面向AI数据流处理的边缘GPU集群通信系统
2022-05-27陈庆奎
涂 聪,陈庆奎
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
物联网[1]与人工智能[2]技术的融合已在视频监控与视频分析[3]等领域得到了广泛的应用.以社区养老照护为例,传统的解决方案利用终端设备采集视频图像并通过网络传输到云端服务器后进行处理.因为原始图像数据量巨大和传输距离远等问题,造成应用的处理和响应延迟较大,无法提供实时的数据分析.边缘计算[4]作为云计算的一种补充和优化,能够提供更实时、更快速的数据处理能力.通过在靠近终端的边缘侧部署边缘GPU集群,能够更好地支撑本地业务的实时智能化处理.
图像信息的传输往往面临着用户隐私泄漏的风险.AI技术的快速发展,使得终端设备能够利用自身计算资源通过AI技术将隐私信息处理成不可还原的中间数据,很好的保护了用户隐私.终端数据的周期性采集决定了AI数据流的周期性,以及数据处理的周期性;同时,大量的终端设备势必会形成并发的AI数据流.边缘GPU集群按照处理周期对数据流进行并行处理,可以有效发挥GPU及GPU集群的SPMD(Single Program Multi Data)的设备优势特性.随着终端设备规模的不断扩大,边缘GPU集群所处理的数据量显著增加,这对边缘GPU集群的计算能力和通信能力提出了更高的要求.
为了提升边缘GPU集群的通信能力,满足大规模AI数据流的实时处理需求,本文基于DPDK(Dada Plane Development Kit)设计了面向AI数据流处理的边缘GPU集群通信系统.该系统实现了基于DPDK的高效AI数据流传输协议;根据节点计算能力和网络负载情况制定合理的数据流分配策略,以提高集群计算效率;动态调整缓冲区和转发核心数量,以提高系统性能、降低系统能耗.
2 相关工作
随着边缘AI[5]的兴起,如何在资源受限的终端设备上执行AI计算成为研究热点.文献[6]提出了一种网络分层的方法,根据终端设备的资源情况将CNN(Convolutional Neural Networks)网络动态切分.在该方案中,网络被拆分为两部分,一部分在终端上进行简单的卷积和池化等预处理,预处理后的AI数据流被传输到服务器上,并作为部署在服务器上另一部分的输入以完成后续的计算.随着接入终端规模的不断扩大,服务器存在计算能力不足的问题.由于GPU超强的计算能力,现已在人工智能、算法加速[7]等场景中广泛应用.实际应用中通常在靠近终端的边缘侧构建边缘GPU集群进行并行计算,以提高服务器计算能力、缩短计算时间.由于需要计算的数据量较大,集群中各计算节点的数据传输延时是影响计算响应的一个重要因素.
在传统的TCP/IP网络通信中,数据从产生到交付给应用程序的过程中包含了硬件中断、内核协议栈处理、软件中断、网络协议栈处理等一系列操作,期间存在着的多次内存拷贝、频繁上下文切换等都会增加通信时延,降低通信效率.RDMA(Remote Direct Memory Access)是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术[8],通过在网卡上将RDMA协议固化于硬件,以及支持零拷贝网络技术和内核内存旁路技术这两种途径来达到其高性能的远程直接数据存取的目标,很好地解决了传统网络传输中数据处理延时问题.但是,该方案需要专业的硬件设备来实现,同时需要专用的网卡和交换机[9],对于分布广泛的边缘GPU集群来说,成本较高.
传统网络通信方案及专用方案的局限性严重制约着相关业务的发展,亟待解决.经业界不断研究,目前已出现了如netmap、DPDK等优秀的高性能网络数据处理框架.其中,netmap基于共享内存的思想,提供了一套用户态库函数,绕过系统内核的包处理操作,实现了用户态和网卡之间的数据包高性能传递[10].但是其仍然依赖中断通知机制,未完全解决瓶颈.DPDK使用基于UIO(Userspace I/O)的旁路技术,在数据包收发时,采用轮询技术减少中断处理开销.大页内存和CPU亲和性机制的应用,提升了cache命中率,省却了线程在不同核间频繁切换的开销[11].近年来,DPDK因社区完善、实施简单而被广泛使用.文献[12]利用DPDK的高效数据包处理能力,设计并实现了一套数据包捕获系统,使系统能够实现接近线速的收包.在网络虚拟化方面,DPDK+NFV(Network Function Virtualization)的应用[13-15],将一部分原来由硬件实现的网络功能,在服务器上加载DPDK组件,以VNF(Virtualized Network Function)软件的形式直接运行在服务器上,通过调用DPDK的用户态API进行快速转发.因优秀的包处理能力,DPDK在各领域应用前景广泛.
3 系统架构及核心思想
3.1 AI数据流定义
目前,通过终端设备自身的计算能力对数据进行预处理后传输到边缘集群进行后续处理的方式在用户隐私保护、数据实时分析等方面优势明显.其中,经AI计算得到的中间结果称为AI数据流.AI计算的特性决定了AI数据流的组成为大量的浮点型数值矩阵;终端数据的周期性采集也决定了AI数据流的周期性;同时,数据存在时效性,必须在处理周期内完成处理.
大规模终端设备都存在并发周期,也就意味着边缘GPU集群需根据周期将AI数据流划分,并将周期相同的并发AI数据流统一提交到计算进程进行并行处理.为了更好地对AI数据流进行描述,在此给出AI数据流的相关定义.AI数据流表示为AS(S_id,timestamp,data,ptime),其中S_id用于唯一标识该AI数据流;timestamp为该数据流的生成时间,AI数据流按照时间形成序列;data表示数据部分;ptime为该AI数据流的处理周期,即该时刻的数据流必须在ptime内处理完毕.大量AI数据流构成并发AI数据流,表示为PAS(ASS,AS_num,ptime),ASS是由具有相同处理周期的AS构成的集合,AS_num为构成集合的AS数量.
3.2 多核多网卡并行通信机制
海量的AI数据流会对网络传输造成巨大的压力,本文采用多网卡技术增加带宽,在提高服务器吞吐量的同时,降低了系统部署成本.边缘GPU集群完成复杂的模型计算主要依靠的是GPU强大的计算能力,CPU资源长期空闲,DPDK多核多线程机制可以充分利用空闲的CPU资源提高通信性能.另外,得益于DPDK用户态驱动和轮询机制等特性,在处理数据包时避免了不必要的内存拷贝和中断开销,相比传统内核协议栈的数据处理方式,处理时间大幅降低,进一步提升了集群的数据容量和带宽利用率.
本文通信架构如图1所示,多核多网卡的并行通信机制,提高了服务器间的数据传输的带宽和效率.集群中各节点通过交换机连接,当集群需要扩展时,只需将新节点连接交换机接入集群即可.

图1 多核多网卡并行通信架构
3.3 AI数据流的缓存分配调度
除了满足海量AI数据流的通信需求,边缘GPU集群还必须支持大规模AI数据流的实时处理.借助于多核处理器的性能优势,我们将任务按功能划分,与核心进行亲和性绑定,不同任务交由不同的核去处理,避免任务在不同核间频繁切换,提高了工作效率.其中,主核负责调度,包括系统的监控、节点的配置等;其他核心负责数据的收发及处理.
数据处理转发过程中,未能及时转发出去的数据需要进行缓存,对于缓冲区的设置,以往的方案通过动态增加缓冲区长度来适应更多的数据.但是,当数据流增加,转发能力受限时,继续增加缓冲区的长度会造成内存溢出和系统资源浪费的问题,影响数据处理.考虑到这一问题,我们设计了动态多核多缓冲区模型,在纵向扩充缓冲区的同时提升数据的处理转发能力,确保能够在处理周期内将数据提交给本地计算进程或转发到其他节点进行计算分析.另外,节点硬件配置的不同意味着数据处理能力会有差异,本文通过综合分析集群各节点计算能力和网络负载,确定了各节点处理能力及其所占权重,根据权重占比完成集群各节点的数据流分配,保证了集群任务计算的稳定性.
4 系统模型及实现
4.1 数据传输协议与通信模型
AI数据流的数据由源源不断的数值型矩阵数据构成,包含大量的浮点数.对于该类型数据,通用的字符流文件格式如json、xml等会增加待传输数据的开销,在数据接收端也需要额外进行解析后才能获取真正的数据内容,并非最佳传输方案.为此,根据AI数据流特性,设计了基于消息的数据传输协议,减少数据量的同时,根据协议内容,接收端只需一次解析便可直接获取需要分析的数据.
如图2所示,以太网包数据域为协议的主要内容.协议字段包括每个数据包产生的时间(timestamp),数据包的序号(pkt_id),数据流头部信息(s_head)等.根据数据包的时间戳、序号及流头部信息中的流编号(id)可以唯一标识一个数据包.集群内部也需要定时进行信息交换,以供任务调度模块综合分析集群中节点的负载,根据分析结果完成任务的分配.信息交换使用较短的控制消息,内容包括计算节点的最大计算能力Vg,当前计算能力Cg以及可用带宽anbg等.

图2 AI数据流数据包格式
系统数据收发及任务调度如图3所示.其中,配置表用于存放系统的配置信息,包括网卡端口数量、端口类型、缓冲区数量、转发核心与缓冲区对应关系以及流分配表等.系统使用多张多端口网卡进行数据的收发,网卡端口被划分为数据接收端口和数据转发端口,接收核心根据配置表的信息获取接收端口的端口号,并循环扫描端口接收数据.流分配表用于AI数据流的分配,转发核心通过查询配置表中的转发端口的端口号并根据流分配表信息将数据发送到对应的计算节点完成任务计算.

图3 数据收发及任务调度示意图
系统维护一个或多个循环AI数据流缓冲区,缓冲区的数量随AI数据流的变化动态调整.循环AI数据流缓冲区用于将AI数据流按处理周期进行缓存,每一行的数据属于同一个ptime.DPDK使用内存池对数据进行管理,在收到数据后,接收核心首先从内存池中申请mbuf对象,完成对数据的封装之后,根据数据包的标识符及处理周期将数据包缓存到写指针pWrite对应的缓存行中,即每一行对应为处理周期相同的并发AI数据流PAS.完成数据的缓存后维护转发表,转发表与循环AI数据流缓冲表一一对应,对应缓冲区满后,转发表将对应位置标记为满并记录每一小块所缓存的数据包的数量.
转发核心与循环AI数据流缓冲区绑定,随数据量的变化而唤醒/休眠,负责数据的转发.发送指针pSend指向缓冲区中当前需要发送的并发AI数据流PAS,转发核心查询转发表,将准备好的数据根据配置表信息进行转发,完成数据的转发后,释放内存空间,同时更新转发表.
任务调度模块负责系统的任务调度,根据分析信息判断是否需要更新缓冲区配置表.其中,监控模块定时监控本机网络端口接入的AI数据流情况,预测下一时刻数据流的数量,实现缓冲区的动态划分.同时接收集群中其他节点定时反馈的计算能力及网络负载信息,分析可用资源情况,为数据流的分配提供最优策略.
4.2 动态多核多缓冲区模型
为了减少对共享资源的争用,提高数据处理效率,将数据流与核心进行亲和性设置,即属于同一数据流的数据包交给指定的核心去处理.其中,每个转发核心管理一个循环AI数据流缓冲区,负责转发所管理的缓冲区中的AI数据流.而多个核心之间对于转发端口的选择是根据端口的负载均衡情况动态选择的[16].系统初始化时,只有一个转发核心启动,一个缓冲区负责数据缓存,其他转发核心处于休眠状态,并随系统的状态动态唤醒.何时唤醒处于休眠状态的核心或者是让工作中的核心再次休眠需根据数据流的数量来调整.运行在主核上的调度模块会对缓冲区的情况进行监测,当监测到缓冲区中的实时数据流数量有超过缓冲区大小的趋势,即下一时刻会有大量的数据流到来,此时的缓冲区无法缓存如此大规模的数据流,调度模块会立即唤醒处于休眠状态的核心,新到来的流将进入到新唤醒的核心所对应的缓冲区中进行处理.与此对应的是,当调度模块监测到此时缓冲区中的实时数据流数量减少,且多个缓冲区中的数据流能够合并到一个缓冲区中去,此时调度程序会选择一个核心进行休眠,即减少缓冲区的数量,删除配置表中该核心对应的条目,同时将缓冲区中的数据处理完成.之前属于该缓冲区管理的数据流会作为新数据流重新缓存到其他缓冲区中.
物联网终端产生的AI数据流,其往往是具备一定周期性的、可预测的,偶尔会因设备故障形成少数异常值.Mann-Kendall检验方法不受少数异常值的干扰,同时不需要样本遵从一定的分布,能够较好的检测时间序列的变化趋势.本文采用该方法对下一周期内数据流的数量进行预测,根据预测的趋势,进行后续分析,最终实现对缓冲区的动态划分,即动态唤醒/休眠转发核心.在Mann-Kendall检验中,对于时间序列x1~xp,定义检验统计量X(公式(1)),其中sign()为符号函数,当(xi-xj)小于、等于或大于零时,sign(xi-xj)分别为-1、0、1.X为正态分布,其均值为0,方差为var(X);M-K统计量公式如式(2)所示:
(1)
(2)
在双边趋势检测中,对于给定的置信水平α,若|Z|≥Z1-α/2,则在置信水平α上,时间序列存在明显的上升或下降趋势.Z为正值表示增加趋势,负值表示减少趋势.

(3)
(4)
其中,公式(4)中ΔTi表示的是实际数据流数量相对于预测数据流数量的变化量,当ΔTi>0时,表示预测结果偏小,当ΔTi<0时,表示预测结果偏大,当ΔTi=0时,表示预测数量与实际数量相符.当预测结果偏大或偏小时,对于下一次预测,应该做一定的修正,以保证之后预测结果的准确性.引入修正因子λ,根据预测数据流增加或减少的情况以及ΔTi的值,需进行如下调整:
下一时刻数据流增加:
(5)
下一时刻数据流减少:
(6)

L′Ti+1=L′Ti+λΔ
(7)
ΔL=aN-L′Ti+1
(8)
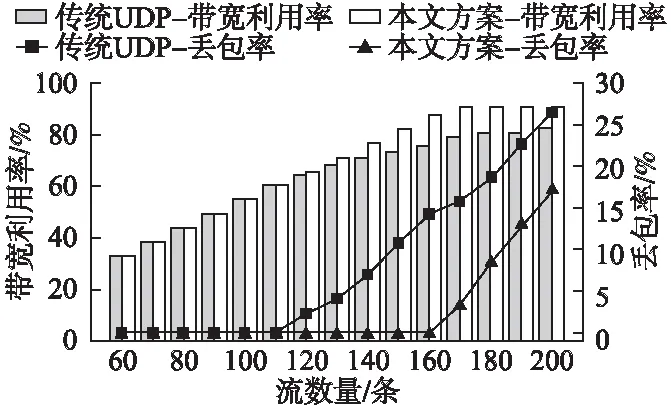
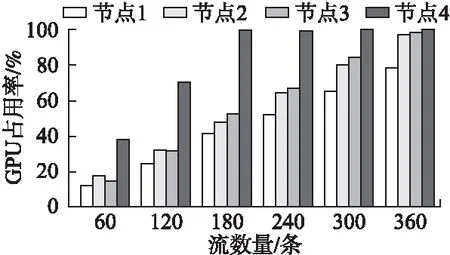
若0≤ΔL 算法1.动态多核多缓冲区算法 开始: if Z>0 由公式(5)计算λ else if Z<0 由公式(6)计算λ else Nothing to do,go to end end if 由公式(8)计算实际数据流数量与预测的差值ΔL if 0 ≤ΔL nothing to do else if ΔL≥N&&a>amin 减少缓冲区并使对应的核心休眠 else if ΔL<0 &&a 增加缓冲区并唤醒对应的核心 end if 更新配置表中缓冲区信息 结束 本文仅介绍数据流的合理分配问题,对于因计算节点故障而需将任务迁移问题由课题组其他成员负责.每个节点因所配置的硬件不同,拥有的处理能力也各异.因此,需根据每个节点的处理能力的不同合理分配数据流进行计算. 首先对计算节点的计算负载建立数学模型,计算节点用g表示,m表示GPU集群中计算节点的数量,GPU集群中计算节点所属集合为G={g1,g2,…,gm}.Vg是计算节点g的最大计算能力,终端设备处理后得到的AI数据流大小为y(单位:Byte),单位时间内计算节点处理单个数据流所耗计算资源为f,则由公式(9)可计算出单位时间内计算节点g能处理的最大数据流数量SVg. (9) 当前待发送的并发数据流PAS中有S条数据流,计算节点g当前的计算能力为Cg,可用网络带宽为anbg,由公式(10)可计算出g在该计算能力下能够处理的数据流数量SCg,集群中所有计算节点当前总的计算能力为SCG,由公式(11)计算出网络带宽允许下g能接收的最大数据流数量Sanbg.综合考虑可用带宽和计算节点当前计算能力两个因素,则计算节点g当前实际能接收的数据流数量SRg为SCg和Sanbg两者中的最小值.为了合理分配数据流,根据公式(14)计算出节点g可计算的数据流数量在集群G中所占权重βg,之后由公式(15)计算出计算节点g实际分配的流数量Sg. (10) (11) (12) SRg=min{SCg,Sanbg} (13) (14) Sg=βgS (15) 如果数据流数量保持不变,则配置表不更新,否则根据模型分析结果更新配置表,将数据流按配置表信息转发到计算节点. 算法2.AI数据流分配调度算法 开始: 由公式(9)-公式(12)计算SVg、SCg、Sanbg、SCG for each g in G if S stays the same 根据当前配置表进行转发 else SRg=min{SCg,Sanbg} 由公式(14)、公式(15)计算节点g需分配的数据流数量Sg end if end for 更新配置表 数据流分配完成,选择端口转发 结束 为了验证所提出方案的性能,我们使用11台普通服务器模拟大规模并发AI数据流的产生,其中,每台服务器可以同时模拟多个终端设备.另外,使用安装有GPU的计算节点搭建边缘GPU集群,集群中计算节点数量可以根据实际应用场景中终端设备数量的变化来进行调整.实验环境中,我们使用4台计算节点搭建了边缘GPU集群,每台节点配置了两张4口千兆网卡,4台计算节点的处理能力各异,服务器的详细配置信息如表1所示. 表1 服务器配置信息 在对系统进行评估时,选取丢包率、带宽利用率、任务丢弃率以及CPU负载来对整个系统的性能进行评估. 丢包率是指网络传输过程中丢弃的数据包数量Npkt_loss占数据包总量Npkt_total的比例,用于评估网络性能. (16) 带宽利用率指的是单位时间内网口的收发包速率Vpkt与带宽BW的百分比,反映了网络带宽的利用情况. (17) 任务丢弃率反映的是整个系统的性能,任务丢弃率包括数据因转发不及时造成缓冲区中数据覆盖导致的任务丢弃,以及在进行计算时,因计算不及时而丢弃的任务占总任务的比例. (18) 本文所述系统应用在了社区养老照护场景中,搭建的边缘GPU集群用于满足社区养老机构终端设备所产生的AI数据流的传输及实时计算分析.部署在用户侧的终端设备周期地采集视频图像信息,经预处理后得到大小为672KB的AI数据流,将该消息封装成若干个大小为750B的切片,发往边缘GPU集群完成后续的处理,如人体姿态检测判断老人是否摔倒等. 首先对系统网络传输性能进行测试,考虑到本文未实现可靠传输,因此选择传统UDP通信进行实验对比.在单张网卡单端口接收数据情况下,利用数据发送服务器模拟大规模AI数据流的并发发送,逐渐增加AI数据流的数量,统计两种方案的丢包率及带宽利用率. 如图4所示,折线图为单端口接收数据情况下,传统UDP通信方案与本文通信方案的丢包率对比.可以看到,随着AI数据流数量的增加,两种通信方案都出现了一定的丢包现象.当AI数据流数量超过110时,传统UDP方式开始丢包,而本文通信方案在AI数据流数量超过160时才出现丢包.与传统UDP通信相比,在无数据丢失的情况下,本文的通信方案有约30%数据量提升.柱状图表示的是随着AI数据流数量的增加,网卡带宽利用率的情况.得益于DPDK高效的数据包处理能力及用户态驱动特性,本文通信方案的带宽利用率最终稳定在90%左右,相比传统UDP通信最高82%的带宽利用率,能够更好地使用网卡资源,通过多张网卡的叠加,可以最大程度的提升网络吞吐量. 图4 丢包率和带宽利用率 GPU集群中各计算节点的处理能力因搭载的硬件不同而存在差异.实验所使用的4台计算节点组成的边缘集群分别使用了不同的GPU组合.对于节点处理能力各异的GPU集群,采用数据流平均分配的方式将数据交给GPU进行计算,会导致计算节点的“饥饿”或“过饱”现象.如图5所示,将数据流平均分配给集群中的所有计算节点,其中,节点4由于处理能力受限,短时间内GPU的数据处理能力达到极限,处于“过饱”状态,而此时其他节点仍有处理更多数据的能力,处于“饥饿”状态.此方案中,由于处理能力较弱的节点来不及处理更多的任务,会造成大量的任务丢弃,影响分析结果. 图5 节点GPU占用率-平均分配数据流 如图6所示,在加入数据流分配策略后,调度模块根据计算节点实时反馈的计算能力和网络负载情况来分配AI数据流,可以看到,GPU集群中各计算节点GPU占用情况几乎相同,达到了一个负载均衡的状态.在可处理能力范围内,计算节点未出现“过饱”现象,有效避免了大规模任务丢弃情况的发生. 图6 节点GPU占用率-根据节点负载分配数据流 在对AI数据流的转发中,将转发任务与核心进行绑定,每个核心负责一个缓冲区中数据的转发,对于未能及时转发出去的任务,系统作丢弃处理.图7、图8分别是在单核单缓冲区和三核三缓冲区情况下的实验结果,分析两图可以看出,随着AI数据流数量的增加,单核单缓冲区的情况下,转发性能很快达到极限,出现了大量任务丢弃现象.而在三核三缓冲区情况下,由于核心的增加,系统转发效率也大大增强,在前期,任务丢弃率几乎为零. 图7 任务丢弃率及cpu负载-单核单缓冲区 观察图7和图8的CPU负载曲线和活动转发核心数量变化,发现活动转发核心数量一直未发生变化,且CPU负载均维持在特定的值附近,但图8中的CPU负载处于较高水平.这是因为在多核多缓冲区情况下,所有转发线程一旦开始工作,转发线程会不断轮询缓冲区完成数据转发,当数据量较少时,此时核心处于“空转”状态,CPU负载仍然过高. 图8 任务丢弃率及cpu负载-三核三缓冲区 终端设备在社区部署中,以家庭为单位增长,随着终端设备的逐渐增加,处理周期内单核心最大能转发的AI数据流数量会达到极限,图7、图8实验结果显示,对于单核心来说,最大能转发的AI数据流数量不超过180条.同时,为了避免CPU核心满负载情况下对数据处理的影响,除主核及负责数据接收的核心外,不占用剩余全部核心进行数据转发.经过前期测试,确定了如表2所示的主要参数值. 表2 实验参数 如图9所示,调度模块根据实时AI数据流的变化,动态划分缓冲区,让暂时不工作的转发核心处于休眠状态,当AI数据流增加时,再将处于休眠状态的转发核心唤醒.从图中可以看到,由于系统根据任务量动态调度转发核心进行工作,在系统容量范围内,几乎不会出现任务大规模丢弃的现象.同时,在AI数据流较少的情况下,大部分转发核心处于休眠状态,CPU未出现长期高负载状态. 图9 动态划分模型下任务丢弃率及CPU负载 本文针对并发AI数据流场景下的边缘GPU集群内快速数据传输的需求,在多核多网卡基础上利用DPDK高性能包处理特性,设计实现了面向AI数据流处理的边缘GPU集群高效通信系统.在实现快速数据传输的基础上,动态调度转发核心完成数据的转发,避免了核心无数据转发下的“空转”情况的发生,进一步降低了系统能耗.同时通过实时监控集群中节点的计算能力和网络负载,分析计算节点的实时处理能力,分配与处理能力相适应的任务量,在整体上减少完成计算所需要的等待时间,提高了集群计算效率. 本文设计方案通过构建高性能价格比的边缘GPU集群架构,可以有效应对局部大规模高并发AI数据流的传输和实时计算分析的挑战,部署成本低且易于扩展,具有实际意义.接下来的工作将继续对集群功耗、系统可靠性等方面做进一步的探讨和研究.

4.3 AI数据流分配调度模型
5 实验测试及评估
5.1 实验环境

5.2 评估指标
5.3 实验过程与分析





6 结 语
