知识引导的跨语言义原预测*
2022-06-09刘高军刘思睿鲁朝阳王昊
刘高军刘思睿鲁朝阳王昊
1.北方工业大学信息学院;2.CNONIX国家标准应用与推广实验室
语言学家认为,义原是人类语言的最小语义表示单位,词语的任何含义都可以通过义原间组合表达。目前,义原资源已应用于多种自然语言处理的下游任务中并取得不错的效果。现有义原资源主要以中文词语为主,同时少部分英文词语也有义原标注,但在其他语言中尚未普及。目前,已有部分研究者提出了自动化的跨语言义原预测方法,一定程度上实现为其他语言的目标词汇自动标注义原的能力。但现有的研究方案多是从词语的语义层次角度开展,忽略了外部知识信息的作用。为此,提出了一种全新的基于知识引导的跨语言义原预测方法,利用知识图谱的外部关系信息辅助对齐和预测过程,提升了跨语言义原预测的性能。最后,设计对比实验,证明了在这项任务中使用外部知识信息的有效性,且模型在性能上也优于现有模型。
众所周知,一个词语所处位置不同对应的含义也不相同,如何精确表达词语的含义是自然语言处理领域的工作基础。语言学家定义了最小的语义表示单位——义原[1],实现对词语含义的精准表达,并认为任何词语的含义都能够由一个有限封闭的义原集合来表示[2]。HowNet知网[3]是最著名的义原知识库,用层级结构描述了词语和义原的对应关系。其中,定义了2,000多个义原,并为10万多中英文的词语标注了义原信息。同时,义原已经成功应用在多种任务。
当前,知网只为中文和部分英语词汇标注了义原信息,其他语言没有对应义原标注也无法使用义原资源。跨语言义原预测任务旨在为目标语言(非中文)标注上源语言(中文)的义原信息。现有跨语言义原预测方案,多是先完成源语言和目标语言词义对齐,然后进行目标语言端的义原预测。相比于中文义原预测,跨语言的义原预测任务的主要难点在于构建是源语言词语的含义与目标语言含义的映射关系。文献[4]的研究就是利用双语词嵌入对齐的方法实现跨语言的义原预测。
为了进一步提升跨语言义原预测的精准度,本文使用同义词林扩展版构建义原外部知识图谱,从关系的角度利用知识信息引导跨语言义原预测,并提出了三种不同的对齐方式将知识信息作用在源语言和目标语言端增强义原预测的性能。同时,设置多组对照实验研究外部知识的作用,比较和测试知识的增强预测效果。
1 相关工作
1.1 知网HowNet
知网,HowNet是最著名的义原知识库[3],包含2,000多个义原和带有义原标注的100,000个中英文双语的词语,用层级结构自上到下描述了词、词义、义原的对应关系。其中,一个词对应多种词义,每个词义又由义原组合标识。
本篇文章中,同文献[4]一样构建的跨语言义原预测模型只关注词语和义原之间的对应关系,HowNet的层次结构不做体现,不同词语含义的不做区分,统一合成一个词语对应的所有义原,例如:“苹果”= {“样式值”“能”“携带”“特定牌子”“水果”}。
1.2 同义词词林
词林扩展版[5]简称词林是由不同研究领域的专家标注的同义词知识库,其中包含100,093个常用词语。在词林中的词汇通过上下位关系相连组织成层次结构共有5种不同的层次,每个层次又有对应不同的类别,层级由上到下层级越低词语的粒度越细致。
为了方便区分每一层次有对应的词义编码表示对应的位置。第一层至第三层按照词语类目分类,第四层只有对应的编码,最后一个层次按照词语的关系划分成组进行表示。最后一个层次刻画的最为细致,包含三种不同的关系“is_synonym”(相同含义的词)、“is_similar”(相近含义的词)、“is_independent”(不同含义的词,孤立),常用在信息检索、文本分类和自动问答等领域,本文采用最后一个层次的关系。
2 方法
在本部分,首先定义了跨语言义原预测任务,然后详细阐述构建同义词义原知识库的步骤,以及利用知识图谱中的关系信息实现跨语言义原预测方法,提出融入知识后全新的对齐方法,最后提出了组合模型。
2.1 任务定义
跨语言义原预测任务,即为一个目标语言词添加一组义原的过程,是一种多标签分类任务。形式化如下,定义WT为目标语言集合和ST、SS分别为目标语言和源语言的义原集合。其中,每一个目标语言词wT∈WT对应一组来自源语言的义原集合m代表义原集合的大小。目标语言词wT原预测公式描述如下,其中P(s|w)代表s为给定词w的义原的概率值。
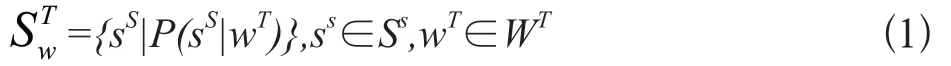
2.2 知识引导的跨语言义原预测
现有研究的跨语言义原预测主要分为两个步骤,词嵌入对齐和义原预测,前者实现源语言词义和目标语言词义对齐,后者完成核心的义原预测工作,本文提出的基于知识的义原预测旨在从关系角度预测义原。
2.2.1 实体嵌入训练
同义词具有相同的义原,近义词共享部分义原,为提取出同义词林和知网知识图谱中的信息,本文借用TransH翻译模型[6,7]的核心思想建模义原词林知识图谱,使用三元组(h,r,t)描述词与词和词与义原之间的关系,其中h为头实体h∈{Whownet∪Wciline},代表来自知网和词林的词语,r为关系r∈{Rhownet∪Rciline}表示词语间关系“is_synonym”(同义词关系)、“is_similar”(近似词关系)、“has_sememe”(义原关系),t为尾实体 t∈{Whownet∪Wciline∪Shownet}代表来自知网和词林的词语和知网中的义原。

为增强图谱中的实体节点的语义信息,同时引入了正则项表示词语包含的义原集合信息中的语义信息公式如下,其中re描述义原关系的向量,Sw表示一个词语w对应的义原集合。

最后综合上述两个函数同时考虑实体间关系和实体的语义信息,得到总的损失函数,如公式(4),其中λL为超参数控制两者权重。

在完成建模后,义原预测工作就是把义原作为尾实体,头实体为待预测义原的词语,词语和实体的关系。实体嵌入义原预测模型(Knowledge Based Sememe Prediction:KSP)预测分数则可以表示为:
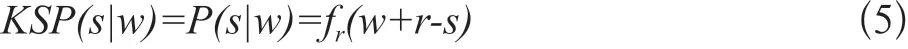
2.2.2 基于知识的义原预测方法CKSP-S
源语言和目标语言嵌入均使用预训练GloVe词向量。对齐部分选用与基线模型相同的对齐方式。预测时,计算相似度的源语言和目标语言的相似度,使用加权平均的方式将源语言知识嵌入KSP模型的信息融入到源语言义原预测的义原层次进行预测,模型如下:
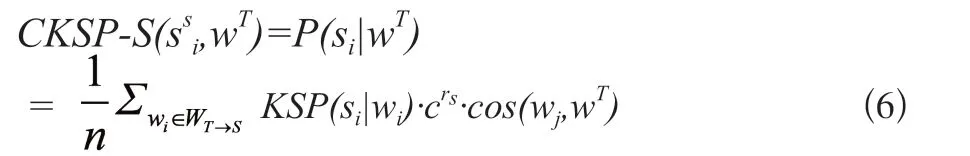
CKSP-S(si,wT)为目标语言词wT对给定义原si的条件概率,其中,WT→s为目标词语对应源语言相似词语的集合,n为集合大小,c∈(0,1)为超参数,rs为衰减系数按相似度顺序衰减。
2.2.3 基于知识的虚拟词节点预测方法CKSP-W
嵌入部分和对齐部分与CKSP-S方法一致。在预测部分,则通过计算相似度使用加权平均的方式在源语言部分构建一个虚拟知识图谱节点wvirtual,再利用KSP模型的知识信息预测目标语言词汇的义原,公式如下:

CKSP-W(ssi,wT)为目标语言词wT对给定义原si的条件概率,其中,WT→s为目标词语对应源语言相似词语的集合,n为集合大小fvir(wT)生成虚拟实体嵌入,c∈(0,1)为超参数,rs为衰减系数按相似度顺序衰减。
2.2.4 基于知识的双端增强预测方法CKSP-D
相较于前两种方法,CKSP-D源语言部分使用TransH学习的实体嵌入,目标语言使用预训练GloVe词向量。在对齐时,区别于双语词嵌入对齐,通过对齐源语言知识图谱内的实体嵌入和目标语言的预训练词嵌入来实现知识信息引入。文献[8]的思想实现嵌入对齐,其中,S和T分别代表实体嵌入和目标语言词嵌入矩阵,Si与Ti分别代表矩阵的第i行词语的词嵌入,W为线性变换矩阵,目标是通过线性变换SW得到最近似T,即SW=T公式如下:

为了更好使用义原和知识图谱中信息,对实体嵌入向量进行改造,融合更多义原信息,公式如下:

同时,为保持词向量在单语言上的特性,将W限制成正交阵,即WTW=I,进而得到W=VUT,TTS=UΣVT,为此可以使用SVD矩阵分解得到矩阵W。最后将源语言实体嵌入和目标语言预训练嵌入单位化和中心化目标函数为:
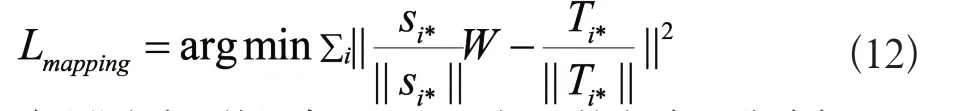
在预测时,使用与CKSP-S相同的方式,公式如下:

2.3 组合模型
相较于已有模型从语义角度提取信息预测义原,本文提出的模型从关系角度利用外部知识信息预测义原。两者从两个不同方实现了对目标语言词语的义原的预测,为了综合两个模型的不同方面,最后提出了模型组合的方式,组合方式如下:
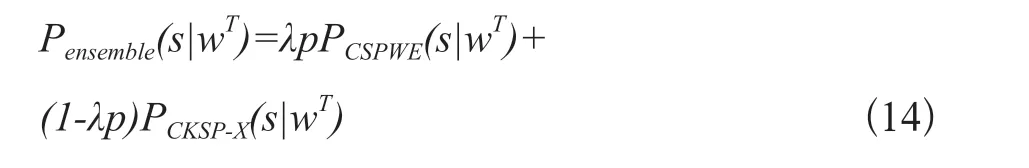
其中,Pensemble(s|wT)代表组合模型的预测分数,λp为超参数是组合权重,PCKSP-X为CKSP系列模型中的任意一种。
3 实验
本部分阐述了实验中所使用的数据集以及实验中的超参数设置,将知识引导的跨语言义原预测模型与现有基线模型作对比,比较模型的性能表现,同时设置不同的分析实验考察知识对跨语言义原预测的作用,最后挑选典型例子进行分析。
3.1 数据集
实验中以中文作为源语言,英文作为目标语言,并采用与文献[4]相同的数据集HowNet和词-义原知识图谱,具体细节如下:
HowNet数据集,包含103,843个中英文对照词汇并使用2,000多个义原进行标注,与基线模型[9]使用了相同的中文语料,保留66,794个词语和1,752个义原。
词-义原知识图谱,本文从HowNet和词林扩展版中抽取词语,添加同义、近似和义原关系并形成三元组映射关系。最终知识图谱中包含了65,630个词语、1,752个义原,包含了132,077组同义关系映射,173,038组近似关系映射,165,088组义原关系映射。
跨语言义原预测使用的单语言中英文词嵌入,分别使用Sogou-T和Wikipedia语料训练得到。种子词典与文献[9]基线模型相同使用6,752对中英文词汇。
3.2 实验设置
基线模型选用目前跨语言预测效果最好的模型CSPWE[4]。实验中,中英文词语、义原和关系向量的维度均采用800维,使用Adam优化器优化训练学习率设置为0.05,L1中超参数∈值设置为4,衰减系数c设置为0.8,组合模型的λ1∈[0.9,0.95]和λ2∈[0.05,0.1]随不同组合方式不断变化。
3.3 实验结果
实验中选取BiLex[9]传统方法和CSPWE[4]最优方法作为基线模型,与CKSP系列模型作对比。同时,和CSPWE组合形成组合模型,评估不同组合模型的效果,实验结果如表1所示:

表1 主试验结果Tab.1 Main test results
(1)首先,考察单一模型预测效果,可以看到引入外部知识的CKSP系列模型显著提升了预测性能。在系列模型中,CKSP-W模型的表现最好,优于经典对齐模型BiLex,说明了知识信息引入对跨语言义原预测任务的有效性。然而,与最优模型CSPWE相比CKSP系列模型的性能较差,CKSP系列模型仅从知识图谱中获取同义、同类关系信息语义信息相对薄弱,而CSPWE模型从大规模语料库预训练的词向量中获取带有丰富上下文背景的语义信息预测相对较好。
(2)从组合模型实验结果看,所有组合模型均优于CSPWE基线模型,说明CKSP系列模型引入知识图谱中的关系信息是对基线模型的有效补充。其中,CKSP-D直接在源语言和目标语言两端进行对齐,对基线模型性能的改善最为显著。而CKSP-S模型和CKSP-W模型只运行在源语言中,与目标语言的关系较小知识引导效果不明显,因此提升效果一般。
3.4 消融实验结果
3.4.1 词性分析
词性不同对应上下文信息和词义数目也不同,跨语言义原预测的精度也不一样,为此,本实验分析了词性对跨语言义原预测的影响。在知识图谱中,关系被定义成三元组形式词性不同对应上下文信息和词义数目也不同,跨语言义原预测的精度也不一样,为此,本实验分析了词性对跨语言义原预测的影响。在知识图谱中,关系被定义成三元组形式(h eadword,tail(word∪sememe),relation),目标语言词语对应多个源语言词语,为了便于分析词性的影响定义了平均三元组的概念,公式如下:

其中,ws和wt是源语言和目标语言词语的词嵌入,Tri(ws)是源语言词语对应三元组数目。实验结果如表2所示:
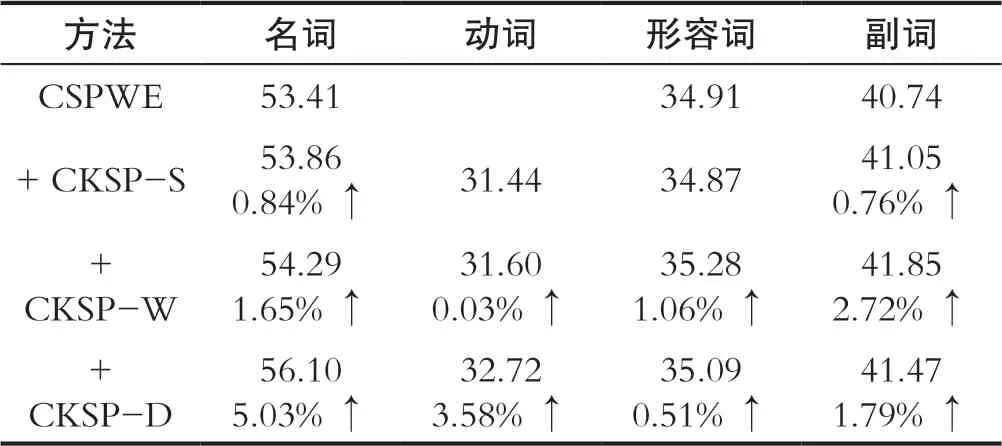
表2 词性消融实验结果Tab.2 Experimental results of part of speech ablation
如表2所示,与CSPWE相比除CKSP-S模型在动词和形容词精度下降外,其他实验组性能有明显提高。名词的性能提升效果最为明显,而动词的性能提升效果较差。原因是名词的三元组数量最多,而动词的三元组数量最少。这印证了从知识图中获得的信息越多,对改进预测效果越好。
3.4.2 平均词度分析
知识图谱中度表示词语中关系的数目,度越多关系越多提供给跨语言义原预测任务的信息越多,本实验分析词度大小对跨语言义原预测的影响。为了便于分析词性的影响定义了平均词度的概念,公式如下:

其中,ws和wt是源语言和目标语言词语的词嵌入,Deg(ws)是源语言词语对应词度的大小。如图1所示可以看出,随着目标语言单词词度的提高,CKSP系列组合模型的预测性能不断提高。结果表明,知识图中对应源语言词的关系越多,目标词的预测性能越好。

图1 平均词度实验结果Fig.1 Experimental results of average word size
4 结语
本文提出了一个外部知识引导的跨语言词汇语义预测模型,该模型旨在将语义信息和特征资源从语义层面扩展到关系角度,并利用有CilinE来改进已有的研究。使不同语言文化背景的研究者在研究中更容易地利用义原资源。实验部分,验证了引入外部关系知识的有效性,也同时表明该方法能显著提高现有跨语言模型的性能。在未来将尝试使用更多的外部知识,探索更多的方式导入知识,提供不同语言的各种义原资源,也将研究如何使用义原丰富外部知识。
…………
引用
[1] BLOOMFIELD L.A Set of Postulates for the Science of Language[J].Language,1926,2(3):153-154.
[2] CLIFF G,ANNA W.Semantic and Lexical Universals: Theory and Empirical Findings[M].Philadelphia:John Benjamins Publishing Company,1994.
[3] DONG Z D,DONG Q.HowNet-A Hybrid Language and Knowledge Resource[C]//International Conference on Natural Language Processing and Knowledge Engineering.Beijing China:IEEE,2003:820-824.
[4] QI F C,LIN Y K,SUN M S,et al.Cross-lingual Lexical Sememe Prediction[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,2018:358-368.
[5] CHE W X,LI Z G,LIU T.LTP:A Chinese Language Technology Platform[C]//COLING 2010:International Conference on Computational Linguistics,2010:13-16.
[6] LIN Y K,LIU Z Y,SUN M S,et al.Learning Entity and Relation Embeddings for Knowledge Graph Completion[C]//Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Austin Texas:AAAI Press,2015:2181-2187.
[7] WANG Z,ZHANG J W,FENG J L,et al.Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence. Québec Canada:AAAI Press,2014:1112-1119.
[8] ARTETXE M,LABAKA G,AGIRRE E.Learning Principled Bilingual Mappings of Word Embeddings while Preserving Monolingual Invariance[C]//Conference on Empirical Methods in Natural Language Processing.Austin Texas:Association for Computational Linguistics,2016:2289-2294.
[9] 张檬,刘洋,孙茂松.基于非平行语料的双语词典构建[J].中国科学:信息科学,2018,48(05):564-573.
