基于深度学习的植物果实重量正态分布检验设计与实现
2022-06-07曾祥潘吴俊杰孙丽君
曾祥潘 吴俊杰 孙丽君












正态分布是自然界中最常见和最重要的一种分布,如某地区一个月降雨量的分布、一个公园里树木高度的分布等。在其他的一些数据分析中,如T检验、回归分析等,都要求先对数据进行正态性检验。学生在种植活动中收获植物的果实,果实重量分布是否符合正态分布呢?如果只预设总体的正态性,直接套用计算公式进行计算,可能会影响统计效果。我们可以用计算机采集数据,再用统计软件进行计算分析,验证果实的重量是否符合正态性。
本实验研究使用电子称测量在种植园采摘的小番茄重量。首先对小番茄逐个称重、拍照记录;然后利用深度学习框架训练的AI模型识别照片中电子秤显示的数值,采集所有小番茄的重量数据;最后通过R语言进行数据正态分布检验。通过活动让学生体验利用人工智能项目解决实际问题的一般路径,为今后制作通用的仪表数据收集工具提供必要的训练数据和技术路线。
● 设计思路
通过本实验活动,实现小番茄称重数值的识别采集,并检测重量数据是否符合正态分布。实验项目需经历AI数据集制作、训练AI模型、使用AI模型推理这一过程,能够从小番茄称重图片中识别和保存重量数据;利用R语言工具进行数据分析,绘制统计图,验证数据是否符合正态分布。
在图片中识别称重数据,这在人工智能领域属于OCR文字识别技术,需要两方面的功能——文本检测和文字识别,识别过程如图1所示。
文本检测和文字识别都有非常成熟的算法可以使用,如DBNet场景文本检测算法、CRNN文字识别算法等。这些算法经过不断改进,已经广泛地在各种文字识别项目中应用。PaddleOCR是一个开源文字识别工具库,整合了多种优秀算法,其基于PaddlePaddle深度学习框架开发,具有识别率高、识别速度快的优点,能满足本次实验的需求。
PaddleOCR有多种语言通用识别模型,可以直接用于文本检测和文字识别,但这些模型不能用于本实验项目,因为这些模型会把电子秤上印有的商标文字、功能说明文字识别出来,识别结果会出现大量与数值无关的文字。此外,电子称显示屏的数字并不是印刷体文字,在使用通用文字识别模型时,识别结果的正确率会偏低,导致数据不准确。所以,使用PaddleOCR必须训练出符合实验项目需要的文本检测和文字识别模型。
● 实验过程
实验过程由三个环节组成,分别是制作模型训练样本集、训练文字识别模型和使用模型进行推理,如图2所示。
1.准备训练样本
训练样本的准备是人工智能项目首先要完成的部分,也是最耗费人力的工作。样本的数量和质量直接影响模型的训练效果,因此要有足够的耐心,认真完成。
首先用电子称给小物件称重,小物件可以是U盘、笔、硬币等,并在称重时拍照。通过给单个物件或者两个、三个等不同组合的物件称重,采集不少于500张图片,再用图片处理软件将图片处理为960×960像素。所有图片复制两份,分别放入两个文件夹,一份用于制作文本检测样本,另一份用于制作文字识别样本。
(1)文本检测样本制作
打开图片标注工具PaddleOCRLabel,点击“矩形标注”,给每张图片中显示屏里面的数字进行标注。标注框要緊贴数字边缘,不要随意扩大或缩小范围。标注完毕,导出结果保存在图片文件夹内,文件名为Label.txt。
(2)文字识别样本准备
用图片处理软件把液晶屏的数字裁剪出来,注意控制裁剪范围,仅保留数字。然后在图片文件夹内创建一个文本文件List.txt,内容是图片文件名和数字内容,中间用“Tab”键隔开。此文档作为标注文件使用。
此外,还要创建一个词典文件。在文件夹PaddleOCR/ppocr/utils内创建文本文件lcdnumber_dict.txt,内容是数字“0~9”以及小数点“.”,每个数字占一行。
2.训练AI模型
训练AI模型需要耗费很长的时间,根据计算机配置的不同,以及样本数量、训练次数设置等影响因素,训练时长从一两个小时到几十个小时不等。
(1)文本检测模型训练
文本检测模型训练使用的配置文件为PaddleOCR/configs/det/det_mv3_db.yml。修改配置文件,把epoch_num设置为100,其他各项根据计算机配置等实际情况修改。
样本图片和标注文件Label.txt放入文件夹PaddleOCR/train_data/det/。
文件准备妥当,开始训练模型,命令如下:
python tools/train.py -c configs/det/det_mv3_db.yml
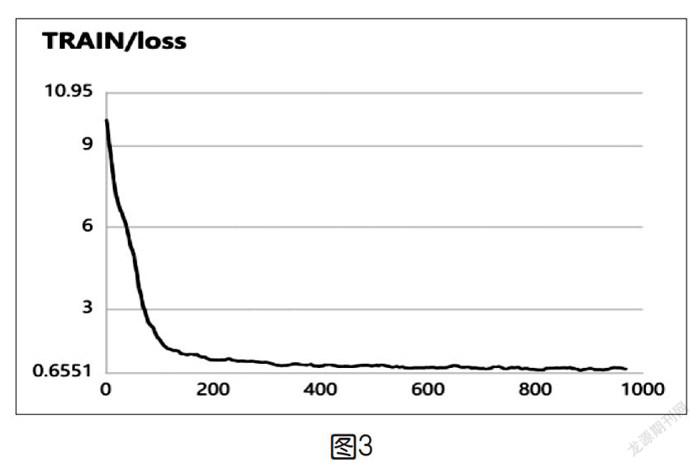
训练开始后观察Loss的变化,正常情况下Loss数值下降速度从快到慢。除了观察数字变化外,还可以使用VisualDL工具用图形方式观察Loss变化曲线(如图3)。
当发现Loss曲线下降平稳后,可以考虑终止训练,避免模型训练出现过拟合,导致训练效果下降。训练得出的模型保存在PaddleOCR/output/det。
(2)文字识别模型训练
文字识别模型训练使用的配置文件为PaddleOCR/configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml。修改配置文件,把epoch_num设置为100;词典文件路径character_dict_path设置为./ppocr/utils/lcdnumber_dict.txt;其他各项根据计算机配置等实际情况修改。
样本图片和标注文件List.txt放入文件夹PaddleOCR/train_data/rec/。
开始训练模型,命令如下:
python tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml
训练开始后除了要观察Loss的变化外,还要留意acc的变化。正常情况下训练一段时间后acc数值才开始上升,最后稳定在1附近,如图4所示。
当acc上升到1附近,而loss下降并稳定后就可以终止训练,避免模型过拟合。模型文件可在文件夹PaddleOCR/output/rec内找到。
3.使用AI模型推理
训练完成,可以先用几张图片测试效果。测试用图片可以从训练样本里挑选,也可以重新拍摄或者使用小番茄称重图片。
文本检测测试图放入PaddleOCR/train_data/det/test/文件夹;文字识别测试图放入PaddleOCR/train_data/rec/test文件夹。
(1)文本检测模型推理
测试命令如图5所示。识别结果可在./output/det/det_results文件夹内查看。
(2)文字识别模型推理
测试命令如图6所示。识别结果将显示在终端屏幕上。
(3)文本检测文字识别串联推理
以上模型只能实现单一的文本檢测或者文字识别,要实现小番茄称重数据的采集,还需要将两个模型转化为推理模型,然后串联使用。首先将两个模型转为推理模型。文本检测模型转换推理模型命令如图7所示,文字识别模型转换推理模型命令如图8所示。
把小番茄称重图片放在PaddleOCR/doc/imgs/,用两个模型串联起来推理,命令如图9所示。
识别结果保存在PaddleOCR/inference_results文件夹内。
● 数据分析
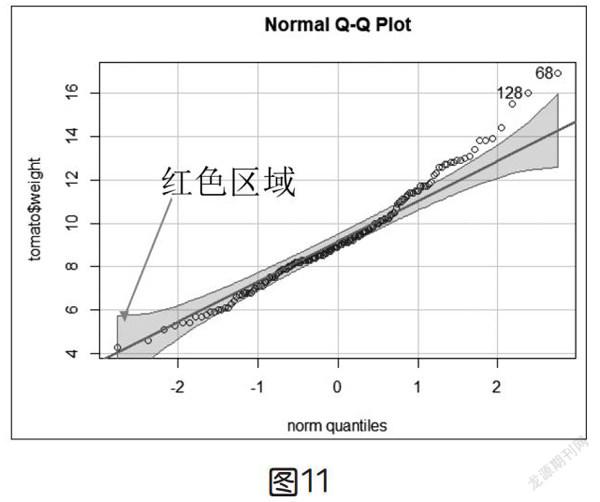
检验小番茄的重量是否符合正态分布,这里使用了R语言进行检验。比较直观的方式是用R语言绘制图像,如频数分布直方图(如下页图10)和QQ图(如下页图11)。
1.绘制检验图形
导入小番茄称重数据后,先绘制频数分布直方图,命令如下页图12所示。
从图10可见,数据呈现了中间高两边低的钟形曲线,基本符合整体分布的特征。接着,再绘制QQ图,命令如下页图13所示。
图11中的红色区域为95%置信区间,蓝色散点为实际数据。大部分数据分布在置信区内,虽然有少部分数据在置信区外,但实际中很少有完美的分布图,可以认为数据符合正态分布。
2.正态性检验
除了通过观察图形的方式判断数据的正态性以外,还可以通过Shapiro-Wilk正态检验来判断。
命令:shapiro.test
(tomato$weight)
检验结果如图14所示,从结果得知P值大于0.05,可认为数据符合正态分布。
● 总结
在这一实验中,笔者花了大量的时间准备样本和训练模型,训练出来的模型除了识别小番茄的称重数据就没有其他用途了吗?能不能借助这种方法进行数据采集呢?答案是肯定的。在工厂等生产环境中,利用人工智能技术识别仪器数值已经普及。如果多采集一些仪器的仪表盘图片,做成样本,重新训练出模型,这样的模型能够识别出更多类型的仪器读数。把模型部署到手机、摄像头等设备,就能够实现拍照、录像自动记录数据的功能了。至于怎样进一步深入使用基于深度学习的OCR技术,在后续的学习中再探讨研究。
