基于集成学习算法的消费行为预测
2022-05-30贾志强乐金祥
贾志强,李 涛,乐金祥
(武汉科技大学 计算机科学与技术学院,湖北 武汉 430065)
0 引 言
在大数据和线上营销的影响下,传统营销方式已经无法满足销售企业的发展要求,商家急需寻找新途径刺激用户的消费行为。而销售企业发展至今,已经积累了庞大的用户基数与消费数据,于是,从海量的数据中挖掘有价值的信息,利用大数据算法推动营销成为了企业关注重点[1]。
在实际应用上,消费行为预测[2]在营销活动中具有很高的价值,如果能提前预测出用户是否将要购买商品,那么企业在接下来的营销活动中将会有针对性地选择用户,既能保证想要消费的用户享受到优惠,购买更多商品,增强忠诚度;也能避免不会到店消费的用户对企业产生抵触心理,降低企业形象。因此消费行为预测的研究是极具实用性与商业价值的。
在消费行为预测研究中,Wang Xingfen等[3]采取XGBoost算法作为特征变换,再输入到逻辑回归模型中,实验证明该算法能很好地预测电子商务中用户的购买行为。Kareena等[4]对决策树、支持向量机、随机森林、模糊聚类、遗传算法等技术进行了实验,最终得出支持向量机是最好的一种;H. Valecha等[5]研究了消费者购买产品行为与环境因素、组织因素、个体因素、人际因素等参数的变化关系,利用独特特征工程设计实时演化随机森林分类器预测消费者购买行为;X. Dou等[6]研究电子商务平台不平衡的真实购物数据,运用以对称决策树(oblivious trees)为基学习器的catboost模型对消费者是否会购买某一产品进行分析和预测,证明该模型有更高的准确率。
虽然消费行为预测的研究已经有了一定的成果,但大多数实验在特征工程上都是尽可能多地考虑影响预测的各个方面,从不同的角度去挖掘特征,尽可能扩展特征挖掘的广度[7]。而在已有数据和特征的基础上继续深入挖掘,扩展特征挖掘的深度方面还存在欠缺。在算法建模方面,大多数已有实验都是利用单个模型进行预测,虽然也有提到集成学习的相关文献,但也只是使用封装好的带有集成学习思想的某一种分类器,如catboost、随机森林、XGBoost等这类强分类器,没有充分利用多个经典分类器的优点,利用集成学习将这些优点结合起来进行预测。
为此,该文提出在深度上深入挖掘的特征工程方法。一是采用两种滑动窗口相结合的特征提取方法提取到更多样本数据,深入挖掘消费数据的时间信息,给特征添加时间属性,同时分别对离散和连续特征做独热编码和分箱操作,更好地处理属性数据、减少噪声干扰;二是深入挖掘商品与用户之间隐含的关联关系,基于先验知识与矩阵分解,对特征进行交叉,深入挖掘各特征中的协同信息,在原有特征的基础上提取出新特征。而在算法建模方面,采用stacking策略构建集成学习模型,以XGBoost、随机森林和梯度提升决策树作为初级学习器进行特征变换,以逻辑回归作为元学习器进行消费行为预测,充分利用到各模型算法的优势。通过特征工程和模型算法对比实验证明该特征工程方法在多个模型算法中均能明显提高精准率,提出的集成学习模型预测效果也均高于单个模型。
1 面向消费行为预测的特征工程方法
1.1 基于两种滑动窗口的特征提取方法
在对消费行为进行预测时,由于购买用户通常比例很小,正负样本不平衡,正样本数据量较少,直接训练模型效果不理想,为增加正样本数据量,该文采用定长滑动窗口[8]提取更多样本数据,再结合欠采样解决样本不平衡问题。
根据企业实际营销活动情况,定长滑动窗口特征提取方法先固定特征与标签的区间长度,然后通过窗口的滑动不断提取特征数据。如用第T1到T30提取第一批样本数据,再用T31到T37打上是否到店买药的标签,取滑动步长为N如7天,用第T8到T37提取第二批样本数据,用T38到T44打上是否到店买药的标签。依此类推,提取更多的样本数据,如图1所示。
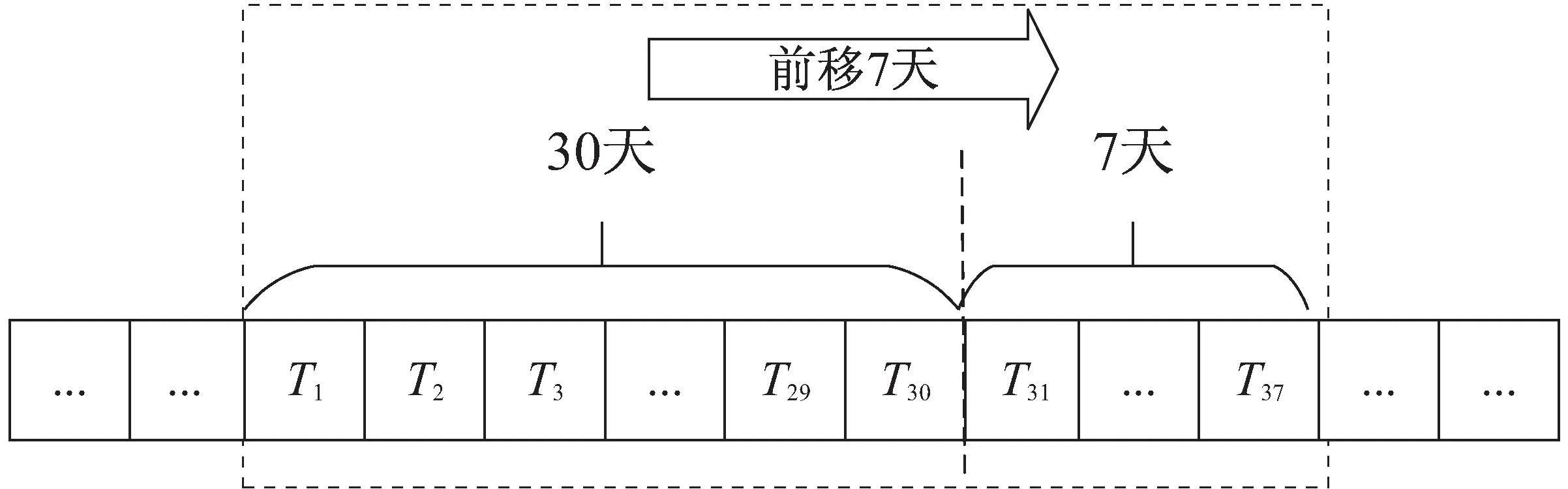
图1 定长滑动窗口提取特征
为能充分挖掘用户消费的时间属性,还原用户消费习惯,得到分类效果优秀的特征,提出先固定待提取特征的数据区间长度,再通过变长滑动窗口的方法依次划分时间段提取特征(见图2)。因为用户消费存在周期性,经过一个周期后再给用户做推荐更能激起用户的购买欲;同时,最新的消费记录能更为准确地反映用户消费情况,因此分别给不同时间段提取的特征赋予权重,给特征加上时间属性,能更好地反映用户的消费行为。同样以30天作为提取特征的数据区间长度,采取前7天(T24-T30)、前14天(T17-T30)、前21天(T10-T30)和全部时间段分别提取如表1所示的数据特征。
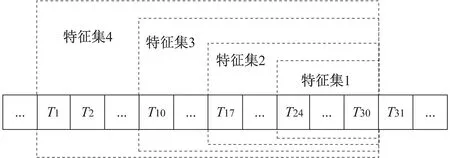
图2 变长滑动窗口提取特征
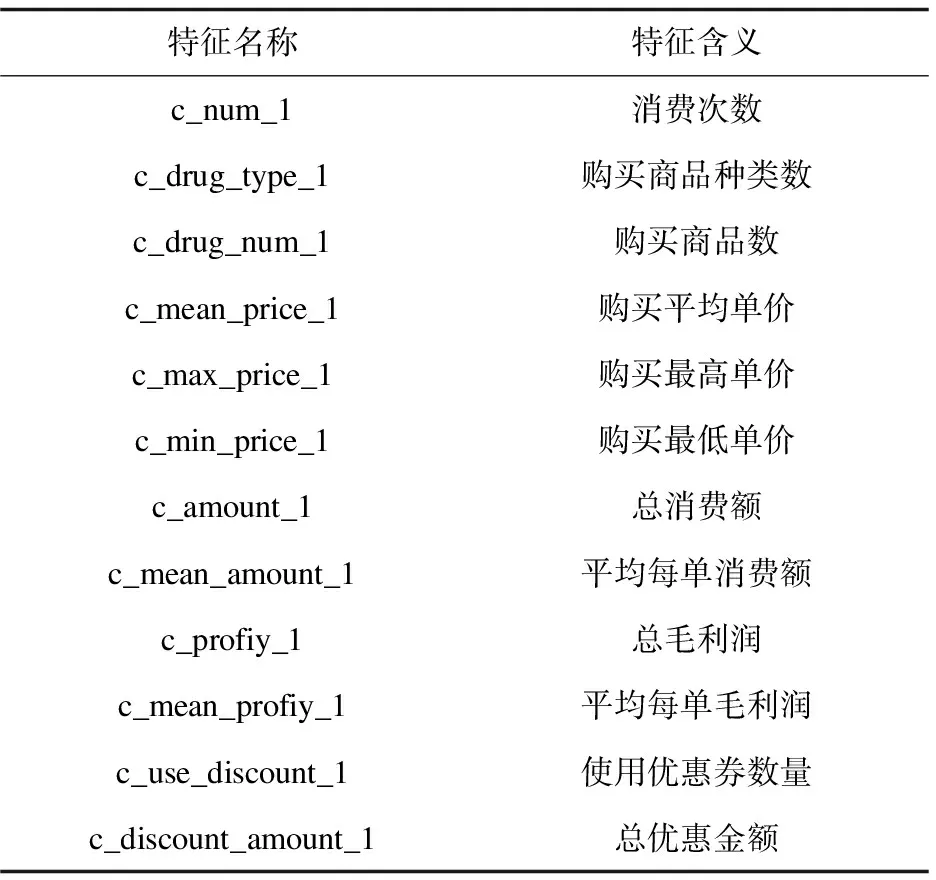
表1 特征集1提取的特征
在提取的特征中,存在较多连续型的消费特征,如各时间段的商品数、消费金额、消费客单价、购买种类数等,为降低噪音数据的影响,增强模型的鲁棒性,同时加快模型的迭代速度,对上述连续型特征进行特征分箱。
对于用户的离散型特征,对其进行编码处理,主要是对二值取值的特征进行标签编码和对多类别的特征进行独热编码,见表2。

表2 二值编码和独热编码特征
1.2 基于先验知识与矩阵分解的特征交叉方法
除了分别考虑用户和商品的特征,二者相结合的组合特征也对预测有较大影响。该文采用基于先验知识的特征交叉和基于矩阵分解的特征交叉方法,充分挖掘各个特征中的交互信息。
(1)基于先验知识的特征交叉,通过分析相关销售人员的工作经验以及与商品相关的专业知识,找出有关联的用户特征和商品特征进行交叉组合。该文以医药企业为例,如把商品类别特征和用户性别特征进行交叉组合,男性用户可能会偏好体能保健类和男科类,而女性用户可能会偏好美白保健类和妇科类,这样组合在一起能得到较为有效的组合特征,如表3和表4所示。

表3 用于交叉的用户特征
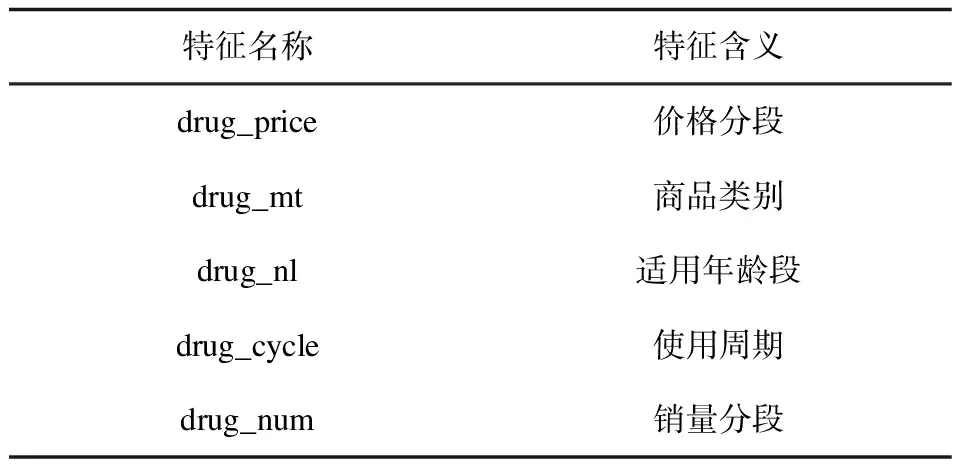
表4 用于交叉的商品特征
(2)基于矩阵分解的特征交叉,根据用户购买商品的历史消费记录构造(m×n)的矩阵,其中m代表用户数量,n代表商品数量。将用户-商品矩阵分解成用户矩阵(m×k)和商品矩阵(k×n),将每一位用户和每一种商品分别映射到一个k维的隐空间中,每个用户对应用户矩阵中的一行,每个商品对应商品矩阵中的一列,如图3所示,用户和商品都可以用一个k维向量表示。计算用户和商品隐向量之间的相似度,作为用户和商品之间的潜在交叉特征。

图3 矩阵分解获取交叉特征
2 基于stacking策略的集成学习模型构建
集成学习通过结合多个学习器完成学习任务,先训练出多个个体学习器,再采用某种集成策略将这些个体学习器相结合。文献[9]利用多源数据集和多种机器学习方法交叉构建单一检测模型,并设计一种基于Logistic的集成学习方法,进一步提升恶意软件未知变种检测方法的准确性和鲁棒性。文献[10]考虑不同个体学习器在数据集上的表现以及各学习器之间的多样性,提出一种基于Bagging异质集成学习的窃电检测方法,并验证了该模型在窃电检测中的准确率、命中率、误检率等检测指标更好。文献[11]运用信息增益法筛选指标,采用V折交叉确认法,利用UCI的信用数据对单个分类器、集成分类器模型的分类精度和稳健性进行试验比较,证明集成分类器模型在个人信用评估的分析中有更为优秀的效果。由此可以看出,集成学习在很多应用场景上都有较大的优势。
该文构建一种基于stacking策略[12]的集成学习模型对用户的消费行为进行预测。stacking策略的集成学习模型结构如图4所示。
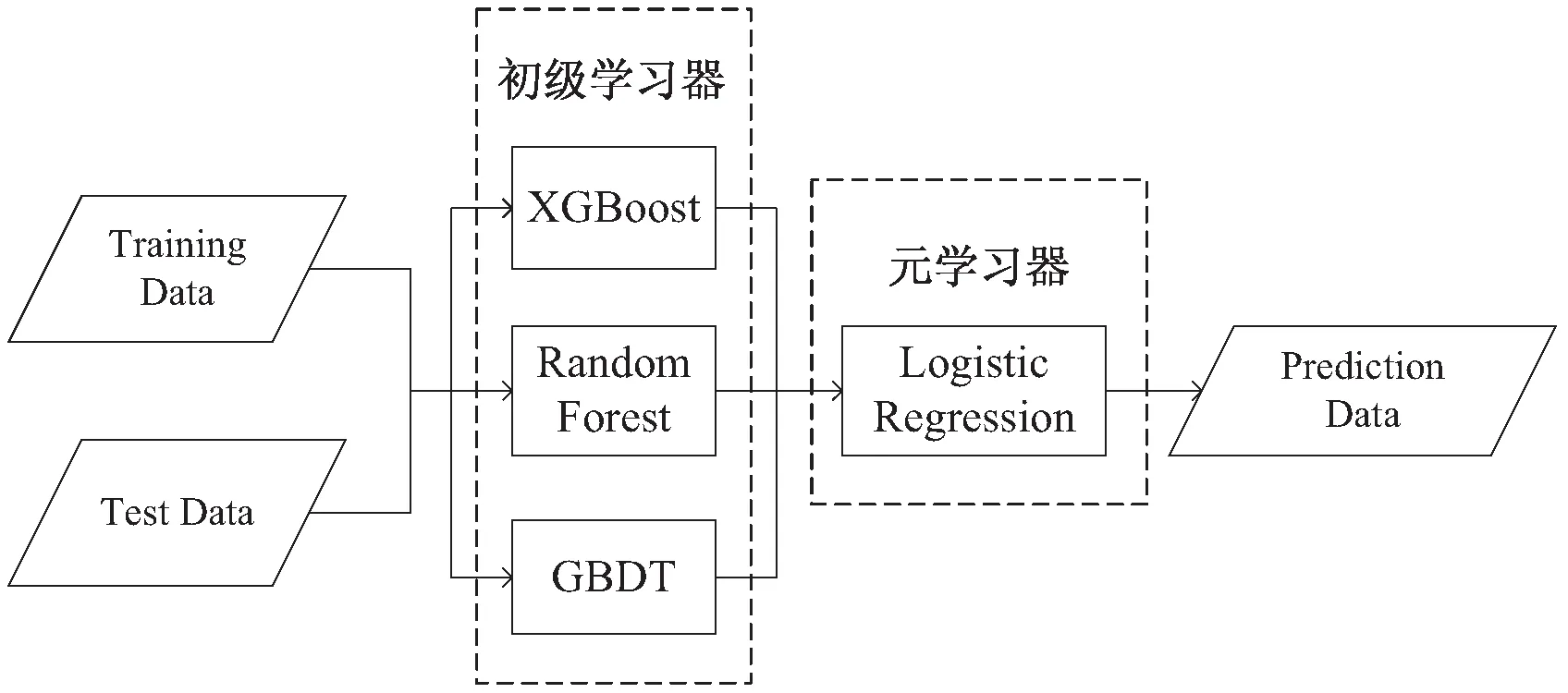
图4 stacking策略的集成学习模型结构
该集成学习模型采用XGBoost[3]、随机森林[13]和梯度提升决策树[14]作为初级学习器,对特征进行变换,再输入到元学习器逻辑回归模型中做最终的预测。具体算法步骤如下:
(1)划分数据集为训练集与测试集。
(2)将训练集分别输入初级学习器中,在每个初级学习器中采用k折交叉验证,进行k次实验,每次实验对1/k的训练集和全部测试集做预测,把每次预测出的1/k训练集合并得出完整训练集的预测结果,对k次测试集的预测结果取平均得到最终测试集预测结果;合并训练集与测试集的预测结果得到完整数据集预测结果。
(3)将每一个初级学习器的预测结果作为一个特征输入元学习器逻辑回归模型得到最终预测结果。
算法1:初级学习器特征变换算法。
输入:X_train:训练集特征数据;X_test:测试集特征数据;y_train:训练集标签数据
输出:变换后的训练集特征数据;变换后的测试集特征数据
1:clfs为初级学习器列表
2:k为正整数,表示采取k折交叉验证
3:X_train_stack = np.zeros((X_train.shape[0], len(clfs))) # 初始化用于存储训练集预测结果的二维数组
4:X_test_stack = np.zeros((X_test.shape[0], len(clfs))) # 初始化用于存储测试集预测结果的二维数组
5:skf=StratifiedKFold(n_splits=k, shuffle=True, random_state=1) # 用于k折交叉划分训练集
6:for i, clf in enumerate(clfs): # 遍历每一个初级学习器
7: X_stack_test_n = np.zeros((X_test.shape[0], n_folds)) # 初始化用于存储测试集结果的二维数组
8: for j, (train_index, test_index) in enumerate(skf.split(X_train, y_train)): # 遍历k折交叉划分的训练集
9: tr_x = X_train.iloc[train_index,:] # 读取第j次划分的训练集中用于训练的特征数据
10: tr_y = y_train[train_index] # 读取第j次划分的训练集中用于训练的标签数据
11: clf.fit(tr_x, tr_y) # 训练第i个初级学习器
12: X_train_stack[test_index, i] = clf.predict_proba(X_train.iloc[test_index,:])[:, 1] # 存储第i个初级学习器
13:在第j次划分下被用于测试的训练集的预测结果
14: X_stack_test_n[:, j] = clf.predict_proba(X_test)[:, 1] # 存储第i个初级学习器第j次对测试集预测的结果
15: X_test_stack[:, i] = X_stack_test_n.mean(axis=1) # 第i个初级学习器预测测试集的k次结果取平均
16:return X_train_stack,X_test_stack # 返回变换后的训练集特征数据和测试集特征数据
3 实验与分析
实验环境:Windows10操作系统,16 G内存,3.6 GHz八核心处理器,实验软件为Python3.7。
3.1 数据来源
该文采用某药店服务商提供的四个月的用户消费记录,一个用户购买一个药品代表一条记录,去掉没有用户Id的无效消费数据和单价小于等于0的赠品、塑料袋、退货等噪音数据,剩余有效数据共2 059 718条。按照前30天消费行为预测后7天是否有消费,后7天有消费即为正样本,没有消费即为负样本,采取7天为步长,滑动提取更多样本数据。一共提取的样本数据为284 071条,其中正负样本15 018条,负样本269 053条。
3.2 评价标准
考虑到实验数据正负样本不平衡的问题,为提高实验可信度,采用精准率(PA)来评估特征工程的有效性,在算法建模效果验证实验上,为更为直观地比较模型效果,添加auc值和roc曲线的对比。
将预测值分类汇总,建立如表5所示的混淆矩阵。TP代表模型中预测正确的会响应消费的用户数,FP代表模型中误测会响应消费的用户数,TN代表模型中预测正确的不会响应消费的用户数,FN代表模型中误测不会响应消费的用户数。

表5 混淆矩阵
(1)精确率(Precision)。
P=TP/(TP+FP)
(1)
精确率P表示预测为正例的所有样本中预测正确的比例,衡量了分类器对正例的识别能力。
(2)特效度(Sensitive)。
S=TN/(TN+FN)
(2)
特效度S表示所有预测为负例的样本中预测正确的比例,衡量了分类器对负例的识别能力。
(3)精准率PA。
(3)
评价指标精准率PA受响应消费用户和没有响应消费用户两者的准确率的影响,避免因响应消费用户与没有响应消费用户样本数偏差影响评价指标。而auc值为roc曲线下的面积,auc值越大,roc曲线下的面积越大,模型效果越好。
3.3 特征工程有效性验证实验
文献[4]在消费行为预测中使用了多种分类算法,对比证明支持向量机的预测效果要优于其他方法,文献[15]和文献[3]使用逻辑回归和XGBoost预测消费行为,文献[5]使用随机森林算法也获得了较好的预测效果。为客观地验证特征工程的有效性,该文选用支持向量机、逻辑回归、XGBoost和随机森林这四种算法进行对比实验。
为验证文中特征工程方法在药品消费行为预测中的有效性,采取实验步骤如下:
(1)输入未采用文中特征工程方法的原始特征进行预测;
(2)在原始特征的基础上添加文中特征工程方法,再与原始特征的预测效果做对比。
为排除偶然性问题,采用十折交叉验证的方法进行10次实验,取平均,得到的结果如图5所示。

图5 特征工程有效性对比
在相同数据集中,对定长滑动窗口提取的原始特征添加文中特征工程处理方法,在支持向量机、逻辑回归、XGBoost、随机森林分类模型4种经典的模型算法中采用十折交叉验证进行对比实验。通过实验结果可知,较原始特征相比,在添加文中特征工程方法后精准度提高约5.75% ~14.92%。以上对比实验结果表明,文中特征工程方法对模型效果有提升作用,即在消费行为预测上具有一定的有效性。
3.4 集成学习模型对比实验
为验证文中提出的基于stacking策略的集成学习模型优于单个的机器学习模型,选取集成学习模型与其包含的单个模型进行对比,即与XGBoost、随机森林、梯度提升决策树和逻辑回归进行对比,实验结果如图6与表6所示。
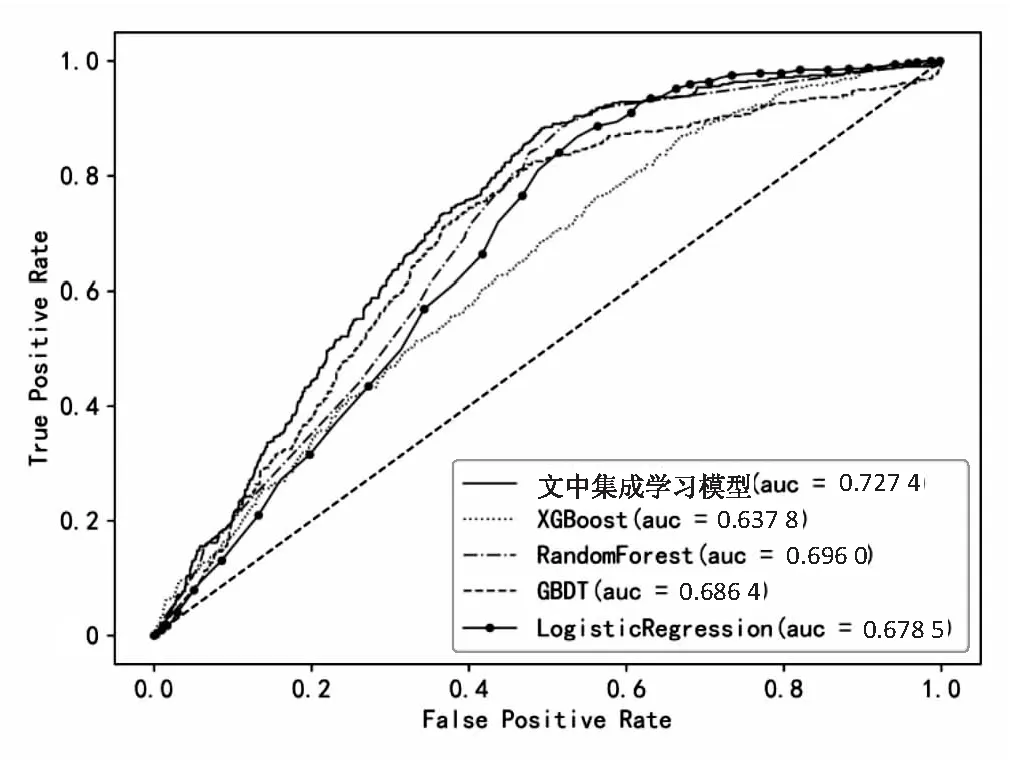
图6 文中模型与单个模型roc曲线对比
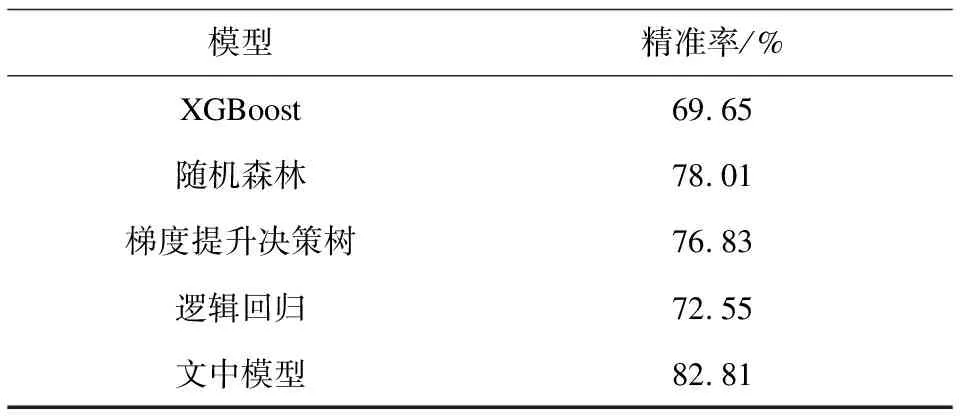
表6 文中模型与单个模型精准率对比
由图6的roc曲线对比可知,在消费行为预测上,基于stacking策略的集成学习模型整体性能要优于其他四个单个模型,其中auc值最大,达到72.74%。由表6可知,基于stacking策略的集成学习模型在精准率上也是最高的,达到82.81%,验证了提出的集成学习模型在消费行为预测上的有效性。
4 结束语
销售企业结合电子管理系统快速发展,已经积累了庞大的用户基数与消费数据,而在现今的互联网时代,传统的营销方法已无法满足企业的发展要求,商家急需寻找新途径刺激用户的消费行为,提高企业竞争力,于是从海量数据中挖掘价值信息,预测用户的消费行为,从而促进销售成为了企业关注的重点。该文考虑到多数特征工程方法在现有数据挖掘深度上不足的问题,通过结合具体活动场景,提出了深入挖掘特征的时间属性和特征之间隐含信息的特征工程方法,并在多个算法模型中验证了该特征工程方法的有效性,精准率提升约5.75%~14.92%。同时充分学习利用多个分类器的优点,构建stacking策略的集成学习模型,对消费行为进行预测,实验证明该集成学习模型比单个模型的效果更好,精准率最高,达到82.81%,充分验证了该模型在消费行为预测上的有效性。
