融合社交主题和兴趣主题的个性化推荐研究
2022-05-31丁丽
丁 丽
(亳州职业技术学院 信息工程系,安徽 亳州 236800)
随着经济社会发展,数据在规模、产生速度、类型和价值的维度上大幅度提高,大数据能够及时准确挖掘消费用户的潜在需求并及时个性化推荐给用户.然而,移动互联网环境下,移动设备的微型化导致用户在单位屏次下浏览信息量减小,导致信息超载,用户兴趣度降低[1].在互联网的云端大数据呈几何指数的增长的情况下,解决一端数据量大,而另一端用户单位频次浏览信息量小的问题关键在于个性化服务推荐技术.
目前个性化推荐采用传统的协同过滤推荐技术,前提条件是用户能够很方便地对项目进行评分,实现目标用户聚类,然后把邻居用户感兴趣的项目推荐给目标用户.这种推荐往往不准确,不能满足用户的真正需求,不能很好解决推荐度不精确的问题[2].另外,用户评分的项目往往不超过总项目数的 1%[3],导致项目评分数据的极端稀疏性和冷启动问题.综合文献,传统计算用户相似性的方法不能反映用户潜在需求[4].基于互联网平台上消费环境和社交环境的两端分析,本文提出了社交关系和兴趣主题相结合算法,通过实验数据对比本文提出的推荐算法效果理想.
1 基于用户关注关系的推荐算法
1.1 基于用户关注推荐形式化描述
U为应用系统用户的集合,ε为用户关注对的集合,u和v两个用户u∈U,v∈U.其中元素e(u,v)∈ε表示关注与被关注的关系.其中u为关注用户,v为被关注用户.关注用户集合φ,被关注用户集合φ,它们的形式化描述为
φ={u|u∈U∧∃(v∈U∧e(u,v)∈ε)},
(1)
φ={v|v∈U∧∃(u∈U∧e(u,v)∈ε)}.
(2)
在用户关注关系对e中,挖掘关注用户兴趣主题和社交动机,建立用户偏好模型,提升推荐质量.用户u偏好模型为学习到计算方法η,通过η生成用户候选列表.
η:(u,ε)→Ranklist(L){p1(v)≥p2(w)…pn-1(v′)≥pn(w′)},
(3)
其中,p1(v)≥p2(w)表示用户u关注用户v意愿强于用户w,n表示在用户候选集的位置.
1.2 用户关注关系框架模型(UATMF)
用户关注关系框架模型(UATMF)是首先通过用户关注关系集合,挖掘用户的兴趣主题和社交动机,其次计算目标用户候选集列表[5].
结合公式(1)和(2),文本语料库D和文本Ndu的关系表达
du={v|v∈φ∧e(u,v)∈ε},
(4)
(5)
在图1中,|D|、du、Kit和Ksc为采样次数,设定主题数为K,包括Kit个用户兴趣主题和Ksc个社交关系主题,K=Kit∪Ksc,o为主题类型参数(o取值为1或者0),0为用户社交关系主题,1为用户兴趣主题.超参数ε通过Beta采样得到η,η为o的Bernoulli分布.θit和φit分别是αit和βin的Dirichlet先验分布中采样得到的Multinomial分布.同理θsc和φsc分别是αsc和βsc的Dirichlet先验分布中采样得到的Multinomial分布.
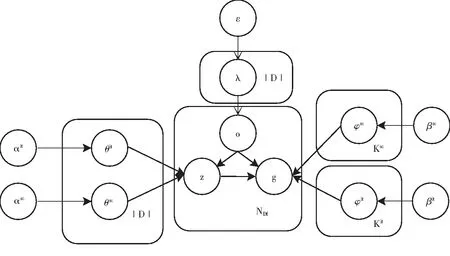
图1 UAMF参数逻辑关系
1.3 UATMF模型算法
输入文档D,主题数为K,αsc、βsc、αit、βit四个参数,用户u关注的用户集合φu,原始用户关注关系矩阵A.输出是θsc、φsc、θit、φit.模型算法步骤如下.
Step1 在主题集合Ζ中,循环每个主题z,z∈Ζ;
Step2 判断主题z是否社交主题,true转入Step3,否则Step4;
Step3 采样生成θsc~Dirichlet(βsc);
Step4 采样生成θit~Dirichlet(βit);
Step5 判断结束,循环结束;
Step6 在文档集合D中,循环每个主题Df,Df∈D;
Step7 采样生成主题分布λ~Beta(ε)、社交主题分布θsc~Dirichlet(αsc)、兴趣主题分布θit~Dirichlet(αit);
Step8 循环文档Du中每个关注的用户u(u∈UDf);
Step9 采样生成社交主题类型Drawaswitcho~Benouli(η);
Step10o为0,则跳转Step11,o为1则跳转Step12;
Step11 采样生成社交主题a~Multinomial(θsc)(a∈zsc),采样生成词语a~Multinomial(φsc,zsc);
Step12 采样生成兴趣主题b~Multinomial(θit)(b∈zit),采样生成词语b~Multinomial(φit,zit);
Step13 end(step10)、end (step8)、end(step6).
UATMF模型算法流程图,如图2所示.
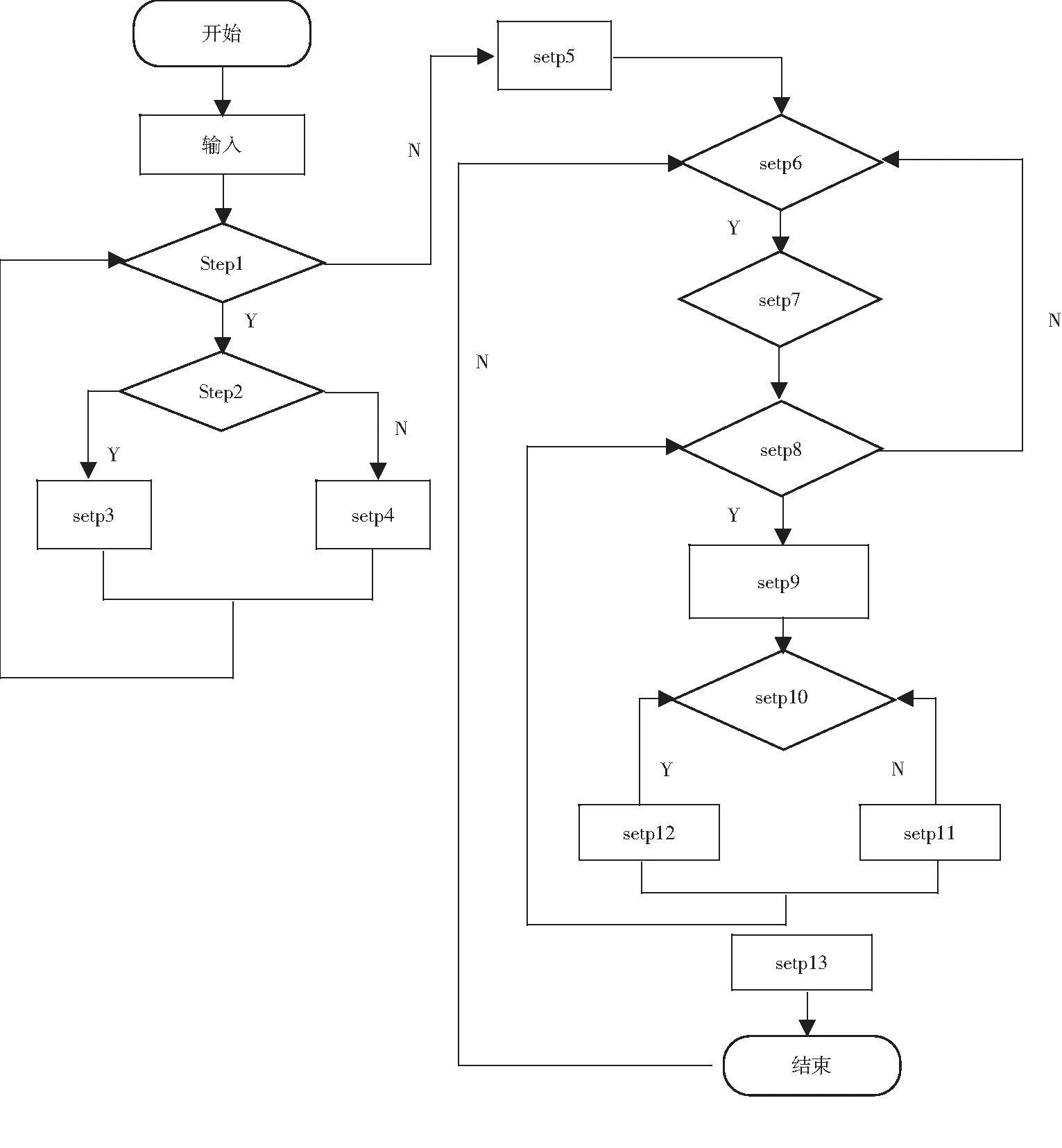
图2 UATMF算法流程图
1.4 采样
令所有用户相互关注的用户对集合ω,ω中的每个元素w(u,v)表示为用户u与用户v相互关注 即得到公式(6)和公式(7).
∃e(u,v)∈ε∧e(v,u)∈ε,
(6)
ωu={u|u∈φ∧e(u,v)∈ω},
(7)
其中,ωu表示用户u相互关注的用户集合.
构建一个用户关注关系矩阵A,A是|φ|×|φ|维实数矩阵,A中每一个元素ΔW(u,v)表示用户u在某一主题下,用户v在该主题下社交权重改变的程度用公式(8)表示.
(8)
从公式(8)中可以看出,矩阵A对角线上的元素即用户u自身关注的社交权重增1;当u与v相互关注的不同用户社交权重增γ,其他情况用户社交权重不改变.
(9)

(10)
其中,χzit,u表示在兴趣主题zit下,用户u的被关注的次数,χzsc,u表示在兴趣主题zsc下,用户u的被关注的次数.Kit和 Ksc分别是兴趣主题数和社交主题数.
1.5 兴趣主题社区和社交主题社区
用户数据稀疏导致推荐的准确率不高,因此数据稀疏问题是推荐领域的热点和难点问题,通过文献[5]和文献[6]发现,可利用社群的方法解决此类问题.社区中数据密度大,很难产生稀疏现象.设计一种数据规模小并且复杂度较低的算法.基本思路是先在源数据集中划分规模较小的数据子集,数据子集称为社区;然后在数据子集基础上进行矩阵分解,得到用户偏好值,产生TOP N用户.本文结合数据社区思想,首先在用户的兴趣主题和社交主题基础上分别产生兴趣主题社区和社交主题社区;其次进行矩阵分析,得到用户偏好值;最后进行排序产生N个目标用户.
从心理科学分析,用户关注关系是由用户的兴趣驱动和社交驱动而形成的.相对社区而言,用户的社区归属度反映用户兴趣主题或社交主题与社区内容的契合性,用户的归属度分为关注用户归属度和被关注用户归属度两种.
(i)兴趣主题社区
Oi t为兴趣主题类型,Zit为兴趣主题,每个Zit形成一个社区Cit,包括兴趣主题Zit下的关注用户集Cit·φ和被关注用户集Cit·φ,两者形式定义公式(11)和公式(12).
Cit·φ={u|u∈φ∧∃Pχ(zit/du)≥ζ},
(11)
Cit·φ={v|v∈φ∧∃Pχ(zit/dv)≥τ} ,
(12)
其中,ζ和τ为设定的阈值,Pχ(zit/du)为关注用户在兴趣主题Zit下社区Cit的归属度.代表用户u被分配到主题Zit下的概率,定义如公式(13).
(13)
一个用户的关注用户多数在兴趣主题Zit下发现,则用户本身在兴趣主题Zit下发现的概率越大,因此Pχ(zit/dv)的定义公式(14)如下.
(14)
在社区Cit中关注关系的集合ΩCit,定义如下.
ΩCit={e(u,v)|e(u,v)∈ε∧u∈cit·φ∧cit·φ}.
(15)
(ii)社交主题社区
每个社交主题Zsc产生一个社区Csc,包括社交主题Zsc下的关注用户集Csc·φ和被关注用户集Csc·φ,两者形式定义公式(16)和公式(17).
Csc·φ={u|u∈φ∧∃Pχ(zsc/du)≥ζ},
(16)
Csc·φ={v|v∈φ∧∃Pχ(zsc/dv)≥τ} ,
(17)
公式(16)中,Pχ(zsc/du)为关注用户在社交主题Zsc下社区Csc的归属度.用户u被分配到主题zsc下的概率,定义如下公式(18).
Pχ(zsc/du)≈φscdu.
(18)
同理,Pχ(zsc/dv)的定义公式(19).
(19)
在社区Csc中关注关系的集合ΩCsc,定义公式(20).
ΩCsc={e(u,v)|e(u,v)∈ε∧u∈csc·φ∧csc·φ}.
(20)
在社区C中包括Kit各兴趣主题社区Cit和Ksc各社交主题社区Csc.
1.6 矩阵分解
在传统的协同过滤算法CF中研究的是用户和项目的关系,在本文UATMF中,研究的是关注用户和被关注用户的关系,借此原理把被关注用户u∈c·φ视为项目,关注用户v∈c·φ视为用户,即c∈(Cit∪Csc)也就是C为用户关注项目的关系矩阵,并对C进行矩阵分解,得到c·φ|×|c·φ|维度的矩阵CM,CM中每个元素ρu,v,ρu,v定义如下.
(21)
C中每个CM进行矩阵分解得到两个低纬度隐式矩阵XCM=h×X|c·φ|和YCM=Yh×|c·φ|,从而把关注用户与被关注用户映射到h维矩阵中.在社区中计算关注用户对于被关注用户的偏好值fcm(u,v),公式可得
fcm(u,v)=xuyv,
(22)
其中,xu和yv分别为XCM和YCM隐式特征向量.对所有社区计算fcm(u,v),并去最大值fc(u,v),即得公式(23).
(23)
将fc(u,v)作为最终预测值.最后对于目标用户u,根据fc(u,v)的值进行排序,取N个候选被关注用户.
1.7 算法复杂度分析
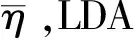
2 实验设置与分析
2.1 实验数据集
分别选取新浪微博数据集和Twitter数据集,两个数据集同时包含关注和被关注关系,随机选取用户数据,关注数和被关注数少于8人的用户进行数据清洗.在新浪微博数据集上每个用户平均关注数是252.3、被关注数为278.7,其中相互关注关系的用户数为103.28,占比高于37%.Twitter数据集上每个用户平均关注数为98.37,被关注数为112.53,其中相互关注关系的用户数为56.81,占比高于50%.两数据集的稀疏分别为99.81%和99.94%.如表1所示.
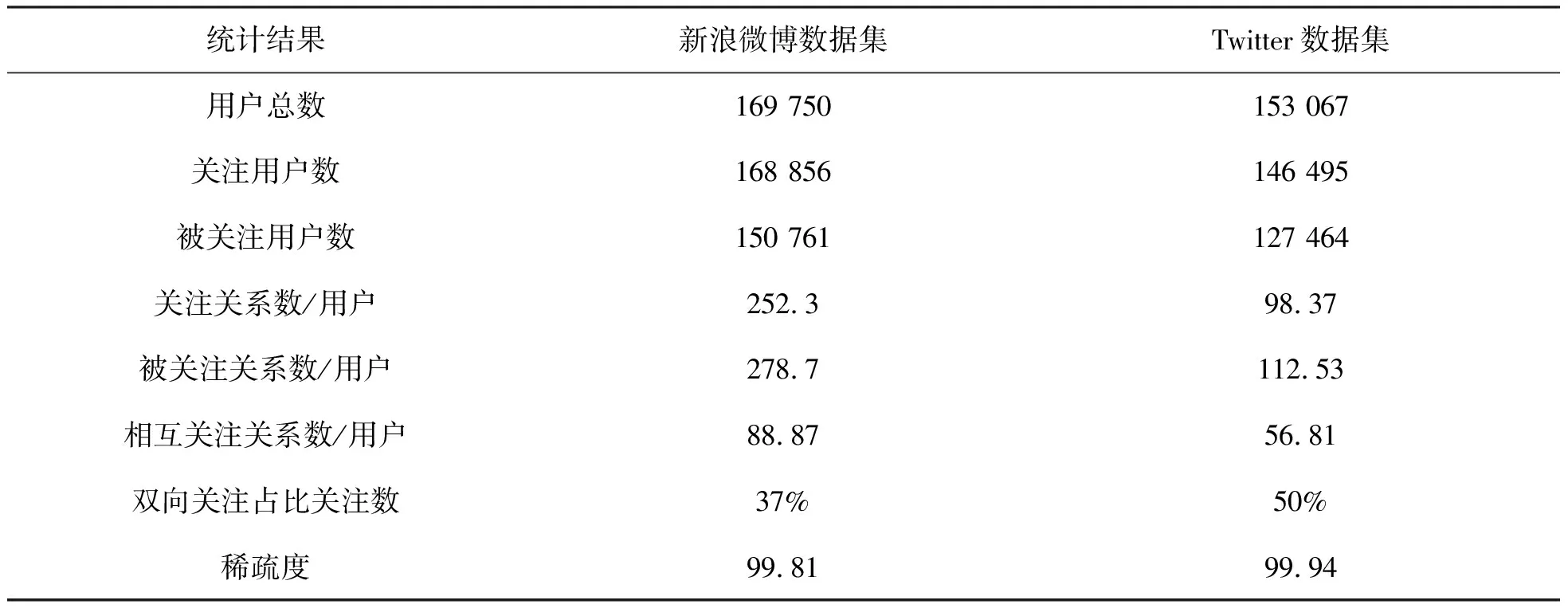
表1 实验数据统计信息表
2.2 评估指标
通过推荐领域常用的五个指标来衡量实验结果,分析本文提出推荐算法的有效性.设定推荐候选集用户规模为N,将N个用户排序好的用户集合纳入评估指标地计算过程中,三个评估指标如下.
(i)召回率(recall)
计算命中用户数占理论上最大命中用户数的比例[7].记T′为关注的用户列表,T为候选集用户列表,则RecallN定义如下.
(24)
(ii)准确率(Precision)
计算命中用户数占总的推荐用户数中的比例[7].则PrecisionN定义如下.
(25)
(iii)F1_score
全面衡量召回率Recall和准确率Precision的指标,反映算法整体性能的指标.与Recall和Precision的调和平均值正相关性,F1_scoreN定义如下.
(26)
2.3 对比方法
本实验选用三种基本社区推荐方法来进行对比,以评估UATMF推荐算法的性能.
(i)LDA-Based[8],一种通过关注与被关注建立关系的LDA建模算法,其核心推荐模型是公式(27).
(27)
(ii)CB-MF[9],与本文算法相似,运用LDA技术分析关注用户群中主题的概论分布,以及某一主题下的关注用户分布,通过主题概率分布用户群体矩阵并进行矩阵分解.
(iii)PopRec,最基本的非个性化推荐方法,对于每个目标用户,推荐同样概率分布高的主题列表.
2.4 实验与分析
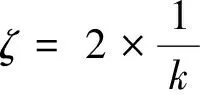

表2 敏感参数列表
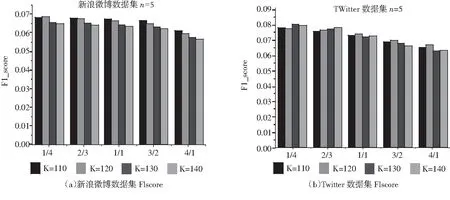
图3 两大数据集的F1score指标统计
(ii)推荐结果分析
在Twitter数据集和新浪微博数据集上,n分别取值5、10、15、20、25、30,四个算法进行比较.如图4和图5所示,在Twitter数据集上UATMF算法Precision指标下降8.4%,Recall指标提升65.9%;在新浪数据集上UATMF算法Precision指标下降46.6%,Recall指标提升68.6%.
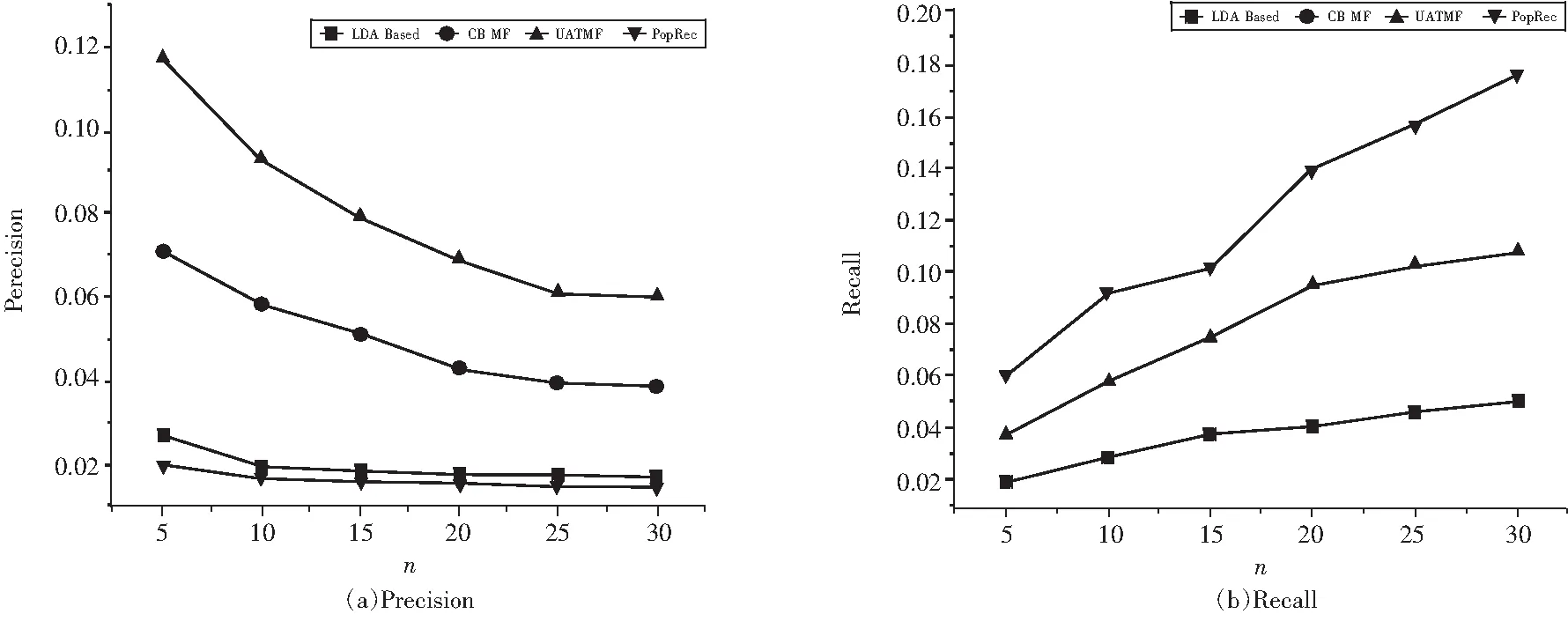
图4 Twitter数据集上各算法推荐指标比较
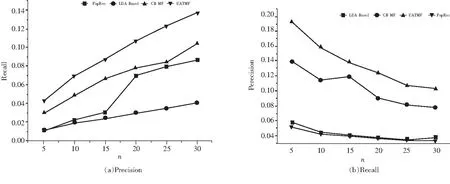
图5 新浪微博数据集上各算法推荐指标比较
3 结语
根据新浪微博数据集和Twitter数据集的实验和结果分析,新浪微博数据集上UATMF算法相对CB-MF(其他三种最优算法)算法在F1score指标上平均提升35.72%,Twitter博数据集上UATMF算法相对CB-MF算法在F1score指标上平均提升55.32%.可见融合社交主题和兴趣主题更好反映用户偏好,基于关注与被关注关系的UATMF算法推荐度得到提升.
