面向云环境的Flink负载均衡策略*
2022-05-27徐浩桐孙国璋贺菲莉段晓东
徐浩桐 ,黄 山 ,孙国璋,贺菲莉,段晓东
(1.大连民族大学计算机科学与工程学院,辽宁 大连 116600;2.大数据应用技术国家民委重点实验室(大连民族大学),辽宁 大连 116600;3.大连市民族文化数字技术重点实验室(大连民族大学),辽宁 大连 116600)
1 引言
人类正从IT时代走向DT(Data Technology)时代,数据是新时代最有价值的资源。DT时代的大数据分析系统以云计算为平台,以数据为中心来组织存储模型、计算模型和应用[1]。Flink[2]作为新一代的大数据计算引擎,能够以数据并行和流水线的方式执行包括批处理和流处理在内的任意流数据程序,备受学术界与工业界青睐。同时,容器技术因其卓越的再生性、一致性、可追溯性与可移植性使得应用程序容器化已变为一种发展趋势。因此,在容器技术盛行的今天,大数据技术与容器技术相结合必然会成为一个热点研究问题。容器化Flink部署能够消除线上线下的环境差异,提高资源利用率,保证生命周期内的环境一致性与标准化,为开发者提供巨大便利,提升开发效率。
然而就传统的容器化Flink运行部署模式来看,资源利用不均衡和通信开销过大等问题依然存在。针对此问题,本文提出了一种面向云环境的Flink负载均衡策略FLBS(Flink Load Balancing Strategy)。FLBS通过计算节点间的容器开销差异和资源利用率,从通信代价和均衡负载2个方面,对Flink集群中的容器进行动态调整,实时迁移。在不同规模的不同Benchmark作业上的实验表明,与Flink默认调度策略相比,该策略在资源利用和计算时延方面均有优化。本文的主要工作如下所示:
(1)提出了一种面向云环境的Flink负载均衡策略FLBS:针对容器化Flink集群中负载较大的节点,对容器进行迁移,在减小节点间负载差异的同时,最小化容器间的跨节点通信开销,提升系统的计算效率。
(2)提出了Flink容器通信代价模型:通过计算同节点和跨节点的数据流大小,对待迁容器的目标节点进行评分,降低迁移后的跨节点通信开销。
(3)提出了负载均衡模型:迁移容器时,从资源利用率和资源均衡程度2个方面对计算节点进行考量,以均衡负载。
2 相关工作
现阶段国内外对于容器化大数据处理引擎任务调度优化的研究主要集中在以下2个方面:一是针对容器迁移策略的研究,二是优化Flink等大数据计算引擎的任务调度策略的研究。
在容器迁移策略方面,有以下相关工作。文献[3]针对容器放置和重分配问题,提出了一种有效的通信感知最差拟合递减算法来将一组新的容器放置到数据中心,并通过在服务器之间迁移容器来优化容器的初始分配。文献[4]通过引入伪随机比规则,同时结合局部信息素蒸发和全局信息素更新,确定容器的迁移优先级,设计了一种基于改进蚁群系统MACS(Modified Ant Colony System)的迁移算法,利用负载均衡联合迁移成本LBJC(Load Balancing Joint Migration Cost)模型来进行容器迁移。文献[5]通过CRIU(Checkpoint/Restore In Userspace)[6]技术给出了一种支持Linux容器迁移的驱动程序的原型实现。文献[7]提出了一种考虑容器间距离、成本和可用带宽的局部动态迁移模型,对云环境下的容器进行热迁移。文献[8]针对边缘计算中基于容器的服务迁移问题,提出了一种基于移动感知的服务迁移机制,根据迁移成本和服务所在设备的移动方向,选择相应的目标节点进行迁移。文献[9]针对容器迁移过程中的资源开销和延迟会降低高性能计算机计算效率的问题,提出了一种多容器迁移策略,并设计了相应的迁移工具。文献[10]通过分析传统虚拟机和Docker容器的差异性,提出了一种面向Docker[11]容器的热迁移机制,实现了容器的运行状态迁移。
在优化Flink等大数据计算平台的任务调度策略方面,有以下相关工作。文献[12]提出了平滑加权轮询任务调度算法和基于蚁群算法的任务调度算法,解决了Flink集群运行过程中负载不均衡问题。文献[13]针对流处理系统Flink任务调度策略忽略了集群异构和节点可用资源,导致集群整体负载不均的问题,提出了一种基于异构Flink集群的节点优先级体系,动态调整适应当前作业环境的节点优先级指数,并按照节点优先级体系完成了任务的分配。文献[14]针对目前Spark大数据平台在任务调度时未考虑集群的异构性和节点资源利用的情况,提出了一种能够根据任务执行过程中的节点状态动态调整各个节点优先级的节点优先级调整算法。文献[15]针对大数据流式计算平台拓扑中因各关键节点上任务间不同类型的通信方式导致的通信开销较大问题,提出了一种Flink环境下的任务调度策略。通过各任务间数据流大小确定拓扑边权重,将有向无环图转化为拓扑关键路径模型,在保证关键路径上节点负载差异较小的同时,最小化关键任务的节点间通信开销。文献[16]通过建立负载预测模型,预测集群负载的变化趋势,提出了一种Flink环境下基于负载预测的弹性资源调度LPERS-Flink(Load Prediction based Elastic Resource Scheduling strategy in Flink)策略。文献[17]建立了流网络模型并通过构建算法计算每条边的容量值;其次通过弹性资源调度算法确定集群性能瓶颈并制定动态资源调度计划;最后通过基于数据分簇和分桶管理的状态数据迁移算法,实施调度计划并完成节点间的数据迁移。
虽然上述研究都取得了不错的成果,但目前在容器化Flink集群上的调度优化工作仍有欠缺。现有工作一部分无法适应Flink资源调度,一部分没有结合容器化Flink特点考虑容器间通信开销对节点负载均衡的影响,有些针对Flink任务调度的优化工作只停留在任务分配阶段,而不能在运行时动态调整,不够灵活。针对以上问题,本文提出了一种面向云环境的Flink负载均衡策略FLBS,既考虑了容器化Flink特点,又能够在运行时即时调整负载,有效提升了系统的计算效率。
3 研究技术背景
本节主要介绍相关的技术背景,主要包括Flink计算框架、容器技术和CRIU迁移技术。
3.1 Flink计算框架—Apache Flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据处理引擎。Flink以数据并行和流水线的方式执行包括批处理和流处理在内的任意流数据程序。此外,其运行时本身也支持迭代算法的执行。Flink作为最新一代的大数据计算引擎,除具有低延迟、高吞吐量和高性能的优势外,还支持事件时间(Event Time)概念,支持有状态计算,支持高度灵活的窗口(Window)操作、基于轻量级分布式快照(CheckPoint)实现的容错和基于JVM实现的独立内存管理,支持保存点 (Save Point)机制。因此,Flink以其优越的性能备受学术界与工业界青睐。
3.2 容器技术
容器化因其在部署应用程序和服务时的便利性和良好性能而备受青睐。首先,容器通过名称空间技术提供了良好的隔离,消除了与其他容器的冲突。其次,容器将代码、运行时状态信息、系统工具和系统库等都放在一个包中,并且不需要任何外部依赖来运行进程[18],这使得容器具有高度的可移植性和分发速度。
3.3 CRIU技术
CRIU最早是由Pavel Emelyanov发布到Linux开发者社区的,依赖于从3.11版开始逐渐提供的Linux内核特性,该工具主要是在用户空间实现的,可以对一个正在运行的应用或该应用的一部分进行状态保存并设置检查点,将进程信息转存为一组文件,并通过这些文件从快照位置恢复应用运行,以实现容器的热迁移、快照和远程调试等其他功能。
CRIU技术能够实现基于容器的迁移,因此本文使用该技术对Flink容器进行动态迁移,以提升系统计算效率,降低通信开销。
4 问题分析与系统架构
本节将从容器的编排工具和Flink容器化部署时默认的任务调度策略2个方面进行问题分析,并阐述整个均衡策略的系统流程。
为了确保服务的完整性,特定应用程序的一个函数可以实例化多个容器。例如,在Flink中,每个TaskManager或JobManager应该被部署为一个容器,这些容器部署在云或数据中心中,协同完成计算任务,并由Kubernetes[19]和Mesos[20]等编排工具管理。使用名称服务,这些编排工具可以快速定位不同服务器上的容器,因此可以很好地完成应用程序升级和故障恢复。由于容器易于构建、替换和删除,这样的体系结构使得维护基于多容器的应用程序变得很方便。
但是,基于多容器的体系结构也带来了一些副作用,即通信效率低。由于部署在同一组容器中的功能属于同一个服务,它们之间需要交换控制消息和传输数据。因此,同一应用程序的容器间的通信效率对整体任务性能影响很大。然而,简单地整合策略可能会导致多个资源的不平衡利用,因为同一组的容器通常集中于同一资源。上述容器编排工具虽然提供了利用容器的可能性,但是如何管理容器组以减少通信开销和平衡资源利用仍然是一个悬而未决的问题。

Figure 1 Flink default task allocation model图1 Flink默认任务分配模型
如图1所示,在Flink集群中,一个任务中不同容器中各算子之间需要频繁地通信,以协作完成计算任务,而各容器分布在Flink集群的不同物理机节点上,故容器间通信可分为同节点通信和跨节点通信。由容器间的通信机制可知,跨节点的通信代价远高于同节点的通信代价,而Flink默认采用轮询的调度策略,在不同节点的各容器间随机分配算子,未考虑任务中算子分布特点和容器间通信开销,同时Flink默认的任务调度策略也不具备均衡负载的能力,即不能即时获取各节点的资源信息以进行实时调度,均衡负载。

Figure 2 Structure of FLBS图2 FLBS结构
综上,若能够在保证各节点负载均衡的同时尽可能地将容器间的跨节点通信转变为同节点通信,降低通信开销,便可以有效地提升系统计算效率。故本文提出了一种面向云环境的Flink负载均衡策略FLBS,通过迁移Flink容器进行均衡负载的同时,结合Flink的算子分布特点,考虑了不同容器间的通信情况,从负载均衡和通信开销2方面对容器化Flink集群进行均衡优化。
如图2所示,本文提出的FLBS主要分为3个部分:(1)负载均衡探测对容器化Flink集群中的节点进行负载探测,并决定是否进行迁移;(2)基于负载均衡和通信代价的容器迁移模型;(3)面向Flink容器的动态迁移策略,包括迁移容器的选择和迁移目标节点的选择。下面将从以上3个方面介绍各部分的具体流程。
5 Flink负载均衡策略
在Flink容器通信代价模型和节点负载均衡模型的基础上,FLBS中的算法通过将部分容器从过载的节点迁移到跨节点通信开销较低的相对空闲的节点上以进行均衡负载。下面将详细介绍FLBS策略的执行流程与具体实现。
5.1 负载均衡探测
为了解决容器化Flink集群中节点负载不均的问题,首先需要获取集群中各节点的性能信息,并对整个集群进行负载均衡探测,确定超载节点,触发迁移算法以均衡负载。本文在进行容器迁移时所采用的负载均衡探测步骤如算法1所示。
算法1负载均衡探测
输入:当前周期t的资源利用率rt,所有节点集合N。
输出:超载节点nhot。
1:N←set of all nodes;//Flink集群中计算节点集合
2:Nhot← set of hot nodes;//超载节点集合
3:Whilenode∈N≠∅do
4:Ifrt>kthen//判断资源利用率是否超过阈值
5: AddnodetoNhot;//将当前节点添加到超载集合
6:endIf
7:endWhile
8:SortNhotbyRU;//将超载节点按负载排序
9:Pick thenhot∈Nhotwith the largestRUvalue;/*挑选负载最大的节点*/
10:Returnnhot
首先,周期性采集Flink集群中每个节点的资源利用率,监控每个节点的资源利用情况,判断集群中是否存在超载节点,当超载节点出现时,将其加入超载集合。其中,当前周期t的节点资源利用率rt都是通过使用自回归模型(Autoregressive Model)由最近n个周期的资源使用情况预测得到的,如式(1)所示:
rt=φ0+φ1rt-1+φ2rt-2+…+φnrt-n+ω
(1)
其中,rt-n,rt-n-1,…,rt-1表示节点中某一资源在n个周期内的利用率,φ0为常数项,φ1,…,φn为自相关系数,ω是均值为0、方差为σ的随机误差值。若节点在当前周期的资源利用率超过了给定的阈值,则该节点被标记为超载节点。
下一步计算针对不同资源利用的综合指数。一个Flink任务通常需要多种不同类型的资源来提供服务,如CPU、内存和网络带宽等,在负载均衡探测过程中,不能以单一性能信息作为衡量标准,故本文定义了一个资源综合利用指数来统计各节点中不同资源的综合利用率,如式(2)所示:
(2)
其中,mem表示节点中的内存利用率,cpu表示CPU利用率,net表示节点网络带宽的使用率。RU值为Flink集群中各节点的资源利用率的综合指数,RU值越大,节点中的资源利用率越高,负载越大,将计算节点按RU值从大到小进行降序排列,则排列越靠前的,执行迁移程序的优先级越高。
5.2 模型构建
本节主要结合通信代价与均衡负载对问题进行定义和建模。
5.2.1 AoE网络拓扑模型
为确定Flink集群中各算子间数据流大小,量化容器间跨节点通信和同节点通信的开销差异,根据Flink的任务拓扑模型,定义有向无环图G=(V(G),E(G)),它由顶点和作业边组成,其中,V(G)表示拓扑中的算子集合,E(G)={e〈vs,vt〉|vs,vt∈V(G)}表示算子间的数据流集合。由流式计算的任务拓扑结构可知,若将顶点vs流向顶点vt的数据流大小作为弧vs→vt的权重,那么可以将流式计算的拓扑图转为带权值的AoE网络。AoE网络拓扑模型如图3所示。
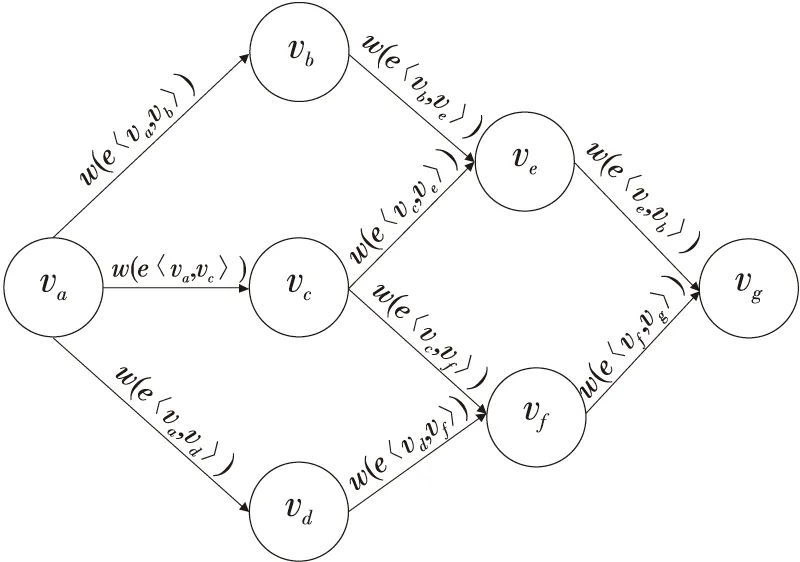
Figure 3 Topology model of AoE network 图3 AoE网络拓扑模型
5.2.2 Flink容器通信代价模型
如第3节所述,为最小化容器间跨节点通信开销,提升计算效率,需要分别计算当前容器的跨节点通信开销和同节点通信开销,通过AoE网络拓扑模型,便可以量化计算各节点与当前容器的开销差异。现将2个容器间的通信代价定义如式(3)所示:
(3)
其中,C代表Flink集群中所有Flink容器集合,对于每一个容器c∈C,H(c)表示容器c部署在节点H上,若H(ci)=H(cj),则代表容器ci和容器cj部署在同一个节点上;f(H(ci),H(cj))表示在相同或不同节点上容器ci和容器cj之间的通信代价,它是由互相通信的2容器间各算子的数据流大小的累加得到;V(ci)表示容器ci上所有算子集合。w(·)为2个算子间的数据流大小。
同时,在Flink集群中,一个节点可能部署有多个Flink容器,每个容器中均可能有上下游算子,故在计算一个容器的跨节点通信代价和同节点通信代价时,通常是一个容器对多个容器的,故定义一个容器与多个容器间的通信代价如式(4)所示:
(4)
最终待迁容器与待选节点的通信指数如式(5)所示:
(5)
其中,Cscore表示待选节点的通信评分,它是由待迁容器的跨节点通信代价与同节点通信代价相减得到的。若Cscore>0,则表示跨节点通信代价大于同节点的通信代价,由Flink拓扑模型可知,当提交拓扑给节点后,拓扑实例便不会发生改变,其包含的任务总数和数据流总量也不会改变[15],故迁移后能够有效降低跨节点通信代价,缩短通信时间,增加通信效率,且增加的通信效率将大于迁移后因同节点通信变为跨节点通信而降低的通信效率;其差值越大,则迁移后提高的通信效率越多,因迁移而降低的通信效率越少,待选节点的通信评分越高。
5.2.3 节点负载均衡模型
在迁移过程中对目标节点进行选择不仅要考虑容器间的通信代价,负载均衡也是一个重要指标,故本文提出资源需求评分Rscore和资源均衡评分Bscore来衡量节点的负载均衡程度,以实现迁移容器时目标节点的优选。如式(6)所示,资源需求评分Rscore是由节点空闲资源与节点资源总容量的比值计算而来,即由CPU或内存资源的总容量减去节点上已有容器和当前要迁移容器的需求总量,得到的结果再除以总容量。其中,capacity为资源总容量,requested为容器资源需求量,CPU和内存具有相同的权重,资源空闲比例越高的节点得分就越高。
当时,除了此项新任务,医院还承担着各项社区帮扶工作,还托管着宁波多家小型医院,阮列敏酝酿将关联工作全部系统化。经过一段时间梳理,她拍板成立基层服务指导科,将慢病管理、医联体、分级诊疗等工作协调起来。
(6)
而资源均衡评分Bscore是以CPU利用率cpu和内存资源利用率mem的相近程度作为评估标准,如式(7)所示,二者越接近的节点权重越高。资源均衡评分与资源需求评分相结合用于平衡优化节点资源的使用情况,以选择那些在迁移当前容器后系统资源更为均衡的节点。
(7)
综上所述,本文共提出了2个模型:Flink容器通信代价模型和节点负载均衡模型,3个指标:待选节点的通信指数、资源需求评分和资源均衡评分。由上述可知,使用任意单一指标均不能很好地完成容器化Flink集群的负载均衡优化,对多个优化目标进行优化的常用方法是将多个目标转换为单个目标。本文就采用这种方法,将最终待选节点评分定义为所有上述定义的评分的加权和,如式(8)所示,从通信代价、资源利用和资源均衡3个方面对待选节点进行评估,以选出最优目标节点进行迁移,提升系统计算效率。
finalScoreNode=
ωC*Cscore+ωR*Rscore+ωB*Bscore
(8)
其中,ωC为通信评分权重,ωR为资源需求评分权重,ωB为资源均衡评分权重,ωC+ωR+ωB=1。
5.3 Flink容器迁移
容器迁移要解决的主要问题是被迁移容器的选择和容器的重映射。其中,选择待迁容器时主要考虑2个方面:一是所在节点的负载情况;二是容器迁移时的开销大小,在进行迁移时,负载越大、内存占用越小的容器迁移优先级应越高。在进行容器重映射时,根据5.2节中提出的评分模型,通过评分对集群中的待选节点进行择优,将由负载均衡探测算法选出的待迁容器迁往负载较为均衡的、跨节点通信代价相对较低的目标节点。Flink容器重映射的具体过程如算法2所示。
算法2Flink容器重映射
输入:超载节点nhot、有向无环图G=(V(G),E(G))、有向边权值集合W、资源利用率rt。
1:Cn← the set of containers in nodenhot;
2:Ntarget←target node;//目标节点
3:Sort containers inCnbyRSV;//容器排序
4:Whilert>kdo
5:IfCn≠∅then
6: Pick thec∈Cnwith the largestRSVvalue;
7:Ntarget←Max(finalScoreNode(G,W,rt));
8: MigratectoNtarget;
9:EndIf
10:EndWhile
在算法2中,集群中的超载节点已由负载均衡探测算法给出,但由于每个节点中各容器的体量不同,迁移代价也不同,故在超载节点队列中拥有最大RU值的节点中,将所有Flink容器按RSV值降序排序,以选出迁移效率最高的待迁容器;然后为待迁容器进行节点评分,将分数最高的节点作为目标节点。其中,RSV值为资源利用综合率指数RU与容器内存占用大小size的比值,如式(9)所示,资源使用率越高,容器内存越小,则RSV值越大,容器的迁移优先级越高。
(9)
算法按RSV值的大小依次执行容器的迁移程序,直到超载队列中所有节点的各资源均低于相关阈值,Flink容器动态迁移结束。
容器迁移的具体设计架构图如图4所示,集群中每个Worker节点上都有一个资源监测模块,周期性地对当前节点的资源使用情况和负载均衡情况进行监测,并将监测结果实时反馈给Master节点的调度器;调度器根据资源信息选择超载节点和待迁容器,根据待迁容器的通信情况和各节点的负载信息,对节点进行评分,已选择目标节点进行迁移;直到集群中不再出现超载节点,迁移结束。
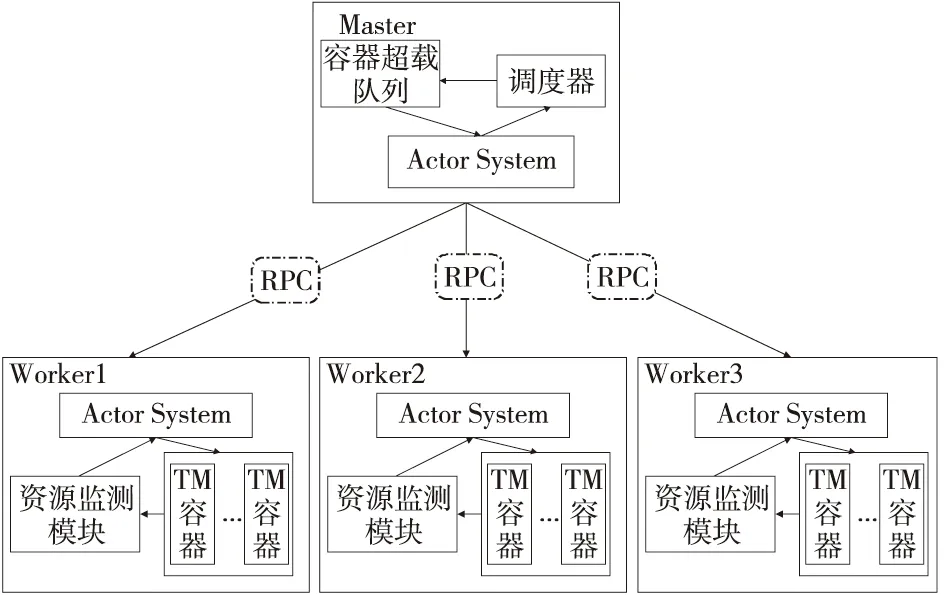
Figure 4 Architecture of container migration design 图4 容器迁移设计架构
6 实验与结果分析
本节主要将Flink默认调度策略、Kubernetes容器调度策略和本文提出的FLBS策略进行实验和对比分析,使用不同规模的数据集在不同类型的计算任务下从任务运行时间、资源利用率和节点间数据流大小3个方面验证FLBS的有效性。
6.1 实验环境与参数设置
实验使用的Flink集群包括1个Master主节点和4个Worker从节点共5台物理机,每台机器软件、硬件配置如表1和表2所示。
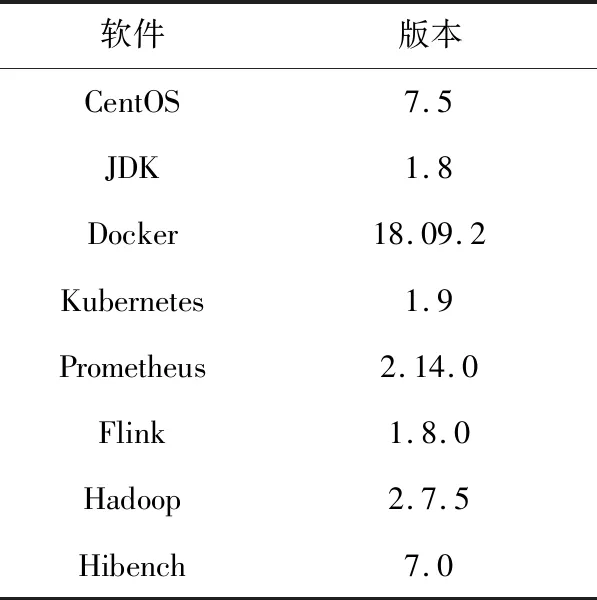
Table 1 Software configuration表1 软件配置
本文使用大数据基准测试工具Hibench中的标准测试数据集,在不同类型的计算任务下进行实验,为保证实验结果的可靠性同时减小误差,通过多次重复实验的平均值作为最终结果,实验中涉及的参数配置如表3所示。

Table 2 Hardware configuration表2 硬件配置

Table 3 Default parameters configuration表3 默认参数配置
6.2 实验结果分析
图5展示了分别使用2 GB,4 GB和6 GB数据进行WordCount计算任务时,3种调度策略运行时间的对比。从图5中可以看出,相较于其他2种策略,本文提出的FLBS在3种规模的数据下Flink任务的运行时间均有明显减少,且随着数据量的增加,优化效果逐渐明显。

Figure 5 Comparison of task execution time on different scale datasets图5 不同规模数据集上任务运行时间对比
本文分别使用WordCount、PageRank和TeraSort 3种不同类型的计算任务来验证本文FLBS的普遍有效性,每种Flink任务均采用4 GB数据集,实验结果如图6所示。从实验结果可以看出,与Flink默认策略和Kubernetes调度策略相比,本文提出的FLBS在运行时间上均有一定的优化效果,其中,在PageRank任务上的优化效果最为明显。这是由于PageRank属于计算密集型作业,而WordCount属于数据密集型作业,TeraSort属于I/O密集型作业,后2类作业中消耗较多的I/O资源,而本文提出的FLBS在资源均衡方面主要考虑了CPU和内存的利用率,故在计算密集型作业上的优势更为明显。

Figure 6 Comparison of execution time of different types of computing tasks图6 不同类型计算任务运行时间对比
为验证策略对容器化Flink集群中各节点均衡负载的有效性,本文使用Prometheus对各计算节点的CPU和内存的使用情况进行监测,实验结果如图7所示。从实验结果可以看出,Flink默认调度策略在各节点上CPU和内存的负载差异较大。这是由于默认调度策略使用轮询的方式在节点间随机分配任务,没有考虑节点间的资源均衡,其中,节点2和节点4的CPU负载最大,节点3和节点4的内存负载最大,超出了预设阈值0.75。运行FLBS,执行容器迁移后,各节点的CPU和内存负载差异明显缩小且低于阈值0.75。

Figure 7 Load comparison of cluster nodes图7 节点负载对比
FLBS策略在不同容器数量下对运行时间的影响如图8所示。从实验结果可以看出,Flink任务的运行时间随容器数的增加逐渐减少,但当容器数增加到一定数量时,运行时间的下降速度开始逐渐减小。这是由于Flink集群中的容器数量增加时,容器间通信增加,算法的时间开销增加,总运行时间上升,但FLBS的平均运行时间仍小于Flink默认调度策略的。

Figure 8 Execution time vs.the number of containers图8 运行时间随容器数变化
图9为在Flink默认调度策略下和本文提出的FLBS策略下各节点间数据流大小随时间变化曲线。从实验结果可以看出,2种策略的节点间数据流均从0开始快速上升最后趋于稳定,而FLBS稳定时期的节点间数据流量明显小于Flink默认调度策略的,即容器间跨节点通信的数据流大小小于默认策略,可见,FLBS在降低跨节点开销方面有明显效果且符合Flink容器通信代价模型,验证了策略的有效性。

Figure 9 Data flow between nodes over time图9 节点间数据流大小随时间变化
7 结束语
通过归纳梳理现阶段国内外对于容器化大数据处理引擎任务调度优化的相关工作,发现现有的成果大多存在调度不灵活,与Flink平台不匹配,或未考虑容器间通信开销对负载均衡的影响等问题,因此本文提出了一种面向云环境的Flink负载均衡策略(FLBS),以通信代价和负载均衡为衡量标准对容器进行迁移,在集群出现负载不均的情况时,能够有效减少作业运行时间,提高系统计算效率。
下一步的研究工作计划使用更大规模的数据集和更多类型的计算任务进行实验,对算法进行进一步优化,以减小迁移的时间和空间开销。
