基于文本词特征加权LDA的疾病表征提取方法
2022-05-30余肖生
余肖生,沈 胜,陈 鹏
(三峡大学 计算机与信息学院,湖北 宜昌 443002)
0 引 言
电子病历(Electric Medical Record,EMR)是指存储在计算机上的医疗信息记录,如病人身份信息、问诊记录、体检报告等,具有数据体量大、数据结构复杂多样等特点。EMR已经成为健康医疗大数据中使用最广泛、记录信息最丰富、最复杂的数据类型之一。从复杂多样的非结构化EMR文本数据中提取出疾病表证词,是EMR文本数据处理及后续相关研究的关键。文本提取的方法主要分为两类:(1)基于人工标注的数据集进行模型训练,如CRF模型、深度学习模型等[1-2]。但由于医疗数据的专业性,在面对大体量的数据时,医疗数据标注是十分困难的;(2)基于统计聚类实现关键信息提取,如TF-IDF模型、词袋模型等[3-4]。这类模型忽略了文档词之间的关联性,难以有针对性地提取出电子病历中的疾病表证词。在基于统计聚类的方法中,LDA(Latent Dirichlet Allocation)模型[5]在统计文档词频率的基础上,结合文档词的共现关系,以实现对文本数据的无监督分类,进而提取出疾病所对应的疾病表证词。但LDA模型是基于词频与词语共现关系实现文本聚类的,忽略了词自身的语义信息,这使其在处理复杂文本时不可避免地会出现语义稀疏的问题。
为了解决LDA模型忽略语义信息的问题,该文将词特征加权引入了标准LDA模型,以提升LDA模型的语义可解释性,实现对EMR文本数据的针对性挖掘;将词性、词长和词义特征加权引入标准LDA模型,改变了LDA模型的词分布状态,提升了任务目标词的共现频率,约束了LDA模型的主题词挖掘,增强了LDA模型的语义解释能力,从而实现了任务目标词的有针对性提取。
1 相关工作
1.1 文本数据挖掘
由于医疗领域数据记录标准不一,往往都是内容形式复杂多样的非结构化文本数据,因此需要一定的数据挖掘手段对这些文本数据进行提取、分析。其中,文本数据挖掘的手段主要有以下两类:
(1)基于文本特征。文献[6-8]基于词特征的关联规则与外部语义对文本语义进行扩展,提高了模型的文本分类性能。文献[9-10]通过对文档中心词、关键词、近义词等进行分析,计算出文档相似度,进而形成对文档的分类。胡燕等人认为通常能标识文本特性的往往是文本中的实词,如名词、动词、形容词、副词等;而文本中的一些虚词,如感叹词、介词、连词等,则对于文本特征识别贡献很小,因此可以通过词性特征对文本进行提取[11]。文献[12]基于语言习惯及句法依存来发现文本特征,进行文本挖掘。
由于EMR文本数据记录标准不一,记录形式多样,且多呈现为百字以内短文本形式。因此,文本特征中的语义相似度、句法依存等方法很难直接应用于EMR文本数据的挖掘。
(2)基于机器学习与深度学习。机器学习算法在EMR文本的特征提取和利用上有着较好的表现,针对于不同的应用场景不同的机器学习算法都有着其独到的表现[13-15]。而在处理序列化的数据时,机器学习方法通常无法很好地对时序数据进行解释。为了更好地提取数据的时序特征,文献[16-17]尝试使用深度学习(如RNN、LSTM等)方法对文本数据进行建模分析。
机器学习与深度学习方法模型训练的数据集往往是需要人工标注的。而EMR文本标注需要有专业的医学知识储备才能完成,因此对大数据量的EMR文本标注是困难的。
1.2 LDA模型
随着文本数据挖掘领域的研究发展,文本挖掘任务对文本数据提取出的数据要求也愈发趋向多样性。研究者开始基于标准LDA模型进行优化变形,以使得LDA模型可以更好地适应于所需求的文本挖掘任务。目前LDA模型优化研究多是围绕对LDA模型词分布的调整进行的,对LDA模型的词分布调整方法主要分为以下两种:
(1)基于文档词频率的调整词分布。彭云等人在标准LDA模型的基础上引入了特征词-特征词、特征词-情感词和情感词-情感词三组语义关系约束,提出了SRC-LDA模型[18]。Fan Lin等人为了降低词频对低频词提取的影响,引入了TF-IDF特征加权和高斯特征加权,对词分布进行调整,最终实验证明高斯特征加权对主题提取结果有明显的改善[19-20]。文献[21-24]通过文档词之间的共现关系及时序相似性约束对词分布进行调整,以降低主题分布之间的差异。
(2)基于语义或外部语义库对词分布进行调整。文献[25-28]在对文档进行建模时,将文档描述对象的基本信息引入模型中,以便于模型更好地理解文档内容。张勇等人[29]通过对不同词性在文本中的重要性进行分析,去除重要性较低的词性的词,进而缩减原始数据集,优化计算性能,避免模型提取出词频高而重要程度低的词语。文献[30]利用网络语义知识对文档词进行概念和命名实体的提取扩充。
上述LDA模型的优化模型,亦难以从EMR文本中有针对性地提取出疾病表征词。为了更好地提取文本中任务目标词(疾病表征词),该文将词特征加权引入了LDA模型,使得模型可以适应于任务需求进行有针对性的提取。
2 词特征加权
为了解决LDA模型忽略语义信息的问题,有针对性地对EMR文本中疾病表证词进行提取,该文在标准LDA模型的基础上引入了词特征加权。词特征加权是通过对文档词的词性、词长和词义的语义特征进行提取,生成相应的文档词分布权重,进而生成带有语义信息的文档词分布,从而使得LDA模型可以有针对性地提取文档中的目标信息。
2.1 基于词性的词分布加权
一篇文档通常是由不同词性特征的词组成,不同词性特征的词所携带的语义信息程度也是不同的。一般来说,文档中名词、动词、形容词、副词带有的语义信息较丰富,具备很好的文档特性标识能力。而量词、助词、介词等带有的语义信息较少,且会较频繁地出现在文档中,这会对文档信息提取造成较严重的干扰。
在确定提取任务情形下,为了排除低信息量词的干扰,可结合任务目标对各词性的信息量进行评估,然后按公式(1)对文档词进行加权。

(1)
其中,ρ1为词性加权权重,v为词性所对应的权重值。
此外,基于不同任务的文本提取,需获取的文本信息内容是不同的,所需关注的词性特征往往也是不同的。如,任务为知识图谱时,会更关注文本中的实体名词;任务为情感分析时,则会更关注文本中带有情感信息的形容词。因此,在处理确定目标的文本提取任务中,可根据任务所关注的词性,对权重值进一步的细分,细分规则可参考公式(2):
(2)
其中,v1,v2,v3,v4分别为一、二、三、四级词性所对应的细分权重值,一级为关注等级最高的词性。如,任务知识图谱时,一级词性便为名词。
2.2 基于词长的词分布加权
一篇文档常常会由不同长度的文档词组成,且呈现词长越长其带有的信息越丰富的特征。长词主要呈现为两种情况:(1)由长度短的词组合而成,对短词描述的信息进行了扩充或延伸。如,“头”、“疼”与“头疼”;(2)专业名词,这类词与文本主题关联度较高,有较好的主题揭示性。如,文本中有词:“原发性高血压病”、“继发性糖尿病”,那么该文本大概率是描述高血压和糖尿病的电子病历文本。一般来说,词长越长的词,其为专有名词的概率越高。
在现代汉语中,单字词多为助词、介词,词信息相对单一;2、3字词最为常见且应用灵活;4字词多为成语等固定用词,词信息较为丰富;5字以上词多为专有名词,词信息有较好的主题揭示性,且不同词长的专业名词应具备相近的主题揭示性。在处理中文文本时,考虑到词长与主题的相关性,可以通过公式(3)确定不同词长的文档词的加权权重。
(3)
其中,ρ2为词长加权权重,l为文档词长度。
图1为词长加权拟合公式(即公式(3)),图中用圆圈标记出了各词语字数所对应的词长加权权重值。图中可以看出字数不大于5时,所对应的词长加权权重值增长较快,与上述分析保持一致;而在词语字数大于5时,不同字数的专业名词所对应的主题揭示性相似,因此,词长加权权重值增长缓慢。
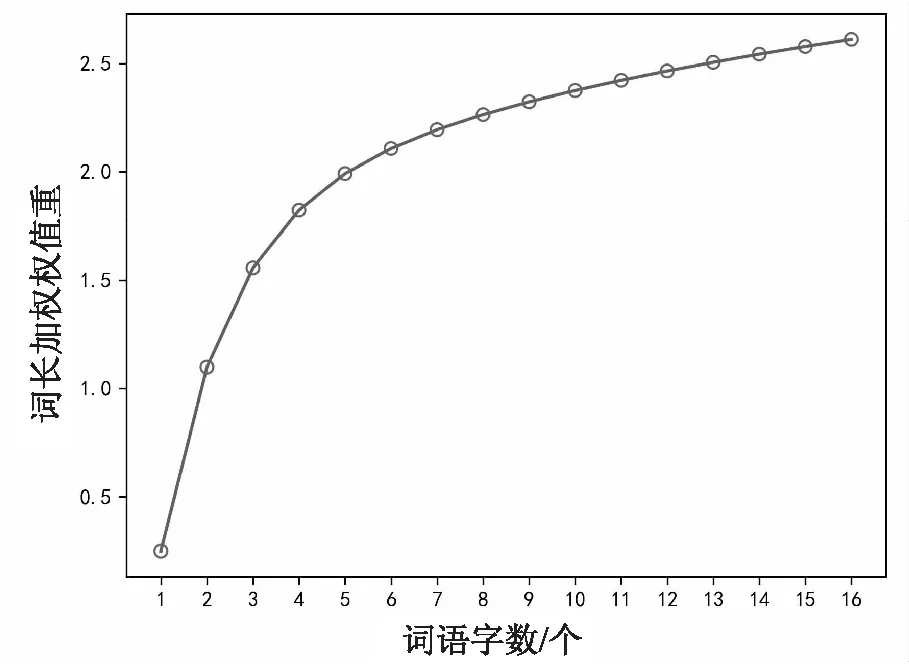
图1 词长加权拟合公式图
2.3 基于词义的词分布加权
在确定目标的文本提取任务中,所关注的文档词往往具有一定的相似性。这种相似性不单单体现在词性特征上,也会体现在词义上。即使是相同词性的词,在选择时也会根据词义的不同有所侧重。如图2中,名词有“患者”、“昨日”、“状况”、“今晨”、“我院”。若目标为实体关系的提取,则侧重“患者”与“我院”;若目标为时序的提取,则侧重时间名词“昨日”、“今日”。
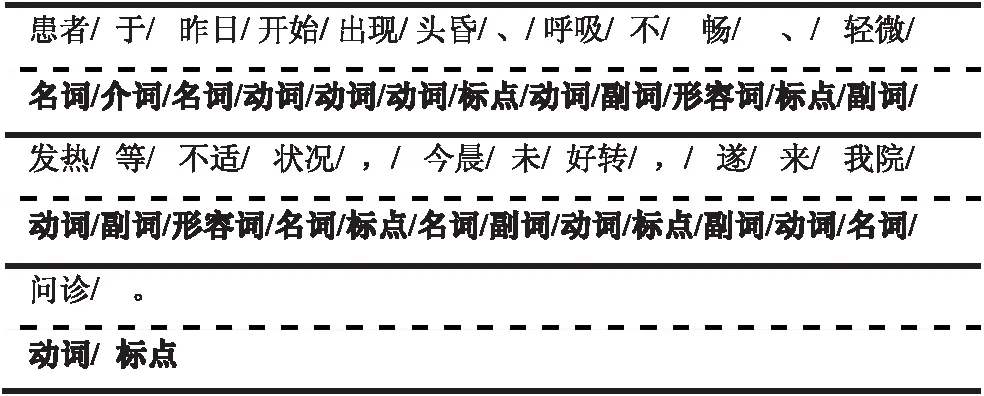
图2 文档词性标注
文本中文档词词义的识别是困难的,需要引入外部语义知识进行辅助识别。识别处理办法主要分两种:(1)构建任务侧重外部语义知识库时,对任务侧重语义进行识别,提升所识别文档词的权重;(2)构建非任务侧重外部语义知识库时,对非任务侧重语义进行识别,降低所识别文档词的权重。在构建外部语义知识库后,可参考公式(4)确定对应词义的加权权重。
(4)
其中,ρ3为词义加权权重,w为文档词,pos为任务侧重外部语义知识库,cpos为文档词w在任务侧重外部语义知识库中所赋予的加权权重值,neg为非任务侧重外部语义知识库,cneg为文档词w在非任务侧重外部语义知识库中所赋予的加权权重值。
外部语义词库确定词义加权权重具有一定的局限性,它无法对非词库外的文档词进行加权。在外部语义词库一定的情况下,随着任务自身领域的发展,会出现词库外的新文档词。而现有的外语语义词库无法确定这些新文档词的语义加权权重,则会在一定程度上对主题的发现造成干扰。为了解决词库外文档词语义不确定的问题,在确定语义加权权重时,可以引入语句位置来推断新文档词的加权权重。
文档中处于不同位置的语句往往有着不同的重要性。通常,在多个语句组成的文本段落中,位于句首与句尾的语句可以较好地反映段落主题。而语句总是由文档词组成的,且位于同一语句中的文档词往往有着相似的主题揭示性。因此,在进行长文本多语句文本处理时,可以根据语句的位置对文档词进行加权,关注主题揭示性好的语句。长文本多语句文本计算方法可参考文献[31]。
短文本语句数较少,且文档内容结构相对松散,很难从语句的位置顺序去判断其主题揭示性。但同一语句的文档词仍具有相似的主题揭示性,由此,可以通过对语句中的词进行采样,以推断该语句的主题揭示性,计算方法见公式(5):
(5)
其中,npos,nneg分别为语句中在pos和neg中的文档词个数,deg为语句的主题揭示性,值越大主题揭示性越好。
在确定了文档词所在语句的主题揭示性后,可通过公式(6)计算语句中文档词的主题加权权重。
(6)
其中,sem为不在外部语义词库中的文档词主题加权权重,N为语句中的文档词总个数。
由公式(4)和公式(6),确定词义加权权重,如公式(7):
(7)
3 FW-LDA模型
标准LDA模型的词分布是通过词频共现关系所生成的,其忽略了文档语义信息,很难有针对性地完成EMR文本中的疾病表征词提取任务。通过词特征加权改变词分布状态提高主题相关性词语权重,从而实现任务的有针对性主题提取。在对EMR文本中的疾病表征词进行提取时,词特征加权方式可有词性加权、词长加权和语义加权,其对应的权重确定方式如下:
词性加权权重的确定。疾病表征词在文本中对应的词性主要为名词与动词,因此一级词性为名词与动词。形容词与副词主要伴随一级词性出现,对疾病表征状态进行修饰,为二级词性。此外,在对疾病表征进行状态修饰时,会出现一定的重复,使得二级词性的词频偏高。因此,在计算一级词性的权重时需给予适当的系数,以减轻词频偏高带来的影响。
由于其他词性权重值为0,即在文档主题提取时不起作用。故为了降低词分布的复杂度、提升计算性能,在数据预处理时,去除标注为其他词性文档词。处理后数据集保留词性有:名词、动词、形容词和副词。然后,基于疾病表征词提取任务的特点,将四种词性分为两级,其中名词与动词为一级词性,形容词与副词为二级词性。
EMR文本中的疾病表征词词性加权权重可由公式(8)确定。
(8)
词长加权权重的确定。获取EMR文本中文档词的长度,参照公式(3)确定文档词对应的词长加权权重。
词义加权权重的确定。EMR文本中提取疾病表征时,应侧重病症描述词,如图3中的“头昏”、“发热”、“呼吸”,及疾病表征状态修饰词,如“不畅”、“轻微”。为了对文档词语义进行识别,笔者收集了疾病表征的常用词,并根据EMR文本数据特点,构建了对应的外部语义词库,结合公式(7)确定词义加权权重公式:
(9)
由公式(3)、公式(8)和公式(9),确定EMR文本中的疾病表征词提取的加权权重公式:
ρ=ρ1ρ2ρ3
(10)

图3 文档词性标注
3.1 FW-LDA模型结构
LDA模型受限于语义解释性,很难有效地提取出文本数据中的任务目标词。为了提升LDA模型的语义可解释性,实现有针对性地提取EMR文本疾病表证词,该文将词性加权、词长加权和词义加权引入标准LDA模型中,形成FW-LDA(feature weighting LDA)模型。FW-LDA模型结构如图4所示,符号说明具体见表1。
表1 FW-LDA模型符号说明
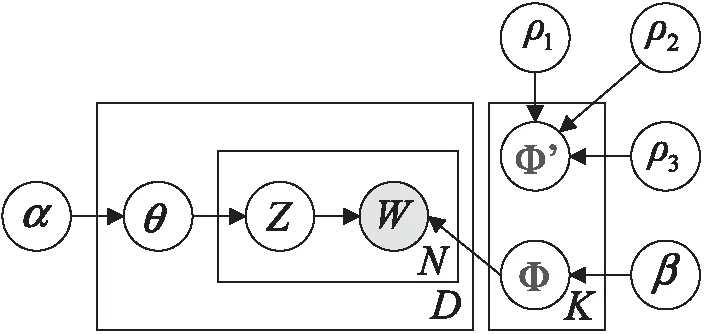
图4 FW-LDA模型结构
3.2 生成文档过程
FW-LDA模型的生成文档过程如下:

for主题 k∈[1,K] do 采样生成主题文档词分布Φk~Dir(β) Φ'k=ρ∗Φkend for for文档m∈[1,D] do 采样生成主题文档分布θm~Dir(α)for文档词n∈[1,Nm] do 采样生成主题Zm,n~Mult(θm) 采样生成词语Wm,n ~Mult(Φ'Zm,n)end forend for参数与变量说明: Φk:主题k的词分布Φ'k:主题k的词特征加权词分布θm:文档m的主题分布Nm:文档m的文档词数Zm,n:文档m的第n个词对应的主题Wm,n:采样最终生成文档词
4 实验分析
4.1 数据集
实验采用了某市疾病防控中心提供的心血管疾病数据,该数据字段主要为主诉、现病史、既往史和诊断四个部分。研究的主要目的是从EMR文本数据中提取出疾病对应的疾病表征,以辅助医生的诊断工作。考虑到患者自述的可能的不完善性与该数据本身的质量,本研究选取了字段为现病史的数据,共有3 678条数据。为了保证每条数据的信息质量,删除了少于50字的记录,最终得到3 595条数据样本。实验使用jieba分词工具对数据集文本进行分割,并保留了分词后各词对应的词性。此外,实验结合数据集的特点进行了词性信息量评估,在预处理时去除了动词、名词、形容词和副词以外的低信息量词性的词。最终样本的数据统计信息如表2所示。

表2 数据集信息统计
4.2 评价指标
以人工标注的方式,标注出每条样本对应的疾病表征词,并以人工标注的数据作为实验评价的基准,采用提取疾病表征任务下的主题一致性(Topic Consistency)[24,31]来评估模型提取主题词与人工标注的疾病表征词的一致性性能。
主题一致性计算公式见公式(11)~公式(13):
(11)
其中,TC为主题一致性, 为点互信息,PMIK为主题K的主题一致性,ntop为主题词数,w为相同主题下主题概率最大的前ntop个词的集合,p(wi)为词wi出现的概率,p(wi,wj)为词wi、词wj共现的概率,K为主题个数。TC的值越大,则提取的主题词与人工标注的疾病表证词的一致性越好。
精确率(Precision)计算公式为:
(14)
其中,P为精确率,TP为提取词为疾病表征相关词数,FP为提取词与疾病表征不相关词数。
4.3 实验设置
模型参数采用Gibbs采样估计,采样次数为1 000;主题数K,主题词数ntop=10;文档-主题服从参数为α(α=50/K)的Dirichlet分布,主题-词语服从参数为β(β=0.01)的Dirichlet分布。
根据任务目标与EMR文本数据特点,本实验构建了对应的任务侧重和非任务侧重的外部语义词库。实验中,任务侧重外部语义词库包含有64个词,共78个字;非任务侧重外部语义词库含有45个词,共50个字。
4.4 结果分析
实验固定了模型中除主题数以外的其他参数,主题数参数取值范围为[5,100]。图5为仅基于词性、词长、词义加权的LDA模型、LDA模型和FW-LDA模型的主题一致性对比图。

图5 不同主题数下的主题一致性对比图
从图5中可以看出:
(1)仅基于词性加权的LDA模型(pho1 + LDA)与LDA模型的主题提取性能相似。
(2)仅基于词长加权的LDA模型(pho2 + LDA)比LDA模型的主题提取性能略有提升。
(3)仅基于词义加权的LDA模型(pho3 + LDA)比LDA模型的主题提取性能有较显著提升,且随着主题数增加主题一致性有递减的趋势。
(4)在主题数值为20附近时,FW-LDA模型的主题一致性会有较好的表现,而主题数大于30,FW-LDA模型较仅基于词义加权的LDA模型主题一致性下降较快。
原因分析:由于数据预处理时去除了其他词性,因此仅基于词性加权的LDA模型与LDA模型的主题一致性性能相似。此外,仅基于词长加权的LDA模型在一定程度上,降低了单字词的出现率,提高了电子病历中专有名词的出现率,因此其较LDA模型的主题一致性有所提升。随着主题数的增加,模型提取出的主题词的数也在增加,会出现较多的与任务目标词无关的主题词,因此,主题一致性会出现较快的下降趋势。仅基于词义加权的LDA模型会根据所建立的侧重与非侧重外部语义知识库进行主题词筛选,在外部语义知识库较为完善的情形下,可以较好地提高任务目标词的出现概率,提高主题一致性性能。在模型所提取主题词数较多情况下,任务相关性较低的主题词会随之增多,那些字数较多的低相关性主题词将会在一定程度上,降低提取任务的性能。此外,由于现有分词工具分词存在一定的误差,也会对模型性能造成一定的干扰。因此,随着主题数增多,仅基于词义加权的LDA模型收到的干扰较小,主题相关性下降趋势也较缓。
这些结果都表明了基于词特征加权对文本提取任务性能提升的有效性。其中,基于词义特征加权有着较好的表现,并且外部语义词库质量的好坏将直接对模型结果产生影响。利用外部语义词库对模型注入文本提取任务相关领域知识,可以帮助模型更好的完成目标任务。
实验分别统计了主题数取值范围为[5,65]时两种模型提取词中疾病表征相关词数,表3给出了实验统计结果的疾病表征词提取的正确词数和精确率。
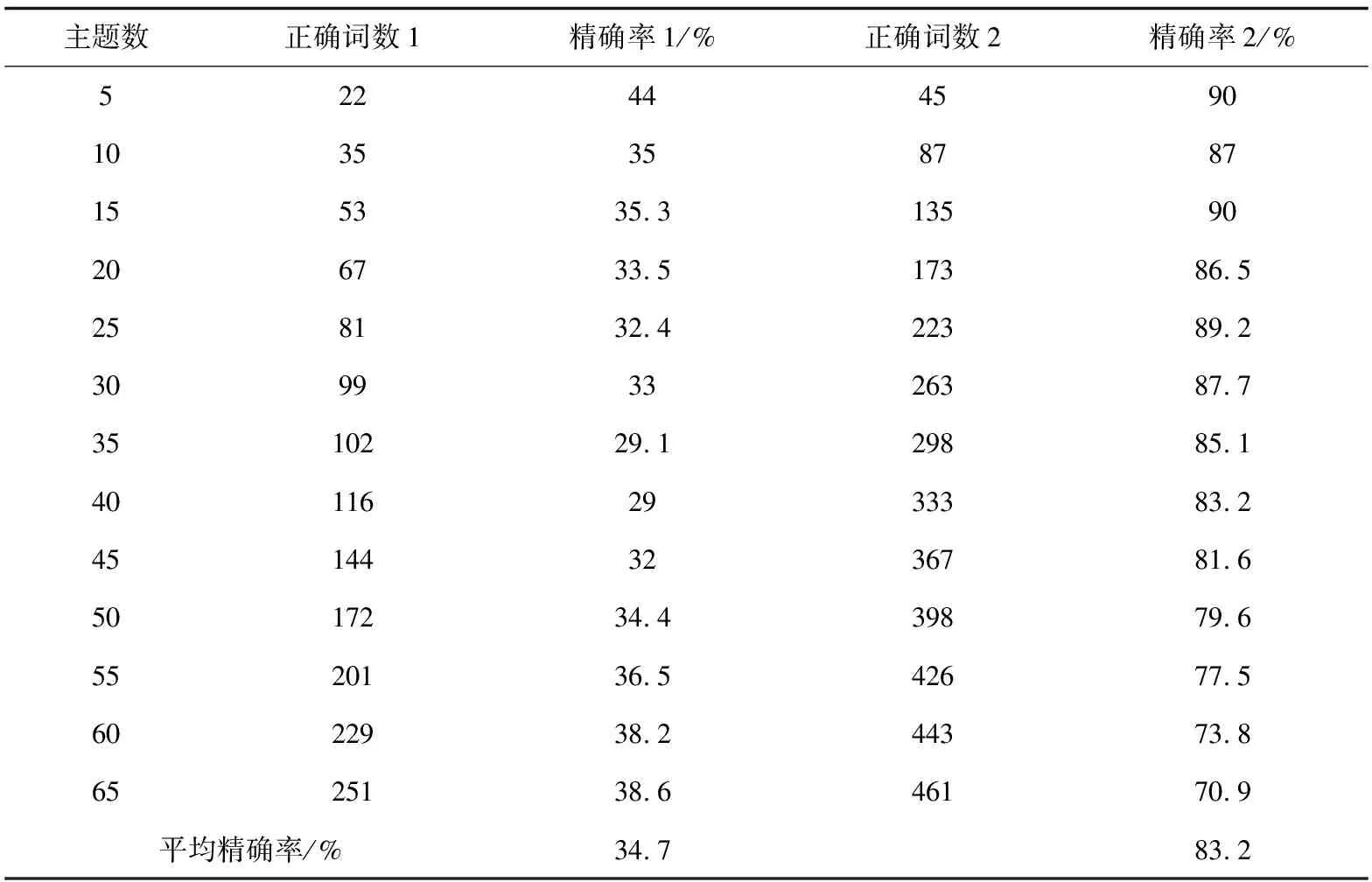
表3 疾病表征词提取精确率
其中,1表示LDA;2表示FW-LDA。

图6 不同主题数下的疾病表征词提取精确率对比图
从图6中可以看出:
(1)FW-LDA模型对疾病表征词的提取精确率明显优于标准LDA模型。且从表3的统计值可知,在主题数值范围[5,65]上,与LDA模型相比,FW-LDA模型的疾病表证词提取平均精确率提升了48.5%。
(2)主题数值偏大时,标准LDA模型的提取精确率呈提升趋势,而FW-LDA模型则相反,两模型的提取精确度差距趋小。在对提取出的主题词特点进行分析后,对该现象进行了解释:当主题数偏大时,模型提取主题词的规模将会变大,主题相关性弱的词被提取的概率也将随之变大,提取精确率便会随之减小。此外,在主题数值大于40后,提取的主题词有明显的重复,重复的主题词会使得两模型的精确率向中间值(0.5)靠拢,造成两模型的提取精确度差距趋小。
由于EMR文本本身的特点,如“无”、“有”、“就医”、“就诊”、“治疗”等词在文本中会有较高的共现频率。标准LDA模型是基于词共现频率进行提取的,故这些非疾病表征词会频繁出现在模型提取的主题词中,造成模型疾病表征词提取精确率偏低。FW-LDA模型基于词特征处理会针对性地降低这些任务无关词的共现频率,降低任务无关词在所提取的主题词中出现的概率。
由实验结果的主题一致性、疾病表征词提取的精确率可知:(1)将词性、词长和词义特征加权引入LDA模型可以有效提升模型的语义可解释性;(2)在电子病历的疾病表征词提取任务上,与LDA模型相比,所提出的FW-LDA模型表现更优越。
5 结束语
由于LDA模型忽略了语义信息,缺乏语义揭示性,在EMR文本提取任务中,很难有针对性地实现疾病表征词的提取。该文提出的FW-LDA模型将词性、词长和词义特征加权的形式引入了标准LDA模型,改变LDA模型的词分布状态,提高LDA模型对任务目标词的发现概率,进而实现模型对任务目标词的针对性提取。
实验结果表明:FW-LDA模型在EMR文本数据中提取疾病表征词的任务中,与标准LDA模型相比在主题数值小于30时主题一致性有着更优越的性能;此外,在主题数值范围[5,65]上,发现FW-LDA模型与标准LDA模型相比疾病表征词提取平均精确率提升了48.5%。
下一步工作将进一步完善外部语义词库,强化模型的疾病表征词的提取能力,进一步提升模型任务主题词的精确率。此外,将尝试其他领域任务中应用FW-LDA模型,研究其在不同领域任务中的性能。
