基于铆钉表面缺陷检测的语义分割网络研究
2022-05-27覃志东肖芳雄
赵 娜,覃志东,蔡 勇,肖芳雄
(1东华大学 计算机科学与技术学院,上海 201620;2上海岳展精密科技有限公司,上海 201614;3金陵科技学院 软件工程学院,南京 211169)
0 引 言
铆钉作为一种紧固件,被广泛用于航空、船舶、武器装备等安全关键行业。为杜绝铆钉缺陷所致安全隐患,铆钉缺陷检测是生产加工过程中必不可少的一环。目前,大多数缺陷检测方案是基于传统机器视觉技术的。如周永洪等人采用阈值法去除噪音对检测的影响,借助最小二乘法进行边缘拟合,来提高铆钉缺陷检测的精度。刘春辉等人采用了Blob算法、金字塔匹配等基于图像的缺陷判别方法来检测铆钉缺陷。但是,由于受生产环境的干扰,人工提取到的缺陷特征往往不能完全表达缺陷的特性。所以,铆钉表面缺陷具有难以量化的特点,使得基于规则的传统机器视觉检测方案效能不佳。
而基于深度学习的缺陷检测技术利用卷积神经网络针对原始输入图像,逐层抽取底层特征最终得到抽象的高级语义,提取到的特征更加合理,避免了人工提取特征且特征模型后续难以使用的问题。深度学习的发展为产品表面缺陷检测提供了新的思路和替代方案。
考虑到产业界只对铆钉是否存在缺陷、缺陷位置和所占像素进行识别,而不关注其所属类别,因此本文将铆钉缺陷检测问题定位为机器视觉中的语义分割问题。FCN网络是一种典型的语义分割网络,是将来自浅层的语义信息与深层的语义信息融合,以产生更为准确的分割结果。
FCN虽然实现了端到端的卷积网络,但是其卷积过程仍然丢失了很多细节信息,分割精度有待提高。此外,FCN缺乏空间一致性,分类过程是对独立的像素进行的,忽略了像素之间的关系。因此本文采用了另外一种解码效果更好,更注重保留细节信息的语义分割网络U-net。U-net是2015年被提出用来解决医学中图像分割问题,由于其出色的分割结果,现已广泛应用到不同的语义分割任务中。2018年,针对U-net网络中跳跃连接仅在编码器和解码器的相同比例特征图上进行强制融合以及编解码结构的深度因数据集而异的问题,Zhou等人对U-net原始网络进行了改进,提出了U-net++。Unet++对固定深度的U-net进行改进,引入了一个内置的深度可变的U-net集合,并重新设计了跳跃连接方式,去除了U-net需要相同比例特征图进行融合的限制。本文将U-net++作为基础网络,结合铆钉缺陷特点进行改进得到新网络U-net++,用于铆钉表面缺陷检测。
1 U-net++网络介绍
为了更好地介绍U-net++网络的结构,首先简单介绍一下原始的U-net网络。U-net是经典的利用全卷积网络进行语义分割的算法,整体网络结构呈现一个“U”型结构,左侧部分是网络的编码阶段,右侧是解码部分,如图1所示。灰色矩形框代表的是网络提取的特征图,在编码阶段,每进行一次下采样,特征图尺寸都会减半,通道数加倍;目的是增加图像抗干扰的能力,降低过拟合的风险,减少运算量。在解码阶段是为了将特征图还原至原始图像大小。在进行上采样前,网络先将特征图与编码阶段生成的相同比例的特征图进行融合,用来增加浅层网络提取的细节信息。融合的方式是通过跳跃连接实现的。将编码器阶段的局部的细节特征与解码器阶段全局的抽象特征进行融合,使得网络更加有效地抓取目标的细节特征。
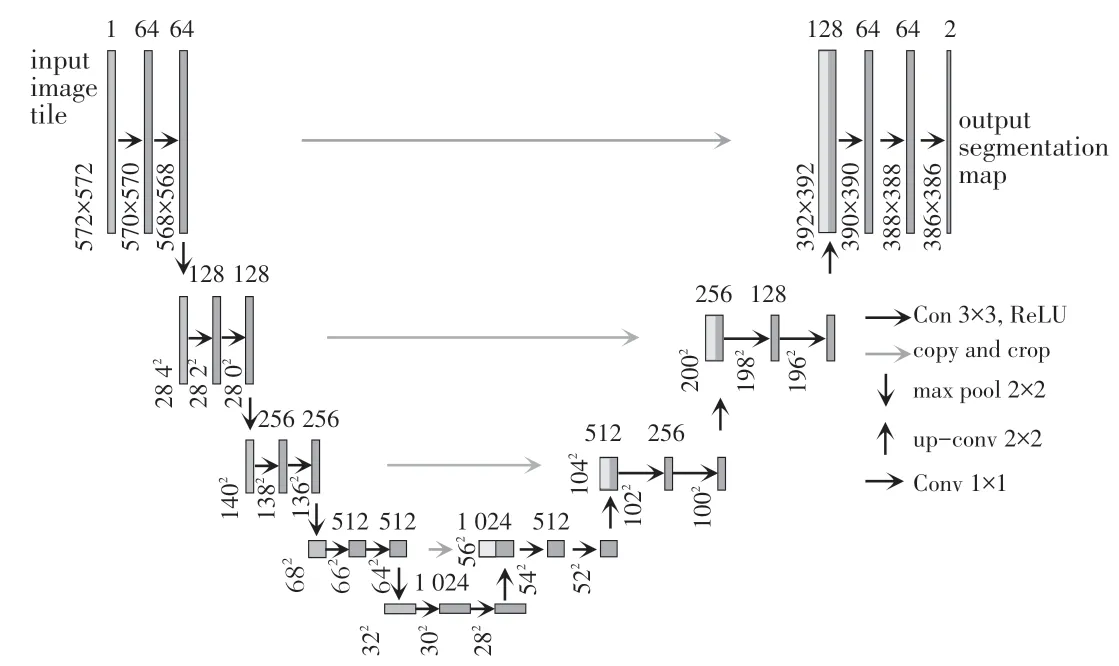
图1 U-net网络结构Fig.1 Network structure of U-net
U-net++网络是U-net网络的改进版,在整体设计上还是遵循编解码的“U”型结构,如图2所示。U-net++与U-net原始网络相比,相当于把不同深度的U-net进行了拼接,让网络自主学习,极大地丰富了解码过程。为了解决单纯的拼接导致U-net网络会存在中间隐藏层的输出没有与最终的输出相连接,造成网络计算的损失无法通过反向传播的方式更新中间隐藏层权重的问题,在保留原始长链接的同时,为中间隐藏层每个卷积之间都增加了短链接。长连接和短链接共同作用于网络,使得解码阶段特征融合得更加灵活,还有助于还原下采样带来的信息损失。除此之外,网络还引入了深监督(Deep Supervision),为每一个隐藏层的输出增加了1*1的卷积,来监督中间层的输出结果,不仅进一步解决了中间隐藏层无法训练的问题,还加快了网络的收敛速度。
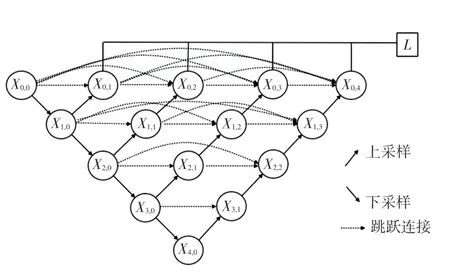
图2 U-net++网络结构Fig.2 U-net++network structure
2 改进的缺陷检测模型U-net++*
U-net++原始网络是针对医学图像中的细胞分割,虽然在医学图像上取得了很好的分割效果,但是由于本文铆钉缺陷与医学细胞特征的差异性,使得原始网络并不能完全适合本文的检测对象。因此本节从铆钉表面缺陷特点出发,分析U-net++网络结构并对其改进得到用于缺陷检测的模型U-net++。
2.1 U-net++网络结构的改进
在深度学习网络中,浅层网络是用来提取一些具体的、局部的特征信息,随着网络层次的加深,所提取到的特征逐渐变得复杂。针对本文铆钉缺陷数据集而言,缺陷特征多为局部特征,语义层次较低,感受野不宜过大。因此铆钉表面缺陷检测网络不需要设计得过深。其次,网络越深,网络参数会呈现直线上升趋势,因此采用合理的网络结构是保证缺陷检测精度和效率的关键。
为了确定更适合铆钉缺陷的网络深度,本文基于U-net++设计了1~4层的网络结构,并在本文数据集上进行了对比试验,实验结果如图3所示,其中圆圈、矩形、三角形、五角星分别表示1~4层的网络。随着网络深度的增加,和推理时间都有增加的趋势。但是4层的网络结构相比于3层网络结构,提升0.3个百分点。推理时间需要多消耗19.6个百分点,可见用时间消耗大幅增加换来精度的微弱提升是不值得的,因此本文对原始网络进行剪枝,采用3层下采样的网络结构,如图4所示。
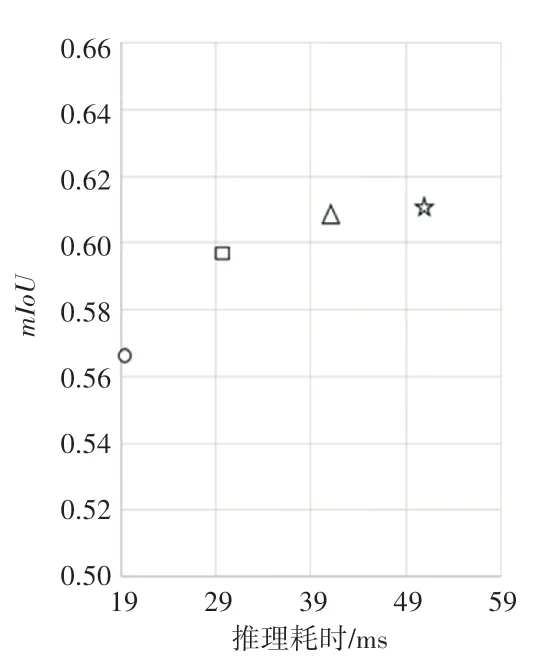
图3 不同深度网络对比图Fig.3 Comparison of networks with different depth
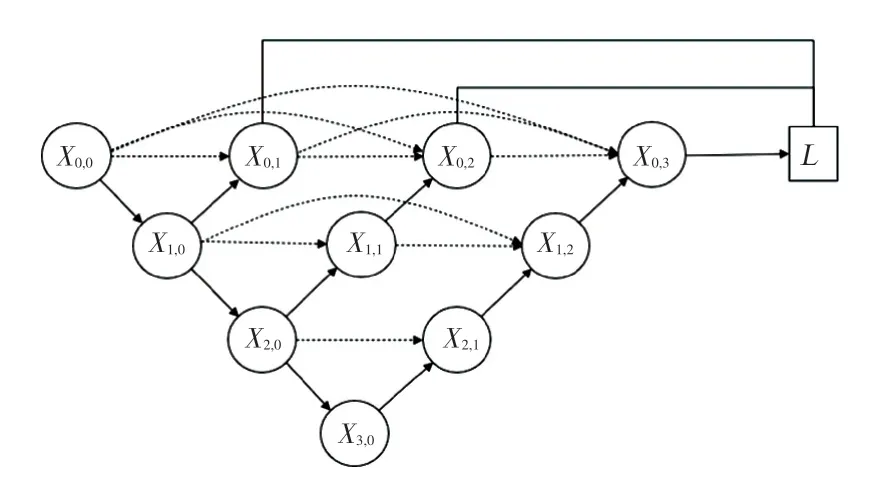
图4 剪枝后的网络结构Fig.4 Network structure after pruning
网络的整体结构还是遵循典型的全卷积网络结构,编码阶段由3部分组成,每一部分包含2个3*3的卷积,每个卷积后有一个激活函数和一个最大池化层。其中,卷积采用same卷积。避免了在解码阶段时为了使不同尺寸的特征图进行融合而采用的裁剪步骤。解码阶段由6个基本单元组成,每一部分包含一个2*2的反卷积对特征图尺寸进行加倍,2个3*3的卷积加一个激活函数,最后通过一个1*1的卷积映射到二分类进行输出。
2.2 数据增强
工业中缺陷数据集的收集比较困难,而且铆钉的缺陷种类繁多,形状各异,缺陷标注的工作量非常大,标注过程中往往需要根据公司需求反复确认修改标注。因此本文最终共标注了300张缺陷图像。为了在小数据集上训练得到一个较好的模型,避免训练过程的过拟合现象,本文除了使用常规的水平翻转、垂直翻转等数据增强方式外,还针对铆钉缺陷的特点设计了模糊标签的数据增强方式。
工业环境中缺陷产生的随机性导致缺陷并没有一个标准的形状,对于那些位于缺陷中心的像素可以很明确地认为是缺陷像素,但是对于缺陷边界处的像素就难以界定。同时,本文的缺陷检测是像素级别的检测,每个像素的标签值对网络的学习结果影响较大。为此,本文提出了模糊标签的解决方案,即在缺陷边缘区域像素的标签值不仅局限于是缺陷、或不是缺陷这种非0即1的情况,而是通过一个较好的方式根据缺陷边缘像素不确定的程度赋予一个对应的标签权重。本文中标签模糊化是通过一个3*3的均值滤波来处理的。均值滤波处理思路比较简单,即将这个3*3大小窗口内的像素根据式(1)来计算平均值:

此后,将窗口计算得到的均值设置为锚点上的像素值。均值滤波有个明显的特点,就是通过计算均值的方式会使边缘信息模糊掉,而本文正是基于此而将原本标签边界0到255的跳变通过均值滤波处理成连续的像素值。
2.3 损失函数改进
原始网络是针对医学图像细胞的分割,针对细胞之间相互接触问题引入了带权重的交叉熵损失函数,使得越靠近边缘的像素权重越大,从而使网络更好地学习边缘信息。对于语义分割这种二分类的情况,模型最终只需要输出2种结果,交叉熵损失函数非常适合这种二分类问题。假设每个类别中预测的概率为和1,那么交叉熵损失函数可以写成式(2)的形式:
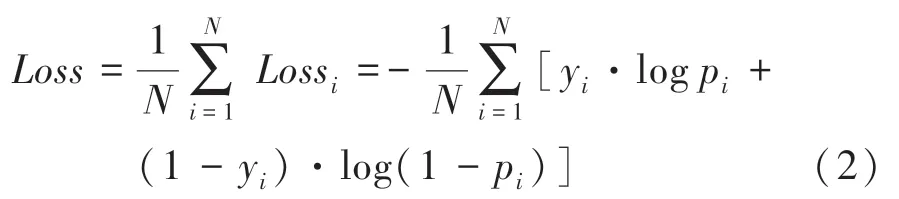
其中,y表示样本的标签,前景为1,背景为0;p表示样本预测为正类的概率,在这里是归一化后的概率值。由于本文采用模糊标签增强数据,所以就需要进行归一化处理,本文选择了更适合二分类的激活函数如式(3)所示:
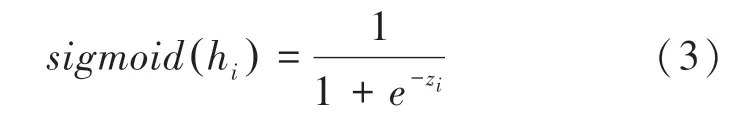
但单一交叉熵损失函数在本文数据集中存在收敛速度较慢的问题。原因在于本文数据集中的缺陷形状大小差别较大,有很多缺陷、如碰伤,所占像素面积很小,但是深度较深仍需要检出,加上交叉熵损失函数的竞争机制,使得损失函数关注于正确标签预测概率的准确性。如果网络把所有的样本都视为无缺陷样本,准确率也可以达到一个很高的结果,因此若只是用交叉熵损失函数,网络训练前期将长时间学习不到缺陷样本。为了提高网络的收敛速度,本文引入了损失函数。即交并比,可以很好反映出预测区域和真实区域的预测效果。即交集与并集的比值。值越大,说明预测值与真实值越接近,损失函数值应该越小。损失函数的定义如式(4)所示:

其中,表示预测的像素区域;表示标注的像素区域。本文采用交叉熵损失函数和损失函数相结合的复合损失函数方式,可以有效加快网络的收敛速度。
3 实验结果
3.1 公开数据集上对比试验
鉴于本文所使用的铆钉表面缺陷数据集是未公开数据集,为了证明本文网络模型改进方案的合理性和有效性,故在公开数据集Kolektor对本文网络模型与其它算法进行对比实验。Kolektor是由Kolektor Group提供和标注的电子换向器表面缺陷数据集。图像数据在电子换向器8个不重叠的表面进行采集,共采集了50个有缺陷的电子换向器。在采集过程中保证一个缺陷仅在一张图像中可见。数据集共采集399张图像。其中有缺陷图像52张,无缺陷图像347张,每张图像分辨率为500*1 263。为了适应本文网络训练,图片分辨率被调整为480*1 248。在该公开数据集上评估了语义分割算法Unet、DeepLabv3+以及文献[9]提出的改进算法SqueezeNet,与本文模型U-net++的数据对比结果如图5所示。
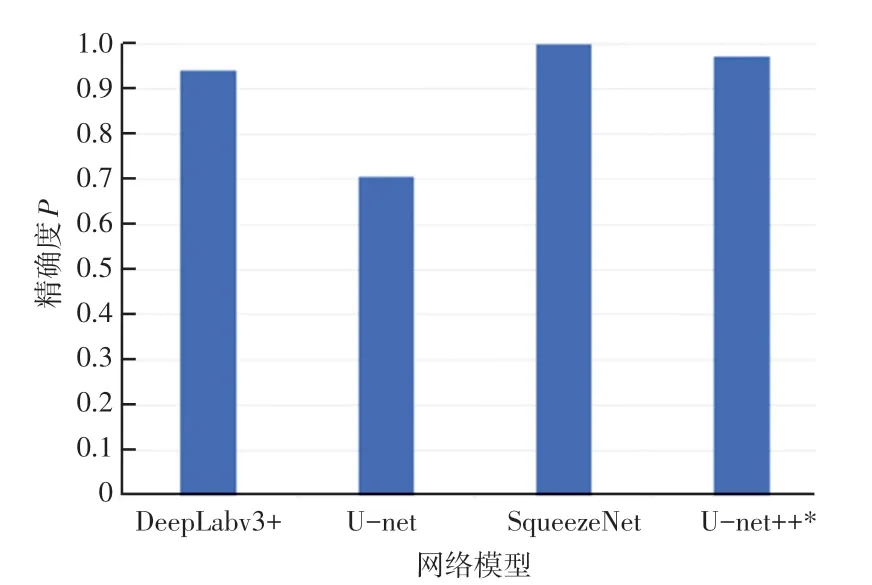
图5 网络模型精确度对比柱状图Fig.5 Accuracy comparison histogram of network models
从图5可以看出,文献[9]采用的网络模型SqueezeNet精确度最高,但是其网络模型并未对图像进行全分辨率的像素级别的分割,输出图像的分辨率降低了8倍,而本文网络模型输出结果是原比例输出,仅比SqueezeNet低了1.8个百分点。此外,本文算法模型在该公开数据集上将缺陷样本识别为无缺陷样本的概率降至0,其它对比算法中仍存在将缺陷样本推理为无缺陷样本的情况。
图6是本文网络模型在Kolektor上的预测部分结果展示,图6(a)是人工标注结果,图6(b)是本文模型推理结果。图6(c)是人工标注结果的对应放大图,图6(d)是本文算法推理结果的对应放大图。该结果直观表明了本文网络模型在Kolektor数据集上仍有较好的表现。

图6 U-net++*模型在Kolektor上的预测结果Fig.6 Prediction results of the model U-net++*on Kolektor
3.2 损失函数的改进实验
为了验证损失函数,与交叉熵损失函数构成复合损失共同作用于网络的训练过程,与只使用单一的交叉熵损失函数的网络模型相比,可以加快模型拟合的速度。本文设计了单一交叉熵损失函数和复合损失函数在本文数据集和公开数据集对比试验Kolektor上的对比结果。实验数据如图7所示。图7中,数据集1是本文铆钉的表面缺陷数据,数据集2是公开数据集DAGM 2007。横坐标表示模型训练的迭代次数,纵坐标用于观测模型训练过程的拟合趋势,其值是训练数据集在当前迭代次数训练得到的模型检测出缺陷面积与标注图像中缺陷面积的比值。
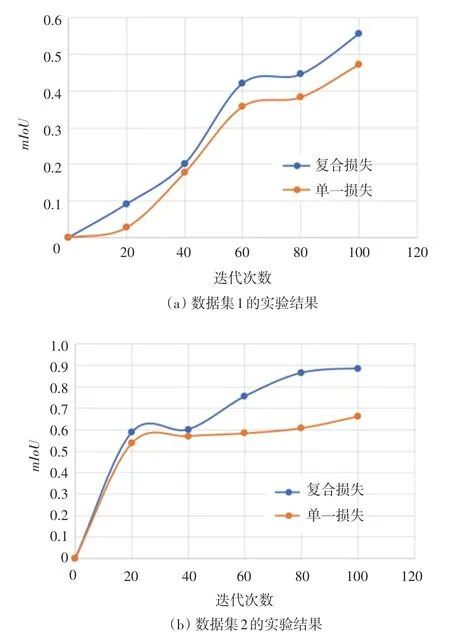
图7 有无IoU损失函数对比曲线图Fig.7 Comparison graph of loss function with and without IoU
从2组对比实验不难发现,复合损失函数在前期迭代过程中,都不同程度上加快了网络的收敛速度,分别在数据集1上提升了21.3%、数据集2上提升了24.9%。实验表明,单一的交叉熵损失函数对网络模型的优化方向较为单一,对于背景较多的数据集而言,找到前景所消耗的时间较长。交叉熵损失函数配合损失函数后,可以促使优化方向发生一定的跳动以加快寻求最好的优化结果的速度。
3.3 铆钉缺陷检测结果
图8展示的是本文模型U-net++推理结果,可以看到每一个缺陷都计算了其所占像素。因为本文在缺陷标注过程中,一些细微的缺陷仍然标注在内使得模型将很小的缺陷也被标注出来,这往往会导致最终的精确度会偏低,因为某部分存在一些狭小缺陷但可以被认定为良品的铆钉被判定为了不良品。因此在系统做了根据缺陷所占像素进行筛选的功能操作后,根据用户的需求,可以调高或者放低对缺陷大小的要求,更符合铆钉的生产场景需求。

图8 模型推理检测结果Fig.8 Model inference detection results
4 结束语
目前,缺陷检测已经成为工业生产流水线中的重要一环,随着对产品质量的要求越来越高,基于规则的传统的机器视觉检测方案在一些难以量化的缺陷面前表现不佳。本文针对铆钉表面缺陷检测的特点,设计了一种基于U-Net++的语义分割网络模型U-net++。首先针对铆钉缺陷语义层次的特点,对U-net++原始网络进行剪枝;此外针对数据集较小、且缺陷边界难以界定的问题,提出了模糊标签的数据增强方式;并针对单一的交叉熵损失函数在网络训练中存在收敛过慢的问题,本文增加了损失函数与其构成复合损失函数共同作用于网络。本文提出的铆钉表面缺陷检测模型U-net++,是在U-Net++的基础上改进优化,满足工业实时性检测需求的网络结构。
