基于深度学习的图像检索研究概述
2022-05-30谢亦才易云
谢亦才 易云
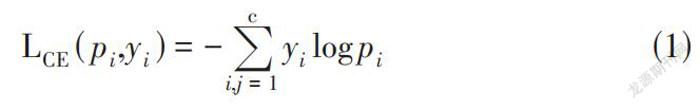
摘要:随着数字技术的发展,各领域产生并共享了大量的视觉内容。如何搜索到所需要的图像成为一个挑战,特别是在数据库中搜索相似的内容,即基于内容的图像检索(CBIR) ,是一个由来已久的研究领域,实时检索需要更高效、更准确的方法。人工智能在基于内容的檢索方面取得了进展,极大地促进了智能搜索的进程。文中,回顾了最近基于深度学习算法和技术开发的CBIR工作;介绍了常用基准和评估方法;指出面临的挑战,并提出有希望的未来方向。文中关注使用深度学习进行图像检索,并根据深度网络结构、深度特征、特征增强方法和网络微调策略的类型组织最先进的方法。文中调查考虑了各种最新方法,旨在展示基于实例的CBIR领域的全局视图。
关键词:Transformer;架构修改;预训练
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)10-0084-03
1 引言
基于内容的图像检索(CBIR) 是通过分析图像的视觉内容,在一个大型图像库中搜索语义匹配或相似的图像,给定一个描述用户需求的查询图像。CBIR一直是计算机视觉和多媒体领域的一个长期研究课题[1]。随着目前图像和视频数据量呈指数级增长,图像搜索是最不可或缺的技术之一。因此,基于内容的图像检索(CBIR) 的应用几乎有无限的潜力,如人员重新识别、遥感、医学图像搜索[2]、在线市场购物推荐等。
要准确检索到相应图像,必须准确提取图像特征,而提取特征的方法有传统的手工特征和现在广泛使用的深度特征学习方法。
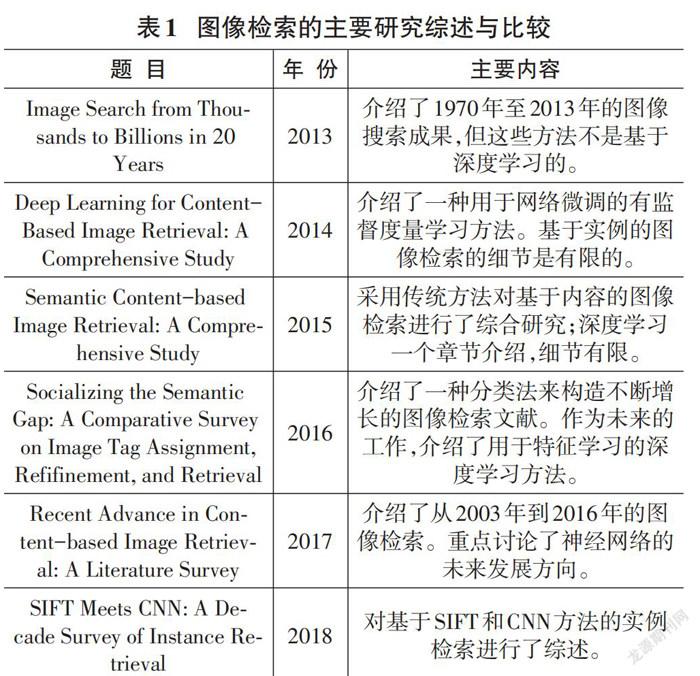
自2012年,深度学习已经在各研究领域有了广泛应用,因为深度神经网络可以直接从数据中进行多级抽象,提取深度特征。深度学习在图像检索[3]等计算机视觉领域取得了重大突破。在图像检索中有四种主要用作特征提取的深度卷积神经网络(DCNN) 模型,分别是AlexNet、VGG、GoogLeNet和ResNet。关于图像检索的主要综述与比较主要如表1所示。
2 基于深度学习图像检索分类
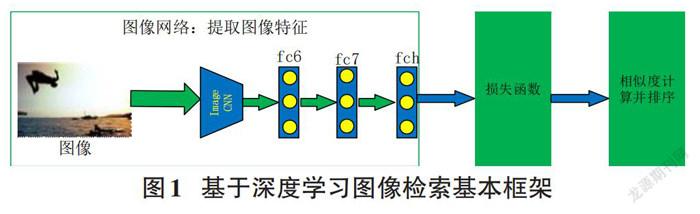
基于深度学习图像检索的基本框架如图1所示,首先通过深度神经网络(例如VGG) 提取图像特征,再通过全连接层映射到所设定维度特征空间,然后通过损失函数训练网络,最终训练好的网络把图像映射到低维特征空间,并进行相似度计算、排序,从而检索出最相似的图像。
基于深度学习图像检索方法可以分为基于已训练好的深度预训练模型和基于深度表征学习两大类。
2.1 基于预训练模型图像检索方法
这种方法有一些局限性,比如深度特征可能无法超越经典手工制作的特征。最基本的是,存在模型转移或域转移任务之间的问题,这意味着模型经过了训练对于分类,不一定要提取适合的特征进行图像检索。特别是,分类决策可以是只要特征仍在分类范围内,就可以进行分类边界,因此此类模型中的层可能会显示在特征匹配比最终分类概率更重要的情况下,在检索任务中能力不足。
此类方法可以进一步分为基于深度特征提取和基于深度特征融合的方法。
2.1.1 基于深度特征提取方法
(1) 前馈预训练模型。单前馈传递神经网络将整个图像送入现成的模型中提取特征。该方法相对有效,因为输入图像只馈送一次。对于这些方法,全连接层和最后一个卷积层都可以用作特征提取器。全连接层有一个全局感受野。经过归一化和降维后,这些特征是用于直接相似性度量,无须进一步处理,也不需要有效的搜索策略。但使用全连接层缺乏几何不变性和空间信息。
与单前馈传递神经网络相比,多前馈传递神经网络更耗时,因为从输入图像生成多个面片,并在编码为最终全局特征之前将两个面片送入网络。由于特征表示分为两个阶段:图像块检测和图像块描述,因此多通道策略可以提高检索精度。可以使用滑动窗口或空间金字塔模型获得多尺度图像块。
(2) 深度特征选择
深度特征提取可以从全连接层和卷积层提取。
选择一个全连接层作为特征提取器非常简单。通过PCA降维和归一化,可以测量图像的相似性。只有全连接层可能会限制整体检索精度,Jun等人[5]将多个全连接层的特征连接起来,Song等人[6]指出,在第一个完全连接的层和最后一个层之间直接连接可以实现从粗到精的改进。
来自卷积层(通常是最后一层) 的特征保留更多特别有益的结构细节。卷积神经元图层仅连接到输入要素地图的局部区域。较小的感受野确保生成的特征保留更多的局部结构信息,并且对图像变换(如截断和遮挡) 更为鲁棒。通常,池化卷积特征后的鲁棒性会得到提高。
(3) 特征融合
不同网络层之间的融合。融合不同层的特征的目的是在特征提取器中组合不同的特征属性。在深度网络中融合多个全连接层是可能的:例如,Yu等人[7]探索了融合网络的不同方法从不同的全连接层激活并引入性能最佳的Pi-融合策略,使用不同的权重用于聚合特征,Jun等人[5]构造多个全连接层串联在ResNet顶部,然后连接这些层的全局特征,以获得组合的全局特征。
在测量语义相似度时,来自全连接层(全局特征) 和来自卷积层(局部特征) 的特征可以相互补充,并在一定程度上保证检索性能。
模型之间的融合。可以将不同网络模型的功能组合在一起;这样的融合侧重于模型互补,以实现更好的性能,分为模型内和模型间。
通常,模型内融合指的是具有相似或高度兼容结构的多个深层模型,而模型间融合指的是具有更多不同结构的模型。例如,AlexNet中广泛使用的退出策略可以被视为模型内融合:在两个全连接的层之间,不同神经元的随机连接,每个训练阶段可以被视为不同模型的组合。作为第二个例子,Simonyan等人[4]介绍了一种ConvNet融合策略,以提高VGG的特征学习能力,其中VGG-16和VGG-19被融合。与单个对等网络相比,该模型内融合策略将图像分类中的前5位误差降低了2.7%。类似地,Liu等人[8]混合了不同的VGG变体,以加强对细粒度车辆检索的学习。Ding等人[13]提出了一个选择性深度集成框架,将ResNet-26和ResNet-50结合起来,以提高细粒度实例检索的准确性。为了关注图像中物体的不同部分,Kim等人[9]训练了三个注意力模块的集合,以学习具有不同多样性的特征。每个模块都基于GoogLeNet中的不同初始块。
2.1.2 基于深度特征增强的检索方法
(1) 特征聚合
特征增强方法将特征聚合或嵌入到提高深层特征的识别能力。在特征聚合方面,和/平均池化和最大池化是两种常用的卷积特征聚合方法地图。特别是,和/平均池化的区分性较低,因为它考虑了来自卷积层的所有激活输出,因此削弱了高度激活特征的影响。相反,最大池化特别适合概率较低的稀疏特征积极主动。如果输出特征映射不再稀疏,最大池化可能劣于和/平均值池化。
(2) 特征嵌入
除了直接池化或区域池化外,还可以将卷积特征映射嵌入到高维图像中空间,以获得紧凑的特征。广泛使用的嵌入方法包括BoW、VLAD和FV。使用PCA可以降低“嵌入式特征”的维数。注意,BoW和VLAD可以通过使用其他度量来扩展,如汉明距离。
(3) 注意力机制
注意力机制的核心思想是突出最重要的部分相关特征和避免无关激活函数的影响,通过计算注意力图来实现。获得注意力图的方法可分为两组:非参数和基于参数的,这两种方法的主要区别在于重要性权重是否可以学习获得。
(4) 深度哈希嵌入
由深度网络提取的实值特征通常是高维,因此检索效率不太满意。因此,很有必要将深层特征转换为更紧凑的编码。哈希算法由于其计算和存储效率高而被广泛用于大规模图像搜索。哈希码由哈希函数生成,而哈希函数可以作为一个层插入到深度网络中,这样可以同时使用深度网络训练和优化哈希码。在哈希函数训练过程中,将原始相似图像的哈希码嵌入到尽可能接近的位置,将不相似图像的哈希码尽可能分离。
2.2 基于深度特征学习的图像检索方法
在2.1节中,介绍了特征融合和增强现成的DCNN,仅作为获取特征的提取器。然而,在大多数情况下特征可能不足以进行高精度检索。为了模型具有更高的可扩展性和更有效的检索,常见的做法是网络微调,即更新预先存储的参数[10]。然而,微调并不是否定第2.1节中特征处理方法;事实上,这些策略是互补的,可以相互补充作为网络微调的一部分进行合作。
本节重点介绍更新网络参数的有监督和无监督微调方法。
2.2.1 有监督微调方法
(1) 基于分类的微调方法
如果新数据集的类标签可用,则可首先取在单独的数据集上先前训练好的诸如AlexNet、VGG、GoogLeNet或ResNet等主干网络的特征。然后,通过基于交叉熵损失优化其参数,可以对DCNN进行微调。交叉熵损失如公式1所示:
[LCE(pi,yi)=-i,j=1cyilogpi] (1)
其中,yi和pi分别是真实标签和预测概率值,c是类别总数。这种微调的里程碑工作是文献[11],其中AlexNet在具有672个预定义类别的Landmarks数据集上重新训练。经过微调的网络在与真实相关的数据集(如Holidays、Oxford-5k和Oxford-105k) 上生成了卓越的特征。新更新的图层用作图像检索的全局或局部特征检测器。
(2) 基于验证的微调方法
利用表示相似和不相似对的相似性信息,基于验证的微调方法学习一个最佳度量,该度量最小化或最大化数据对的距离,以验证和保持它们的相似性。与基于分类的学习相比,基于验证的学习侧重于类间和类内样本。
2.2.2 无监督微调方法
因为此类信息的收集成本很高或不可用,有监督网络微调的方法可行性变得较差。鉴于这些局限性,使用无监督的图像检索微调方法非常必要,但研究较少。
对于无监督微调,两个广泛的方向是通过流形学习挖掘特征之间的相关性以获得排名信息,以及设计新颖的无监督框架(例如自动编码器) ,每个框架将在下文中讨论。
(1) 基于流形学习的样本挖掘
流形学习侧重于捕捉数据集内在关联或推断。与原始的流形相似之处是提取的特征用于构造关联矩阵,然后使用流形学习对其进行重新评估和更新[12]。根据更新的关联矩阵中的流形相似性,基于验证的损失函数(如对损失、三重态损失或N对损失) ,选择正样本和硬负样本进行度量学习。这不同于上述基于验证的微调方法,其中硬正样本和负样本根据给定的关联信息从有序数据集中显式选择。
(2) 基于自动编码器的框架
自动编码器是一种神经网络,其目的是重建其输出尽可能接近其输入。原则上,将输入图像作为特征编码输入到潜在空间中,然后使用解码器将这些特征重构为原始输入图像。编码器和解码器都可以是卷积神经网络。
在自动编码器中,存在不同的重建级别(例如像素级别或实例级别) 。这些不同的重建会影响自动编码器的有效性,因为像素级重建可能会通过关注重建图像中的微小变化来降低编码器的学习特征,因为自然图像通常包含许多位置、颜色和姿势的细节因素。
3 结论和未来展望
在这篇综述中,回顾了图像检索的深度学习方法,并根据深度神经网络的参数更新方式将其分为预训练模型的深度图像检索和微调模型。具体地说,基于预训练模型方法涉及通过冻结预先存储的参数来获得高质量的特征,其中提出了網络前馈方案、层选择和特征融合方法。而基于微调的方法在有监督和无监督两种方法中都具有用于特征学习的网络参数更新操作。
基于深度学习图像检索方法未来发展方向主要有如下几个方面:
(1) 图像检索中的零样本学习;
(2) 端到端无监督图像检索;
(3) 增量图像检索。
参考文献:
[1] Smeulders A W M,Worring M,Santini S,et al.Content-based image retrieval at the end of the early years[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(12):1349-1380.
[2] Nair L R,Subramaniam K,Prasannavenkatesan G K D.A review on multiple approaches to medical image retrieval system[C]//Intelligent Computing in Engineering,2020:501-509.
[3] Kalantidis Y,Mellina C,Osindero S.Cross-dimensional weighting for aggregated deep convolutional features[C]//Computer Vision-ECCV 2016 Workshops,2016:685-701.
[4] K. Simonyan and A. Zisserman.Very deep convolutional networks for large-scale image recognition[J].arXiv preprint arXiv:1409.1556, 2014.
[5] H. Jun, B. Ko, Kim I. Kim, Kim J.Combination of multiple global descriptors for image retrieval[J].arXiv preprint arXiv:1903.10663, 2019.
[6] Song J F,Yu Q,Song Y Z,et al.Deep spatial-semantic attention for fine-grained sketch-based image retrieval[C]//2017 IEEE International Conference on Computer Vision.October 22-29,2017,Venice,Italy.IEEE,2017:5552-5561.
[7] Yu D,Liu Y J,Pang Y P,et al.A multi-layer deep fusion convolutional neural network for sketch based image retrieval[J].Neurocomputing,2018,296:23-32.
[8] Liu H Y,Tian Y H,Wang Y W,et al.Deep relative distance learning:tell the difference between similar vehicles[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:2167-2175.
[9] Kim W,Goyal B,Chawla K,et al.Attention-based ensemble for deep metric learning[C]//Computer Vision – ECCV 2018,2018:736-751.
[10] Oquab M,Bottou L,Laptev I,et al.Learning and transferring mid-level image representations using convolutional neural networks[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.June 23-28,2014,Columbus,OH,USA.IEEE,2014:1717-1724.
[11] A. Babenko, A. Slesarev, A. Chigorin, and V. Lempitsky.Neural codes for image retrieval[C]//in ECCV,2014:584–599.
[12] Donoser M,Bischof H.Diffusion processes for retrieval revisited[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition.June 23-28,2013,Portland,OR,USA.IEEE,2013:1320-1327.
[13] Ding Z Y,Song L,Zhang X T,et al.Selective deep ensemble for instance retrieval[J].Multimedia Tools and Applications,2019,78(5):5751-5767.
【通聯编辑:梁书】
收稿日期:2021-12-06
基金项目:本文受江西省自然科学基金(面上项目,20202BAB202017,面向监控视频的高效行为检测方法研究) 资助
作者简介:谢亦才(1981—) ,男,硕士研究生,主要研究方向为深度学习、图像分析与检索。