分类算法应用程序的蜕变测试方法研究
2022-05-28陈自力
陈自力
(福建船政交通职业学院 信息与智慧交通学院,福建 福州 350007)
随着科学技术的不断发展,互联网取得了巨大的进步,智能设备的应用范围逐渐扩大,并开始渗透到人们生活、工作的方方面面,涉及的应用类型也呈现出明显的多样化趋势[1]。为更好地满足人们在对各类应用程式使用过程中的使用需求,分类算法的应用逐渐被重视,并逐渐成为应用程序设计以及开发中的重要因素。分类算法的作用主要体现在提高对应用程序内所储存的内容进行精准划分,在最短时间内反馈用户需求的信息[2]。为此,在对其进行分类计算过程中,需要进行蜕变测试,确保分类算法应用程序输出结果可靠性的重要手段。现阶段,蜕变测试方法的主要思路是采用已经在正确性上得到验证的测试结果作为待测内容进行验证,将理论结果与实际验证结果进行对比,并将其作为判断待测内容质量的标准[3]。根据这一思路,已有诸多学者对于蜕变测试方法进行了研究。其中,江竞捷等[4]提出了关于图像识别系统的蜕变测试方法研究,以图像GAN 为基础设计了对应的蜕变测试方法,该方法对于提高图像识别准确率有明显效果,但占用的内存较大;钟文康等[5]提出了面向翻译系统的蜕变测试研究,在一定程度上提高译文的质量,但需要大量的样本作为基础,前期准备工作相对较多。
基于此,提出分类算法应用程序的蜕变测试方法研究。通过对分类算法特征进行分析,建立了相应的蜕变关系,以此实现对分类结果的测试。并通过试验验证了其有效性。通过研究,以期为分类算法应用程序的测试提供参考。
1 蜕变测试流程设计
为实现分类算法应用程序分类结果的正确性进行有效测试,进行测试是关键环节。因此,本文设计了针对该类程序的蜕变测试方法。对蜕变测试的主体流程进行设计,通过在该流程中嵌入响应的蜕变关系,实现对分类结果的精准检测。
利用已有的检测方法对分类算法应用程序中分类结果进行测试,并选中最终输出结果与预期结果保持一致的一组数据作为原始用例。在此基础上,对程序的特征进行分析,并以其特点为基础,构造与程序相适应的蜕变关系,以原始用例为基础,生成蜕变用例,将其再次输入到分类算法应用程序中,根据输出的分类结果与本文设计的蜕变关系之间的契合度判断程序是否存在异常。基本流程如图1 所示。
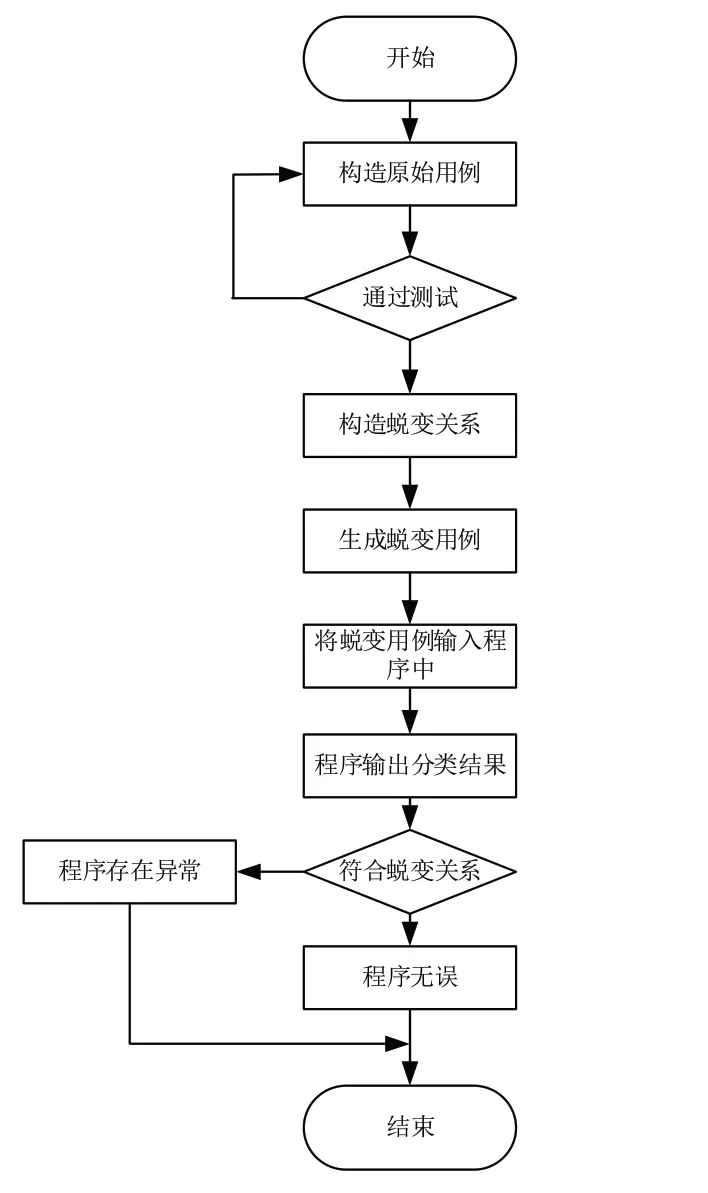
图1 蜕变测试流程图
2 分类算法应用程序特征分析
现阶段分类算法的种类和方式多种多样,其中应用最为广泛的是KNN(K-Nearest Neighbor Classification)算法[6],具有明显的计算过程简单、空间占用小、鲁棒性高的特点[7]。所以,本文以KNN 算法为基础,对其特点进行了全面分析,并进行相应的蜕变测试研究。
KNN 算法是一种经典的模式识别算法。核心是找到最接近的K 个样本,在这K 个近邻中计算出优势最明显的数据群体,以确定对应的样本分类结果。以此为基础,本文归纳了KNN 算法的主要特征如下所示:
需要对待分类样本与训练样本集中每一个样本的距离进行计算[8],对不同的样本类型,计算距离的方式也不同,可以是欧氏距离也可以是马氏距离,对于部分样本,也可以采用余弦相似度的方式来间接表示距离。在确定了距离之后,需要对最近邻数据进行搜索,并将距离排名前K 的训练样本作为最近邻进行采集。根据最近邻的实际情况,对数据进行分类。因此,KNN 算法实现的关键主要在于K 值的选择、距离的计算以及样本的排序。
为了便于蜕变关系的描述,作出了如下定义:
定义1:数据类型相似度。在待分类样本距离范围内的K个近邻样本中,隶属于类型A 的样本数量为KA,那么,待分类样本与类型A 之间存在的相似度则表示为KA/K。
定义2:数据相似类。当待分类样本与类型A之间的相似度大于0 时,则默认类型A 为待分类样本的相似类。
定义3:数据最大相似类。在待分类样本的所有相似类中,若类型A 的类型相似度最大,则类型A 即为待分类样本的最大相似类。最大相似类也就是分类算法应用程序最终分类结果。
定义4:数据最小相似类。在待分类样本的相似类中,若类型A 的类型相似度最小,其即为待分类样本的最小相似类。
定义5:完全隶属类。当待分类样本与类型A之间的相似度为1 时,则称类型A 为待分类样本的完全隶属类。其也是相似度阈值的最大值,因此,完全隶属类也就是样本的最终分类。
定义6:不相关类。当待分类样本与类型A之间的相似度为0 时,则称类型A 为待分类样本的不相关类。上面的定义2 中,已经给出了成为待分类样本相似类的条件为相似度大于0,因此,不相关类不作为待分类样本的备选分类考虑,可以直接对其进行淘汰处理。
3 蜕变关系构造
在上述基础上,本文以蜕变关系构造的基本准则为标准,以KNN 算法分类程序的特征分析结果为依据,假设以训练样本为n,构造了以下的蜕变关系。
MR1 线性平移。在训练样本中,当对所有个体和属性xi同时进行相同规模的线性平移时,不影响最终的分类结果。
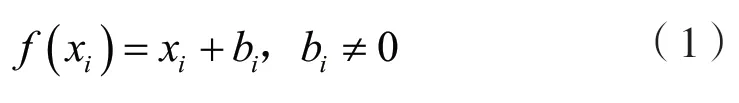
其中,f(xi)表示测试样本,b i表示平移距离。
MR2 等比例缩放。在训练样本中,当对所有个体和属性xi同时进行相同比例的缩放时,不影响最终的分类结果。

其中,a表示放缩比例。
MR3 对称变换。当对训练样本中所有样本的所有属性值xi整体进行完全一致取反处理,以坐标轴为基准进行对称变换时,不影响最终的分类结果。

MR4 属性列置换。在训练样本中,当对任意属性列Ai、Aj 进行置换操作时,不影响最终的分类结果。
MR5 样本乱序。当训练样本中,样本的排列顺序被打乱时,不影响最终的分类结果。
MR6 无效属性列增加。在训练样本中,增加无效属性列不影响最终的分类结果。
MR7-1 样本全复制。在训练样本中,对所有样本及其属性进行完整的复制操作,使样本数量变为2n 时,不影响最终的分类结果。
MR7-2 最大相似类复制。在训练样本中,假设最大相似类的样本数为m,当对其进行复制操作,不影响最终的分类结果。
MR8 不相关类复制。在训练样本集中,假设不相关类样本数为j,对其进行复制,并采用随机的方式再待测样本中选择j 个位置对其进行插入操作,不影响最终的分类结果。
MR9 最小相似类剔除。在训练样本中,假设最小相似类的样本数为i,对其进行剔除操作,不影响最终的分类结果。
4 试验测试
为测试本文设计蜕变测试方法的有效性,对其进行了试验测试。
4.1 测试环境
本文测试环境为Window 8,APU 2G,内存4G。试验设计了一个总系统带宽10 MHz 的单小区作为试验环境,在管理区域中,用户数设置为228,并将每个决策时间内的用户数量控制在一个的定值上。将 KNN 算法部署到小区中心位置,同时,设置用户被在以中心为基础随机分布的距离为100 m。按比例对用户的计算任务进行划分,并在一段时间内对每个用户服务类型进行修改,任务主要包括5 类,分别为迭代、叠加、存储、传递以及筛选。其中,KNN 算法是计算能力为8 GHz/sec,用户任务的数据大小以 kbit 为单位进行统计,在(300,500)范围内均匀分布。本文通过上述任务指标,对用户进行分类。
4.2 测试方法
对本文设计的蜕变关系进行验证的方法如下所示,通过该方法实现对蜕变测试方法有效性的评估。
(1)数据的准备。首先构建待分类样本集,采用随机取样的方式从试验准备的数据中选择10%作为样本数据,即228 条数据,并在对应的5 个任务类型中抽取对应数量,以此作为试验的待分类样本文集;其次,构建试验所需的训练集,本文将剩余的全部数据信息作为试验的训练集。
(2)运用本文设计的蜕变关系,对训练集的数据进行处理,构造蜕变关系。
(3)将蜕变关系作为输入值,输入程序中,并再次运行该分类程序,验证蜕变关系的输出结果与预期结果之间的差异性,并检查各项分类指标变化情况。
(4)分析分类结果和分类指标,确认蜕变关系的实际有效价值。
4.3 测试结果
采用上述方法对试验数据的分类结果进行统计,观察了不同蜕变关系下不同类别的用户数量,结果如表1 所示。
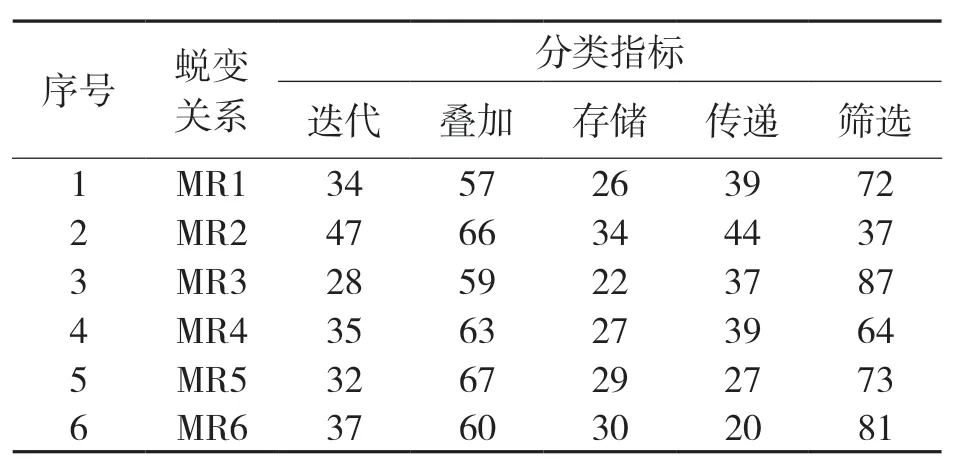
表1 输入蜕变关系后程序的输出结果/个
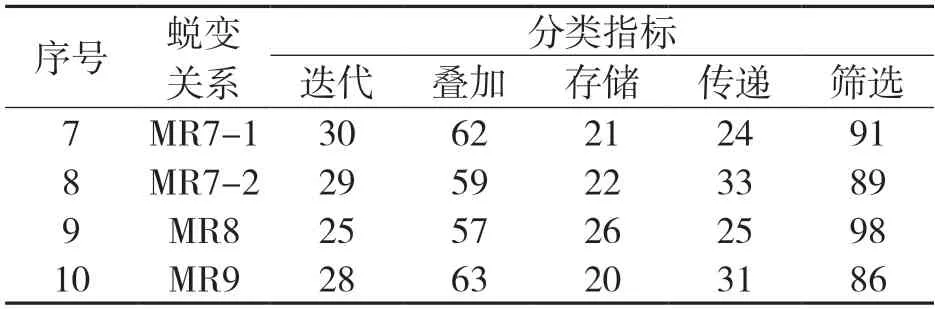
续表1 输入蜕变关系后程序的输出结果/个
从表1 中可以看出,在不同蜕变关系约束下,不同属性的分类结果也存在明显的差异性,这主要是因为在试验数据中,存在一个用户包含多个属性的同种类信息。因此,在不同的蜕变关系下,其分类组别也会不同。
在上述基础上,对比了在不同蜕变关系下分类结果的平均相似度,其结果如表2 所示。
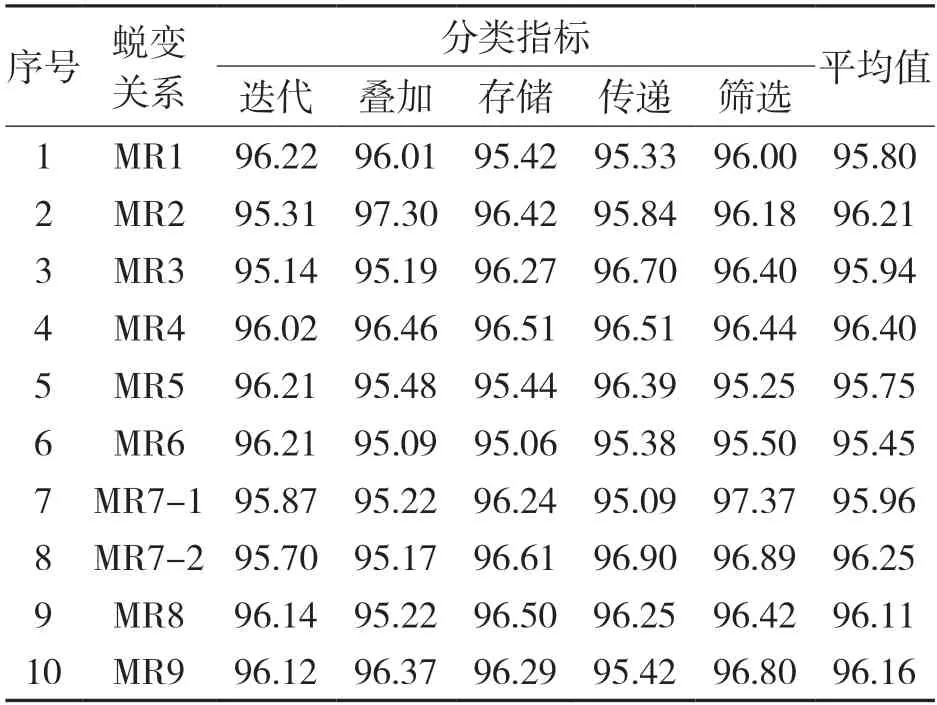
表2 不同蜕变关系下分类结果的平均相似度/%
从表2 中可以看出,在不同的蜕变关系下,不同分类组别中的平均相似度均在95%以上,表明分类结果具有较高的精确度。在上述基础上,本文对比了蜕变后程序的分类结果中,最大组群属性数据之间的平均相似度情况。根据上文的统计结果,10 个组别对应的最大属性组群均为配送时间,从表2 中可以看出,在不同的蜕变关系下,配送时间分类结果的平均相似度基本在96%左右,蜕变关系MR5 和MR6 略低,最高值为97.37%,出现在MR7-1 蜕变关系下。这也表明本文设计的蜕变测试方法具有良好的分类效果。
5 结语
在应用程序不断发展的今天,对于其高精度发展的研究已经成为了一种不可阻挡的趋势。对分类算法应用程序而言,分类的准确性和精确性是其赖以生存和发展的基础。本文提出了分类算法应用程序的蜕变测试方法研究,实现了提高分类精度,确保分类准确性的目的,对实际使用具有一定的参考价值。
