残差混合注意力结合多分辨率约束的图像配准
2022-06-01张明娜吕晓琪谷宇
张明娜吕晓琪谷宇
残差混合注意力结合多分辨率约束的图像配准
张明娜1,吕晓琪1,2*,谷宇1
(1.内蒙古科技大学 信息工程学院 模式识别与智能图像处理重点实验室,内蒙古 包头 014010;2.内蒙古工业大学 信息工程学院,内蒙古 呼和浩特 010051)
医学图像配准在图谱创建和时间序列图像对比等临床应用中具有重要意义。目前,使用深度学习的配准方法与传统方法相比更好地满足了临床实时性的需求,但配准精确度仍有待提升。基于此,本文提出了一种结合残差混合注意力与多分辨率约束的配准模型MAMReg-Net,实现了脑部核磁共振成像(Magnetic Resonance Imaging, MRI)的单模态非刚性图像配准。该模型通过添加残差混合注意力模块,可以同时获取大量局部和非局部信息,在网络训练过程中提取到了更有效的大脑内部结构特征。其次,使用多分辨率损失函数来进行网络优化,实现更高效和更稳健的训练。在脑部T1 MR图像的12个解剖结构中,平均Dice分数达到0.817,平均ASD数值达到0.789,平均配准时间仅为0.34 s。实验结果表明,MAMReg-Net配准模型能够更好地学习脑部结构特征从而有效地提升配准精确度,并且满足临床实时性的需求。
医学图像处理;单模态配准;深度学习;注意力机制;多分辨率约束
1 引 言
医学图像配准[1-2]的目的是为一对图像之间建立密集的非线性对应关系,利用这种关系可以让参考图像和配准后的图像在空间位置或者解剖结构上能够一一对应起来,其在图像融合、医学图谱创建、时间序列图像对比等医学图像分析任务[3-4]中起着至关重要的作用。传统的配准方法[5-6]利用图像对像素之间的信息进行相似性度量计算,通过迭代的方式最小化相似性度量寻求最优的对应关系[7]。然而该类方法通常在高维空间进行运算,使得计算量大,运算时间过长。
随着深度学习在医学图像处理领域的广泛应用[8-10],配准方式发生了改变。最初,Wu等人[11]提出利用深度学习提取输入图像对的特征,以增强配准的性能。Eppenhof等人[12]则直接使用深度学习取代相似性度量来估计图像对之间的误差。这些方法虽然成功地将深度学习应用于配准方法中,但是仍未能改变传统配准方法迭代的本质。空间变换网络(Spatial Transformer Network,STN)[13]的提出使得网络直接估计形变参数的方法得以实现,可以更好地满足临床实时性要求。Chee等人[14]提出的仿射图像配准网络AIRNet中,使用卷积神经网络(Convolutional Neural Networks, CNN)[15]直接估计3D脑部核碳共振(Magnetic Resonance, MR)图像的DVF(Displacement Vector Field)。随后,Hu[16]等人提出了一种有标签引导的深监督配准网络,并在损失函数的计算中添加了多尺度信息进行训练。这类方法的缺点在于,依赖于专家手工操作的数据作为监督信息,而大量的具有标注的数据很难获得,这在一定程度上限制了配准的性能。
为了消除监督信息的限制,Balakrishnan等人[17]使用CNN提出了一种端到端的无监督配准框架VoxelMorph,该方法在无需任何监督信息的基础上实现了快速、精细配准。在此基础之上,为了解决VoxelMorph网络在大位移形变中效果不佳的问题,Zhang等人[18]提出了端到端的递归级联配准网络,使得所有的子网络能够相互协助地学习图像特征,实现由粗到细的图像配准。Ouyang等人[19]选择用残差结构建立不同层之间的联系来消除梯度消失问题,并学习更有效的特征。在网络深度相当的情况下,使用的参数更少,而且在小数据集上表现良好,可以有效抑制过拟合。然而,这些方法都是基于卷积神经网络的加深或加长网络,卷积运算的过程中只考虑一个像素及其邻域像素,并且这种局部运算是重复的。然而,大脑内部解剖结构复杂,脑部结构大小不一,导致不同部位所引起的邻域像素值的变化是不一样的。因此,应该在配准网络的学习过程中提取出这些特征,提升网络性能,实现有效的图像配准。
针对上述问题,本文设计了一种结合残差混合注意力与多分辨率约束的配准框架(MAMReg-Net)用于单模态脑部MR图像配准中。首先,采用残差块[20]加深网络并消除梯度消失问题。其次,在网络中添加多个残差局部和非局部注意力模块,通过特征加权的方式,让网络提取到更关键的特征。尤其需要注意的是,所添加的残差非局部注意力模块,更多地关注于全局,有效改善了卷积运算的缺陷。此外,还采用了一个多分辨率损失函数用于网络训练,从而实现更有效的优化。
2 配准方法
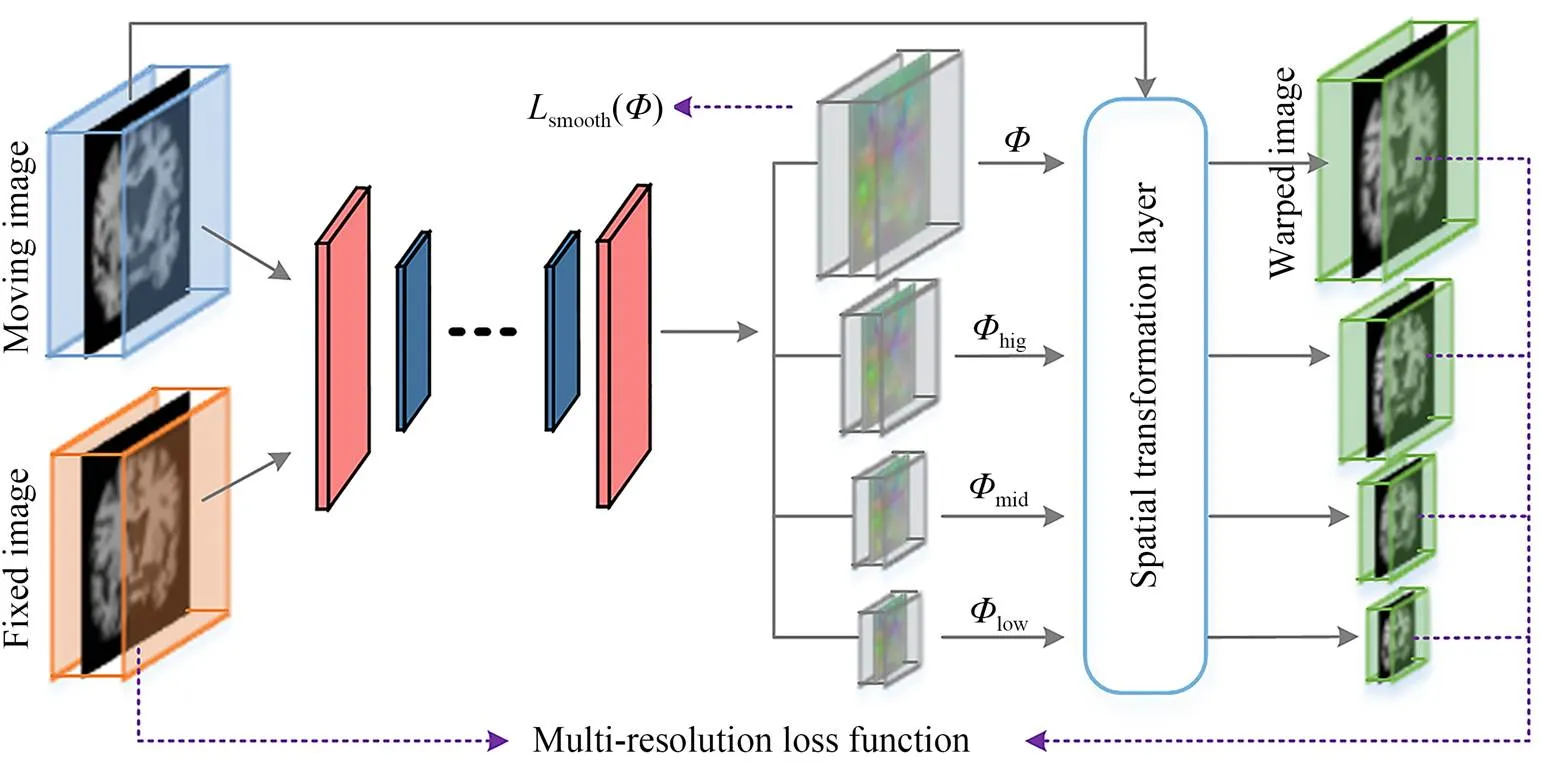
图1 配准网络模型图
2.1 网络结构
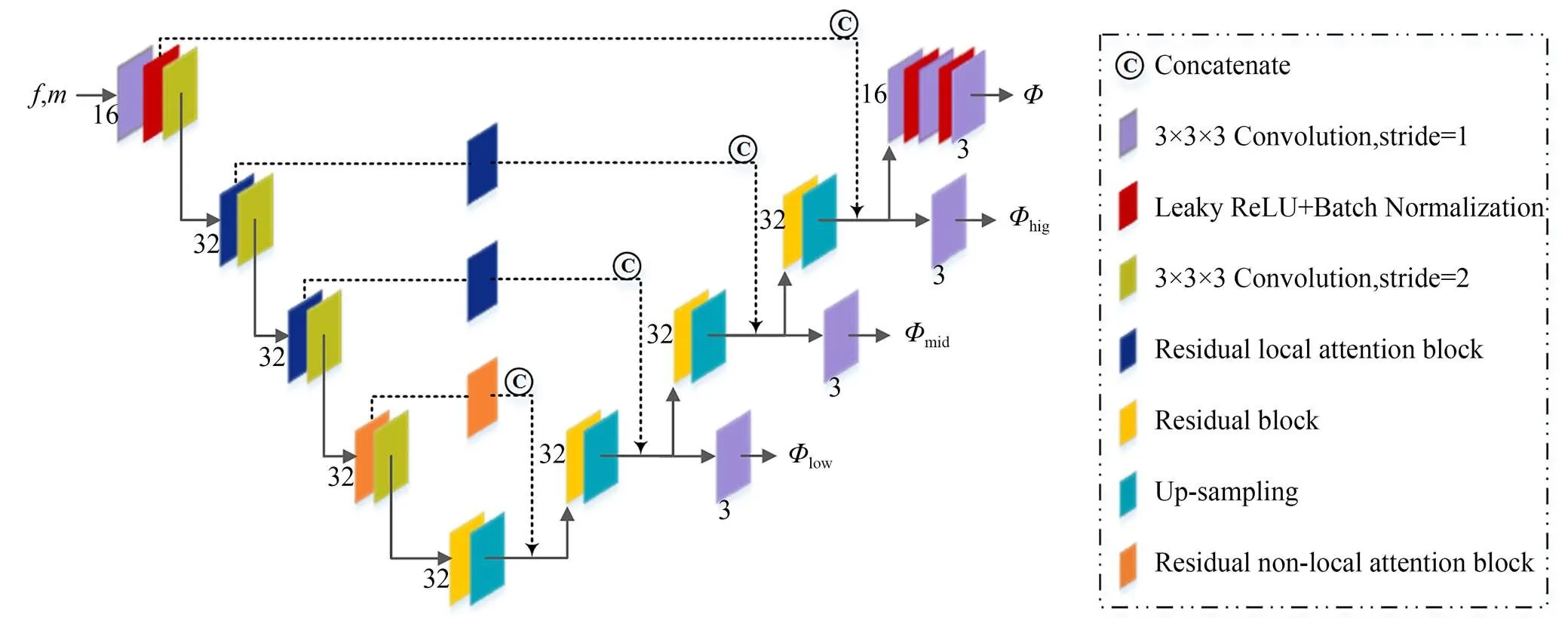
图2 MAMReg-Net网络架构
2.2 残差混合注意力
Oh等人[21]通过实验证明添加注意力模块可以在网络学习过程中保留更多脑部结构特征,得到配准性能的提升。在此基础之上,本文受到秦等人[22]提出的残差注意力机制的启发,引入了残差混合注意力机制,它由多个残差局部和非局部注意力模块构成。残差局部注意力模块的中间部分被分为主干分支Trunk和掩码分支Mask,如图3(a)所示。残差非局部注意力模块就是在残差局部注意力模块的基础上添加非局部注意力模块(Non-local)[23],以此来让网络关注到更多的全局信息,如图3(b)所示。
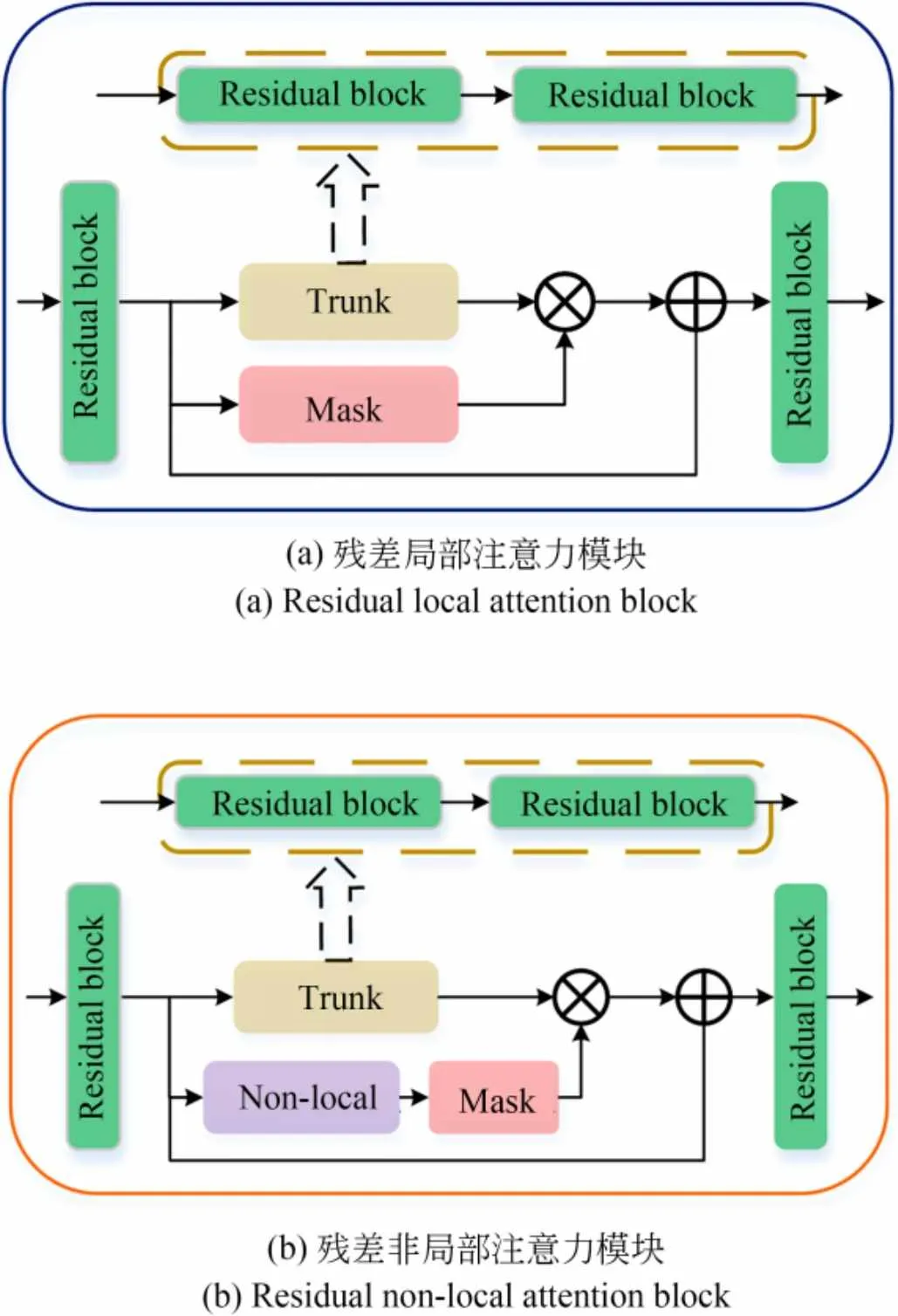
图3 残差混合注意力图
221残差局部注意力模块
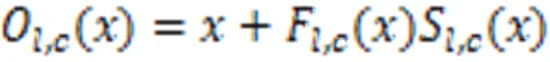
在残差局部注意力模块中,Mask起着非常重要的作用,它能够选择更有效的图像特征并且能够有效地抑制主干分支中的噪声。如图4所示,Mask具有U-Net结构,从输入开始,在编码层中多次执行最大池化与残差块操作之后达到快速增加接受域的目的。之后在上采样结束后进行与编码层的跳跃连接,避免在增加接受域的过程中造成特征丢失。最后添加两个卷积层和一个Sigmoid层对输出进行归一化。通常,残差局部注意力模块通过Trunk保留原有的图像特征信息,使用Mask关注大脑内部细微结构的特征,给出关于图中像素如何与其他像素相关的信息。Mask的输出是一组权重值,它可以表示每一个像素值在配准过程中的重要性。
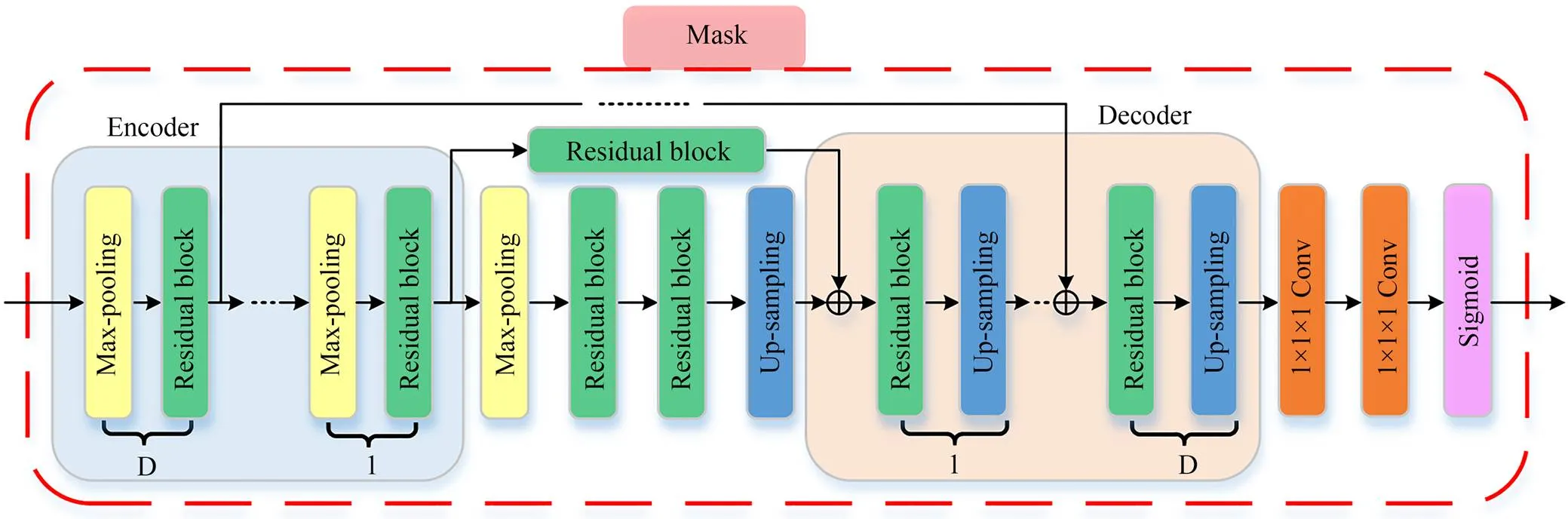
图4 Mask分支结构
222残差非局部注意力模块
为了让网络在学习的过程中关注更多的全局信息,在残差局部注意力模块的掩码分支前加入图5所示的非局部注意力块(Non-local),使之变成残差非局部注意力模块。这种非局部操作的定义如式(3)所示。
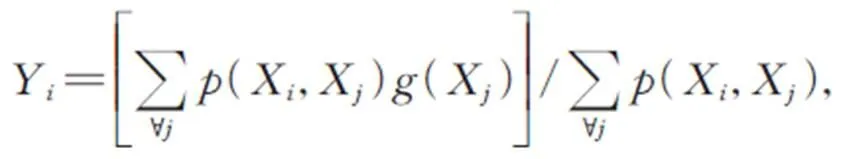
其中:是输出特征的位置索引,代表所有可能位置的索引,和分别表示此操作的输入和输出,用来计算和所有可能相关的位置之间的关系,用于计算输入在位置的特征值;其中,函数有多种变体函数可以达到相似的效果,一般使用嵌入式高斯函数更易于深度学习的应用,使用线性函数,具体定义如式(4)和(5)所示。
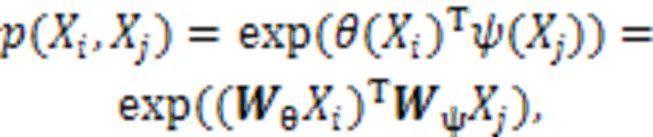
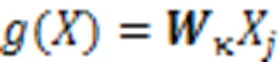
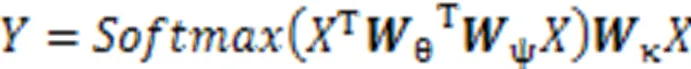
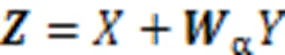
2.3 多分辨率损失函数
无监督配准工作的实质就是一个的函数优化问题,通过最小化损失函数来优化图像之间的相似性,从而找到最优的空间变换参数。通常损失函数的定义如式(8)所示。
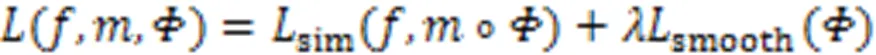
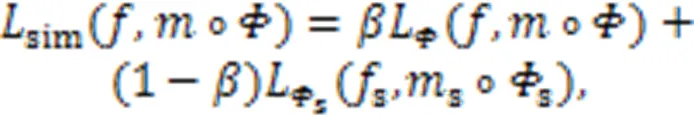
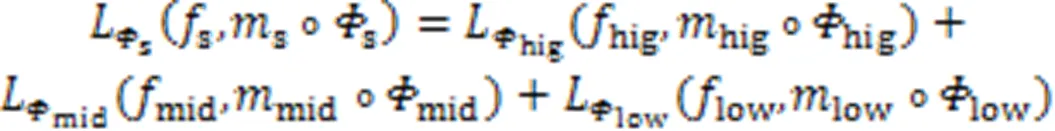

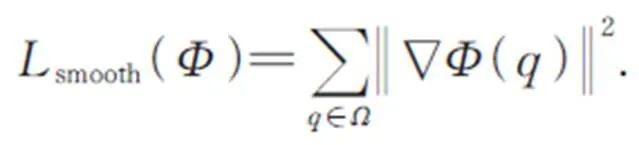
3 实验设置及评价标准
3.1 数据集
原始图像及其经过上述预处理操作的图像如图6所示,预处理后手工去除个别不完整图像数据,一共得到1 551幅T1 MR图像。实验中采用的是基于altas的配准,所以需要在1 551幅MR图像中随机选取一幅作为配准的模板。将另外的1 550幅随机分为1 450幅训练数据,50幅验证数据和50幅测试数据。其中,训练集用于网络模型的训练,验证集用于在训练的过程中保存最优的模型,避免过拟合现象。测试集则用于测试模型的配准性能。
为了进一步研究配准模型的泛化能力,本实验在医学影像数据集ABIDE[28](Autism Brain Imaging Data Exchange)中随机选取了30幅图像进行模型测试,并将选取的30幅3D脑部T1 MR图像进行上述的预处理操作。
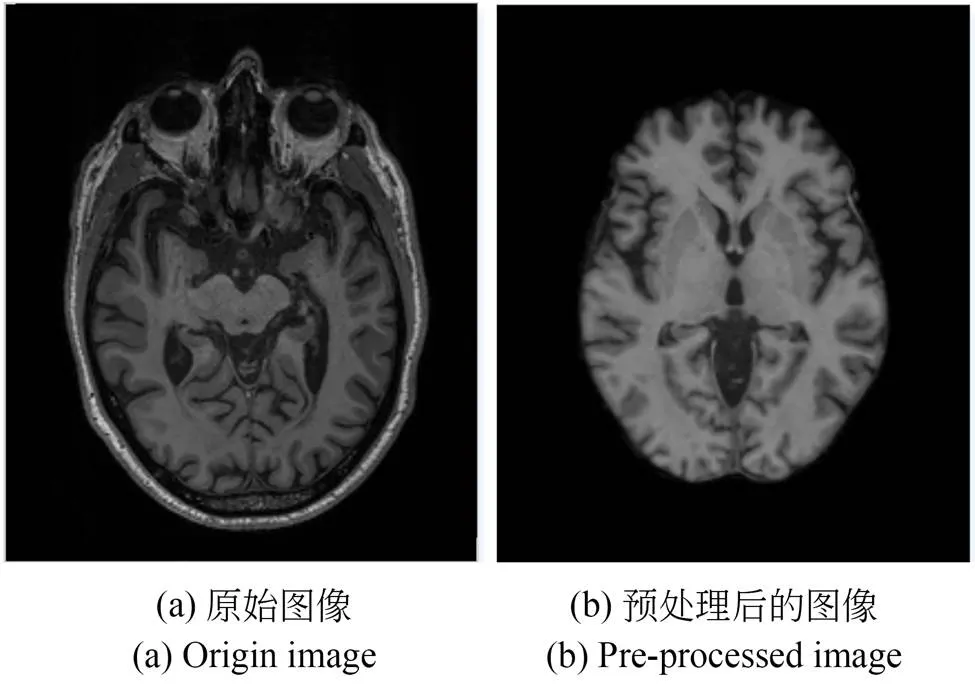
图6 预处理前后图像
3.2 训练策略
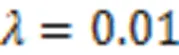
3.3 评价指标
本文的评价指标为配准时间和精确度两个方面。为了满足临床配准实时性的要求,通过比较不同方法的配准时间可以很好地评价配准性能。对于精确度,则通过计算Dice分数和ASD(Averaged Surface Distance)两方面进行定量评价。
Dice分数通常将两幅图片叠在一起进行计算,目的是衡量两个图像之间的相似度,具体计算方式如式(13)所示:
ASD通常用来计算表面平均距离,是评估图像处理结果质量的一个重要的量化标准。具体计算方式如式(14)所示:
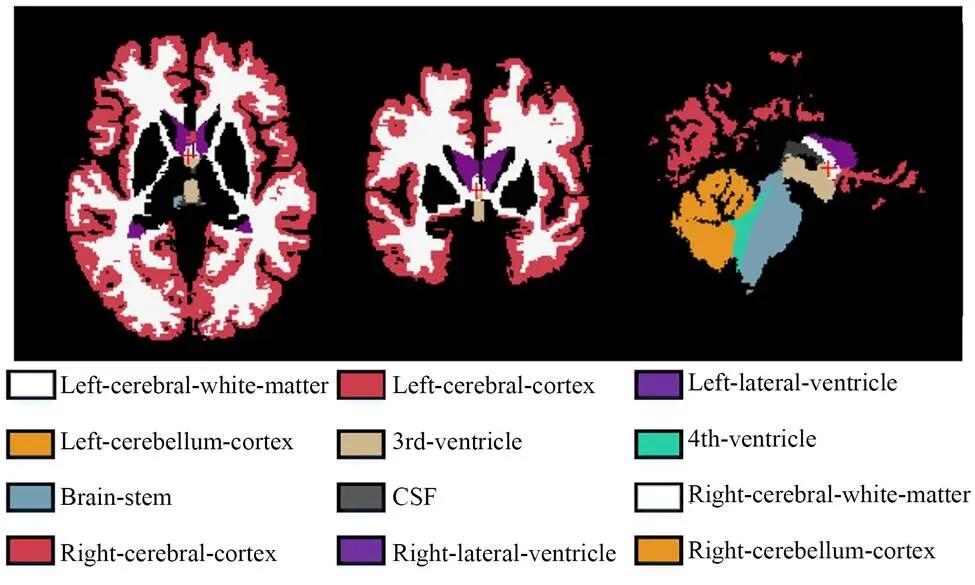
图7 12个解剖结构示例图
4 实验结果及分析
4.1 可视化分析
本文中基于atlas的脑部MR图像配准的可视化结果如图8所示。图中所展示的是从测试集图像中随机获取的一幅样本结果,图8(a)、(b)分别代表参考图像和浮动图像,图8(c)、(d)分别是使用MR图像查看工具ITK-SNAP[30]中的彩色通道成像和网格成像两种不同形式呈现的变形场可视化结果,图8(e)则是配准后图像。可视化结果的分析从图像的三个维度进行,从上到下每一行分别显示了脑部图像的冠状面、矢状面和横断面。从图8可以直观的看出,配准后图像与参考图像具有较高的相似性。
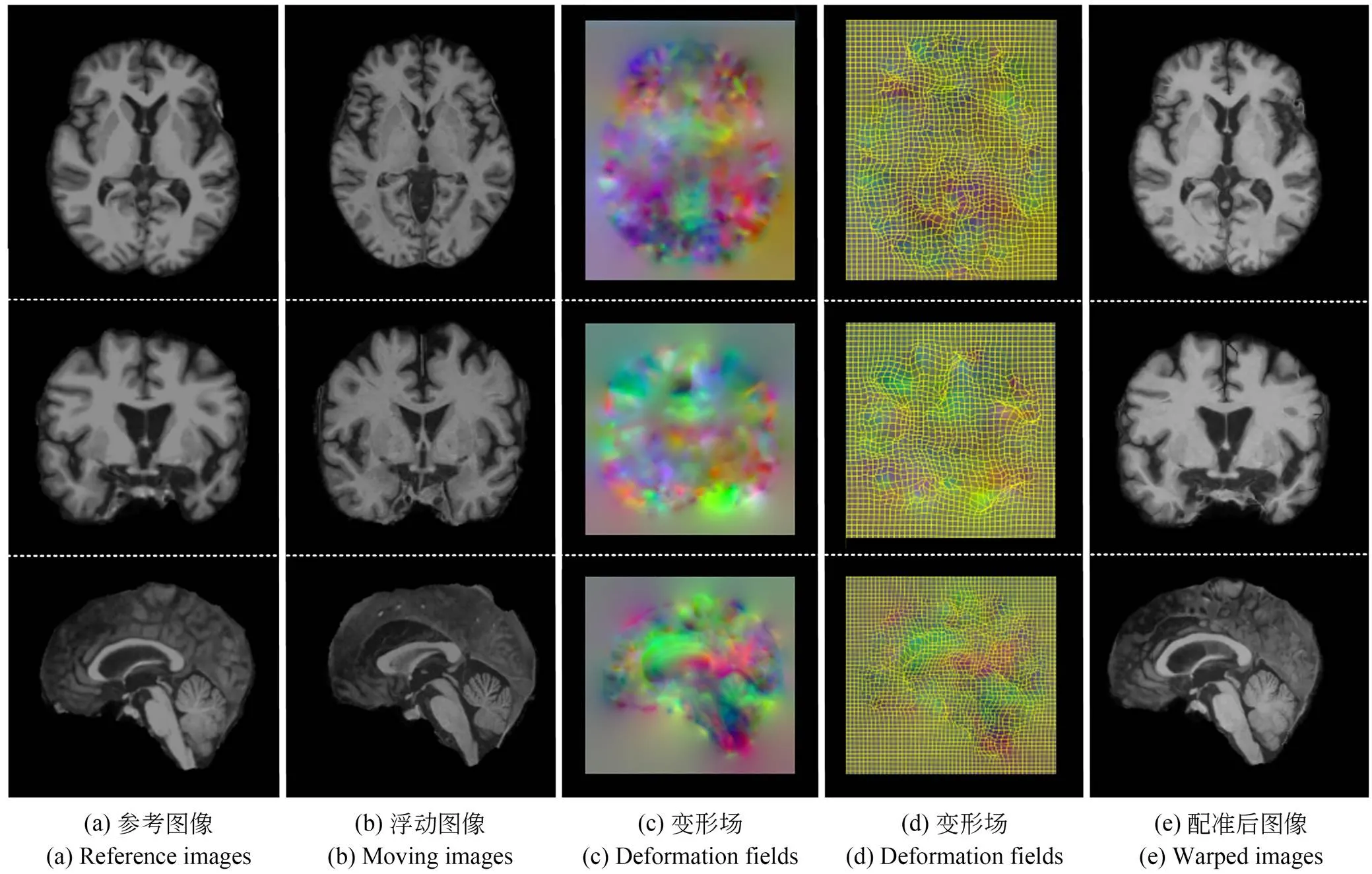
图8 测试集的随机样本配准结果
图9展示了颜色叠加图,以便于更好地观察本文所提出的MAMReg-Net的配准效果。图9(a)代表参考图像与浮动图像的叠加图,图9(b)代表参考图像与配准后图像的叠加图。其中,蓝色标记参考图像,绿色标记浮动图像和配准后图像,蓝色与绿色重叠后表现为青绿色。相比于图9(a),在图9(b)中可以明显看出三个维度的图像绝大部分都呈现为青绿色,只有很少的蓝色和绿色,这表明MAMReg-Net配准后图像与参考图像重叠部位多,达到了很好的可视化配准效果。
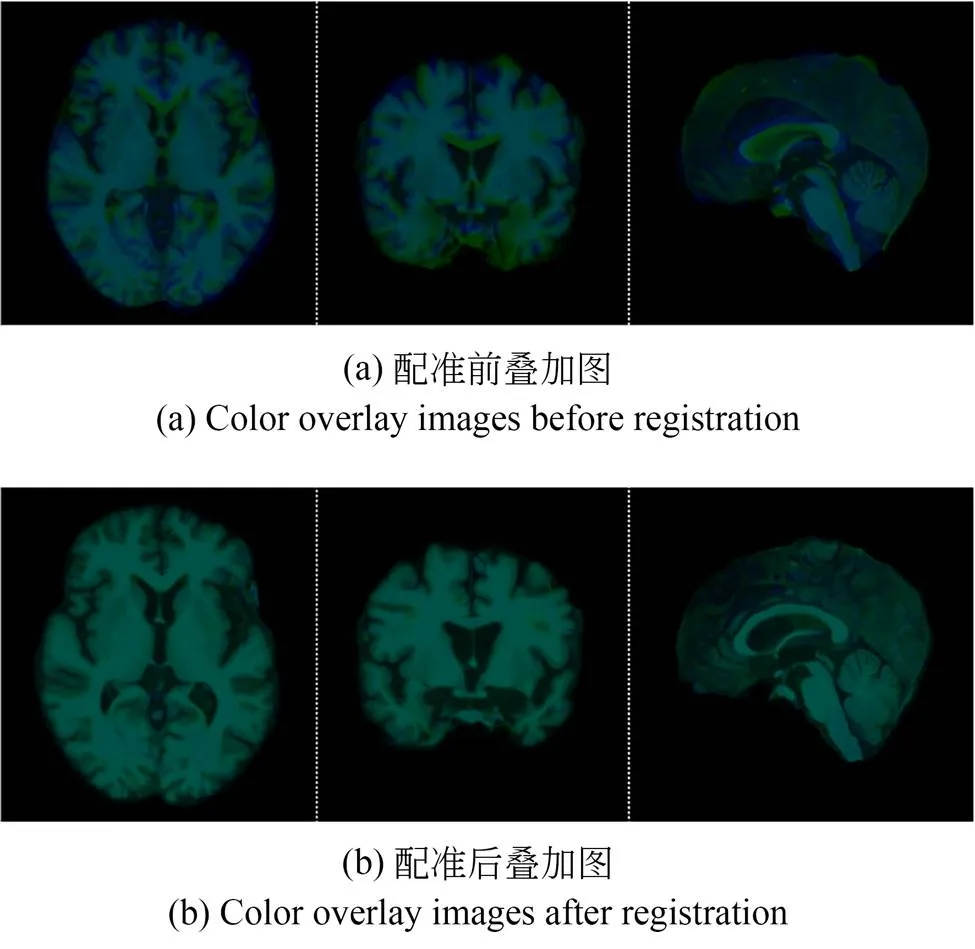
图9 配准前后颜色叠加图
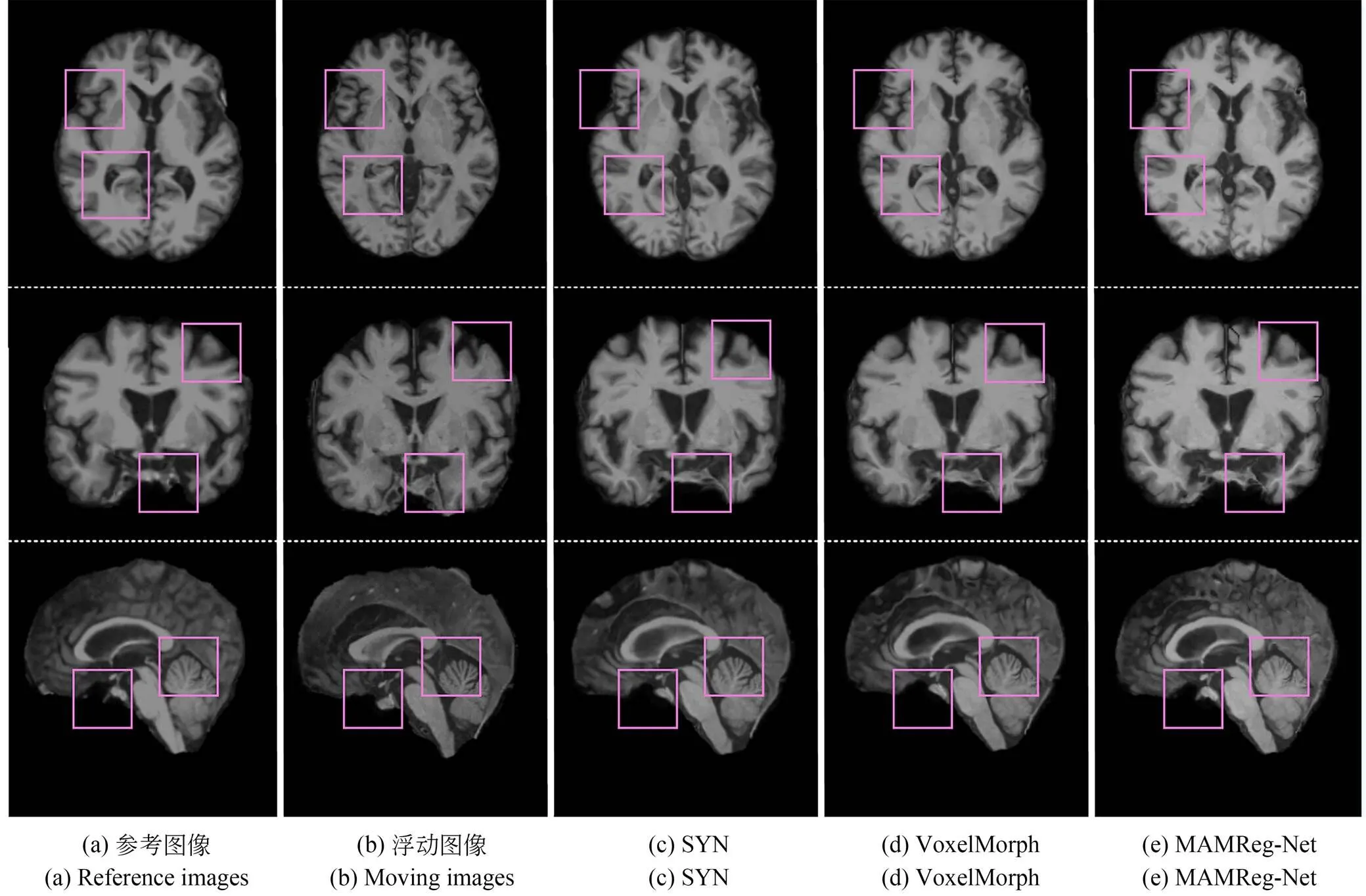
图10 不同方法配准结果
为了进一步对比SYN、VoxelMorph和MAMReg-Net脑部MR图像配准结果的差异,不同方法的可视化结果如图10所示。从图10(c),(d)和(e)可以看出,不同方法得到的配准后图像都能够与参考图像具有较高的相似性。值得注意的是,在粉红色方框所标记的解剖区域上,MAMReg-Net的配准后图像与参考图像最为相似,效果优于SYN和VoxelMorph。图10中图像的三个维度均有粉红色方框标注,表明MAMReg-Net在几种不同方法中具有最好的可视化配准效果。
4.2 量化分析
421配准精度
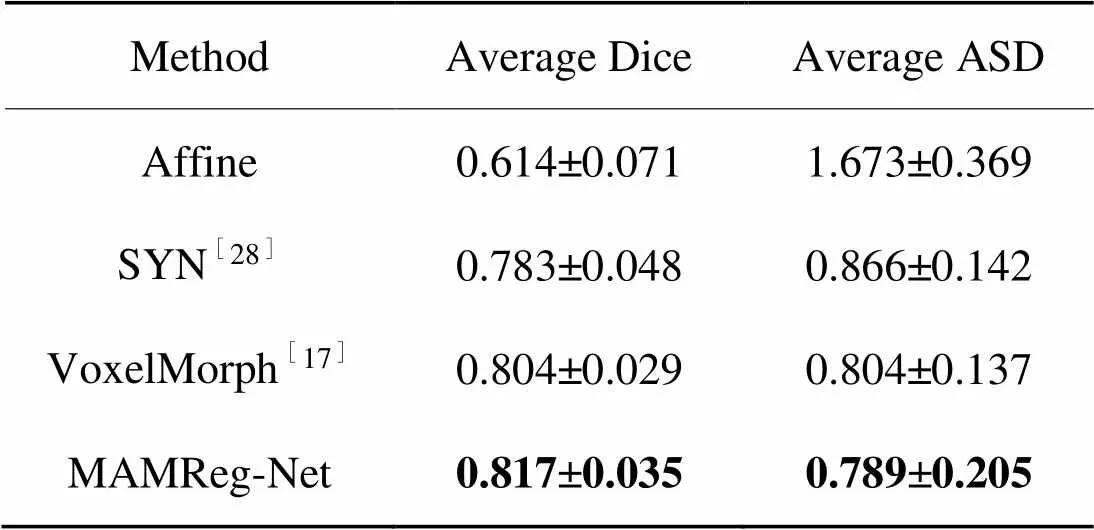
ADNI3测试集的配准结果用评价指标Dice分数和ASD进行计算,得到量化的分析。如表1所示,MAMReg-Net在不同的方法中取得了最高的平均Dice分数,较Affine、SYN和VoxelMorph分别提升了0.203、0.034和0.013。与此同时,MAMReg-Net在ASD评价指标中也取得了最优配准精度,较Affine、SYN和VoxelMorph的平均ASD数值分别降低了0.884、0.077和0.015。
为了能够更加细致地分析不同方法对于不同解剖部位的配准效果,图11和图12分别展示了测试集图像在12个解剖结构上的平均Dice分数和平均ASD数值。从图11中可以看出,经过可变形配准方法之后的平均Dice分数明显高于只进行刚性变换的Affine。对于这12个解剖结构,MAMReg-Net的平均Dice分数在9个结构上的高于SYN,在10个结构上的高于VoxelMorph。同样,从图12可以看出,MAMReg-Net在大部分解剖结构上获得了最优的平均ASD数值。以上结果表明,本文所设计的MAMReg-Net配准模型是有效的。
表1不同方法的配准精度
Tab.1 Registration accuracy of different methods

图11 测试集上12个解剖结构的平均Dice分数柱状图

图12 测试集上12个解剖结构的平均ASD数值柱状图
422配准时间
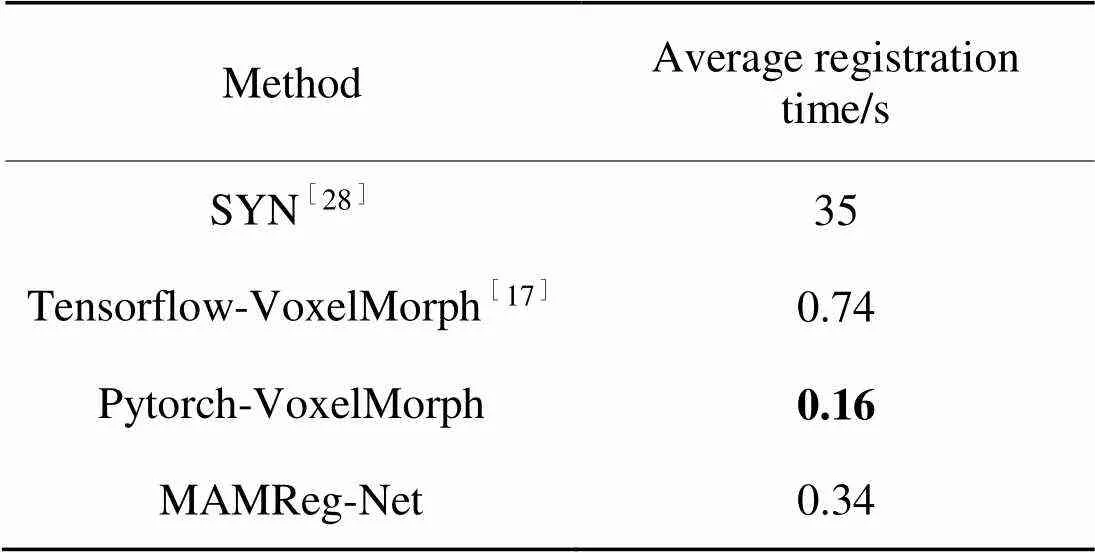
为了评价本文所提出的配准网络模型的配准速度,对SYN、VoxelMorph和MAMReg-Net的平均配准时间进行了比较,如表2所示。结果表明,在对VoxelMorph和MAMReg-Net训练出的最优模型进行测试时均能在1秒之内完成配准。其中MAMReg-Net的配准时间约为基于Tensorflow框架实现的VoxelMorph的一半,约为传统方法SYN的百分之一。由于本文配准模型添加了残差混合注意力以及多分辨率约束,所以相比于Pytorch框架实现的VoxelMorph需要更多的配准时间。
423配准模型的泛化能力
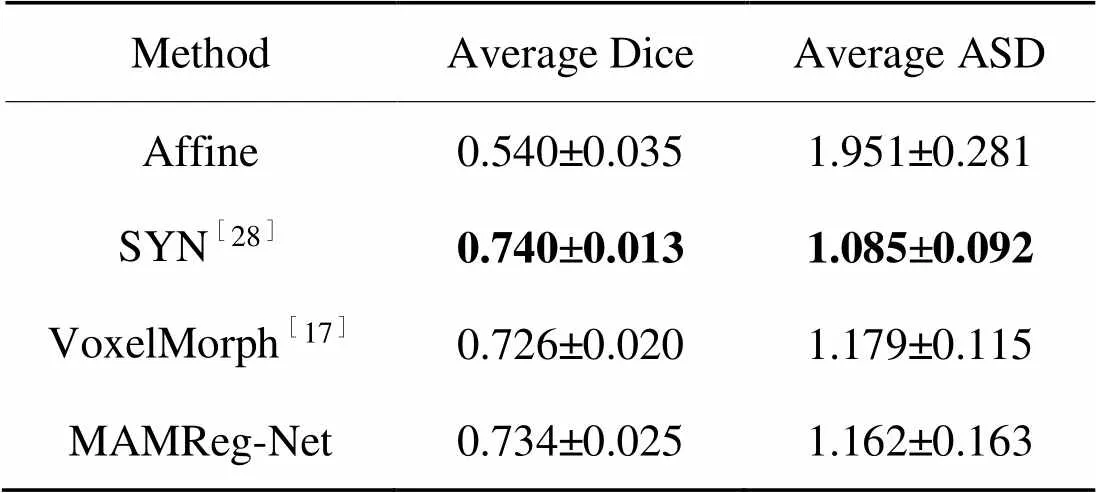
为了评估MAMReg-Net的泛化能力,实验进一步在ABIDE数据集上进行了测试。方法是直接采用ADNI3数据集训练出的模型,不加任何额外的参数调整,对预处理操作后的30幅ABIDE数据进行基于altas配准。测试结果如表3所示,在两个评价标准平均Dice分数和平均ASD数值上,MAMReg-Net的配准精度对比传统配准方法SYN略差,但高于深度学习网络VoxelMorph,这验证了本文配准模型MAMReg-Net的泛化能力较VoxelMorph有所提升。
表2不同方法的平均配准时间比较
Tab.2 Comparison of registration time between different methods
表3ABIDE数据集的配准精度比较
Tab.3 Comparison of registration accuracy of ABIDE dataset
4.3 消融实验
为了验证多分辨率约束、残差局部注意力和残差混合注意力和对配准性能的影响,表4对消融实验的配准精度进行了比较。从表中可以看出,在基础网络中添加多分辨率约束、残差局部注意力和残差混合注意力,平均Dice分数分别提升了0.002,0.006和0.008,平均ASD数值分别降低了0.017、0.031和0.036,这表明三个策略对配准任务均有效。其中,添加残差混合注意力比残差局部注意力的平均Dice分数提升了0.002,平均ASD数值降低了0.005,证明了在配准网络的学习过程中使用残差混合注意力考虑全局信息的重要性。本文配准模型MAMReg-Net将配准精度提升较明显的残差混合注意力与多分辨率约束结合起来,达到了最优的平均Dice分数,相比较于Base模型平均Dice分数提升了0.01,平均ASD数值降低了0.047。
为了更加直观地显示多分辨率约束和残差混合注意力的有效性,消融实验在12个解剖结构上的Dice分数箱线图如图13所示。在大多数解剖结构上,相比于基础模型,添加多分辨率约束、残差局部注意力和残差混合注意力都获得了更高的平均Dice分数。并且在多数解剖结构上添加残差混合注意力可比只添加残差局部注意力获得更高的平均Dice分数。另外,在图13中所有解剖结构上,本文配准模型MAMReg-Net均取得了最高的平均Dice分数。图14是消融实验的ASD数值箱线图,从中可以看出MAMReg-Net在8个解剖结构上取得了最优数值。由此说明,结合多分辨率约束和残差混合注意力能直接有效地提升配准性能。
表4消融实验的配准精度比较

Tab.4 Comparison of registration accuracy of ablation experiments
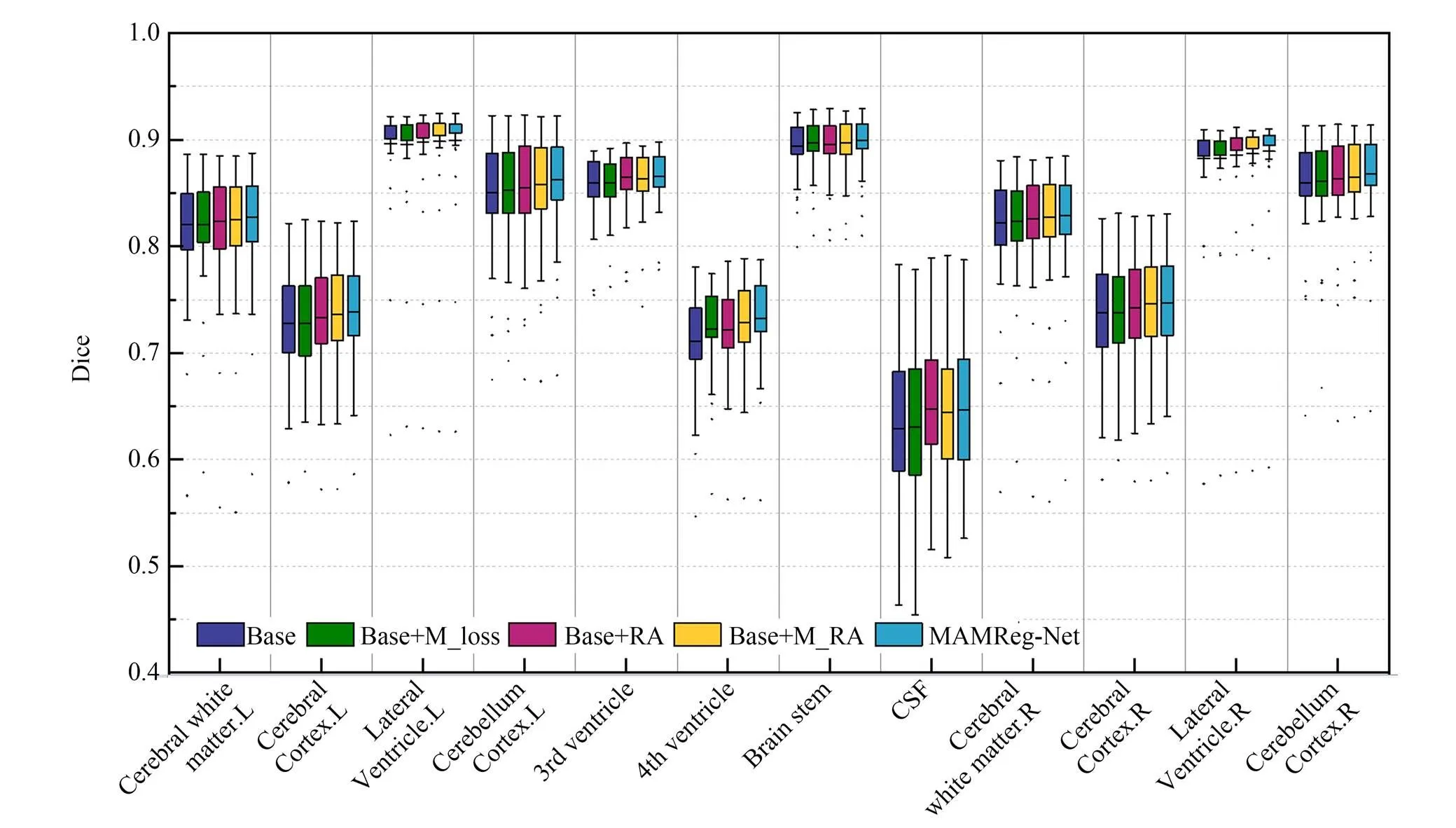
图13 消融实验中12个解剖结构的Dice分数箱线图
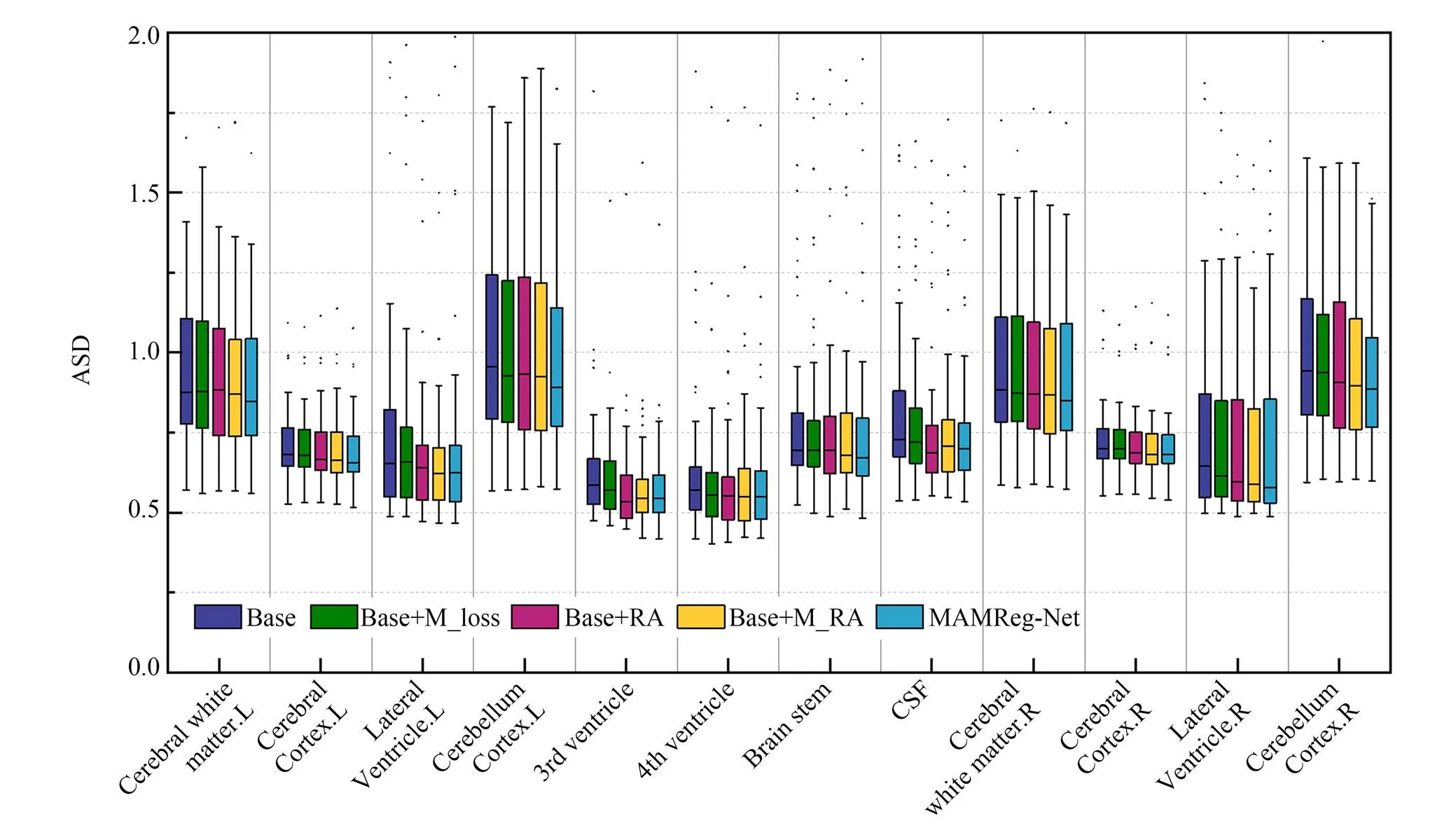
图14 消融实验中12个解剖结构的ASD数值箱线图
5 结 论
本文提出了一种针对脑部MR图像的无监督配准方法。该方法首先通过引入残差混合注意力的方式实现了更好的特征提取,可以在网络学习的过程中通过权重分配的方式选择出较为重要的特征,从而能够提高大脑内部解剖结构中关键部分的对齐程度。然后采用多分辨率损失函数进行网络的优化,可以有效避免过度依赖配准后图像,在不同分辨率下进行网络优化以达到促进网络更好收敛的目的。实验结果证明:本文所提出的MAMReg-Net配准框架的平均Dice分数相较于传统方法SYN和深度学习方法VoxelMorph分别提升了0.034和0.013,并且在平均ASD数值上分别降低了0.077和0.015,更好地满足了医学图像配准在临床应用中高精确度的需求。对于本文模型的泛化能力,虽然相较于VoxelMorph模型泛化能力有较好的提升,但是相比于传统配准方法效果欠佳,尤其是在处理解剖结构差异较大的脑部MR图像时。下一步的工作将针对这一问题进行改善,增强配准模型的稳定性和泛化性。
[1] HASKINS G, KRUGER U, YAN P K. Deep learning in medical image registration: a survey[J]., 2020, 31(1/2): 1-18.
[2] 王宾,刘林,侯榆青,等. 应用改进迭代最近点方法的三维心脏点云配准[J]. 光学精密工程, 2020, 28(2): 474-484.
WANG B, LIU L, HOU Y Q,. Three-dimensional cardiac point cloud registration by improved iterative closest point method[J]., 2020, 28(2): 474-484.(in Chinese)
[3] GU Y, LU X Q, ZHANG B H,. Automatic lung nodule detection using multi-scale dot nodule-enhancement filter and weighted support vector machines in chest computed tomography[J]., 2019, 14(1): e0210551.
[4] LU X Q, GU Y, YANG L D,. Multi-level 3D densenets for false-positive reduction in lung nodule detection based on chest computed tomography[J]., 2020, 16(8): 1004-1021.
[5] ASHBURNER J. A fast diffeomorphic image registration algorithm[J]., 2007, 38(1): 95-113.
[6] 刘坤,吕晓琪,谷宇,等. 快速数字影像重建的2维/3维医学图像配准[J]. 中国图象图形学报, 2016, 21(1): 69-77.
LIU K, LYU X Q, GU Y,. The 2D/3D medical image registration algorithm based on rapid digital image reconstruction[J]., 2016, 21(1): 69-77.(in Chinese)
[7] KHADER M, SCHIAVI E, HAMZA A B. A multicomponent approach to nonrigid registration of diffusion tensor images[J]., 2017, 46(2): 241-253.
[8] GU Y, CHI J Q, LIU J Q,. A survey of computer-aided diagnosis of lung nodules from CT scans using deep learning[J]., 2021, 137: 104806.
[9] QIAN L J, ZHOU Q, CAO X H,. A cascade-network framework for integrated registration of liver DCE-MR images[J]., 2021, 89: 101887.
[10] 李赛,黎浩江,刘立志,等. 基于尺度注意力沙漏网络的头部MRI解剖点自动定位[J]. 光学精密工程, 2021, 29(9): 2278-2286.
LI S, LI H J, LIU L Z,. Automatic location of anatomical points in head MRI based on the scale attention hourglass network[J]., 2021, 29(9): 2278-2286.(in Chinese)
[11] WU G R, KIM M, WANG Q,. Scalable high-performance image registration framework by unsupervised deep feature representations learning[J]., 2016, 63(7): 1505-1516.
[12] EPPENHOF K A J, PLUIM J P W. Error estimation of deformable image registration of pulmonary CT scans using convolutional neural networks[J]., 2018, 5: 024003.
[13] JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks[J]., 2015, 28: 2017-2025.
[14] CHEE E, WU Z Z. AIRNet: self-supervised affine registration for 3D medical images using neural networks[J].:1810.02583, 2018.
[15] 谷宇. 基于三维卷积神经网络的低剂量CT肺结节检测[D].上海:上海大学,2019.
GU Y.[D]. Shanghai: Shanghai University,2019. (in Chinese)
[16] HU Y P, MODAT M, GIBSON E,. Weakly-supervised convolutional neural networks for multimodal image registration[J]., 2018, 49: 1-13.
[17] BALAKRISHNAN G, ZHAO A, SABUNCU M R,. VoxelMorph: a learning framework for deformable medical image registration[J]., 2019, 38(8):1788-1800.
[18] ZHANG L T, ZHOU L, LI R Y,. Cascaded feature warping network for unsupervised medical image registration[C]. 2021181316,2021,,IEEE, 2021: 913-916.
[19] OUYANG X Y, LIANG X K, XIE Y Q. Preliminary feasibility study of imaging registration between supine and prone breast CT in breast cancer radiotherapy using residual recursive cascaded networks[J]., 2020, 9:3315-3325.
[20] HE K M, ZHANG X Y, REN S Q,. Deep residual learning for image recognition[C]. 20162730,2016,,,IEEE, 2016: 770-778.
[21] OH D, KIM B, LEE J,. Unsupervised deep learning network with self-attention mechanism for non-rigid registration of 3D brain MR images[J]., 2021, 11(3): 736-751.
[22] 秦传波,宋子玉,曾军英,等. 联合多尺度和注意力-残差的深度监督乳腺癌分割[J]. 光学精密工程, 2021, 29(4): 877-895.
QIN C B, SONG Z Y, ZENG J Y,. Deeply supervised breast cancer segmentation combined with multi-scale and attention-residuals[J]., 2021, 29(4): 877-895.(in Chinese)
[23] WANG X L, GIRSHICK R, GUPTA A,. Non-local neural networks[C]. 20181823,2018,,,IEEE, 2018: 7794-7803.
[24] MA Y J, NIU D M, ZHANG J S,. Unsupervised deformable image registration network for 3D medical images[J]., 2022, 52(1): 766-779.
[25] JACK C R, BERNSTEIN M A, FOX N C,. The Alzheimer's disease neuroimaging initiative (ADNI): MRI methods[J]., 2008, 27(4): 685-691.
[26] CHEN J Y, HE Y F, FREY E C,. ViT-V-net: vision transformer for unsupervised volumetric medical image registration[J].: 2104.06468,2021.
[27] FISCHL B. FreeSurfer[J]., 2012, 62(2): 774-781.
[28] DI MARTINO A, YAN C G, LI Q,. The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism[J]., 2014, 19(6): 659-667.
[29] AVANTS B B, EPSTEIN C L, GROSSMAN M,. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain[J]., 2008, 12(1): 26-41.
[30] YUSHKEVICH P A, PIVEN J, HAZLETT H C,. User-guided 3D active contour segmentation of anatomical structures: significantly improved efficiency and reliability[J]., 2006, 31(3): 1116-1128.
Image registration based on residual mixed attention and multi-resolution constraints
ZHANG Mingna1,LÜ Xiaoqi1,2*,GU Yu1
(1,,,014010,;2,,010051,),:
Medical image registration has great significance in clinical applications such as atlas creation and time-series image comparison. Currently, in contrast to traditional methods, deep learning-based registration achieves the requirements of clinical real-time; however, the accuracy of registration still needs to be improved. Based on this observation, this paper proposes a registration model named MAMReg-Net, which combines residual mixed attention and multi-resolution constraints to realize the non-rigid registration of brain magnetic resonance imaging (MRI). By adding the residual mixed attention module, the model can obtain a large amount of local and non-local information simultaneously, and extract more effective internal structural features of the brain in the process of network training. Secondly, multi-resolution loss function is used to optimize the network to make the training more efficient and robust. The average dice score of the 12 anatomical structures in T1 brain MR images was 0.817, the average ASD score was 0.789, and the average registration time was 0.34 s. Experimental results demonstrate that the MAMReg-Net registration model can be better trained to learn the brain structure features to effectively improve the registration accuracy and meet clinical real-time requirements.
medical imaging process; unimodal registration; deep learning; attentional mechanism; multi-resolution constraint
TP391.4
A
10.37188/OPE.20223010.1203
1004-924X(2022)10-1203-14
2021-12-22;
2022-02-16.
国家自然科学基金项目(No.62001255,No.61771266,No.61841204);内蒙古自治区科技计划项目(No.2019GG138);中央引导地方科技发展资金项目(No.2021ZY0004);内蒙古自治区自然科学基金项目(No.2019MS06003,No.2015MS0604);内蒙古自治区高等学校科学研究项目(No.NJZY145);教育部“春晖计划”合作科研项目(No.教外司留[2019]1383号)
张明娜(1997),女,山东济南人,硕士研究生,2020年于山东第一医科大学获得学士学位,主要从事智能图像处理、深度学习及图像配准方面的研究。E-mail:1292579223@qq.com

吕晓琪(1963),男,内蒙古包头人,博士,教授,博士生导师,1984年于内蒙古大学获得学士学位,1989年于西安交通大学获得硕士学位,2003年于北京科技大学获得博士学位,主要从事智能信息处理、医学图像处理、数字化医疗相关技术等方面的研究。E-mail: lxiaoqi@imust.edu.cn
