融合NFFD与图卷积的单视图三维物体重建
2022-06-01连远锋裴守爽胡伟
连远锋裴守爽胡伟
融合NFFD与图卷积的单视图三维物体重建
连远锋1,2*,裴守爽1,胡伟1
(1.中国石油大学(北京) 计算机科学与技术系,北京 102249;2.石油数据挖掘北京市重点实验室,北京 102249)
为了解决复杂拓扑结构及非规则表面细节缺失等导致的单视图三维物体重建结果不准确问题,本文提出了一种融合非均匀有理B样条自由形变(NFFD)与图卷积神经网络的三维物体重建方法。首先,通过引入连接权重策略的控制点生成网络对2D视图进行特征学习,获得其控制点拓扑结构。然后,利用NURBS基函数对控制点坐标自适应特性建立点云模型轮廓间顶点的形变关系。最后,为增强细节信息,将混合注意力模块嵌入图卷积网络对形变后的点云位置进行调整,从而实现复杂拓扑结构和非规则表面的高效重建。在ShapeNet数据集的实验表明,CD指标平均值为3.79,EMD指标平均值为3.94,并在Pix3D真实场景数据集上取得较好重建效果。与已有的单视图点云三维重建方法比较,本文方法有效地提高了重建精度,具有较强的鲁棒性。
NURBS自由形变;三维重建;图卷积网络;混合注意力;控制点生成网络
1 引 言
单视图三维物体重建技术广泛应用于姿态估计、形状检索、自动驾驶和增强现实等多种场景,成为计算机视觉领域的研究热点。由于物体单视图受观察视角影响导致几何信息缺失,使得恢复物体完整的三维结构非常具有挑战性。
近年来,基于深度学习的三维模型重建得到了广泛应用。根据重建对象的表示形式可分为网格、体素和点云[1-2]。基于网格[3]和体素[4]进行物体三维重建是利用网络学习二维图像到三维网格或三维体素块上的概率分布映射关系来表达三维几何形状。由于三维物体的网格表示形式存在复杂的拓扑关系,使得在利用同类形状模板进行变形过程中容易出现网格自交叉[5]。基于体素的物体表示形式可以直接实现卷积与池化操作,但受限于计算资源和分辨率等问题会丢失局部细节,难以处理高精度的模型[6]。一些工作[7-8]基于点云的不规则数据形式进行三维形状重建。Fan等[9]提出了一种基于点云的三维模型重建方法PSGN,通过定义倒角距离与空间距离等损失函数,取得了较好的重建精度。Zhang等[10]基于融合特征对内部点和外部点进行分类,并提出一种点云采样优化策略,使得重建点云的细节更为丰富。为了有效恢复物体单视图的遮挡区域,Yang等[11]将3D编码器-解码器结构与生成对抗网络结合,从单幅视图重建物体精细的三维结构,在合成数据集上得到较好的实验结果。
基于点云的三维重建方法中,三维模型中每个顶点的位置及其邻接关系可以通过拓扑图来表示,而图卷积网络(Graph Convolution Network,GCN)能够更好地在拓扑图上捕获隐含、非线性空间特征,因而采用GCN模型实现点云的三维重建得到了广泛应用[12-13]。Wang等[14]提出一种多阶段网格形变的三维重建方法Pixel2Mesh,通过图卷积神经网络精确预测三维模型中每个顶点的位置,实现网格的形变。在文献[14]基础上,Nguyen等[15]通过多尺度的编码器获得更为准确的图像特征,并将这些特征映射到随机点云的每个顶点实现模型重建。虽然上述方法在部分数据集上取得较好的结果,但仍存在由于局部纹理缺失、物体拓扑结构复杂等因素导致重建结果不准确的局限性。
由于点云具有可伸缩性和延展性,一些方法将自由形变(Free-Form Deformation, FFD)引入三维物体重建任务中。Kurenkov等[16]基于FFD模型,提出一种点云三维重建方法,利用网格体包围目标,并在网格上定义若干控制点,通过深度学习方法预测控制点偏移来实现三维重建。Pontes等[17]扩展了这种方法,并引入模型检索思想,根据输入的图像在数据库中查找与其最为相近的三维模型,然后经过自由形变技术得到最终模型。由于FFD模型对计算资源要求较高,任意控制点的坐标变化均会导致模型整体形变,文献[18]改进了FFD模型,提出NFFD (NURBS-based Free-Form Deformation)自由形变模型,增加了形变自由度,在一定程度上提升了自由形变的精度。
为了提升单视图三维物体重建精度,本文提出了一种融合NFFD与图卷积神经网络的三维重建方法。首先,通过引入连接权重策略的控制点生成网络对2D视图进行特征学习,获得其控制点拓扑结构。其次,利用NURBS基函数对控制点坐标自适应特性建立点云模型轮廓间顶点的形变关系。最后,为增强细节信息,将混合注意力模块嵌入图卷积网络对形变后的点云位置进行调整。通过以上两阶段的位置映射,实现复杂拓扑结构和非规则表面的高效重建。
2 融合NFFD与图卷积的单视图三维重建算法
本文提出的系统网络结构如图1所示,包括控制点生成网络、NFFD自由形变和图卷积局部点云形变模块。首先将单幅图像输入到控制点生成网络获得三维模型的控制点,然后利用NFFD自由形变方法对模板模型进行调整,最后利用图卷积对局部点云进行调整,得到最终的三维点云重建结果。
2.1 控制点生成网络
为了利用单幅图像的特征信息生成准确的三维模型控制点,采用编码器-解码器-预测器机制,设计了一个对复杂三维模型结构具有良好表现力的控制点生成网络(Control Points Generation Network,CPGN),如图2所示。编码器由卷积层和ReLU层组成,这里采用了多尺度的卷积层以获得不同层次的特征信息。解码器由反卷积层和ReLU层组成,利用步长为1的卷积代替pooling层,同样用步长为2的反卷积代替unpooling层,这种设计可以减少图像纹理信息的丢失。编码器中每一层的输出与相应的解码器输出通过矩阵加法相融合,以产生增强的特征。为了防止过拟合,加快收敛速度,预测器由卷积模块和两个全连接层组成,最后的一个全连接层实现维度变换,输出控制点坐标偏移量,并与初始控制点坐标相加,获得最终的控制点坐标。
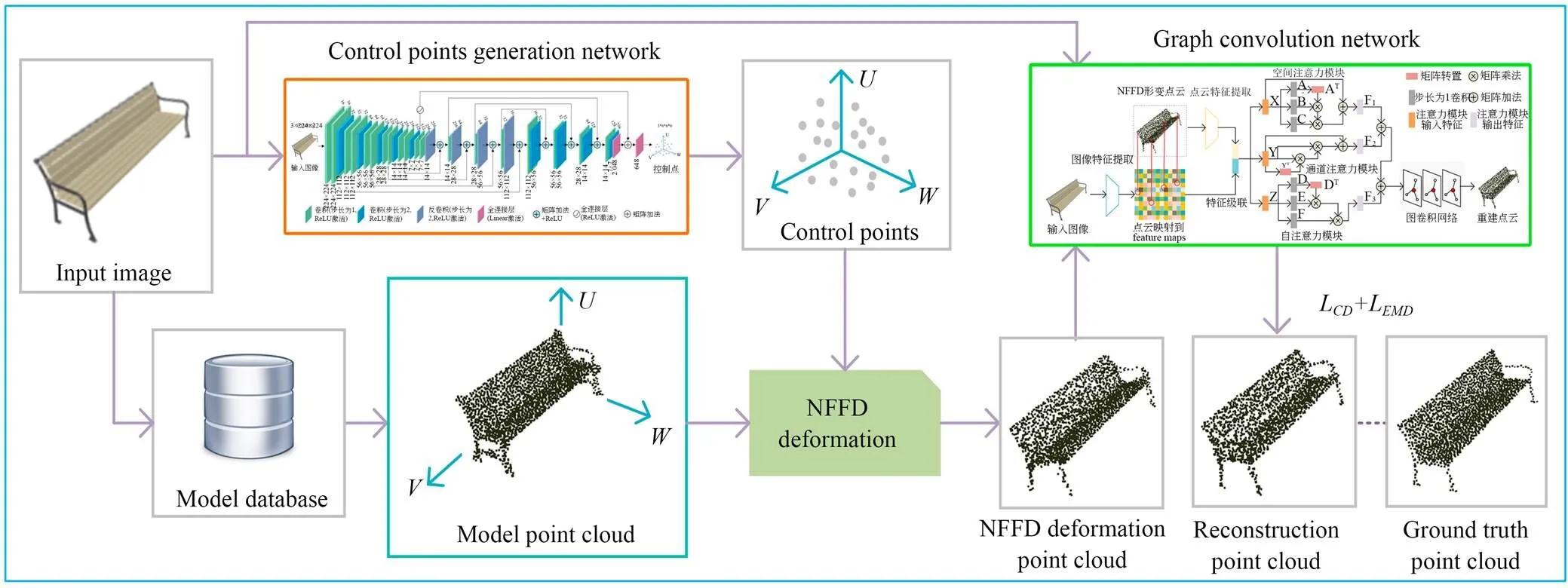
图1 系统网络结构
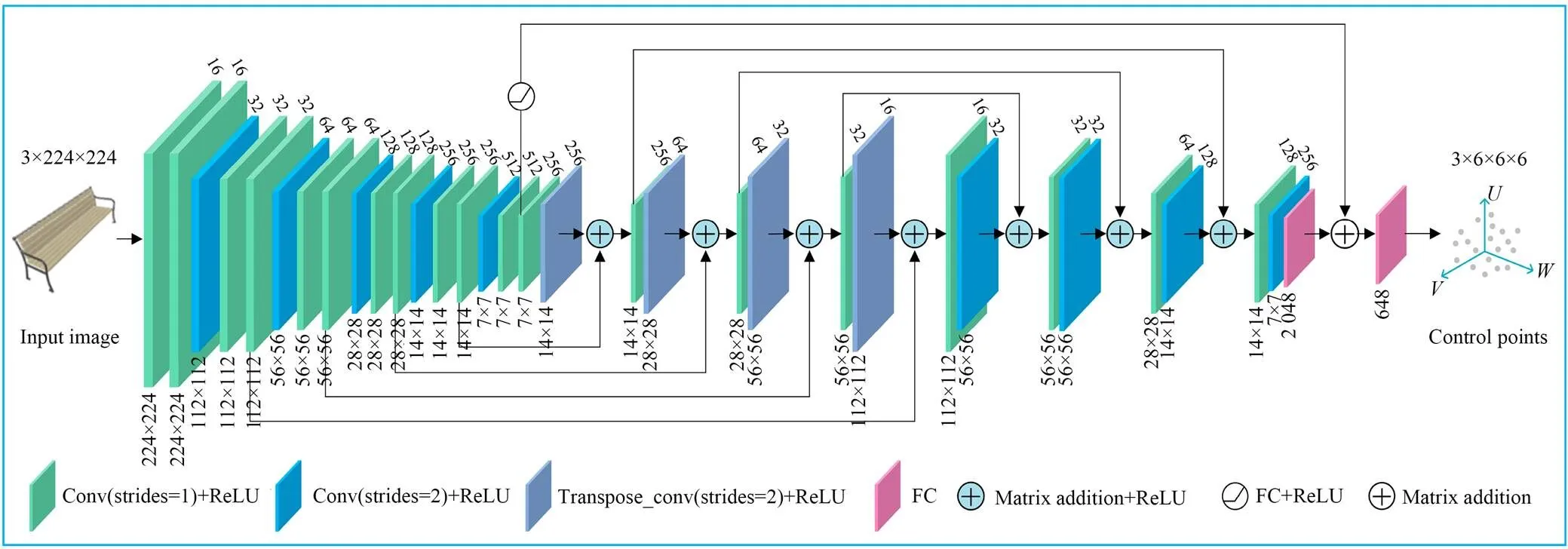
图2 控制点生成网络结构
2.2 NFFD自由形变模型
基于非均匀有理B样条曲面自由形变,采用非均匀控制点矩阵对曲面进行约束,能够有效提升模型形变精度[19-20]。NFFD方法形变过程描述如下:
首先根据输入图像的类别,从模型数据库选择模型点云,其中每个类别对应一种模型点云。建立方向上的局部坐标系,定义模型点云顶点的三元组坐标,记为(,,)。CPGN根据输入图像生成对应三维模型的控制点坐标形变量,并与初始控制点坐标相加,获得最终的控制点坐标。
初始控制点在各个方向上均匀分布,设在三个方向上分别有个控制点,已知坐标系原点为,则初始控制点p的坐标满足如下公式:
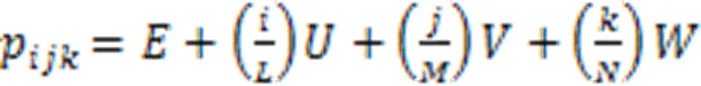
设p为最终的控制点坐标,形变后点云模型的顶点坐标由公式(2)定义:
(2)

通常,B样条基函数的次数与控制点影响的区域正相关。在三个方向上,B样条基函数的次数满足以下条件:
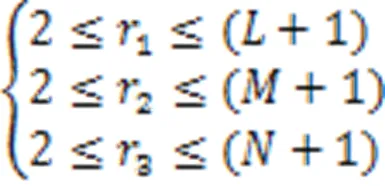
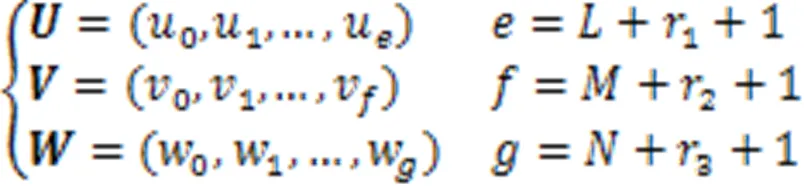
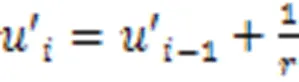
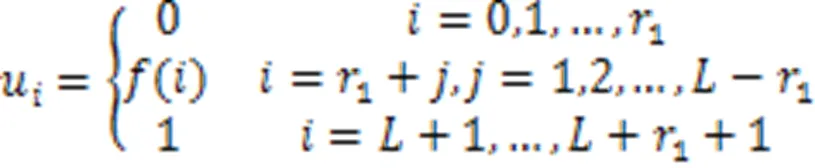
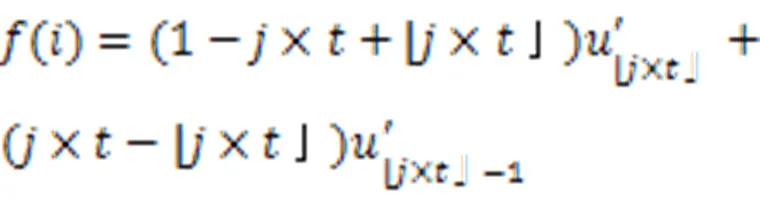
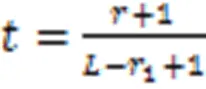
2.3 图卷积点云形变模块
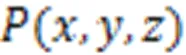
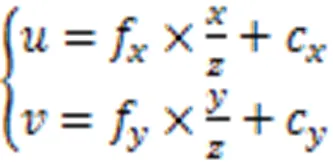
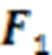
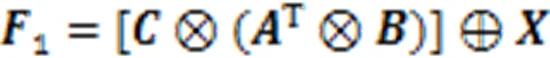
通道注意力模块能有效提取通道间有用的信息。输入特征经过与自身两次矩阵相乘后,再与自身相加获得输出特征。通道注意力模块的表达式为:
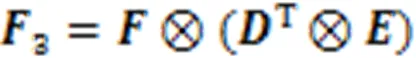
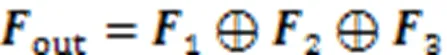
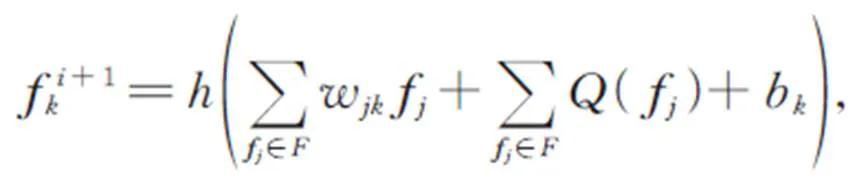
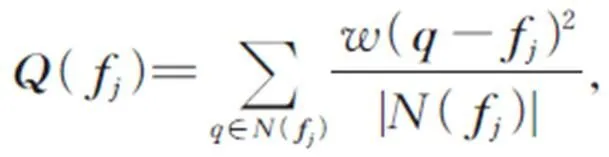
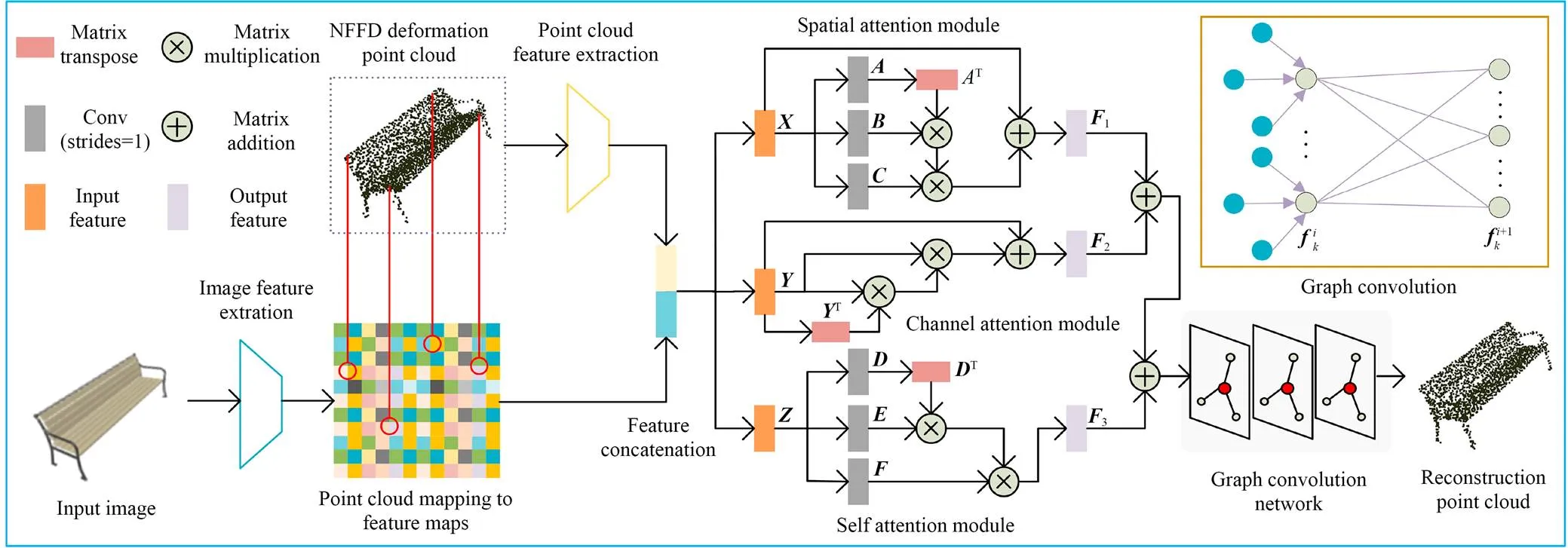
图3 图卷积点云形变模块
2.4 损失函数
为实现对点云的位置进行预测,采用EMD、CD、等距先验损失与对称损失作为模型训练的损失函数,具体定义如下:
241Earth mover’s distance(EMD)
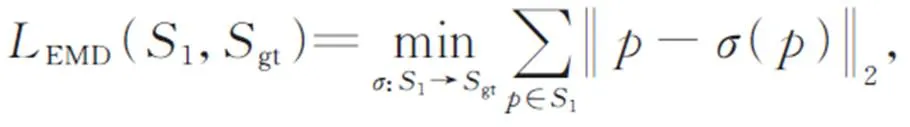
242倒角距离(CD)
倒角距离(CD)用于衡量两组点云之间的距离。形式上被定义为:
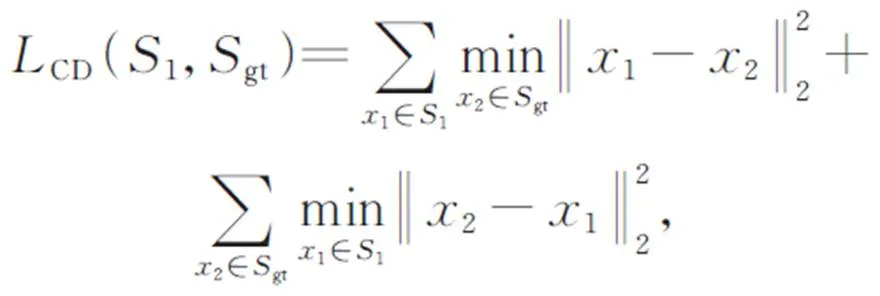
243等距先验损失
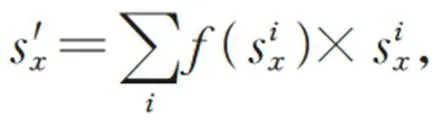
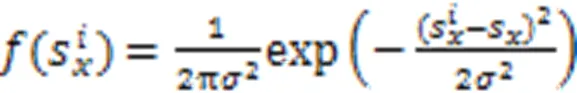
等距先验损失定义如下:
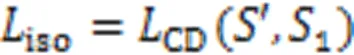
244对称损失
为了使形变过程中的点云模型保持对称性,引入点云的对称损失函数,即:
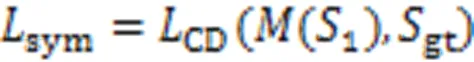
245归一化
总损失函数为上述各项损失函数之和:

3 实验结果与讨论
3.1 模型训练细节
在所有的实验中,模型输入均为RGB彩色图像,输出顶点数为2 048的三维点云。同时,为了端到端训练图卷积网络,在实验中使用了Adam优化器[26],学习率初始化为5×105。模型的迭代次数为50个epoch,批量大小(Batchsize)为32。所有实验均在NVIDIA GeForce GTX1080Ti GPU上使用开源机器学习框架Pytorch实现。
3.2 实验数据和评价标准
为评估本文所提算法的重建性能,使用了ShapeNet[27]合成数据集和Pix3D[28]真实场景数据集进行实验。ShapeNet中共有13个模型类别,共51 300个3D模型,将部分遮挡或截断的数据排除,并按照4:1的比例随机划分训练集与测试集。同样对Pix3D数据集做了预处理,用提供的背景遮罩信息去除无用背景并将物体移动至中心位置,最终将图像缩放或裁剪至224×224作为输入图像。
此外,本文使用IoU(Intersection-over-Union)、CD和EMD作为实验结果的衡量指标。IoU表示网络重建的3D体素形状与真实体素形状的交并比,这里采用与PSGN[9]相同的体素生成方法。CD与EMD表示两个点云之间的差异性,这里对GT点云进行采样,生成顶点数为2 048的点云模型,并与本文重建点云进行对比。
3.3 损失函数分析
对本文提出的损失函数设计策略的鲁棒性进行验证如图4所示,图4(a)展示了损失函数在不同训练集上的效果对比。通过对比可知,在三种不同的训练集上,损失函数在训练中总体保持不断下降的趋势,训练集的损失函数在前20次epoch中下降较为迅速,而在第40次之后总体趋于稳定,可知本文方法具有较高的鲁棒性。进一步,图4(b)展示了图卷积点云形变过程中损失函数收敛情况。通过图4(b)可以看到图卷积形变阶段网络收敛结果较好,表明模型具有较好的三维重建效果。
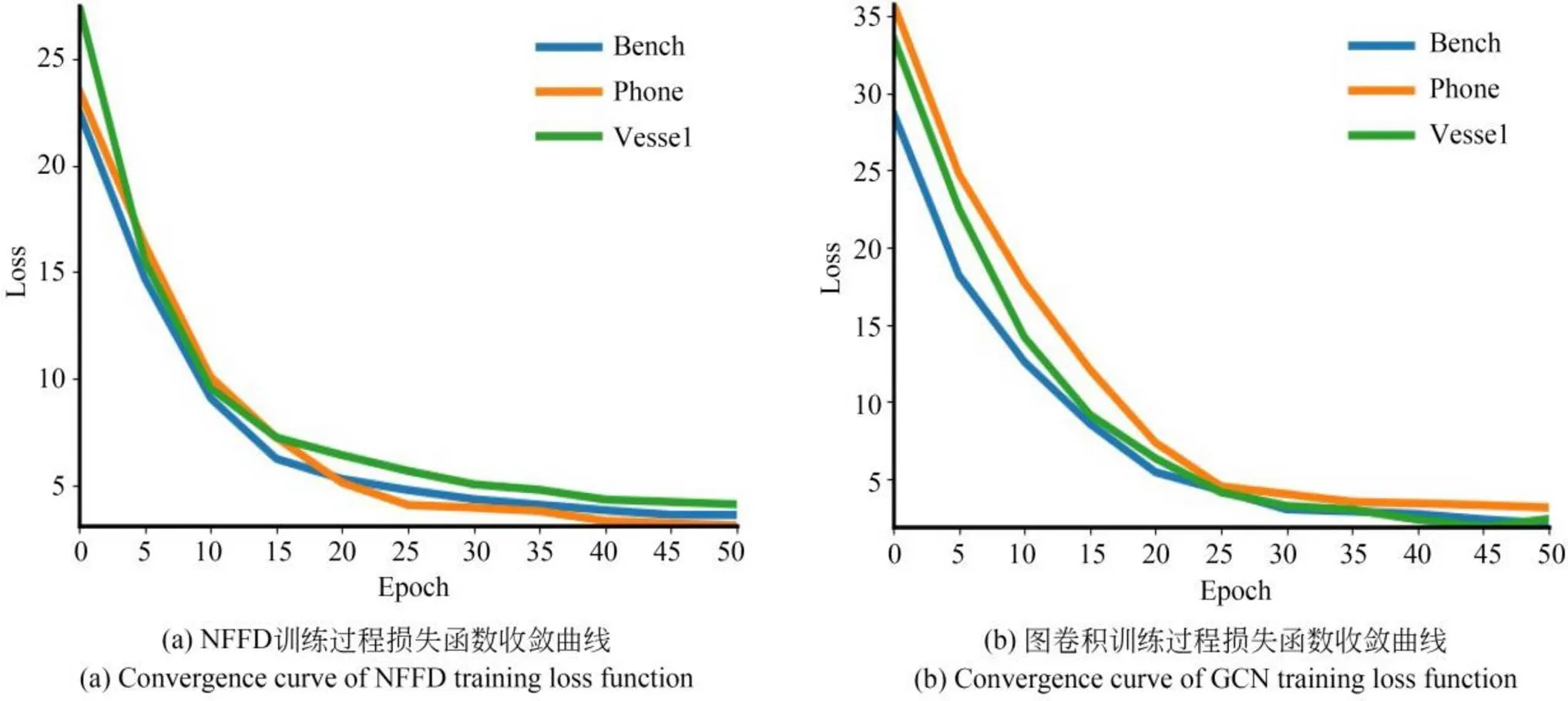
图4 训练过程损失函数收敛曲线
3.4 实验结果定性比较
图5展示了本文方法与3D-LMNet[29]、Occupancy networks[30]、DISN[31]与PSGN在lamp、phone与monitor数据集上的重建结果对比。通过观察可以发现,本文方法在不同数据集下的重建精度均高于其他方法。对于不同的几何结构都有良好的表达能力,并保留更多细节。

图5 本文三维重建结果与3D-LMNet、Occupancy networks、DISN、PSGN对比
图6展示了本文方法和Pixel2Mesh[14]、DISN、PSGN方法在bench与airplane数据集上对比结果。为了更好地展示对比效果,这里选取三种不同的Pixel2Mesh模型。可以看出,在非孔洞的airplane模型中,VGG-Pixel2Mesh重建效果与本文方法差别不大,优于其他两种Pixel2Mesh方法;在有孔洞的模型中,本文方法明显具有更好的重建效果,能够更准确地表达物体的拓扑结构。
为了进一步展示本文方法的三维重建效果,在rifle、monitor和chair数据集上与VGG-Pixel2Mesh、Occupancy networks、DISN和PSGN四种方法进行比较。如图7所示,本文方法在rifle与monitor数据集上的重建效果要优于其他方法,更加接近GT。在chair数据集中,本文重建效果与Pixel2Mesh、Occupancy networks和DISN相近,均取得较好的重建效果。但本文重建的点云模型分布更加均匀,细节更加准确,视觉效果更好。在图7中,Occupancy networks方法对第四幅输入图像的重建效果较好。但总体来看,本文重建效果的细节更加准确。
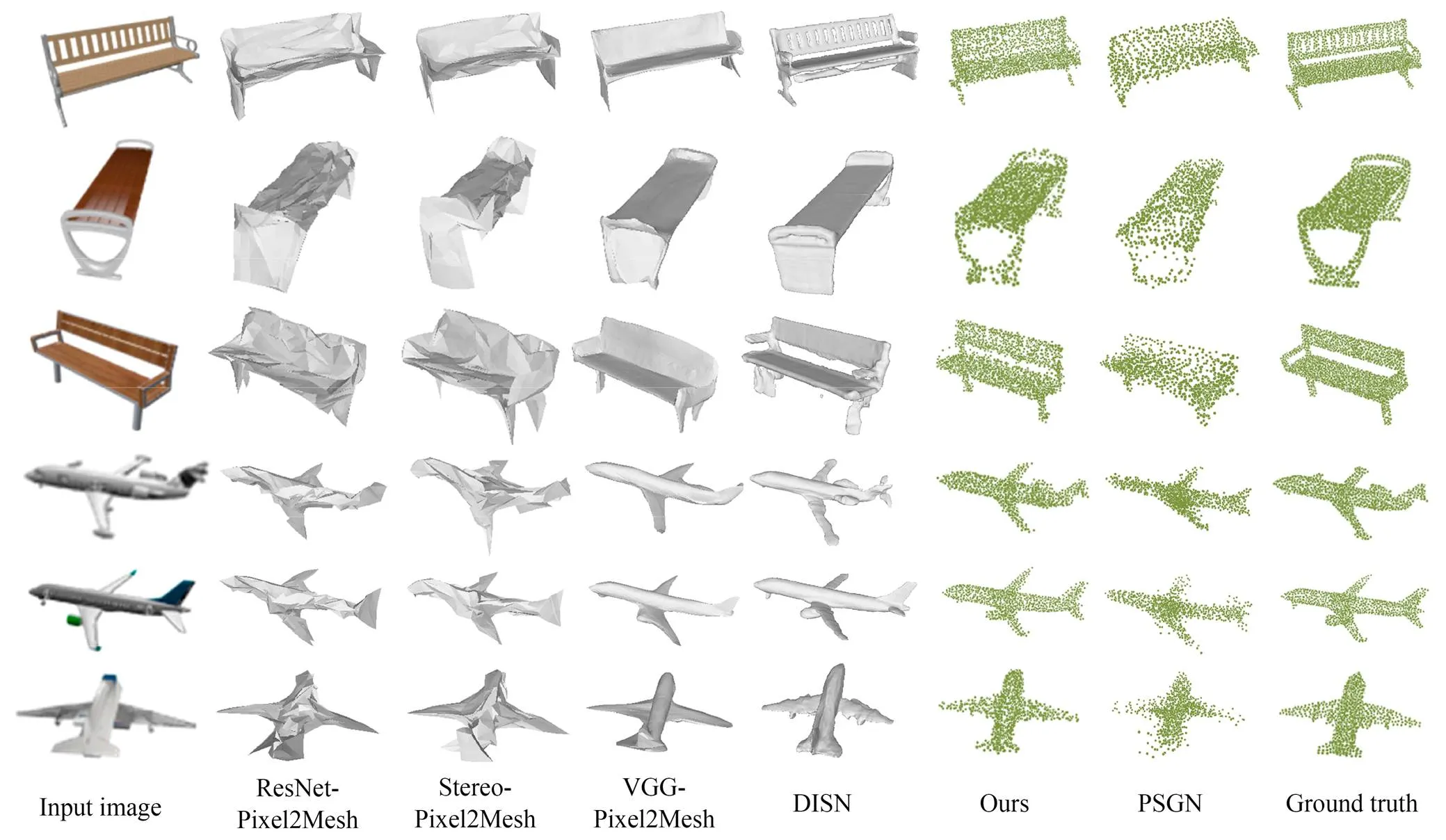
图6 本文三维重建结果与Pixel2Mesh、DISN与PSGN对比

图7 本文三维重建结果与VGG-Pixel2Mesh、Occupancy networks、DISN与PSGN对比
3.5 实验结果定量比较
为了定量分析本文的方法和其他方法的差异,表1展示了在ShapeNet数据集中的重建精度对比。将评价指标缩放100倍,与PSGN、3D-LMNet和pix2point[32]方法比较,在CD评价指标上,本文方法在airplane等13个类别上取得了更高的重建精度;同样在EMD评价指标上,本文方法在所有类别均优于其他方法。在平均重建精度上,CD和EMD比其他方法均有较大的提高。
表1CD、EMD评价指标
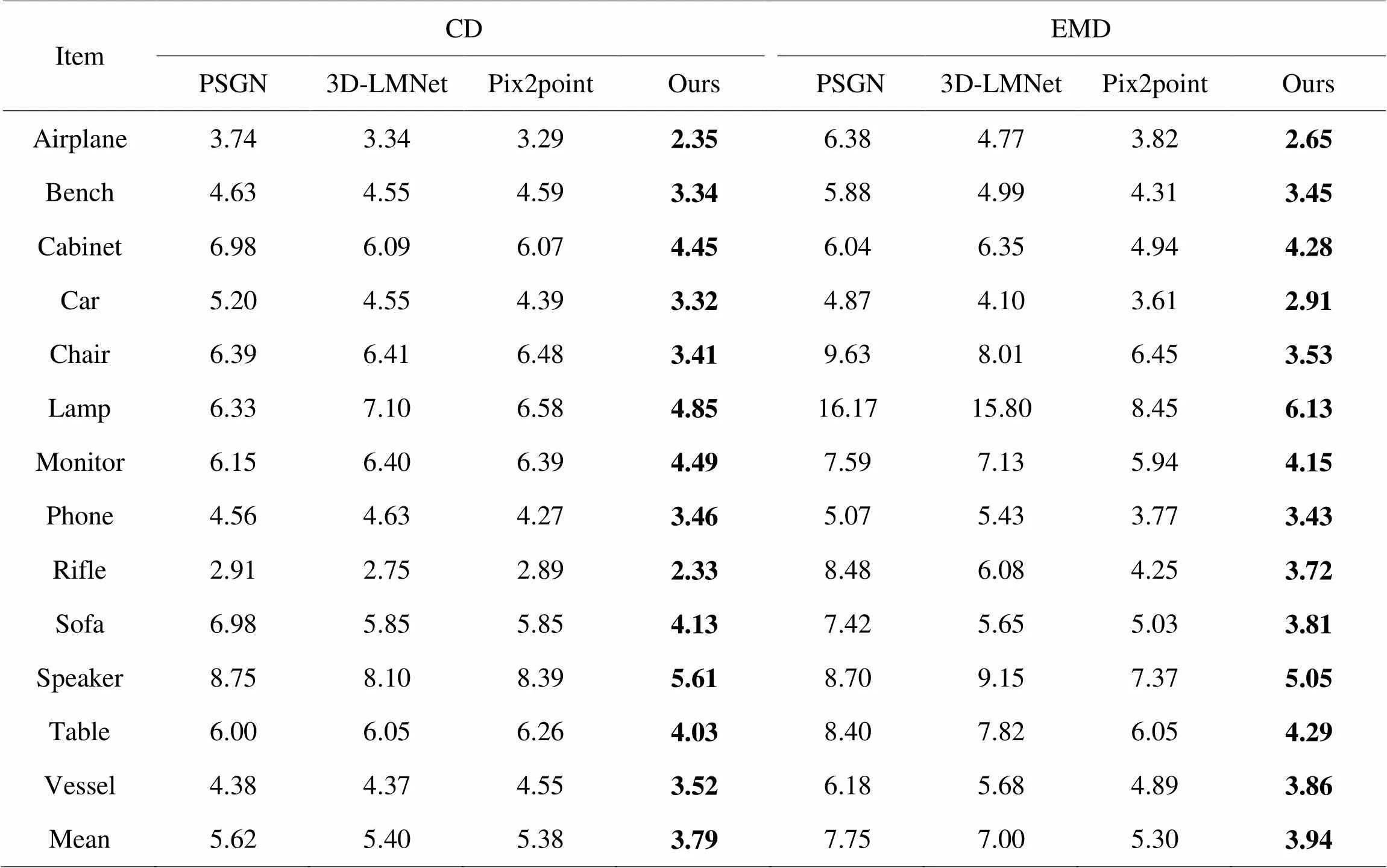
Tab.1 CD、EMD evaluation indicators
进一步地,我们对比了本文方法与PSGN、3D-R2N2在不同类别中IoU的差异。从表2可以看出,本文方法在airplane等8个类别中IoU较高,PSGN在sofa与speaker类别中IoU较高。3D-R2N2在5视图重建下,在cabinet、car与phone类别取得最好表现。但在平均IoU上,本文比3D-R2N2在5视图下提升7.7%,比PSGN提升6.25%。
表2IoU评价指标
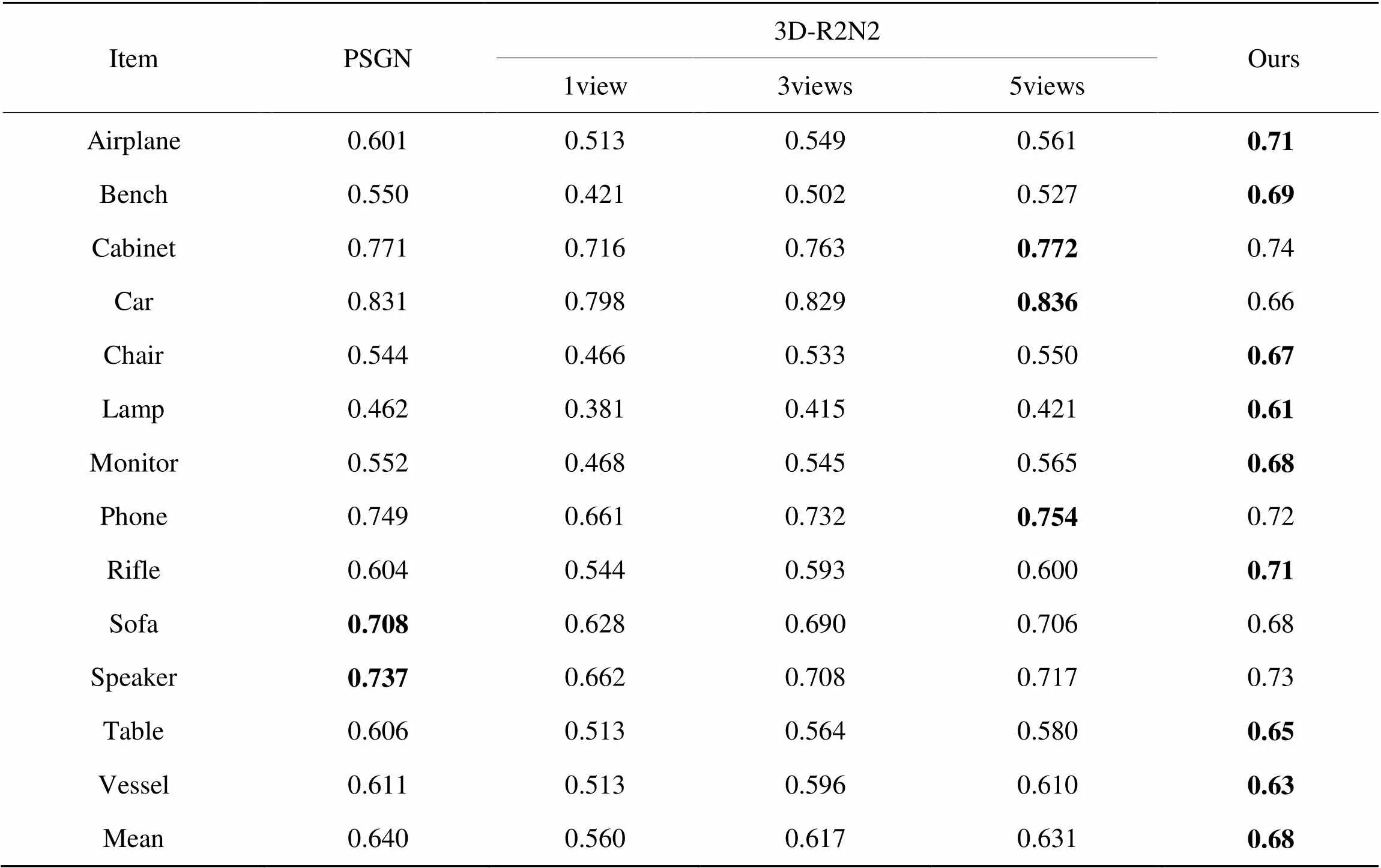
Tab.2 IoU evaluation indicators
3.6 消融实验
361图卷积模块消融实验
本文2.3节利用图卷积模块对NFFD重建点云模型进行调整。为了验证该方法的有效性,这里将图卷积模块替换为普通的全连接层,并对模型进行训练与测试。使用CD与EMD两个指标来衡量生成点云的质量,测试结果如表3所示。
从表3可以发现,加入图卷积模块后,CD与EMD在大部分数据集上均有一定提升,但在部分数据集略有下降。其中,CD平均提升0.11,EMD平均提升0.06。对于CD指标,chair数据集提升0.32;对于EMD指标,monitor数据集提升0.40。由此可知,引入图卷积模块可以有效提升点云的重建精度。
表3图卷积消融实验评价指标
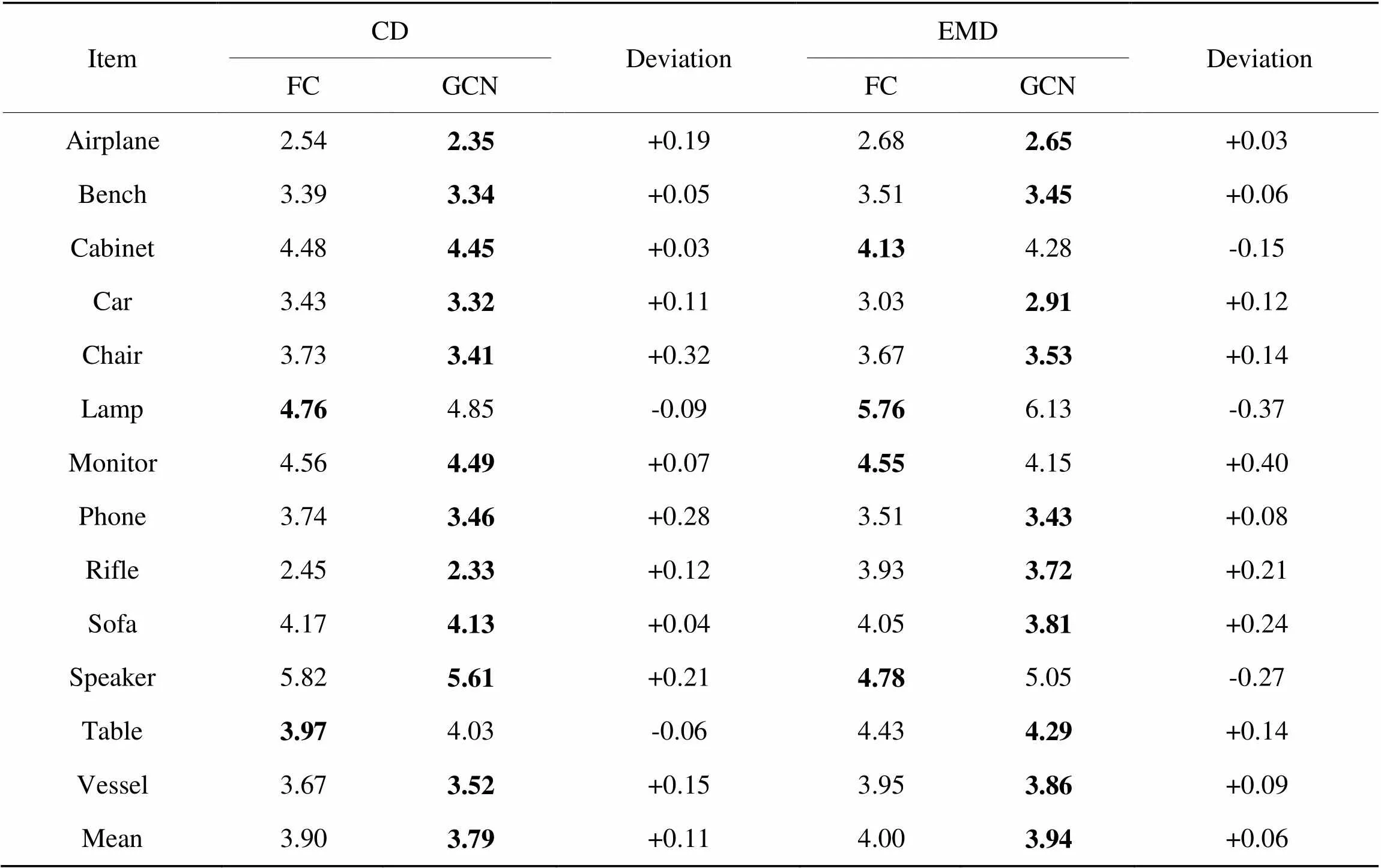
Tab.3 Evaluation indicators of GCN ablation experiments
为了验证NFFD点云映射图像特征图的有效性,针对bench数据集,去除图卷积模块的NFFD点云映射图像特征图,并重新训练网络。经过测试,未添加映射操作,CD评价指标为3.348 6,添加点云映射图像特征图操作后,CD评价指标为3.342 0,验证了点云映射图像特征图的有效性。
为了验证NFFD形变网络性能,在bench、monitor与phone数据集上训练并测试评价指标。如表4所示,加入图卷积模块后,不同数据集的评价指标均有提升,CD指标平均提升0.35,EMD指标平均提升0.52。由此证明所提出的图卷积模块对点云坐标具有良好的预测性。
表4NFFD消融实验评价指标
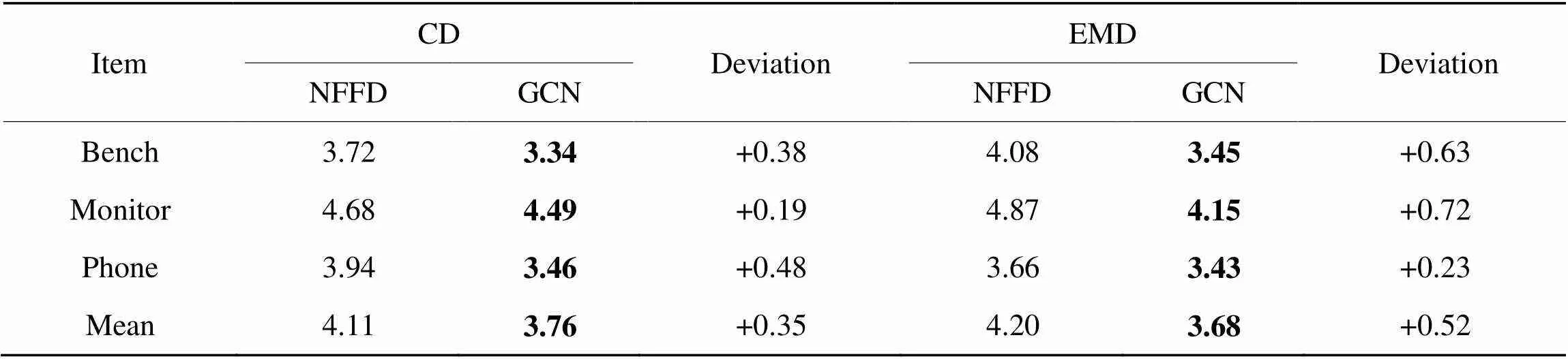
Tab.4 Evaluation indicators of NFFD ablation experiments
362损失函数消融实验
为了验证本文采用损失函数的有效性,选取不同的损失函数组合,并对模型进行重新训练,基于bench、rifle与vessel数据集,测试结果如表5所示。观察表5可知,采用全部损失函数后,CD指标取得较好表现,超过其他两种策略,且对不同数据集均有效,提高了模型的泛化性能。
表5损失函数消融实验CD对比

Tab.5 CD comparison of loss function ablation experiments
363控制点生成网络消融实验
为了验证CPGN设计合理性,我们将CPGN解码器中步长为1的卷积替换为平均池化,将反卷积替换为反池化,并重新训练网络。测试过程中,随机选取bench数据集80幅图像,分别用两种网络生成控制点,采用NFFD方法进行三维重建。其中,卷积-反卷积CPGN的CD指标平均值为3.69,而池化-反池化CPGN的CD指标平均值为3.93,比卷积-反卷积CPGN减少约6.50%。由此说明本文CPGN的网络结构设计的合理性。
进一步,与文献[33]的控制点生成网络对比,以car数据集为例,随机选取100幅图像进行测试。通过对比,CPGN效果更好,评价指标CD与EMD的数值更小,比文献[33]的控制点生成网络提升3.81%。
364混合注意力模块消融实验
为了验证2.3节图卷积网络中混合注意力模块的作用,本节去除混合注意力模块,重新训练网络。以bench数据集为例,添加混合注意力模块后,模型的收敛效果更好,局部细节得到一定提升,更加接近GT点云,如图8所示。
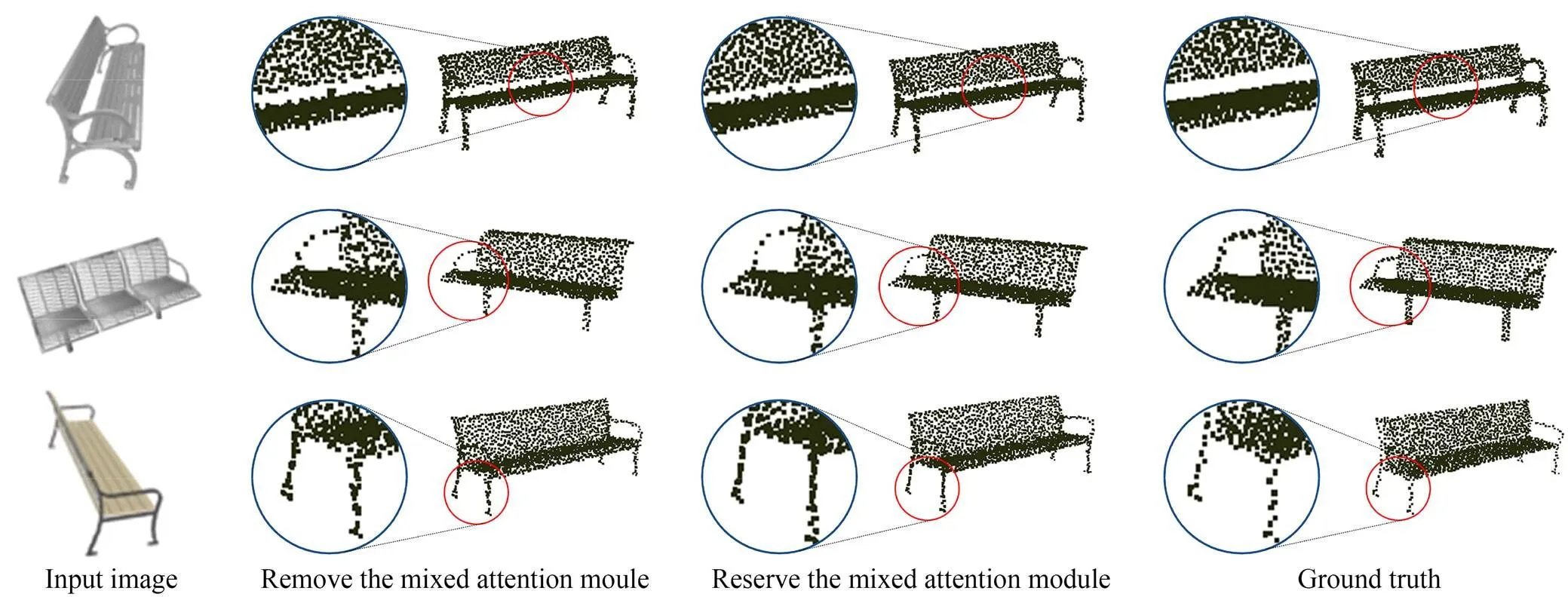
图8 混合注意力模块对点云局部细节的影响
3.7 真实场景三维重建
本文选取了Pix3D数据集中真实场景下的图像进行了三维重建,以验证所提出方法的适应性和泛化能力。图9展示了本文方法对于不同场景的重建效果。如图9所示,本文方法在包含椅子、桌子与沙发三个类别的真实场景中达到较好的三维重建效果。

图9 本文真实场景三维重建效果
4 结 论
本文提出了一种融合NFFD与图卷积的点云三维重建网络。设计了控制点生成网络对2D视图进行特征学习,获得其控制点拓扑结构。为了实现高质量的3D点云重建模型,利用NURBS基函数对控制点坐标自适应特性建立点云模型轮廓间顶点的形变关系,并在此基础上将混合注意力模块嵌入图卷积网络对形变后的点云位置进行调整。在ShapeNet数据集的实验表明,CD指标平均值为3.79,EMD指标平均值为3.94,本文所提出的方法提升了单视图的三维重建结果,能够从不同角度保持重建的一致性。未来将优化图卷积网络模型,进一步提高点云重建精度。
[1] JIN Y W, JIANG D Q, CAI M. 3D reconstruction using deep learning: a survey[J]., 2020, 20(4): 389-413.
[2] FAHIM G, AMIN K, ZARIF S. Single-View 3D reconstruction: a Survey of deep learning methods[J]., 2021, 94: 164-190.
[3] HENDERSON P, FERRARI V. Learning single-image 3D reconstruction by generative modelling of shape, pose and shading[J]., 2020, 128(4): 835-854.
[4] CHOY C B, XU D F, GWAK J,. 322:3[M]. Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 628-644.
[5] 李雷,徐浩,吴素萍. 基于DDPG的三维重建模糊概率点推理[J]. 自动化学报, 2022, 48(4): 1105-1118.
LI L, XU H, WU S P. Fuzzy Probability Points Reasoning for 3D Reconstruction via Deep Deterministic Policy Gradient[J]., 2022, 48(4): 1105-1118. (in Chinese)
[6] 夏清,李帅,郝爱民,等. 基于深度学习的数字几何处理与分析技术研究进展[J]. 计算机研究与发展, 2019, 56(1): 155-182.
XIA Q, LI S, HAO A M,. Deep learning for digital geometry processing and analysis: a review[J]., 2019, 56(1): 155-182.(in Chinese)
[7] CHENG Q Q, SUN P Y, YANG C S,. A morphing-Based 3D point cloud reconstruction framework for medical image processing[J]., 2020, 193: 105495.
[8] JIN P, LIU S L, LIU J H,. Weakly-supervised single-view dense 3D point cloud reconstruction via differentiable renderer[J]., 2021, 34: 93.
[9] FAN H Q, SU H, GUIBAS L. A point set generation network for 3D object reconstruction from a single image[C]. 20172126,2017,,,IEEE, 2017: 2463-2471.
[10] ZHANG S F, LIU J, LIU Y H,. DIMNet: Dense implicit function network for 3D human body reconstruction[J]., 2021, 98: 1-10.
[11] YANG B, ROSA S, MARKHAM A,. Dense 3D object reconstruction from a single depth view[J]., 2019, 41(12): 2820-2834.
[12] WU Z H, PAN S R, CHEN F W,. A comprehensive survey on graph neural networks[J]., 2021, 32(1): 4-24.
[13] VALSESIA D, FRACASTORO G, MAGLI E. Learning localized representations of point clouds with graph-convolutional generative adversarial networks[J]., 2021, 23: 402-414.
[14] WANG N Y, ZHANG Y D, LI Z W,. Pixel2Mesh: generating 3D mesh models from single RGB images[C].(). 2008:52-67
[15] NGUYEN D, CHOI S, KIM W,. GraphX-convolution for point cloud deformation in 2D-to-3D conversion[C]. 2019()272,2019,,(). IEEE, 2019: 8627-8636.
[16] KURENKOV A, JI J W, GARG A,. DeformNet: free-form deformation network for 3D shape reconstruction from a single image[C]. 20181215,2018,,,IEEE, 2018: 858-866.
[17] PONTES J K, KONG C, SRIDHARAN S,.2:3[M]. Computer Vision-ACCV 2018. Cham: Springer International Publishing, 2019: 365-381.
[18] LAMOUSIN H J, WAGGENSPACK N N. NURBS-based free-form deformations[J]., 1994, 14(6): 59-65.
[19] TAO J, SUN G, SI J Z,. A robust design for a winglet based on NURBS-FFD method and PSO algorithm[J]., 2017, 70: 568-577.
[20] ORAZI L, REGGIANI B. Point inversion for triparametric NURBS[J].(), 2021, 15(1): 55-61.
[21] 孟月波,金丹,刘光辉,等. 共享核空洞卷积与注意力引导FPN文本检测[J]. 光学精密工程, 2021, 29(8): 1955-1967.
MENG Y B, JIN D, LIU G H,. Text detection with kernel-sharing dilated convolutions and attention-guided FPN[J]., 2021, 29(8): 1955-1967.(in Chinese)
[22] 李经宇,杨静,孔斌,等. 基于注意力机制的多尺度车辆行人检测算法[J]. 光学精密工程, 2021, 29(6): 1448-1458.
LI J Y, YANG J, KONG B,. Multi-scale vehicle and pedestrian detection algorithm based on attention mechanism[J]., 2021, 29(6): 1448-1458.(in Chinese)
[23] 蔡体健,彭潇雨,石亚鹏,等. 通道注意力与残差级联的图像超分辨率重建[J]. 光学精密工程, 2021, 29(1): 142-151.
CAI T J, PENG X Y, SHI Y P,. Channel attention and residual concatenation network for image super-resolution[J]., 2021, 29(1): 142-151.(in Chinese)
[24] 秦传波,宋子玉,曾军英,等. 联合多尺度和注意力-残差的深度监督乳腺癌分割[J]. 光学精密工程, 2021, 29(4): 877-895.
QIN C B, SONG Z Y, ZENG J Y,. Deeply supervised breast cancer segmentation combined with multi-scale and attention-residuals[J]., 2021, 29(4): 877-895.(in Chinese)
[25] MA J Y, ZHANG H, YI P,. SCSCN: a separated channel-spatial convolution net with attention for single-view reconstruction[J]., 2020, 67(10): 8649-8658.
[26] KINGMA D P, BA J. Adam: a method for stochastic optimization[EB/OL]. 2014:: 1412.6980[cs.LG]. https://arxiv.org/abs/1412.6980
[27] CHANG A X, FUNKHOUSER T A, GUIBAS L J,. ShapeNet: an information-rich 3D model repository[J]., 2015, abs/1512.03012.
[28] SUN X Y, WU J J, ZHANG X M,. Pix3D: dataset and methods for single-image 3D shape modeling[C]. 20181823,2018,,,IEEE, 2018: 2974-2983.
[29] MANDIKAL P, MURTHY N, AGARWAL M,. 3D-LMNet: latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image[C].,:, 2018.55-56.
[30] MESCHEDER L, OECHSLE M, NIEMEYER M,. Occupancy networks: learning 3D reconstruction in function space[C]. 2019()1520,2019,,,IEEE, 2019: 4455-4465.
[31] XU Q G, WANG W Y, CEYLAN D,. DISN: deep implicit surface network for high-quality single-view 3D reconstruction[J]., 2019, 32: 492-502.
[32] AFIFI A J, MAGNUSSON J, SOOMRO T A,. Pixel2point: 3D object reconstruction from a single image using CNN and initial sphere[J]., 2020, 9: 110-121.
[33] JACK D, PONTES J K, SRIDHARAN S,. Learning free-form deformations for 3D object reconstruction[C].2018, 2019: 317-333.
Single-view 3D object reconstruction based on NFFD and graph convolution
LIAN Yuanfeng1,2*,PEI Shoushuang1,HU Wei1
(1,,102249,;2,102249,),:
To address the issue of inaccurate single-view three-dimensional (3D) object reconstruction results caused by complex topological objects and the absence of irregular surface details, a novel single-view 3D object reconstruction method combining non-uniform rational B-spline free deformation with a graph convolution neural network is proposed. First, a control points generation network, which introduces the connection weight policy, is used for the feature learning of two-dimensional views to obtain their control points topology. Subsequently, the NURBS basis function is used to establish the deformation relationship between the vertex contours of the point cloud model. Finally, to enhance the details, a convolutional network embedded with a mixed attention module is used to adjust the position of the deformed point cloud to reconstruct complex topological structures and irregular surfaces efficiently. Experiments on ShapeNet data show that the average values of the CD and EMD indices are 3.79 and 3.94, respectively, and that good reconstruction is achieved on the Pix3D real scene dataset. In contrast to existing single view point cloud 3D reconstruction methods, the proposed method offers a higher reconstruction accuracy of 3D objects and demonstrates higher robustness.
NURBS-based free-form deformation; 3D reconstruction; graph convolution network; mixed attention; control points generation network
TP391
A
10.37188/OPE.20223010.1189
1004-924X(2022)10-1189-14
2021-11-10;
2021-12-08.
国家自然科学基金资助项目(No.61972353);中国石油天然气集团有限公司-中国石油大学(北京)战略合作科技专项:“一带一路”海外长输管道完整性关键技术研究与应用项目(No.2006A10401006)
连远锋(1977-),男,吉林延吉人,博士,副教授,硕士生导师,2012年于北京航空航天大学获得博士学位,主要研究方向为图像处理与虚拟现实、机器视觉与机器人、深度学习与数字几何。E-mail:lianyuanfeng@cup.edu.cn

裴守爽(1997-),男,河北唐山人,硕士研究生,2020 年于河北农业大学取得学士学位,主要研究方向为深度学习与三维重建。E-mail:peishoushuang@163.com
