一种基于Flink的流关联挖掘算法
2022-05-25胡佳丽裴腾达段晓东
冯 鹏,胡佳丽,黄 山,裴腾达,段晓东
(1.大连大学 大连市环境感知与智能控制重点实验室,辽宁 大连 116622;2.大连民族大学a.计算机科学与工程学院;b.大数据应用技术国家民委重点实验室,辽宁 大连 116650)
5G及互联网技术与各行业相结合,使许多行业产生高速实时的流式数据。基于流式数据的关联规则挖掘,可以发现事务间的隐藏联系,具有广泛的应用范围。流数据具有大量连续随机出现、体量潜在无限大、不断出现、不能控制数据流项目序列的到来顺序等特点。因此,流数据在挖掘处理时需要追踪更多的信息,如之前的频繁项在一段时间后可能转为非频繁项,亦或者之前的非频繁项一段时间后转为频繁项。而且数据不断的输入,使得系统内存中的数据需要不断维护与调整。在此背景下,一些经典的挖掘算法如Apriori[1]、FP-Growth[2]及CHARM[3]等,已无法维持流数据增量式更新的要求。Chris G等人[4]针对流数据挖掘过程中的时间敏感性,提出了流数据挖掘算法FP-Stream,但难以满足现阶段流式大数据关联规则挖掘的需求。Storm[5]、Spark-streaming[6]、Flink[7]等流框架的出现,为大量经典的关联规则挖掘算法提供了新的生机。在此背景下,本文提出一种基于Flink的流关联挖掘算法FP-Flink。
1 背景知识
首先介绍本文提出的FP-Flink算法的两个基本结构,全局模式树(Pattern-Tree)与倾斜时间窗口。然后介绍相关基本概念。
(1)全局模式树。全局频繁模式树是现阶段内所有频繁模式的统一表达。FP-Flink把FP树中的支持度计数改为滑动时间窗口表便形成了其特有的FP-Flink结构如图1。表中记录着该频繁模式从过去到当下时间窗口内每阶段的频率。通过这种记录方式详细记录近期的数据,粗略记录时间较为久远的数据,来保证在跨度较大的时间段内对数据信息进行保存,从而缓解计算机的存储压力。

图1 带有时间窗口的FP树
(2)倾斜时间窗口。在数据挖掘过程中,不仅要关注频繁项集,还必须注意对潜在频繁项集进行维护,因为潜在频繁项集可能随着时间变化转化为频繁项集,而无法转变的非频繁项集则应该被丢弃。倾斜时间窗口的基本思想为:相较于久远的信息,人们对当下的信息更感兴趣。以本文所使用的对数倾斜时间窗口,先选择一个最小时间粒度T作为当前整个的时间窗口的基础,当然T可以任意取值,然后以2为对数进行求值即可,在此模型下,若想求得最近一年的数据,同样取一分钟为最小时间粒度,则与之相邻近的2 min、4 min及8 min……均需进行处理,则一年数据的对数倾斜时间窗口模型如图2。

图2 对数倾斜时间窗口模型
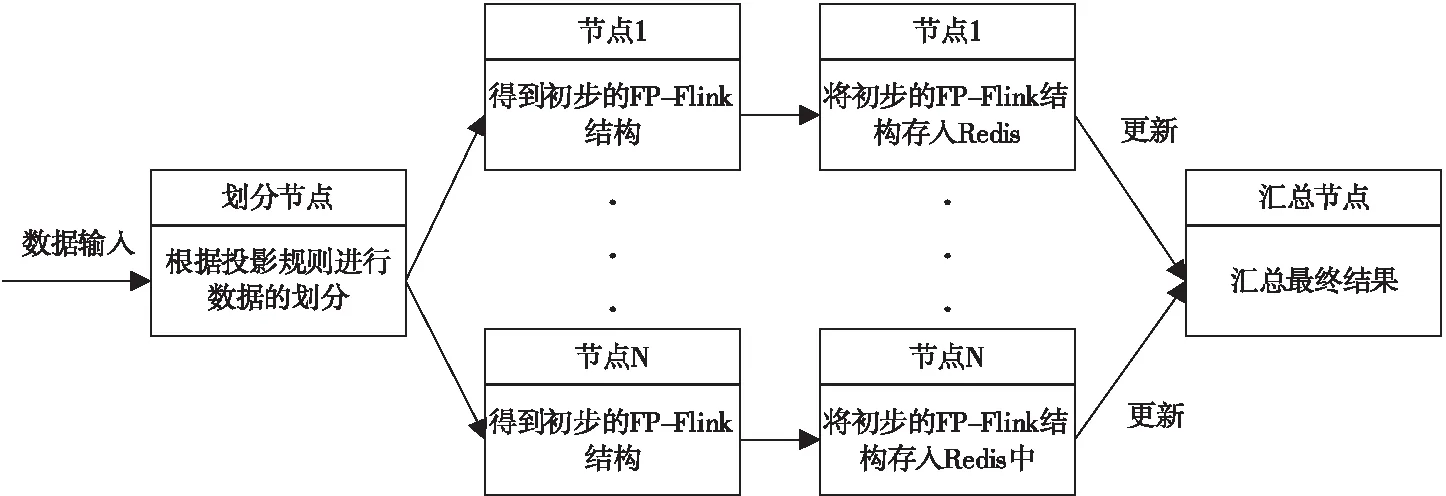
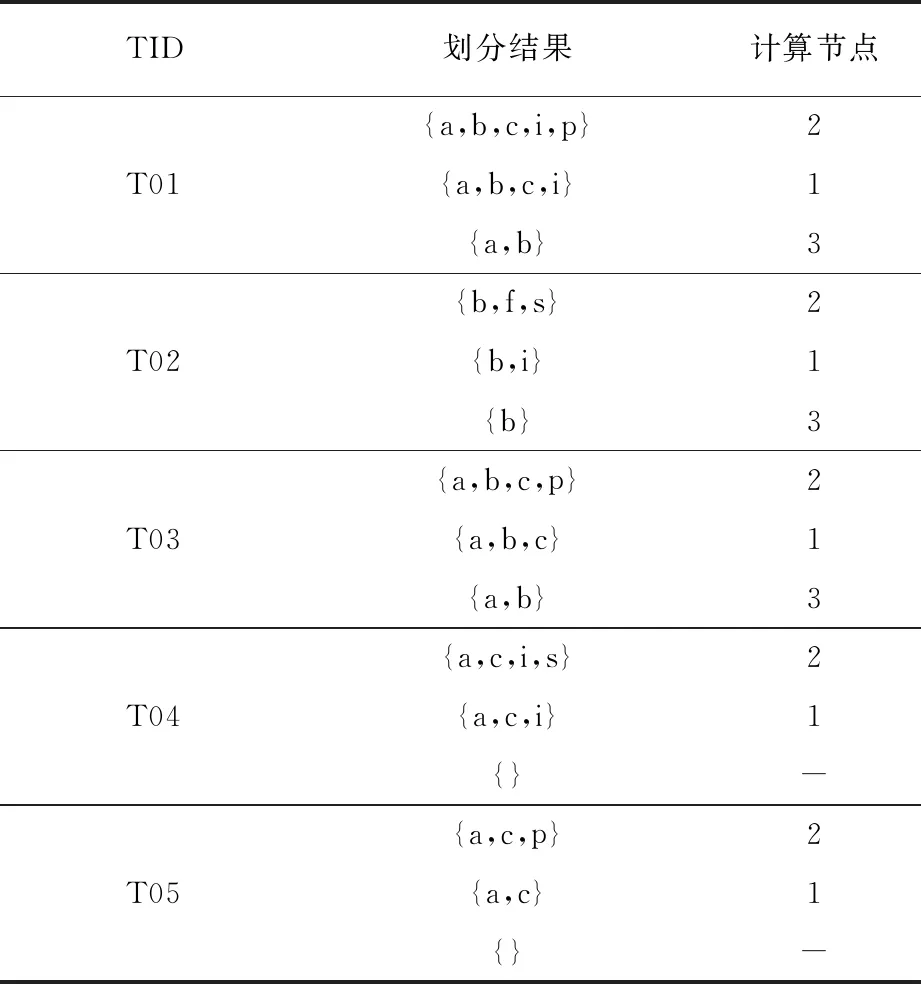
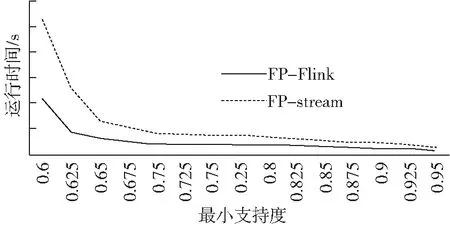
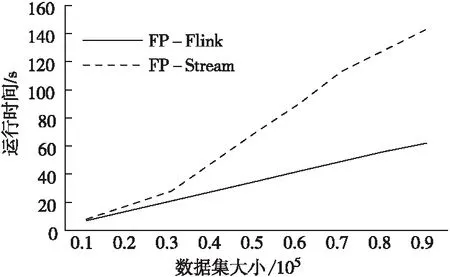
(3)相关基本概念。 设I={i1,i2,…,ik,…,im}是一系列项的集合,则项集X可以定义为X={i1,i2,…,ik}⊆I是一个k项集,事务T可以定义为T=(Tid,X),其中Tid被称作事务标识。以此类推,我们可以定义某事务集D={T1,T2,…,Tk,…,Tn}。则称D中所包含的项集Z的事务数量Sup(Z)为项集Z的支持度。最小支持度minsup(0 设松弛变量ρ=ε/minsup,显然可以根据ρ得到最大支持度误差ε,则以此可以把项集分为三种情况:(1)若Sup(X)≥σ,则项集Z为D中的频繁项集;(2)若ε≤ Sup(Z) < minsup,则Z为D中的潜在频繁项集;(3)若Sup(Z)<ε,则Z为D中的非频繁项集。 虽然FP-Flink算法所采用的树结构在一定程度上也能够缓解内存压力,但在高速的流数据面前,FP-Flink结构会异常庞大,遍历树结构完成挖掘任务也会更加费时,不能满足用户对实时性的要求。FP-Flink算法的分布式模型如图3。FP-Flink先把数据划分配给不同的节点,然后在所有节点记录数据概要信息,接着挖掘投影前缀子树生成初步的FP-Flink结构,最后把FP-Flink结构更新汇总。 图3 FP-Flink分布式模型 FP-Flink算法的核心思想是采用划分投影、字典序结构及序列化存储的方式,降低算法计算过程对空间的过度占用问题,并加快数据的挖掘效率。FP-Flink算法步骤主要有:(1)数据的预处理,主要包括数据的读入与频繁1项集的生成;(2)剔除非频繁项集;(3)划分投影,即把大数据集分成小数据集;(4)挖掘投影子树,即生成初步的FP-Flink结构,所生成的FP-Flink初步结构为字典序结构;(5)更新FP-Flink树结构,包括把FP-Flink序列化存入Redis与全局更新时将其取出更新两个操作。 (1)数据预处理。本操作主要是对Flink读入的数据做一个简单的词频统计,得到其中的潜在频繁一项集,以方便下一步剔除非潜在频繁项。即通过输入数据集和最小潜在支持度,输出中一切频率大于的项的集合。首先,Flink接收来自数据源的一个批次的数据,即对于事务,过滤其中的每一项,然后输出元组,综合得到的频率以及所有项的总计数,当的时候,则认为为频繁1项集,并输出。数据预处理伪代码见表1。 表1 FP-Flink数据预处理伪代码 (2)剔除非潜在频繁项。本操作将剔除当前时刻批次内数据事务T中非潜在频繁的项,并按照字典序[8]的偏序关系对频繁项集进行排序。以表2中的数据为例,设最小支持度为2,则经过数据预处理和剔除非频繁项这两步,得到的结果见表3。 表2 某批次数据集 (3)划分投影。设定划分规则,尽量保证把上一步产生的频繁1项集中的所有项能够均衡地分配给不同的节点。根据设定好的划分规则,把数据分配到不同的计算节点之中。针对某一条事务,从该事务的最后一项开始,逐项向该事务的第一项进行遍历,并根据当前最后一项的值进行划分,把其第一项到该事务集的所有项,分配给划分规则中对应的节点。当对应节点已经存有该条子记录时,则跳过这一项。直到该条事务的最小的子记录也存在于计算节点中,则结束遍历。假设存在一个具有3个节点的集群,则表3中的数据,按照Hash取余的划分投影方式,其数据分配结果见表4。 表3 排序结果 表4 数据划分结果 这种数据划分方法的使用,使得划分后的数据集同时进行运算挖掘成为了可能,消除了节点间不必要的数据通信。同时降低了一些节点里边子记录的重复率,缓解了计算时的内存压力。 (4)挖掘投影子树。本步骤主要是生成FP-Flink的初步结构。每个节点在接收到相应的数据后,会把其对应的消息添加到其自己的子树中,每个投影子树只记录着全局前缀树的一部分数据。按照上一步的划分投影规则,每个计算节点中事务的最后一项一定是划分规则中的某一项。因此挖掘投影子树的时候,本文选择从每个事务的最后一项为起始项,采用自下而上的方式遍历挖掘。以表4为例,则其节点2可以得到挖掘结果如图4。 图4 节点2的FP-Flink初步结构 (5)FP-Flink树更新。这一步包括两个操作,首先需要将初步生成的FP-Flink结构序列化成字节流后存入Redis中,这样可以大大减少FP-Flink结构对内存的占用。最终更新FP-Flink的全局模式时,可以根据需要以数据读取批次数、或者固定时间间隔进行FP-Flink结构的全局整合,如系统每读取5批次的数据或每间隔500 ms,便进行一次FP-Flink结构更新,更新算法见表5。 表5 FP-Flink全局模式树更新算法 实验在三台机器所组成的集群上进行,采用一主两从结构,实验相关配置见表6。 表6 实验环境配置 本文使用合成数据集评测FP-Flink算法性能。由于流数据本身具有很大的不确定性及高并发的特点,为了降低数据源对实验的影响,同时保证流数据的特性,本文选择Kafka作为消息中间件接收各个渠道的数据流。实验从算法的精确性和运行时间两个角度,对FP-Flink算法与经典的FP-Stream算法进行比较。 (1)测试频繁项集随支持度变化情况。随着最小支持度的减小,FP-Flink和FP-Stream算法的挖掘时间都会以指数级爆炸增长如图5。因为随着最小支持度的不断减小,整个频繁1项集会大幅增加,从而生成更为庞大的频繁模式树,加剧算法挖掘时的耗时。当最小支持度处于0.7到0.95的区间内,频繁项集较少,FP-Flink算法因为有着额外的工作节点间调度和数据通信会造成的额外开销,其算法运行时间会比FP-Stream算法稍微高一点点。当最小支持度小于0.7时,随着挖掘出的频繁项集的增多,因为FP-Flink算法所有的计算节点的频繁模式树和全局频繁模式树均小于FP-Stream算法的,故而其时间优势也越来越明显。 图5 最小支持度对算法影响 (2)吐量测评。随着系统的吞吐量的不断增大,FP-Stream算法的运行时间增长率逐减增大后慢慢趋于平稳如图6。FP-Flink的运行时间也随着系统吞吐量的增大不断增大,但整个测试时间段内,FP-Flink算法运行时间均优于FP-Stream算法。 图6 数据吞吐量对运行时间的影响 (3)可伸缩性测试。在数据集和支持度相同的条件下时,FP-stream与FP-Flink算法的挖掘结果相同。本文提出的FP-Flink算法随着数据集的增大有着较好的线性可伸缩性,而经典的FP-stream算法则没有,算法可拓展性测试如图7。FP-Flink算法运行的时候,其每个线程都会生成比FP-Stream更小的树,所以对树进行遍历所需要的时间也更少,故而FP-Flink运行时间比FP-Stream少。 图7 算法可拓展性测试 本文提出一种基于Flink的流关联挖掘算法FP-Flink,其核心思想是通过划分投影、字典序结构与序列化存储的方式,解决流关联挖掘过程中,数据中间结果太大,过度占用内存的问题。经实验验证,该算法可以缓解计算时的内存压力,缩减数据的挖掘时间,相较于经典流挖掘算法具有更快的处理速度且具有更强的可扩展性。受研究环境有限,本文仅研究了具有万条数据的流关联挖掘。以后需要在更大的数据集及更多流数据上应用,以进一步验证算法的有效性。2 基于Flink的流关联挖掘算法





3 实验测评
3.1 实验环境配置

3.2 实验结果与分析

4 总结与展望
