基于机器学习算法的核电结构材料性能预测
2022-06-01颜达鹏崔予文
王 卓 朱 虹 许 斌 颜达鹏 杜 华 罗 亮 崔予文,4
(1.中南大学轻合金研究院,湖南 长沙 410083;2.成都材智科技有限公司,四川 成都 610041;3.中国核动力研究设计院核反应堆系统设计技术重点实验室,四川 成都 610213;4.南京工业大学,江苏 南京 210009)
自1954年第一座核电站在苏联建成至今已过去60多年,核能作为高效、清洁、安全的能源备受国际社会的关注,核电技术也随之不断发展、完善,更新到了第四代,展现出广阔的应用前景。随着我国经济水平和综合国力的不断提升,对能源的需求也呈现递增态势,导致能源短缺问题日渐突出[1-3]。因此,核能作为目前唯一能达到大规模商用的替代能源,其发展可有效提高国家能源安全保障能力。我国核电工业发展大致经历了起步、适度发展和快速发展等3个阶段,逐步形成了完整的研发设计、工程建造、运行维护、燃料保障、设备配置、生产制造等全产业链体系,同时安全高效地发展核能成为我国能源电力发展战略的重要组成部分[4-7]。
核电结构材料的设计研发作为核电技术发展的关键,同样也是核电站使用寿命和安全运行的重要影响因素。福岛核事故之后,国际对核电技术发展的安全性提出了更高要求,亟待寻找各项性能更具竞争力的新核电结构材料来进一步优化核电效能,提高其寿命周期[8-10]。目前,我国在建和使用的核电结构材料主要包括镍基合金、奥氏体不锈钢、低合金钢和碳钢等,其测试及服役常在高温、高压、强辐射等苛刻条件下进行,性能数据获取十分不易。然而,传统材料开发方式步骤繁琐,研发到应用周期冗长且达不到预期性能效果,仅靠人力更无法挖掘材料特征与性能之间的深层联系[11-12]。因此,在材料理论研究的发展过程中,人们将试验与计算模拟产生的数据整合形成一定规模的数据库,在材料数据库的基础上,进一步采用机器学习方法针对核电结构材料的各项属性建立代理模型(surrogate model),从而实现对材料性能的快速预测,例如Wicker等[13]采用支持向量机器学习算法预测了分子材料的结晶度;Stanev等[14]通过机器学习模型得到了模拟超导体的临界温度;Voyles等[15]通过机器学习算法提高了材料显微镜数据的质量,以进一步深挖材料信息。以上示例说明机器学习已在多行业多领域有了重要应用,因此通过机器学习构建核电结构材料数据库,不仅可以加快材料的设计进程,缩短研发周期,还可为实现对材料目标属性或性能定制打开新的蓝图[16-17]。
本文对机器学习方法的主要思想和基本步骤进行了概述,介绍了机器学习应用平台及其系统功能模块和流程结构,展示了机器学习系统通过模型构建和应用包装两种途径对核电结构材料性能进行预测的步骤,对进一步研究机器学习方法在核电结构材料性能预测乃至新材料的发现方面具有参考意义。
1 机器学习原理和方法
机器学习(machine learning)是由模式识别、人工智能计算学习理论为基础所转变的一类计算机科学分支,其目的是根据大数据和历史情况来训练模型[18-19]。一方面机器学习能够在不明确潜在物理机制或没有物理模型的情况下,从可用数据中获取性能和预测发展趋势;另一方面,已经建立的机器学习模型可反过来用于材料的发现和性能设计。因此,作为人工智能核心之一的机器学习方法,现已在材料科学领域取得了一系列应用成果,其中包括预测钢疲劳强度、金属催化活性、合金的物理机械性质和光伏材料的鉴定等,成为材料发展的一种创新模式[20-23]。目前,可选择不同的机器学习算法对大量材料数据集进行性能参数的预测,不同算法对不同材料数据集中数据的敏感度也不同,需要对样本数据进行有针对性的选择,然后再通过相对应的性能评估手段进行比较和评估。机器学习的性能预测模型工作流程如图1所示。在建立模型之前,将原始材料数据集按比例划分为训练集和测试集(如80%为训练集,20%为测试集),通过训练集中的数据对算法模型进行训练,再利用训练后的模型对测试集中的数据进行预测,最终得到模拟结果。

图1 机器学习性能预测模型工作流程图Fig.1 Workflow chart of machine learning prediction model
1.1 机器学习方法
目前,在建立模型时可用到的算法主要有随机森林、支持向量回归和神经网络等。
随机森林(random forest)回归算法是由Breiman于2001年提出的,其基本思想源于统计学理论[24]。随机森林是由决策树组合成的算法,用随机方式建立很多决策树而组成森林,决策树间并没有关联,利用bootstrap[25](又称为自助法,用于估计或修正统计估计值的偏差或方差信息)在训练集中随机抽取N个样本,假设每个样本构造决策树,通过所有决策树预测值的平均值计算得出最终预测值。
支持向量机(support vector machine)是运用支持向量机来解决回归问题的方法,其基本思想是建立在统计学习理论基础上,通过一个非线性映射φ,将数据x映射到高维特征空间F,在这个空间进行线性回归,其优势是可以解决小样本数据集、非线性及高维模式识别,可以推广至函数拟合等其他机器学习问题中[26]。
神经网络(neural network)算法是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算,由输入层、隐藏层(即中间层)和输出层3层结构组成[18],其中输入、输出层的神经元个数是根据具体问题来确定的,而中间层则通常由经验确定,确定好结构后可对其通过输入输出样本集及逆行训练,网络经过训练后,输入输出的映射关系得以实现,设输入1个训练样本Xn,输出层的神经元为:
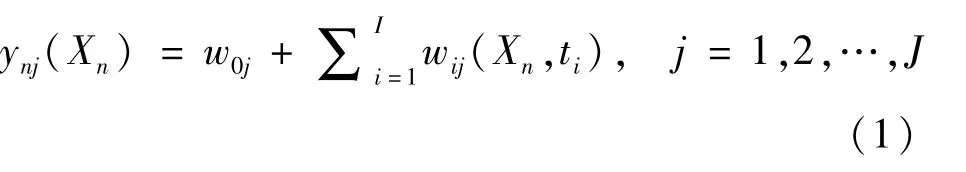
式中:I为隐藏层神经元个数;N为训练样本组数;J为输出层神经元个数;w为输入层与输出层间权值。基函数为高斯函数时,可表示为:
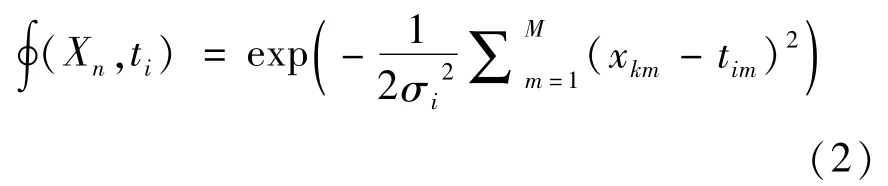
式中:σi为高斯函数方差;tim为基函数的中心;M为输入层神经元个数。
1.2 预测算法性能评估
通常采用均方误差MSE(mean squared error)、均方根误差RMSE (root mean squared error)、平均绝对误差MAE(mean absolute error)作为学习器的泛化性能评价指标,校正决定系数R2(adjusted R-square)则用以衡量预测值与实际值的吻合程度,计算公式为:
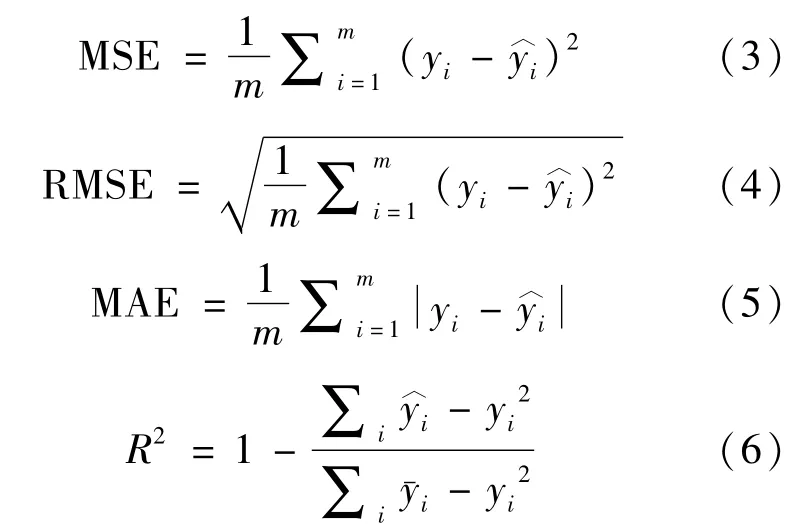
式中:m为样本数量;yi为真实值;为预测值。前3个指标根据不同的业务有不同的值,不具有可读性,最后可根据R2的取值来判断模型的优劣,其取值范围是[0,1],如果是0,说明拟合效果很差,如果是1,说明模型准确预测。
2 核电结构材料机器学习系统功能使用流程
核电结构材料在核电站的建设应用中扮演着重要角色,其中合金占绝大部分,而且合金材料具有化学元素的多样性。理论上这类材料的数据达上万种,因此可作为机器学习预测材料性能甚至到设计新材料的理想应用体系。本文选择通过构建机器学习平台实现模型训练和模型应用的双功能,模型方面主要针对专业用户,以工作流的方式实现用户自定义算法、评价方法及数据预处理过程,完成机器学习模型的构建,可重复进行模型训练;应用部分则可支持将模型配置成操作简单的应用供普通用户直接使用,方便其完成机器学习预测,并得到性能预测结果和可视化分析。图2是材料数据机器学习系统的基础建设框架层级图,以B/S架构来构建整个系统,从底层数据资源到应用层面总共划分为4个层级,应用层面可满足不同业务场景需求。
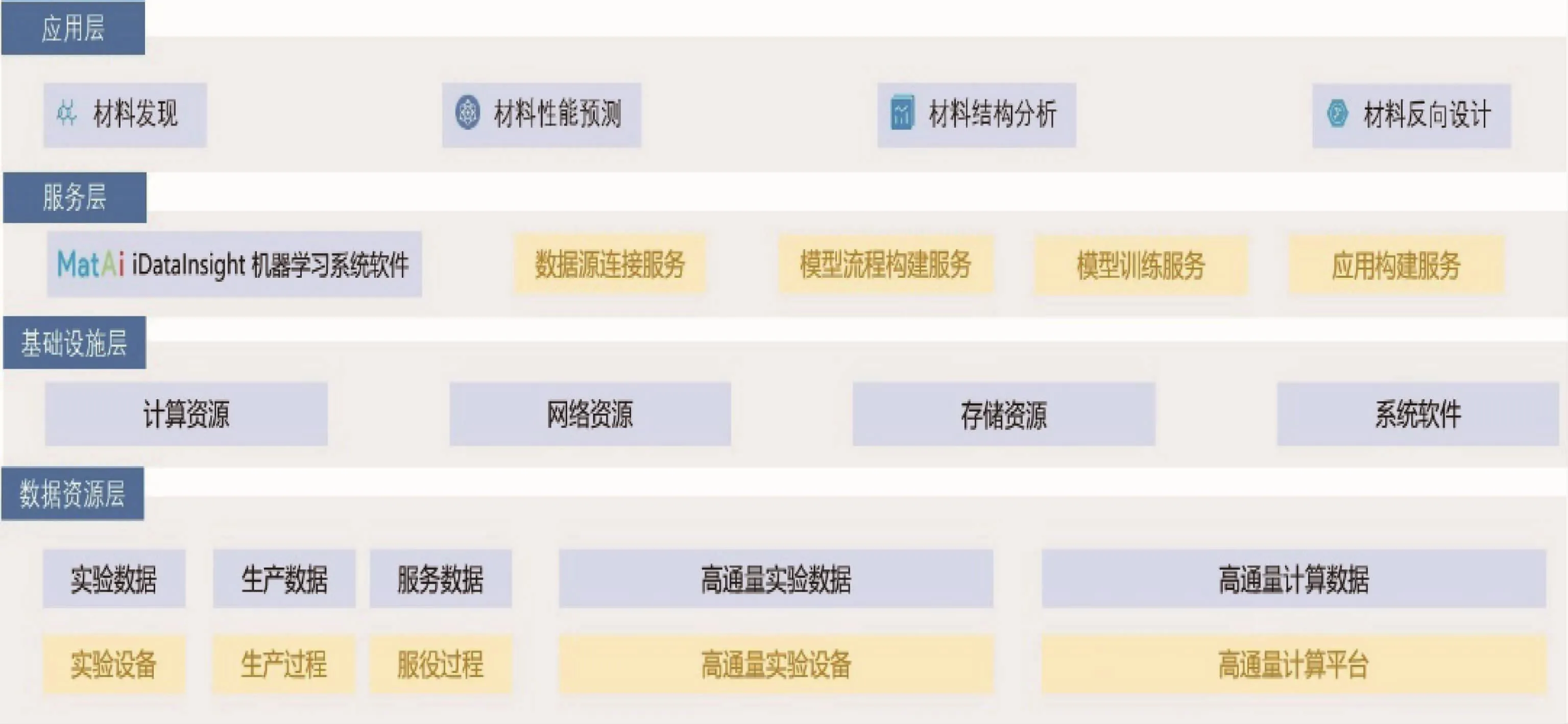
图2 机器学习系统整体架构图Fig.2 Overall architecture diagram of machine learning system
材料数据机器学习系统的功能概览如图3所示,系统由首页、数据源、模型及配置和应用部分构成。首页可以直观地显示收藏的应用和新发布的应用,可支持搜索应用;数据源部分主要包含用于材料数据机器学习的数据来源,支持连接外部数据源作为训练数据,可预览其中每张表的数据,同时也支持结合前处理方法及算法训练数据模型;在模型及配置部分通过模型构建器进行模型构建,在系统中能够对模型进行管理,控制模型发布和权限处理;最后到应用部分,将配置好的模型包装成界面美观、操作简单的应用,可方便用户阅览并使用模型,对其产生的结果还可以进行可视化分析。基于合金材料数据集,可通过机器学习平台对其性能进行预测,系统流程及演示将在下文进行详细描述。
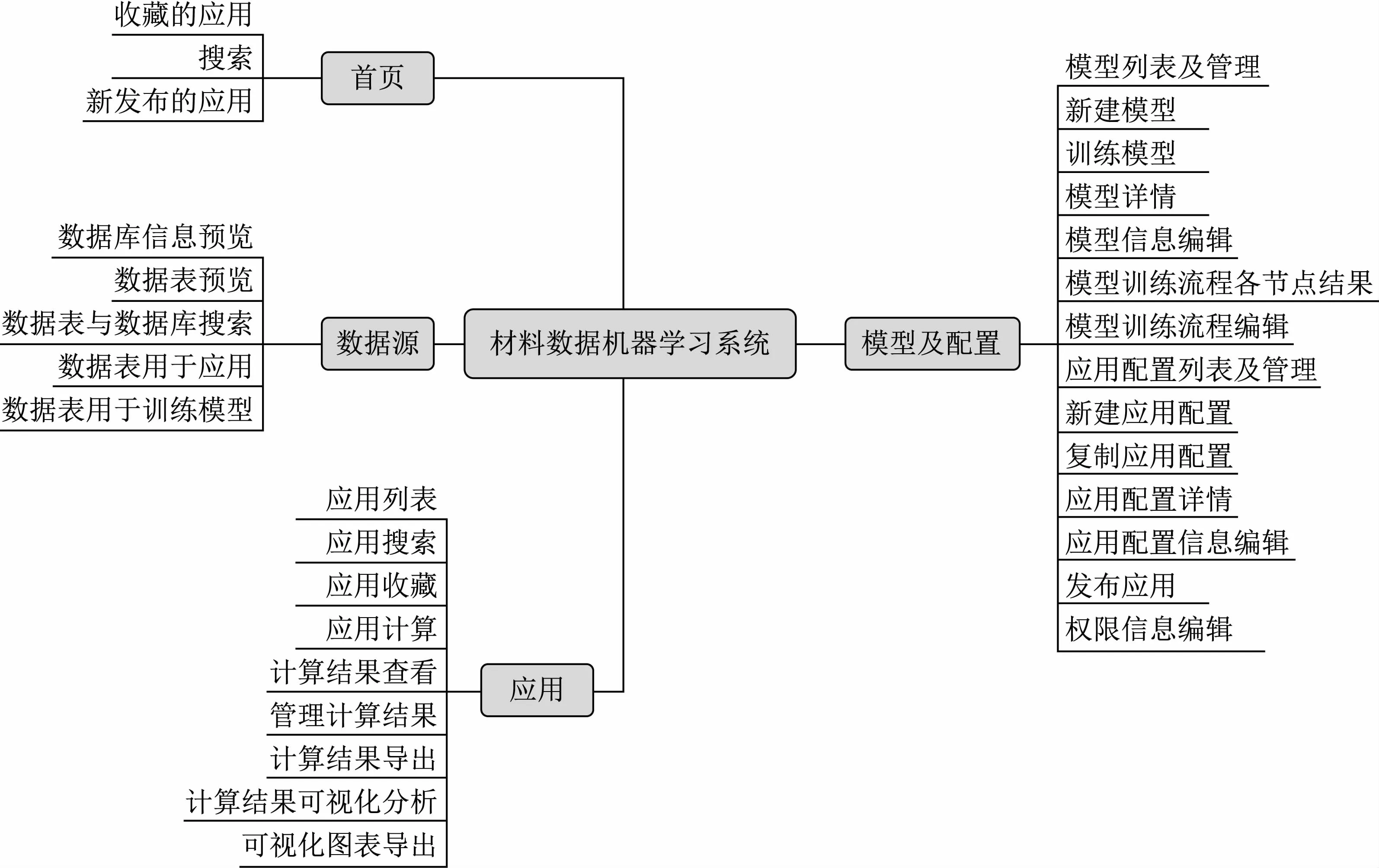
图3 材料数据机器学习系统功能概览Fig.3 Overview of the material data machine learning system functions
2.1 数据连接
系统支持连接包括Excel、MySQL、iDataCenter在内的多种数据库,用户登录系统后点击数据源Tab页可管理当前账号下所有的材料合金数据库及数据表,点击数据库右侧即可出现数据库详情,可查看该数据库类型、账号密码、配置信息及当前更新时间等。用户可以点击新建数据连接,填写参数后进行测试,最后完成数据连接新建,系统操作界面及演示示例如图4所示。
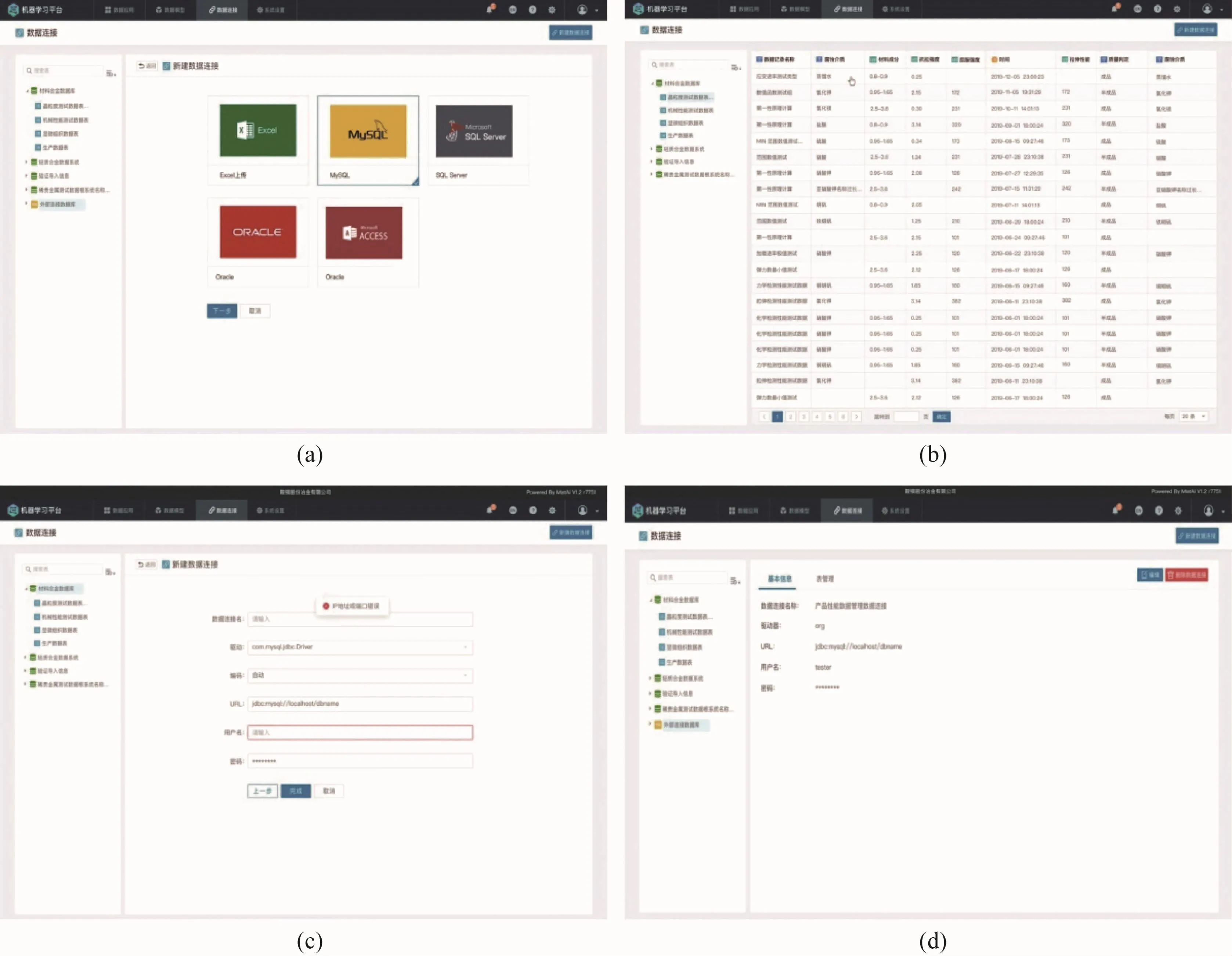
图4 合金材料数据机器学习平台数据连接演示示例Fig.4 Demonstration example of alloy material data connection on material data machine learning platform
2.2 模型构建
模型功能是针对专业用户配置的功能模块,用于训练模型,可查看当前账号下已有模型或直接进行模型编辑。如图5所示,专业用户登录系统后,可点击模型Tab页进入我的模型列表,也可切换至模型仓库,顶部按钮为新建模型,可进行模型新建;右侧可进行筛选;最右侧可进行模型搜索;下面每一条对应一个模型,从左到右依次是创建人、创建时间、训练进度条和操作按钮(包括发布、追加数据、参数修改和删除)。模型建好后可直接点击发布到模型仓库,也可追加数据对模型进行迭代,追加数据时可选择数据源的某一张表,系统会自动根据名字匹配特征列与字段,用户还可以进行手动调整,等待该模型状态变为待运行,即可重新使用。用户点击新建模型后,系统进入新建模型,操作界面将显示出一个类似于工作流的界面,前3个步骤可进行基本信息、数据源和特征目标的选择,之后可进行数据预处理或算法选择。特征列、目标列选择后右侧自动出现相关性分析图表,分析方法默认为最大信息系数(maximal information coefficient,MIC),其后有选取相关性靠前字段选项,分为前5、前10、前15、前x,点击某个按钮左侧特征会自动取消选择相关性不在该范围内的字段。数据预处理后进行算法选择,系统有线性回归、BP(back propagation)神经网络、随机森林回归、支持向量机回归等算法可供选择。

图5 合金材料数据机器学习系统模型演示示例Fig.5 Demonstration example of alloy material data machine learning system model
如图6所示,模型建立后进入模型详情页,进行模型训练,模型训练流程每一个节点右侧均有标识提示该步骤是否成功,失败会显示原因,后续步骤选项变灰。训练完成后可显示模型概览,包括模型基本信息、当前状态、MAE与R2评价结果以及评价数据量,最下方为实际值与测试值的偏差图。
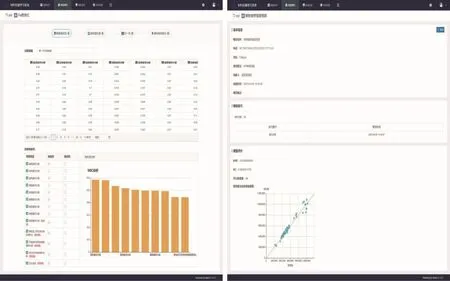
图6 合金材料数据机器学习系统模型训练演示示例Fig.6 Demonstration example of alloy material data machine learning system model training
2.3 模型应用
系统支持将模型配置为方便直接使用的模型应用,同时支持在系统中测试应用,发布后的应用即可在模型应用服务系统中供用户使用。如图7所示,普通用户登陆系统后,点击应用Tab页进入应用仓库,此处可显示该账户下所有应用及基本信息,单击标题进入应用使用界面,可收藏应用方便筛选使用。专业用户进入应用列表页可显示创建的应用包含已发布和未发布的应用,还可以进行应用新建。进入应用新建界面后有3个步骤,分别是填入基本配置信息、选择模型和输入规范,完成后生成1个未发布的应用,点击发布按钮后完成用户使用权限的选择,确定后发布应用成功,也可取消发布。在应用使用界面,可选择数据输入方式,支持单条输入和多条输入,无论什么输入方式均在右侧对特征值进行实时校验,提醒输入数据是否符合要求,没有错误后可进行实时计算,计算完成后跳转回结果页。结果页可显示预测结果,有简略与详细两种模式,可手动切换。

图7 合金材料数据机器学习系统模型应用演示示例Fig.7 Demonstration example of alloy material data machine learning system model application
3 模型验证
核电站堆型种类多样,其中采用普通水作为冷却剂和慢化剂的压水堆应用最为广泛,该类型核电站的大部分部件采用钢铁材料,由于高温和强辐射服役环境的限制对核电用钢的性能要求非常严苛,钢材制备研发也需模拟实际环境进行,试验难度大、危险系数高,试验数据来之不易。因此,可借助机器学习算法构建模型并对其进行训练,训练后包装成应用供用户直接使用,可达到基于材料数据预测核电用钢某种性能的效果。如图8所示,通过机器学习系统建模训练后,得到核电用钢疲劳强度预测值与实际值的对比图,可见每组样品的预测准确度相对较高,说明简单高效的模型构建和训练可以针对不同材料的不同性能进行预测,从而有效降低试验成本,便于科学家们选材用材。
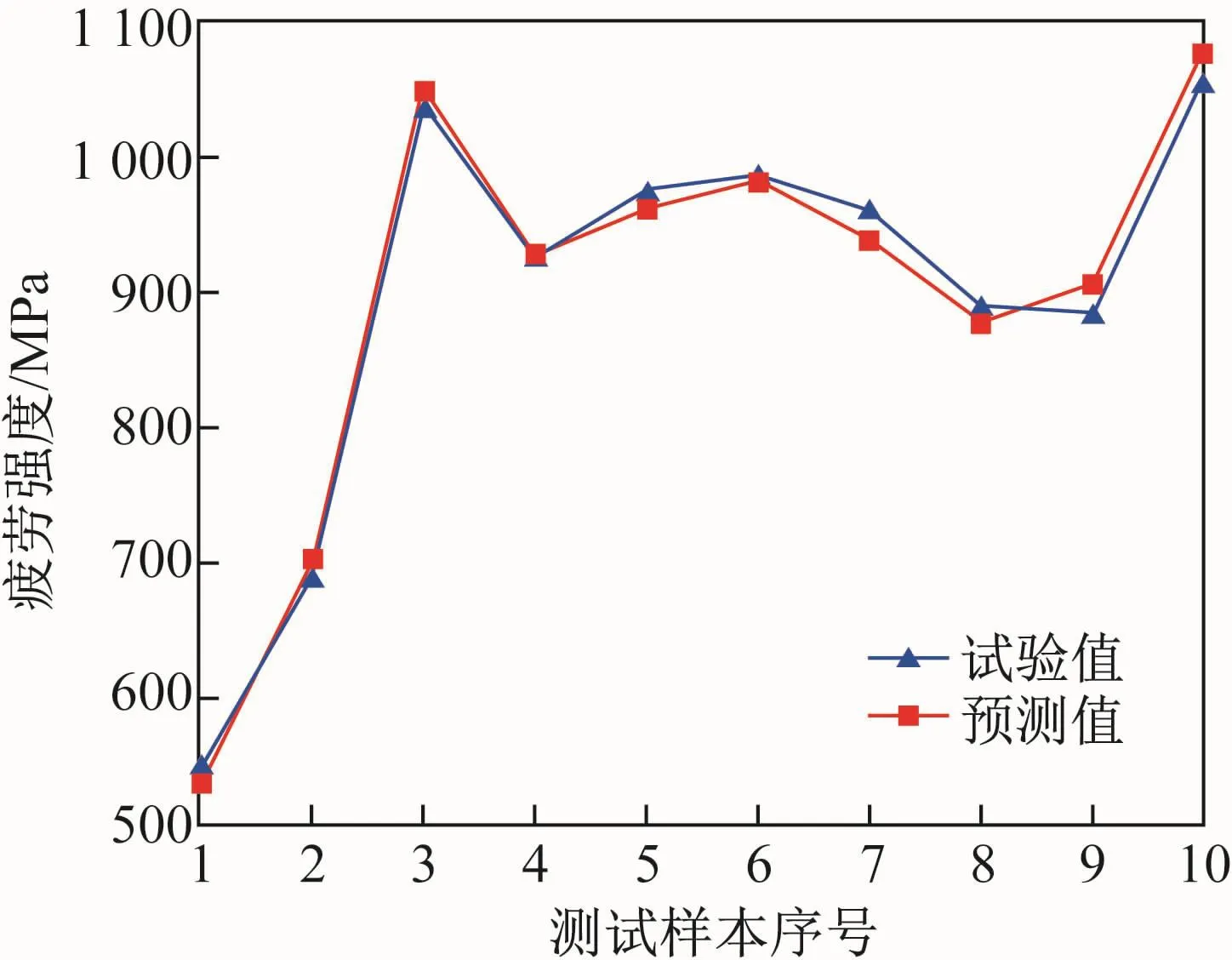
图8 核电用钢疲劳强度性能预测值与实际值的对比Fig.8 Comparison of predicted and actual values of fatigue strength properties of nuclear power steels
4 结论与展望
数据驱动与人工智能的结合成为科学的第四范式,作为核心技术之一的机器学习的应用与发展已经完全改变了材料研究的理念,并在该领域取得了一定的进展,朝着快速准确地预测材料的各种性质目标迈出了重要一步,利用数据帮助人们发现、设计和优化新材料,成为重要的材料数据分析工具[28]。本文基于机器学习算法对核电结构材料性能预测进行深入研究,该过程摒弃传统材料研发设计周期长且成本高昂的缺点,在材料科学与工程领域展现出了与传统研究方式不一样的视角。
本文通过多源异构数据、非结构化、半结构化数据的结构化处理技术,针对跨尺度的核电合金结构材料数据库,主要介绍了机器学习平台的建设思路和主要功能模块构成,总结了该机器学习系统对核电合金性能预测的基本步骤流程和具体演示示例。结果表明:通过对核电合金材料数据进行整理和有效利用,挖掘数据中的潜在信息对材料的某一目标性能进行预测,可以不经过传统试验和第一性原理计算获得相对可靠的性能,充分发挥机器学习系统对研发人员的助力作用;文中配置的机器学习平台操作页面简洁美观,易于用户理解使用,面对不同类型的用户可提供不同的模式包括模型训练和应用创建,可有效减少研发人员的工作量;以上均对材料性能预测乃至新材料的研发具有一定实用价值。
虽然材料数据机器学习系统的构建可以让科研人员不再依赖反复试验或数据计算,有效预测材料的特征性质并开发寻找新的高性能材料。但总的来说,机器学习是一种数据驱动的方法,其应用对数据依赖性很强,对核电材料的性能预测需要从相关文献和数据库中获取特征性能参数,这种方式在数据量有限的情况下和具有上百万数据量的图像识别等领域相比,会导致机器学习模型的过拟合,从而降低机器学习方法的泛化能力。因此为了提高数据量,一方面需要进一步通过高通量的计算来增加材料理论数据,另一方面针对文献中试验数据可以开发智能读取系统,从先进文献及出版物中读取访问可靠的试验数据。此外,机器学习向其他重要领域的发展仍然处于起步阶段,还需要不断地进行完善和改进,通过发掘可解释性的描述符将机器学习的黑盒子模型变得可解释也是具有发展前景的方向之一。总之,在可预见的未来,随着高新技术的发展,机器学习方法不仅可以助力于研发人员设计制备高性能的新型材料,还可能为其提供理论依据,一定也会在其他材料科学领域大放异彩。
