基于优化锚点的细粒度文本检测与识别
2022-05-30王漳梁祖红罗孝波
王漳 梁祖红 罗孝波









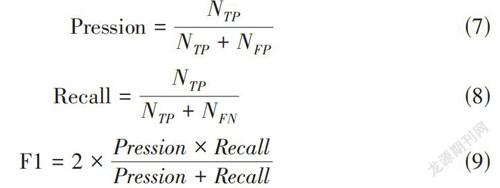
摘要:CTPN文本检测模型在细粒度文本检测过程中会出现断连、漏检的情况,尤其是在细粒度的文本场景下。针对以上问题,提出了一种细粒度文本检测算法。该算法基于CTPN模型网络进行改进,重新设计了垂直锚点尺度,以适应细粒度文本的特征;同时调整主干网络的结构适应锚点的尺度。在anchor的连接过程中采用了自适应间隔的连接方式,从而保留水平语义信息的完整性。文本识别阶段采用CRNN方式进行识别。通过PyTorch环境验证细粒度的发票数据集,所提方法相比于原CTPN文本定位方法效果显著提高。
关键词:文本检测;细粒度;锚点机制;文本识别;深度学习
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)10-0009-06
随着社会经济的发展,票据的重要性越来越被人们重视,尤其是在各个企业中使用增值税发票报账的人数日益剧增[1],财务管理人员录入发票的工作量大幅度提高。而传统人工录入票据内容的方式,工作强度高、效率低下,很容易导致工作人员在疲惫状态下疏忽出错。如能实现自动化地从图像上提取文字信息,会大大降低企业的人力和物力,为企业带来极大的便利。
使用电子设备将纸质中的字符翻译成计算机文字的过程被称为光学字符识别[2](Optical Chatacter Recognition,OCR)技术。OCR技术核心在于文本的检测和文本识别两部分。传统的文本检测包含基于连通域的方法[3-4]和基于滑动窗口(Sliding-window Method)的方法[5-6]。基于连通域的方法利用图像的形态学的特征,通过二值化、膨胀、腐蚀等一系列形态学操作将连通域找出来作为文本位置的候选集,通过人为设计特征规则过滤候选集,粗略定位图像中文本的位置。但若图像中存在背景噪声就可能造成连通错误的情况;其次,人为设定的过滤规则并不能有效区分文本与非文本区域。基于滑动窗口的方法设计多尺度的窗口大小,从左到右、从上到下依次扫描图像,通过分类器对窗口滑到的位置做是文本和非文本的判别。该类方法的不足在于对窗口的依赖难以把握,窗口的尺度、滑窗步长设置较为困难。
近几年,随着深度学习的发展,研究者们对于自然场景文本的检测有了大量的研究,成了当下的研究热点。文字检测在一定程度上是一种特殊的目标检测任务,从2014年开始,用于目标检测的R-CNN[7-9]系列论文被提出。该方法是基于RPN (Regions with Convolutional Neural Network)网络进行运作的;首先做特征提取工作,通过主干网络获取输入图像的特征图;然后通过锚点机制,计算锚点对应的置信度;对初步结果筛选并做出细致调整,最后得到检测结果。在国内,郑祖兵等人[10]将医疗票据的信息分为出厂印刷的内容和后期打印的内容,利用Faster RCNN[9]算法完成后期打印内容的定位,再将文本分割开来进行单字符的识别,总体准确率达到95.4%。何鎏一等人[11]使用连通域分析方法完成整个增值税发票版面文本的检测;连通域最优阈值的大小很难确定,可能会存在断连情况,同时也不利于文本的筛选,鲁棒性较差。基于RPN的思想,Tian等人[12]提出了专门用于文本检测的开山之作CTPN(Connectionist Text Proposal Network)算法。随后,EAST[13]、TextBox++[14]等系列场景文本检测算法相继提出。
公认的自然场景文本检测任务是国际文档分析与识别国际会议(International Conference on Document Analysis and Recognition,ICDAR)举办的比赛。以ICDAR2015[15]文本检测任务为例,比赛所用数据集图像像素规格为1280×720,其单个文字的高度从50px到80px,甚至达到100px,占比高达近14%。票据识别隶属于自然场景文本检测的子类任务,不同于自然场景文本字体大的特点,票据图像文字排列分散、字体较小,在一张图上的文字规格基本统一,文字高度占比通常在20px左右,高度占比仅为3%左右。如果不对图像做任何处理就直接使用传统OCR技术进行识别;或是直接用自然场景文本检测模型对其进行检测和识别,往往会出现漏检断检,效果不好、鲁棒性差等问题。
针对自然场景文本检测模型在细粒度的文本上出现的断检漏检情况,本文搭建一种面向漏检断连的细粒度票据文本检测与识别方法,该方法的文本检测阶段和文本识别部分均由深度学习模型实现,两者模型串联起来形成端到端的完整架构。文本定位模型采用改进的CTPN网络,主要改进在:(1)调整CTPN主干网络池化层和卷积层,更少的最大池化层使得Anchor在特征图上的移动对应原图更短的步长,即捕捉更精细的文字特征;(2)针对细粒度的文本,重新设计CTPN模型中的Anchor尺度和数量;(3)对于生成一系列文本建议区域,采取了自适应间距解决了文本的断连问题,提高文本行检测的完整性。文本识别模型采用CRNN模型[16]。对比实验结果表明,自制的细粒度票据数据集上,效果显著。
1 本文方法
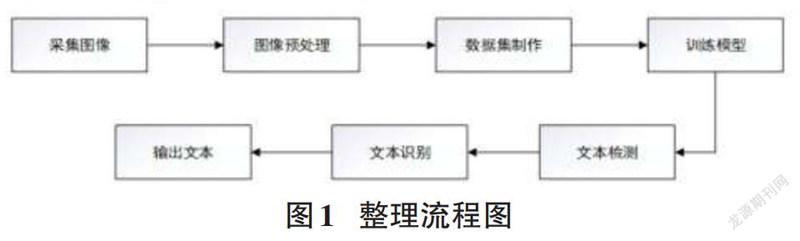
本文提出的面向漏检断连的细粒度票据文本检测与识别主要由图像采集模块、图像预处理模块、文本检测网络模块、文本识别网络模块、文本输出模块等5个主要模块组成,该算法的整体设计流程图如图1所示。
1.1 图像采集与图像处理
随着电子设备的层出不穷,图像采集的方式也有许多可选的操作——扫描仪、智能手机、摄像机、高拍仪等。大多数人往往更倾向于手机移动端便捷的拍照方式,本文所采用的發票数据集是由高拍仪完成。为了后期能够更好地进行文本的区域划分、文本检测和文本识别,需要将采集到的倾斜图像进行仿射变换或者水平校正的操作。一般对于倾斜图像的矫正需要借助于Hough变换[17],其主要是利用图片所在的笛卡尔空间和霍夫空间之间的变换。在Hough变换中,常用式(1)表示直线:
[ρ=xcosθ+ysinθ] (1)
其中,ρ为点到直线的距离,θ为直线与X轴正向的夹角度数;在Hough空间中(ρ,θ)为已知量,(ρ,θ)为未知量。笛卡尔空间上一个点的n个方向映射到Hough空间中为一条正弦曲线,当多个共线的点在多个方向上的映射就会交于一个(ρ,θ);在霍夫空间图像上,具有最多交线的点具有便是一条直线,此时可以求出倾斜角度θ完成图像的水平矫正。
1.2 文本区域划分
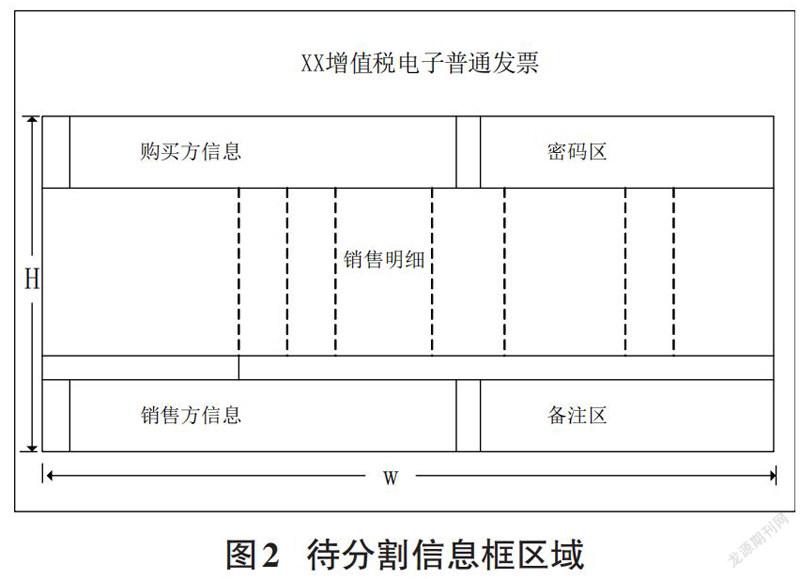
基对文本区域进行划分的依据是发票的尺寸规格为国家税务局统一规定大小,通过等比例缩放可以将输入的图像进行文本区域的粗划分。文本区域通常包含购买方信息、销售方信息、销售明细、密码区和备注等信息区域。增值税票据的模板样式如图2所示,其信息框的高H、宽W及任何一个小框的位置信息(x,y,h,w)都可以先验测出。
假设给定一张票据图,通过openCV直线检测将票据中信息框主体裁出来,测得其尺寸为H’×W’,通过公式(2)可以得到输入图像与标准模板的缩放比例α。输入图像中每一小框的位置信息(x’,y’,h’,w’)可以按照公式(3)进行线性变换。分割出的小区域信息示例如图3所示。
[α=H / H'] (2)
[x' =α×xy' =α×yh' =α×hw' =α×w] (3)
2 基于CTPN的文本位置检测
本文检测方法在CTPN基础上做出了3个改进:(1) 重新设置Anchor的尺度,以适应票据细粒度的特点;(2)调整特征提取的主干网络,即减少原VGG的Conv5阶段(包含一个最大池化层),使得Anchor的每一次移动都对应原图更小尺度的移动,以适应Anchor的尺度;(3)在Anchor的合成阶段摒弃了固定阈值的做法,先对行进行聚类,再自动计算Anchor的最大间隔,并将其设为阈值,使得间隔过长的Anchor也能得以连上。
2.1 CTPN算法
由于发票中的文本具有较好的水平性质,本文提出的票据文本定位方法是基于CTPN算法的,其结合了卷积神经网络和循环神经网络,如图4所示。
首先通过主干网络VGG16[18]进行卷积操作,得到conv5的特征图。为了得到基于时序的特征,在特征图上以3×3的窗口进行滑窗拆分特征图,得到基于序列的特征后将其输入到BiLSTM[19]中。通过BiLSTM输出的特征转换成向量的形式输入到全连接层(Fully connected layer,FC)后准备输出。输出层主要有三个部分,2k个anchor的位置信息、2k个文本与非文本的得分和k个anchor的水平偏移量。获取文本建议框以后将得分较低的候选框剔除,并使用NMS过滤多余候选框。
CTPN的思想是基于固定锚点机制的,在特征图上每个像素点的垂直方向上设置了[k]个不同高度的anchor,在[y]方向上从11px~273px(依次除以0.7),在[x]方向上固定尺寸(16px)。回归层的输出是预测anchor的中心位置高度y轴坐标和矩形框的高度h值,每个anchor的位置信息由两部分组成,[k]个anchor对应[2k]个值。关于anchor垂直坐标的计算如公式(4)所示。
[VC=(Cy-Cay)/haVh=log (h/ha)V*C=(C*y-Cay)/haV*h=log (h*/ha)] (4)
其中,[{vc,vh}]和[{v*c,v*h}]分别是预测坐标和真实坐标。[{cay,ha}]是anchor的y軸坐标和高度,[{cy,h}]是预测出来的y轴坐标和高度,[{c*y,h*}]是真实的y轴坐标和高度。
在正负样本分类问题上,其本质是一个二分类问题,采用softmax损失作为损失函数,对应的输出为文本的得分和非文本的得分,[k]个Anchor对应[2k]个值。在[x]方向上的回归任务,主要用来精修文本行的两个端点,表示每个Anchor的水平偏移量,其计算如公式(5)所示。
[o=(Xside- CαX) / Wαo*=(X*side- CαX) / Wα] (5)
以上三个分支对应三部分的学习任务,其损失函数是分类损失和回归损失的和,如公式(6)所示。
[L(si,vj,ok)=1NsiLcls(si,s*i)+λ1NvjLrev(vj,v*j)+λ2NokLreo(ok,o*k)] (6)
其中,[Lcls]为分类损失,采用softmax loss;[{Lrev,Lreo}]为垂直方向上和水平方向上的回归损失,使用Smooth L1 loss。[{Si,Vj,Ok}]为网络预测输出,[{S*i,V*j,O*k}]代表真值标签。[{λ1,λ2}]为权重系数,用于平衡各学习任务的损失。[{Ns,Nv,No}]为归一化参数,表示对应任务的样本数量。
2.2 调整特征提取的主干网
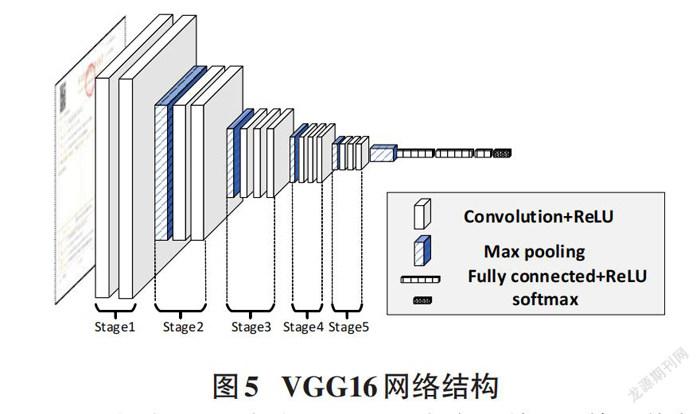
VGG16包含了13个卷积层和3个全连接层,其网络如图5所示。CTPN算法选取Stage1至Stage5的卷积层用来提取输入图像的特征,conv5_3层的特征图经历了4次Max-pooling Layer,特征图上的感受野对应原图的1/16,在特征图上移动1个像素对应原图移动16个像素。对于自然场景文本数据集而言,街景文字的尺度普遍较大,对于这样的感受野,CTPN算法中的anchor检测级别仍能够对应到文字的一部分,获得部分文字特征。
而本文使用的数据集图像尺寸为1024×768,略小于ICDAR2015数据集的尺度,对比图如图6所示。此外,本文数据集中文字的尺度远不及自然场景中文本的尺度,若经过原始的CTPN卷积层后,Anchor所对应原图的感受野区域包含多个文字,检测级别不够精细。为了适应这种小尺度的文本、捕捉更精细的特征,本文算法将卷积操作进行到Stage4即可。输入的图像经历3次Max-pooling Layer,特征图上的感受野对应原图的1/8,在特征图上移动1个像素对应原图移动8个像素,从而Anchor可以获得更细的特性表征。
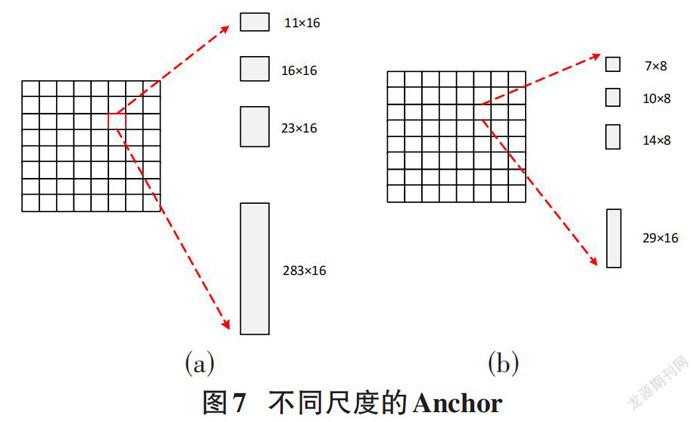
2.3 小尺度锚点策略
CTPN针对不同尺度的自然场景文本,设置了不同尺寸的Anchor。如图7(a)所示,其中,在x方向上的尺度固定(16px),在[y]方向上设置了10个不同尺度,从11px(依次除以0.7)直到283px。本文数据集中的文字,其规格较为统一,每一行文本字体大小一致;最高的文字为中间标题,其像素值在25px左右。针对细粒度的文本,从优化anchor的思想出发,本文设计了更少、更小尺度的anchor。如图7(b)所示,在[x]方向将anchor的尺度缩小为原来的一半(8px),适应减少1个Max-pooling Layer的改变所带来的影响,即anchor覆盖原图每个点且不相互重叠;同时能将anchor检测的级别精确到文字更细的特征上。在y方向上设置了5个不同尺度{7px,10px,14px,20px,29px},满足本文数据在y方向上的最大需求。
2.4 自适应间距的文本行构造算法
在获得一系列的text proposal之后,需要将建议框连接成文本线。CTPN先将分类得分低的Anchor判定为非文本并将其剔除,然后使用非极大值抑制,将剩下的anchor中重叠程度大的Anchor进行合并。
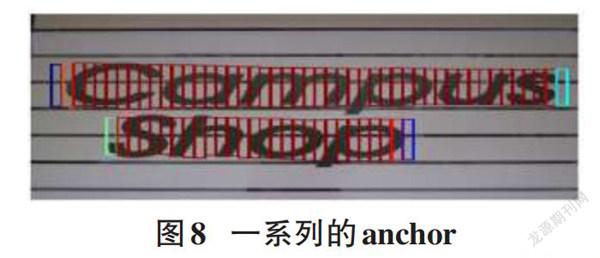
CTPN中按照水平[x]坐标排序Anchor, 将水平距离小于固定阈值(50px)和垂直方向上重合度大于0.7的筛选出,再挑出分类得分最大的anchor。如此依次筛选,将符合的Anchor组成一个系列,如图8所示。最后将此系列的Anchor合并成语句获得最终的文本检测框。由于票据数据集有良好的分行特征,基于该思想在对[x]排序之前对[y]左边进行聚类,类别数N即为文本区域的行数。
在每一行上分别计算最大的Anchor间隔,将其作为阈值;这种动态设置阈值的方式,将一行的文本框连接起来,保证间隔较大的文字也能被连接起来,便于后续字符识别网络的使用。
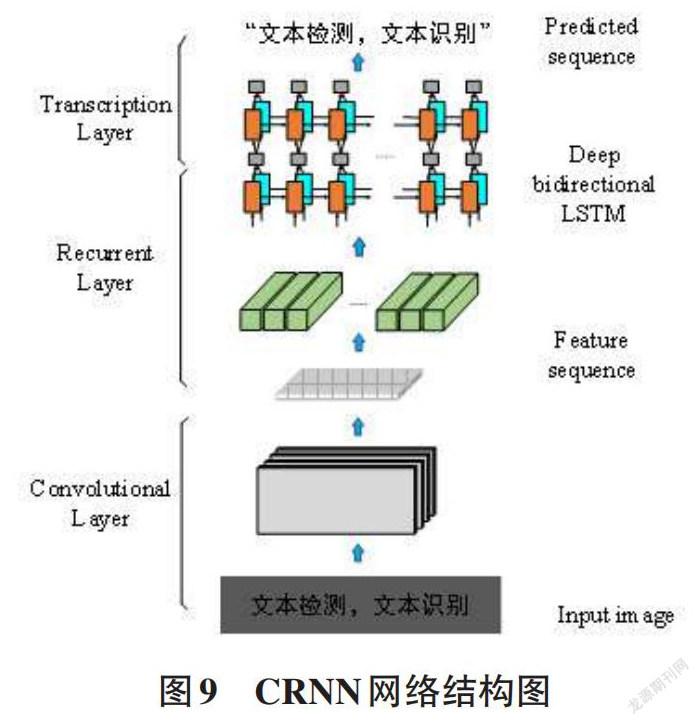
3 基于CRNN的文本识别
字符文本识别是将图像中的文字序列转换成计算机语言描述字符的序列。目前,在文字识别上的深度学习方法主要有两种实现方式:一是基于Attention注意力机制[20],二是基于CRNN实现。本文采用的CRNN是一种端到端的卷积循环神经网络模型,它采用了“CNN+LSTM+CTC”的网络结构,如图9所示。网络具体的详细参数如表1所示。
识别流程包含了三部分,自底向上依次是:(1)卷积层由固定的卷积层和最大池化层组成,主要是从输入的图像中完成文本特征序列的提取;(2)循环层作为一个序列建模,由一个双向的LSTM组成完成,从卷积层获取的特征序列分析过程;(3)转录层把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。
4 实验与结果
4.1 实验环境
本文实验硬件平台的CPU型号为Intel Xeon E5-2620 v4,GPU为NVIDIA Corporation GP100GL,16G显存,详细实验环境如表2所示。
4.2 数据集
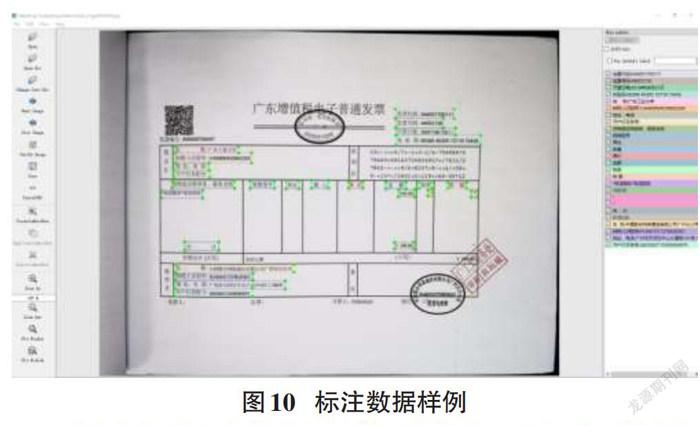
本文从细粒度票据文本检测和识别两个方面进行测试分析。在财务部门共随机采集330幅图像用于文本检测和识别,其中300张用于训练文本定位模型,测试采用与训练样本无交集的30张数据集。将采集处理的图像通过Labelimg标注工具进行标注,样例如图10所示。得到对应PascalVOC数据格式的文件,如图11(a)所示,每个标注框都对应一个Object标签,编写脚本将其中bndbox标签和name标签的内容提取出来制作为icdar数据集格式如图11(b)所示。
4.3 评价指标
本文的文本检测采用ICDRA大赛常用的评价指标:准确率(Pression)、召回率(Recall)和F1值;准确率可以反映识别错和多识别的情况,召回率可以反映识别错和漏识别的情况;其表达式如公式(7)~(9)。
[Pression= NTPNTP+NFP] (7)
[Recall=NTPNTP+NFN] (8)
[F1=2×Pression×RecallPression+Recall] (9)
其中,[NTP]表示将正样本预测为正样本的数量,[NFP]表示将负样本预测为正样本的数量,[NFN]表示将正样本预测为负样本的数量。
4.4 实验结果
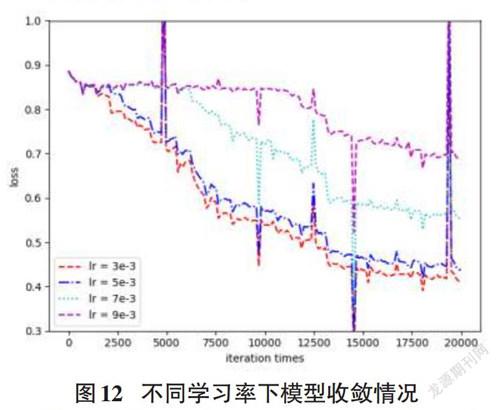
在训练CTPN模型时,采用SGD随机梯度下降法,超参数Momentum为0.9,学习率多次对比测试最终设置为0.003,batchsize设置为128,在此基础上迭代30轮,共60000次,间隔采取20000次繪图如图12所示。
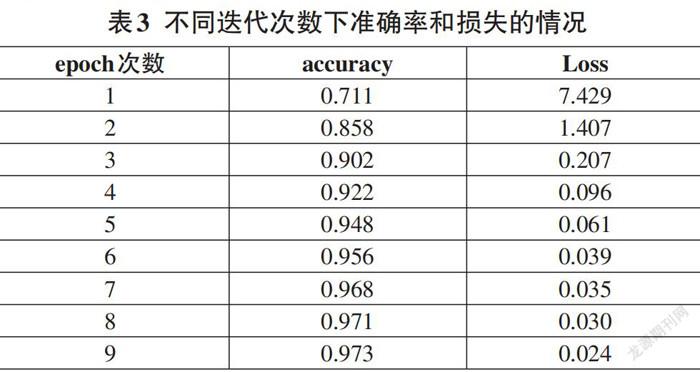
CRNN模型训练图像的高度归一化到32像素;训练采用Adam优化器,自适应动态调整学习率。初始化学习率为0.0001,BatchSize为256,当进行不同次数的迭代时,模型识别的准确率必定也会有所影响。理论上迭代次数越多,模型的准确率越高,最终趋于收敛。由表3可知,当迭代6个Epoch后,网络的损失维持在0.03左右,准确率维持在97%上下几乎不再变化,趋于收敛。
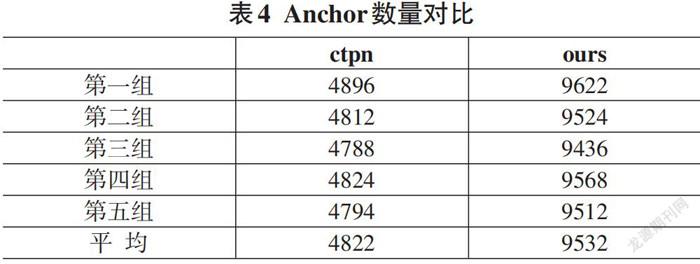
将CTPN用于细粒度文本的图像检测任务上,改进策略主要基于调整其Anchor的尺寸,以适应小尺度的文本图像。抽取5张票据,将票据主体的信息框作为输入,分别用CTPN模型和本文改进Anchor机制的CTPN模型做对比实验,在产生Anchor的数量上,结果如表4所示。可以发现在同样的输入上,本文改进的模型产生的候选Anchor远大于原文方案,并且本文方法产生Anchor的数量近似为原文的2倍,主要是因为改进的锚点在x方向上的尺寸减小一半。
为了验证本文改进的文本检测方法在细粒度文本上的优越性,将本文模型和原ctpn模型分别在icdar2015数据集上和细粒度票据数据集的测试集上进行测试验证,最终结果如图13所示。从图中可以看出,本文方法在准确率、召回率和F值上对icdar数据集的适应性都不如原ctpn模型,精度分别降低了3.6%、2.1%和2.7%。但是在细粒度的发票数据集上,准确率、召回率和F值上都高于原ctpn模型的效果,精度分别高出了2.7%、2.3%和2.5%。相比较之下,本文方法有效地提高了细粒度文本场景的检测精度。
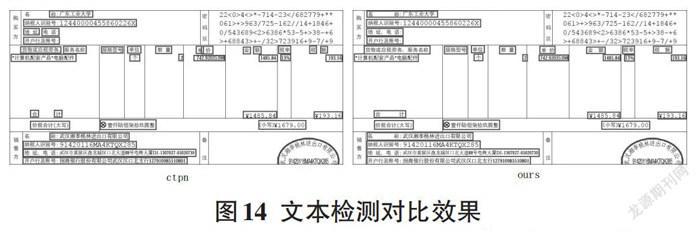
将分割出的购买方、销售方和详细信息区域分别送入两个检测模型中,得到检测出的位置信息后再还原到票据图中,测试的结果如图14所示。在ctpn检测模型中,出现的“名”字漏检,“合计”“税额”断检等问题,在笔者所提算法中均被很好地解决。
为了进一步验证对本文细粒度文本检测改进的有效性,在上述两种不同算法的文本检测后,接上同一CRNN文字识别模型进行字符识别。识别的结果如表5所示,本文改进的检测算法接上CRNN模型方式优于CTPN接上CRNN模型的方式,在准确率、召回率和F值分别高出1.3%、1.1%和1.2%,间接证明了本文所提算法能检测出漏检的文字。
5 结论
本文针对CPTN网络用于细粒度的文本检测任务中出现的漏检和断连情况,提出了一种适合细粒度文本检测的方法。针对细粒度的图像文本,重新设计ctpn网络中的锚点机制,在x方向上缩小步长提取更细的特征信息,在y方向上减少不必要的尺寸、减少计算的代价,并减少主干网络中的一个最大池化层适应Anchor宽度的改变。通过对所提的算法进行评估,从各項指标的结果表明,本文提出的算法能够比原模型更好地适应细粒度场景文本的检测,为类似细粒度的场景文本检测提供了新思路。
参考文献:
[1] 何文琦.基于OCR技术的高校财务报销新探索[J].商业会计,2020(10):79-81.
[2] Govindan V K,Shivaprasad A P.Character recognition—A review[J].Pattern Recognition,1990,23(7):671-683.
[3] Matas J,Chum O,Urban M,et al.Robust wide-baseline stereo from maximally stable extremal regions[J].Image and Vision Computing,2004,22(10):761-767.
[4] Chen H Z,Tsai S S,Schroth G,et al.Robust text detection in natural images with edge-enhanced Maximally Stable Extremal Regions[C]//2011 18th IEEE International Conference on Image Processing.September 11-14,2011,Brussels,Belgium.IEEE,2011:2609-2612.
[5] Chen X R,Yuille A L.Detecting and reading text in natural scenes[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2004.CVPR 2004.June 27 - July 2,2004,Washington,DC,USA.IEEE,2004:II.
[6] Lee J J,Lee P H,Lee S W,et al.AdaBoost for text detection in natural scene[C]//2011 International Conference on Document Analysis and Recognition.September 18-21,2011,Beijing,China.IEEE,2011:429-434.
[7] Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.June 23-28,2014,Columbus,OH,USA.IEEE,2014:580-587.
[8] Girshick R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision.December 7-13,2015,Santiago,Chile.IEEE,2015:1440-1448.
[9] Ren S Q,He K M,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[10] 郑祖兵,盛冠群,谢凯,等.双网络模型下的智能医疗票据识别方法[J].计算机工程与应用,2020,56(12):141-148.
[11] 何鎏一,杨国为.基于深度学习的光照不均匀文本图像的识别系统[J].计算机应用与软件,2020,37(6):184-190,217.
[12] Tian Z,Huang W L,He T,et al.Detecting text in natural image with connectionist text proposal network[C]//Computer Vision – ECCV 2016,2016:56-72.
[13] Zhou X Y,Yao C,Wen H,et al.EAST:an efficient and accurate scene text detector[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.July 21-26,2017,Honolulu,HI,USA.IEEE,2017:2642-2651.
[14] Liao M H,Shi B G,Bai X.TextBoxes:a single-shot oriented scene text detector[J].IEEE Transactions on Image Processing,2018,27(8):3676-3690.
[15] Karatzas D,Gomez-Bigorda L,Nicolaou A,et al.ICDAR 2015 competition on robust reading[C]//2015 13th International Conference on Document Analysis and Recognition (ICDAR).August 23-26,2015,Tunis,Tunisia.IEEE,2015:1156-1160.
[16] Shi B G,Bai X,Yao C.An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(11):2298-2304.
[17] Srihari S N,Govindaraju V.Analysis of textual images using the Hough transform[J].Machine Vision and Applications,1989,2(3):141-153.
[18] Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[J].CoRR,2014,abs/1409.1556.
[19] Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[20] Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly learning to align and translate[J].CoRR,2014,abs/1409.0473.
【通聯编辑:唐一东】
收稿日期:2021-12-15
基金项目:国家基金:单元流水车间双重资源优化配置(项目编号:71402033)
作者简介:王漳(1996—) ,男,湖北襄阳人,硕士,研究方向为计算机视觉;梁祖红(1980—) ,男,广东惠阳人,教授,博士研究生,研究方向为深度学习;罗孝波(1997—) ,男,湖南娄底人,硕士,研究方向为文本数据挖掘。