融合图嵌入的光滑主成分分析网络图像识别算法
2022-06-08陈飞玥朱玉莲田甲略
陈飞玥,朱玉莲,田甲略,蒋 珂
(1. 南京航空航天大学 计算机科学与技术学院, 江苏 南京 211106; 2. 南京航空航天大学 公共实验教学部, 江苏 南京 211106)
图像识别是计算机视觉的重要分支,在安全验证[1-2]、电子商业[3]、医学影像[4]、目标检测[5-6]等领域均有广泛的应用。通常,图像识别分为四个步骤,即图像采集、图像预处理、特征提取和分类。图像采集是指通过成像设备获取图像的过程;图像预处理是将图像信息转换为计算机可以操作的数字信息,并进行简单的编辑;特征提取是从图像中提取出利于样本类别判别分析的信息;而分类则是对提取的特征进行判断,以确定该样本所属的类别。所以,特征提取是图像识别的关键步骤之一。特征提取方法主要包括两类:基于手工设计的特征提取方法和基于学习(数据驱动)的特征提取方法。其中,基于人工设计的特征提取方法主要有尺度不变特征变换[7](scale-invariant feature transform, SIFT)、方向梯度直方图[8](histogram of oriented gradient, HOG)等;基于学习的特征提取包括基于子空间学习的特征提取(如主成分分析[9](principal components analysis, PCA)、线性判别分析[10](linear discriminant analysis, LDA)等)和基于深度学习的特征提取(如LeNet[11]、AlexNet[12]、VGG[13]等)。
以卷积神经网络[11](convolutional neural networks, CNN)为代表的基于深度学习的特征提取方法得到迅速发展,并在图像识别领域得到了广泛的应用。CNN通常由多层网络组成,而每一层网络又由卷积层、非线性处理层和池化层构成。其中,卷积层是CNN的核心,训练CNN的过程实际上就是学习各层卷积核参数的过程。为了学习卷积核,CNN一般使用反向传播(back propagation, BP)算法进行训练。BP算法是一个迭代算法,它包含数据的正向传播和梯度的反向传播。正向传播是根据已有参数从输入层开始依次计算每个隐含层直至输出层的过程;而反向传播则是利用梯度下降法从输出层到输入层依次更新参数的过程。两个过程交替进行,直至满足停止条件(如误差最小值)。由于CNN网络结构通常非常复杂,有大量的参数需要学习,所以一方面,需要有大量的训练样本进行训练以避免过拟合现象出现;另一方面,采用BP迭代求解参数的过程是非常耗时的。此外,复杂的网络结构通常需要一些额外的训练技巧才能获得良好的性能。
为了解决这些问题, Chan等提出了一种简化的深度网络——主成分分析网络PCANet[14]。PCANet由输入层、两层卷积层和输出层组成。由于PCANet的卷积核直接通过PCA方法获得,有效避免了CNN中调参的过程,因此不仅大大降低了计算代价而且也避免了过拟合问题。大量的实验证实PCANet在很多方面取得了接近于CNN的性能[14-16]。鉴于PCANet的成功,人们基于PCANet提出了一些新的算法,如Low等通过引入池化层实现了PCANet中两个卷积层之间的非线性映射进而提出了stacking PCANet+[16];Xi等使用局部二值模式(local binary patterns, LBP)描述符替换了CNN卷积核,从而提出了局部二值模式网络(LBPNet)[17];Ng等则利用二维离散余弦变换(two-dimensional discrete cosine transform, 2D-DCT)与PCA高度近似这一特点,使用2D-DCT基作为卷积核提出了二维离散余弦变换网络(DCTNet)[15]。
然而,PCANet算法也存在不足。由于在训练过程中将所有局部块[14]视为彼此独立的,该算法忽略了局部块的中心像素点之间隐含的位置关系。设pi、pj是输入图像中相邻的两个像素点,以pi、pj为中心的局部块分别为xi、xj。由于图像中相邻像素pi、pj之间通常具有很高的相似性,因此局部块xi、xj之间也应具有较高的相似性,但是PCANet在利用PCA获得卷积核时却忽略了这一重要信息,致使最终所学习的特征未能很好地保持其空间特性。通常,一个较好的空间变换应该能有效地保持原空间样本点之间的近邻关系及相似性。亦即,在原空间位置数据值相近的两个近邻样本点投影至目标空间后,仍然应满足位置相邻且数据值接近的空间特性。基于此,提出了各种图嵌入方法[18-21]。图嵌入方法一般首先根据原空间样本建立一个图G=(Q,E),其中Q是图节点的集合,每个图节点对应着每个样本;E是图节点之间带有权值的边的集合,而边的权值表示两个图节点之间的邻接关系。根据邻接关系求得一空间变化矩阵,使得图中的节点映射至目标空间后,样本间的位置关系与原空间尽可能一致。在图嵌入方法中,图节点既可以是整幅图像也可以是图像中的一个像素点。传统的流形学习方法如局部保持投影[18](locality preserving projections, LPP)、局部线性嵌入[19](locally linear embedding, LLE)等均以整幅图像为图节点。其中,LPP通过寻找样本点间拉普拉斯特征映射的最优线性逼近实现图嵌入的目标;LLE采用保持近邻样本点之间线性关系的思想保持样本点间的位置关系。而空间光滑的子空间学习方法[20](spatially smooth subspace learning, SSSL)则以一幅图像的像素点作为图节点。SSSL方法通过对子空间的基向量做光滑约束,使基向量中相邻位置元素值的变化趋于平缓进而获取图像的位置关系。在SSSL的基础上,通过变换约束函数提出了基于高斯拉普拉斯算子(Laplacian of Gaussian, LOG)和高斯导数(derivative of Gaussian, DOG)惩罚的空间光滑子空间学习[21]等方法。大量的实验结果证实,在特征提取过程中保持局部位置信息,有利于后续图像识别性能的提升。
为了充分利用图像的位置信息,本文将图嵌入的思想融入PCANet中,提出基于图嵌入的光滑PCANet(Smooth-PCANet)。在求解PCANet卷积核时,除了保证各个局部块在新空间的特征(向量化操作后)具有最大的协方差,同时还要保证新特征之间的光滑性,即相邻的局部块在新空间的特征应该具有相似的特征值。因此,相比于PCANet,Smooth-PCANet利用了更多的位置信息。为验证Smooth-PCANet的有效性,分别在人脸数据集(以AR和Extended Yale B数据集为例)、手写体文字数据集(以MNIST数据集为例)和图片数据集(以CIFAR 10数据集为例)上进行了实验。实验结果表明, Smooth-PCANet获得了比PCANet更好的性能;同时,和一些经典的神经网络算法相比,当训练样本数量相对较少时Smooth-PCANet表现更为出色。
1 融合图嵌入的Smooth-PCANet
1.1 PCANet
PCANet为简易的深度学习网络,由输入层、两个卷积层和输出层组成。对各层进行简要介绍。
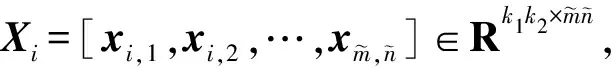

输出层:经过两层卷积层的操作后,每个输入图像Ii都能得到L1×L2个特征图像,随后在输出层进行非线性处理、分块直方图和特征拼接等一系列操作后,最终得到图像Ii的特征向量表示。由于本文算法只涉及卷积核的构建,并不涉及输出层的改进,因此关于输出层的操作此处不做详细介绍,具体操作参见文献[14]。
1.2 Smooth-PCANet
在PCANet 的基础上,通过引入像素点之间的近邻信息,本文提出了Smooth-PCANet。Smooth-PCANet和PCANet算法的流程对比如图1所示。从图1可以看出,相对于PCANet,Smooth-PCANet在计算卷积核时融入了拉普拉斯矩阵信息。下面,本文将从构建拉普拉斯矩阵及求解卷积核两方面对Smooth-PCANet进行详细介绍。

(a) PCANet
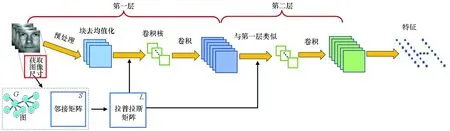
(b) Smooth-PCANet图1 PCANet和Smooth-PCANet算法的流程对比示意Fig.1 Flow charts comparison of PCANet and Smooth-PCANet
1.2.1 构建拉普拉斯矩阵
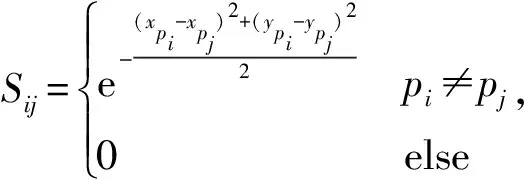
1.2.2 求卷积核
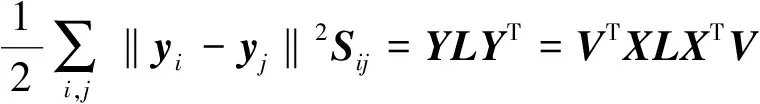
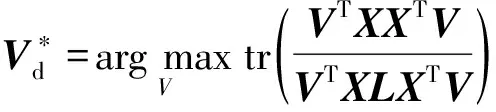
(1)
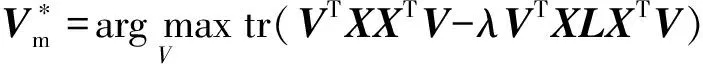
(2)
其中,I为L1阶单位矩阵,λ∈(0,1]为超参数。
因为式(1)~(2)是(广义)特征值问题,因此很容易得到闭解。在求解卷积核后,Smooth-PCANet采用和PCANet完全一样的操作进行特征提取。
2 实验结果与分析
2.1 人脸识别任务
在人脸识别任务中,本文使用AR数据集和Extended Yale B数据集进行了实验。在实验中,PCANet和Smooth-PCANet的基本参数设置如下:卷积核的大小和数目分别设置为k1=k2=5、L1=L2=8、直方图块重叠率为0.5,直方图块大小为8×8。
2.1.1 AR 数据集
AR人脸数据库由126个人(70个男性和56个女性),每人至少26幅共计4 000多幅正面图像组成。本文中采用AR的一个子集,包含100个人(50个男性、50个女性)每人26幅共2 600幅图像,并将图像分辨率调整为66×48。某个人的26幅人脸图像如图2所示。在图2中,时间1和时间2分别表示图片拍摄时间在第一周内和第二周内,下标1~13代表图像的序号。实验将时间1和时间2的人脸图像划分为6个数据子集,即s1:Illum & Exps(时间1的1~7)、s1:Sunglass(时间1的8~10)、s1:Scarf(时间1的11~13)s2:Illum & Exps(时间2的1~7)、s2:Sunglass(时间2的8~10)、s2:Scarf(时间2的11~13),使用s1:Illum & Exps学习网络并进行训练,其余子集作为测试集评估各算法的性能。

图2 AR数据库上某个人的样本Fig.2 Samples of one person from AR database
实验结果如表1所示。由表1数据可以看出:①从平均准确率上看,只有PCANet及Smooth-PCANet算法能达到90.00%以上的准确率,尤其是Smooth-PCANet(m)取得了最高结果91.53%,而传统神经网络的准确率均低于50%。这是因为实验中仅以700幅无明显噪声的人脸图像作为训练集,致使传统神经网络出现了不同程度的过拟合;而PCANet和本文提出的Smooth-PCANet均是浅层网络,有效避免了过拟合,因此性能更为稳定。②从各个子集的实验结果来看,含遮挡的人脸图像严重影响了传统神经网络的分类性能,例如LeNet在无遮挡的s2:Illum & Exps上准确率约为73.86%,但在s2:Scarf上准确率仅有约6.33%。值得注意的是,虽然PCANet及Smooth-PCANet在遮挡人脸图像上亦有性能下降,但是比起其他算法明显降幅最小,比如在s1: Scarf上,与s2:IIlum & Exps的识别结果相比,PCANet及Smooth-PCANet算法的性能降幅未超过6.86%,远低于LeNet在该子集上的性能降幅59.85%。③Smooth-PCANet(d)和Smooth-PCANet(m)针对不同类型的人脸图像遮挡噪声分别表现出了最佳性能。其中,Smooth-PCANet(d)在墨镜遮挡人脸的性能具有明显优势,Smooth-PCANet(m)则在围巾遮挡图像上表现更优。综上所述,Smooth-PCANet不仅提升了PCANet在含遮挡人脸识别的准确性和鲁棒性,还在小样本训练集上发挥出比PCANet更大的优势。
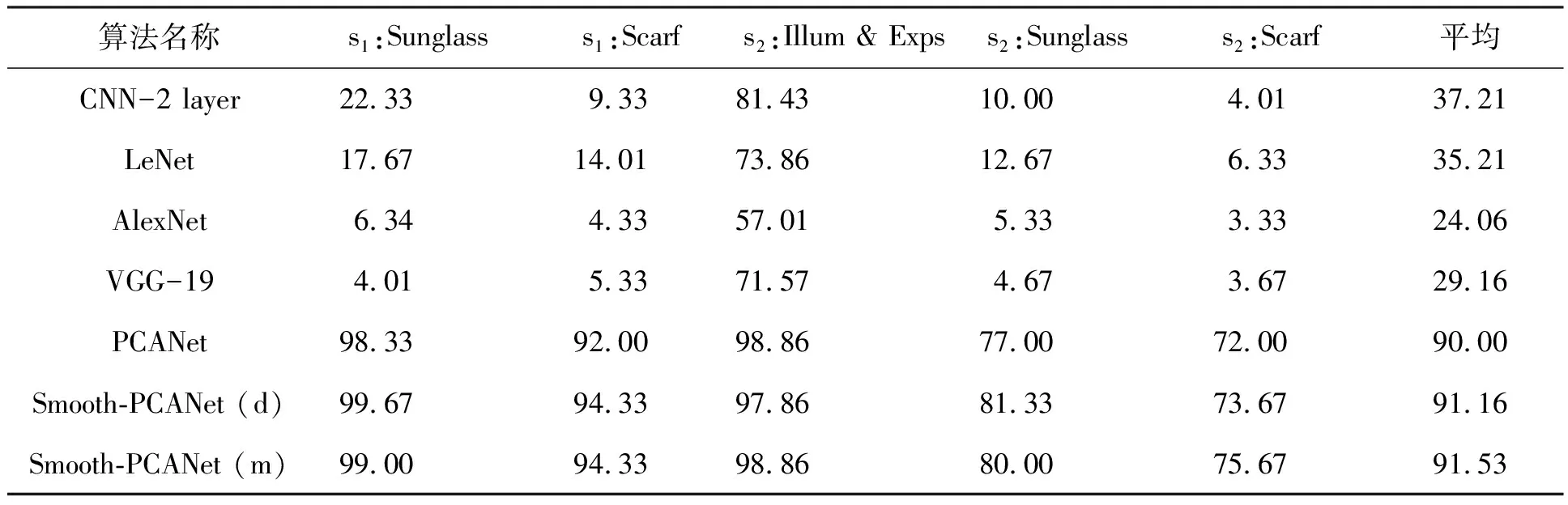
表1 AR数据集上各算法的性能
2.1.2 Extended Yale B数据集
图3 Extended Yale B数据集的各子集示例Fig.3 Overview of each subset of Extended Yale B datasets
Extended Yale B数据集包含38个个体的2 414幅人脸图像,每个个体拍摄约64幅不同光照下的照片[22]。实验采用了该数据库的一个子集,包含30个个体的1 920幅人脸图像,分辨率为96×84,并依照光照条件划分为5个子集(子集1~子集5)[23],使用子集1进行学习和训练,其余子集作为测试子集。某个个体的图像部分划分如图3所示。实验所得结果见图4。从图4中可以看出:①从子集2~子集5,所有算法都出现了性能降低,说明光照是影响图像识别性能的重要因素。②PCANet和Smooth-PCANet的性能在所有子集上都超越了传统神经网络,且在子集4和子集5上该优势尤为明显,例如在子集4上Smooth-PCANet(d)和Smooth-PCANet(m)准确率分别为68.57%和68.1%,而AlexNet仅有9.05%。这是因为小样本训练集时神经网络再次出现过拟合问题。③在子集5上,Smooth-PCANet(m)表现出更显著的光照鲁棒性,识别准确率比起第二名的Smooth-PCANet(d)亦至少高出1.9%。因此,Smooth-PCANet(m)更适用于光照条件极差的人脸识别场景。
2.2 手写体识别任务
本文使用MNIST数据集进行手写体识别。MNIST是数字0~9手写体图像库,共包含60 000幅训练图像和10 000幅测试图像[11,14, 24],图像分辨率为28×28。实验设置PCANet与Smooth-PCANet的参数如下:k1=k2=7、L1=L2=8。在实验中发现在不同网络上将60 000幅训练图像全部用于训练所得的结果几乎无差异,所以本文分别使用2 000和20 000幅训练样本做实验。实验结果如表2所示。从表2中可以看出:①训练样本为20 000幅时,所有的算法都达到了93%以上的准确率,VGG-19和LeNet达到了最高准确率98.72%;Smooth-PCANet(d)略低于前二者,结果为98.55%;PCANet和Smooth-PCANet(m)达到97.90%的准确率,与第一名差别不超过1%。当训练样本仅为2 000幅时,各算法出现了不同程度的性能降低,如AlexNet性能下降了约1.52%,VGG-19下降了5.52%,PCANet亦出现4.2%的降幅,仅有Smooth-PCANet(d)的性能具有最小降幅0.9%,并且获得最高准确率97.65%。②从整体上来说,在手写体字符识别任务中Smooth-PCANet比PCANet获得了更好的性能;同其他算法相比,Smooth-PCANet(d)在小样本训练时具有更出色的表现。
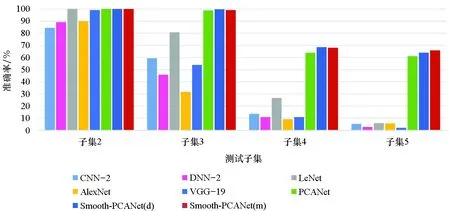
图4 在Extended Yale B所有子集上各算法识别准确率柱状图Fig.4 Histogram of recognition accuracy of each algorithm on all subsets of Extended Yale B
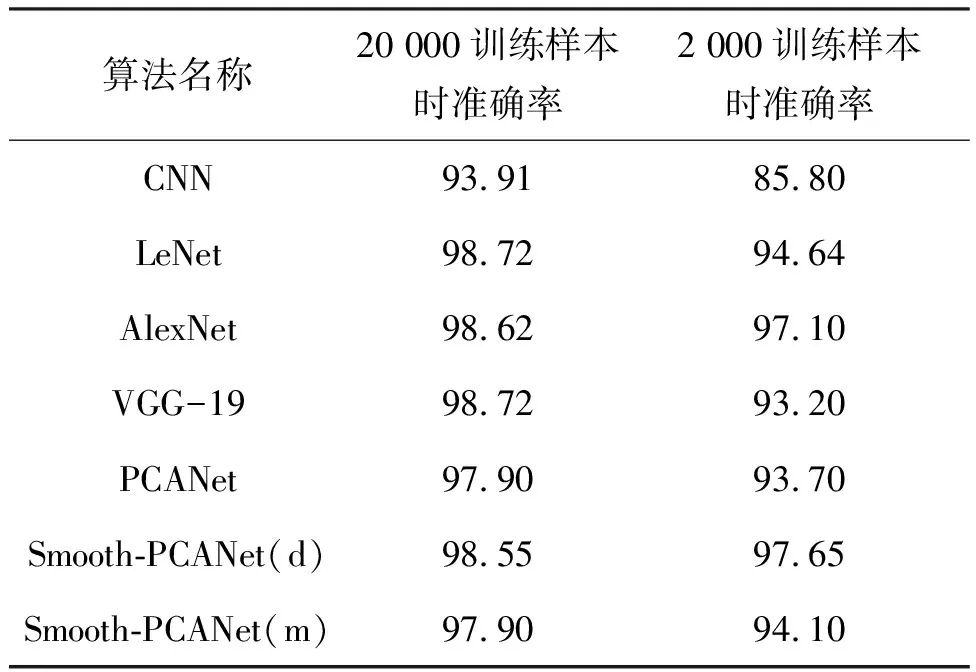
表2 各算法在不同训练样本规模的MNIST数据集上的性能Tab.2 Performance of each algorithm on MNIST datasets with different training sample sizes %
2.3 图片识别任务
本文在CIFAR 10数据集进行了图片识别实验。CIFAR 10数据集由10个类共60 000幅彩色RGB图像组成,图像分辨率为32×32。在实验中,将这彩色图像转为灰度图,以50 000幅图像为训练集、10 000幅图像为测试集进行实验。实验中PCANet以及Smooth-PCANet(d)、Smooth-PCANet(m)的参数统一设置为k1=k2=5、L1=20,L2=8。所得结果如图5所示。从图5中可以看出,在CIFAR 10数据集上所有的算法都无法达到较高的准确率,这是因为经过灰度处理后图像的特征变得更难分辨与提取。故在图片集上提出的Smooth-PCANet与一般的神经网络相比并未展现出结果优势。值得关注的是,PCANet和本文算法的实验结果与LeNet十分接近,但是LeNet是较深层的神经网络,除去输入输出层还包含了3个卷积层、2个下采样层和1个全连接层。其他的神经网络层数更高。所以实验中传统的神经网络算法花费了远多于PCANet及Smooth-PCA的时间和硬件资源。如文献[25]所指出的,在一定范围内深度学习网络的隐含层越多,其分类性能越好。基于PCANet和Smooth-PCANet在实验中以最浅的网络层数达到图中所示性能水平的这一事实,本文认为,若对Smooth-PCANet进行合理的层数扩充,其有望在图片识别任务上表现出更好的性能,且在资源使用上仍具有较大优势。

图5 在CIFAR 10上各算法的识别准确率Fig.5 Recognition accuracy of each algorithm on CIFAR 10
3 结论
目前大多数深度学习存在着网络复杂训练难度大、硬件条件要求高、训练样本少时容易陷入过拟合等问题。本文在一种简易的深度学习网络PCANet上,通过融合图嵌入的光滑思想,提出了Smooth-PCANet图像识别算法,并分别在不同数据集上与其他方法进行对比实验。实验结果表明,Smooth-PCANet实现了对PCANet的有效改进,对光照、遮挡等人脸图像噪声的鲁棒性更强,对手写字符的识别性能也更高;同PCANet一样,Smooth-PCANet在小样本训练集上可以有效避免过拟合,与传统神经网络相比更有优势。
