低空遥感地质灾害目标数据集的制作及测试
2022-06-05詹总谦黄兰兰张晓萌
詹总谦 黄兰兰 张晓萌 刘 异
1武汉大学测绘学院,湖北 武汉,430079
基于机器学习方法的遥感图像灾害目标检测是灾害分析中的研究热点之一。这类方法的初期模型有支持向量机(support vector machine,SVM)[1]、模式识别技术和监督分类方法[2]、联合视觉词袋(bag of visual words,Bo VW)与概率隐含语义分析(probabi⁃listic latent semantic analysis,PLSA)的滑坡场景分类方法[3]等。这些方法通常先进行预处理并构建灾害目标样本库,然后设计目标特征提取方法,最后选取分类器模型进行训练和测试。由于无法充分利用样本信息,并且所选特征描述符的稳健性不高,该类方法还不足以创建用于灾害损伤检测的强泛化模型。
深度学习[4,5]已在许多应用中取得了突破性进展,其中,卷积神经网络(convolutional neural net⁃work,CNN)在目标识别领域表现优异[6⁃8]。与基于像素和面向对象的技术[9,10]相比,深度学习方法提供了对灾害目标特征相对高级的解释,且减少了特征提取前的诸多繁琐的预处理步骤,部署训练好的模型便可实现目标的快速检测。文献[11]中利用Google Earth影像制作滑坡样本数据集,并搭建了一个包含3个卷积层和两个全连接层的CNN,经训练后用于遥感图像滑坡区域的自动提取。相比于传统方法,基于深度网络的方法使影像信息得到了充分利用,提取的精度和召回率有明显改进。文献[12]利用无人机影像制作火灾样本数据集,采用深度学习方法进行训练和测试,判断遥感影像中是否存在火灾,测试精度达85%。文献[13]提出一种被命名为wavDAE的基于深度学习的光学遥感图像滑坡识别方法,先利用Google Earth影像制作样本,并搭建一个具有多个隐藏层的深度自动编码器网络进行学习,再输入softmax分类器用于分类预测,效率和准确性优于SVM和人工神经网络(artificial neural net⁃work,ANN)等先进分类器。文献[14]对灾情建筑物的受损情况进行了检测,使用独立的CNN特征或结合3D点云特征来构建分类框架,并基于迁移学习策略训练模型,实验平均精度达到85%。
虽然上述研究取得了一定效果,但是深度模型的表征能力高度依赖训练数据的多样性。然而,目前还没有完整公开的倒塌房屋、滑坡和泥石流等多种灾害目标数据集(disaster event dataset,DED)。上述基于深度学习的灾害目标检测方法均需要自己制作数据集,即在不同的实验设置下对不同数据集进行评估,难以比较各种深度学习方法的优劣。另一方面,现有方法主要使用的数据为Google Earth影像,该类影像经过处理后,光谱特征和空间分辨率等发生变化,从而导致影像与实际应急场景中包含的信息有差别,实用性不足。当前,无人机低空遥感已成为增强应急测绘现场勘测能力的重要手段,在灾情快速分析方面发挥了重要作用。相比于卫星影像,无人机影像的获取更为快速、便捷,分辨率更高。因此,制作实用多样化的无人机影像DED具有重要的应用价值。
针对上述问题,本文重点介绍了一种无人机影像地质DED的制作方法。该数据集包含坍塌房屋、滑坡和泥石流3种典型地质灾害目标,共有16 535个标注对象。本文使用Faster R⁃CNN[15]模型和k⁃means聚类优化方法对其有效性进行了实验评估。
1 DED
1.1 制作背景
现今,机器学习、深度学习方法仍依赖于大量的标注数据。已经有很多公开数据集可用于算法的开发、训练、验证以及模型性能的比较。其中,大多数数据集与场景目标识别有关,通常被应用于人脸识别、行人检测、车辆检测、日常物体识别等。这些数据集中的图像基本都在与目标较近的拍摄距离(几米或几十米)获取,与拍摄距离动辄几百米甚至几千米的遥感影像有很大区别。遥感领域也已经有不少公开或非公开的数据集,非公开的有IKO⁃NOS卫星图像数据集[16]、SPOT图像数据集[17]等。一些常用公开场景数据集和遥感数据集的信息如表1所示。
由表1可知,如ImageNet和COCO等挑战赛常用的数据集的规模都很大。然而,它们在实际中不适用于目标的自动识别。这些数据集关注的是物体的多样性和类别的数量,其感兴趣目标大多占据图像主体。遥感数据集则更关注地物目标的大小,图像通常来自不同的传感器,且包含噪声,多光谱影像资源丰富。在实际应用中,自动检测更多情况下是检测小目标。现有的遥感数据集大多规模较小、尺寸单一,数据过于理想化,导致数据集之间的泛化程度较低。且它们或只用于分类,或只针对船只、飞机等普通场景目标,并未涉及坍塌房屋和滑坡等灾害目标,无法被直接应用于灾害目标的自动监测。
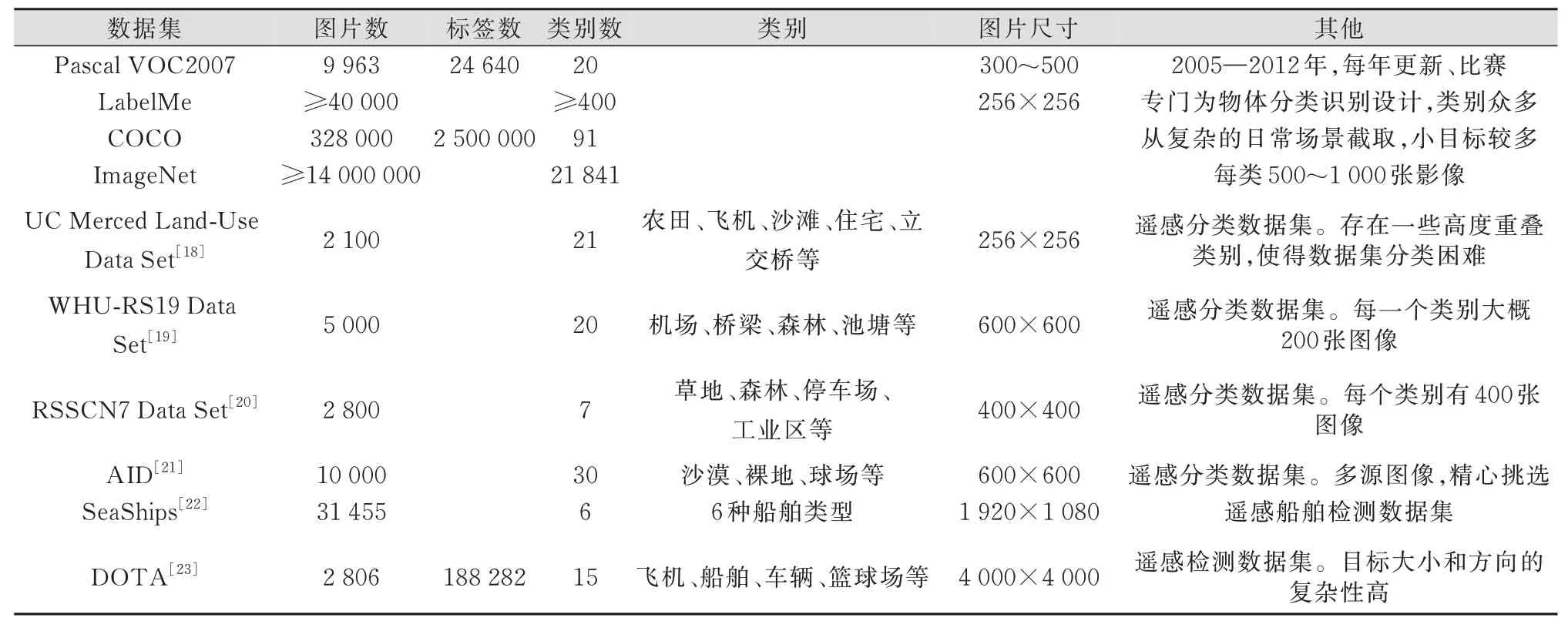
表1 常用场景数据集和遥感数据集的信息Tab.1 Information of Commonly Used Scene Datasets and Remote Sensing Datasets
针对坍塌房屋、滑坡和泥石流这3类常见地质灾害的数据集要符合地质灾情现场精准速报系统的模型训练要求;不同灾害目标的数量及类型足够多样化,背景应尽可能复杂多变(平原、山区、高原、荒地等不同地貌),目标要大小不一;且数据集标签的规模要相对较大。
无人机低空探测获取的图像中,感兴趣目标一般都很小;相机分辨率不高或无人机抖动等会产生图像模糊,导致目标难以分辨;不同地区发生的地质灾害,加上太阳光照和四季变化,使得影像有着复杂多变的背景;可用的灾害数据资源相对缺乏。这些因素导致数据集制作和灾害目标检测面临诸多挑战。灾害目标数据集在应急救灾系统中的关键应用决定了其信息结构和实用价值与其他目标检测数据集显著不同。本文充分考虑了上述难点和挑战后,制作了首个版本的地质DED,为后续该类数据集的制作提供范例。该数据集目前还属于内部数据集。
1.2 制作方法
1)数据来源。本文从国内不同的地质灾害地区收集了大量无人机影像,约1万张,包括汶川、舟曲、玉树等地区。这些无人机影像拍摄的相对高度在300~500 m之间,地面分辨率在10~15 cm之间。按照数据集的图片质量、重叠度等要求挑选出最具代表性的灾区影像。这些影像来自地形各异、气候不同的地区,有着不同季节和光照的成像条件,增加了类别内部的差异性。表2展示了DED的原始影像信息。
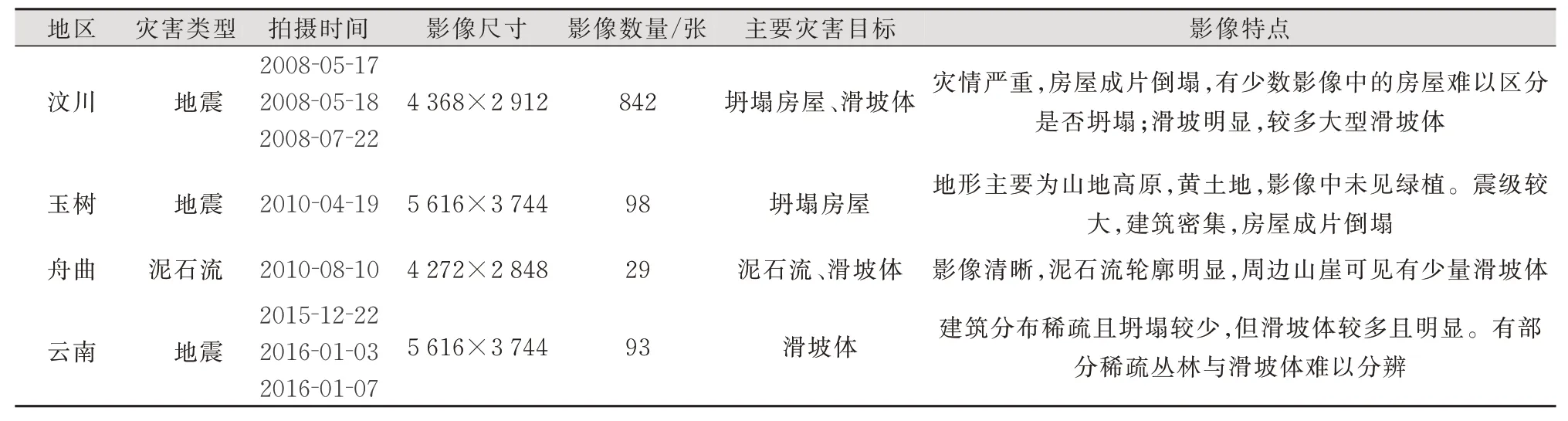
表2 DED的原始影像信息Tab.2 Original Image Information of DED
2)格式选择。模式分析、统计建模、计算学习视觉物体分类(pattern analysis,statistical modelling and computational learning visual object classes,PASCAL VOC)[24]挑战赛是视觉对象识别和检测的一个基准测试,提供了检验算法和学习性能的标准图像注释数据集和标准的评估系统。现今的许多深度学习模型均在VOC数据集上进行训练和测试,可参考性强。因此,本文制作DED时参照了PASCAL VOC数据集的格式。
3)标签制作。该过程主要为标记图像中所有对象的类别和位置,每个标签对应包含该目标的最小矩形框,位置信息存储为矩形框的4个角坐标。最小矩形框代表了目标对象的真实位置,是模型训练及学习阶段的参考以及评估算法性能的比较参考,因此这些标签应尽可能准确。手动标记图像中的目标是一个繁琐而缓慢的过程,目前已经有一些工具可以帮助完成这项任务。本文使用的是label Img工具,它提供了一个图形用户界面,用户可以通过菜单工具勾画和调整边界框,随时改动或完善标签,是一种便捷的标注工具。
考虑到无人机影像的重叠度太大,或者存在部分影像无法使用的情况,且由于很多深度模型已经具备基本的数据增强功能,因此,本文从中挑选出了最具代表性的影像1 062张,最终标注了16 535个标签。新数据集包含坍塌房屋、滑坡体、泥石流3个目标类别。每种灾害目标类别的标签数目差别很大,且以小目标居多。各类别的一些标注样本如图1所示。

图1 3种典型地质灾害目标的样本示例Fig.1 Sample Images of the Three Typical Geological Disaster Events
1.3 数据集特点
1)影像尺寸大。与日常场景的目标数据集相比,无人机影像尺寸较大。常规数据集(如PASCAL VOC)中的大多数图像尺寸不超过1 000×1 000,而DED中的图像尺寸在2 800~5 700之间,这些大尺寸图片作为网络的输入给深度模型的训练及优化带来了一定困难。
2)标注方式的差异。本文对灾害影像的标注方式不同于普通场景图片,不能同等定义最小矩形框。日常场景图片中的目标大多为有规则形状的单个目标,如一只小狗或一张桌子;灾害目标则是成片而无特定形状的,有些目标区域散乱不连续,不可明确区分哪块区域属于一个灾害目标。再者,本文任务是检测出灾害目标的大致位置,不需要对坍塌房屋进行计数,因此,对于成片的坍塌房屋或滑坡,有时会采用几个目标框进行标注。类别实例的大小范围很广,小到几个像素,大到600像素以上,实例标签的纵横比差别也很大。
3)影像和目标的特殊性。无人机影像分辨率高、细节多、数据大,对硬件设备的需求更高;信息量大,特征提取更为困难。3种目标都呈片状或散落状,轮廓毫无规则可言。
2 目标检测方法
本文采用Faster R⁃CNN[15]方法进行实验。Faster R⁃CNN是一个典型的基于深度学习的目标检测模型。自出现以来,Faster R⁃CNN的影响力越来越大,后续很多目标检测与分割模型都受其启发,包 括single shot multibox detector(SSD)[25]、基 于 区域的全卷积网络(region⁃based fully convolutional network,R⁃FCN)[26]等。Faster R⁃CNN已经不是最简单、最快速的目标检测方法,但其出现频率和使用表现仍位列前茅。目前,Faster R⁃CNN仍是很多目标检测模型的主要思想。
Faster R⁃CNN的构建分为两个阶段:①区域建议网络(region proposal network,RPN),与之前的R⁃CNN及Fast R⁃CNN[27]模型相比,RPN可谓Faster R⁃CNN模型的主要创新点。它用RPN快速神经网络代替了之前慢速的选择搜索算法,利用CNN实现候选区域生成这一关键步骤,加速了整个模型的训练进程。输入图像先由一个基础CNN作为特征提取器处理,并将某些选定的中间卷积层得到的特征图输入RPN进行候选区域提取,整个RPN则是用完全卷积的方式高效实现。②将阶段①得到的候选区域输入到一个本质上是Fast R⁃CNN的检测器,其与前面的RPN共享特征以构成统一网络进行学习,再添加池化层和一些全连接层,连接softmax分类器和边界框回归器。分类器对边框内容进行分类,或者舍弃它并将其标记为背景;边框回归器负责调整边框坐标,使之更好地包含目标。获取具备类别标注的目标检测框后,还要进行非极大值抑制后处理,以实现边框调整和简化。其中,基础CNN的选择和区域框的设定对检测结果都有很大影响。
VGG16[28]和残差网络(residual network,ResNet)[29]是常见的两种基础CNN。VGG16采用连续的几个3×3的卷积核代替较大卷积核,这样多层的非线性层就可以增加网络深度,以学习更复杂的模型,并且参数更少。VGG16使用了一种“多次重复使用同一大小的卷积核来提取更复杂和更具表达性特征”的块结构,这种结构在VGG之后被广泛使用。现有研究表明,网络深度有着至关重要的影响,在确保没有过拟合的前提下,一般网络越深,可获得的准确度越高,但更深的网络却存在梯度消失、爆炸或退化的问题。ResNet的出现很好地减轻了深度网络的退化问题,从而能够训练更深的网络。ResNet设计了一种残差模块,该模块在输入和输出之间建立直接的连接,这种新增的层只需要在原来的输入层基础上学习新的特征,即学习残差。因此,残差结构既不增加计算复杂度,又不增加模型的参数量。目前的50、101、152层的ResNet已被广泛使用,不仅没有出现退化问题,还显著降低了错误率,同时保证了较低的计算复杂度。
Faster R⁃CNN中的RPN在最后特征图层每个元素的对应位置会生成9个不同大小和尺寸的区域框,称为Anchor。这些Anchor的尺寸和比例都是预先设定好的,没有根据数据集中的目标大小设置,导致其难以适用于各种类型的目标检测数据集,并且训练和检测的速度也会受到影响。针对此问题,已有不少研究将k⁃means聚类算法用于优化Anchor的尺寸和大小的设置,使之更符合特定类型的数据集。k⁃means目前在目标检测领域的应用主要是YOLOv2及其改进版本。比如,YOLOv2用的是k⁃means聚类[30],而YOLOv3用的是k⁃means++聚类[31]。应用于目标检测时,k⁃means算法并不使用标准的欧氏距离,而是使用交并比(intersection over union,Io U)度量,以避免大区域框比小区域框产生的错误多。在Faster R⁃CNN模型中,可以使用k⁃means对训练集进行聚类分析,得到目标框的k个聚类中心,使用这k种聚类中心的尺寸代替Anchor原本设定的9个框的尺寸,也可以根据聚类结果和复杂度更改Anchor的数量。
3 实验及分析
3.1 实验设置
为了检验所提出的DED在灾害目标上的检测功能并评估其应用效果,本文使用Ubuntu16.04环境下的Tensorflow框架,在单个GTX 1070显卡上重新训练和评估Faster R⁃CNN模型[32]。采取迁移学习中的模型迁移方式,使用VGG16、Res Net⁃50、ResNet⁃101 3种基础网络来微调训练Faster R⁃CNN模型,检验不同深度的网络对于DED的适用性;基于k⁃means算法对训练集进行聚类分析,根据聚类结果修改Faster R⁃CNN中固定设置的Anchors尺寸。本文采用平均精度(average precision,AP)、平均精度均值(mean AP,mAP)指标和直接观察模型对新影像的预测结果进行评价。
3.2 结果及分析
模型经训练集训练后,用测试集检验模型的精度。测试结果的mAP值统计结果见表3。表4为3种目标检测数据集在相同模型下的mAP值比较。

表3 基于DED训练不同深度网络的测试结果Tab.3 Test Results of Different Deep Networks Trained by DED
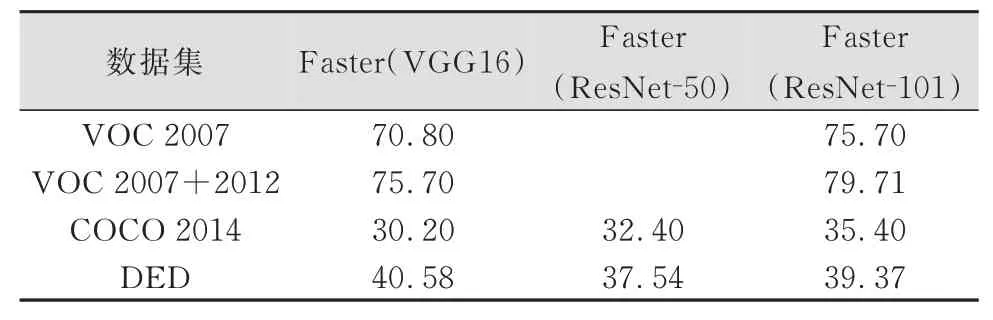
表4 不同数据集在相同模型下的mAPTab.4 mAP Values of Different Datasets Obtained by the Same Model
数据是决定模型学习结果上限的最核心要素。一般而言,在训练数据足够多的情况下,网络越深效果越好。根据本文实验结果,DED的规模量级还不足以训练好ResNet,出现了过拟合现象,其mAP值比使用浅层网络的VGG16低。由于3种灾害目标的标签样本数量不同,它们在不同深度的网络中的训练效果也不一样:随着网络层数的增加,滑坡体的检测精度越来越高,而泥石流的检测精度越来越低。在DED中,含有泥石流样本的影像是最少的。
从表4可以看出,DED训练模型后得到的mAP值与VOC数据集相差较远,而与COCO数据集相比则略有优势。这3种数据集的目标内容和应用场景不同,三者的图片及标签举例见图2。COCO数据集包含91类目标,小目标较多,且包含复杂的日常场景,因此其mAP值最低。DED的目标形状特殊,很多时候需要分成多个矩形框进行标注,这与VOC及COCO的日常场景目标可以逐个标注的方式不同,而精度评价指标则使用相同的IoU和mAP计算方式,本文认为这是导致DED的mAP值低的主要原因。再者,多个矩形框标注零散且片状分布的目标,模型会因为非极大值抑制而过滤其中几个预测框,导致出现一些漏检,最终的检测率降低。模型原始设置的Anchor尺寸也不适合DED,因此,本文用k⁃means对训练数据集进行聚类,基于聚类结果更改了Anchor尺寸设置,使之更符合DED标注框的大小范围,mAP提高了2.84%。

图2 示例图片和标签Fig.2 Sample Images and Annotations
模型经DED训练后,使用新的影像进行预测,预测结果包括目标定位框、目标分类标签以及每对标签和边框所对应的概率(即得分)。部分预测结果见图3。图片中的大部分目标都可被检测出来,且得分较高,能达到定位检测出绝大部分灾害目标的效果。其中,使用k⁃means聚类结果优化Anchor尺寸设置的Faster R⁃CNN+VGG16模型的预测效果更佳,漏检率更低、目标框的平均得分最高。可见,本文制作的DED是可用、有效的,而且相较于其他灾害目标检测方法,基于深度模型的方法检测目标快速高效,可在后续研究中应用于低空无人机在线检测灾害目标系统。
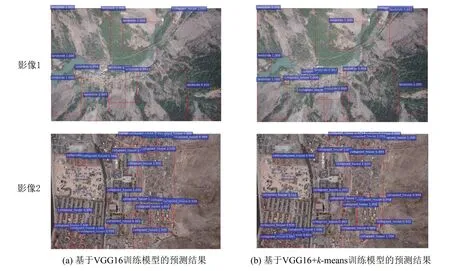
图3 两种训练模型的预测结果示例Fig.3 Examples of Prediction Results Obtained by Two Training Models
3.3 讨论
综上,基于深度网络进行灾害目标检测是可行的,本文制作的DED也可成功用于训练深度模型。在检测速度方面,基础网络的深度差别以及每张影像包含的目标个数不同,导致耗时有差异,但总体相差不大,每张影像的检测耗时平均值在0.4 s左右。本文未对检测速度展开分析,主要讨论了检测精度。
经DED训练的模型,其测试精度mAP值较低,原因在标签制作的介绍中已有分析,灾害目标呈片状或散乱分布,制作标签时难以确定目标边界。多个矩形框标注一片区域的方式导致无法用普通场景的目标检测评价指标来衡量本文模型质量。图4为预测结果图和人工标注图,按照预测框与真实标签的IoU值来计算精度,结果确实会很低。而目视判读发现,预测结果已经基本满足定位受灾区域这一应用需求。对于这些成片且零散分布的灾害目标,存在少量漏检是正常的,也难以通过数个目标框就将大片的目标定位完整。本文预测了50张新图片,将预测结果与目视判读进行比较,发现绝大多数目标均能被检测出来,实现正确分类和大致定位,没有出现成片目标的漏检,尺寸较大目标的检测效果鲁棒性较好。
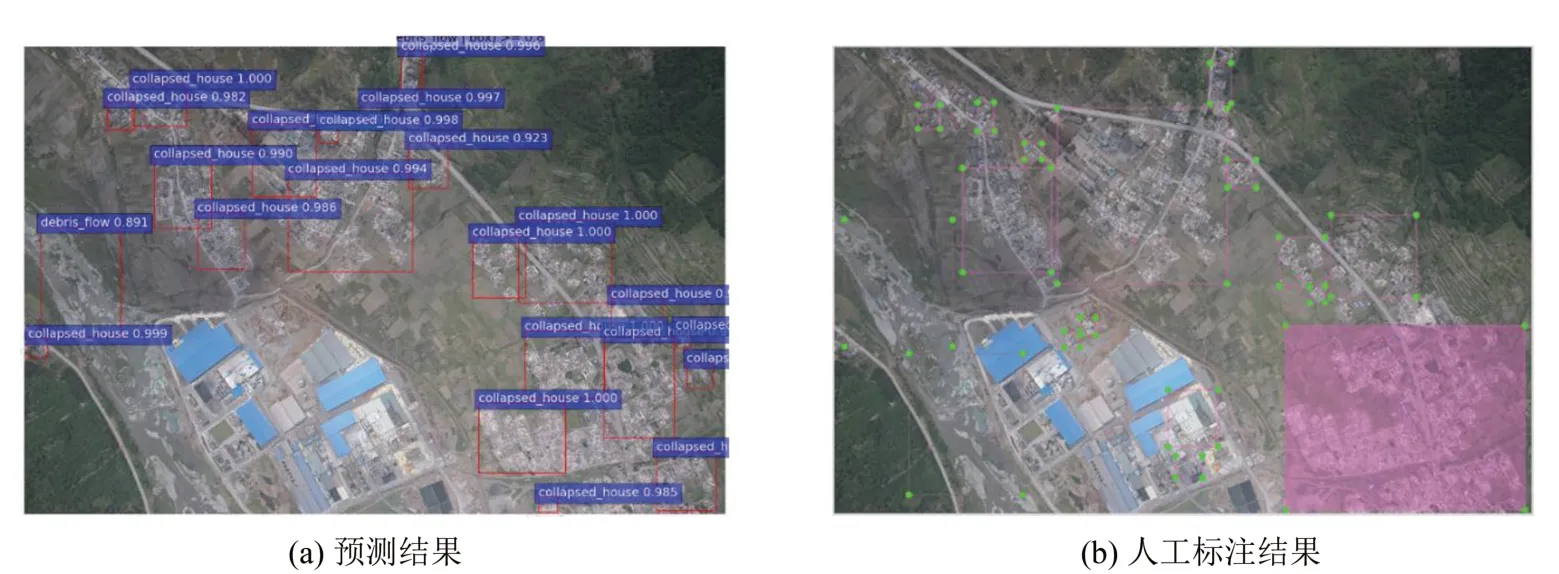
图4 预测结果与人工标注结果的比较Fig.4 Comparison of Prediction Results with Manual Annotation
模型预测时,少数情况下也出现了错检,如图5所示。错检发生在背景与目标极为相近的情况下,这在实际应用中也会遇到。尤其是在地形复杂以及影像模糊时,人眼难以区分目标与背景,进行标注也极为困难。灾害目标的特殊性导致了其检测结果的多样性和分析问题的困难性。
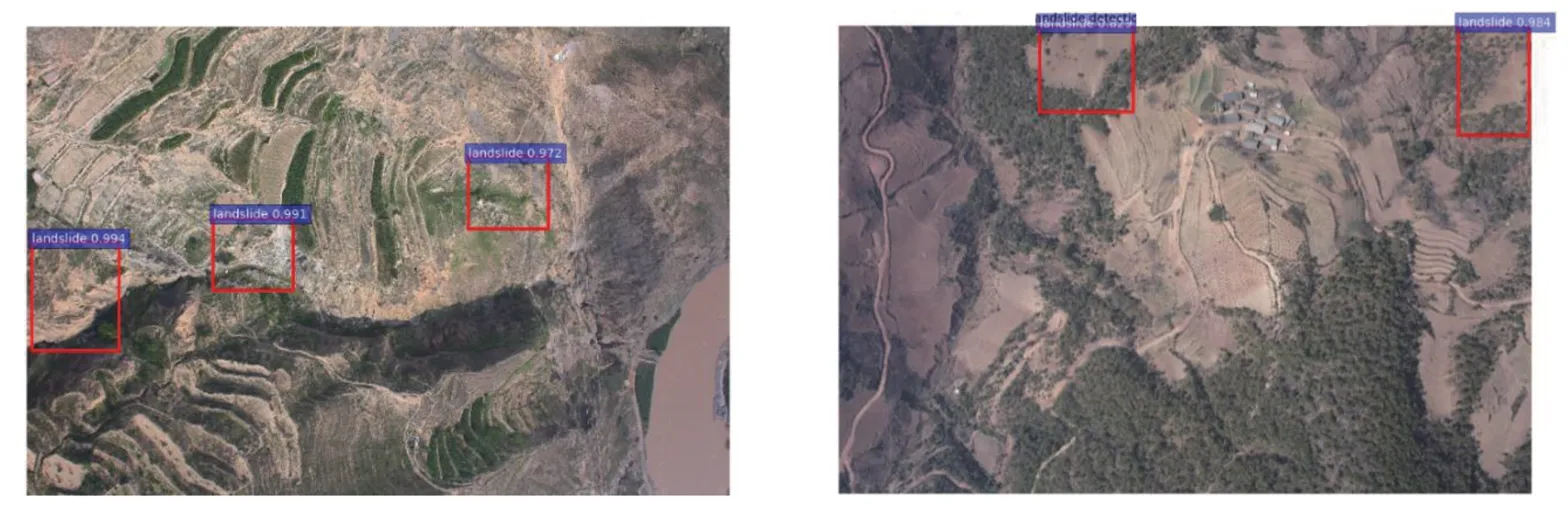
图5 被误检测有滑坡的图片Fig.5 Pictures That Were Erroneously Detected to Have Landslides
深度模型的训练是一个非常复杂的过程,包括各类参数的设置和初始化策略,受到硬件条件的限制以及数据集的显著影响。针对不同的应用场景,需要制作特定的数据集,并结合实际应用来分析和评价数据集的质量和模型的适用程度。使用数据集训练深度模型后,要达到的实际效果是能快速检测灾害目标的类别并定位出其大致位置。DED在精度上低于日常场景数据集,但其实际效果是明显的。由预测结果可知,利用DED微调出来的模型已经能将绝大多数灾害目标检测出来,分类正确且得到大致定位,虽有小部分漏检,但错检率极低,说明基于DED训练Faster R⁃CNN模型是有实际效果的。
4 结束语
本文收集了大量无人机影像,根据性质、组成、用途三大要义制作了首个版本DED,包含坍塌房屋、滑坡体和泥石流三大常见地质灾害目标,并基于Faster R⁃CNN模型对其进行验证。实验结果表明,通过DED训练的模型能成功预测出灾害目标,目标分类及定位效果较好。对比实验结果表明,DED对不同深度的网络模型的训练效果有差异,使用k⁃means聚类结果优化模型Anchor的尺寸设置后,检测精度明显提高。受限于无人机影像和灾害目标的特殊性,实验结果精度不够高。后续研究会继续增加目标影像数据,同时细化探究灾害目标与日常目标的区别,改善标签制作过程。再针对这一类无人机灾害目标数据集对网络模型进行改进,使其对灾害目标的检测准确度更高、速度更快,以期能真正应用于应急救灾系统。
