基于POI-K-means地铁车站聚类方法研究
2022-05-27赵源,王越,胡华
赵 源,王 越,胡 华
(1同济大学 道路与交通工程教育部重点实验室,上海 201804;2上海轨道交通运营管理中心,上海 200070;3上海工程技术大学 城市轨道交通学院,上海 201620)
0 引 言
随着城市轨道交通的快速发展,车站的数量也在迅速增长,截止2020年底,全国轨道交通累计投运车站共计4 681座,不同类型的车站客流特征不同,管理方式不同。也有些研究要基于车站的分类,例如在研究客流时间分布特征时需要将车站准确分类才能总结出不同类型车站的客流系数。因此研究车站分类以及建立车站分类模型可以为客流特征研究与预测、地铁车站管理以及周边土地开发提供依据。
马壮林等人采用主成分分析(PCA)方法对轨道交通进出站客流进行特征提取,采用Hopkins统计量分析聚类趋势并探讨聚类数量确定方法,采用CH系数、轮廓系数和DB指标对比分析高斯混合模型(GMM)和K-means聚类的优劣,目前大多数分类方法包括:按车站所处的城市位置,分为都市中心站、交通枢纽站等;按场所导向型标准,分为城市外围区、成熟居住区等;按功能导向型标准,分为起点站、换乘站、终点站等;按运营性质,分为中间站、区域站;按车站交通重要性,分为二线换乘、三线换乘等。既有分类方法稍显简单,标准较单一,可能导致一个车站属于多个类别的情况。
为了得到车站的精细化分类,本文总结了影响车站分类的因素:车站自身属性,即是否为起/终点站或者是几线换乘站、客流特征,即早晚高峰时段5 min粒度客流占全天客流的比重、POI特性,即地铁车站800 m范围内土地利用情况。构建了POI-Kmeans车站聚类模型并将上海14条线、共计416座车站,分为6类,验证了模型的实用性。
1 车站分类影响因素
1.1 车站属性
车站是轨道交通线网的重要节点,由于在线路中的位置不同,功能不同,所以在确定车站属性类聚类指标时,选取了起点站、终点站、非换乘站、二线换乘站、三线换乘站、四线换乘站5个指标,输入数值为0,1型,是为1,否为0。详见表1。

表1 车站属性聚类指标Tab.1 Stations attribute clustering index
1.2 车站客流特征
相比道路流量、公交客流量,城市轨道交通客流量有很大的不同,由于城市轨道交通有着固定的发车间隔与营业时间,使得其统计的客流量在不同时间粒度(如5 min、15 min、30 min、60 min)都可以显示出客流本质特征,要使车站做到精细化的分类,所以选择5 min时间粒度,而在全天客流中早晚高峰最具代表性,为了使指标更能代表客流趋势,这里将5 min客流与当天进站或者出站总客流的比值作为聚类客流特征指标,其中包括早晚高峰各2 h进出站客流各48个、共96个指标,见表2。
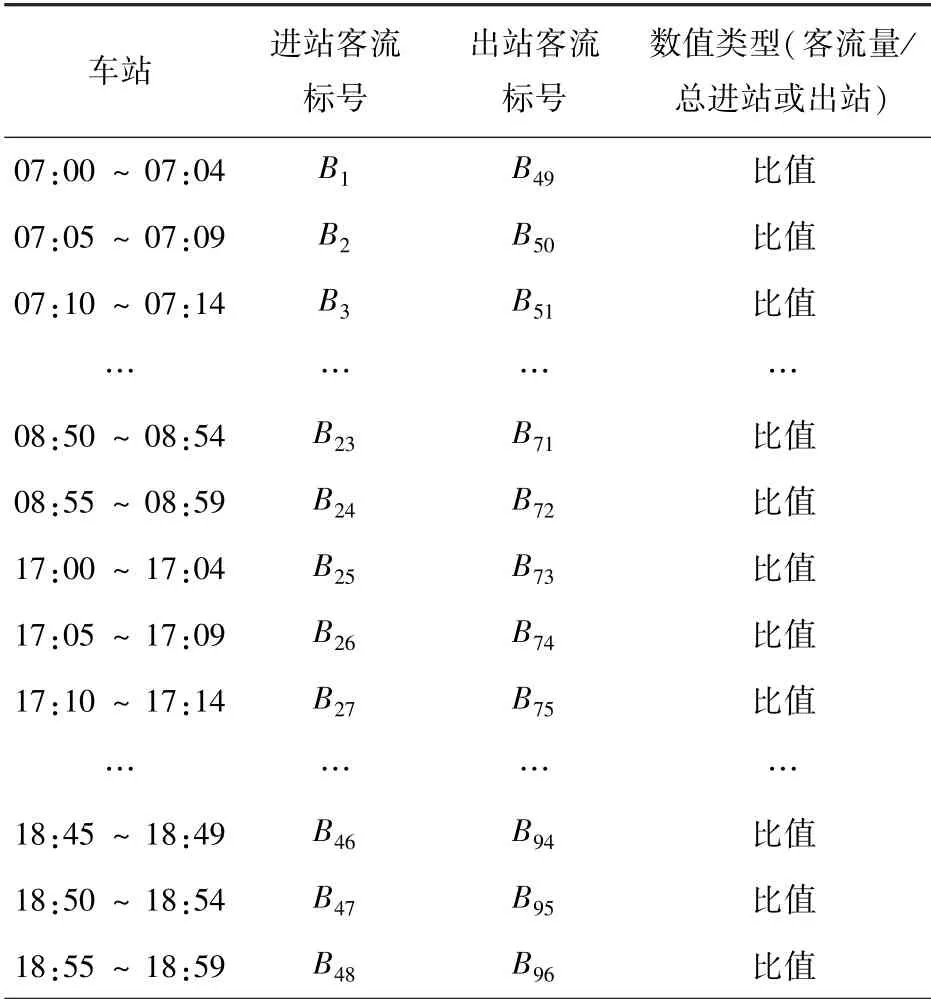
表2 客流特征指标Tab.2 Passenger flow characteristic index
1.3 车站客流吸引范围内POI
POI(一般作为Point of Interest的缩写,也有Point of Information的说法),通常称作兴趣点,泛指互联网电子地图中的点类数据,POI数据目前可通过高德地图或者百度地图等方式获取,主要包含名称、地址、坐标、类别四个属性;源于基础测绘成果、即数字线划地图(Digital Line Graphic,DLG)产品中点类地图要素矢量数据集;在地理信息系统(Geographic Information System,GIS)中指可以抽象成点进行管理、分析和计算的对象。通常情况下,POI分类一共有3级,但是对于分类的个数大同小异。高德地图针对全上海的POI分类中,一级分类有23个,二级分类有267个,三级分类有869个。研究中给出部分POI分类见表3。具体的餐饮类别POI数据见表4。表4中包含了经纬度等重要信息。

表3 POI分类Tab.3 POI classification

表4 车站POI指标Tab.4 Stations POI indicators
为了更好地统计地铁车站附近POI数量,故划分一定范围,对于站点吸引范围,学者认为根据实际情况取400 m到800 m之间,目前应用较为广泛的是800 m,以800 m为半径画圆为地铁车站的缓冲区域,统计缓冲区内各类POI数据的个数作为车站分类的POI指标。
在确定POI分类指标时,选取对地铁车站影响较大的兴趣点作为车站分类的指标,并且将个别POI分类进行了整合或拆分,例如将汽车服务、汽车维修、汽车销售、摩托车服务统一为汽车服务,将“事件活动”、“地名地址信息”、“室内设施”、“道路附属设施”对车站无影响的类别不纳入指标选取中。由表4可知,车站附近POI数据指标共16个。
2 K-means算法
2.1 算法原理
K-means聚类算法是由Steinhaus(1955年)、Lloyd(1957年)、Ball&Hall(1965年)、McQueen(1967年)分别在各自不同的科学研究领域独立地探讨提出的。K-means算法、也称作快速聚类法,是一种非监督的聚类算法。对于给定的样本集,按照样本之间的距离大小,将样本集划分为个簇。让簇内的点尽量紧密地连在一起,而让簇间的距离尽量地大。如果用数据表达式表示,假设簇划分为(,,…,C),那么最小化平方误差可用如下公式计算求出:

其中,μ是簇C均值向量,有时也称为质心,表达式如下所示:

聚类过程示例如图1所示。图1(a)表达了初始的数据集,假设2。图1(b)中,随机选择了2个类所对应的类别质心,即图中的红色质心和蓝色质心,并分别求取样本中所有点到这2个质心的距离,再标记每个样本的类别为和该样本距离最小的质心的类别,见图1(c),经过计算样本和红色质心与蓝色质心的距离,得到了所有样本点的第一轮迭代后的类别。此时标记为红色和蓝色的点分别求其新的质心,见图1(d),新的红色质心和蓝色质心的位置已经发生了变动。图1(e)和图1(f)重复了图1(c)和图1(d)的过程,即将所有点的类别标记为距离最近的质心的类别并求得新的质心。最终得到的2个类别见图1(f)。
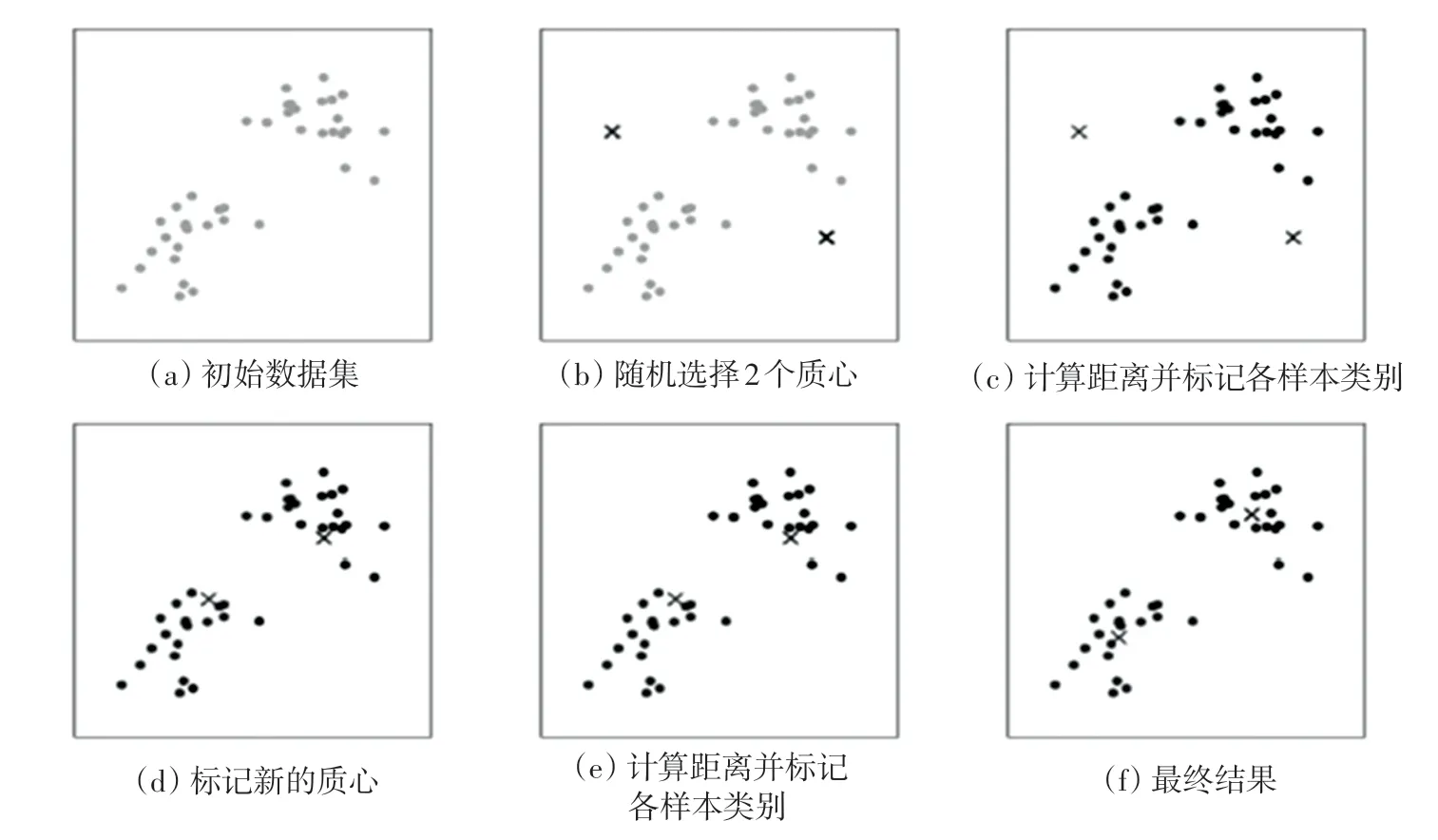
图1 聚类过程示例Fig.1 An example of clustering process
总地来说,K-means算法步骤为:
选择个聚类的初始中心。
对任意一个样本点,求其到个聚类中心的距离,将样本点归类到距离最小的中心的聚类,如此迭代次。
每次迭代过程中,利用均值等方法更新各个聚类的中心点(质心)。
对个聚类中心,利用Step2、Step3迭代更新后,如果位置点变化很小(可以设置阈值),可判定为达到了稳定状态,迭代结束。对不同的聚类块和聚类中心可选择不同的颜色标注。
2.2 基于POI-K-means地铁车站聚类模型
在分类过程中,最主要的是对分类指标的选取,本研究分类指标共包含3个部分,分别是:车站属性指标、车站客流特征指标以及车站附近POI数据指标。
在选取完车站聚类指标后,形成的初始矩阵见表5。由于指标数值的类型和单位不同,而且数值差距过大,故将矩阵归一化,归一化方法对K-means聚类的有效性也通过各种数值实验证明,基本上是Z-Score、Min-Max和小数缩放方法。实验分析表明,Z-Score在3个归一化过程中表现良好,准确度更高,因此该方法减少了迭代次数。所以本模型使用Z-Score标准化,将变量统一转化为同一个量级,可以将数据有效地转换为统一的标准,Z-Score的数学公式可写为:
表5 车站初始矩阵Tab.5 Stations initial matrix

其中,为总体数据的均值;为总体数据的标准差;为个体的观测值。
Z-Score最突出的优点就是简单,容易计算,能够应用于数值型的数据,并且不受数据量级的影响,因为其作用就是消除量级给分析带来的不便。但是需要指出的是,Z-Score本身没有实际意义,具体的现实意义需要在比较中得以实现,这也是Z-Score的缺点之一。
手肘法是一种利用和值的关系图确认最优值的方式,还可以替换为样本点到聚类中心欧式距离平均值,本文选用利用手肘法确定最佳值。在K-means算法中,最主要的步骤就是确定值,每一步都可以计算出值、又称为。值的计算方式就是每个聚类的点到其质心的距离的平方,如式(4)所示:

指定一个值,即可能的最大类簇数。然后将类簇数从1开始递增,一直到,计算出个。根据数据的潜在模式,当设定的类簇数不断逼近真实类簇数时,呈现快速下降态势,而当设定类簇数超过真实类簇数时,也会继续下降,但下降会迅速趋于缓慢。通过画出曲线,找出下降途中的拐点,即可较好地确定值。
利用Python编程实现确定值与分类的部分,总的分类模型如图2所示。
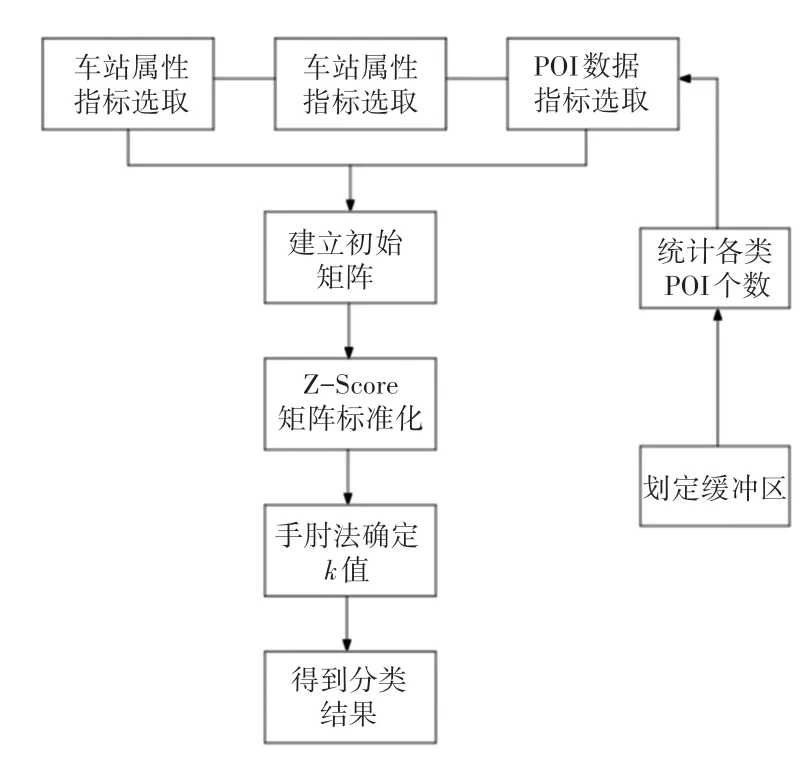
图2 分类流程图Fig.2 Classification flow chart
3 实例验证
3.1 上海地铁车站分类
上海城市轨道交通线网截止2020年底共有运营车站430座,本次研究选取运营时间较长的416座,其中包括1号线、2号线、3号线、4号线、5号线、6号线、7号线、8号线、9号线、10号线、11号线、12号线、16号线、17号线。
基于AFC数据、上海POI数据,分别确定车站属性、车站附近POI数据、早晚高峰客流特征三类指标进行聚类,如图3所示,利用手肘法得到最佳值,在6时出现明显的拐点,所以将上海地铁车站分为6类,聚类结果见表6。
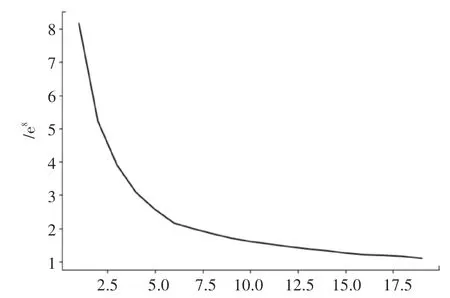
图3 上海地铁车站分类k值手肘图Fig.3 The elbow diagram of the k-value of Shanghai subway stations classification

表6 K-means聚类结果Tab.6 K-means clustering results
3.2 各类车站特征分析
根据统计每个类别POI个数,分析其土地利用特点以及客流特征,得到以下类型描述。
(1)商务型:地铁车站周边用主要有办公楼、密集的公司、少量的住宅和商户,地面大部分建筑为高层办公楼,土地开发强度高,土地利用率高,高峰时期的交通较为复杂,接驳方式众多,POI类别中商务写字楼占比最多。
(2)休闲旅游型:地铁车站周边多为景区、音乐厅、体育场、公园等公共场所及建筑,这种类型涉及土地范围稍广,往往换乘线路比较多,配套商业也较多,土地开发率也相对较高,在节假日客流较多,POI中餐饮服务、购物服务占比较多。
(3)居住型:地铁车站周边多为住宅,商业用地较少且开发程度已经完成,功能比较单一,早晚高峰客流特征明显,接驳方式多以公交、单车为主。
(4)交通枢纽型:地铁车站以大型客运站、火车站、高铁站、机场为主,该类型往往对地上、地下空间利用范围较广,有一些配套的商业,客流量也较大,接驳方式最为全面,从POI占比看交通设施服务类占比最大。
(5)活动型:地铁车站周围以大型场馆为主,在活动期间客流骤增,周边场地大,可容纳大量客流,接驳方式主要为地铁、出租。
(6)混合型:地铁车站周边土地利用复杂,多为住宅及学校、办公,商业用地较多且开发程度较高,潮汐客流特征明显,接驳方式众多,POI类别中生活服务类占比较多。
4 结束语
本文为了得到车站精细化分类,总结了影响车站分类的因素:车站自身属性,即是否为起终点站或者是几线换乘站、客流特征,即早晚高峰时段5 min粒度客流占全天客流的比重、POI特性,即地铁车站800 m范围内土地利用情况。构建了POI-K-means车站聚类模型,并将上海14条线、共计416座车站,分为6类,验证了模型的实用性。
