基于Weka软件的数据挖掘技术在学生体质健康分析中的应用
2022-06-09高岩汪正焰王志玲
高岩 汪正焰 王志玲
(江苏信息职业技术学院基础部体育部 江苏 无锡 214153)
信息技术革命衍生出的大数据时代让世界上的每个角落通过互联网络联系到一起,信息爆炸时代产生了海量数据,应运而生的数据挖掘技术能够在浩瀚无垠的信息海洋中去粗取精、去伪存真地将浩如烟海的数据转换成知识。
1、研究目的
近年来,体育领域中不乏数据挖掘的身影,主要应用在竞技体育训练比赛、体质健康监测、体育教学、体育新闻报道和体育产业等领域之中。本文通过Weka软件对学生体质健康测试的相关数据进行分析,探究数据挖掘在学生体质健康分析中的应用。
2、研究方法
2.1、文献资料法
通过登录CNKI中国学术期刊网络出版总库、CNKI中国优秀硕士学位论文全文数据库、维普中文期刊数据库、万方学术期刊、万方数据知识服务平台和高校图书馆联盟文献共享服务平台获得国内外足球运动训练负荷研究的最新文献。
2.2、数据挖掘
数据挖掘是一种信息提取活动,它是要用自动化的方法对大量数据进行系统分析,目标是发现在数据库中有用的隐藏因素。基于这些发现,信息工作者能够更好地做出决策和解决问题。数据挖掘是一门综合性的学科,它的主要分析思想和方法来源于统计学、模式识别、公式发现、仿生物技术、人工智能、模糊数学等学科。
本文使用Weka,一种使用java语言编写的数据挖掘机器学习软件,主要应用于科研、教育和应用领域,是目前掀起的数据挖掘和机器学习的热潮中,较为友善的一款软件,其代码开源,可以免费下载使用,且操作界面友好。
3、结果与分析
3.1、数据挖掘对象及数据收集
本文以某高校大一、大二、大三、大四的体质健康测试数据研究对象,对学生体质健康数据挖掘进行分析。
3.2、数据准备
原数据格式为.xsl,通过Excel转成.csv格式进行数据挖掘,男生数据556条,女生数据577条,8个属性值,分别为身高体重分数H-Wr、 肺活量体重分数F-Wr、50m跑50mr、1000m/800m1000/800r、坐位体前屈ZWTQQr、立定跳远LDTYr、仰卧起坐/引体向上Y/Yr、总分成绩ZFDJ,除身高体重分数H-Wr属性的值分为low Weight、normal、overWeight和obesity外,其他属性的值均分别为fail、quality、good和excellent。
在数据存取过程中由于人工失误或机器故障可能导致数据出现噪声、不完整和不规则。噪声在这里特指的是数据背离有效区间而出现的错误,比方说,坐位体前屈的测试数据会出现负值,但年龄、跳远等是不可能出现负数的;不完整是指缺乏要分析的属性值,比如,要分析成绩,某个学生被录进系统中,有相关信息却没有录入成绩,或因病缺席等因素导致个别测试项目没有测,某几项数据出现空白;不规则也叫不一致,在不同的存储单元储存的某些相同的体质测试数据可能存在名称或格式上的差异。数据的这几个性质都给数据挖掘带来难度,为了方便快捷的分析学生体质建康,我们需要预先对数据进行处理,以便分析。可以采用以下处理方法对有噪声、不完善、不规则的数据进行处理:
(1)数据转换。
由于Weka数据处理的常用文件格式为.arff和.csv两种,需要对数据进行格式的转换可通过Excel和Ultra-Edit进行处理。
(2)数据清理。
数据因为测试机器或是人工原因导致数据出现的缺失、有噪音和非法数据可通过手动补全遗漏数据、算法(FP-Growth算法等)过滤对数据进行筛查和处理。
(3)数据规约。
对于一些大型的数据分析公司或单位来讲,即使对数据库中的数据进行了冗余和冲突处理后,其数据的体量依然庞大。这些海量的数据直接进行数据挖掘处理是不可行的,这会导致分析运行的时间出现较常的延时情况,效率就大打折扣了。此时,可以通过对数据进行规约处理,从而压缩数据的实际数量。规约处理存在两个必须满足的条件:一是规约后的数据量应该比原数据量少;二是规约后的数据应该保持原数据的完整性。只有这样,两个数据集对于同一个分析算法才会生成相同或相近的分析结果。
本文对学生体质健康数据采用离散化,把一个线性空间中的数据划分为多个线性子空间,对每个子空间的数据可用一个值来替代,以实现数据压缩。
经过以上几步的数据处理,得到如下图的数据集(部分)。
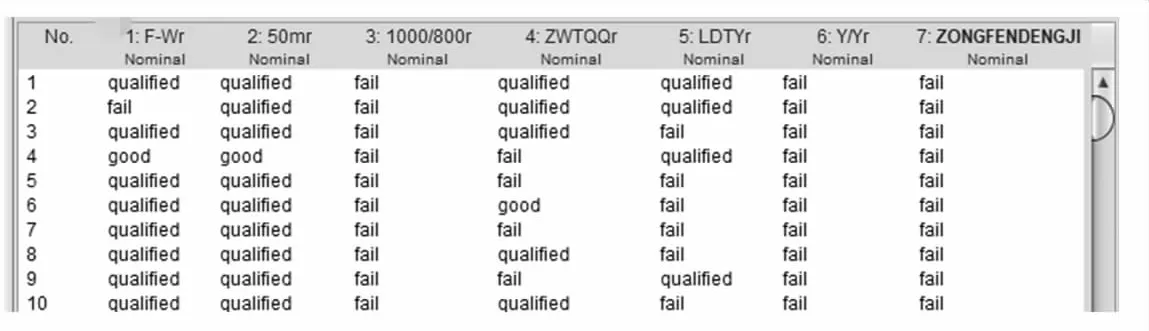
图2 Weka中的数据集视图(部分)
3.3、数据挖掘过程及分析
对数据库中的数据进行了预处理后可以开始进行数据的挖掘工作。此次实验数据来源于某高校体质测试数据,利用数据库技术将多个数据源中的可能对体质测试总成绩造成影响的项目进行整合,合并成一个用于分析学生体质测试成绩的数据表。运用Weka软件,挖掘出学生身高体重分数、肺活量体重分数、50m跑、1000m/800m、坐位体前屈、立定跳远、仰卧起坐/引体向上这几项测试成绩与体质测试成绩之间潜在的关系。
(1)分类分析。
分类是数据挖掘中一个极其重要的技术,应用范围非常广泛。通过对学生体质测试数据进行分类分析,找出测试数据所反映的各项身体素质之间的共性特征和各项身体素质之间的水平差异性。此外由于分类器的构造方法主要来源机器学习方法、统计方法、神经网络方法等等,因此分类也可以用于预测。
常用分类算法有:①决策树算法:决策树也称为判定树,它是以数据实例为基础的机器学习方法。它从无序和无规则的训练元组中推导出以分枝树为表示形式的分类规则。未知数据可以从树根节点沿唯一一条路径到达叶子节点,每个叶子节点就是一个具体的分类。生成决策树构造算法有ID3算法、C4.5算法、CART、SLIQ算法、SPRINT算法等;②贝叶斯分类算法:贝叶斯分类属于统计学方法和参数判别方法,是一种应用数学概率统计知识来进行分类的算法。由于其算法简单,分类精度高,常应用于大型数据库系统;③神经网络分类:其分类模型的建立,是在训练阶段通过调节神经网络中每个连接的权值,使之预测出输入样本的正确类别。这种方法有时又称为连接者学习。目前应用最广的神经网络算法是20世纪80年代提出的BP算法。此外还有关联规则、支持向量机、惰性学习法等分类算法。
本文采用决策树中的J48算法分别对男生和女生的数据进行分类分析,采用cross-validation交叉验证为测试模式,默认十折交叉验证进行分析,分类器输出结果如图3和图4所示,正确率为87.4101%和84.5754%。产生的决策树如图5和图6所示。
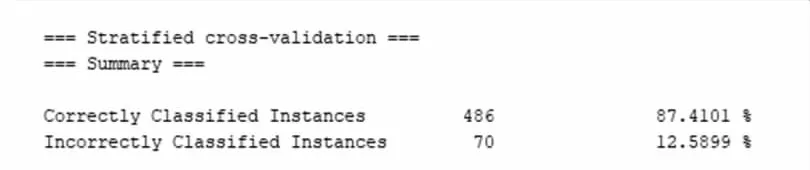
图3 J48算法产生的决策树的正确预测率图(男)
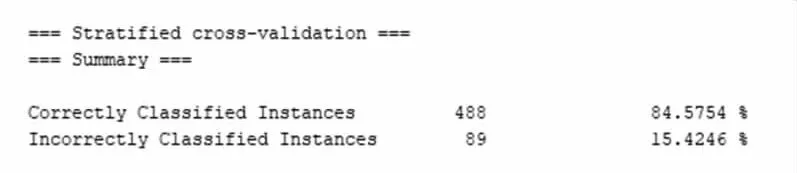
图4 J48算法产生的决策的正确预测图(女)

图5 J48算法产生的决策树图(男)
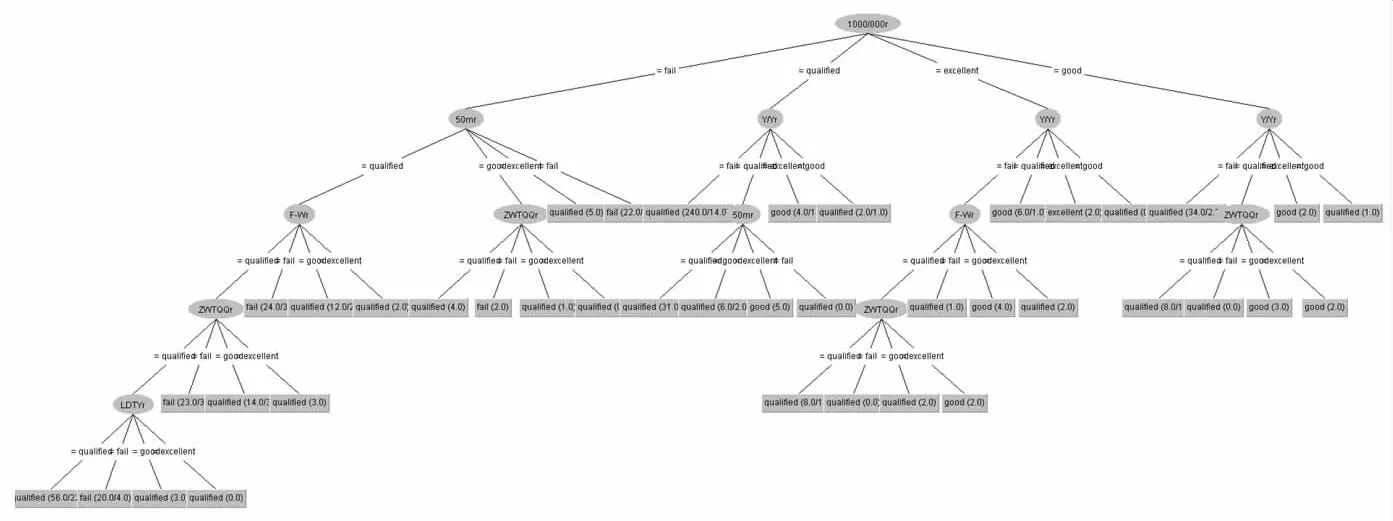
图6 J48算法产生的决策树图(女)
结合《国家学生体质健康标准(2014)》(以下简称《标准》)从建立的决策树模型中推测影响该校女生体质测试成绩的主要因素为50m和800m成绩,影响男生体质测试成绩的主要因素为1000m成绩,其次为50m和坐位体前屈的成绩。在《标准》中50m跑、长跑(800m、1000m)各占比20%,其次为体重指数、肺活量各占15%,剩余3项内容各占10%。
通过决策树模型可以看出,该校大学生女生的测试成绩,只要50m和800m成绩能够及格,其测试总分基本上能够及格,说明这两项成绩对于女生体质测试成绩影响较为大。女生在爆发力上与男生来说相对薄弱一些,如果能在50m上及格,也能比较容易通过测试。对于该校男生来说除了1000m的长跑外,50m、坐位体前屈也是影响其体质测试成绩能否合格的因素。对于该校所有学生来说,长跑项目(800m和1000m)是较为薄弱的,说明学生的有氧耐力相对于其他身体素质较为欠缺,在爆发力项目上男生成绩比女生好,而在柔韧性上,女生的成绩优于男生。
该校学生有氧耐力和爆发力有待进一步的训练提升,除此之外,该校男生与女生相比,在柔韧性方面相对薄弱,在体育课和课余体育锻炼中,男生应当适量增加柔韧性的针对性练习。
(2)关联规则分析。
通过关联规则挖掘算法,去描述测试所得的各项学生体质测试数据中各项身体素质数据项之间所存在的关系的规则,例如,在力量素质中立定跳远中出现的规律出现可能在力量素质中引体向上中也会出现,即找出隐藏在数据间的关联或相互关系。典型的算法有Apriori算法,其侧重于找出数据库中某些特定事件一起发生的情况,以发现那些可信的并且具有代表性的规则。此算法的基本思想是首先通过迭代挖掘所有频繁项集,然后利用频繁项集构造满足用户最小置信度规则。
图7为采用Apriori算法得到男生体质测试的五条关联规则。对5条关联规则进行解读:规则1:1000m成绩及格、立定跳远及格、引体向上不及格的人,体测总分能够及格;规则2:体型正常、1000m及格、引体向上不及格的人,体测总分能够及格;规则3:1000m不及格的人,引体向上可能不及格;规则4:体型正常、50m及格、1000m及格的人,体测总分能够及格;规则5:1000m及格、引体向上及格的人,体测总分能够及格。

图7 男生体质测试关联规则
图8为采用Apriori算法得到女生体质测试的五条关联规则。5条关联规则进行解读:规则1:体型正常、体测总分及格的人,50m成绩是及格的;规则2:仰卧起坐及格的人体型属于正常一类;规则3:体测总分及格的人,50m能够及格;规则4:肺活量能够及格的人,体型一般正常;规则5:肺活量及格、50m及格的人,体型正常。

图8 女生体质测试关联规则
对男生而言,引体向上虽然是最头疼的测试项目,然而其单项成绩能否及格对体质测试总分是否及格的影响并不大,1000m与体测总分能否及格的关联性较大。与男生相比较而言,体型对女生体质测试总分的影响要更大一些,且体型与各项身体素质的关联度较男生更高。
4、结论
本文使用 Weka平台数据挖掘技术对学生体质健康测试成绩进行分析,可以提高测试数据的利用水平,获得测试数据之间潜在的规律和趋势。数据挖掘技术在学生体质健康分析中的应用中具有以下几个特点:
4.1、可行性
通过本文对数据进行挖掘的过程和检索过的文献发现,基于数据挖掘领域的关联规则可应用在体质监测领域,通过对数据的筛选经过算法的处理从而得到数据背后隐藏的关系;关联规则反映了该校学生体质指标间的潜在规律,分析该校学生在运动锻炼和身体素质方面存在的共性和薄弱点;可用于体质监测工作的改进,有助于进一步指导学生进行体育锻炼和运动。
4.2、有效性
每年我国学生都要进行体质健康测试,覆盖到每位学生,其背后是海量的数据,通过挖掘技术处理并分析这些体质数据背后潜在的有用信息,通过运用体育领域知识,为体质数据分析和体质健康实际工作提供科学的决策依据。
通过对不同指标之间的数据挖掘,发现其规律,分析原因,掌握规律,更深层次地去了解学生各项体质测试数据之间的关联,更好地为体质测试的后续工作提供,这些规则的发现一定程度地证明了关联规则挖掘技术应用的有效性;数据挖掘作为可作为体质测试数据分析的工具,进一步为体质科研服务提供助力。
4.3、指导性
可以针对性地挖掘不同项目和体质健康之间的关联,为校园体育服务提供帮助;挖掘不同特征学生的体质健康水平,为学生健康管理服务和不同人群的体育运动负荷安排提供建议和指导;挖掘学生体质规律,为学生体质健康促进提供指导等。
4.4、局限性
通过实际操作,不难发现数据挖掘存在的局限性。像关联规则挖掘技术作为一种工具,无法实现对结果的最终解析,需专业人员结合相关领域的知识对数据结果进行解释、翻译和表达。对于数据挖掘结果的利用与开发,需要体育专业人员和数据挖掘专业人员共同努力。数据挖掘结果的落地和对学生体质测试后续服务问题,仍然需要体育工作者结合数据分析,根据学生的实际情况制定相关锻炼计划并实施。
