大视场单镜片计算成像系统图像分割学习方法
2022-06-03纪轶男李海峰
纪轶男,李海峰,刘 旭
浙江大学光电科学与工程学院,浙江 杭州 310027
1 引言
作为融合光学、算法、电子学、信息处理等学科于一体的新兴领域,计算光学利用对所有元件的并行设计和联合优化来提升光电系统的处理能力,在过去20 年中取得了非常大的进展并产生了诸多分支[1-2]。其中一个较为典型的就是基于参数化光学和图像处理联合优化的端到端成像,该技术在近几年中成功应用到了扩展景深和超分辨率成像[3]、单目深度估计[4-6]以及图像分类[7]上。
除了端到端成像外,还有一个热门研究方向就是基于深度学习的图像增强[2]。深度学习作为近几年大热的研究课题,主要解决从数据中自动获取有效特征表示的问题,即贡献度分配问题。而由于神经网络的误差反向传播算法能够较好地解决该问题,故深度学习主要采用神经网络模型[8]。
目前常用的典型神经网络模型有2014 年Goodfellow 等人[9]提出的生成对抗网络(generative adversarial nets,GAN)和2015 年Ronneberger 等人[10]提出的U-Net 卷积神经网络。2017 年,Zhang 等人[11]提出了一种迭代非盲反卷积的全卷积网络,给出了较好的图像恢复任务数据驱动方法。同年,Sinha 等人[12]首次证明了深度神经网络(deep neural networks,DNN)可以解决计算成像系统的图像恢复问题,并用网络恢复出了无透镜系统成像结果的相位信息。2018 年,Kupyn 等人[13]提出了一种基于有条件的GAN 和内容损失的端到端学习方法用于运动去模糊,并在各种评价标准中获得了比前人更好的表现。2019 年,Huang 等人[14]开发了一个基于U-Net 架构的深度神经网络作为监控系统的预处理模块,并在不均匀光源场景下保障了监控目标检测的准确性。2020 年,Jung 等人[15]提出了一种基于全局和局部残差学习的先进U-Net 模型,并在恢复复杂退化图像方面具有以往方法无法比拟的性能。同年,Jin 等人[16]提出了一种基于GAN 和多尺度特征融合的图像恢复算法,成功在提升图像复原精度的同时生成了更逼真的复原图像。2021 年,Li 等人[17]提出了一种基于CycleGAN 的终身学习框架,实现了连续多任务下的图像恢复。
然而,以上方法都是在较小的视场下所提出,往往忽略了大视场的问题。鉴于这种情况,2019 年,Peng 等人[18]用特别设计的菲涅尔单透镜结合新的学习架构(变体U-Net+GAN+知觉损失),实现了对大视场单镜片成像结果的高质量恢复。该工作的主要贡献是借助于深度学习降低了对成像透镜光学性能要求,从而可以实现光学成像系统的低成本化。但该方法对成像系统也提出了新的要求,即需要光学系统的PSF在各视场中尽量保持一致。虽然作者在设计时考虑到了PSF 的均一性问题,但做到全视场PSF 完全一致依旧比较困难,并且最终设计出来的透镜也没有完全达到PSF 一致性的要求。
本文基于光学系统的对称性,以及PSF 从中心往边缘视场逐渐劣化的特点,通过对图像的环形分割、学习以及图像融合,对具有相近PSF 的环带图像进行单独学习训练,从而提高了图像恢复的质量。
2 实验原理
2.1 光学系统成像过程与神经网络主要任务
光学系统在成像过程中经常会因为各种内在或外在原因造成图像的模糊和退化[19],其中一个最基本的模型就是假设点扩散函数(point spread function,PSF)是线性空间不变的,其具体表示为
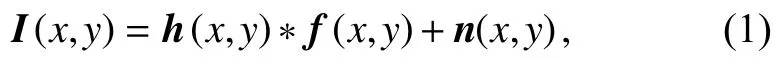
其中:I(x,y)为最终得到的低质量图像,h(x,y)为系统PSF,∗表示卷积,f(x,y)为原始清晰图像(可以将实物场景看作一张非常清晰的原始图像),n(x,y)为背景噪声。
对于网络而言,其主要任务有两点:学习出系统PSF 并对输入图像反卷积PSF,以及通过网络学习尽可能多地消除背景噪声。经过对Peng 等人成果[18]的复现,发现其所用的网络算法对噪声的消除效果非常不错,可改动的地方不大,所以本文将改动的方向瞄准了PSF。
2.2 针对大视场不同PSF 的分环处理
对于大视场光学系统而言,在不同视场参数下其PSF 会呈现不同的形状,即整个系统没有统一的PSF。而由上一小节得知,网络算法对输入图像的要求恰恰是需要一个固定的PSF。针对这种情况Peng等人采用的是混合PSF[18]方法,将不同视场下的PSF 混合为一个整体的PSF。但这种混合的PSF 无论对中心视场还是对边缘视场来说都是不准确的,这势必会造成网络学习中的PSF 误差,从而对恢复图像质量产生影响。
图1 为Peng 采用了混合PSF 处理得到的不同视场下的PSF 图。整个视场的PSF 主要由约10°视场角以内的圆形PSF 和约10°视场角之外的径向拖尾状PSF 构成。虽然10°以外的PSF 呈现一定的径向拖尾状,但PSF 的平均半径要远大于中心视场圆形PSF。如果直接训练整张图像,边缘处较差的PSF 势必会影响中心区域的还原效果,故要提升图像恢复质量可以将图像先分割再训练。
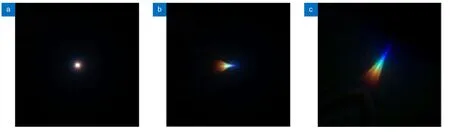
图1 不同视场PSF 放大图[18]。(a) 约10°以内视场PSF;(b) 约10°至30°视场PSF;(c) 约30°至53°视场PSFFig.1 Amplification of PSF with different fields of view[18].(a) PSF within about 10 degrees;(b) PSF about 10 degrees to 30 degrees;(c) PSF about 30 degrees to 53 degrees
经过上述观察分析,为了解决PSF 误差问题,本文采用了一种新的思路,即先将图像按视场环切,分为中心和边缘两个部分,再将这两个部分分别做成两个数据集,之后将两个代表不同视场的数据集分别输入各自对应的网络训练,最后将网络对两部分图像的恢复结果拼接到一起得到最终结果。具体流程如图2所示。
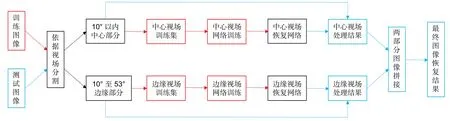
图2 新思路具体实施流程(红色、蓝色和黑色框分别表示训练、测试和二者共有的步骤,红色、蓝色和黑色箭头分别表示训练、测试和二者共有的流程)Fig.2 The concrete implementation process of the new idea(The red,blue and black boxes represent training,testing and the steps shared by them respectively,and the red,blue and black arrows represent training,testing and the processes shared by them respectively)
在分割过程中,为了防止图像拼接后接缝处留有暗环印记,本文采用了一种结合高斯函数的分割方式。对于一个宽度为m、高度为n的图像,首先生成两个与其等大的二维网格−宽度网格x取值范围,高度网格y取值范围,之后使用如下公式生成与图像等大的高斯强度网格:
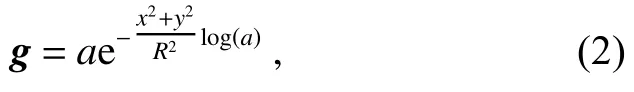
其中:g为 生成高斯强度网格,a为高斯函数高度,x和y分别为之前生成的宽度和高度网格,R为被分割圆形范围的半径。最后将图像与高斯强度网格相乘完成高斯分割,并可以通过大圆减小圆的方式得到对应不同视场的环形区域。
3 实验过程
实验用的菲涅尔透镜采用文献[18]所提出的方法设计,采用FLIR Grasshopper3 GS3-U3-123S6C 传感器和华硕PA32U 显示器构建实验系统。该系统中镜头视场角为53°,装载在传感器上,传感器距离显示屏约1.2 m,传感器像面中心点正对显示屏中心点,二者等高且相对无倾斜、旋转和俯仰角度关系。具体系统如图3 所示。

图3 整体硬件系统(红色方框内为传感器)Fig.3 Overall hardware system (sensors in the red box)
训练网络采用和文献[18]相同的变体U-Net+GAN+知觉损失网络架构,用Adobe 5K 数据集进行网络训练。我们首先从数据集官网下载了1772 张数据集图像,将其设定为三通道48 位、高度2160 pixels、宽度等比缩放的格式以适应显示屏大小和拍摄需要。在对系统进行相机标定和渐晕、背景校正后,对处理好的数据集图像进行投屏拍摄和配准,得到宽2972 pixels、高1910 pixels 的48 位深度PNG 格式数据集。具体步骤流程如图4 所示。
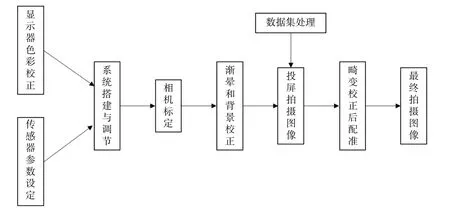
图4 图像拍摄配准流程Fig.4 Image shooting and registration process
取其中54 张作为测试集,将剩余的1718 张用2.2 节分割方法分为宽与高均为2544 pixels、对应视场为 10° 的中心部分,和与处理后数据集等大、对应视场为 10°~53° 的边缘部分,做成如图5 和图6 所示的训练集,分别放入各自的网络中进行训练。其中,所有图像均未加Gamma,网络训练采用的GPU 为英伟达GeForce 2080 Ti。

图5 中心部分数据集示例(左侧为拍摄图,右侧为原始图)Fig.5 Sample of center partial dataset (shot image on the left,original image on the right)

图6 边缘部分数据集示例(左侧为拍摄图,右侧为原始图),中间留洞原因详见后文Fig.6 Sample of edge partial dataset (shot image on the left,original image on the right).The reasons for leaving holes in the middle are detailed in the following article
待训练结束后,将之前处理好的54 张测试集图片和我们自己拍摄的36 张实景图片(21 张室内景物图,15 张室外景物图),同样用2.2 节的高斯分割方法分为中心和边缘两部分,将两部分送入各自对应的网络中进行恢复,最后将两个网络输出的结果拼接得到最终的恢复图像。
4 结果与讨论
由于测试集是和训练集一同拍摄处理的,所以分割后的两个部分与训练集对应部分大小、格式相同。因为本文采用的变体U-Net 网络不是端到端的网络,即网络会造成输出图像尺寸改变,所以经网络处理后两部分均保存为24 位深度,中心部分尺寸变为宽与高均为2304 pixels,边缘部分尺寸变为宽2816 pixels、高1792 pixels。将两部分图像拼接得到最终输出结果图,并将该结果与原始清晰图、未处理拍摄图和直接用Peng 等人[18]方法恢复图进行对比,得到如图7 所示结果。其中,7(a)为测试集的原始图像,7(b)为输入网络的模糊测试集图像,7(c)为用文献[18]方法得到的输出图像,7(d)为本文文方法得到的输出图像,所有图像均为24 位深度且都被加上了1.8 的Gamma值,原始清晰图和未处理拍摄图均被裁成和网络输出图一样的尺寸以便比较。由图可以看出,本方法恢复得到的图像质量更好,如从测试集第二组图中的树屋顶及茂密枝叶、第三组图中的细密树枝及树干以及第四组中建筑窗户等,能够看到新方法让图像细节更加自然和丰富,更接近原图;而原方法除细节缺失外,还存在一定程度的鬼影,如第二组树叶图像以及第四组黑背景下的条状物体。
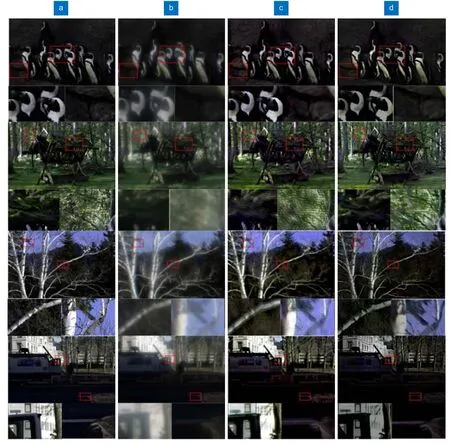
图7 测试集恢复结果示例,每张图片下方列出了用红框选出的两处细节。(a) 清晰图像;(b) 模糊图像;(c) 文献[18]方法得到结果;(d) 本文方法得到结果Fig.7 Sample of test set after restoration,with two details highlighted in red boxes are listed below each image.(a) Ground truth images;(b) Blurred images;(c) Results obtained by means of Ref.[18];(d) Results of our method
用单镜片拍摄实际场景得到宽4096 pixels、高3000 pixels 的48 位深度PNG 格式图像,分割后得到对应视场为10° 且宽与高均为3654 pixels 的中心部分和对应视场为10°~53° 且与原图等大的边缘部分。两部分分别经过各自对应的网络处理后均从48 位降到24 位,中心部分大小变成宽与高均为3584 pixels,边缘部分大小变成宽4096 pixels、高2816 pixels。同样,将两部分拼接得到最终输出结果图,并类似地将该结果与原始拍摄图和直接用文献[18]方法恢复图进行对比,得到如图8 所示结果。其中,8(a)为原始实拍图像,8(b)为用文献[18]方法得到的恢复结果,8(c)为本文方法得到的恢复结果,所有图像均为24 位深度且都被加上了1.8 的Gamma 值,原始拍摄图被裁成和网络输出图一样的尺寸以便比较。

图8 实拍图恢复结果示例,每张图上方或下方列出了用红框选出的一处细节。(a) 模糊图像;(b) 文献[18]方法得到结果;(c) 本文方法得到结果Fig.8 Sample of real pictures after restoration,with a detail selected in a red box is listed above or below each image.(a) Blurred images;(b) Results obtained by means of literature [18];(c) Results of our method
由图8 可以看到,实景拍摄恢复得到的图像的清晰度和原始方法相比也有较大提高,如第一组图中的毛衣细节,书脊文字细节,第三组草坪的细节以及第四组图中座椅套图案细节等,都有明显的提升。
为了更进一步证明本文的思路对该大视场单镜片计算成像系统起到了改进和优化作用,首先采用图像评价常用的峰值信噪比(peak signal to noise ratio,PSNR)指标,对拥有标准清晰图像的测试集进行评价。具体评价结果如表1 所示。

表1 PSNR 评价结果对比Table 1 Comparison of PSNR evaluation results
之后继续采用结合亮度、对比度与结构因素更贴近人眼观感的结构相似性(structural similarity,SSIM)[20]指标,对测试集进行评价。具体评价结果如表2 所示。

表2 SSIM 评价结果对比Table 2 Comparison of SSIM evaluation results
通过客观定量评价可以发现,虽然在PSNR 指标上用本文的方法得到的结果比用Peng 等人[18]方法得到的结果略逊一筹,这主要由于分割产生的渐变视场过渡区导致恢复图像的亮度相比原图发生了变化,但是通过比较可以发现图像在清晰度和振铃鬼影问题上相比之前结果确有改进提升,而在SSIM 指标上用本文的方法得到的结果比Peng 等人[18]方法要高出一大截。所以,总体来看本文提出的新思路确实改进和优化了Peng 等人[18]提出的大视场单镜片计算成像系统,让系统恢复图像的质量得到了提升,变得更适宜人眼观看。
5 结论
总体来看,本文提出的方法:先将图片按视场高斯环切分割,再分别训练对应各个视场的网络,最后将各个网络原始输出按视场关系拼接得到最终结果,应用在Peng 等人[18]提出的大视场单镜片计算成像系统上之后,其最终输出图像结果从主观人眼评价角度来看,更清晰、舒适,更贴近原始图像;从客观定量评价角度来看,在PSNR 相差无几的情况下SSIM 值有了较大的提升。本文最终成功实现了对Peng 等人[18]提出的大视场单镜片计算成像系统的改进和优化,成功让其整体图像恢复质量更上一层楼,使其恢复效果更适宜人眼观看。
虽然环形分割训练对图像的清晰度有提升作用,但针对边缘视场PSF 的径向发散特性,通过对图像进行一定的空间变换使PSF 的形状一致,可以进一步提高本文方法的训练效果,具体方法将在我们后续工作中进一步展开。
