COVIDSeg:新冠肺炎肺部CT图像轻量化分割模型
2022-06-07谢娟英
谢娟英,夏 琴
(陕西师范大学 计算机科学学院, 陕西 西安 710119)
2019年12月新型冠状病毒肺炎(corona virus disease 2019,COVID-19)疫情暴发,感染人数迅速增长[1]。截至2021年9月,全球累计确诊新冠肺炎人数达2.2亿,其中死亡人数达458万,确诊和死亡人数呈现持续快速增长趋势[2-3]。依据《新型冠状病毒肺炎诊疗方案(试行第七版)》[4],肺部影像的诊断结果可作为新冠肺炎患者的评判标准,新冠肺炎患者肺部影像早期呈现多发小斑片影及间质改变,进而发展为双肺多发浸润影、磨玻璃影,严重的患者出现胸腔积液少见、肺实变等。放射科医生通过查看肺部影像,结合临床信息,发现异常之处,从而诊断出新冠肺炎患者。
作为一种常见的医学放射成像方式,计算机断层扫描(computed tomography,CT)是医生诊断肺炎的重要手段[5]。医生通过查看肺部CT图像,判断是否存在新冠肺炎患者特征,包括毛玻璃影结节、肺纤维化、胸腔积液以及多发性病变等[6-8],从而做出诊断。然而,诊断结果常常取决于放射科医师经验,人为因素影响很大,诊断困难且耗时。因此,利用计算机辅助医生对肺部CT图像病变区域进行诊断,定量评估治疗前后效果,不仅能提高医生的医学影像判读效率,而且能加强医生的临床诊疗能力,提高患者治愈率、减少病人等待时间。随着深度学习技术的蓬勃发展,出现了基于深度学习的安全、准确、高效的计算机辅助诊断手段[9-12],在医学图像分析领域取得显著效果。
医学图像分割是依据频域、灰度、纹理等特征对2D或3D图像进行分割。在全球新冠肺炎疫情暴发后,许多研究者开展了基于深度学习的新冠肺炎CT图像分割研究。Rajamani等提出DDANet模型,运用动态可变形交叉注意力机制,在新冠肺炎CT图像数据集COVID-SemiSeg的Dice指标达到79.1%[13]。Budak等在SegNet模型基础上使用注意门控机制自动分割新冠肺炎CT图像的病变区域,在473张新冠肺炎CT图像数据集的Dice指标达到89.61%[14-15]。Kumar等提出LungINFseg模型[16],该模型使用接受域感知(receptive-field-aware,RFA)模块,在不丢失任何信息的情况下扩大分割模型的接受域,提高模型学习能力,在新冠肺炎CT图像数据集COVID19Seg的Dice指标达到80.34%。Fan等提出用于新冠肺炎肺部感染分割的Inf-Net模型[17],并行部分解码器来聚合高层特征,用隐性反向注意力和显性边缘注意力针对病灶边界进行建模,提出了一种基于随机选择传播策略的半监督分割框架,在新冠肺炎CT图像数据集COVID-SemiSeg的Dice指标达到73.9%。使用深度学习方法可以自动精确地对新冠肺炎CT图像分割病变区域,为医生诊断提供辅助意见,提高诊断效率。
深度学习模型不仅需要大量训练样本,且往往比较费时,为此本文提出轻量化的新冠肺炎肺部CT图像分割模型COVIDSeg。首先,提出轻量化的压缩-扩展通道注意力模块SECA(squeeze and extend channel attention block),降低模型参数,提高计算效率,通过跳层连接缓解模型退化问题,加入通道注意力子模块增强特征表达能力;其次,提出残差多尺度注意力模块RMSCA(residual multi-scale channel attention block),通过多分支结构捕获多尺度信息,增大模型感受野;同时,将SECA模块和RMSCA模块作为编码器子网络的主要组成模块,通过双通路结构连接各模块,通路内特征逐层传递,通路间多级特征交互,促进不同层级有效信息的传递和表达。
1 相关工作
1.1 深度图像分割
图像分割是计算机视觉领域的重点研究方向,深度学习技术使得图像分割研究得到空前发展,尤其卷积神经网络(CNN)[18]为提取图像特征带来了全新解决方案。Shelhamer等以卷积神经网络为基础,提出全卷积神经网络(FCN)[19],用卷积层代替了传统卷积神经网络模型中的全连接层,对图像进行像素级别的分类,解决了语义级别的图像分割问题。2015年的ISBI Challenge比赛上,Ronneberger等提出U-Net模型[20],用级联操作将编码器与解码器融合,编码器对输入图像进行编码,用卷积进行下采样,提取图像特征,解码器采用反卷积进行上采样,将编码信息映射为对应的二值分割掩模;与FCN模型对比,该模型可以在较少样本量上完成网络训练并实现图像分割。随后,大量研究人员在U-Net模型基础上进行改进,Zhou等2018年提出U-Net++模型[21],在解码器和编码器间增加了细粒度信息,重新设计了跳跃连接;Oktay等提出Attention U-Net模型[22],在拼接编码器和解码器对应特征图之前使用注意力机制,抑制了无关区域的特征,提高了分割准确度。
1.2 通道注意力机制
注意力机制是深度学习常用的数据处理方法,是对人类认知功能的模拟[23],利用有限的注意力资源从海量信息中快速筛选高价值的信息。注意力机制快速扫描全局图像,发现重点关注的目标区域,对该区域投入更多注意力,以获取更多细节信息,抑制其他无用信息。
通道注意力机制通过捕获通道间依赖关系,强调或弱化通道间特征响应,提高网络表达能力。Hu等提出的SENet(squeeze-and-excitation networks)模型中的SE模块是一种典型的通道域注意力机制[24]。Wang等在SENet模型基础上,提出一种不降维的局部跨信道交互策略,用于图像分割[25]。其他基于通道注意力的模型还包括GCNet[26]、DANet[27]等。本文拟将SE模块融入提出的新模型,以增强特征表达能力。
1.3 跳层连接与多尺度
近年来,随着深度卷积神经网络在计算机视觉领域的崛起,涌现出许多高效模型。但随着网络层数的加深,会出现信号和梯度消失现象,为此出现了跳层连接模型。Schraudolph等最早提出跳层连接思想[28]。Raiko等研究了跳层连接对模型性能的影响,发现跳层连接不仅提高了随机梯度下降算法的学习能力,而且提高了模型的泛化能力[29]。Srivastava等借鉴LSTM模型的控制门思想提出了残差结构[30]。ResNet模型借助跳层连接,训练更深网络[31]。DenseNet模型[32]在跳层连接基础上,建立前、后层的密集连接,使各层间都有连接,每一层都以前面所有层的输出为其输入,提高了模型的信息提取能力。
多尺度是对信号不同粒度的采样,在不同尺度下可以观察到不同特征,完成不同任务。卷积神经网络通过逐层抽象方式来提取目标特征,感受野太小,只能观察到局部特征,感受野太大,则会获取过多无效信息,因此大量多尺度特征融合模型被提出。多尺度特征融合模型分为并行多分支模型和串行多分支模型,二者均在不同感受野下进行特征提取。常见的并行多分支模型有Inception[33]、DeepLabv3[34]、PSPNet[35]和Big-Little Net[36]等。并行多分支模型结构能够在同一层级获取不同感受野的特征,融合后传递到下一层,可以更好地平衡计算量,有利于压缩模型。串行多分支模型通过跳层连接来完成特征组合,这种模型结构在图像分割中很常见,如FCN[19]、U-Net[20]等模型。串行多分支模型结构将不同抽象层级的特征进行融合,对于边界敏感的图像分割任务不可缺少。
2 模型与方法
2.1 压缩-扩展通道注意力模块
本文提出的压缩-扩展通道注意力模块(squeeze and extend channel attention block,SECA)遵循轻量化、跳层连接、注意力增强原则。其中:轻量化有助于降低模型参数,提高计算效率;跳层连接有助于缓解模型退化问题;通道注意力子模块有助于增强特征表达能力。具体结构如图1所示。

图1 压缩-扩展通道注意力模块SECA
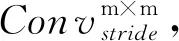
首先,将输入特征图X经过1×1卷积,输出特征图F1,其通道数变少、分辨率不变,有助于减少后续操作的计算量,如式(1)所示。
(1)
然后,将生成的特征图F1经过3×3卷积,进一步提取特征,输出特征图F2与输入特征图尺寸保持一致,如式(2)所示。
(2)
接着,将生成特征图F2经过1×1卷积,使输出特征图的通道数变多、分辨率不变,与输入的原始特征图X尺寸大小一致;然后和输入的原始特征图X逐元素相加,即图1的跳层连接,再进行批归一化BN处理,之后输入给激活函数PReLU,如式(3)~(4)所示。
(3)
(4)
最后,将生成的特征图F4经过通道注意力模块,增强输入特征的表达能力,输出最终的特征图
(5)
2.2 残差多尺度注意力模块
本文提出的残差多尺度注意力模块RMSCA(residual multi-scale channel attention block)遵循多尺度、跳层连接、注意力增强原则。通过多分支结构捕获多尺度信息,增大模型感受野;跳层连接避免信息消失,提升模型提取信息能力和泛化能力;注意力增强提升模型的特征表达能力。RMSCA模块的具体结构如图2所示。

图2 残差多尺度注意力模块RMSCA
假定输入特征图为X∈RC×H×W。一方面,经过3×3卷积来提取特征,由于残差多尺度注意力模块在COVIDSeg模型中的不同位置,因此经过3×3卷积后输出特征图的通道数和分辨率可能改变,也可能与输入特征图尺寸保持一致。当输出特征图通道数和分辨率发生变化时,3×3卷积的步长stride为3;当输出特征图与输入特征图尺寸一致时,3×3卷积的步长stride为1,该操作如式(6)所示。
(6)
另一方面,经过1×1卷积提取特征,该卷积的步长与上述3×3卷积的步长相同,其输出特征图F2与特征图F1尺寸大小一致,如式(7)所示。
(7)
3×3卷积和1×1卷积对同一输入特征图在不同尺度上提取特征,2种特征在后续操作中通过逐元素相加进行有效融合。
另外,将特征图F1经过3×3卷积,输出与F1尺寸大小一致的特征图
(8)
接着,特征图F1、F2和F3逐元素相加进行特征融合,其中F1和F2的相加可看做不同尺度下的特征融合,F1和F3的相加属于残差特征融合,如式(9)~(10)所示。
F4=F1⊕F2⊕F3,
(9)
F5=PReLU(BN(F4))。
(10)
最后,将生成的特征图F5经过通道注意力模块,增强输入特征的表达能力,输出最终生成的特征图
(11)
2.3 卷积下采样模块和特征聚合模块
卷积下采样模块CDS(convolution down sampling)位于编码子网络中,该模块执行下采样任务,具体结构如图3所示。
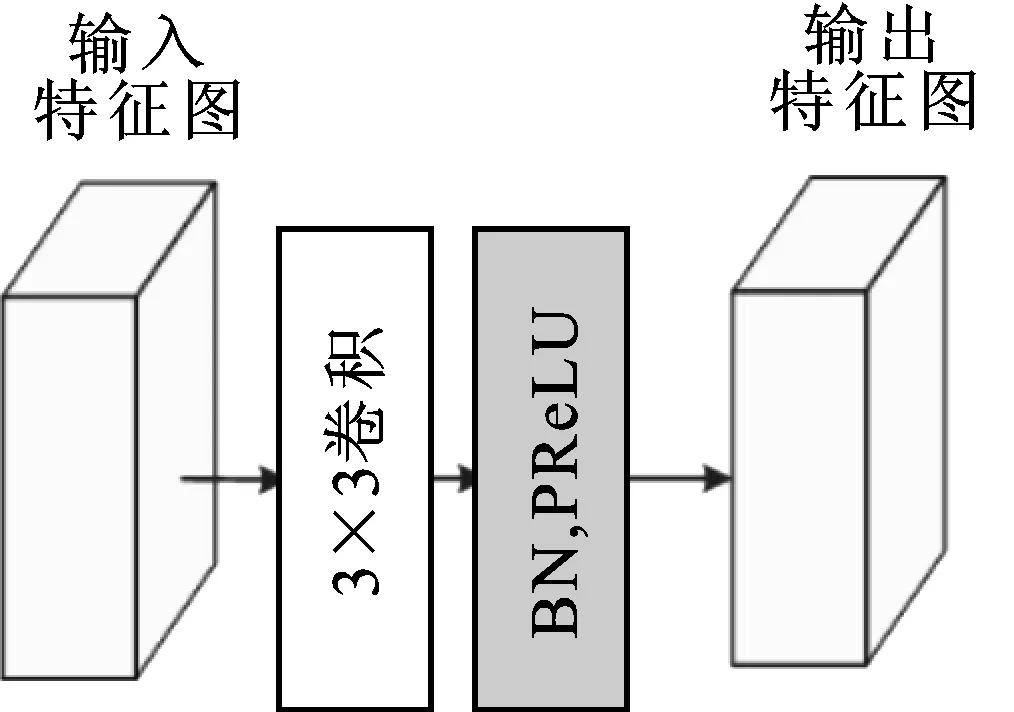
图3 卷积下采样模块CDS
其中,输入特征图通过3×3卷积提取特征,然后经过批归一化BN和激活函数PReLU后输出特征图。经过卷积下采样模块后输出特征图的通道数增加,分辨率降低。
特征聚合模块FFM[37](feature fusion module)是解码器子网络的主要组成部分,将解码子网络中上一Stage层的输出特征进行多尺度特征提取,具体结构如图4所示。

图4 特征聚合模块FFM
输入特征图先经过1×1卷积提取特征,再分2路分别经过空洞率为2的3×3空洞卷积和空洞率为1的3×3空洞卷积,然后将2路特征图逐元素相加,最后经过批归一化BN操作,输出特征图。经过特征聚合模块后输出特征图的通道数减少,分辨率不变。
2.4 COVIDSeg模型
COVIDSeg模型(图5)包含COVIDSeg-Base模型和在COVIDSeg-Base模型基础上扩展而出的COVIDSeg-Large模型,2种模型结构一致,其中的模块类型相同,数量不同。图5a是COVIDSeg-Base模型,图5b是COVIDSeg-Large模型,2种模型在本文统称为COVIDSeg模型。
COVIDSeg模型包括编码子网络和解码子网络两部分,每部分分别包含4个Stage层,如图5所示的Stage1-Stage4。编码子网络由双通路结构构成,即图5的Left Path和Right Path通路,这些通路连接各个模块,通路内特征逐层传递,通路间多级特征交互,从而促进不同层级有效信息的传递和表达。编码子网络的SECA模块汇聚了不同通路的特征,并在不同通路间传递。解码子网络是一个简单有效的多尺度特征解码网络,各Stage层逐层进行特征上采样,并融合编码子网络对应Stage层的特征图。下面以图5a展示的模型COVIDSeg-Base为例详细阐述COVIDSeg模型的网络结构。
图5a所示COVIDSeg-Base模型的编码子网含有左通路(left path)和右通路(right path),从上到下4个Stage层,各Stage层输出特征的通道数依次增加,分辨率依次减小。每个Stage层包括一个SECA模块、一个CDS模块和3个RMSCA模块,每个Stage层最上面的RMSCA和CDS模块输出特征图的通道数和分辨率均发生改变,其他模块输入特征图与输出特征图的尺寸保持一致,因此给另外2个RMSCA模块间添加跳层链接,融合2个RMSCA模块的输出。编码子网络的左通路负责特征的聚合与分发,先将CDS模块和RMSCA模块输出的特征逐元素相加实现多通路特征聚合,而后经过SECA模块实现特征提取,最后将提取的特征分发到右通路的相应模块,以实现特征增强,并传递到下一个Stage层;编码子网络的右通路是主干分支,负责主要特征的提取和传递。
COVIDSeg-Base模型的解码子网络由Stage1-Stage4共4个Stage层构成,依次对应编码子网络的Stage4-Stage1,各Stage层输出特征图的通道数依次减少,分辨率依次增加。解码子网络的各Stage层以上一Stage层的输出经过FFM模块进行特征聚合,然后与编码子网络对应Stage层的输出经过1×1卷积和批归一化BN操作后,进行逐元素相加,作为该Stage层的输入。解码子网络的各Stage层包括1×1卷积、线性插值、FFM 3种主要模块。其中,与编码子网络连接的1×1卷积不改变特征图的通道数和分辨率,实现了跨通道信息整合;与模型输出连接的1×1卷积将特征图的通道数变为3,分辨率不改变。图中的2×、4×、8×表示线性插值,经过该操作后特征图的通道数不变,分辨率增加相应倍数。FFM模块的多尺度特征聚合,提高了网络的特征表达能力。
图5b的COVIDSeg-Large模型是在COVIDSeg-Base模型基础上进行进一步改进获得,其框架与COVIDSeg-Base模型一致,只是COVIDSeg-Large模型编码子网络的每个Stage层中增加了1个SECA模块和2个RMSCA模块。COVIDSeg-Large模型通过复用SECA模块和RMSCA模块,以及保持相似的模块连接,来增强模型的表达能力。

图5 本文提出的COVIDSeg模型结构图
以CONVIDSeg-Base模型为例,假设输入图像为3×512×512,即3通道、512宽、512高的图像,编码子网络4个Stage层的输出特征则依次为8×256×256、24×128×128、32×64×64、64×32×32。CONVIDSeg-Base模型每个Stage层内各模块输出特征图的相关信息如表1所示。
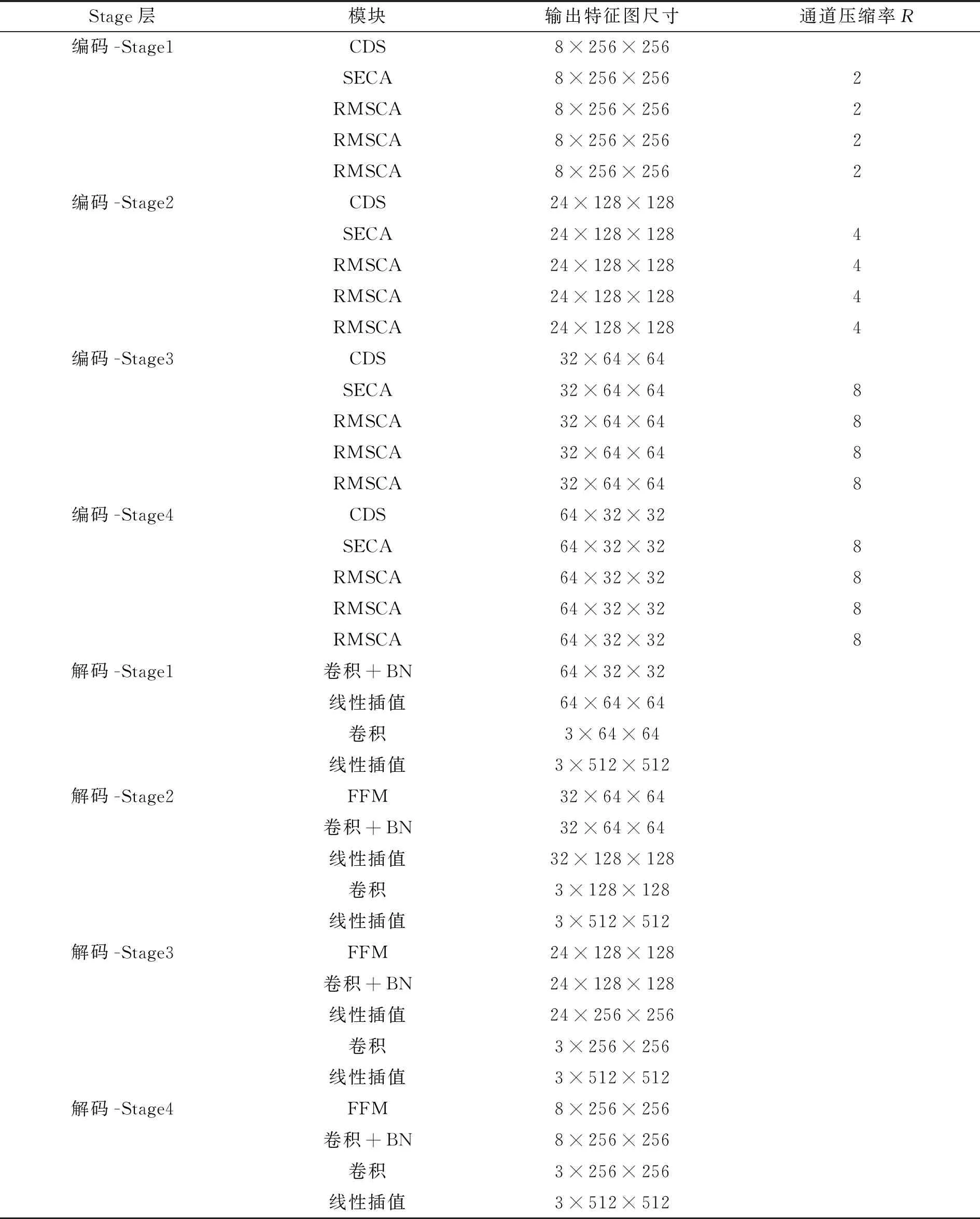
表1 COVIDSeg-Base模型结构细节(输入为3×512×512)
3 实验结果与分析
3.1 实验数据
目前,针对新冠肺炎肺部CT图像分割的研究主要分为2类:第1类旨在图像中分割出肺部区域[38-39],这是新冠肺炎研究的第一步;第2类旨在图像中直接分割出肺部感染病变区域[37,40-42]。本文属于第2类研究,我们采用有肺部感染区域标记的数据集,用提出的COVIDSeg模型分割图像病变区域,测试模型的分割结果与标记是否一致。由于新冠肺炎肺部CT图像数据来源、分割标准、病变标注类型各不同,难以组合成一个统一的CT图像分割数据集[40,43-44]。因此,本文利用2020年发布的4个广泛使用的COVID-19 CT图像分割公开数据集测试提出的模型COVIDSeg。4个公开数据集分别是:COVID-19 CT Segmentation Dataset中的2个子数据集[45]、COVID-19 CT Lung and Infection Segmentation Dataset[41]和MosMedData[46]。为方便起见,本文将这些数据集分别命名为COVID-19-A[45]、COVID-19-B[45]、COVID-19-C[41]、COVID-19-D[46],其基本信息如表2所示。

表2 实验用COVID-19 CT数据集图像数量统计
表2显示,COVID-19-A数据集包含来自约60个不同病例的共100张轴向二维CT切片,均为感染了新冠肺炎的CT切片;该数据集的CT图像来自意大利医学和介入放射学会,放射科医生使用不同标签来标识CT图像的肺部感染区域,提供了毛玻璃(ground glass)、结石(consolidation)和胸腔积液(pleural effusion)3种病变标签,本文将3种标签合并为病变标签。COVID-19-B数据集包含来自Radiopaedia的9个不同病例共829张轴向二维CT切片,放射科医师将其中的373张切片评估为新冠肺炎切片,并进行图像分割标示,数据为NIFTI格式。COVID-19-C数据集包含来自Coronacases Initiative和Radiopaedia的20个不同病例共1 844张CT切片,所有图像均为感染了新冠肺炎的CT切片,图像由有经验的放射科医生标记。COVID-19-D数据集包含来自俄罗斯莫斯科市立医院1 110个病例的肺部CT图像,诊断和远程医疗技术专家对其中50个病例图像进行标注,共包含785张确诊新冠肺炎的CT图像,该数据集提供了毛玻璃(ground glass)、结石(consolidation)2种病变标签,本文将2种标签合并为病变标签。
4种数据集的部分图像如图6所示,第1行表示原始CT图像,第2行表示Mask标记图像。其中,图6a来自COVID-19-A数据集,图6b来自COVID-19-B数据集,图6c为COVID-19-C数据集的示例,图6d为COVID-19-D数据集的示例。

图6 COVID CT数据集部分CT图像
3.2 实验环境与评价指标
本文实验操作系统为Ubuntu 16.04,在单个型号为NVIDIA GeForce RTX 2080的GPU上训练模型。基于PyTorch 1.4.0深度学习框架构建COVID-19图像分割网络,CUDA版本9.0。利用Adam优化器来更新网络模型权重,初始学习率是0.001,学习率衰减值为0.000 1,beta_1参数为0.9,beta_2参数为0.999。使用poly学习策略更新学习率。使用交叉熵损失函数,batch size为5,最大训练次数为80,保留最后一轮训练结果模型。
使用医学图像分割领域常用的5种评价指标来定量评价提出的新冠肺炎CT图像分割模型COVIDSeg的性能。5种评价指标包括:平均交并比(mean intersection over union,MIoU)、灵敏度(sensitivity,SEN)、特异度(specificity,SPE)、Dice相关性系数(Dice similarity coefficient,DSC)以及豪斯多夫距离(Hausdorff distance,HD)。各指标分别定义如下。
MIoU(式中简记为MIoU)表示平均每一类的预测值和真实值的交集与并集的比值,计算公式为
(12)
式中:k为类别数;TP为正确预测为第i类的样本数;FP表示错误预测为第i类的样本数;FN表示错误预测为不是第i类的样本数。
本文实验只有病变区域和背景区域,我们用TP表示正确分割为肺部病变区域的真阳性像素数,FP表示错误分割为肺部病变区域的假阳性像素数,TN表示正确分割为背景区域的真阴性像素数,FN表示错误分割为背景区域的假阴性像素数,则考虑算法对病灶区域和背景区域综合分割性能的MIoU为
(13)
Sensitivity(式中简记为Sp)也称为True positive rate,在二分类问题中表示正类(即本文的病变区域)的识别率。因此,本文用Sensitivity衡量算法正确分割出肺部病变区域的能力,定义为正确分割为肺部病变区域与真实肺部病变区的比率。灵敏度的值越接近1,说明肺部病变区域像素点被错误分割成背景区域像素点越少,其分割性能越好。计算公式为
(14)
Specificity(式中简记为Sn)也称为True negative rate,在二分类问题中表示负类(即本文CT图像的背景区域)的识别率,表达了真实负类被正确预测为负类的比例。本文用Specificity表示算法正确分割为真实背景区域的比率,衡量算法正确分割出背景区域像素点的能力。计算公式为
(15)
DSC是集合相似性的度量指标,计算2个集合的相似度,值域为[0, 1];最好时为1,表示2个集合完全相似;最差时为0,表示2个集合没有任何相似性。在图像分割问题中,DSC(式中简记为DSC)用来度量算法的分割结果与真实结果的相似性。计算公式为
(16)
式中:X和Y分别表示真实结果和算法分割结果;X∩Y表示X和Y的交集。
HD描述2组点集间的相似度,对分割边界敏感。计算公式为

(17)
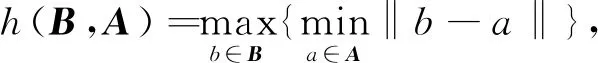
(18)
HD(A,B)=max(h(A,B),h(B,A))。
(19)
式中:‖·‖是距离范式;h(A,B)和h(B,A)分别为从点集A到点集B和从点集B到点集A的单向豪斯多夫距离;式(19)是豪斯多夫距离的最基本形式,称作双向豪斯多夫距离。双向豪斯多夫距离HD(A,B)是单向距离h(A,B)和h(B,A)中的较大者,它度量了2个点集间的最大不匹配程度,其值越小越好。
另外,还将比较本文COVIDSeg模型与现有模型的参数量和时间效率,即模型的时间复杂度和空间复杂度。
3.3 数据预处理
本文采用5-折交叉验证实验,测试提出的COVIDSeg模型。为了保证数据输入的一致性,图像大小统一调整为512×512。采用归一化(Normalize)、成比例缩放图像大小(Scale)、随机裁剪并调整大小(RandomCropResize)、随机翻转(RandomFlip)共4种数据预处理方式。其中,归一化操作Normalize( )对输入的RGB图像3个维度分别计算平均值和方差,并逐维度进行归一化处理;成比例缩放图像大小操作Scale(w,h)分别用双线性插值和最近邻插值改变输入图像和Mask标记图像的尺寸至宽高分别为w和h的图像;随机裁剪并调整大小操作RandomCropResize(n)以0.5的概率随机选取图像,沿图像外围在最大为n的范围内裁剪,裁剪后图像以最近邻插值方式恢复至输入图像大小;随机翻转操作RandomFlip( )以0.5的概率水平或竖直翻转图像。
本文实验组合上述4种数据预处理策略,得到如表3所示的5种不同数据预处理方法。其中,训练集在一轮训练中依次采用#1-#4方法进行数据预处理,共训练80轮;测试集用#5方法进行预处理。

表3 数据预处理方法
3.4 COVIDSeg与其他方法的对比实验
本文将在不同图像分割数据集测试提出的COVIDSeg(COVIDSeg-Base和COVIDSeg-Large)模型,并与其他10种主流分割模型进行性能比较。这里选择了2种类型的主流图像分割模型,一种是分割模型参数量大、计算复杂度高的模型,如U-Net[20]、U-Net++[21]、Attention U-Net[22]、SegNet[15]、 DeepLabv3[34]、DeepLabv3+[47];另一种是分割模型参数量小、计算复杂度低的轻量化模型,如ENet[48]、ESPNet[49]、CGNet[50]、EDANet[51]等。表4列出了各模型的参数量(parameter)和浮点运算次数(floating-point operations, FLOPs),分别从空间占用和时间消耗两方面衡量模型性能,即比较模型的时间和空间复杂度。
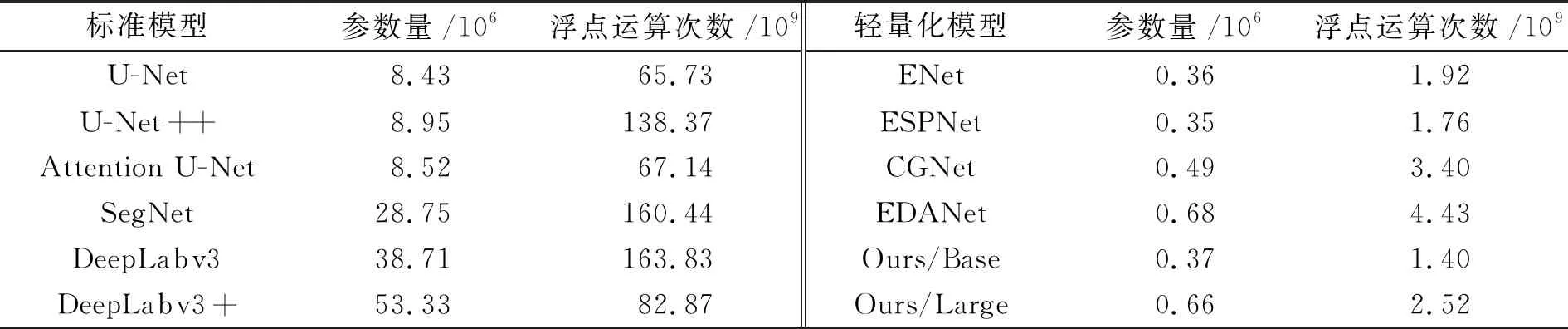
表4 各模型的参数量和FLOPs
各模型5-折交叉验证实验的结果如表5所示,加粗表示最优结果,下划线表示本文提出的COVIDSeg模型性能在所有比较算法中位居前三,但非最优结果。从表4可以看出,与10种主流分割模型相比,本文提出的2种模型参数量较少,因此能够有效避免小数据在大模型上的过拟合问题。另外,本文提出的2种模型的FLOPs值较小,表明模型的时间效率高、计算速度较快、时间消耗较低。

表5 各模型的5折交叉验证实验结果
下划线表示本文提出的COVIDSeg模型性能位居前三。
表5实验结果可见,提出的COVIDSeg模型在COVID-19-C数据集的性能最优,然后依次是在COVID-19-D、COVID-19-A、COVID-19-B数据集的性能。总体来看,本文提出的COVIDSeg模型是所有比较模型中性能最优的。对比模型DeepLabv3在COVID-19-A数据集的MIoU、DSC和HD指标取得最优值,与参数量类似的轻量化模型相比,本文提出的COVIDseg模型性能优越性更加明显。
另外,对比提出的2个模型的5-折交叉验证实验结果发现,COVIDSeg-Large模型的性能更优。除了COVID-19-D数据集,其在COVID-19-A、COVID-19-B和COVID-19-C数据集的MIoU、DSC和HD指标都优于提出的COVIDSeg-Base模型;但其在COVID-19-D数据集SEN和SPE指标优于提出的COVIDSeg-Base模型。
3.5 主要模块和结构测试实验
3.5.1 主要模块测试
为了分析提出的SECA和RMSCA模块对模型性能的影响,以COVIDSeg-Base模型为例使用COVID-19-B数据集进行实验,通过MIoU、SEN、SPE、DSC和HD量化分析指标,验证SECA和RMSCA模块对提出COVIDSeg模型的作用。实验结果如表6所示,其中model-1是COVIDSeg-Base模型中有SECA模块没有RMSCA模块的结果,model-2是COVIDSeg-Base模型中有RMSCA模块但没有SECA模块的结果,model-3是完整的COVIDSeg-Base模型,加粗表示最好结果。

表6 不同模块对模型性能的影响
实验结果显示,同时拥有SECA和RMSCA模块的COVIDSeg-Base模型在MIoU、SPE、DSC和HD 4个指标上均取得最优值,较各指标最差值分别提升2.83%、0.39%、3.54%和12.88%,在SEN指标上取得了次优结果,model-1的SEN值最优。这表明完整的COVIDSeg-Base模型对新冠肺炎肺部CT图像的分割效果最好。model-1在SEN指标上取得最优结果,在SPE指标上取得最差结果,这说明model-1会将较多的非病变区域(背景)误识为病变区域。分析原因是,真实的Mask标记图像中病变区域往往存在较多微小的非病变区域,这些微小的非病变区域被预测为病变区域,导致对病变区域识别能力高(SEN指标最优),对非病变区域识别能力差(SPE指标最差)。model-1与model-2相比发现,后者在MIoU、SPE、DSC、HD 4个指标上均取得了更优结果,说明提出的RMSCA模块对于新冠肺炎CT图像的正确分割非常重要。
3.5.2 双通路结构测试
为了分析COVIDSeg双通路结构对模型性能的影响,依然以COVIDSeg-Base模型为例,在COVIDSeg-Base基础上,设计2个单通路编码器结构,测试双通路结构的性能,实验结果如表7所示。右通路是指仅保留编码子网络双通路结构中的右通路,并取消左右通路间的信息交互操作;同理,左通路是指仅保留双通路结构中的左通路,取消左右通路间的信息交互操作,同时用左通路的输出代替右通路的输出与相应的解码器Stage层交互;双通路是指本文提出的带有双通路结构的COVIDSeg-Base。表中加粗指标值表示模型在同一指标下的最优结果。

表7 双通路结构对模型性能的影响
表7实验结果显示,与2种单通路结构相比,双通路结构在MIoU、SPE、DSC 3项指标上均取得了最优结果,与表7中各指标的最差值相比,分别提升4.91%、0.72%和6.32%;另外,双通路结构分别在SEN、HD指标上取得次优结果。比较右通路和左通路模型发现,左通路模型在除了HD的其他4个量化指标上均优于右通路模型,说明左通路对模型COVIDSeg的性能贡献大于右通路。因为左通路的主要模块是SECA模块,这说明提出的SECA模块有很强的特征提取能力。
另外,左通路模型本质上相当于表6中去掉RMSCA模块的model-1模型,但左通路模型除了包含SECA模块,还包含卷积下采样模块CDS。因此,表6中去掉SECA模块的model-2模型比右通路模型多了卷积下采样模块CDS以及通路间的信息交换。表6中model-2模型的MIoU、SEN、SPE和DSC指标比右通路模块更优,这说明COVIDSeg模型左通路的卷积下采样模块CDS和左右通路间的信息交互对整个模型COVIDSeg的性能提升不可或缺。
与表5中的10种主流模型相比,表7的左通路和右通路模型在多项指标上也取得了不错的结果,这不仅表明本文提出的左、右单个通路结构的有效性,也说明本文提出的SECA和RMSCA模块的有效性。
3.6 结果可视化
通过提出的COVIDSeg-Base模型和COVIDSeg-Large模型在COVID-19-A、COVID-19-B、COVID-19-C和COVID-19-D数据集部分实验结果的可视化,来展示提出的COVIDSeg模型的分割性能,实验结果如图7所示。图7a来自COVID-19-A数据集,图7b来自COVID-19-B数据集,图7c来自COVID-19-C数据集,图7d来自COVID-19-D数据集。

图7 COVIDSeg模型分割结果的可视化
从图7可以看出,提出的COVIDSeg-Base模型和COVIDSeg-Large模型在4个数据集的分割结果与图像的真实Mask标记大致相同,能够较好地对肺部CT图像进行分割。同时,提出的模型能够对CT图像的整体病变轮廓进行很好分割,尤其是能较好地分割较大的病变区域,但对于微小病变区域的分割效果仍然有值得改进的空间。另外,COVIDSeg-Large模型的分割结果比COVIDSeg-Base模型的分割结果更精确。
4 结论
基于深度学习的医学图像分割在计算机辅助诊断中有着广泛应用价值和重要研究意义。本文基于轻量化模型设计原则,提出了针对COVID-19肺部CT图像分割的轻量化模型COVIDSeg。该模型采用双通路结构,包括提出的通道注意力模块SECA和提出的具有多尺度、残差连接等设计思想的注意力模块RMSCA,以及复杂的跳层连接和通道间信息交互连接,能捕获丰富的上下文信息,在多个新冠肺炎肺部CT图像数据集取得了良好的分割效果。
然而,本文提出的COVIDSeg模型各模块间的连接存在太多人为设计痕迹,不能保证所得模型是最优模型。如何自动搜索设计最优的模块连接方式,使模型性能达到最优,仍然有待进一步研究。
