基于全局信息的目标检测标签分配方法
2022-05-30张培培吕震宇
张培培 吕震宇


摘要: 随着深度学习框架的发展,新的目标检测算法也不断被提出,如一阶段、二阶段检测模型等,它们很好地提高了检测速度、解决了不同尺度目标检测的问题,但对于交叠、遮挡等问题,仍没能很好地解决。造成该问题的原因之一就在于模型训练期间,标签分配工作没有做好。针对该问题,提出基于全局信息的目标检测标签分配方法,该方法在模型训练阶段,利用指派方法,根据损失函数,建立全局最优的标签分配数学模型,给出了该模型与其他目标检测模型的融合方式,以及该方法在目标检测过程中所起到的作用。将该模型与常规的目标检测模型相融合,进行目标检测,实验结果表明,在有交叠、遮挡等复杂检测场景下,融合该方法的检测模型,其精确率均优于没有使用该方法的模型。
关键词:
目标检测;标签分配;指派模型;深度学习
DOI:10.15938/j.jhust.2022.04.005
中图分类号: TP391.41;TP18
文献标志码: A
文章编号: 1007-2683(2022)04-0032-07
Target Detection Label Assignment Method Based on Global Information
ZHANG Pei-pei,L? Zhen-yu
(College of Management , North China University of Science and Technology, Tangshan 063000, China)
Abstract:With the development of deep learning framework, new object detection algorithms have also been proposed, such as first-stage and two-stage detection models, which have improved the detection speed and solved the problem of object detection at different scales, but they have not yet been well solved for overlapping, occlusion and other issues. One of the reasons for this problem is that during model training, label assignment is not done well. Aiming at this problem, this paper proposes a target detection label allocation method based on global information, which uses the assignment method to establish a global optimal label allocation mathematical model based on the loss function in the model training stage, and gives the fusion mode of the model with other object detection models, and the role played by the method in the process of object detection. The experimental results show that the detection model of the fusion method is better than that of the model that does not use the method under the complex detection scenarios such as overlapping and occlusion.
Keywords:object detection; label assignment; assign the model; deep learning
0引言
目標检测是机器视觉领域较热门的研究,其任务是在图像中检测到物体,并用框将该物体框上,给出物体类别。人头检测是目标检测常用的情形之一,一般会用于基于静态图像的人数统计和基于动态视频的人流量统计中,因视频或图像中人头尺度大小不一、交叠、遮挡等各种复杂情形存在,已成为目标检测的热点和难点。
相比较传统的机器学习算法,基于深度学习的检测框架,大大提高了目标检测性能。目前主流的基于深度学习的目标检测方法主要有两类:两阶段检测方法和一阶段检测方法。所谓两阶段检测方法是将目标检测分为两个阶段来做,首先找到检测目标的潜在边界框,再通过分类的方式去判断边界框内目标所属类别,从而判断该边界框是否真的包含目标[1-3],该方法的检测准确度比较高,但其检测速度却是较慢的,主流算法有R-CNN、Fast-RCNN和Faster-RCNN等。一阶段检测方法是由Joseph Redmon于2016年提出来的,该方法取名为You Only Look Once(YOLO)[4-5],顾名思义,只需要经过一个阶段就可以实现目标检测的功能,该方法将目标检测问题转化为回归问题,仅经过一个神经网络,大大提高了检测速度。2018年,Joseph Redmon又提出了YOLO v3,该方法采用多尺度融合的方式做检测[6-9],较好的实现了多尺度物体的检测,也就是小目标检测的目标。一阶段检测方法主要有YOLOv1-v5、RetinaNet 、CornerNet、FCOS等。
目标检测算法一直都在寻求快速、准确的检测方法,先是实现了快速检测的目标,而后又实现了小目标检测的目标,但始终没能对于物体交叠的情形下存在漏检、误检等问题,提出较好的解决方案。造成该问题的原因就是标签分配没有做好。虽然两种方法的检测机制不同,但都面临着标签分配不准的难题,甚至是需要手动的方式进行修改,但如果标签分配没有做好,就会影响检测效果,就会出现漏检、误检的情形,基于此,近两年很多标签分配的方法被提出。
1标签分配方法
所谓标签分配就是指检测器在训练阶段区分正负样本的过程,也就是给每個特征图的每个位置分配一个合适的学习目标的过程。标签分配主要应用于有锚框的应用场景和无锚框的应用场景,具体流程如下:
1.1有锚框机制
有锚框机制(anchor-based)方法在训练前,利用聚类算法生成一些基础锚框(anchor-box),然后根据锚框和目标框的交并比(intersection-over-union, IoU)来确定正负样本[10-12]。如式1所示,当IoU大于阈值时,该锚框的真值为前景,低于阈值时,该锚框的真值为背景。使用有锚框机制的目标检测算法既包含一阶段检测也包含二阶段的检测,如二阶段的检测方法Faster-RCNN和一阶段检测方法YOLO v3等。
1.2无锚框机制
无锚框机制(anchor-free)方法与有锚框机制不同,不需要预设锚框,它是基于点来判断该点的最优锚框,训练过程中自生成锚框,但无锚框机制的标签分配仍需将真值指派给某组角点。其主要方法是根据上、下、左、右4个极值点,也就是角点(corner-point)来预测目标的几何中点,再用该几何中心点计算到目标中心点的距离,大于阈值时,4个角点的真值为一组真目标框,低于阈值时,4个角点的真值为一组假目标框[13-14]。使用无锚框机制的目标检测算法主要有FCOS等。
1.3标签分配存在的问题
无论是有锚框机制还是无锚框机制,它们都是对各种大小、形状和类别的对象采用非全局的静态分配标准(如区域偏移阈值或IoU阈值)来实现标签分配的,这种简单的阈值处理方式,就会造成每个真值对应多个锚框或多个角点的问题,或者某些真值没有被分配锚框或角点的情形。当遇到两个交叠目标时,就会容易陷入次优情况[15-17],出现漏检或误检的情形。针对静态分配的问题,Zhang [18]等提出的ATSS方法利用概率统计的方法为每个真值生成不同的阈值,借助动态阈值,提高了真值与锚框的匹配度。但该方法只是基于每个真值而局部产生的最优匹配方法,没有全局性的考虑,容易出现一个锚框或角点对应多个真值的情形,在该情形下,对其分配任何一个标签都可能对网络学习产生负面影响。2021年,Ge等[19]提出了OTA方法,利用运输模型实现了标签的全局最优匹配,该方法利用Sinkhorn-Knopp算法计算最优的匹配方案,避免出现一个锚
框或角点对应多个真值的情形,但该算法需知道每个真值所应提供正样本的数量k,虽然利用每个真值拥有锚框的IoU之和来动态确定k的取值,但用来进行IoU相加的锚框个数是需手动设定,相加个数大则k值大,相加个数少则k值小,作者在COCO数据集中多次实验之后将之设定为20,但在教室人头检测这样单类别小目标检测的数据集中,20个锚框相加动态获得的k值却并不能获得好的检测效果。另外,为了加快算法的训练速度,OTA算法在损失函数上额外增加一个常数作为惩罚项,对不在一定范围内的预测框不进行匹配,但范围大小的设定又是一个超参。
针对这些问题,提出基于全局信息的标签分配方法,该方法利用0-1指派模型直接生成1对1匹配,省去了动态设定k值的操作,另外,对于0-1问题的求解采用最大最小选择法的计算方法,大大简化了计算过程,加快了训练速度,不需额外设定惩罚项来提高训练速度。
2基于全局信息的标签分配方法
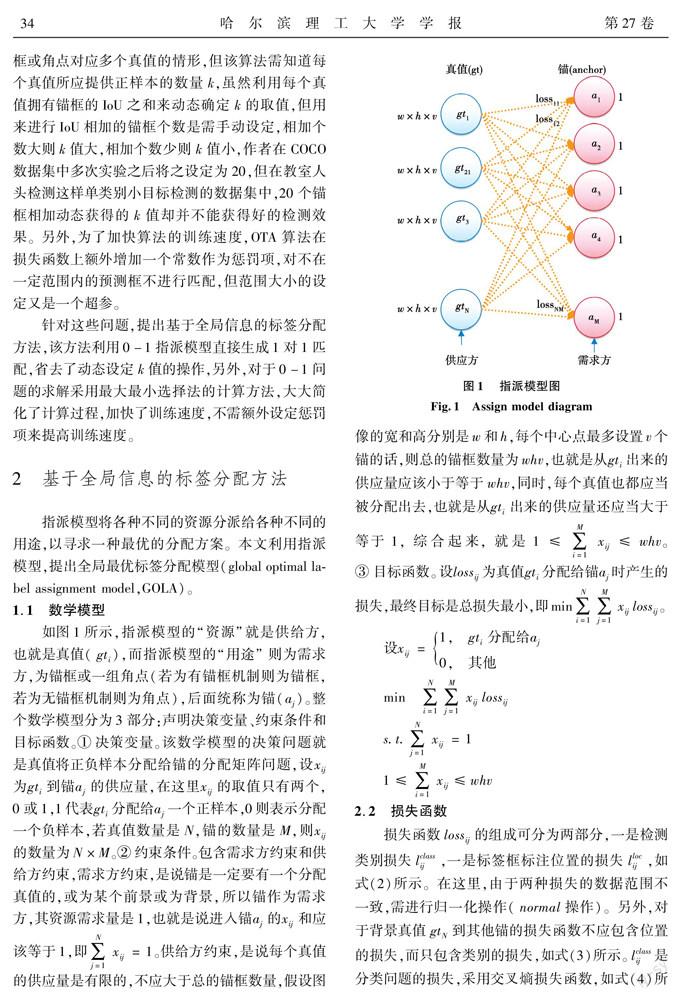
指派模型将各种不同的资源分派给各种不同的用途,以寻求一种最优的分配方案。本文利用指派模型,提出全局最优标签分配模型(global optimal label assignment model,GOLA)。
1.1数学模型
2.2损失函数
2.3最大最小选择法
最大最小理论是冯诺依曼在两人零和博弈中提出的最优选择策略,在这里用来作为真值选锚的全局最优选择法。如图2所示,该方法从全局出发,每次利用最大最小选择理论来进行选择,直到最后只剩下2×1或2×2矩阵的时候,再选择最小值作为最后的选择方案。整体来说,该方法具有全局最优性和执行效率高的特点。
2.4与检测模型的融合
2.5GOLA模型的作用
3实验结果
将GOLA与YOLOv3相融合得到新的检测模型GOLA_YOLO,将GOLA与FCOS相融合,形成新的检测模型GOLA_FCOS,本文对GOLA_YOLO、YOLO v3、GOLA_FCOS和FCOS以及OTA这五个模型进行检测比较。
本实验的训练环境均为CentOS 7操作系统,Keras框架,CPU为 Intel(R) Core(TM) i5-8250U,GPU为NVIDIA GeForce RTX3060,软件环境为CUDA11.1、CuDNN8.0、Python3.6。输入图像统一缩放为 512×512的大小。初始参数设置为:学习率为1×10-4,Batch size为16。
本实验收集高校不同水平拍摄角度的学生上课照片作为训练集和测试集。照片数量共计11974张,有70%的照片为训练集,共计8382张,有30%的照片为测试集,共计3592张,水平拍摄角度分为正面拍摄和背面拍摄,为同一教室同一时间不同角度的拍摄结果,正面和背面拍摄照片数量是相等的。每张照片有若干人头,共计572052个人头,同样正面拍摄人头数量与背面拍摄人头数量是相等的,具体样本分配情况如表1所示。
3.2训练模型
运行5个检测模型,其损失函数变化曲线如图5所示,发现这5个检测模型的收敛变化趋势相差不多。
3.3测试模型
实验对不同的标签分配方法进行了精度比较,首先结合教室场景下头部检测的特点设计了人头检测准确率综合评价指标AP以及误报率综合指标AR:人头框选成功即为准确,背景取误框即为误报,比如所有测试样本集中共100人,实际有效框选90人,误框选背景区域20个,则准确率AP为90%,误报率为20%。同时为更好地分析问题,设计AP10、AP10x、AP20和AP20x 4個准确率特殊指标,分别表示真实场景面积小于10×10无遮挡,真实场景面积小于10×10有遮挡、真实场景面积小于20×20无遮挡以及真实场景面积小于20×20有遮挡的4种容易出错的情况。综合结果如表2所示。GOLA_YOLO的准确率和误报率均大于其他标签分配的检测精度。
3.4具体照片检测结果分析
在测试集中,取正、背面各一张人头密集的照片作为案例,正面人头共计77,背面人头共计64,采用不同方法、不同角度进行检测,各方法的检测结果如图6、图7所示,其中圆形框为漏检、虚线矩形框为误检,实线矩形框为正确检测的情况,其漏检、误检结果如表3所示,结果表明在有交叠、遮挡等复杂检测情形下,无论是正面拍摄还是背面拍摄,使用GOLA方法的检测效果均相对较好。
GOLA全局标签匹配能够显著提升模型检测精度,测试结果表明,在教室人头检测场景下,GOLA加持的YOLOv3准确率提升了11.73%,误报降低10.1%。在教室学生检测这样一个包含头部交叠、大小差异巨大的复杂检测场景中,使用全局标签匹配能够可以提高其检测精度,更好地避免误检和漏检的情形出现。GOLA模型与YOLO v3结合后与OTA相比较,检测精度不相上下。数据表明GOLA模型具有很强的实践推广价值,不仅教室这样的人头检测场景,其他场合涉及人头交叠、遮挡等复杂检测场景,都可以参考该模型。如图8所示,我们利用GOLA与YOLOv3结合的模型对室外图片进行了人头检测,场景更加随机,具有更多交叠的情形,结果显示模型具有良好的泛化性能。但模型对于视频检测中的极小目标交叠情况还存在漏检和误检情况,后续需要对模型做进一步地改进。
4结论
针对目标检测中存在的因为遮挡而漏检的情形,提出了全局最优标签分配模型——GOLA模型。该模型解决了标签分配中一个锚框或角点对应多个真值的问题,同时,也解决了OTA等全局标签分配方法超参依赖的问题。在模型训练阶段,将GOLA模型与其他目标检测模型相融合,建立全局最优的标签分配策略,在教室人头检测这一交叠、遮挡等复杂场景的目标检测中,对正面和背面人头进行检测,实验结果表明,将GOLA与其他目标检测模型相融合,能够显著提升模型的检测精度,具有很强的实践推广价值。
参 考 文 献:
[1]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137.
[2]HE Kaiming, GEORGIA Gkioxari, PIOTR Dollar, et al. Mask R-CNN[C]// In Proceedings of the IEEE International Conference on Computer Vision, Venice, October 22-29,2017: 2980.
[3]ROSS Girshick. Fast R-cnn[C]// In Proceedings of the IEEE international Conference on Computer Vision, Santiago, December 7-13 ,2015: 1440.
[4]JOSEPH Redmon, SANTOSH Kumar Divvala, ROSS B. Girshick, et al. You Only Look Once: Unified, Real-Time Object Detection [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, June 27-30,2016: 779.
[5]LI Hengduo, WU Zuxuan, ZHU Chen, et al. Learning from Noisy Anchors for One-stage Object Detection[C]//In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, June 13-19, 2020: 10585.
[6]JOSEPH Redmon, ALI Farhadi. Yolov3: An Incremental Improvement[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2018: 89.
[7]DU Yuchuan, PAN Ning, XU Zihao, et al. Pavement Distress Detection and Classification based on YOLO Network[J]. International Journal of Pavement Engineering, 2020: 1.
[8]SHI Pengfei, JIANG Qigang, SHI Chao, et al. Oil Well Detection via Large-Scale and High-Resolution Remote Sensing Images Based on Improved YOLO v4[J]. Remote Sensing, 2021, 13(16): 3243.
[9]LEE Jeonghun, HWANG Kwang. YOLO with Adaptive Frame Control for Real-time Object Detection Applications[J]. Multimedia Tools and Applications, 2021: 1.
[10]KONG Tao, SUN Fuchun, LIU et al. FoveaBox: Beyound Anchor-based Object Detection[J]. IEEE Transactions on Image Processing, 2020(99): 7389.
[11]LIU Wei, DRAGOMIR Anguelov, DUMITRU Erhan, et al. SSD: Single Shot Multibox Detector[C]//In European Conference on Computer Vision,Netherlands, October 8-10, 2016:21.
[12]NEUBECK A, GOOL L J V. Efficient Non-Maximum Suppression[C]// International Conference on Pattern Recognition. IEEE Computer Society, Hong Kong, August 20-24,2006:649.
[13]ZHOU Xingyi, WANG Dequan, PHILIPP Krhenbühl. Bottom-Up Object Detection by Grouping Extreme and Center Points[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, June 15-20, 2019:303.
[14]LAW H, DENG J. FCOS: Detecting Objects as Paired Keypoints[J]. International Journal of Computer Vision,2020(2):642.
[15]TSUNG Yilin, PRIYA Goyal, ROSS Girshick, et al. Focal Loss for Dense Object Detection[C]//In Proceedings of the IEEE International Conference on Computer Vision, Venice,October 22-29,2017: 2999.
[16]LIU Songtao, DI Huang. Receptive Field Block Net for Accurate and Fast Object Detection[C]//ECCV 2018: In Proceedings of the European Conference on Computer Vision, Munich, September 8-14, 2018: 404.
[17]LIU Songtao, HUANG Di ,WANG Yunhong . Adaptive NMS: Refining Pedestrian Detection in a Crowd[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, June 15-20, 2019, 2019: 6452.
[18]ZHANG Shifeng, CHI Cheng, YAO Yongqiang, et al. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, June 13-19,2020:9756.
[19]GE Zheng, LIU Songtao, LI Zeming, et al. OTA: Optimal Transport Assignment for Object Detection [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, June 20-25,2021: 303.
(編辑:温泽宇)
