混合神经网络模型与注意力机制的地址匹配算法*
2022-05-27陈健鹏佘祥荣水新莹
陈健鹏,陈 剑,佘祥荣,水新莹,陈 刚
(长三角信息智能创新研究院,安徽 芜湖 241000)
1 引言
地名地址作为智慧城市建设中最重要的基础数据资源之一,如何从地址文本中挖掘其特征内涵进行规范化建设,是直接影响智慧城市建设水平的关键因素。当前对地名地址的研究主要有以下2类方法:一类是对单一非标准地址的匹配,这类方法主要以基于字符串的方法和基于规则库的方法为主;另一类是基于已构建的标准库的地址匹配,这类方法以基于文本统计特征的方法为主,如支持向量机[1,2]、最长公共子串和编辑距离[3]等。然而这2类方法均存在一定的问题,对于规则库来说,由于中文地址信息的整体结构非常复杂,规则在处理错乱或缺失的地址问题上,显示出一定的局限性;而基于统计特征的方法虽然一定程度上规避了地址结构复杂带来的问题,但标准地址库的建立难度非常大。同时,此类方法对于具有复杂结构,或者包含冗余信息的地址不能起到很好的标准化作用,究其原因在于这些方法缺乏对地址的语义理解,不能很好地提取地址的语义特征。
针对这一问题,本文提出一种基于注意力(Attention)机制和Bi-LSTM-CNN(Bidirectional Long Short-Term Memory-Convolutional Neural Network)的地名地址匹配算法,首先利用Trie语法树构建标准地址树;接着运用双向长短期记忆网络Bi-LSTM(Bidirectional Long Short-Term Memory)[4]和卷积神经网络CNN(Convolutional Neural Network)[5]模型对地址进行表征,并在整合2个通道的信息后引入注意力机制,补充上下文的相关信息,以此进一步提高语义表征的准确性;最后对2组表征信息计算相应的曼哈顿距离,得到地址对中2条地址的相似度信息。
本文贡献有如下几点:
(1)提出了一种基于深度学习与语法树规则相结合的地址语义相似度匹配算法,结合已有知识与深度学习方法有效提升了地址匹配的准确率。
(2)提出了一种基于Bi-LSTM与CNN融合网络的地址字符串的语义向量表示模型。同时引入了注意力机制,为较为重要的地址元素分配较高的权重,突出地址的重要特征。
2 相关工作
早期对地址标准化的研究方法主要集中于字符相似性上,从某一度量维度计算要匹配的地名地址之间的字符串相似性,然后通过手动设定阈值或使用分类器(支持向量机等)来确定他们是否匹配以做出决策。Levenshtein等[6,7]提出的编辑距离方法将相似性定义为由一个地址字符串转换为另一个地址字符串所需的字符编辑操作的最小数量,以此计算2个地址的相似度。Jaccard[8]提出的方法则通过计算2个地址的局部相似度,在短地址匹配上获得了更为精确的效果[9],但在地址要素缺失的情况下匹配效果不佳。之后基于向量空间的N-gram方法[10]被提出,其通过将待匹配的地址转换为同一向量空间中的向量对,利用余弦相似度[11]等计算方法计算二者之间的相似度,在提升效果的同时提高了对地址要素差异的容错度。
随着多样化的地址记录快速增加,上述相似度度量方法逐渐难以应对大量非标准化的地址记录,因而基于地址要素解析的地址匹配方法被提出,根据地址元素的层次结构构建类似语法树的结构,利用与语法树的匹配确定地址记录中的地址要素,进而确定地址对是否匹配[12]。针对中文地址,地址要素的获取主要分为利用字典、概率分布(条件随机场[13]、隐马尔可夫模型[14]、词频-逆文本频率TF-IDF[15]等)或自然语言分词工具(Jieba、清华中文分词工具包THULAC(THU Lexical Analyzer for Chinese)[16]等)进行分词,以及与现有的地址层次结构进行对比2个阶段。薛兵兵等[17]提出的基于规则与词典的地址匹配算法,使用地址要素特征词与地址特征词典从非标准地址中提取最有效匹配要素,但该算法依赖于地址要素的完备性,且规则的制定难度较大。康昆等[18]提出的基于地址树模型的中文地址提取方法,以拓扑关系作为空间约束,从非标准地址中提取标准地址,但该方法无法罗列出所有的非标准地址和地名元素集合。为了处理这类特殊情况,吴睿等[19]提出一种多策略结合的地址匹配算法,结合字符相似性和地址要素抽取策略,使用基于特征字词典和序列标注的方法与标准地址数据库进行匹配。
然而基于地址要素的方法在处理较长的地址记录时,由于无法考虑到语义信息,在部分非标准地址信息重心分布不规律的情况下效果较差。为了解决这类问题,研究人员开始将神经网络应用在这一任务上,使用CNN[5]、循环神经网络RNN(Recurrent Neural Network)[20]、Bi-LSTM[4]或融合方法[21]等来表征地址的语义。Santos等[22]提出了一种多模型融合方法,使用RNN和门控循环单元GRU(Gate Recurrent Unit)进行地址语义建模,相对于单一相似度度量及监督学习的方法取得了不错的性能提升。Lai等[23]结合RNN与CNN模型的优点,提出区域卷积神经网络RCNN(Regions with CNN features)模型,使用双向循环结构,在卷积层中嵌入一个双向循环神经网络BiRNN(Bidirectional Recurrent Neural Network)结构,有效降低了网络噪声,最大化地提取出地址信息中的上下文信息。
综上所述,基于神经网络的方法能有效解决地址匹配中对于语义信息的缺失和传统方法中对于地址要素之间的各类差异导致的效果欠佳问题,但对于这类模型,如何有效融合全局与局部范围的上下文信息是一个重要的问题。
3 地址匹配算法结构
本文根据地址的结构特点,提出了一种基于语义的地址匹配算法。该算法首先利用Trie树构建标准地址模型,判断地址是否需要进行匹配;然后利用一种融合注意力机制的地址语义模型对非标准地址进行匹配,从标准数据库获得最佳匹配地址。
3.1 地址模型
中文地址由多个地址要素构成,一个有效的地址要素应该包括行政区划名称、街路巷名、小区名、门址、标志物名和兴趣点名。当前几种常用的地址要素组合模型有:行政区划+街路巷+门牌号;行政区划+小区(自然村)+门牌号;行政区划+(街路巷)+兴趣点(标志物)。行政区划可以划分为省、市、区(县)、街道(镇)和社区(行政村)[24]。
Trie语法树是一种树形结构,是哈希树的变种,一般应用于统计和排序大量的字符串。与二叉树不同,Trie语法树的键不是直接保存在节点中,而是由节点在树中的位置决定。它的优点是最大限度地减少无谓的字符串比较,查询效率比哈希表高。一个节点的所有子孙都有相同的前缀,该前缀就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶节点和部分内部节点所对应的键才有相关的值。
本文构建了如图1所示的Trie语法树,以提取地址中的元素,并列举了几类常见的地址形式及覆盖路径(如表1所示)。对于第1类地址,覆盖路径为A-B-C-D-E-G,无中间信息缺失,符合地名地址表达规范,在本文中属于标准地址,不需要进行匹配。对于其他几类地址,或多或少丢失了一些信息,属于待匹配地址。对这类地址,本文利用3.2节所述语义模型对其进行匹配。

Figure 1 Trie grammar tree constructed for address element extraction图1 针对地址要素提取构建的Trie语法树

Table 1 Several typical address coverage paths表1 几类常见地址覆盖路径
3.2 融合注意力机制的地址语义模型
本文结合注意力机制,以及Bi-LSTM和CNN网络的特点和优势,根据中文地名地址的特点,建立基于Attention-Bi-LSTM-CNN融合网络的地址语义表征模型。本文将此模型称为SGAM(Symmetrical Geographic Address Matching)模型,主体算法描述如算法1所示。
算法1地址语义匹配算法
输入:地址集合A,地址文本对(ai,aj),ai∈A,aj∈A。
输出:2条地址的相似度sim(ai,aj)。
Step1初始化匹配结果数组sepResult为空;
Step2构建语法树:
divisionTree←BuildTree(A)
Step3遍历语法树节点进行地址元素匹配:
forelein [ai,aj]do
fornodeindivisionTreedo
ifheadof(ele,len(node))==node:
sepList←node;
ele.delete(node);
ifnode==LastNode(A):
sepList←ele;
sepResult←sepList;
Step4基于SGAM模型预测(ai,aj)相似度:
similarity←SGAM(sepResult[0],sepResult[1]);
sim(ai,aj)←similarity
语义模型接受地址对的输入,并分别生成地址的语义向量表示,最后通过计算曼哈顿距离判断地址对是否相似。模型结构如图2所示。SGAM模型由编码模块、语义表征模块和语义距离计算模块组成,下文对各模块进行详细说明。

Figure 2 Overall structure of SGAM model图2 SGAM模型整体结构图
3.2.1 编码模块
编码模块主要将中文地址转化为向量的形式,即将输入地址映射成为m*n的矩阵。中文地址实际上是一种特殊的自然语言描述,中文的词没有形式上的分界符。在进行词编码之前,需要对地址进行分词。而中文地址的分词特殊性在于,更注重将地名地址分成各类地址要素,每个地址要素相当于中文分词中的一个词。本文采用Jieba的分词算法,并且加载自定义分词语料库。分词语料库的构建根据城市地名和地址的特殊性,补充Jieba分词对未识别名称正确分词。
假设地址a由N个词组成,即a={a1,a2,…,aN},对于地址a中的每个词,可以从词向量字典Dw∈Rdw×lenv中查找到词向量,其中,lenv是词表中单词的个数,dw是词向量的维度。词向量字典Dw通过学习获得,词向量的维度dw根据需求设置。故地址a中的词ai的向量如式(1)所示:
ei=DwVai
(1)
其中,Vai是一个长度为lenv的独热向量,所有Vai的长度均相等且都等于lenv,设词ai在词表中的位置是j,则Vai的第j维为1,其余维为0。
这样,地址a的向量可表示为e={e1,e2,…,eN}。
本文限定每个地址a分词之后的最大长度N为20,词表的大小lenv为10万,词向量的维度dw是300,即经编码层后每条地址映射成一个20×300矩阵,作为后续模块的输入。
3.2.2.1 Bi-LSTM模块
LSTM是在RNN基础上改进而来的一种神经网络模型,可以解决长期依赖问题[19]。LSTM 神经网络使用输入门、遗忘门和输出门3种门结构,以保持和更新细胞中信息的增减。但是,单向LSTM只能处理一个方向上的信息,无法同时处理另外一个方向上的信息,双向LSTM是为克服LSTM的不足而做的进一步扩展。本文使用双向LSTM提取特征信息,更充分地学习地址特征。具体来说,使用2个不同的 LSTM神经网络层分别从中文地址的前端和后端进行遍历,这样便能保存2个方向的地址信息,如图3所示。其中Tokenri,Tokenrj,Tokenrk表示输入的地址分词,wordvector表示分词对应的词向量,hi表示隐藏层输出,concati表示2个网络层融合后的输出向量,V表示融合后的最终输出。相对于单向 LSTM,Bi-LSTM 既能保存前面的上下文地址信息,又能考虑未来的上下文地址信息,更加完整地提取了地址的语义信息。
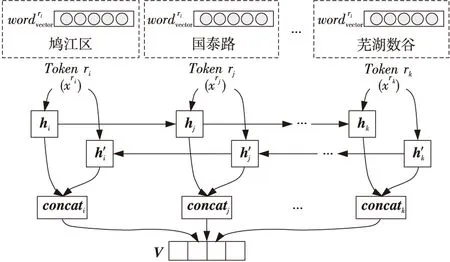
Figure 3 Structure of Bi-LSTM module图3 Bi-LSTM模块结构
首先,遗忘门根据上一个记忆单元的输出ht-1和输入数据xt产生一个0~1的数值ft,来决定上一个长期状态Ct-1中丢失信息多少。ht-1和xt通过输入门确定更新信息得到it,同时通过一个tanh层得到新的候选记忆单元信息C′t。通过遗忘门和输入门的操作,将上一个长期状态Ct-1更新为Ct。最后,由输出门得到判断条件,然后通过一个Sigmod层得到一个(-1,1)的值ot,该值与判断条件相乘,决定输出当前记忆单元的哪些状态特征。Bi-LSTM的工作原理如式(2)~式(7)所示:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
C′t=tanh(Wc·[ht-1,xt]+bc)
(4)
Ct=ft*Ct-1+it*C′t
(5)
ot=σ(Wo·[ht-1,xt]+bo)
(6)
ht=ot*tanh(Ct)
(7)
其中,Wf、Wi、Wc和Wo分别为遗忘门、输入门、控制门和输出门的可学习权重矩阵,bf、bi、bc和bo分别为对应的偏置矩阵,*表示哈达玛积。
3.2.2.2 CNN模块
卷积神经网络CNN在计算机视觉领域取得了不错的效果[25],其卷积核池化的过程实际上是一个特征提取的过程。CNN的总体思想是将整体的数据局部化,在每一个局部数据中利用卷积核函数提取特征,随后重构所有的碎片化特征,在目标函数的指导下实现对数据整体信息的提取。
地址文本具有多地名性和层次性,即是由一连串的地理实体组成的文本,如“安徽省(省)芜湖市(市)鸠江区(区县)国泰路2号(街路巷)芜湖数谷A座6楼(POI)”。中文描述地址的不同层级的变化和CNN分层卷积的应用场景吻合。基于此,本文采用基于CNN的卷积模型对地址数据进行特征提取,具体的卷积结构如图4所示:首先利用ZeroPadding1D对输入词向量矩阵的边缘使用零值进行填充;然后利用100个卷积核长度为5的过滤器进行卷积,即相当于利用100×5×300的卷积核对嵌入层输出矩阵进行卷积操作,经卷积操作后,可提取尺寸为20×5×300。再选用池化窗口大小为2的池化层对卷积出来的特征进行采样处理,最后输出维度为20×100的向量,作为下一模块的输入。
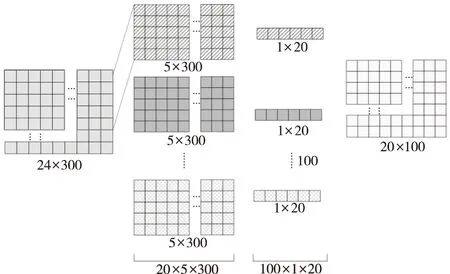
Figure 4 Structure of CNN module图4 CNN模块结构
3.2.2.3 Attention模块
中文描述地址的习惯是将有意义的词或者具体地址的词放在前面进行表述,因此应该对每个词赋予不同的权重。例如“第一村第一村民组”“第一小区6号1楼”“第一小区4区11栋1号”“第一商城E5-6”和“第一路第一小区1幢11号门面”。本文提出利用Attention机制表征地址的语义信息,通过分配不同的权重来使语义向量表示更丰富的语义信息。
定义H是输入向量,本阶段输入向量由CNN和Bi-LSTM的输出向量加权求和得到,相关公式说明如下:
A′=tanh(H)
(8)
α=softmax(WTA′)
(9)
A″=HαT
(10)
其中,H∈Rdw×T,dw是词向量的维度,W是通过训练获得的权重矩阵,WT是其转置,A″为经过注意力机制之后得到的向量表示。
那么每个地址的最终向量表示如式(11)所示:
(11)
通过将经过注意力机制生成的语义向量相加得到最终向量。
3.2.3 语义距离计算模块
(12)
使用Sigmoid函数预测最终的相似度值,如式(13)所示:
y=Sigmoid(Md)
(13)
4 实验
4.1 实验环境
本文基于CUDA 10.0深度学习框架Keras 2.3.0构建网络模型,实验在内存DDR4 32 GB,3.6 GHz i7-7700 Intel(R)Core(TM)CPU,NVIDIA GoForce GTX 1080 Ti的Ubuntu 18.04 LTS系统上进行。
4.2 数据集
为了评估本文提出的SGAM模型的稳定性,本文使用标准地址库构建了一个包含294 571个地址信息对的数据集,并在其后使用人工标记的方法标记了每个地址对中的2个地址是否相似,地址对举例如表2所示。本文从该数据集中选取了10%的地址对组成测试集,其中包含7 364个相似地址对与22 095个非相似地址对,正负样本比例约为1∶3。对剩余的地址对,采用十折交叉验证的策略进行训练与验证。

Table 2 Address pairs in custom dataset表2 构建数据集上的地址对
在数据预处理阶段,将地址对中的2条地址进行划分后,使用第三方中文处理工具Jieba对地址进行分词。考虑到地址作为一种结构特殊的短文本,可能包含大量的地名类特有词汇,在分词时配合使用了自定义的停用词表。
4.3 实验设置
本文SGAM模型中使用word2vec模型作为语义表征模型,利用预定义词表将地址对中的2条地址编码后,将不足20维的句子编码用0补足,而后将句子中的每个单词表征为对应词向量,词向量融合作为整个句子的向量表示。在超参数的设置上,考虑到地址可能的长度,语义表征层中每一个词输出维度为768维,表征后输出的2个地址语义表征维度均为100维,完成语义表征后,将获得的2个语义向量分别输入到下一层神经网络结构中。
在神经网络模型训练过程中,本文设置的批处理大小为1 024,采用双层的Bi-LSTM网络与CNN分别作为获取全局上下文信息与局部上下文信息的神经网络模型进行训练,dropout设置为0.5,并将二者的输出融合为x∈R25×100的特征矩阵送入自注意力网络,补充上下文位置的相关信息;最后输出2个100维的表征向量作为地址对中2条地址的语义表征向量,并计算两者之间的曼哈顿距离,经过4层的全连接压缩后输出2个地址的相似度标量sim。对SGAM模型,使用学习率为0.01,beta1为0.9,beta2为0.999,衰减率为0.1的Adam优化器对模型进行优化,SGAM模型的具体参数如表3所示。

Table 3 Hyper parameter setting of SGAM model表3 SGAM模型训练参数设置
4.4 实验结果与分析
为了判断相似度预测结果的有效性,本文选取了准确率(accuracy)、精确率(precious)、召回率(recall)与F1得分(F1-score)作为评价指标。其中准确率越高,表明模型对于“相似/不相似”的判定结果越精确;而F1得分越高,表明模型整体性能越好。
4.4.1 消融实验分析/模型稳定性验证
为了验证本文提出的SGAM模型中融合上下文及位置信息的判别模块的稳定性,实验中设计了多个去除SGAM部分结构后的消融模型进行对比实验,3个消融模型及其实验结果对比如表4所示。以每50个训练样本为一轮迭代,对各个模型的召回率和F1得分进行记录,2个指标随训练过程的变化趋势如图5所示。
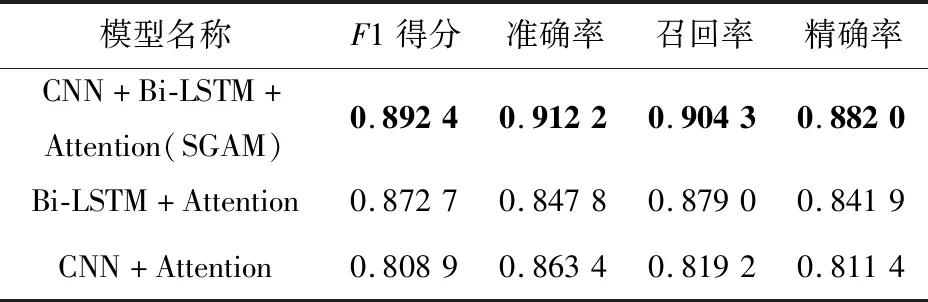
Table 4 Experimental results on ablation models表4 消融模型及其实验结果

Figure 5 Preformance of different ablation models 图5 消融模型判别性能对比(召回率和F1得分)
实验结果显示,在召回率和F1得分方面,本文所提出的模型综合表现最好且性能稳定。在F1得分上,相比消融模型,SGAM模型性能提升了大约3%~10%,表明了在仅考虑Bi-LSTM获得的全局上下文信息或者CNN获得的局部信息时,模型无法有效捕捉地址中的部分关键信息,导致模型的整体性能下降,而同时结合上下文全局信息与位置相关的局部信息后,模型的预测效果得到了有效提升。同时,F1得分表明,SGAM模型的准确率提升并非受到数据集中正负样例的比例影响,而是模型的整体学习能力相较于其他消融模型确实获得了增强。
4.4.2 对比实验分析/与基线模型实验对比
为了证明本文提出的模型相比其他主流模型能达到更好的效果,实验中选取了一些基线模型作为参照进行性能对比。考虑到地址相似度判断问题简化成“相似”与“非相似”的结果判断问题后,可以将其看成一个文本二分类任务,因而将本文提出的模型与多个主流的文本分类模型进行了对比,包括深度学习模型与机器学习模型。
(1)与深度学习模型的对比。
由于可以将相似度问题转换为二分类问题,因而本文选取了部分分类问题的基线模型进行对比,包括层数为3的多层感知机MLP(MultiLayer Perceptron)模型、以n-gram词向量作为语义输入并在隐藏层对所有向量进行平均化处理的FastText模型[26]、将RNN与CNN进行结合,使用双向RNN获取文本上下语义语法信息并使用最大池化自动筛选最重要特征的TextRCNN模型,以及整合局部特征和全局信息的基于注意力卷积神经网络ABCNN(Attention Based Convolutional Neural Networks)模型[27]。预测结果对比如表5所示,其中部分指标的变化趋势对比如图6所示。
从表5中可以看出,SGAM模型在判定效果上相比其他模型有不同程度的提升,其中,相比其他考虑语义信息的模型,SGAM模型在准确率上有大约2%~10%的提升,表明本文模型在分类效果上确实具有一定优势。
进一步细化分析,从模型随训练过程收敛的速度来看,FastText由于结构较为简单明了,因而收敛到最优效果的速度相对于其他几个模型要快,但是由于TextRCNN利用双向RNN获取上下文信息,在信息获取的全局性上相对FastText具备一定优势,因而其分类效果有较为明显的提升。而ABCNN利用2个CNN模型对2个地址分别建模,而后引入注意力机制考虑2个地址之间的关系,加入了词句间上下文信息,在信息抽取中融入了加权信息,因而效果相对前2个模型更好。而与SGAM模型相比,对比模型准确率的差距约为4%~6%,差距相对较小。这一结果说明,一方面,使用针对句子对分开获取上下文信息的语义提取方案相对于使用双向整条语料来获取上下文信息的方法有一定优势,尽管RNN是一种偏序模型,双向的RNN能弥补偏序模型在词语的重要性分配上产生的问题,但是会忽略句子对中二者的对比信息,因而在性能上会劣于SGAM模型;另一方面,引入注意力机制的位置也对模型的相关效果产生了影响。通过加入注意力机制而额外引入的位置相关信息,对模型整体的效果有一定提升,且在网络中更合适的位置引入注意力机制对模型效果会有所提升,但提升效果较为有限。这一结论可以解释为:地址作为一种基于一定规则的特殊文本信息,由于规则的确定性,其位置相关的语义信息分布往往较为统一,因而引入位置信息后,地址之间的信息差距已经较小,对模型整体性能的提升影响并不是很大。
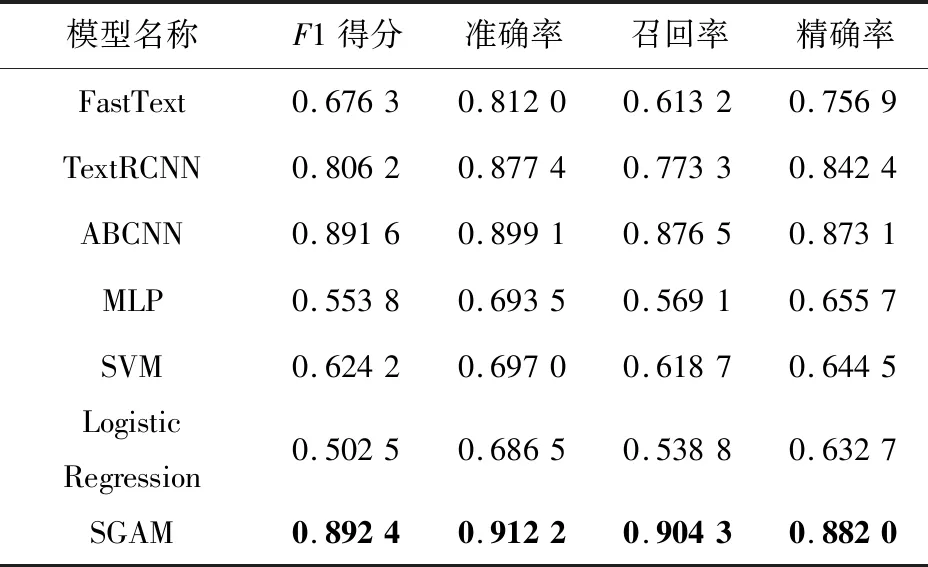
Table 5 Experimental results of comparative models表5 对比模型实验结果

Figure 6 Preformance comparison of comparative models 图6 对比模型性能比较(召回率和F1得分)
(2)与机器学习模型的对比。
作为另一类对比模型,实验中将部分常用的机器学习方法加入基线模型,包括支持向量机方法与逻辑回归方法,并以相同指标对这些基线模型的性能进行了衡量。对比结果如表5后半部分所示。
对比结果显示,相对于其他机器学习模型,尽管在训练时间方面机器学习方法具备较大优势,但SGAM模型的预测性能在各个指标上都有较为显著的提升,表明SGAM模型引入的语义信息和位置信息能有效提升模型在相似性预测上的性能。
4.5 特殊情况
由于本文采用的是基于文本信息的地址语义相似度判断,在碰到诸如表6所示的较为特殊的情况时,尽管模型判定Address 1与Address 2的关系为“不相似”,但在实际情况中,Address 1中的主体与Address 2中的主体指代的是同一个建筑物,因而实际二者是同一个地址。

Table 6 A special case of failure determination表6 一种判定失败的特殊情况
得到这样的结果的可能原因是在训练集中没有包含这类关联信息,亦或是缺乏相关的外部知识补充,模型无法找出存在部分关联关系的主体。
5 结束语
针对目前出现的无法识别中文地址中冗余信息问题,本文提出了一种基于BiLSTM与CNN的预测算法。实验结果显示,所提出的算法在多个指标上均有较好的效果。
对地址与地理实体之间的关联进行研究,并尝试引入诸如地理信息图谱类的信息以增强识别的准确度是下一步需要考虑的内容。同时,对未知的地址数据集的泛化能力也有待进一步研究。
