存了从低索引到高索引和从高索引到低索引的叶片索引。所有没有用合并方法计算的叶子都被保留为未合并,并且被称为编码在未合并区域中。
DAT中使用的合并方法的优点如图3所示,其中编码后的sub-Trie存储在存储器中的节点数量从图3(a)中的3位Trie减少到使用DAT的2位,如图3(b)所示。使用DAT,存储前缀P1的两个相邻叶被合并,但也合并相邻的空叶。
DAT通过合并记录相同信息的相邻节点来定制内存效率。然而,在图3(b)中,DAT需要另一个级别来将前缀P2与前缀P1分开。因此,为了减少DAT的深度,当一个节点覆盖的前缀数量低于阈值b时,前缀被编码在LB中。
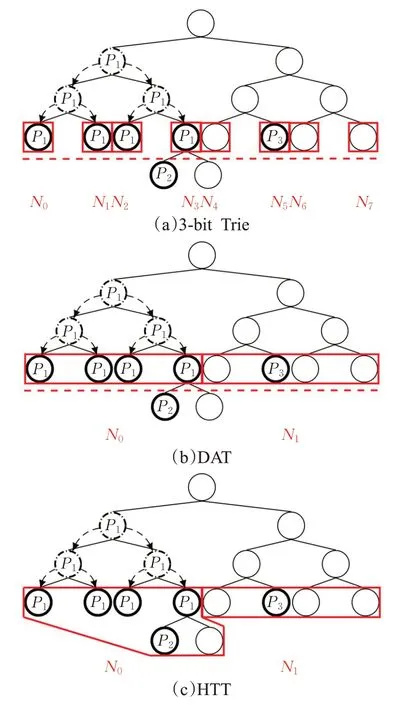
图3 不同情况下的减少内存中存储的子节点N i的数量Fig.3 Reduceing number of child nodes Ni stored in memory under different conditions
3.2 Leaf Bucket(LB)
LB存储一组多达b个不同的前缀及其NHI,由一个DAT节点覆盖,并存储在DAT节点下的分支中。例如,在图3(b)中,DAT节点N0覆盖前缀P1和P2。
提出的LB来自树叶,但只存储了未匹配的前缀位。每个前缀的不匹配位数都以LB编码,以及存储的前缀数。通过减少存储的信息量,所提出的LB提高了树叶的内存效率,并且需要较少的内存访问被读取。使用LB编码前缀的兴趣是两倍。当sub-Trie在叶中保存最多b个稀疏分布前缀时,LB需要的节点存储前缀的节点比DAT少。此外,由于大多数PLS组的前缀很少,LB可以在单个节点A PLS组中编码。
在图3(c)中,覆盖两个或更少前缀的DAT节点被编码为LBs。因此,使用将DAT与LBs结合的HTT,表1所示的前缀集被编码在具有两个子节点LB0和LB1的DAT根节点中,如图4所示。在图4中还介绍了每个LB的内容。
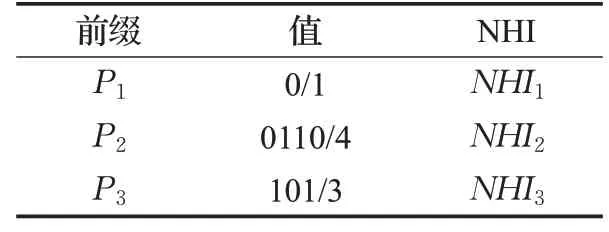
表1 前缀示例Table 1 Prefix example
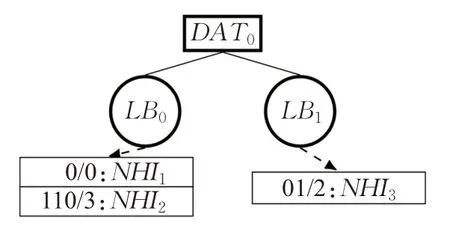
图4 表1完整的HTTFig.4 HTT based on Table 1
3.3 HTT构建过程
HTT构建过程分为两部分:主过程和sub-Trie的选择。
(1)主过程:主过程在二进制Trie的根节点启动。如果存储在二进制Trie中的前缀数量低于固定的阈值b,则将前缀编码在LB中。否则,算法从二进制sub-Tries中迭代选择,即从主二进制Trie中分割出来的二进制Tries,这些Tries被编码到HTT节点中。
对于选定的sub-Trie,DAT合并方法应用于叶。然后,当一个DAT节点覆盖多达b个前缀时,前缀将被编码到一个LB中。否则,将创建一个DAT节点,并在sub-Trie的每个非空分支上重复该过程。
图3(c)和图4给出了表1所示前缀集的图示。前缀被插入到二进制Trie中,如图3(a)所示。在图3(a)和(c)中,所选的sub-Trie位于虚线红线上方。sub-Trie叶在HTT节点中编码。然后对红色虚线下方的每个sub-Trie重复该过程。
(2)Sub-Trie的选择:贪婪算法作为算法1,在每次迭代中提取一个子矩阵,从中构建一个内存高效的浅层HTT。
算法1启发式选择sub-Trie编码到HTT节点的深度

贪婪算法从二进制Trie中提取关于存储开销约束的最深sub-Trie。因为每次迭代都会选择一个深sub-Trie,所以构建了一个具有很少级别的数据结构,而这反过来又需要很少的内存访问来遍历。
从用作所选sub-Trie的根的二进制Trie节点开始,该算法迭代地增加sub-Trie的深度,直到违反存储开销约束。
作为存储开销约束的空间度量因子(Smpf)的计算方法是将选定的sub-Trie及其分支中包含的前缀数乘以一个常数,在这里设置为8。使用更高的常量值有利于选择更深的sub-Trie,代价是更高的存储开销。这里使用的常数是实验性地选择的,以在亚深度和存储开销之间提供一个很好的折衷。
在每次迭代中,空间度量(Sm)函数通过计算保留在叶上和保存在分支中的前缀的数量(NumPrefixes(leaf j))来估计所选sub-Trie的存储开销,并在其中添加惩罚项。在将前缀推送到sub-Trie的叶之后,计算保留在叶上的前缀数。
启发式算法选择一个sub-Trie,包含分支的平均前缀长度。如果所选分支中的平均前缀长度大于子串覆盖的前缀长度,则Sm将缓慢增长,并选择更深的sub-Trie。为了避免Sm在多次迭代中保持不变时选择非常深的sub-Trie,在Sm中添加一个惩罚项,并将该惩罚定义为Sm(i-1)和所选sub-Trie的叶数之和。
3.4 HTT寻址过程
HTT寻址算法从遍历密度自适应Trie开始,直到到达LB为止。然后,将保存在LB中的前缀与目标IP地址进行匹配,并返回最长匹配前缀的NHI。
(1)密度自适应Trie遍历:当从内存中读取DAT节点时,必须对DAT节点中编码的sub-Trie进行解码,以计算下一次读取的子节点的地址。使用DAT节点中存储的LtoH和HtoL数组,可以识别sub-Trie合并的叶子。
在DAT中,由于图3(b)和(c)所示的合并方法,sub-Trie的叶与图3(a)中所示的k位Trie的节点之间的一对一映射不成立。因此,子节点的存储器位置是所选子节点之前合并叶数的函数。算法2给出了计算子节点地址的步骤。
算法2匹配子节点地址的标识

接下来要访问的子节点的地址分两步计算。首先,确定包含子节点的区域(LtoH数组、HtoL数组或未合并的区域)以及所选区域中的子节点索引。其次,计算匹配节点索引之前合并的叶子数,以导出其地址。
首先提取IP地址段,选择索引等于IP地址段的sub-Trie叶。LtoH和HtoL数组都用于标识所选叶索引是否被LtoH区域、HtoL区域或未合并区域中的合并节点覆盖。此外,如果选择了LtoH或HtoL区域,则将标识包含所选叶索引的合并节点的数组索引。LtoH或HtoL数组中的数组索引分别记为p LtoH和p HtoL。如果匹配的节点位于未合并区域中,则数组索引为IP地址段。
其次,使用子节点索引之前的合并叶数,导出子节点偏移量。如果子节点在LtoH区域中,偏移量由p LtoH直接给出。在未合并区域中,使用p LtoH数组计算的合并叶数从IP地址段中减去,以获得子节点偏移量。在p H toL区域中,使用LtoH和HtoL数组计算的合并叶数从子节点索引p HtoL中减去。最后,偏移量被添加到子基地址。
在图5中示出了L=3和IP seg=10情况下的算法2。IP地址段匹配HtoL区域中的节点,如IP seg≥HtoL[0]。当9≤IP seg≤10时,HtoL区域内匹配的节点存储在数组索引p HtoL=1中。使用HtoL和LtoH数组计算到匹配节点的合并叶数。基于LtoH数组,合并的叶数为LtoH[L-1]-(L-1)=1。当p HtoL+HtoL[0]=IP seg时,匹配节点之前的HtoL区域中不会合并任何叶。因此,匹配子节点的偏移量为IP seg-1=9。
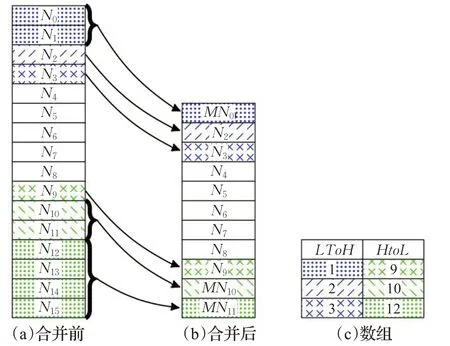
图5 合并前和合并后的节点索引存储在LtoH和HtoL数组中Fig.5 Node indexes before merging and after merging storing in LtoH and HtoL arrays
(2)LB匹配:遍历DAT,直到到达LB为止。首先解析叶,然后读取前缀。接下来,根据目标IP地址匹配所有前缀,如果匹配为正,则记录它们的前缀长度。当所有前缀都匹配时,只有匹配的最长前缀与它的NHI一起返回。
4 更新支持
首先分析了更新的特点,然后评估了使用SHSL算法进行更新的代价。
与其他工作类似,离线过程在接收到前缀更新后识别要修改的SHSL数据结构的节点[15-16]。
4.1 前缀更新分析
共有三种类型的前缀更新可应用于FIB;NHI修改现有前缀、插入前缀、删除前缀。从2020/12/1到2020/12/2,由RIS远程路由收集器[14](rrc)接收的更新如图6所示。基于图6,可以观察到每秒2 000个NHI修饰的峰值,而峰值前缀插入和删除速率在每秒550个更新时相对相似。
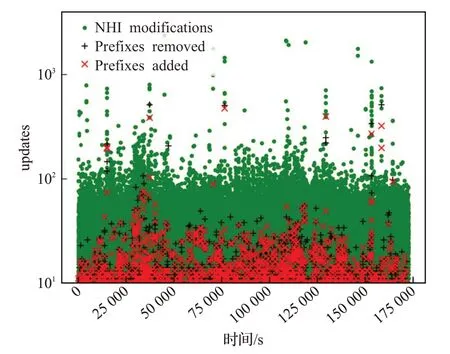
图6 两天的更新Fig.6 Update rates over two days
然而,有效的删除率和插入率可以大大降低。实际上,由于路由器可以与多个路由器交换网络状态信息,同一更新信息可以被一个路由器多次接收。此外,在网络链路发生故障后的几分钟内,前缀可以被撤回和插入多次。事实上,先前的研究表明,在网络链路故障后,观察到的恢复时间平均为分钟[16]。由于从相邻路由器多次接收到信息,在网络链路发生故障后的几分钟内,前缀可以被撤回并多次插入。总之,通过延迟删除和每个时间戳对每个前缀进行一次更新,有效的前缀添加和删除率将下降到每秒20次以下的更新。
4.2 开销更新
现在通过计算修改SHSL数据结构的内存访问次数来评估更新的开销。让CHTT和Chashtable分别代表HTTs和哈希表开销更新。前缀的插入或删除可以触发哈希表更新和HTT的更新,与前缀长度无关。如果已更新前缀的23个MSB尚未与哈希表中的ABB关联,则哈希表和HTT都必须更新。否则,只更新HTT。首先评估Chashtable。当ABB表中的一个条目被删除时,需要一个与ABB表相关联的词条来更新。但是,必须重建整个哈希表以添加ABB。
为了降低更新的复杂性,需要构建一个哈希表,其中包含与当前IPv6单播地址空间相关联的所有ABB[9]。因此,当添加前缀时,关联的ABB条目通过单个存储器访问被启用。此外,观察到应用于哈希表的更新次数不到每秒一次。因此,Chashtable=insert ionrate×#memoryAccessperinsertion=1。保存所有ABB的哈希表使用54 KB,与SHSL上的数据结构大小相比可以忽略不计。此外,IPv6单播地址空间自2006年以来一直未被修改,其使用率仍然极低,因此该方法对于未来IPv6网络的发展是有效的。
现在对HTT的更新成本进行了评估。当前缀NHI被更新时,更新HTT叶需要一次内存访问。但是,前缀的插入或删除需要重建HTT的一部分,或者一个完整的HTT。在所有使用的基准上,HTT中的节点数小于前缀的数量。结果,前缀更新后要修改的节点数最多等于n,即HTT中保留的前缀数。因为观察到的大多数前缀更新都应用于HTT,CHTT=insertionrate×n+deletionrate×n+NHIupdaterate。
更新SHSL数据结构的成本为CHTT+Chashtable=20×n+20×n+2 000+1。因此,SHSL架构的更新复杂性为O(n)≈O(N),其中N是FIB中前缀的数量。使用最大的前缀表,HTT中编码的最大前缀数为n=7 000。因此,在最坏的情况下,每秒最多需要282 001个内存访问来更新SHSL数据结构。
在最坏的情况下,每秒处理282 001次内存访问对寻址速率的影响非常有限,而寻址速率大约是每秒数亿次的寻址。
为了更新所提出的流水线硬件体系结构中的SHSL数据结构,使用了文献[16]的技术,它是一种广泛采用的技术,用于将更新推送到流水线硬件体系结构,该技术主要包含插入到管道中的三元组(管道阶段、内存地址、值)。当到达三元组中指定的管道阶段时,控制电路用三元组中保存的新值更新内存地址。
5 性能评估
5.1 实验设置
SHSL的性能是用11个实前缀表来评估的,这些表保存着大约25 000个前缀,这些前缀是从RIS远程路由收集器中提取的[14]。每一种情况下,rrc中的后两位数的数字代表了所使用的远程路由收集器在网络中的位置。此外,还使用了合成前缀表。使用非随机方法生成了一个合成的580k前缀表[17]。从580k前缀表中创建了四个较小的前缀表,前缀长度分布相似,分别保存290k、116k、58k和29k前缀。
由于SHSL使用两级前缀分组对前缀进行聚类,因此在后面章节中评估了聚类后的前缀分布。使用一个小的实前缀表rrc00和最大的前缀表(580 000个前缀)来评估前缀分布。
SHSL性能的特征是遍历数据结构的内存访问次数及其内存占用。考虑了两种情况:一种没有聚类,即单个HTT对所有前缀进行编码,另一种是使用两级前缀分组对前缀进行聚类并在多个HTT中编码。对于第二种情况,数字K的范围是1到6。
所述架构的存储器总线允许每个时钟周期读取一个HTT节点。此外,在ABB中选择的K个HTT被并行地遍历。报告的内存访问数是所有ABB中所有HTT之间的最大内存访问数。
HTT存储开销以每字节前缀字节数表示,以捕获数据结构开销。这个度量的计算方法是数据结构的大小除以前缀表中每个前缀的大小之和。为了表征每层的HTT效率,评估了HTT节点分布、HTTs深度分布和前缀分布。最后两个指标只考虑最大深度。这些度量结合起来,可以评估每个HTT节点编码的前缀的平均数量,这直接反映了HTT的效率。这些指标使用K=2 PLS组进行评估,类似于用于聚类分析和FPGA实现的参数。
5.2 实验结果
5.2.1 簇内的前缀分配
如前所述,在MSB上存储前缀的动机在于IPv6地址结构[9]。在本小节中,通过实验证明,前缀可以使用ABB宽度设置为23。
在图7中,评估ABB宽度对前缀分布、单元数和前缀数的影响。在这个图中,ABB和PLS两种聚类方法被应用于前缀。ABB宽度设置为23位时,ABB的单元数和前缀的数量被规范化,因为所提出的聚类方法将其23个MSB作为前缀。
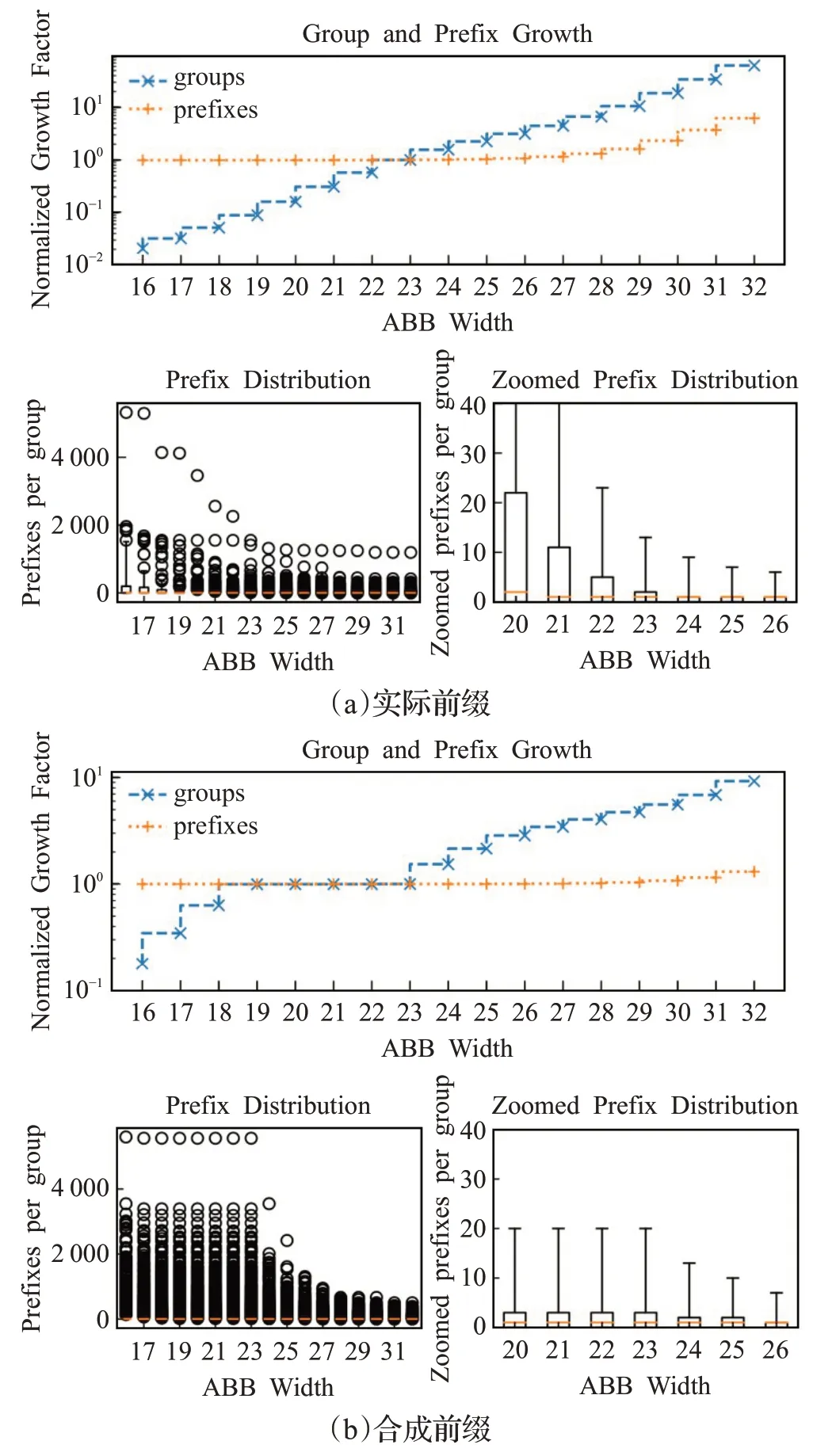
图7 聚类后PLS组内前缀分布与ABB宽度Fig.7 Prefix distribution of PLS vs ABB width
使用ABB宽度等于或大于23位的实数前缀会使前缀沿着图7(a)所示的PLS组分布得更均匀。使用ABB宽度大于23的前缀无助于减少PLS组中的最大前缀数量,如异常值方框图所示。此外,使用大于23位的ABB宽度对前缀的总数几乎没有影响,但是bin的数量有一个超线性的增长。
使用合成前缀,观察到ABB宽度大于或等于24位的分布更加均匀。虽然使用大于23位的ABB宽度对前缀的总数影响很小,但是bin的数量与ABB的宽度有超线性的增长。
总之,对真实前缀和合成前缀的实验表明,使用23位是一个很好的折衷方案。
5.2.2 ABB哈希表
记录ABB指针的哈希表的性能如表2所示。对于真正的前缀,ABB方法使用19 KB到24 KB之间的值。在所有测试的场景中,存储开销都是相似的,因为前缀共享23个MSB中的大部分。使用合成前缀,平均每个前缀字节2.7 Byte的内存用于评估的5个场景。哈希表显示了线性存储开销比例。由于使用了一个完美的哈希函数,因此在所有场景中,内存访问的数量都是常量2。

表2 ABB内存开销和内存访问数Table 2 ABB memory overhead and accesses
5.2.3 HTTs
实际前缀:HTTs的性能如图8(a)和(b)所示。两级前缀分组减少了存储开销并平滑了其可变性。对于两级前缀分组的所有场景,HTTs的存储开销在每个前缀字节1.36到1.60 Byte之间。相比之下,在没有集群的情况下,对于编码整个前缀集的单个HTT,存储开销在每个前缀字节1.22到3.15 Byte之间。
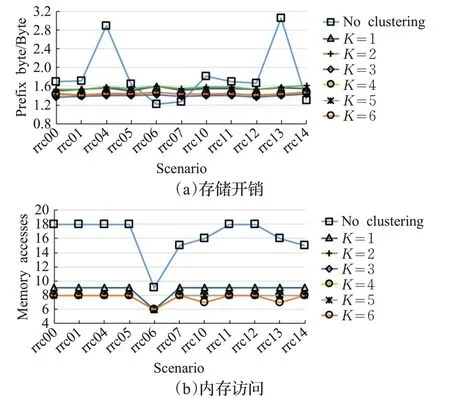
图8 实际前缀中K对HTT性能的影响Fig.8 Influence of K in actual prefix on performance of HTT
从图8(a)可知,将K增加到3会降低存储器消耗,尽管使用更多组会使存储器开销加大。事实上,当K增加时,大多数组包含很少的前缀,这导致分配给HTT的大部分内存未使用。
使用聚类方法,内存访问次数平均减少2倍。虽然对于单个HTT,使用两级前缀分组,在没有聚类的情况下,存储器访问的数量在9到18之间,但是如图8(b)中所观察到的,它在6和9之间变化。然而,将K从1增加到6,在存储器访问数量上几乎没有增加。实际上,可以观察到内存访问的数量受到几个只包含/48个前缀的PLS组的限制。因此,增加K并不能减少这些PLS组中的前缀数目,这会导致内存访问次数的改善。
表3显示PLS组1和2的平均HTT深度分别为1.4和2.1。大约75%的HTT的深度等于1,因为75%的PLS组包含少于2个前缀,如图7所示。实际上,在HTT中,两个前缀可以存储在单个节点中。实验上,对于PLS组1和2,每个HTT节点的平均前缀数分别为1.3和1.4。对于大于1的级别,PLS组1和2的每个HTT节点的平均前缀数分别为1.5和1.0。基于图7,深度大于1的HTT编码超过75%的前缀。
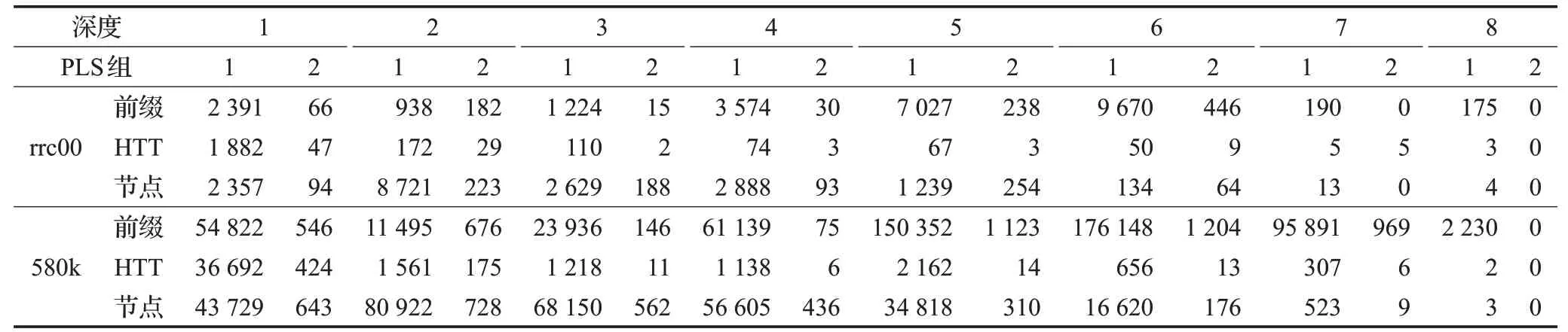
表3 每层的HTT分析Table 3 HTT analysis for each layer
合成前缀:图9展示了具有合成前缀的HTT的性能。在图9(b)中可以观察到两种存储开销行为。对于包含290 000个或更多前缀的前缀表,使用K=2个组的两级前缀分组稍微降低了单个情况下的存储开销HTT。另外,使用K>2并不能提高内存效率。对于具有高达116 000个前缀的较小前缀表,仅使用单个HTT实现较低的存储开销。事实上,使用包含高达116 000个前缀的合成前缀表,大多数PLS组只包含一个前缀。因此,对于每个PLS组,分配给HTT的大部分内存未使用,这降低了内存效率。
HTT的存储开销比例如图9(c)所示。这种存储开销,无论是否有两级前缀分组,都随着前缀的数量线性增长。注意横坐标使用对数刻度。因此,HTT的存储开销缩放在有无两级前缀分组的情况下是线性的。
基于图9(a),使用两级前缀分组减少了单个HTT上的存储器访问次数。平均来说,使用2个或更多组的单个HTT可以减少40%的内存访问量。但是,使用K>3并不能进一步减少内存访问的次数。实际上,导致最大内存访问次数的PLS组不能通过增加组的数量来减小其大小。最后,图9(a)展示了用于搜索的存储器访问次数的增加最多与前缀的数量成对数关系,因为每条曲线近似线性且x轴是对数的。
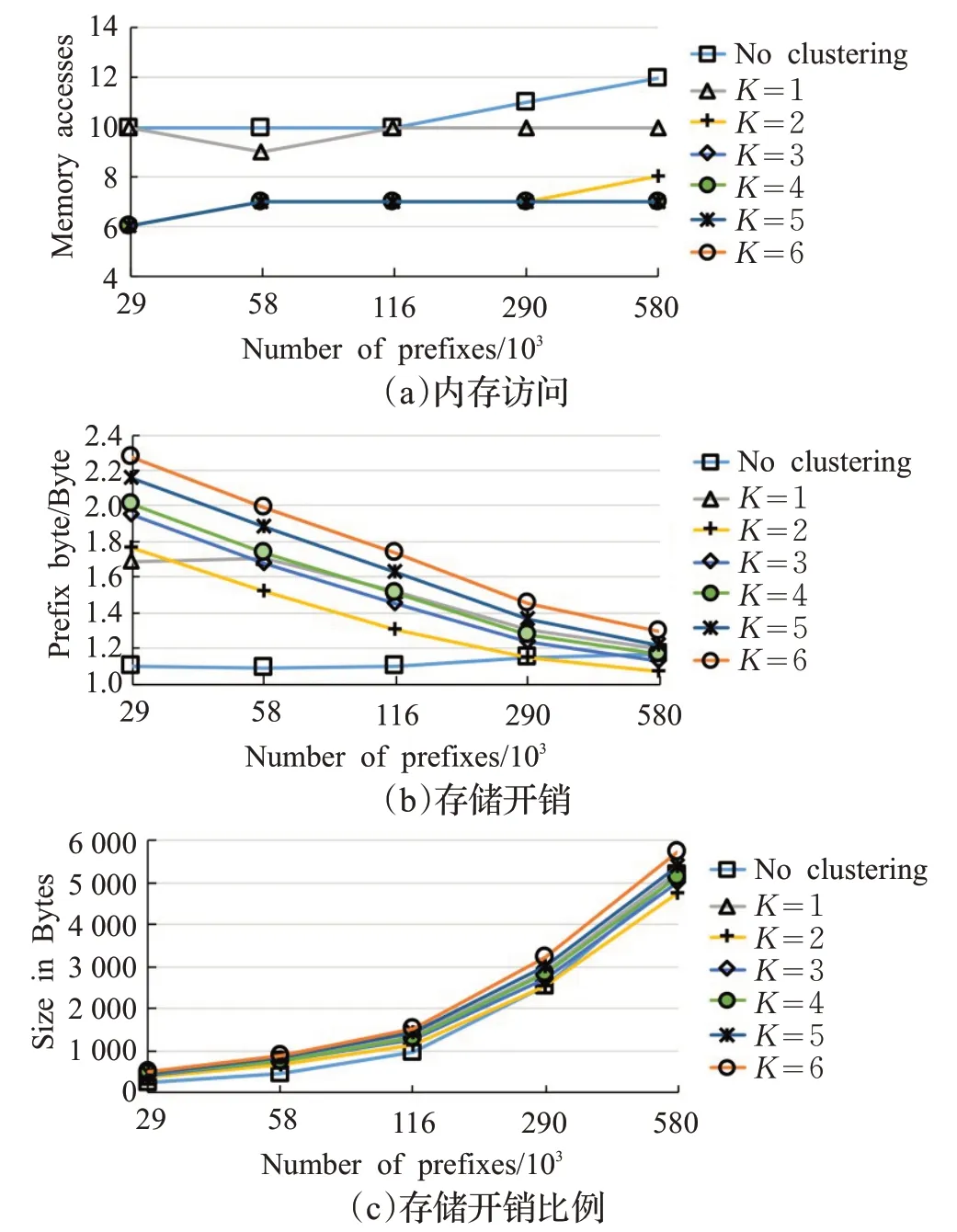
图9 合成前缀中K对HTT性能的影响Fig.9 Influence of K in synthetic prefix on HTT performance
就HTT效率而言,使用合成前缀也可以得出相同的结论。根据表4,PLS组1和2的平均HTT深度均为1.5。80%的HTT具有等于1的深度,这与图2中所示的前缀分布一致。实验上,对于PLS组1和2,平均每个HTT节点在一级分别编码1.5和1.3个前缀。对于大于1的级别,PLS组1和2的每个HTT节点的平均前缀数分别为2.0和2.1。
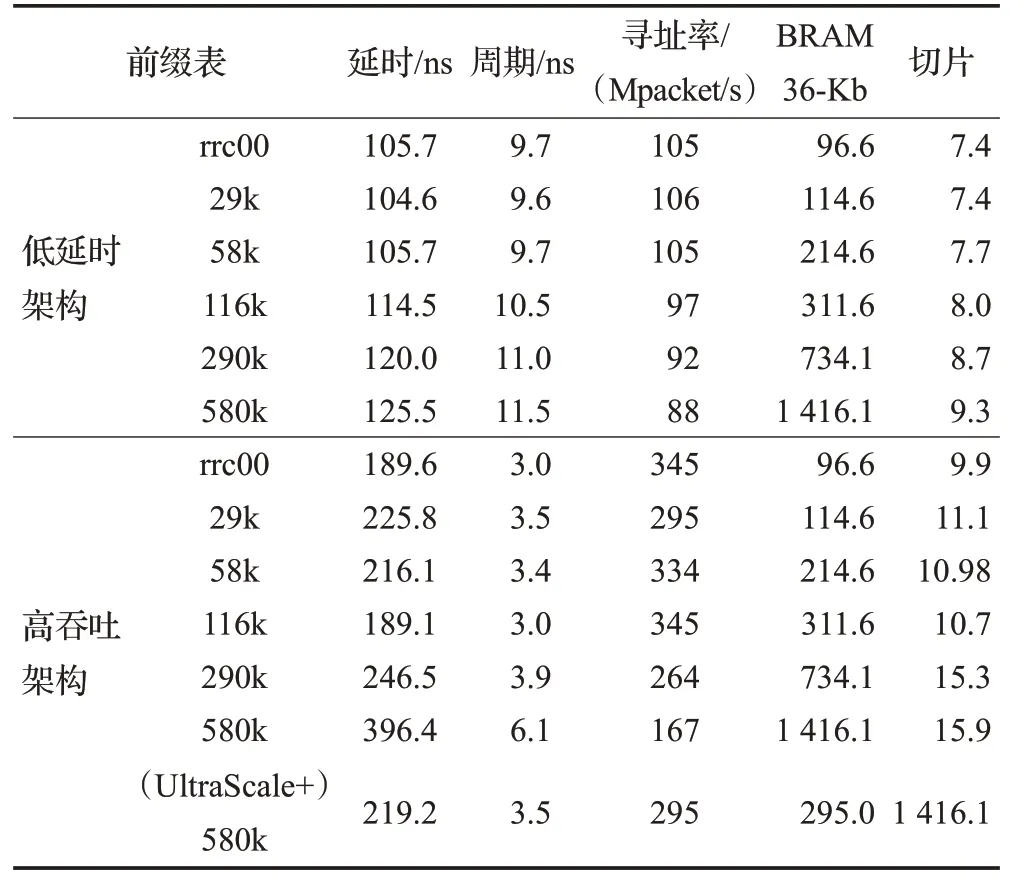
表4 不同架构的性能Table 4 Performance of different architectures
最后,与两级前缀分组一起使用的HTT具有线性存储开销比例和内存访问次数的对数比例。ABB方法中使用的哈希表已经显示出提供了线性存储开销缩放和固定数量的内存访问。因此,SHSL使用所有考虑的基准对内存访问的数量具有线性的存储开销缩放比例和对数缩放比例。
6 基于FPGA的实现
开发了两种SHSL结构的FPGA硬件实现,并对其进行了特性分析。一个被优化以减少延迟,而另一个被优化以提高吞吐量。整个部署是基于C++进行的,并使用了Vivado HLS在Virtex7和UltraScale+上进行实现。
6.1 架构概述
这两种架构实现了对SHSL数据结构的流水线遍历。两种体系结构的HTT遍历模块被划分为K=2个并行管线。每条管线i∈[1,2,…,K]执行由第i个PLS组中的根指针地址选择的HTT的遍历。
对于低延迟架构,HTT遍历模块管线被划分为d个阶段,使得每个阶段专用于单个HTT级别的遍历。管线级j∈[1,2,…,d]由一个遍历引擎(TE)和一个内存组成,存储所有ABB(Bin从1到M)的j级HTT节点。第一个d-1级别的遍历引擎仅用于处理DAT节点,而LB节点处理仅在d级完成。
为了提高低延迟架构上的寻址速率,高吞吐量架构将低延迟架构的每个管道阶段分为多个阶段。通过减少每个阶段的逻辑电平数,可以获得更短的时钟周期,这也提高了寻址率。
6.2 结果
对于表4中给出的每个设计,有四个性能指标值得关注:寻址率、延迟、片上内存使用率(BRAM)和逻辑使用率。寻址延迟或挂钟时间计算为时钟周期乘以管道阶段数。
在这里,首先讨论高吞吐量体系结构的性能。然后,比较了高吞吐量体系结构与低延迟体系结构的开销。
(1)高吞吐量架构:在Virtex7上实现的高吞吐量架构的寻址率随着前缀表的大小而降低。使用25k前缀时,最多支持345 Mpacket/s,而当使用290k前缀时,寻址速率降低到264 Mpacket/s,并且使用最大前缀表进一步降低到167 Mpacket/s。
前缀表大小对寻址速率的影响与片上存储器在FPGA中的分布有关。片上存储器、block RAM被分成列。当SHSL数据结构的一个级别被映射到多个block RAM列时,由于访问多个列的路由延迟,时钟周期增加。作为路由延迟增加的直接结果,寻址率降低。
延迟也随着前缀表的大小而增加,这是在较大场景下时钟周期降低的结果。对于包含290 000个前缀的前缀表,寻址延迟在189.6到246.5 ns之间,而对于最大前缀表,寻址延迟增加到396.4。
block RAM的使用与前缀表大小几乎成线性关系,这是图9(c)中观察到的线性存储器消耗的结果。
由于在较大的场景中block RAM的消耗量较大,FPGA逻辑使用量随着前缀表的大小而增加。在最小场景和最大场景之间,逻辑使用增加了61%。实际上,将单个block RAM组合成一个大内存所需的电路消耗FPGA逻辑。
由于Virtex7上的高吞吐量架构性能受到路由延迟的限制,在UltraScale+上评估了该架构,该FPGA具有更深的block RAM列和减少的路由延迟。在这个FPGA上,对于最大的情况,时钟周期比Virtex7缩短了1.7倍。因此,寻址速率增加到295 Mpacket/s,并且寻址延迟减少到219.3 ns。此外,由于UltraScale+的内部结构经过修改,允许在block RAM列中构建大内存,而无需额外使用逻辑资源,因此逻辑消耗比Virtex 7减少了1.6倍。
为了进一步提高寻址速率,可以修改高吞吐量体系结构,使寻址速率加倍。所提出的技术包括使用两个并行寻址引擎共享Virtex7和UltraScale+上的双端口block RAM。单个双端口内存块可以同时为两个寻址引擎提供服务。因此,带有双端口内存块的高吞吐量体系结构在Virtex 7和UltraScale+上分别可以支持333 Mpacket/s和589 Mpacket/s。然而,由于实现了两个并行寻址引擎,逻辑消耗几乎增加了一倍。
(2)高吞吐量体系结构的开销:在使用Virtex7时,高吞吐量体系结构比低延迟体系结构几乎提高了三倍,使用UltraScale+时寻址率提高了3.3倍以上,如表4所示,高吞吐量架构使用的FPGA逻辑比低延迟架构多1.8倍,因为它的流水线更深,这就要求FPGA逻辑在每个流水线阶段同步中间结果。尽管如此,与低延迟架构相比,高吞吐量架构增加的寻址速率超过了逻辑消耗开销。此外,片上存储器的使用不受管道深度的影响,因此,对于两种架构,block RAM的消耗保持相似。
与低延迟体系结构相比,高吞吐量体系结构的缺点在于寻址延迟增加。由于流水线级的数量增加了5.4倍,而时钟周期减少了不到3倍,与Virtex7上的低延迟架构相比,最大前缀表的寻址延迟增加了3倍,达到397 ns。使用UltraScale+,高吞吐量体系结构的寻址延迟仅比低延迟体系结构增加1.7倍,达到220 ns。
7 结束语
本文提出了一种可扩展的高性能IPv6寻址算法,以满足当前和未来网络应用的性能要求。SHSL利用前缀特性创建一个浅而高效的数据结构。首先,分配的IPv6地址空间用于有效地将前缀放入其MSB上。在每个bin中,前缀按FIB前缀长度分布分组排序。然后,将每个前缀组编码在混合Trie树(HTT)中。本文重新讨论了多比特Trie的概念,但对基于前缀密度的节点数进行了调整,提高了内存效率。将Trie叶片转化为LB,进一步提高了记忆效率。
提出的数据结构支持增量更新,并有效地映射到硬件上。提出了一种利用片上存储器的流水线高吞吐量硬件体系结构。
使用实前缀表和合成前缀表对SHSL进行了评估,该表包含580 000个IPv6前缀,在内存访问数量和线性存储开销比例方面,SHSL表现出对数比例因子。与其他著名的方法相比,SHSL将每个前缀所需的内存量减少了87%。
