基于infoGAN的工业加热炉温度场预测方法
2022-05-27孙全胜
孙全胜
(中石化股份公司天津分公司装备研究院)
工业加热炉是炼化装置的重要设备,其安全运行直接影响装置的长周期生产和企业的经济效益。 焦化炉、常减压炉等工艺介质属于易结焦介质,在运行过程中,常因燃烧状况不好使得炉管受热不均,出现局部超温的现象。 如果工业加热炉长时间运行在超温状态, 将会导致炉管结焦、开裂、鼓胀变形甚至爆管。 因此,必须采取措施减小热强度的不均匀性。 但工业加热炉燃烧过程具有瞬态变化、随机湍流等特征,给温度分布的测量带来困难, 导致燃烧调整没有可靠依据。目前, 大多采用基于成像装置 (Charge Coupled Device,CCD)的摄像机作为二维辐射能量分布传感器,但该类摄像机价格高,经济性不强。
传统工业加热炉的炉温通常只能通过传感器或成像装置获得,价格高昂。 随着计算机技术的进步,机器学习算法,包括基于BP神经网络的方法、基于模糊最小二乘支持向量机等被应用到炉温预测中,但是预测能力有限;人工智能兴起后,深度学习算法,包括粒子群神经网络[1,2]、基于卷积神经网络的算法也被应用到工业领域,但大部分都是基于时间序列的预测方法,对于短期数据进行的实时预测效果不佳,因此并没有得到广泛推广。
笔者的研究是将深度学习方法应用于工业加热炉温度场的预测。 生成对抗网络(Generative Adversarial Nets,GAN)是一种具有强大数据生成能力的深度学习模型[3],在数据增强、图片生成等领域应用广泛[4,5]。 本研究中,笔者研究选用信息最大化生成对抗网络 (Information Maximizing Generative Adversarial Nets,infoGAN)作为基础算法框架,同时选取结合最优传输距离生成对抗网络 (Wasserstein Generative Adversarial Nets,WGAN)的损失函数代替原有损失。利用工况数据和计算流体动力学 (Computational Fluid Dynamics,CFD)仿真得到的温度场数据作为训练算例进行有监督训练, 并且将结果用Matlab进行可视化,实现任意炉膛截面和炉管表面温度场云图的实时三维显示。
1 模型网络框架
infoGAN由生成器、 鉴别器和分类器组成[6],网络结构如图1所示, 其中,c′为分类器判断出的隐含编码。 随机噪声向量z是生成器的输入,生成器的作用是生成尽可能接近训练样本的假样本以欺骗鉴别器;鉴别器则通过比较训练的样本数据x和生成器获得的假样本G(z),计算出假样本数据接近真样本的概率。 infoGAN将GAN网络和信息理论相结合, 引入隐变量编码和生成数据之间的互信息关系约束,将连续噪声向量z分成两个部分:一部分是不可压缩的噪声;另一部分是隐含编码c,且c可以是离散值,通过建模隐藏编码和生产样本的对应关系, 从而达到改变输入噪声控制生成样本的目的。在本方法中,将处理后的工况数据视为隐含编码, 训练生成器得到一个重建温度场, 并与CFD仿真温度场一起投入鉴别器进行真假判断, 使得模型最终能够仅凭借工况数据生成与CFD仿真温度场足够接近的重建温度场。

图1 infoGAN网络结构
GAN的目标函数定义为:

其中,E代表期望值,x~Pdata(x)代表样本数据x满足分布Pdata(x),z~Pz(z)代表随机噪声向量z满足分布Pz(z)。
对于两个变量X和Y,它们之间的互信息I(X;Y)定义为:

其中,p(x,y)是X和Y的联合概率密度函数,p(x)和p(y)分别代表了X和Y的边缘概率密度函数。
H代表熵,则互信息又可以表达为:

β代表超参数,则最终损失函数的表达式为:

最初的GAN 模型在理论和实践中并不成熟,GAN的训练需要大量的样本,并且训练次数也很多,模型难以得到最理想结果,而且很容易出现梯度消失[7]或者模式崩溃[8]的问题。 因此,笔者采用WGAN原理进行改进[9],所设计的网络模型如图2所示,生成器每个网络块都包括了转置卷积层(Deconv)、批次归一化层(Batch Normalization,BN) 和全连接层 (Fully Connected,FC),激活函数选择LeakRelu,最后一层选择Sigmoid激活函数。 完整网络中总共使用了4个网络块,每个转置卷积层卷积核K的大小均为4,卷积核个数N分别为8、16、32、64,步长S为2。 设计的鉴别器网络与生成器类似, 共包含4个卷积层(Conv) 以及对应的批次归一化层和LeakRelu激活层,每层的卷积核个数分别为64、32、16、2,卷积核大小为4,步长为2,最后使用一个全连接层得到0或1的判别结果。 分类器网络与鉴别器共享网络参数,仅在最后一层发生改变,经过两个全连接层输出分类标签。


图2 改进的网络模型
2 数据仿真
2.1 扩张通道模型尺寸
为了更好地训练模型, 笔者设计了一个扩张通道进行温度场仿真, 具体几何模型及其尺寸如图3所示。 进口为长方形,出口为正方形(边长10 cm);计算域通道在竖直方向上先扩张后变成平直段,水平方向通过竖直方向的截面拉伸得到。

图3 扩张通道的几何模型及其尺寸
2.2 CFD数值仿真
CFD仿真相当于在计算机上虚拟地做流体实验来模拟实际情况,基本原理是数值求解流体流动的微分方程。 在遇到复杂问题时,人为难以进行理论分析或直接做实验,相比之下,CFD只需使用相应软件就可以通过模拟实际环境得到可靠的实验数据, 甚至可以通过CFD软件进行实验的同时发现新的实验现象[10]。
本次实验采用CFD数值模拟的方法, 输入变量有进口速度、温度和气体导热系数,输出变量有计算域的温度场和速度场。 采用ANSYS ICEM17.0进行计算网格划分, 采用ANSYS FLUENT 17.0进行数值模拟。
计算域中几个典型位置的温度分布:进口处气体温度为输入变量之一, 外界环境的温度为300 K。 由于壁面与外界环境的换热,通道内气体温度降低且越靠近壁面气体温度越低。 计算域内气流的温度在300~1 500 K。
对于仿真得到的370组数据, 选取250组作为训练集、60组作为测试集、60组作为验证集。 先将原始一维的50 933个点处理成二维数据训练,再将一维数据用于训练,只取温度数据,为了方便训练,将数据归一化到(0,1)之间,其变换公式如下:
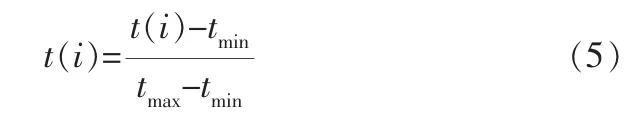
式中 t——温度,K;
tmax——温度最大值,K;
tmin——温度最小值,K。
3 模型训练与参数调整
3.1 学习率
学习率(Learning Rate,LR)是深度学习中一个很重要的超参数,它主要在梯度下降法中发挥作用。 梯度下降法的目的是寻找函数的最优解。而学习率则是起始寻优步长,深度学习网络中各部分权重ω的计算式为:

其中,α为学习率,loss为神经网络所选择的损失函数。
学习率设置过小,收敛速度就会非常缓慢,进而导致网络效率低下;学习率设置过高,可能导致网络学习过程中错过最优解, 在最优解附近来回摆动,因此,设置恰当的学习率是很重要的。 最初对生成器和鉴别器设置了相同的学习率, 即0.01。但是在训练过程,鉴别器的loss极小(接近0),而生成器的loss则较大且不稳定, 持续在0.2~1.0摆动,说明生成器为了结果能混淆鉴别器而在反复进行调整,但由于鉴别器判别能力过强,使得生成器不管怎么调整也无法得到最优解, 这将导致整体模型无法收敛。为了解决这个问题,笔者决定为生成器和鉴别器设置不同的学习率, 并按照初步实验结果将鉴别器学习率设置为生成器的5倍。
3.2 隐空间维度
隐空间代表网络学习到的训练样本的特征数,隐空间维度有下限无上限。 通过以往经验,如果隐空间维度过小,则生成图片变化很小;但对于工业数据预测来讲, 对于每一个固定的条件,温度场的变化范围很小,因此,其隐空间维度不应过大,否则生成的温度场结果将不稳定且训练耗时较长。 综合上述分析,需要寻找能够满足本项目的适合的隐空间维度大小。
3.3 批次训练样本数
批次训练样本数(Batch Size,BS)是指一次训练过程中所用到的样本数量。 由于模型数据集较大,如果每次训练都使用全尺寸训练集,将会导致模型训练缓慢、 内存空间不足且泛化性能一般。 但过小的批次训练样本数会使得模型收敛缓慢。 因此,需寻找既能满足效率要求又能满足精度要求的批次训练样本数。
由于不同参数之间的结果会互相影响,并不是完全解耦合的, 最优值会随着其他参数的变化发生改变, 并且每个参数对最终结果的影响也是非线性的。因此,无法逐个对上述参数进行单独寻优, 即需要寻找的最优参数是学习率、 隐空间维度、批次训练样本数共同作用的组合。笔者通过对上述参数设置在合理范围内设置多个组合, 以寻找结果最优的参数搭配。 将生成器和鉴别器学习率设在0.000 1~0.010 0,隐空间维度设在5~180,批次训练样本数设置在10~270。 以平均相对误差为结果评价标准,部分训练条件和结果见表1。
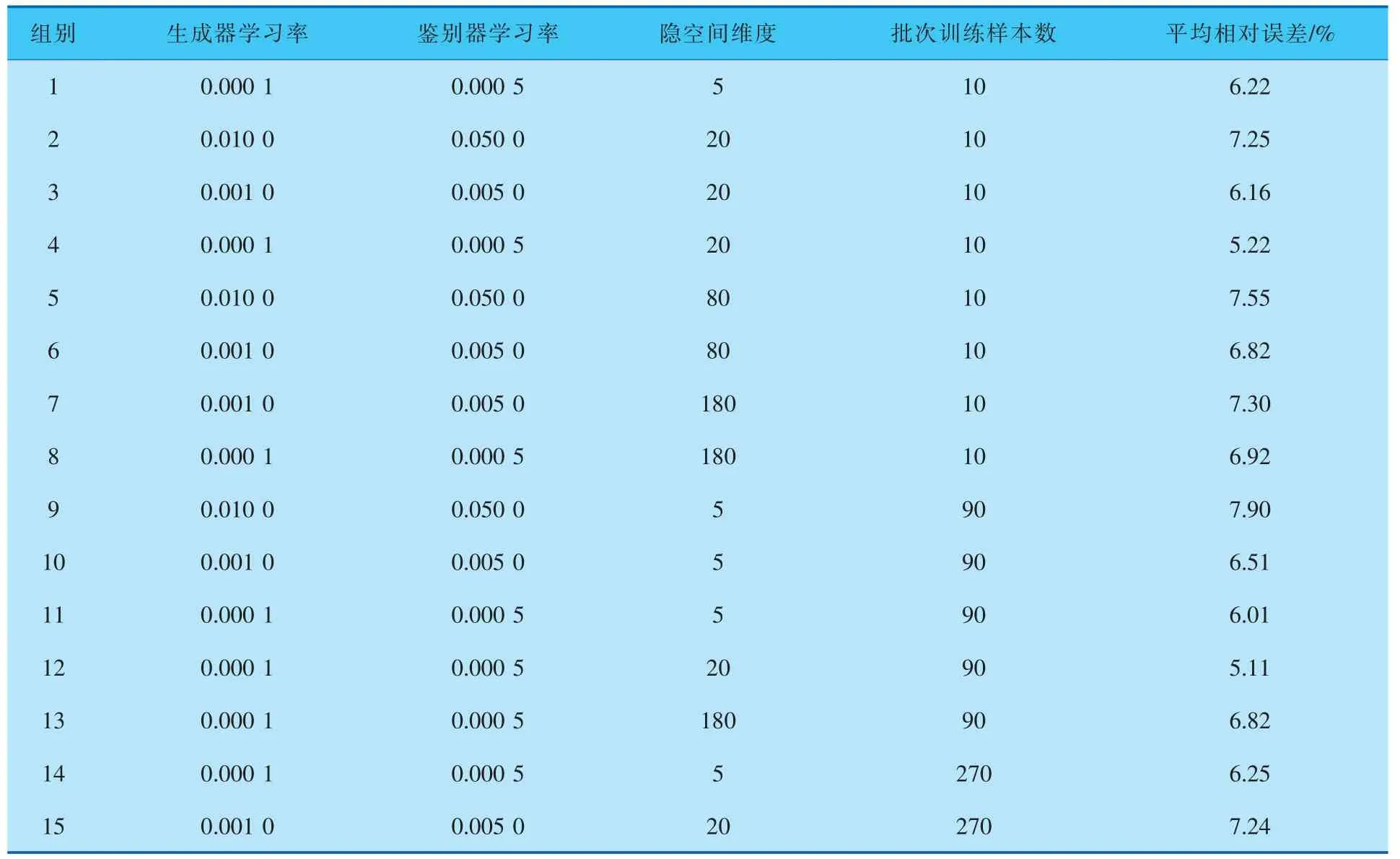
表1 不同参数下部分预测结果
3.4 结果分析
采用表1第4组参数组合能够在较短的时间内得到较优的结果, 而第12组虽然能获得最优结果,但其所需的时间开销是第4组的数倍, 综合分析后决定采用第4组的参数组合进行后续训练, 即生成器和鉴定会别器学习率分别为0.000 1和0.000 5,批次训练样本数为10,隐空间维度为20。
CFD仿真数据的输入速度变化范围为0.5~2.75 m/s,变化步长为0.25 m/s;输入温度变化范围为600~1 500 K,变化步长为100 K;气体导热系数变化范围为0.024 2~0.242 0 W/(m·K), 变化步长为0.024 2 W/(m·K)。 随机选取其中60组作为测试集计算预测温度值与CFD真值的相对误差, 表2展示了其中的10组。

表2 部分输入条件下预测温度与CFD真值的平均相对误差
在训练过程中损失函数值的变化趋势如图4 所示。

图4 损失函数值变化趋势
用Matlab软件进行可视化处理, 其中一组温度场的可视化与真实情况如图5所示。

图5 预测结果与真实温度场对比
可以看出, 采用infoGAN网络作为基本框架的深度学习方法能够较好地拟合工业加热炉原始温度场的分布情况,且在参数调整后,所得结果的平均相对误差绝对值在6%以下,基本满足需求。
该方法的实现,可以仅依靠基本的工况数据得到对应工况下与CFD仿真温度场平均相对误差绝对值在6%以下的实时温度场预测,可以据此得到加热炉处于最优燃烧状态下的操作建议,并对超出允许操作参数的情况进行预警,保证加热炉的长期高效运行。
4 结束语
笔者借鉴GAN的思想, 对infoGAN网络进行修改, 使得网络可以训练带有离散标签值的数据; 在infoGAN中引入WGAN损失函数进行优化,同时探究了学习率、批次训练样本数和隐空间维度大小对网络训练结果的影响,并选择最优参数对网络进行训练, 采用Matlab软件做出可视化处理, 实现了工业加热炉温场预测的良好效果,在测试集上平均相对误差绝对值在6%以下。该方法具有良好的应用前景。
