基于半监督深度学习的木马流量检测方法
2022-06-09谷勇浩黄博琪王继刚吴月升
谷勇浩 黄博琪 王继刚 田 甜 刘 焱 吴月升
1(北京邮电大学计算机学院 北京 100876) 2(智能通信软件与多媒体北京市重点实验室(北京邮电大学) 北京 100876) 3(广东省信息安全技术重点实验室(中山大学) 广州 510275) 4(中兴通讯股份有限公司 南京 210012) 5(百度在线网络技术(北京)有限公司 北京 100080)
木马,别称木马病毒,英文名为Trojan.它是指隐藏在正常程序中的一段具有特殊功能的恶意代码,是具备破坏和删除文件、发送密码、记录键盘和发起DoS攻击等特殊功能的后门程序.木马病毒是计算机黑客用于远程控制计算机的程序,将控制程序寄生于被控制的计算机系统中,对被感染木马病毒的计算机实施操作.
国内外对木马病毒检测方法的研究开展得较早,检测方法主要包括3种:1)基于程序特征码的检测方法;2)基于主机行为特征的检测方法;3)基于网络行为特征的检测方法.前2种检测方法在木马病毒种类增多和变异较快的特点下性能下降明显;第3种方法因硬件捕获流量能力的提升,可以实时地识别未知流量,弥补了前2种方法的缺陷,已成为学术界的研究热点.
基于网络行为的木马检测方法的有效性主要取决于特征的提取和分类算法.传统机器学习方法依靠人工设计的特征,如基于网络协议的特征、基于进程、api等统计特征,以及支持向量机、决策树、k-means聚类和决策树等分类算法,取得了较好的检测效果.但依然存在特征设计不够准确、识别未知样本能力不足的问题.
近年来得益于人工智能领域的发展,深度学习迅速在图像识别、自然语言处理等领域取得成功[1-2].传统机器学习相对于深度学习而言都为浅层结构算法,这些算法在解决简单分类问题时足够优秀,但在拟合非线性函数时其泛化能力会下降.而深度学习方法是利用多层神经网络结构,对样本进行表征学习,可以很好地弥补这些算法在特征选择和未知样本分类的不足.
为了解决现有木马流量检测方法中人工提取特征不够准确、大量标记样本难以获取、无标记样本没有充分利用、模型对于未知样本识别率较低以及半监督深度学习模型mean teacher中随机噪声引起的泛化能力不足等问题,本文采用对抗训练来改进半监督深度学习的方法,将虚拟对抗训练和mean teacher模型相结合,主要贡献包括2个方面 :
1) 引入半监督深度学习模型mean teacher,充分利用未标记数据来改善模型检测性能.在USTC-TFC 2016数据集中,模型仅需要10%的标记数据就能在二分类、多分类以及未知样本分类任务中达到98%的准确率.同时,随着标记样本数量的减少,半监督深度学习模型检测性能的下降程度明显小于有监督模型.
2) 将虚拟对抗训练与mean teacher模型相结合,提出虚拟对抗mean teacher模型(virtual adver-sarial mean teacher, VMT),改进mean teacher模型中的随机噪声,进一步提升模型泛化性能.相比mean teacher模型,VMT模型在各对比实验中具有更好的检测效果,在多分类任务中提升明显.
1 相关工作
1.1 木马检测方法
1) 基于程序特征码的检测方法
该类方法是最早用于恶意软件的检测,所谓程序特征码是从木马病毒文件不同位置提取的字节序列,通过特征码匹配识别木马病毒.这类方法能够准确检测已知的恶意软件,但是它依赖专家经验,需要花费大量的人力和物力不断更新特征库.同时,该类方法无法检测新型恶意软件,尤其是采用混淆和变形技术的恶意软件.文献[3]在此基础上,将样本的二进制特征码转换为灰度图,再使用基于K-均值和多样性选择的集成学习分类方法进行分类.
2) 基于主机行为特征的检测方法
该类方法需要监视程序在主机上的动态行为,判断该程序是否为木马.监视内容主要包括:进程派生和执行情况、系统文件的读写情况、注册表项的操作情况、特定API的调用情况、非法驱动程序加载情况、Socket外连情况等.该类方法主要缺点包括:①对未知恶意软件的检测,存在误报的可能;②需要实时监控主机行为,系统资源的开销大,会影响主机的正常工作.文献[4]通过训练一个基于主机行为特征的SVM分类器,解决第一类方法存在的特征码提取错误和提取滞后等问题.同时,采用交叉验证方法提高60种恶意软件家族的检测准确率.
3) 基于网络行为特征的检测方法
该类方法分为基于网络通信负载特征匹配方法和基于通信行为的木马检测方法.
基于网络通信负载特征匹配方法采用深度包检测技术,截获网络通信负载信息并且提取特征,建立恶意流量行为特征库,当待测流量的特征与特征库中的特征匹配成功时,触发流量异常报警.文献[5]分别利用IP包头信息和DPI技术提取pcap包负载特征,进行网络恶意软件的分类.文献[6]提取HTTP数据包负载中的URL等信息后计算URL的可疑度,可以对木马流量进行有效检测.
基于通信行为的木马检测方法不是通过截取流量负载中的特征进行分析,而是通过分析木马流量通信行为进行识别.这类方法的有效性取决于提取的通信行为特征,对专家经验有着较高的要求.通过人工提取特征,再利用机器学习模型实现对木马流量的识别.人工提取特征虽然有一定效果,但是对未知恶意流量检测能力有限,存在误报或漏报.文献[7]通过提取早期阶段的木马流量通信行为特征,识别远程访问特洛伊木马.文献[8]从传输层和网络层提取6个特征,这些特征与具体应用层协议无关,不受流量加密技术的影响;同时,该方法不需要木马结构及其通信协议等先验知识也能进行检测.文献[9]通过跨协议和跨层提取的972个行为特征,采用有监督分类方法对网络流量分类,实现恶意软件检测.特征的选择来源于事务、会话、流和时间窗口等不同粒度的流量数据,通过特征选择方法选出有效特征,提高检测准确率.文献[10]比较了4种机器学习算法(随机森林、序列最小优化、多层感知器和Logistic回归模型)的性能,寻找最佳超参数和特征集选择来优化分类器.随机森林分类器通过查看网络包标识符,如包长度、包和标志计数以及到达间隔时间,识别出与TrickBot相关的流,准确率达到99%.文献[11]提出一种面向HTTPS隐蔽隧道的加密流量检测方法,并将木马通信划分为元数据交互阶段与加密应用数据交互阶段,提出基于时间序列模式的木马流量检测方法,从测试结果看,该方法能够有效检测出使用HTTPS 隧道传输数据的加密木马.
本文所提方法是基于网络行为的检测方法,但基于网络行为的检测方法的有效性取决于人工提取的特征,而受到木马变异速度的加快,特征越来越难以设计,这就需要深度学习中的表征学习进行特征的提取.
1.2 木马流量的表征方法
分类模型的好坏很大程度上取决于选取的特征,即从原始流量中提取能区分该流量是否是木马流量的属性特征,如分析木马流量负载中的特征码和不同阶段中木马流量通信行为特征等.这些特征的提出都依赖专家经验,而专家经验的准确与否直接影响分类效果.本文使用原始流量可以很好地利用深度学习进行特征提取,从而代替人工提取特征,这就是表征学习.表征学习按照表征方法的不同,可以分为表征为图像、表征为时间序列数据和表征为拓扑图.
1) 表征为图像
表征学习又称表示学习,是利用某种方法获取每个样本的向量化表达,以便构建分类器模型,避免手动提取特征的繁琐,典型方法是表征为图像,也是最早用于恶意流量分类的表征方法.文献[12]提出一种基于卷积神经网络的恶意软件流量分类方法.该方法不需要手工设计特征,直接将原始流量转化为图像作为分类器的输入数据.文献[13]先训练递归神经网络提取进程行为特征,然后训练卷积神经网络将所提特征转化为特征图像后进行恶意软件分类.文献[14]通过将流量表征为图像,利用集成森林交替生成类向量和特征向量,对恶意软件进行分类,提出一种混合分层感知方法.该方法具有自动设置参数的自适应特性,因此对小尺度和大尺度数据都能很好地工作,具有较好的计算效率.
2) 表征为时间序列数据
从数据的时序关系来看,恶意软件通信行为数据类似于自然语言中的单词,都是按照顺序获取,恶意软件通信流量数据间的潜在语义关系类似于句子的先后关系.同时,不同目的地和不同通信内容的恶意软件产生的流量可能具有相同功能,这和不同单词组成不同句子可能具有相同语义类似.文献[15]利用恶意软件通信行为变化和具有相同潜在语义特征的特点,挖掘恶意软件通信动态行为与自然语言句子间的相似性,使用递归神经网络模型进行分类,预测未知恶意软件.文献[16]提出了一种基于时空分层特征的神经网络检测模型——HSTF模型,采用CNN和LSTM相结合的方式,输入数据包括原始图像数据、包级特征和流级特征,提高模型的自学习能力,检测基于HTTP的木马,准确率达到99.4%.
3) 表征为拓扑图
图表示学习,也称为图嵌入,它是将高维度的图信息降到低维空间,同时最大化保留图原本的结构信息,图表示学习常用于节点分类和链路预测等任务.图中节点的相似性可以通过学习拓扑图中节点间的结构一致性进行表征,struc2vec表征学习方法使用层次结构来度量拓扑图中节点的相似性,通过构建一个多层图对结构相似性进行编码,然后生成节点间的结构上下文语义.文献[17]利用深度学习模型和图嵌入方法实现恶意软件检测,采用的深度学习框架包括2个叠加去噪自编码器,其中一个去噪自编码器与node2vec技术结合用于学习程序函数调用图的潜在表示,另一个用于学习程序的Windows API调用关系的潜在表示.
为了更好地保留流量的原始特征信息,发挥深度学习模型的表征学习能力,本文拟采用表征为图像的方法.
2 基于半监督深度学习的木马流量检测
2.1 木马流量检测系统架构
木马流量检测系统主要包括数据准备、数据预处理、模型训练,以及检测和结果输出等四大功能模块,如图1所示.其中,准备输入的数据是实时网络流量或静态pcap文件,数据预处理的详细流程在第3节描述,训练数据经过数据过滤和格式化用于模型训练,待测数据经过数据过滤后输入模型进行检测和结果输出.本文采用半监督深度学习模型进行训练,相应模型分别在2.2节和2.3节详细说明.
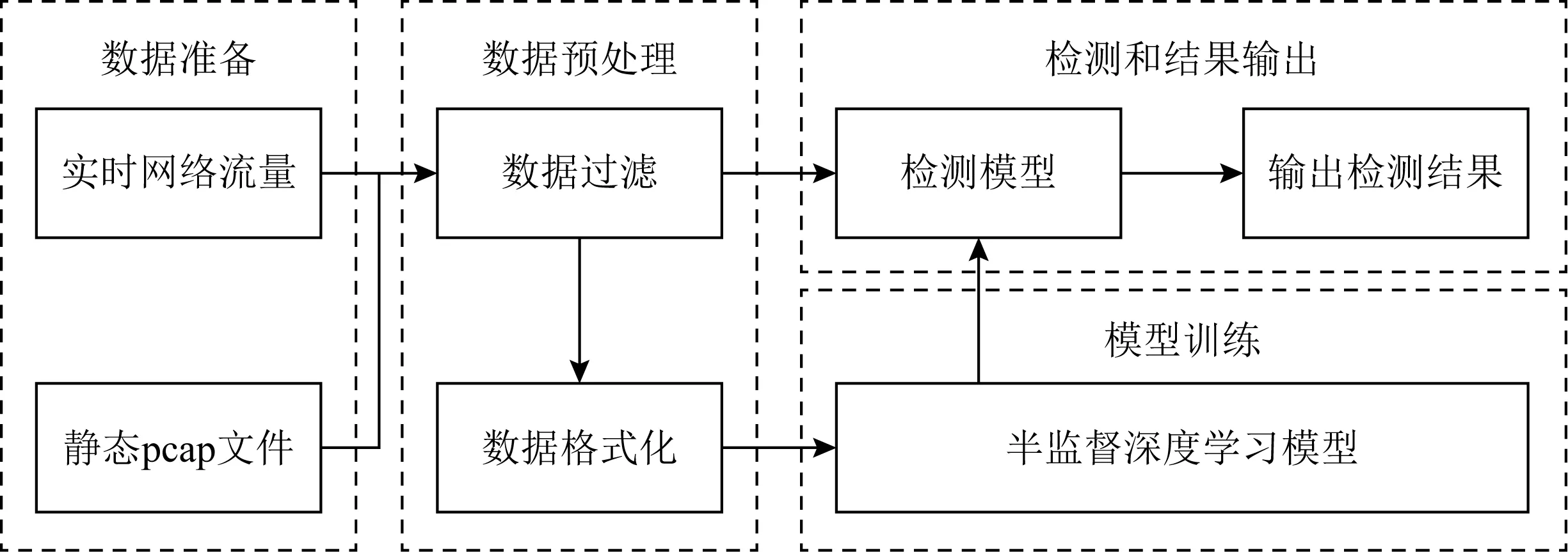
Fig. 1 Trojan traffic detection system architecture图1 木马流量检测系统架构图
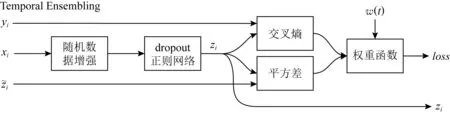
Fig. 2 Temporal ensembling model training steps图2 Temporal ensembling模型训练步骤
2.2 基于mean teacher的木马流量检测
半监督深度学习方法先用有标记数据训练网络,通过隐藏层提取特征,用这些特征训练的分类算法对未标记数据进行分类,将分类结果作为未标记样本的伪标签,经过多次训练,网络对未标记样本的预测趋于正确,达到提升模型性能的目的.
mean teacher模型[19]解决temporal ensembling模型更新较慢的问题,即无标签数据的信息只能在下一个epoch 时才能更新到模型中.该模型既充当学生,又充当老师.作为老师,用来产生学生模型学习时的目标;作为学生,利用教师模型产生的目标进行学习.同时,教师模型的参数是由上一次(step)学生模型的参数经过EMA得到.教师网络权重参数计算公式为
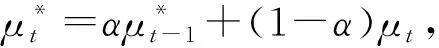
(1)
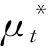
如图3所示,mean teacher模型中的连续损失函数Lm定义为教师网络预测值(权重μ*和噪声γ′)与学生网络预测值(权重μ和噪声γ)间的均方误差,再加上学生网络对有标记样本xl的交叉熵分类损失:
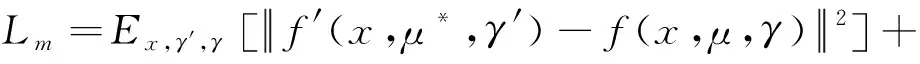
(2)
其中,f′为教师网络输出预测值,f为学生网络输出预测值,x为输入样本,M为类别总数,c为类别编号,yxlc为样本xl是否属于c类的指示变量(1表示属于,0表示不属于),pxlc为样本xl属于c类的预测概率.其中,μ与μ*由式(1)所得.
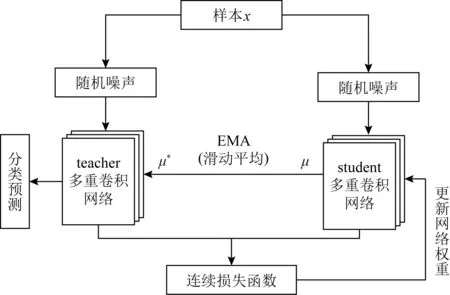
Fig. 3 Trojan traffic detection model based on mean teacher图3 基于mean teacher的木马流量检测模型
mean teacher模型中教师网络和学生网络的结构与文献[12]使用的CNN模型一致,都采用手写网络lenet-5的结构,如图4所示:

Fig. 4 Network structure of teacher and student图4 教师和学生的网络结构图
mean teacher模型的训练过程如算法1所示.
算法1.mean teacher模型训练.
输入:x为输入样本,xlab为有标签样本,xt为第t批的输入样本;
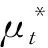
α为超参数;
γ为随机噪声生成函数;
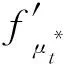
epochs为训练步数,取值6 000;
batch为一批训练数,取值50.
输出:网络参数为μ*的教师网络.
① foriin [1,epochs] do
② fortin [1,batch] do
③f=fμt(γ(xt));
/*学生网络预测值f*/
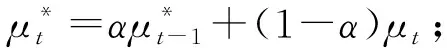
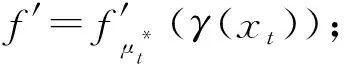
/*教师网络预测值f′*/
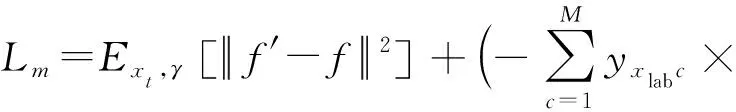
ln(pxlabc));/*描述见式(2)*/
⑧ end for
⑨ end for
⑩ outputμ*./*最终训练得到的网络参数*/
2.3 基于虚拟对抗mean teacher的木马流量检测
1) 虚拟对抗训练
由于未标记样本的存在,随机噪声的数据增强方式不利于半监督学习.为了克服随机噪声产生类似对抗样本攻击对模型性能的影响,Goodfellow等人提出对抗训练Adversarial Training[20]方法,即在模型训练过程中的训练集包括原始样本和对抗样本,对抗样本生成方法取名为fast gradient sign method(FGSM).该方法利用模型参数、输入样本以及样本标签生成噪声radv,损失函数Ladv定义为
Ladv=D[q(y|xlab),p(y|xlab+radv,θ)],
(3)
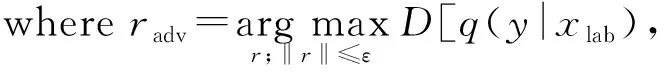
(4)
其中,D[p,q]为计算分布p和q之间距离的函数(如交叉熵函数),p为模型的预测分布函数,q为实际的分布函数.y为标签,xlab为标记样本,r为扰动,θ为模型参数,ε为控制扰动大小的超参数.radv可以近似为
radv≈εsgn(g),
(5)
其中,g为模型梯度下降值:

(6)
对抗训练在有监督学习模型的泛化能力已经得到证明,但式(3)和(4)不适用于半监督学习.为解决该问题,Takeru等人提出虚拟对抗训练(virtual adversarial training, VAT)方法[21].Goodfellow提出对抗训练方法,对抗训练寻找的输入样本扰动方向是使模型对输入样本的预测结果最大程度地偏离该样本正确标签的方向,只适用于有标记样本的训练;VAT寻找的扰动方向是使无标记样本预测的输出分布偏离模型预测虚拟标签(virtual label)的方向,可以适用于无标记样本.因此,VAT可以同时计算有标记样本和无标记样本的扰动.VAT算法损失函数定义为
Lvadv=D[q(y|x*),p(y|x*+rvadv,θ)],
(7)
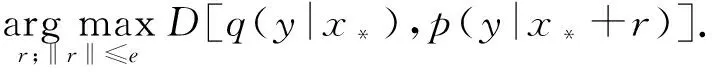
(8)
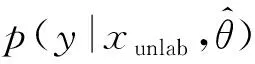
LDS(x*,θ)D[q(y|xlab),p(y|xlab+radv,θ)]+
(9)
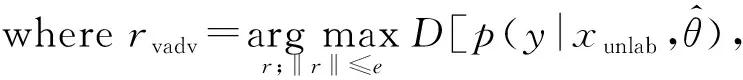
(10)
其中,rvadv可以近似为
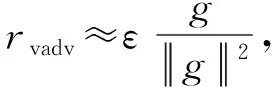
(11)
(12)
2) 虚拟对抗mean teacher模型
为了提升mean teacher模型的泛化能力,本文将虚拟对抗训练与mean teacher模型相结合,提出虚拟对抗mean teacher模型,如图5所示.对抗噪声一方面能使模型抵御对抗样本攻击,另一方面添加的扰动使模型拟合产生的对抗样本,达到比随机噪声更好的正则化效果,提高mean teacher模型的泛化性能.在虚拟对抗mean teacher模型的训练过程中,对抗噪声的训练与mean teacher网络的训练同时进行.模型在每个训练步骤进行梯度下降的同时,要使连续损失函数Lm和对抗损失函数LDS都下降到最小,故虚拟对抗mean teacher模型的损失函数L为
L=Lm+LDS.
(13)
图5所示的虚拟对抗mean teacher模型相对于图3所示的mean teacher模型有3点变化:
① 输入教师网络和学生网络的样本从添加随机噪声变为添加对抗噪声;
② 增加对抗损失函数(式(9)),同时更新对抗噪声(式(11));
③ 网络权重参数的更新从只依赖于连续损失函数(式(2))变为同时依赖于连续损失函数和对抗损失函数(式(13)).
虚拟对抗mean teacher模型的训练过程如算法2所示,模型的3点变化反映在算法2中,分别表现为:
① 算法1输入中的“γ为随机噪声生成函数”变为算法2输入中的“r为对抗噪声生成函数”;
② 算法1方法体的行⑥变为算法2方法体的行⑥⑦,同时算法2中增加行⑧;
③ 算法1方法体的行⑦变为算法2方法体的行⑨.
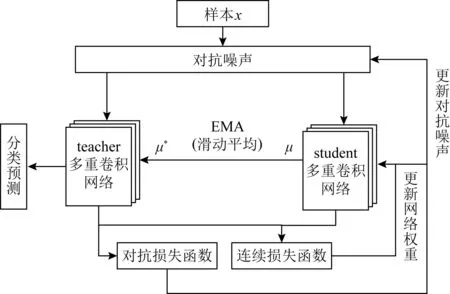
Fig. 5 Trojan traffic detection model based on virtual adversarial mean teacher图5 基于虚拟对抗mean teacher的木马流量检测模型
算法2.虚拟对抗mean teacher模型训练.
输入:x*为输入样本,包含xlab有标签样本和xunlab无标签样本,x*t为第t批的输入样本;
α为超参数;
r为对抗噪声生成函数;
epochs为训练步数,取值6 000;
batch为一批训练数,取值50.
输出:网络参数为μ*的teacher网络.
① foriin [1,epochs] do
② fortin [1,batch] do
③f=fμt(r(x*t));
/*学生网络预测值f*/

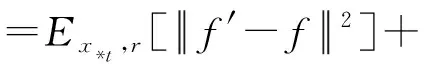
⑦LDS=D[q(y|xlab),p(y|xlab+radv,
⑧ 分别利用式(5)和式(11)更新radv和rvadv;
⑩ end for
3 实验分析
3.1 数据集介绍
异常流量检测领域的开源数据集多数是提供每个样本的特征属性,这些特征是经过人工筛选或统计计算得到,如KDD99和NSL-KDD提供了41个流量特征.本文所提方法不采用人工提取的特征,而是使用原始流量信息,但是木马流量分类中可用原始流量的开源数据集较少,本文使用USTC-TFC 2016[12]数据集作为输入.该数据集的文件格式为pcap,大小为3.71 GB,数据集中流量采集服务器的ip和mac已用随机地址代替.
USTC-TFC 2016数据集包含恶意流量与正常流量2部分.恶意流量数据集包含Nsis,Virut,Neris,Tinba,Hitbot,Cridex,Geodo,Zeus,Miuref和Shifu等10种流量.该流量由CTU大学研究人员于2011—2015年从真实环境采集.正常流量数据集包含SMB,Facetime,MySQL,World Of Warcraft,Gmail,BitTorrent,FTP,Weibo,Outlook和Skype等10种流量.该流量使用IXIA公司专业仿真设备IXIABPS进行采集.按照文献[12]对流量的处理方法,本文将原始流量pcap包,经过流量切分和流量清理后得到的数据流个数为417 383,各类型数据流数目如表1所示,恶意流量和正常流量中数据流个数比例约为3∶4.
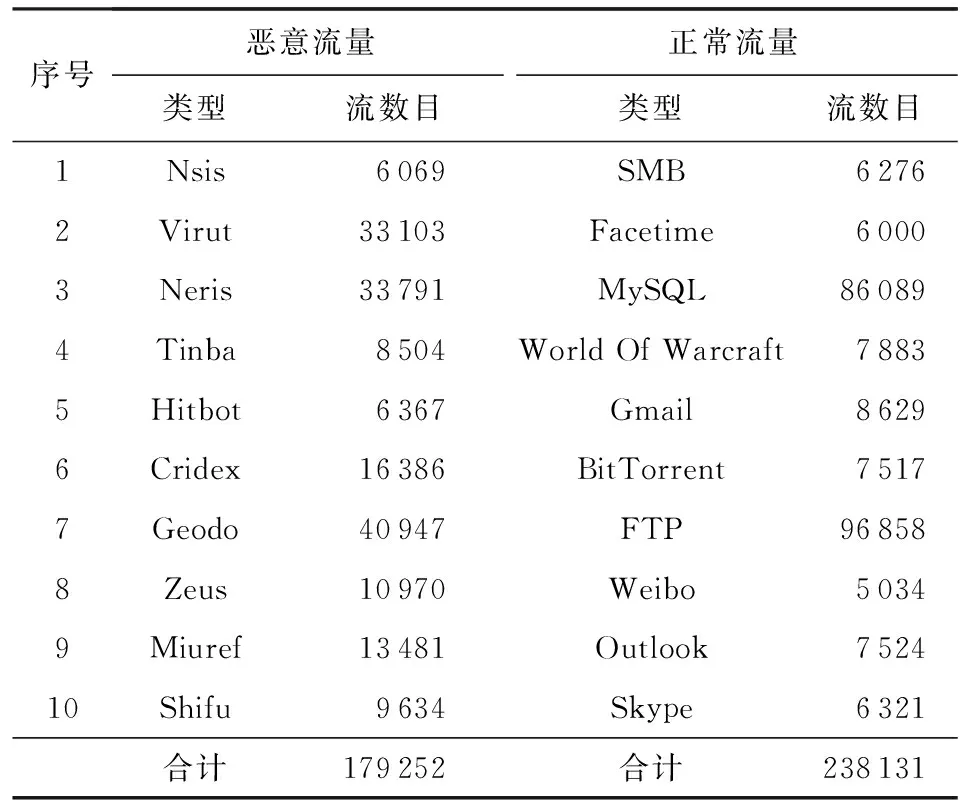
Table 1 Number of Different Data Flows in USTC-TFC 2016表1 USTC-TFC 2016中各类型数据流数目
3.2 对比模型及流量预处理
本文将对比半监督深度学习mean teacher模型(以下称MT)、虚拟对抗mean teacher模型(以下称VMT)、CNN模型[12]、HSTF模型[16]、机器学习模型(决策树(DT)、随机森林(RF)[10]、梯度下降决策树(GBDT)),下面详细描述各模型流量预处理过程.
1) mean teacher和CNN模型预处理
深度学习模型设计之初是为了识别和分类图像,要将其用于木马流量检测需要把木马流量表征为图像.图6是流量预处理流程,具体有6个步骤.

Fig. 6 Flow preprocessing图6 流量预处理流程
步骤1. 流量切分.按照一定的粒度将原始流量切分为多个离散单元,切分规则是按照会话或流的方式对数据进行切分,输入和输出数据的格式都是pcap.同一个pcap文件存储同一会话(源ip、源端口、目的ip、目的端口、传输协议等)的所有内容.
步骤2. 流量清理.删除步骤1中应用层信息为空的会话,消除冗余会话(完全相同的会话保留一份).
步骤3. 统一长度.深度学习模型的输入向量需要统一长度,本文选择统一为784个字节.小于784个字节的输入在后面补充0x00直到784个字节,大于784个字节则截取前784个字节 .选取前784个字节主要考虑3方面因素:1)木马流量检测选取的特征一般来自连接建立阶段,更能体现流量的行为特点,而后续数据传输阶段因长度过长难以反映类型特征[12].2)90%选取原则.实验发现USTC-TFC 2016数据集经过前2步骤处理后,90%的流量会话都小于784个字节,仅有少部分会话超过784个字节,考虑到数据实时处理需求和检测效果的平衡,选取长度应大于80%~90%的会话大小.3)借鉴了经典图像识别网络lenet-5的输入向量大小(28×28),由于该网络结构存在2个2×2大小的池化层,需要保证输入向量可以被4整除为7×7的大小.
步骤4. 打上标签.按照前面3个步骤将数据集切分得到样本集,后续实验为满足半监督训练的要求,按比例对样本打标签,实验1中分别标注为10%,5%,1%,0.1%,实验2为100%标注,实验3为10%标注.
步骤5. 数据选择.3.4节实验2需要从10种木马流量中选出一种作为未知木马,其他实验无需该步骤.
步骤6. mat文件生成.将图像转换为MAT格式的文件输入模型,主要作用是将大量样本压缩存储,并输入到深度学习模型中训练.
2) 机器学习模型预处理
对比的机器学习模型包括DT,RF和GBDT,这些模型需要从数据集中提取特征进行训练,预处理流程有3步:
① 同mean teacher和CNN模型预处理的步骤1和步骤2.
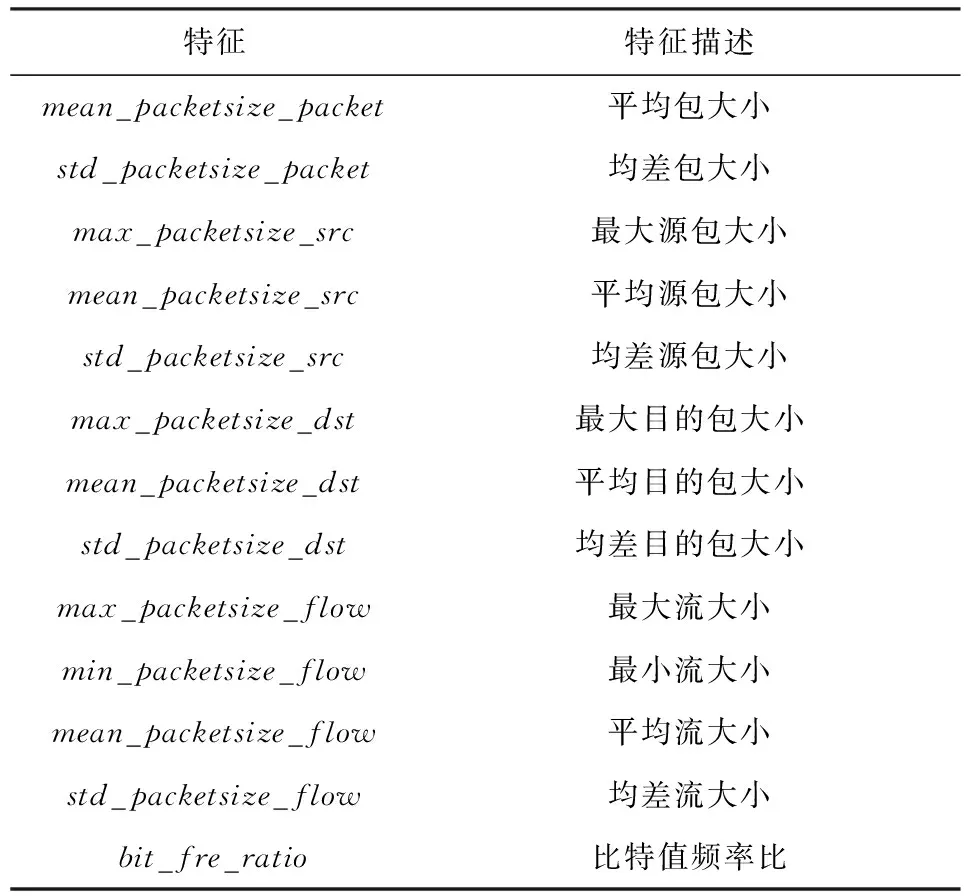
② 提取包含数据包总数、流持续时间在内的35维流级特征[9-10, 22],如表2所示:

Table 2 Flow Level Features表2 流级特征表
续表2
③ 将其存储为csv格式的文件.
3) HSTF模型预处理
HSTF模型[16]采用了CNN和LSTM深度学习融合模型,输入数据包括原始图像数据、包级特征和流级特征.各类输入数据预处理流程有3步:
① 原始图像数据.同mean teacher和CNN模型预处理的步骤1~3,将其存储为npy格式文件.
② 包级特征.首先,同mean teacher和CNN模型预处理的步骤1和步骤2;其次,为了统一输入到LSTM模型中的向量长度,根据原始图像数据特征提取时提出的90%选取原则(统一为784字节),对应地选择同一流中的前6个数据包进行包级特征提取,不足6个数据包的特征全部置0,提取的12维包级特征如表3所示,将其存储为npy格式的文件.
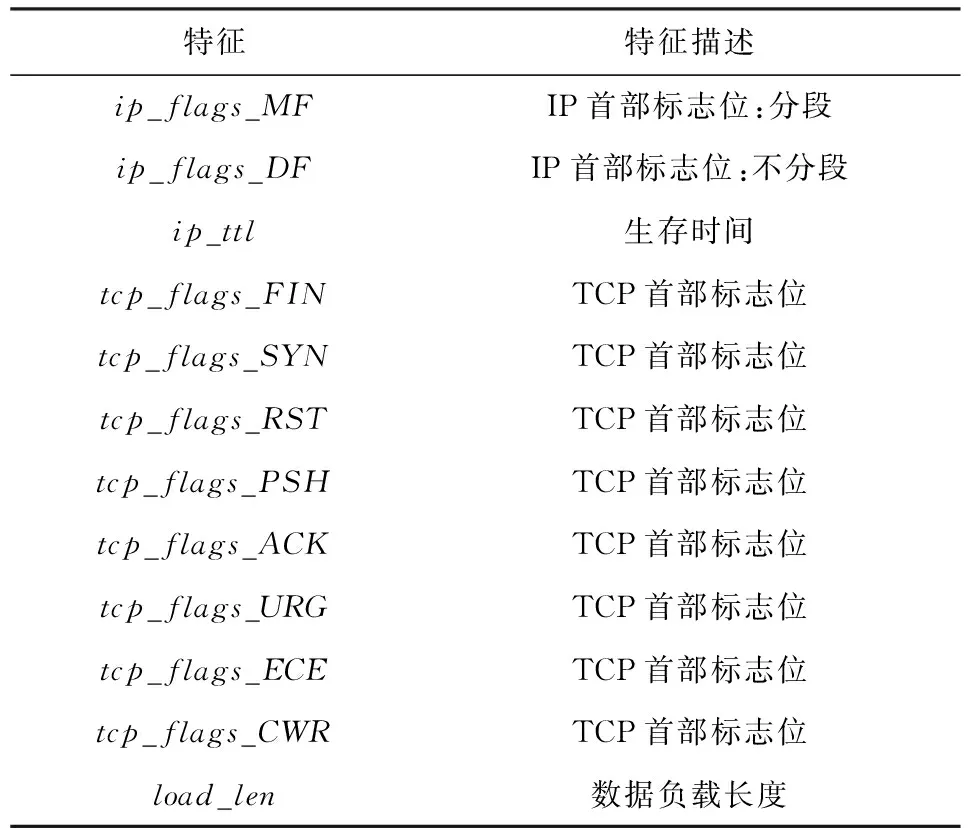
Table 3 Package Level Features表3 包级特征表
③ 流级特征.同机器学习模型预处理流程,特征如表2所示.
3.3 评价指标
实验使用的评价指标包括:
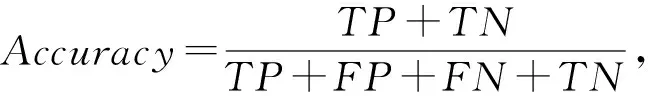
(14)
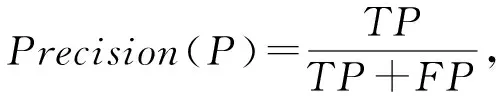
(15)
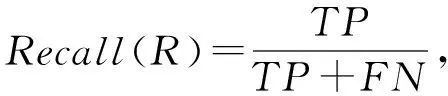
(16)
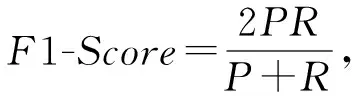
(17)
其中,准确率Accuracy是被分类器正确分类的样本所占的百分比,反映分类器对各类样本的正确识别情况;精确率Precision是标记为正类的样本实际为正类所占百分比;召回率Recall是正样本(木马样本)标记为正的百分比.TP表示正确分类的正类样本数,TN表示正确分类的其他类样本数,FP表示错误分类的正类样本数,FN表示错误分类的其他类样本数.
3.4 对比实验
本节设计了3组实验来验证RF,DT,GBDT,HSTF,CNN,MT,VMT这7种模型的对比效果,包括少标记样本下的二分类实验(实验1)、未知样本检测的实验(实验2)和少标记样本下的多分类实验(实验3).
实验1.7种模型在少标记样本下(10%,5%,1%,0.1%标记样本)的二分类(木马流量、正常流量)效果对比.其中MT和VMT模型的神经网络结构与CNN模型一致,网络参数一致,实验结果如图7所示.
实验2.7种模型对未知样本检测能力的对比,即从10类样本中选取9类作为训练集,另一类作为测试集,重复10次,参与训练的样本全部是标记样本,测试模型对未知木马流量的检测能力.该实验的目的是验证所提半监督深度学习模型(MT和VMT)在检测未知样本下分类效果是否比有监督学习好,解决有监督学习模型对于未知样本检测能力不足的问题,实验结果如图8所示.

Fig. 7 Binary classification results under different proportions of labeled samples图7 不同标记样本占比下的二分类结果图
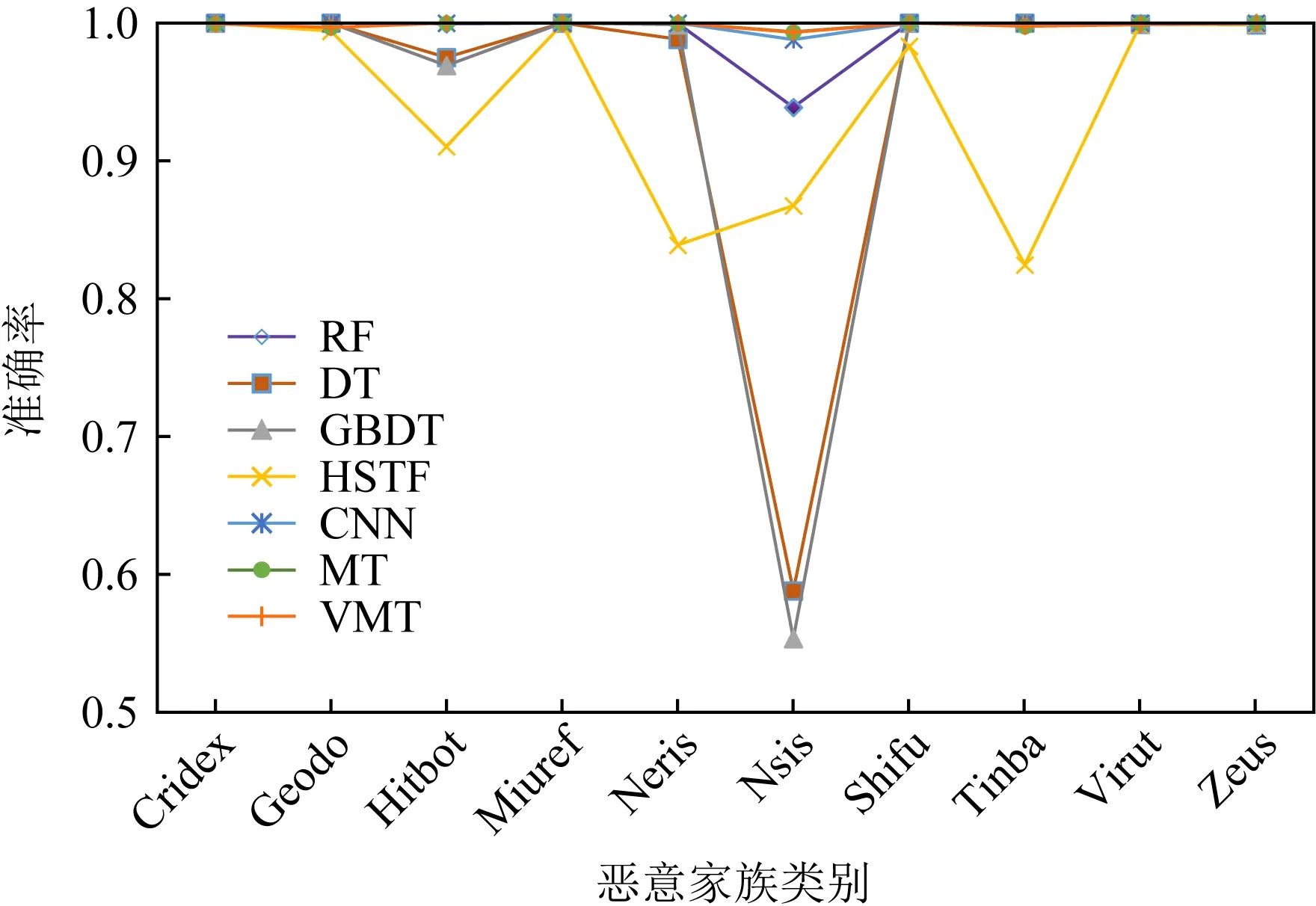
Fig. 8 Classification accuracy rate of unknown samples图8 未知样本的分类准确率对比图
实验3.7种模型在少标记样本下的多分类效果对比,验证不同模型在少标记样本下对不同种类或家族木马流量的识别能力.分别设置10类木马流量以及包含所有类的全集木马流量(All,将每类样本的准确率按照样本量加权平均获得),标记样本占比为10%.多分类任务本身比二分类任务更难,尤其是在少标记样本下,更能反映模型的分类检测能力.除了模型输出的分类数不同,本实验深度学习模型的网络结构和参数与实验1的一致,实验结果如图9所示.
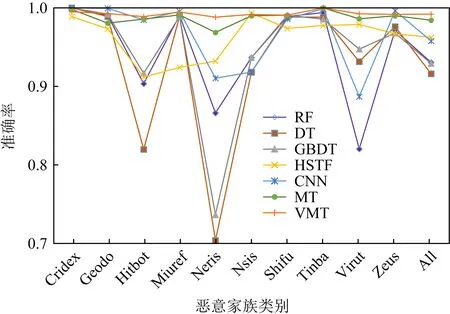
Fig. 9 Comparison of accuracy rate for multi-class classification with few labeled samples图9 少标记样本多分类准确率对比图
3.5 结果分析
由图7可知,在10%标记样本下,半监督和有监督学习除CNN外,各指标都达到0.99以上的水平,说明该数据集二分类难度并不大,靠10%的标记数据集,大部分模型可以准确识别恶意流量.随着标记样本量的减少和未标记样本占比的上升,半监督深度学习模型逐渐显示出更好的分类效果.当标记样本占比下降到1%时,除HSTF模型依然保持0.99的水平外其他模型指标都有下降,但半监督深度学习模型整体效果要优于其他有监督模型.当标记样本占比下降到0.1%时,有监督模型指标出现明显下降(F1降到0.8至0.9区间),而半监督深度学习模型依然保持在0.95以上.该实验说明:1)HSTF模型采用了丰富的特征集,使其在1%标记样本下仍有较好的二分类效果;2)标记样本占比逐渐减少对半监督深度学习模型造成的影响相对较小,尤其是标记样本占比下降到0.1%时,半监督深度学习模型(MT和VMT)优势更加明显.
由图8可知,半监督深度学习和有监督学习模型都具有一定的未知样本识别能力.半监督深度学习(MT和VMT)模型在10类未知样本识别准确率上达到0.99,HSTF和RF模型在9类未知样本(除Nsis)识别准确率上达到0.99,GBDT模型在8类未知样本(除Nsis,Hitbot)识别准确率上达到0.99,DT模型在7类未知样本(除Nsis,Hitbot,Neris)识别准确率上达到0.99,CNN模型在6类未知样本(除Nsis,Hitbot,Neris,Tinba)识别准确率上达到0.99.总体上看,半监督深度学习模型有较好的未知样本识别能力.
由图9可知,在标记样本占比为10%的条件下,半监督和有监督学习的多分类指标相比二分类稍有下降,表明多分类任务要比二分类任务更难.图9中,半监督深度学习模型对所有10个类别识别准确率均在0.96以上,其中VMT模型准确率在0.98以上,优于MT模型.HSTF模型对7个类别(除Neris,Nsis,Virut)识别准确率在0.96以上,CNN模型对7个类别(除Hitbot,Miuref,Neris)识别准确率在0.96以上,RF,GBDT,DT模型对6个类别(除Hitbot,Neris,Nsis,Virut)识别准确率在0.96以上.该实验说明:1)半监督深度学习模型在多分类任务上的识别准确率明显优于有监督学习模型;2)在多分类检测任务中,VMT模型比MT模型表现出更强的泛化性.
此外,综合图7和图9可知,在标记样本占比继续减少,尤其是标记样本占比降低到0.1%时,半监督深度学习模型在多分类任务中识别准确率的优势将更加明显.
3.6 时间复杂度分析
除了检测性能外,本文还考虑模型的时间复杂度,包括流量预处理时间、模型训练时间和模型检测时间.实验中各模型的检测时间都很短暂,差别非常小,主要耗时是在流量预处理和模型训练阶段.
1) 流量预处理时间
流量预处理流程见3.2节,下面分别介绍各模型的预处理时间.
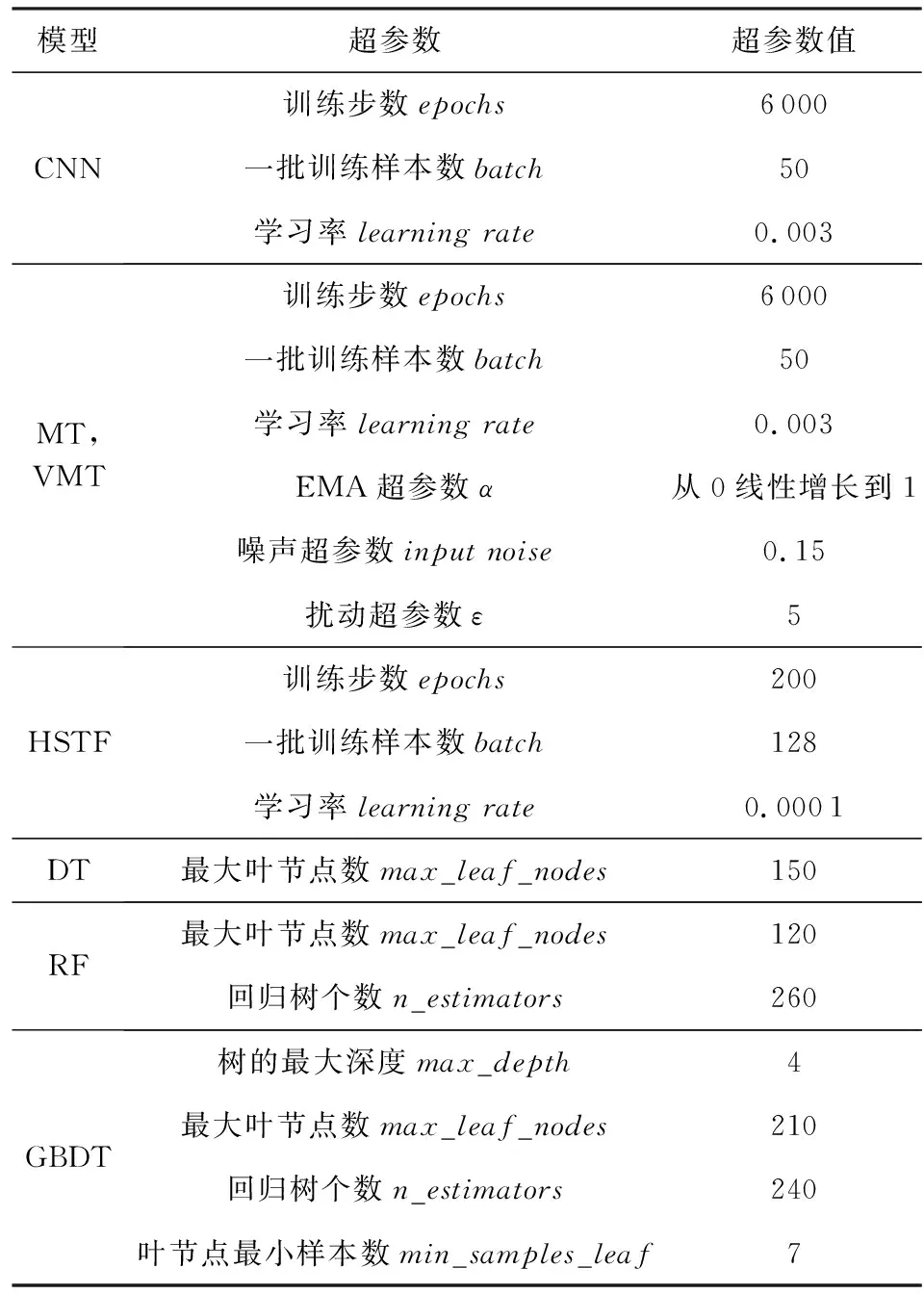
① CNN,MT和VMT模型.3个模型预处理流程相同,对于输入的原始流量,流量切分和统一长度可在一次流量遍历中完成,完整的遍历时间为Tf,而处理过程中大于784字节的会话流量不再处理,因此实际遍历时间Ts TCNN=TMT=TVMT=Ts+Tc. (18) ② DT,RF和GBDT模型.3个模型预处理流程相同,对于输入的原始流量F,为了提取表2的流级特征,需要完整遍历一次流量,时间为Tf,因此DT,RF和GBDT的预处理时间为 TDT=TRF=TGBDT=Tf+Tc. (19) ③ HSTF模型.该模型预处理流程包含图像特征、流级特征和包级特征,图像特征与CNN相同,流级特征与DT相同,包级特征提取需要遍历前6个数据包,时间为Tp,因此HSTF的预处理时间为 THSTF=Tf+Ts+Tp+Tc. (20) 由式(18)~(20)可知,对于同样大小的输入流量,各模型的预处理时间复杂度大小关系为 TCNN=TMT=TVMT 可见,MT和VMT模型在流量预处理阶段的速度要比传统机器学习模型DT,RF和GBDT快,而HSTF模型因其复杂的特征提取过程导致其预处理速度最慢. 2) 模型训练时间复杂度 ① CNN模型.该模型时间复杂度来自卷积层(convolution layer, CL)和全连接层(fully connected layer, FCL)的计算,卷积层的计算时间TCL取决于输入样本量和卷积核大小: (21) 其中,DCL为卷积层的层数,l为本层,M为特征图的大小,K为卷积核大小,Cl-1为上层输入的大小,Cl为本层输出的大小.对于全连接层,层间的神经元互相连接,是每层神经元状态维数的乘积,全连接层的计算时间TFCL为 (22) 其中,DFCL为全连接层的层数,l为本层,Sl为本层的神经元数量.因此CNN的复杂度TCNN=TCL+TFCL. ② MT和VMT模型.2个模型中的学生网络和教师网络在训练中为滑动平均关系,实际进行卷积计算的为学生网络,而损失函数只定义了参数的更新方向,使用的都为梯度下降,所以MT和VMT的时间复杂度相同,比CNN多计算了一次梯度下降(时间复杂度记为g),MT和VMT的时间复杂度为TMT=TVMT=TCL+TFCL+g. ③ HSTF模型.该模型除了卷积层和全连接层外,还需要LSTM层的计算.LSTM时间主要由输入序列的长度决定,其复杂度为TLSTM~O(N×CLSTM×L),其中N是样本量大小,CLSTM是单元状态维数,L是序列长度.因此,HSTF模型的时间复杂度为THSTF=TCL+TFCL+TLSTM. ④ DT,RF和GBDT模型.DT的训练时间复杂度是O(N×M×D),其中N是训练样本量,M是特征数量,D是树的深度;RF的训练时间复杂度是O(N×m×D×d),其中m是每轮采样特征数量,d是产生子树的个数;GBDT的训练时间复杂度是O(N×M×D×d). 各模型的训练时间复杂度大小关系为TDT 综上所述,在各模型检测时间差距很小的情况下,影响各模型检测实时性的主要因素为流量预处理时间.本文所提半监督深度学习模型的流量预处理速度最快,因此本文所提模型(MT和VMT)可采用离线训练、在线检测的方式,实现木马流量检测. 实验中各模型用到的超参数如表4所示.下面介绍网络结构和超参数选择依据. 1) CNN[12],MT,VMT的网络结构和超参数设置 本文所提MT和VMT模型是对基于CNN模型的木马流量检测方法的改进,从而提出基于半监督深度学习的检测方法.所以,模型中教师网络、学生网络的结构与文献[12]使用的CNN网络结构一致,都采用手写网络lenet-5的结构.同时,训练步数、一批训练样本数、学习率3个参数也相同.另外3个参数EMA超参数、噪声超参数、扰动超参数分别参考mean teacher模型[19]和虚拟对抗训练[21]原始论文. 2) RF等机器学习模型的超参数设置 对这类模型的超参数设置,Python sklearn中常用的有GridSearchCV和RandomizedSearchCV两种策略.其中GridSearchCV是依次尝试每一组超参数,然后选取分类结果最好的一组,费时且面临维度灾难问题.本文采用RandomizedSearchCV搜索策略,步骤为:对于搜索范围是distribution的超参数,根据给定的distribution随机采样;对于搜索范围是list的超参数,在给定list中等概率采样.本文预设按照distribution随机采样,对采样所得参数组进行遍历后,选取分类结果最好的一组作为最终超参数. 3) HSTF模型[16]的网络结构和超参数设置 本文在复现HSTF模型时,基本按照原论文中的网络结构和超参数设置方法,但部分超参数原论文没有给出,只能按照经验以及重复多次选择效果最好的超参数.因此,卷积层神经元数目设置为32,卷积核大小为3×3,步长为2,最大池层池化窗口大小为2×2,步长为1,LSTM层神经元数目为16,在LSTM层后增加丢失概率为0.3的Dropout层避免模型过拟合.模型训练过程中,使用learningrate=0.000 1的Adam优化器作为学习率优化算法,根据损失函数的收敛程度确定模型epochs=200,batch=128. Table 4 Model Hyper-parameters表4 模型超参数表 本文主要开展了3方面工作: 1) 将半监督深度学习模型mean teacher引入木马流量检测领域,充分利用未标记数据提高模型检测性能.在USTC-TFC 2016数据集中,模型仅需要10%的标记数据就能在二分类、多分类以及未知样本分类任务中达到0.98的准确率.同时,随着标记样本数量的减少,半监督深度学习模型检测性能的下降程度明显小于有监督模型. 2) 将虚拟对抗训练与mean teacher模型相结合,提出虚拟对抗mean teacher模型,用虚拟对抗训练获得的对抗噪声代替mean teacher模型中的随机噪声,提高模型泛化能力,达到识别未知样本的目的. 3) 在各模型检测时间差距很小的情况下,影响各模型检测实时性的主要因素为流量预处理时间,本文所提模型可采用离线训练、在线测试的方式,实现木马流量检测. 本文所提模型在少标记样本下有助于提升木马流量检测性能,但仍然存在2方面不足: 1) 虽然与RF,GBDT等传统机器学习和改进的深度学习模型HSTF相比,本文所提半监督深度学习模型预处理时间更短,但是为了满足实时性检测的需求,模型预处理速度仍需进一步提高,对于实时网络流量检测需要大数据平台的支持. 2) 本文所提模型为半监督深度学习模型,为了保证模型的准确率,仍然需要一定数量和类别的标记样本. 作者贡献声明:谷勇浩和黄博琪负责创新方法的提出和论文的撰写;王继刚负责论文的润色和修改;田甜负责相关工作的调研;黄博琪、刘焱和吴月升负责模型的实验和对比.3.7 模型网络结构和超参数选择
4 总 结
