白细胞散点图识别模型的建立与验证*
2022-06-07赵天赐李建英连荷清刘丹王庚王欣李柏蕤吴卫中国医学科学院北京协和医院检验科北京00730北京小蝇科技有限责任公司北京00084
赵天赐,李建英,连荷清,刘丹,王庚,王欣,李柏蕤,吴卫(.中国医学科学院北京协和医院检验科,北京 00730;.北京小蝇科技有限责任公司,北京 00084)
血液分析仪作为外周血常规检测仪器,可以对血细胞进行自动分析,生成包括细胞计数与分类、细胞散点图/直方图、报警信息和可供参考的研究参数等结果。在日常血常规审核工作中,如果能够第一时间从细胞散点图/直方图中发现问题,将极大程度节省结果分析、审核时间,提高工作效率,减少漏检[1-2]。
准确判断细胞散点图/直方图是否正确是全血细胞分析初筛过程中的关键步骤。虽然血细胞分析仪提供了大量散点图相关的报警信息[3-6],但在实际工作中,若完全依赖于仪器提供的报警信息,由于仪器内部报警阈值或其他因素的影响,有时会出现误报、漏报的情况,对最终的判断带来一定的不确定性。
为了能够在实际工作中给检验工作者提供准确、全面的白细胞散点图判断结果作为参考,本研究设计了一个深度学习模型,用于识别和判断血细胞分析仪中白细胞分类(white blood cell difference,WDF)通道散点图是否异常。该模型将散点图作为输入,输出散点图正常或者异常的判断结果。该模型基于卷积自编码器算法[7-9]进行特征提取,采用pytorch框架进行训练,同时加入先验知识算法形成双重验证机制,使模型能够精确识别出异常散点图,为检验技师提供更有价值的参考,减少漏检。
1 材料与方法
1.1 样本选择
1.1.1 模型建立与验证样本选择 选取北京协和医院检验科2020年5月至8月门诊及住院患者的EDTA-K2抗凝血常规样本32 729例,提取其WDF通道散点图,其中首诊样本约占70%,复诊样本约占30%。所有样本均在采集后4 h内完成检测。
1.1.2 模型测试样本选择 选取北京协和医院检验科2020年9月至10月门诊及住院患者的EDTA-K2抗凝血常规样本11 043例。所有样本均在采集后4 h内完成检测。
1.2 主要仪器与试剂 Sysmex XN-20全自动血液分析仪及其配套检测试剂、质控品、校准品(日本Sysmex公司)。
1.3 WDF通道散点图细胞分类判断方法 根据Sysmex XN-20仪器说明书中模式图对WDF通道散点图的细胞区域划分方法对散点图中出现的异常细胞分为7类,包括影细胞/细胞碎片、有核红细胞、异常淋巴细胞/原幼淋巴细胞、不典型淋巴细胞/异型淋巴细胞、原始细胞、核左移、幼稚粒细胞,见图1。
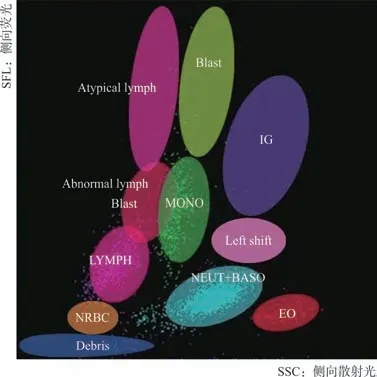
图1 WDF通道散点图细胞分类
1.4 数据集划分
1.4.1 第1阶段数据 选取北京协和医院检验科2020年5月至8月门诊及住院患者的EDTA-K2抗凝血常规样本,提取其WDF通道散点图共计32 729份。由3位检验技师对散点图进行分期标注,间隔2周(脱敏期,排除人为主观因素影响前后2次标注结果)后,对这些散点图进行第2次标注。其中,3位检验技师2次标注共6人次结果全部一致的散点图共28 302份,可以认为此28 302份散点图为特征显著散点图。另有4 427份散点图,虽然3位检验技师最初的标注结果不一致,但经过共同讨论后达成一致,若无法达成一致则追溯涂片镜检结果为最终判断结果,据此认为此4 427份散点图为特征不显著散点图。数据集分为2类,即正常散点图和异常散点图,正常散点图共20 959份,异常散点图共11 770份。训练集、验证集和测试集A所含散点图数量按照8∶1∶1进行划分。
1.4.1.1 训练集 用于前期模型训练。28 302份特征显著散点图中随机选取80%,即22 642份散点图加入训练集,4 427份特征不显著散点图中随机选取80%,即3 543份散点图加入训练集,训练集共26 185份。
1.4.1.2 验证集 用于验证模型性能。28 302份特征显著散点图中选择除训练集之外数据,随机选取10%,即2 830份散点图加入验证集,4 427份特征不显著散点图中选择除训练集之外数据,随机选取10%,即442份散点图加入验证集,验证集共3 272份。
1.4.1.3 测试集A 用于选择性能最优的模型。28 302份特征显著散点图中选择除训练集与验证集之外数据,即2 830份散点图加入测试集A,4 427份特征不显著散点图中除训练集与验证集之外数据,即442份散点图加入测试集A,测试集A共3 272份。
正常散点图和异常散点图数据量分布见表1,特征显著散点图和特征不显著散点图数据量分布见表2。
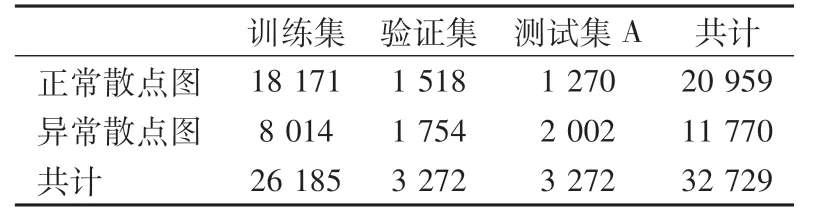
表1 正常散点图和异常散点图数据量分布
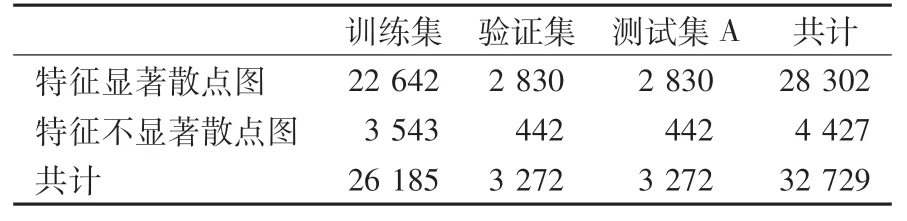
表2 特征显著、不显著散点图数据量分布
1.4.2 第2阶段数据 从北京协和医院检验科2020年9月至10月门诊及住院患者的EDTA-K2抗凝的血常规样本,随机选出11 043份WDF通道散点图,由相同的检验技师利用与第1阶段数据同样的方法进行标注,对于标注结果不一致的散点图,由3位检验技师共同讨论得到最终结果。此11 043份散点图包含了特征显著散点图及特征不显著散点图,构成了测试集B。
1.5 深度学习算法与图像分析
1.5.1 图像预处理 从Sysmex XN-20全自动血液分析仪中导出WDF通道散点图后,为去除原始图像中可能的干扰信息对模型输出结果的影响、便于模型对输入图像进行识别和特征提取,主要对原始图像进行了以下预处理。①将散点图格式统一转换为png格式;②去除散点图中与散点不相关的信息,如坐标轴及标识等;③将散点图背景统一转换为白色。
1.5.2 网络结构 模型主要由卷积自编码器中的编码模块、解码模块、异常值计算模块和统计模块组成,最终分类器采用神经网络模型和先验知识双重验证机制,提高模型输出准确率。具体的网络结构如图2所示。
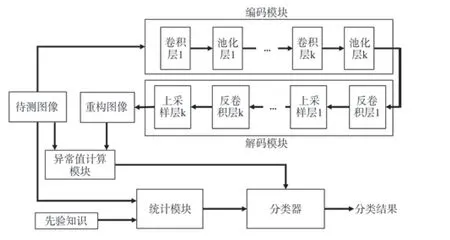
图2 网络结构图
1.5.2.1 卷积自编码器中的编码模块 编码模块可对输入的待测图像进行特征提取,并且随着编码网络的层次逐渐加深,提取的特征也呈现出由浅层到深层的特点。使用大量具有相同或相似特征的正常白细胞散点图对编码器进行训练,可以使其准确捕捉用于重构图像的特征信息。
1.5.2.2 卷积自编码器中的解码模块 解码模块中的计算操作是编码模块的逆向操作,旨在由特征值还原出原图像,得到重构图像。解码器的训练与编码器协同进行,训练的最终目标是使卷积自编码器对正常白细胞散点图的重构误差最小化。
1.5.2.3 异常值计算模块 异常值计算模块以重构图像和待测图像作为输入,计算二者之间的均方误差作为卷积自编码器的重构误差,并作为异常值计算的依据。
1.5.2.4 统计模块 统计模块以先验知识和待测图像作为输入,首先将拥有数十年散点图判断经验的检验技师知识经验转化为一系列统计指标对应的约束条件,之后待测图像在统计模块中经历相关数学运算和变量统计得到判定结果。
1.5.2.5 分类器 异常值计算模块输出的异常值和统计模块输出的基于先验知识算法的判定结果均输入到分类器之中,由分类器作进一步的判断,最终输出结果。
1.6 性能确认方法 最终以模型识别的精确率作为性能指标,算法模型在测试集上的精确率达到95%以上,且比检验技师高,则能说明算法有较好的识别效果,同时能帮助检验技师减少漏检。另外,对比算法与检验技师在异常散点图以及特征不显著散点图上的识别精确率,算法模型识别性能有显著提高,则能表明算法在比较难发现的(异常)样本上对检验技师有更有益的辅助作用,同时由方差来判断其稳定性。精准率计算公式:P=TP/(TP+FP);P:精准率;TP:把正类预测为正类的个数;FP:把负类预测为正类的个数。
2 结果
2.1 训练过程与结果 按照设计的先后顺序训练了2个模型:模型1是现有的神经网络模型;模型2加入了先验知识算法,将图像特征和先验知识结合,得到最终结果。
模型1是采用基于深度学习的神经网络方法构建检测模型。算法训练采用pytorch框架,训练过程经过100个epoch,当损失函数loss稳定时,即为训练过程结束,训练过程中每一个epoch结束时都会通过反向传播对预测结果与真实结果比较,得到预测结果精确率,预测结果精确率较高的几组模型作为备选模型,同时将备选模型用于测试集A,精确率最高的成为最优模型。
模型2在模型1的基础上加入先验知识算法,将神经网络模型中预测结果精确率较高的几组模型与先验知识算法相结合作为备选模型,同时将备选模型用于验证数据集,精确率最高的为最优模型。
2个模型在验证集上的表现见表3,模型2训练过程中Loss变化曲线见图3,模型2训练过程中在验证集精确率变化曲线见图4。
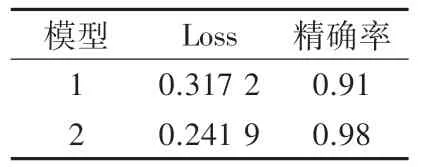
表3 2个模型在验证集上的表现结果
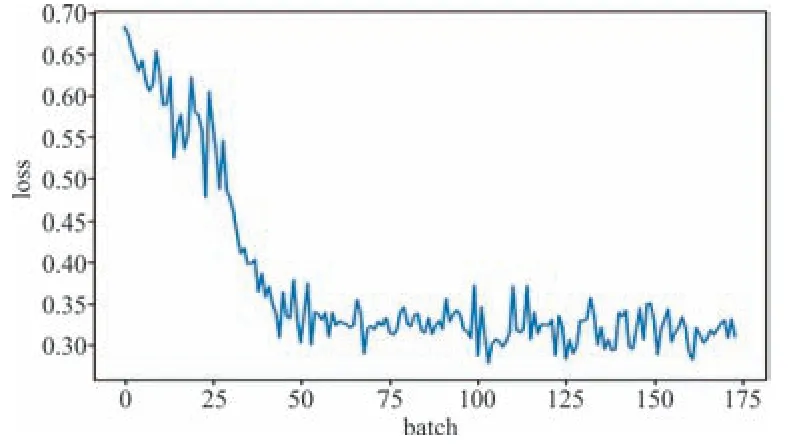
图3 模型2训练过程中Loss变化曲线
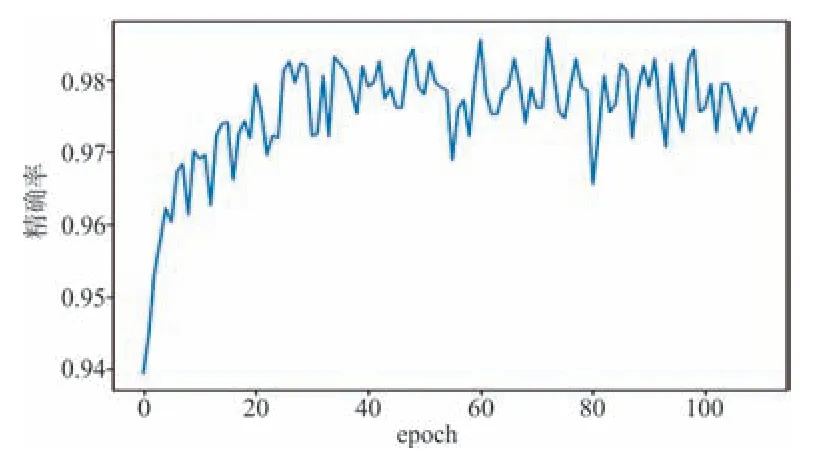
图4 模型2训练过程中在验证集的精确率变化曲线
2.2 测试过程与结果 在测试集A和测试集B上,模型2和检验技师的精确率比较见表4,其中,检验技师的精确率由3位检验技师标定的不同结果与最终讨论结果对比产生。

表4 模型2和检验技师在测试集A和测试集B的精确率比较
将测试集B中所含散点图按是否正常分为正常散点图和异常散点图,按3位检验技师2次标定结果是否完全一致分为特征显著散点图和特征不显著散点图,并比较模型2、检验技师和血液分析仪的精确率,结果见表5。
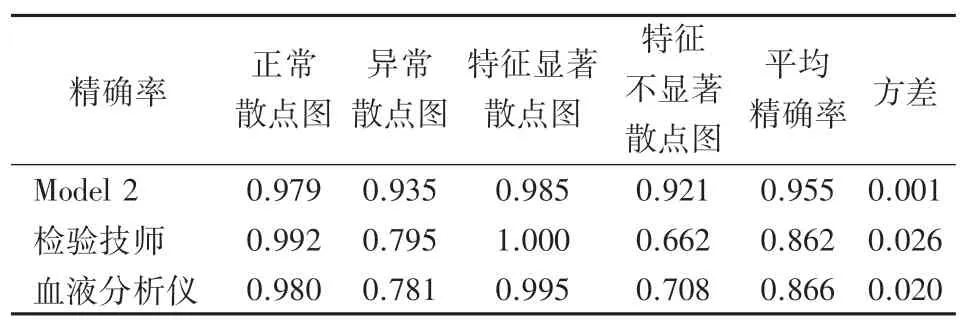
表5 模型2、检验技师和血液分析仪在测试集B的精确率比较
3 讨论
在医学领域,许多研究者已将图像处理、传统的机器学习和深度学习等相关算法运用到实际问题中[10-12]。WDF通道散点图作为血常规初筛过程中判断白细胞分类是否正确的一个重要参考,在血常规复检和审核工作中尤为重要[13-16]。截至目前,在外周血细胞分析的复检和审核规则中,与散点图相关的规则仅为仪器是否给出阳性报警,若完全依赖仪器给出的阳性报警而不对散点图进行具体分析,则可能会出现漏检。此外,鉴于检验技师水平和经验,对散点图的识别有差异,极有可能因无法识别出特征不显著散点图中存在的异常而出现漏检。
本研究设计的模型将标准散点图和高年资检验技师的数十年散点图判断经验相结合。采用深度学习算法针对散点图提取高级特征,精确识别和定位散点图异常点,筛选有用信息自动建模,忽略不相干的背景信息。此外,将拥有数十年散点图判断经验的高年资检验技师的判断经验转化为模型判断条件,形成先验知识算法,与深度学习算法形成双重验证机制,对散点图进行高精确率识别,使得模型的综合判断能力得到了极大的提升。
从实验结果表3可以看出,增加了先验知识算法之后的模型在精确率性能上表现更好,说明了检验技师的判断经验能够在一定程度上弥补仪器模式图带来的过拟合和精确率低等问题,使模型具有更好的鲁棒性和泛化能力。从实验结果表4和表5可以看出,不论是在测试集A或测试集B上,本研究模型的表现都优于检验技师。这是因为检验技师在处理特征不显著的WDF通道散点图时主观性较强。在这种情况下,本研究模型由具有明确分类特征的样本进行训练,对于特征不显著的样本,能够通过识别待测散点图的图像特征并结合先验知识算法计算出属于每个种类的得分,得出综合结果,可重复性强。
值得注意的是,本团队在实际工作中发现,仪器散点图给出的报警信息不仅出现少报、误报的现象,在某些情况下,散点图未给出任何报警信息,或仅给出红系、血小板相关报警信息,但该标本涂片镜检可见白细胞异常,如原始细胞、异常淋巴细胞等,此类情况下,若完全依赖仪器给出的报警信息而不对散点图进行二次确认,则极大可能造成漏检。本研究模型对仪器给出的散点图进行判断,给出“正常”或“异常”结果,旨在辅助检验技师对散点图进行二次判断,并提供参考,减少完全依赖仪器给出的阳性报警信息而不对散点图进行二次确认所导致的漏检。此外,检验技师在核查深度学习模型所给出的结果时,可对模型结果进行校正,校正后的数据可加入模型之后的训练过程中,进一步提升模型判断精确率。对于判断较为困难的WDF通道散点图,深度学习模型能够给出所得出结果的置信度供检验技师参考,大大提高了检验技师的工作效率和判断准确率,减少漏检。由此,检验技师可以将宝贵的时间放到对标本的全面判断和异常标本的涂片镜检中。
本团队将对模型进一步训练和完善,实现对散点图具体异常特征的识别和判断,并与显微镜的镜检结果相结合,弥补现有外周血细胞分析复检规则和审核规则中可能出现的漏检情况,进一步完善现有的外周血细胞分析复检和审核规则,为建立外周血细胞分析智能审核系统奠定基础。此外,本团队观察到散点图典型异常特征与某些血液系统疾病密切相关,通过将散点图典型异常特征与显微镜镜检结果相结合,实现对某些典型疾病的初步判断和鉴别诊断,为临床提供更有价值的参考。
