基于分批估计的自适应加权数据融合算法
2022-05-29施震华包晓安
施震华,张 娜,包晓安,宋 杰
(1.浙江理工大学 信息学院,浙江 杭州 310018; 2.武汉理工大学 经济学院,湖北 武汉 430070)
近年来,随着传感器技术和多传感器融合技术的不断发展,多传感器技术逐渐被应用在日常生活领域,例如智慧农业利用多传感器采集温室大棚的温湿度、二氧化碳浓度、土壤湿度等参数,以有效地监控大棚环境,为农业应用提供了一种可靠的方案。随着多传感器技术应用领域不断拓宽,使用者对传感器的测量精度和稳定性也提出了更高的要求。
针对测量精度不足和稳定性不够等问题,文献[1]提出了改进的自适应卡尔曼滤波,并在北斗伪距单点定位中的研究滤波问题中进行了实验。该研究采用基于移动窗口协方差估计的自适应卡尔曼滤波算法,相比于传统卡尔曼滤波的定位精度提高了50%,收敛速度提高了90%。文献[2]提出了一种基于深度学习并利用特征图加权融合实现目标检测的方法。该方法相比于之前的方法得到了更高的目标检测精度以及目标检测效果。但是,卡尔曼滤波也存在缺陷,当目标长时间被遮挡,会存在目标丢失的情况。此外,深度学习也需要大量的数据集和训练集进行训练,并不适用于大众传感器数据的分析。因此,面对不同的问题,应该采用恰当的数据融合方法进行处理[3-5]。
目前,数据融合方法按融合方式分类可以分为3种:像素级融合、特征级融合和决策级融合。由于一般传感器采集到的都是模拟信号或者数字信号,对于智能家居或者应用系统等场景的初步处理都是对像素级的数据量进行融合,因此这种处理方法最为常见。像素级的方法主要有加权平均法、选举决策法、卡尔曼滤波法和数理统计法[6-9]。与此相关的还有特征级融合和决策级融合,这两种算法一般都需要在先验概率的前提下才能采用,对系统资源的要求比较高。对于传感器的原始数据处理,像素级融合算法较为适合,其既可以被应用在嵌入式芯片上,又可以提高系统的精确度和稳定性。传统的自适应加权数据融合算法只是对噪声信号作权值较小的处理,没有进行数值一致化检测,对数据的准确性有一定的干扰。此外,随着数据量的不断增加,其方差易出现僵化,不能及时体现数据的变化性,无法得到准确的预测值[10]。针对该问题,本文将数值一致性检测处理技术、时间特征和空间特征技术相结合,采用时间序列和空间序列对数据分批求其方差;然后利用数据一致性检测对噪点进行剔除。剔除后的数据的方差能较好地体现数据的真实性和波动性,并得到自适应因子;最后,通过自适应加权法对数据进行融合。基于此,针对这种传感器的本身方差特性和多传感器协方差的影响,本文提出一种基于自适应加权的数据融合算法,并通过仿真实验验证了所提方法的有效性。
1 相关技术
1.1 自适应加权融合
自适应加权算法指的是当处理数据时,能及时根据数据的特征进行参数自我调整,不断逼近目标的过程,通常采用最小均方误差的方法进行逼近。其思想是在总均方误差最小这一最优条件下,根据各个传感器所得到的测量值,以自适应的方式寻找各个传感器所对应的最优加权因子,使融合后的X值达到最优。
设n个传感器的方差分别为σ1,σ2,…,σn,直接估计真值为X,各传感器的测量值分别为X1,X2,…,Xn,传感器数据之间彼此相互独立,并且是X的无偏估计[11]。各传感器的加权因子分别为W1,W2,…,Wn则融合后的X值和加权因子满足式(1)。
(1)
均方误差是由含有噪声的大量测量数据中估计的一个非随机量,均方误差值表示数据的离散程度。均方误差越大,则各个同类传感器测量获得的数据越分散,测量得到的数据越不准确。
总均方误差为
(2)
X1,X2,…,Xn彼此独立,并且为X的无偏估计。其中p和q表示第p个和第q个传感器数据。
(3)
故σ2可写成
(4)
基于无偏估计的总均方误差为
(5)
由于总均方差σ2是关于各加权因子的多元二次函数,因此σ2必然存在最小值[12]。σ2最小值可由式(6)得到。
(6)
根据多元函数求极值理论,可求出总均方差最小时所对应的加权因子,如式(7)所示。
(7)
1.2 数值一致性处理和分批自适应加权融合
由于环境中存在各种噪声或多径效应,传感器会出现测试结果偏差较大或者直接缺失的情况。上文描述的自适应加权融合算法无法有效地处理这些伪数据。如果将这些数据进行融合,会得到不准确的结果。于是,需要对多传感器的数据进行一致化处理。
设有m个传感器对某一对象进行测量,首先对Xi(i=1,2,…,m)进行数据检验。检验准则是X1,X2,…,Xm的值和同组数据期望之差不应超过给定门限ε。门限ε的值根据需求进行调整。
(8)
过滤一些明显偏离的数据之后,会造成数据的缺失。缺失会影响数据连续性和后续方差求取的准确性,因此需要进行补全处理。采用先前数据的数学期望进行补全。利用数据期望的补全方法不会破坏方差的完整性,也不会影响当前自适应因子的大小。由于出现较大偏差的概率较小,故采取此方法可满足要求。目前的使用方法大部分只是对传感器数据进行剔除,并没有补齐空缺数据。虽然这种操作对整体数据影响不大,但是对于实时性较强的系统来说,会影响每次融合后的预估值,因此需要对剔除后的数据进行补齐。当剔除较大偏差以后,数据的分散情况更加集中,方差也会变得较小。若多个传感器的方差一起变小,则可进一步提高结果的精度。
分批估计方法是将数据分为时间特性和空间特性进行分批处理。时间序列的处理可以对未来的趋势进行预判或者分析。空间的处理主要是对当前真实值的判断和分析。针对实际的需要可以选择相应的方法,对时间或者空间的数据进行协同分析,也可以增加数据的真实性和协同性。时间特性采用分时窗,且视窗之间有重叠,可以保证每个数据点至少同时存在于两个不同时窗里(时窗大小以传感器的特性决定),进而求得一个标准道,或者说是普通叠加道,这样就可以对每一道进行做差比较。差值小则权系数较大,差值大则权系数小,相同叠加道的权系数和为1。当确定每一道的权系数之后,做加权叠加。每个点的终点值,为它所在不同时窗所得值的平均,最后完成叠加。空间特性采用同一时间内的传感器数据进行计算分析,可以同时获得空间和时间上的权值并得到融合结果,也可以等效为时间上的另一个时窗。方差可以根据样本的改变而改变,使得融合结果更贴近真实值,提高数据的准确性和鲁棒性[13]。
由于目前使用的分批数据融合算法大多是对数据的整体或者部分进行计算,其对处于同一空间的传感器的相关关系没有进行合理利用[14]。本文对传感器的时序进行融合,可实时得到传感器的融合数据。每一次采集得到的数据都能得到一个当前的估计值。利用时窗特性,能稳定抓住本时段的传感器数据波动,得到的数据不存在传感器方差僵化的情况。同时对多个传感器进行数据采集时,存在相同的变化趋势,这种协方差特性给传感器最优权值的计算提供了依据。
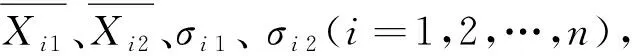
(9)
计算每个传感器时间段的融合值,即
(10)
将n个传感器的数据按照空间的同一时间为一组,算出方差σi+,利用时间上和空间上的方差融合成一个各传感器某一时刻方差σi+,融合方式采取式(9)的计算方式。由式(7)可知,自适应加权因子主要由各传感器的方差决定。于是,对各传感器方差的处理就是对自适应因子的处理。分时窗进行方差的求解可以增强算法的实时性。目前的算法普遍求解一个预测值,实时性不强。本文提出的算法不仅具有时间特性,还具有空间特性。利用协方差可以得到传感器之间的相关性,将横向的数据求方差,得到空间上的一致性。然后将空间上的一致性和时间上的一致性进行求解,得到一个最适合本系统的自适应因子,从而得到预测值。
系统的稳定性不易直接观察得出。在推导过程中,以均方误差最小为最优条件,均方误差越小,得到的结果越可靠。由于本文采取的方法都为无偏估计,故无偏测量过程可以采用方差直接衡量以测量稳定性。本文以方差为参考,方差越小证明系统越稳定。
本文用n个传感器中方差分别为σi的传感器L做均值估计。设传感器L的方差σL2为测量数据,由上文可知多个传感器自适应加权时的最小均方误差σmin2,则有
(11)
将两者的结果进行比较,可得
(12)
(13)
利用自适应加权的方法比均值法得到的方差较小,理论上优于均值法。由上文可知,当剔除偏离较大的数值后,通过式(11)可以看出分批自适应的分母整体增大,σmin2变小。经过数值一致性检测以后,基于分批自适应取得的方差相较于传统自适应方差有了明显改进。
基于分批自适应加权平均算法包括以下步骤:
步骤1计算k时刻σ′i和σi;

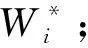
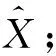
(14)
通过以上步骤,可以算出每个传感器相应的最优加权因子,进而得到一个最准确的结果。在实验过程中,针对不同的场景,可自适应算出最优加权因子,可以泛化地应用于多种场景。
2 实验仿真
本文在Windows10下的MATLAB R2018a环境下进行仿真,模拟多湿度传感器环境中多个传感器进行操作的实验。
为了验证本文所提出的理论分析能够同时对多传感器数据自适应融合,给定估计真值X为常量时,采用3种方法(均值法、自适应加权无偏方法和基于分批自适应加权无偏方法)对多个传感器期望值做估计并做对比。以上3种方法均不考虑数据的不一致性[15]。
式(13)中,当n越大,比值越来越稳定。当n趋近于无穷的时候,自适应加权和多传感器均值的方差比趋近于一个常量,说明传感器的数量在一个临界点时,再增加传感器的数量并不能增加测量精度。在不知道传感器先验概率的情况下,可以计算出先验概率,根据先验概率进行传感器的布设。当传感器测量精度为90%时,取传感器数量为n/0.9。按照仿真实验数据和理论推导,本文选择10个传感器作为仿真的实验对象。
现实生活中的噪声属于加性噪声,由传感器内部噪声和环境干扰等多种相对独立因素产生的测量噪声为相互独立的白噪声。多个相互独立的随机变量相加的和接近正态分布,因此测量噪声的分布规律也是正态分布的。于是,添加均值大于真实值的正态分布作为噪声波动。本实验选取的10个传感器数据如表1所示,大部分传感器的均值都在20左右,传感器6的噪声比例加大,模拟现实环境中的单个传感器不灵敏的情况。针对不同的场景,选择的传感器数量不一样,传感器数量多过,会增大数据量,浪费传感器资源。传感器数目过少,导致测量数据不准确,影响系统功能。因此,节约系统资源和平衡数据精度也是多传感器数据融合的一个重要参考依据[16]。
本文的仿真模拟了高斯分布传感器的情形,传感器性能参数如表1所示。
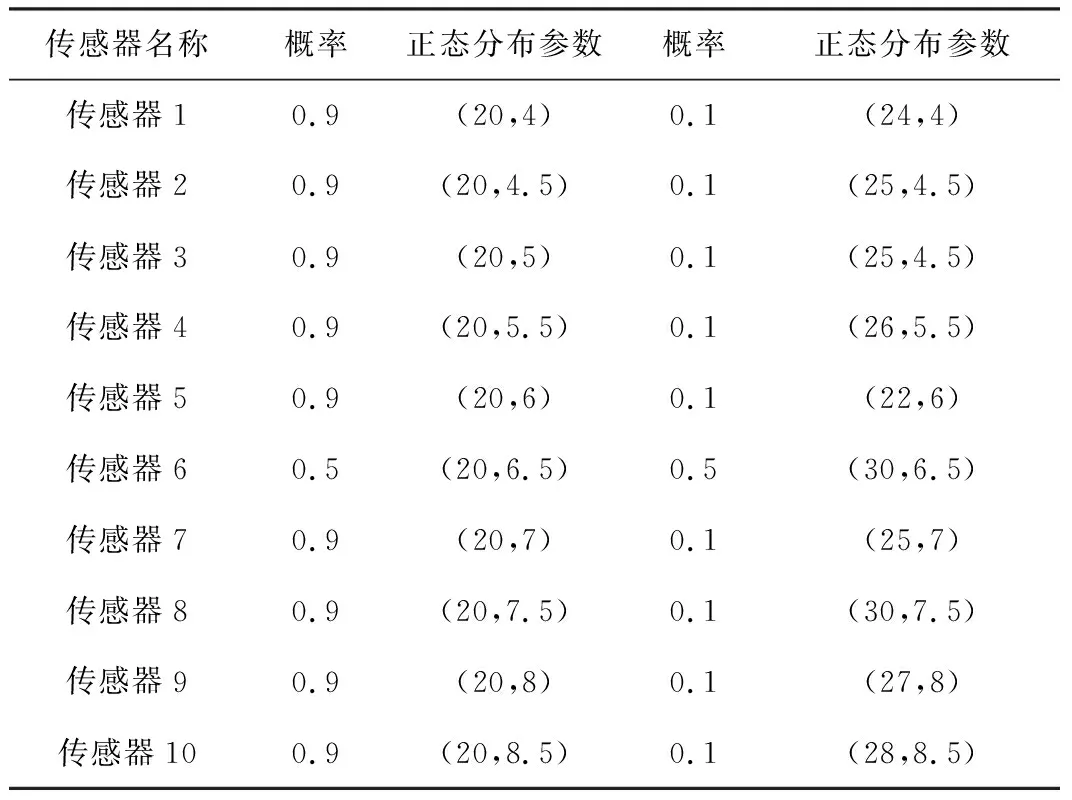
表1 传感器参数
由表1可以看出,模拟10个传感器同时产生10组均值为20的正态分布数据。在检测传感器数据时,模拟数据在范围内满足高斯分布,由于设备自身限制、小概率噪声干扰或者其他干扰,可能会出现小规模偏差。产生数据后,数据波形如图1所示。

图1 各传感器的波形图 Figure 1. The waveform of each sensor
由图1可以看出,10个传感器的数据在20上下波动,加大噪声的传感器6的波动大于其他传感器,传感器1和传感器2的波形则较为平稳。将10个传感器的数据绘成概率密度曲线,如图2所示。
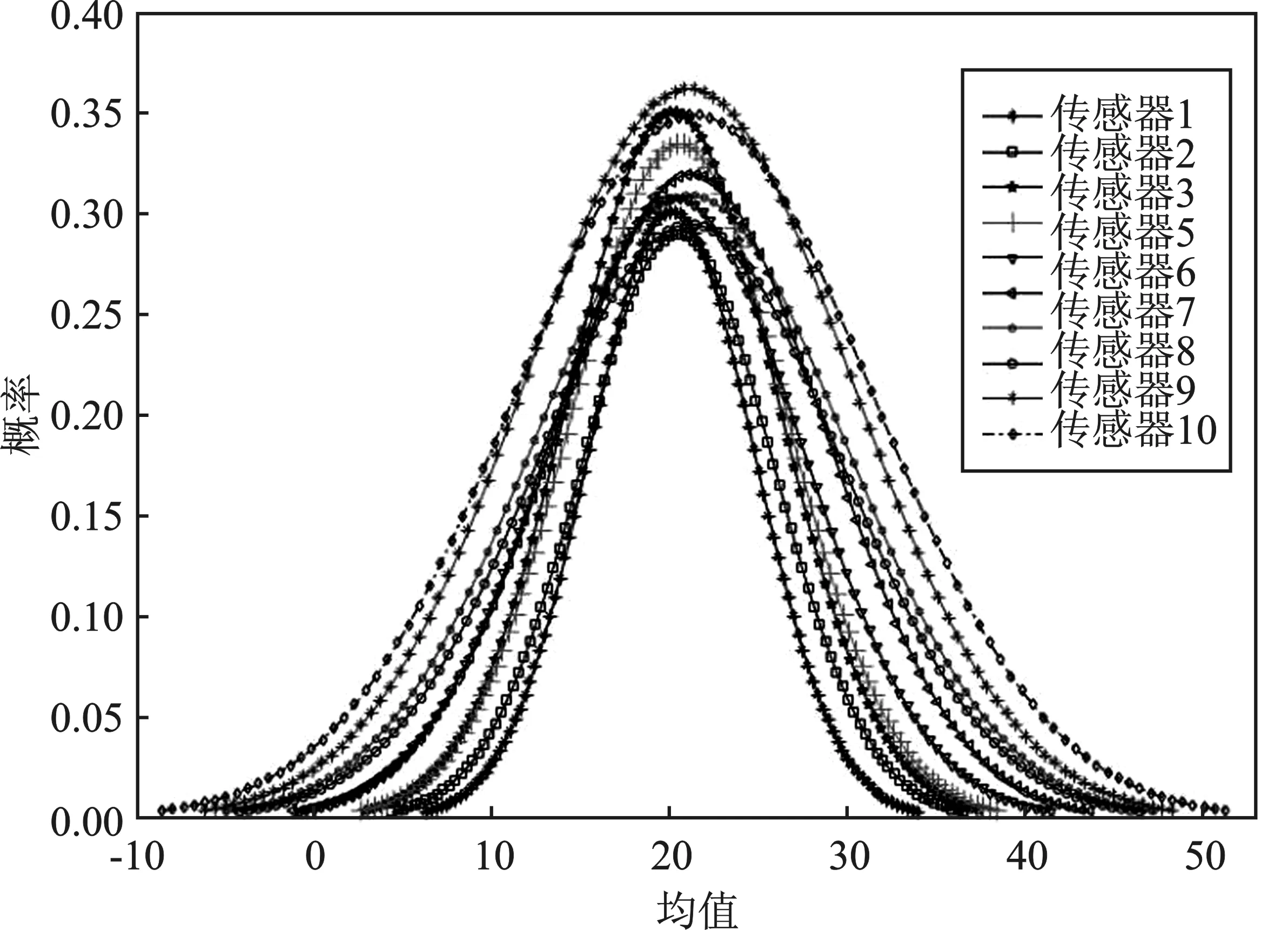
图2 各传感器的概率密度曲线Figure 2. Probability density curves for each sensor
由图2可以看出,10个传感器的数据在均值20左右形成正态分布,存在不同程度的偏移和噪声干扰。
选取10个传感器,每个传感器500个点,进行数据仿真。利用均值法、自适应加权法,分批自适应加权法进行数据的融合操作。均值法直接将同时间的一组数据相加平均,得到一个期望数值,同时算出其均方差。自适应加权利用上述的自适应加权融合方法算出估计值和均方差。基于分批自适应的方法利用数据一致性检验进行剔除,补充缺失值,按时间和空间序列计算出融合方差,得到最优权值,最后求出预测值和均方差。本文中分批处理的自适应加权ε取4,可以视实验结果而定。
首先按照自适应方法求出方差和最优权值,再进行一致化处理,得到处理后的传感器的最优权值如表2和表3所示。

表2 未数值一致性处理的传感器最优权值

表3 数值一致性处理后的传感器最优权值
由表2和表3可以得出,未经数值一致性处理时,单个传感器权值的占比较大;当进行噪点剔除以后,每个传感器最优权值的分布较为稳定。利用分批自适应法计算出传感器最优权值以后,根据式(1)算出其预测值。以采集次数为横坐标,以传感器数值为纵坐标,画出自适应法、平均值法和基于分批自适应法的数据融合波形,如图3所示。
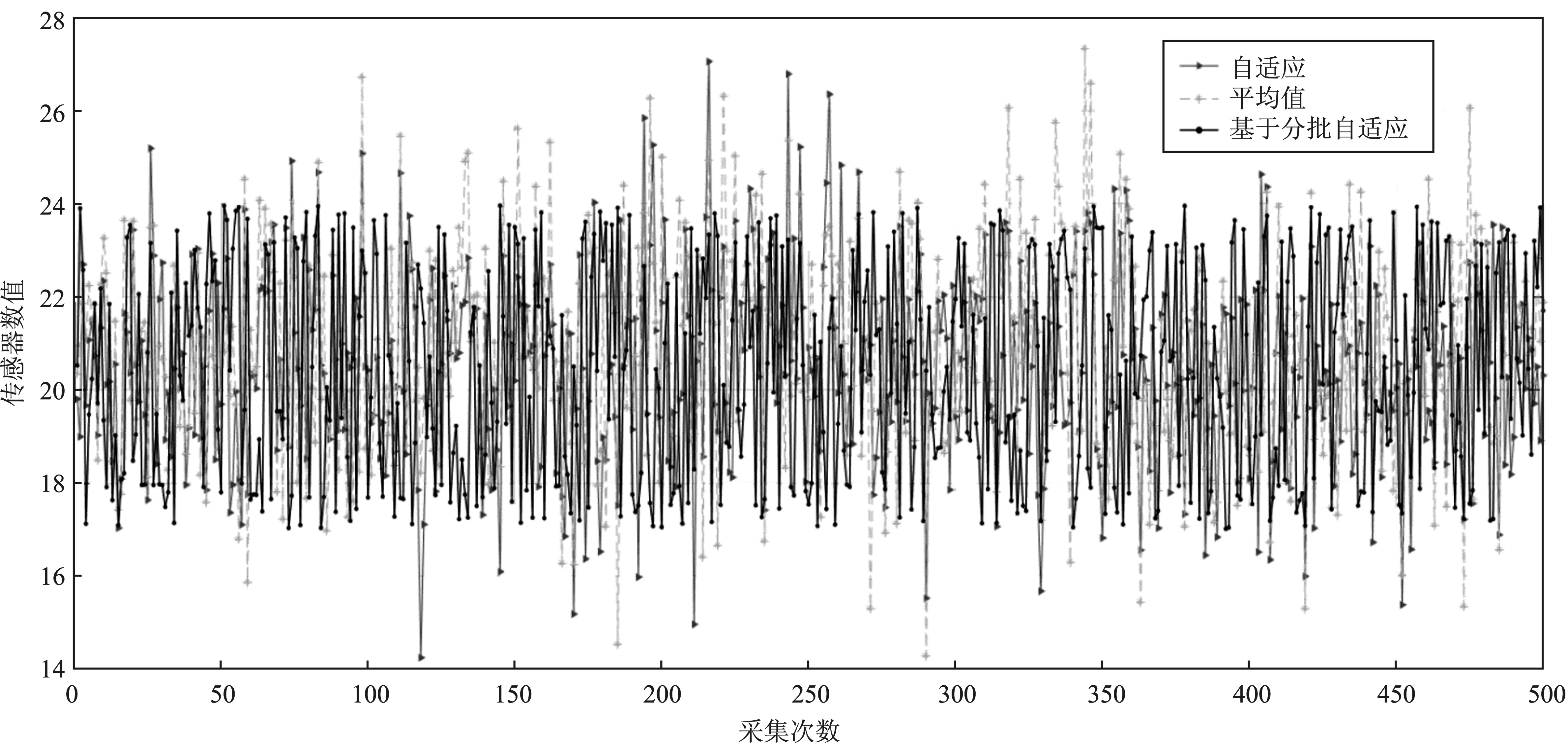
图3 结果比较 Figure 3.Comparison of results
由图3可以看出,均值法波动较大,且偏离中间值较多;自适应加权法波动明显减小;基于分批自适应方法的波动最为平稳,更接近于均中间值。将3种方法得到的融合结果绘成概率密度曲线,如图4所示。
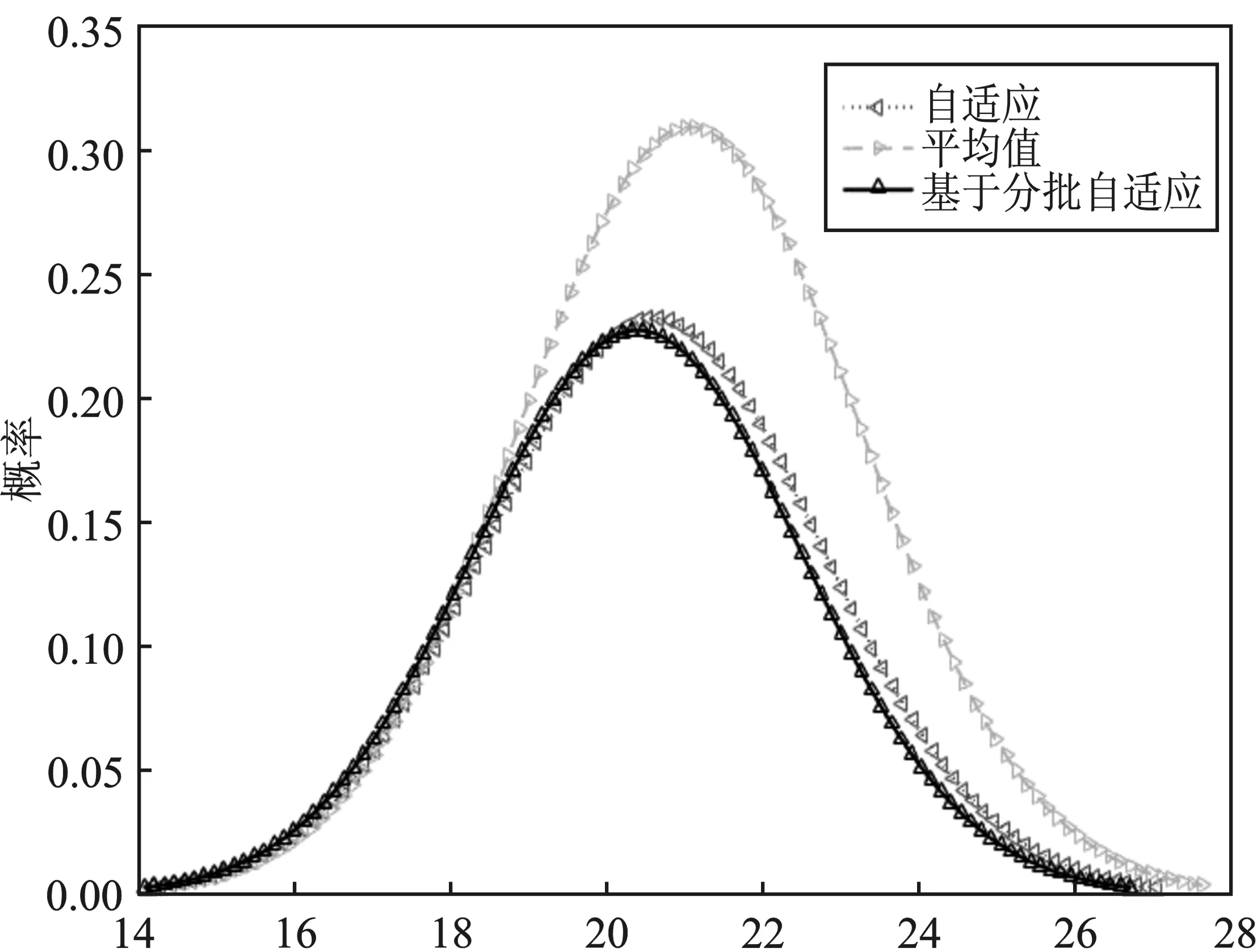
图4 总体概率密度曲线Figure 4. The overall probability density curves
从图4可以直观看出,基于分批自适应数据融合算法的均值和方差值对比于均值法有明显的提升;对比于自适应法基于分批自适应数据融合算法的均值和均方根误差也有了相应的改进。
为了更好地比较3种方法的均值和均方根误差,本文对传感器的一整段数据进行融合,结果如表4所示。
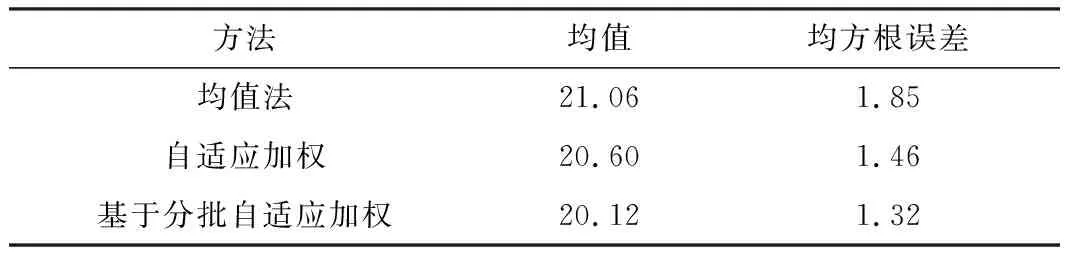
表4 算法的均值和均方误差比较
由表4可以得到,自适应加权比均值法的均方根误差减少了21%,均值精确度提升了2.1%;基于分批的自适应加权比自适应加权减少了10%,均值精确度提升了2.3%。因此,基于分批自适应加权的方法均值最接近真实值,均方根误差也在3种方法中最小。
基于分批的自适应加权算法在自适应加权的基础上进行了数值一致化检测,去除了大部分噪点,又将方差的求解分时间段和空间特性进行求解,避免了方差值的僵化,有效降低了均方根误差,提高了传感器的精度。此种方法在方差较为严重或噪声比较大的情况下,效果较为显著。
3 结束语
在上述实验中,通过对比均值法、传统自适应法和基于分批自适应法的均值预测值和均方根误差,证明了本文提出方法的有效性。该方法的融合结果在精度、容错性方面优于传统的平均值估计算法和自适应加权平均算法,特别是在传感器的误差较大或者单个传感器测量噪声影响较大时,效果显著。该方法可用于智能家居、智能农业的传感器数据检测,将传感器的信息进行融合以得到更为可靠和精确的结果,更有效地进行家居环境和生长环境的监控和调整。
在多传感器数据融合的过程中存在很多干扰,需要解决的问题也千差万别。在单一传感器测量时,为了减少估计值的均方根误差就必须增大测量数据的数量,但该操作会降低实时性[17],因此面对不同的场景需选择不同的传感器融合方法。在物联网和嵌入式领域,对数据的处理大部分都是像素级别的数据融合,主要解决的问题是传感器的精度和系统的稳定性。数据融合算法在处理相同类型的数据和不同类型的数据时具有良好的前景。目前,在有关机器人的领域,利用深度学习训练模型寻找多种传感器数据的内在关系,是数据融合的一个典型的应用。此外,模型的拓展性也是多传感器数据融合领域中有待进一步研究的方向[18-19]。
