快递末端自提网点选址及快递柜配置优化
2022-05-30胡贵彦卢长永
胡贵彦,王 华,卢长永
(北京物资学院,北京 101149)
0 引言
近年来,我国快递业务量在日益增长的同时带来了一些配送难题。一方面,快递量大、配送对象分散导致投递耗时长、配送成本高等,使得配送面对的压力越来越大;另一方面,受新冠疫情影响,“无接触式配送”悄然兴起,对快递终端配送提出了新的要求。
快递柜自提方式作为无接触式配送的主要方式之一,很大程度上缓解了“最后一公里”配送难题,但快递柜自提方式依然存在快递柜数量配置供需不协调、自提网点选址不合理等问题。在快递柜布局配置方面,Wilson指出聚集效应在快递行业突出,应统一规划快递柜配置布局。谭如诗,等以南京城区菜鸟驿站为例,提出自提空间布局与居民社会属性、出行等行为密切相关。在自提点选址方面,张晶蓉,等综合运用层次分析法和重心法,采用定性和定量相结合的方法对郑州大学快递服务中心选址问题进行研究。Deutsch,等根据客户收入和设施运营成本,以利润最大化为目标构建模型。张海军,等以北京城市副中心为研究区域,建立整数规划模型,优化邮政速递自提网点。Morganti,等发现顾客与自提点的距离效用对自提点建立有较大影响。蒋森楚提出快递企业网点布局优化要从实际情况出发,保证与市场的匹配性。张秋燕分析亚马逊自提柜运营经验,总结出自提柜在选址方面应靠近用户、布置合理、靠近中央配送站等。
综上所述,关于自提网点选址问题,国内外学者针对不同应用情况提出了不同选址模型,且普遍认为服务半径和人口密度是主要考虑因素,但提出的方法复杂度较高,缺乏一定的普遍适用性;另外以往通常是单一研究自提网点选址或快递柜配置,缺少综合性。本文以服务半径和人口密度为主要考虑因素,为优化自提网点选址与快递柜配置,提出一种操作简单实用、科学强的方法,有助于缓解“最后一公里”配送问题。
1 快递末端自提网点现状及问题
我国快递末端自提网点主要有快递公司独立建设自提点、依托其他商业实体营业场所建立自提点、专业第三方收货服务自提点、快递柜自提点四类。
其中快递柜自提点能够使用户随时收取快件,隐私保护性较强,也可为广告商提供广告宣传,因此快递柜得以迅速发展。2015-2020年全国智能快递柜数量由6.4万组升至76.9万组,6年时间达到了原来的12倍。这种方式虽然存在对体积较大的快件无法投放、建立之初成本较高等局限,但快递柜自提相对于其他方式还是可以大幅提高投递效率、提高顾客满意度,智能快递柜自提点的发展将是不可逆转的趋势。本研究将主要对快递柜自提点进行分析。
快递末端自提点分布目前整体基本符合“服务跟随需求”原则,但还是不能很好地满足顾客需求。一方面,由于快递柜厂家繁多、市场混乱,选址标准不一,从而导致快递柜分布不均;另一方面,各品牌快递柜随意建设,覆盖范围较小,数量配置不科学,导致快递柜供需不平衡。
快递柜自提相较其它配送方式有不可替代的优势,但对其自身发展存在的快递柜自提点分布不均和快递柜数量设置不合理等问题需要加以解决。
2 模型构建
为解决上述问题,利用集合覆盖法对目标区域快递柜自提点的需求点进行处理,确定初步选址方案,并提出各自提点快递柜设置数量,然后利用层次分析法分析筛选出较优方案。
2.1 模型假设
选址模型构建是从某区域的所有服务设施备选点中选择若干个作为中心节点,然后用尽可能少的中心节点覆盖所有的需求点,形成一个网状射线状结构。该模型构建要求从已经确定的备选点中选择需要的中心节点,属于离散型选址模型。
为便于建立模型和方便模型求解,本节做如下假设:
假设1:每天快递量稳定且不考虑大型网购季节,并以日为单位进行研究;
假设2:顾客对取件方式没有偏好,接受快递柜自提方式;
假设3:建立的各个快递末端自提网点容量不小于快递量;
假设4:为便于计算,将研究区域按照实际小区划分,建立单独坐标系;
假设5:拟选择选址都有建设条件。
2.2 确定初步选址方案
利用集合覆盖法求备选方案,其目标是用尽可能少的服务设施点覆盖所有需求点。需求点指顾客取件地址,本文以顾客取件地址所处的每幢楼为一个需求点;候选点指自提点放置的位置。因快递自提点与顾客取件地址所属楼房相近,所以将候选点位置与需求点位置近似看做一个点,即在本文研究中需求点也是候选点。
目标函数:

约束条件:

式(1)中,u为快递末端自提网点选址变量,表示有个快递自提网点;式(2)表示每一个需求点都可以被覆盖;式(3)表示自提网点覆盖的需求点在其服务半径内;式(4)表示第i需求点是否被j个自提网点覆盖;式(5)表示在候选点j是否建立快递自提网点。
2.3 确定最终优化方案
利用层次分析法分析初步备选方案,选择出最终较优的方案。
(1)建立层次分析模型。层次分析模型的目标层为快递柜选址最优方案。根据对快递末端自提网点现状的研究,确定准则层为建设成本、客户满意度、物流效益、行走距离4个重要的因素。然后分析得到最终的甲方案、乙方案、丙方案。
(2)构造判断矩阵。用1~9 标度法(参见表1)进行两两对比,确定各因素之间的相对重要性并赋值。
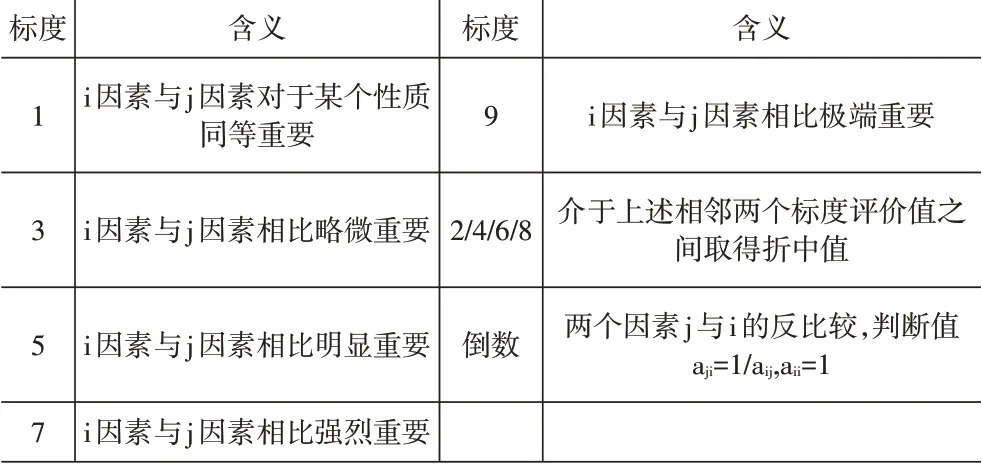
表1 重要性标度表
然后,构造出各层次中所有判断矩阵B:

其中B>0;B=1/B;B=1。
(3)确定各层权重。利用准则对判断矩阵中各因素进行权重计算。判断矩阵B对应的最大特征值特征向量,经过归一化处理,最后得到关于上一层次各因素相对重要性的排序权重。
(4)层次单排序及一致性检验。为避免其他因素对判断矩阵的影响,对判断矩阵进行一致性检验。当矩阵符合逻辑要求时,进行下一步分析。当0 时,表示有完全一致性;当接近0 时,有满意一致性;越大,不一致性越严重。由于随着矩阵阶数增大,保持一致性难度加大,因此引入平均随机一致性指标。当随机一致性比率小于0.10时,即认为判断矩阵具有满意的一致性,否则需要调整判断矩阵。

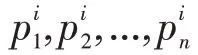
通过上述计算得到各个因素重要性排序值,通过对各个方案的权值进行排序,从而做出最后的决策。
3 实证分析
北京城市副中心第五组团地区中的金融街园中园、新建村二期、北京物资学院三个区域分别代表工业园类、小区类、学校类需求点,在需求类别、需求量等方面具有一定代表性。将上述构建的快递末端快递柜模型运用到实例中,以点代面进行分析。
3.1 数据收集及整理
从360地图中获取北京城市副中心第五组团地区数据进行统计分析并矢量化,将便利店、现存自提网点等作为快递末端备选网点。为后期方便数据分析,将居民区、高校等主要人口密集度高的地点作为需求点,建立各小区独立坐标系,得到需求点坐标。以金融街园中园、新建村二期、北京物资学院为例,编号首字母为A的区域是新建村二期共22个需求点,B为金融街园中园共40个需求点,C为北京物资学院共33个需求点(部分信息见表2)。
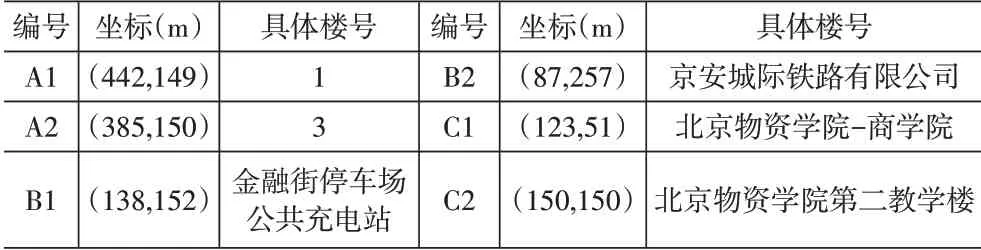
表2 部分小区需求点坐标示例图
经实地调研统计,目标区域每日快件自提量约为12 000 件,其中金融街园中园的最大快递量2 453,最小量867,平均量1 864。新建村二期最大快递量4 796,最小量1 370,平均量3 000。北京物资学院最大快递量3 516,最小量1 259,平均量2 336。三个区域快递量总计约为7 200,约占总区域的60%。
3.2 快递末端自提网点选址
3.2.1 确定初步备选方案。第五组团主要分为人口密度较高和人口密度较低两类地区,高校和住宅区属于人口密度较高地区,工业园属于人口密度较低地区。据调查人走路速度约40-50m/min,为研究计算方便,将步速统一为45m/min。因此本论文设定3 个研究方案,分别是方案甲,快递柜的服务半径R为315m,步行7min;方案乙服务半径R 为225m,步行5min;方案丙服务半径R 为135m,步行3min。下面将对以上三种方案情况进行研究。
(1)建立集合覆盖模型。以金融街园中园为例,方案丙的服务半径R为135m,展示具体的计算过程。
目标函数:

约束条件:


上述式子中,40表示有40个需求点或40个快递末端自提网点备选点;a表示需求点i的横坐标;b表示需求点i的纵坐标;x表示快递备选点j的横坐标;y表示快递备选点j的纵坐标;135表示快递末端自提网点选址的服务半径。
(2)利用Excel 对数据进行初步处理。本文运用excel软件根据集合覆盖模型运用距离公式对各个建筑坐标进行数据初步处理。计算得到初步备选方案(见表3)。
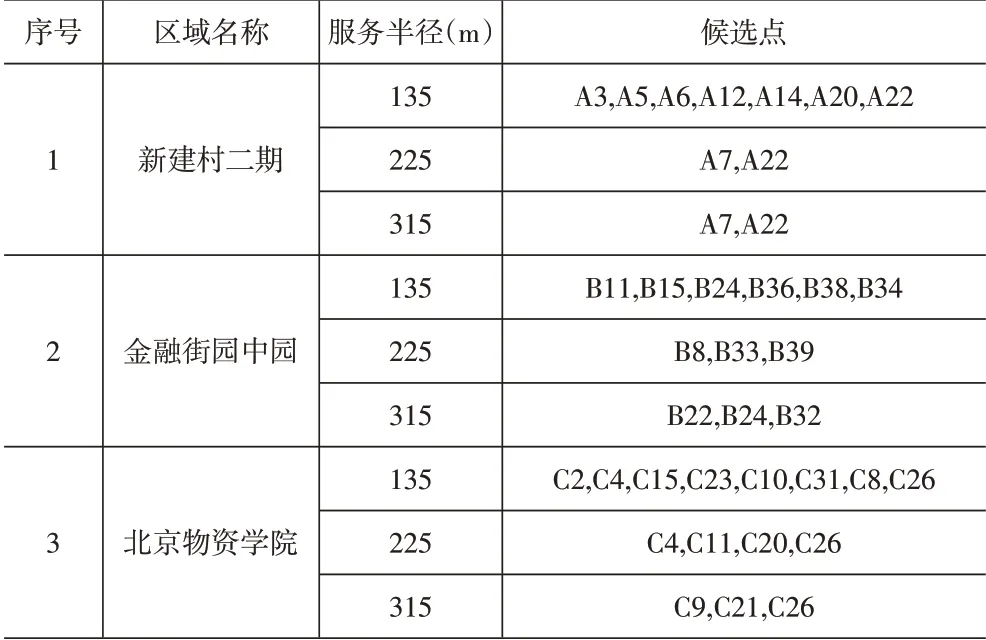
表3 初步备选方案
(3)python优化过程及结果。根据上面的备选方案,使用python软件利用贪婪算法对上述结果进行优化,不断趋近整体最优解,进而获得比较科学的结果。计算得到优化后的方案见表4。

表4 优化后方案
(4)初步备选方案结果。根据改变快递柜的服务半径获得不同的备选方案,方案甲金融街园中园候选点(B22,B24,B32),北京物资学院候选点(C9,C21,C26),新建村二期候选点(A7,A22),建议各区域每个候选点快递柜库存容量分别为平均622 件/d、946 件/d、1 500 件/d;方案乙金融街园中园候选点(B8,B33,B39),北京物资学院候选点(C4,C11,C20,C26),新建村二期候选点(A7,A22),建议各区域每个候选点快递柜库存容量分别为平均622件/d、709件/d、1 500件/d;方案丙金融街园中园候选点(B11,B15,B24,B36,B34),北京物资学院候选点(C4,C15,C23,C31,C26),新建村二期候选点(A3,A6,A12,A14,A20,A22),建议各区域每个候选点快递柜库存容量分别为平均373件/d、473件/d、500件/d。
3.2.2 确定最终优化方案。根据实际情况以及层次结构模型得出人口密度为主要考虑因素,本文将从人口密度高和人口密度低的两类情况进行分别研究。
(1)人口密度较低区域。在人口密度低的地区,目标判断矩阵为E。

由此可得到选址方案的总排序表(见表5)。
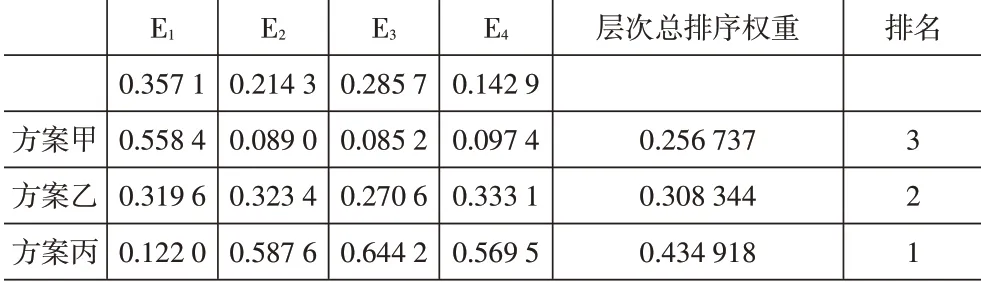
表5 总排序表(人口密度低)
方案甲、乙、丙的权重分别为0.256 737、0.308 344、0.434 918。三个备选方案的排序为甲<乙<丙。方案丙为最优选址方案。
(2)人口密度较高区域。在人口密度高的地区,目标判断矩阵为E。

可得到选址方案的总排序表(见表6)。

表6 总排序表(人口密度高)
方案甲、乙、丙的权重分别为0.244 567、0.300 94、0.454 493。三个备选方案的排序为甲<乙<丙。方案丙为最优选址方案。
综合上述针对人口密度高和人口密度低的不同地区,一致认为方案丙最优。方案丙金融街园中园候选点(B11,B15,B24,B36,B34)北京物资学院候选点(C4,C15,C23,C31,C26)新建村二期候选点(A3,A6,A12,A14,A20,A22),建议各区域每个候选点快递柜库存容量分别为平均373件/d、473件/d、500件/d,即各区域快递柜总库存容量分别为平均1 865件/d,2 365件/d,3 000件/d。因此无论是人口密度高还是人口密度低的地区,自提网点布局服务半径在合理范围内较小是比较好的选择。另外,根据快递柜布局设置规划快递柜组数有利于提高快递柜利用率。
4 结语
近年来快递柜自提已成为“无接触式配送”与解决快递末端瓶颈问题的主要方式之一,但在自提点分布和快递柜容量设置上仍存在一些问题。本文以点代面,以金融街园中园、新建村二期、北京物资学院分别代表北京城市副中心第五组团工业园类、小区类、学校类需求点,利用集合覆盖模型与层次分析法构建快递末端快递柜自提网点选址模型。根据快递量数据,优化各个自提点快递柜容量设置。希望可以对北京等其它地区快递末端自提网点选址、快递柜容量设置提供一定的借鉴。
