相关性视觉对抗贝叶斯个性化排序推荐模型
2022-05-25李广丽卓建武许广鑫李传秀吴光庭张红斌
李广丽,卓建武,许广鑫,李传秀,吴光庭,张红斌
(1.华东交通大学 信息工程学院,江西 南昌 330013;2.华东交通大学 软件学院,江西 南昌 330013)
伴随大数据时代到来,如何在海量数据中挖掘有效的信息,已成为工业界和学术界共同关注的问题。推荐模型(也称推荐系统)是一种有效的信息过滤机制,它根据用户需求从海量数据中筛选出有价值的内容,并以个性化方式推荐给用户。
推荐模型可分为基于内容的推荐、基于协同过滤的推荐、混合推荐和基于对抗学习的推荐。基于内容的推荐是利用用户选择的物品来寻找其他类似物品完成推荐。基于协同过滤的推荐能获取浅层模型无法学到的用户和物品的深层特征,多采用矩阵分解(matrix factorization,MF)、奇异值分解、聚类、贝叶斯个性化排序(Bayesian personalized ranking,BPR)等模型,分析用户与物品间潜在交互,从而预测用户偏好,但传统协同过滤方法面临数据稀疏问题。为此,He等基于卷积神经网络(convolutional neural network,CNN)提取视觉特征改进BPR模型,构建视觉贝叶斯个性化排序(visual Bayesian personalized ranking,VBPR)模型。Chu等基于视觉信息和用户评分完成酒店推荐。视觉信息还可用于旅游推荐、食物推荐和餐厅推荐。融合多源异构信息的混合推荐由于能缓解数据稀疏问题,也受到研究者高度重视。虽然研究者采用视觉信息、混合推荐来应对数据稀疏问题,但该问题仍未得到有效解决,且异构特征间的深层语义未有效挖掘。
近年来,为了提升模型鲁棒性,对抗学习被引入推荐模型中。Wang等提出信息检索生成对抗网络(information retrieval generative adversarial networks,IRGAN),IRGAN首次将对抗学习融入推荐。Wang等使用Softmax函数加速训练过程,大大提高了计算效率。Wang等提出自适应噪声采样器,为推荐模型生成对抗负样本。He等提出对抗个性化排序模型(adversarial personalized ranking,APR),通过为特征增加干扰,减少模型过拟合并提高其鲁棒性。Yang等通过生成增强的用户与待推荐物品间的交互,改进基于协同过滤的推荐。总之,对抗学习在推荐中扮演重要角色,但模型鲁棒性仍有待提升。
综上,推荐模型仍存在数据稀疏、异构特征间深层语义未有效挖掘和模型鲁棒性有待提升等关键问题。为解决以上问题,本文引入新图像特征、聚类典型相关性和对抗学习策略,设计相关性视觉对抗贝叶斯个性化排序(correlation visual adversarial Bayesian personalized ranking,CVABPR)推荐模型,以完成高质量推荐。本文的创新点如下:
1)引入新图像特征SENet并改进聚类典型相关性分析(cluster canonical correlation analysis)模型,将异构SENet特征映射至同一语义空间,挖掘它们间的聚类典型相关性,更好地刻画待推荐电影,从视觉内容角度缓解数据稀疏问题,并充分利用异构特征间深层语义。
2)将挖掘出的聚类典型相关性和对抗学习策略融入VBPR模型中,构建全新的CVABPR模型,其推荐性能优于主流基线;由于在对抗学习中加入扰动因子,推荐模型具备较强鲁棒性。
1 CVABPR模型
1.1 模型框架
CVABPR模型框架如图1所示。CVABPR模型包括图像特征提取、聚类典型相关性分析和对抗学习。首先,基于SENet模型抽取5个异构图像特征:SEResNet50(SR50)、SEResNet101(SR101)、SERes-Net152(SR152)、SEResNeXt50(SRxt50)及SERes-NeXt101(SRxt101)。其次,改进CCCA模型以分析SENet特征间隐含的聚类典型相关性,获得相关性特征,分别用SR50-SR101、SR50-SR152、SR50-SRxt50、SR50-SRxt101等表示,共计10组。例如,SR50-SR101表示SR50与SR101特征之间的聚类典型相关性,其他命名的含义同理。在VBPR模型中引入对抗学习策略,并将聚类典型相关性嵌入其中,构建CVABPR模型,完成高质量个性化推荐。

图1 CVABPR模型框架Fig. 1 Framework of the CVABPR model
1.2 聚类典型相关性分析
在SENet特征提取基础上,改进聚类典型相关性分析(cluster canonical correlation analysis,CCCA)模型,挖掘异构特征间的典型相关性。设两个图像特征矩阵为X
与Y
,图像特征矩阵中的样本从C
个单独类(C
指电影类别数,本文为19)中采集,T
为第1类特征x
的特征集合,T
为第2类特征y
的特征集合。具体如下所示:
X
={x
,x
,···,x
}、
Y
={y
,y
, ···,y
}分 别表示在第c
组中X
和Y
的 数据,c
={1,2, ···,C
},|X
|、 |Y
|分 别表示两个图像特征的维度。设w
、v
分别为X
、Y
对应的投影向量。X
、Y
的相关系数 ρ计算如下:
C
、C
和C
表示协方差矩阵,如下所示:
S
为X
和Y
的成对关系总对数,S
=获取 ρ最 大化时X
、Y
对应的投影向量w
、v
,将X
和Y
映射到中间空间,生成映射后的特征矩阵X
和Y
:
X
和Y
分别进行拼接和相加融合,得到聚类典型相关性特征矩阵U
和U
,如下所示:
1.3 CVABPR模型形式化描述
CVABPR模型的基础框架是VBPR模型,CVABPR模型在VBPR模型中引入对抗学习策略“A(adversarial)”和聚类典型相关性“C(correlation)”。VBPR模型源于BPR模型,BPR模型仅依赖“用户-评分”矩阵完成推荐,该矩阵只包含用户对电影的评分,评分范围1~5分;而VBPR模型在BPR模型中增加了视觉特征接口,基于该接口可将外部语义引入推荐模型中。因此,在VBPR模型中加入已挖掘的聚类典型相关性,即通过视觉特征接口将相关性输入VBPR,构建相关性视觉贝叶斯个性化排序(correlation VBPR,CVBPR)模型,由于仅采用聚类典型相关性,故它是CVABPR模型的变种。下面对CVABPR模型进行推导。
首先,VBPR模型的评分预测函数如下:

u
为用户序号,i
为电影序号;p
q
为 基于传统MF模型的预测评分,p
为基于“用户-评分”矩阵生成的用户u
的特征向量(p
∈ℜ),
q
为基于“用户-评分”矩阵生成的电影i
的特征向量(q
∈ℜ);
h
(E
·c
)为基于电影海报图像特征的预测评分,c
表示电影i
的D
维视觉特征(c
∈ℜ),
E
为转换矩阵(E
∈ℜ),它对电影i
的视觉特征c
进 行维度转置,E
·c
为视觉特征潜语义描述,h
为 用户u
对应的K
维特征向量(h
∈ℜ),它描述用户的潜在偏好。因此,BPR模型损失函数为: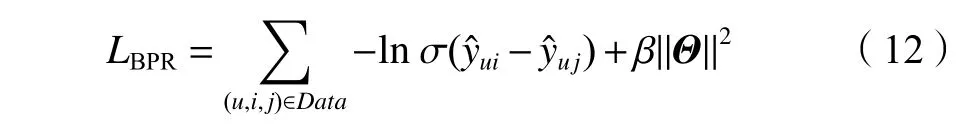
i
、j
为电影序号,Data
为逐对排序优化中的3元组数据, σ为sigmoid激励函数, β为控制正则化的超参数, Θ为BPR模型参数, | |Θ||为正则项。引入对抗学习后,CVABPR模型的评分预测函数为:
p
、q
、E
和c
的含义同式(11), Δ为用于对抗学习的扰动参数。对抗扰动是一种能有效提升模型鲁棒性的正则项,将扰动项添加到视觉特征(即聚类典型相关性特征)中不会改变原视觉特征内容,但它可提升视觉特征潜语义描述E
·c
应对外界噪声干扰的能力。因此,为获取最佳扰动参数需最大化BPR损失,公式如下:
L
为基于式(13)中评分预测函数设计的BPR损失函数; Δ为 模型优化出的最佳扰动参数; ||·||为L2正则化参数; ε为调制扰动幅度的超参数,它控制BPR损失范围。为获得最佳模型参数,需最小化BPR损失:
式中, Θ为优化出的最佳模型参数,、用式(11)计算,、用 式(13)计算, λ为模型训练过程的超参数, β为控制正则化的超参数。使用随机梯度下降算法优化模型并更新参数,对应更新参数的公式如式(16)、(17)所示:

T
为参数 Δ 的梯度, η 为参数ε 的学习率, η为参数 Δ的学习率。2 实验与分析
2.1 数据集及对比模型
MovieLens100k 和 MovieLens1M数据集中包含“用户-评分”矩阵、电影标题和电影类别等信息,“用户-评分”矩阵中是用户对电影的评分,评分范围为1~5分。每个用户至少评价20部电影。MovieLens100k的评分数量为100 000,MovieLens1M的评分数量约为1 000 000,具体信息见表1。此外,MovieLens数据集包括19种详细的电影类别,分别是动作、冒险、动画、儿童、喜剧、犯罪、纪录片、戏剧、奇幻、黑色电影、恐怖、音乐、悬疑、浪漫、科幻、惊悚、战争、西部、未知。本文将电影海报图像加入MovieLens100k 和 MovieLens1M数据集,构建两个全新的多模态数据集:MovieLens-100k-WMI(“WMI”表示“with movie images”)和MovieLens-1M-WMI。根据电影标题从互联网电影资料库(Internet movie database,IMDB)爬取每部电影对应的海报,每张海报属于19个电影类别之一。基于MovieLens 数据集和电影海报图像生成多模态数据集MovieLens-WMI,用户可访问爬取的电影海报图像数据集。MovieLens-WMI数据集的详细信息如表1所示。
表1 MovieLens-WMI数据集详细信息
Tab. 1 Detailed information of the MovieLens-WMI datasets
数据集 用户数电影数评分数海报图像数稠密度/%MovieLens-100k-WMI 943 1 683 100 000 1 683 6.30 MovieLens-1M-WMI 6 040 3 544 993 482 3 544 4.64
实验中,随机抽取80%“用户-评分”及对应图像数据作为训练集,剩下20%“用户-评分”及对应图像数据作为测试集。实验迭代2 000次,每50次迭代计算1次推荐指标均值,共计算40次,从这40次结果中分别选取每个推荐指标的最优值作为模型的最终推荐性能评估值。
选取3种排序评价指标评估模型的推荐性能,分别是平均准确率(average precision @K
,P@K
)、平均精度均值(mean average precision,MAP)和归一化折损累计增益(normalized discounted cumulative gain,NDCG)。P@K
计算推荐结果中前K
个的准确率;MAP对若干次推荐产生的P@K
值取均值;NDCG@K关注排序加权后前K
个推荐结果的准确率。这3个指标值越大说明推荐性能越好。将CVABPR与如下4类方法进行比较。
1)传统模型:最大似然估计(maximum likelihood estimation,MLE)和LambdaFM(lambda factorization machines);
2)基于GAN的推荐模型:GraphGAN(graph generative adversarial networks)、IRGAN和UPMGAN(users preference mining-generative adversarial networks);
3)BPR的变种:BPR、VBPR、CVBPR和APR模型;
4)基于深度学习的推荐模型:DMF(deep MF)和NMF(Neural MF)模型。
2.2 实验结果
2.2.1 CVBPR模型实验结果
为验证聚类典型相关性特征的有效性,首先,在MovieLens-100k-WMI和 MovieLens-1M-WMI两个数据集上,使用不同特征分别建立CVBPR模型(CVABPR模型的变种,即只采用聚类典型相关性而忽略对抗学习策略)并评估其性能。建立模型的特征包括:从SENet模型中抽取的5个异构图像特征(SR50、SR101、SR152、SRxt50及SRxt101)和10组聚类典型相关性特征(如SR50-SR101、SR50-SR152、SR50-SRxt50、SR50-SRxt101);作为对比,还提取VGG16、HSV和ResNet50(R50)等传统特征。计算采用每个特征建立的模型的性能指标。图2展示了建立的模型在P@3和NDCG@3两个指标上的最优值(其他指标类似),包括使用传统特征分别建模获得的最优模型指标、使用5个异构图像特征分别建模获得的最优模型指标、使用10组聚类典型相关性特征分别建模获得的性能排在前2的模型的指标。

图2 CVBPR模型中不同特征的推荐性能Fig. 2 Recommendation performance of different features in CVBPR model
如图2(a)所示:在MovieLens-100k-WMI数据集中,相比最优传统特征R50建立模型的性能,SRxt50特征建立模型的性能更优。该优势在NDCG@3指标上尤为明显,论证了SRxt50特征的有效性。这表明,选取SENet特征进行聚类典型相关性分析可以获取判别性更强的新特征。在全部聚类典型相关性中,性能最优的是SRxt50-SRxt101,这表明:SRxt50和SRxt101这两类SENet特征间存在较强的底层相关性,该相关性被改进的CCCA模型所捕获,进而准确刻画待推荐电影海报图像。此外,由图2(a)还可知:采用聚类典型相关性特征建立的模型的推荐性能均优于采用单特征(包括传统特征和SENet特征)建立的模型,这说明改进的CCCA模型是有效的,它能挖掘出具有足够多判别语义的特征,提升推荐性能。
在MovieLens-1M-WMI数据集上可得到与图2(a)相似的实验结论,其中,SRxt50-SRxt101和SR50-SRxt50表现优异,本质原因同上。综上所述,改进的CCCA模型能准确捕获异构SENet特征之间潜在的聚类典型相关性,从而更好地刻画待推荐电影,最终改善推荐性能。当然,基础的VBPR框架在推荐中也扮演了关键角色(参见第2.3节)。
2.2.2 CVABPR模型实验结果
在聚类典型相关性分析基础上,引入对抗学习策略,在CVBPR模型基础上构造CVABPR模型,CVABPR模型在两个数据集上的推荐性能如图3所示。
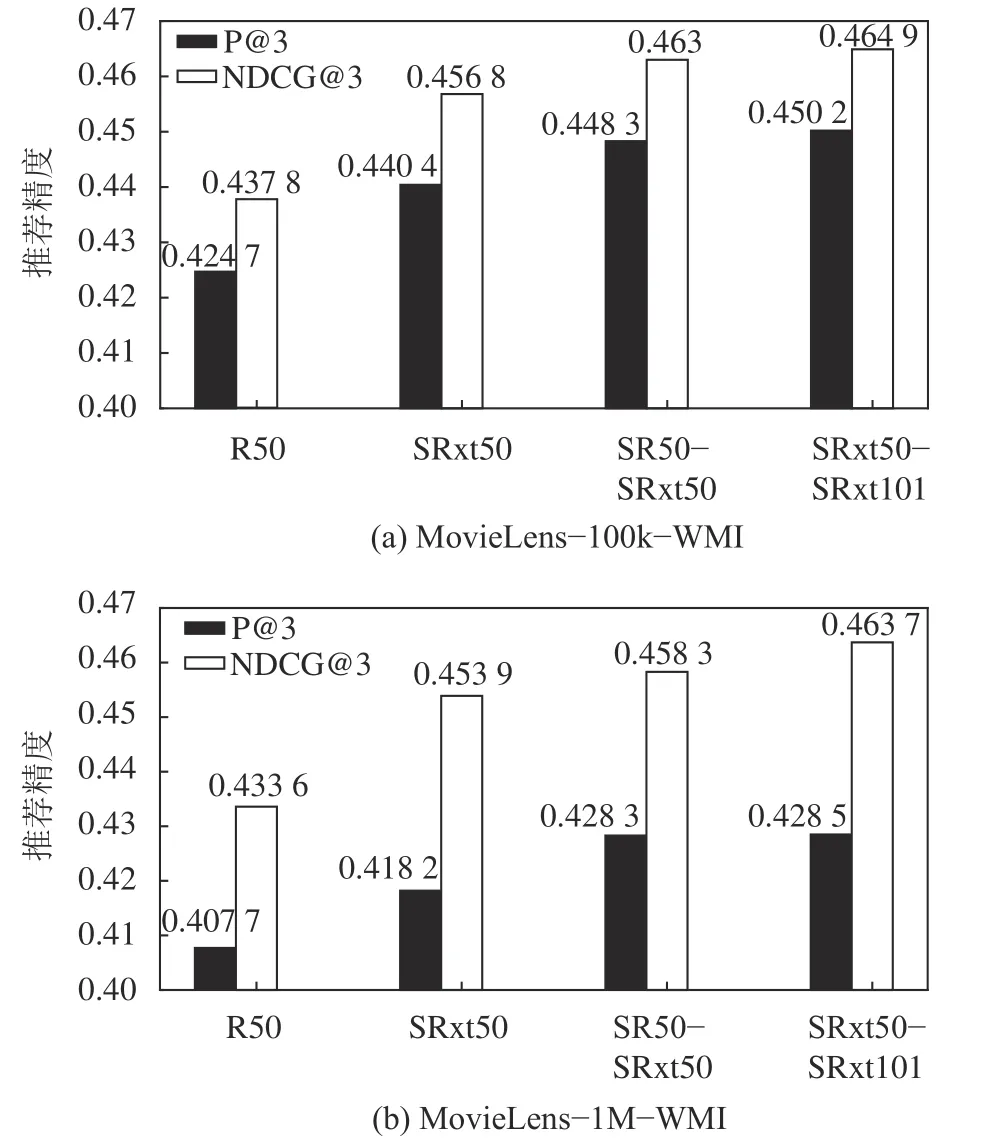
图3 CVABPR模型中不同特征的推荐性能Fig. 3 Recommendation performance of different features in CVABPR model
图3与图2类似,对于传统特征、SENet类特征,仅选择模型在NDCG@3和P@3两个指标上的最优值做展示,对于聚类典型相关性特征,则选取最优的两个模型的指标进行展示。CVABPR相对CVBPR的推荐性能提升幅度见表2。表2中:在MovieLens-100k-WMI数据集上,Improve和Improve分别表示CVABPR模型相对于CVBPR模型在P@3指标和NDCG@3指标上的提升幅度;在MovieLens-1M-WMI数据集上,Improve和Improve分别表示CVABPR模型相对于CVBPR模型在P@3指标和NDCG@3指标上的提升幅度。
表2 CVABPR相对于CVBPR的推荐性能提升幅度
Tab. 2 Recommendation performance improvement of CVABPR compared to CVBPR
%图像特征 MovieLens-100K-WMI MovieLens-1M-WMI Improve1 Improve2 Improve3 Improve4 R50 3.74 3.45 4.61 3.87 SRxt50 4.20 4.23 4.73 4.23 SR50-SRxt50 4.13 4.24 4.69 3.97 SRxt50-SRxt101 4.18 4.30 4.88 4.57
由图3(a)可知:在MovieLens-100k-WMI数据集中,聚类典型相关性SRxt50-SRxt101表现最优,它优于各单特征,这说明改进的CCCA模型能生成高质量聚类典型相关性,准确描述用户偏好并最终改善推荐性能。在MovieLens-1M-WMI数据集上也能获得较高的性能,故模型具备较强鲁棒性,而对抗学习是确保该鲁棒性的关键。相比于图2,图3中推荐效果更优,即CVABPR模型性能优于CVBPR模型。
由表2可知,在数据集MovieLens-100K-WMI上,对于P@3和NDCG@3指标,使用聚类典型相关性特征SRxt50-SRxt101建立的CVABPR模型比CVBPR模型(图2(a))分别提升4.18%和4.30%(MovieLens-1MWMI数据集类似),这进一步表明,引入对抗学习策略使推荐模型能更好地应对外部噪声扰动,提升模型鲁棒性并获取更优的推荐效果。
综上,采用对抗学习策略,能使推荐模型更好地应对外部扰动,从而变得更稳定、鲁棒,即对抗学习使CVABPR模型中的视觉特征潜语义描述能更好地抵御外界噪声干扰,从而准确描述待推荐电影,完成高质量用户兴趣建模,从视觉内容角度积极应对数据稀疏问题并最终改善推荐精度及模型鲁棒性。因此,对抗学习策略在CVABPR模型中扮演非常重要的角色。
2.2.3 与主流基线对比
选择CVABPR模型的最佳结果(图3)与第2.1节所述主流推荐模型进行性能对比,结果见表3和4。表3中,Improve表示在MovieLens-100k-WMI数据集上,与最强基线APR模型相比,CVABPR模型推荐性能的提升幅度。表4中,Improve表示在MovieLens-1MWMI数据集上,与最强基线APR模型相比,CVABPR模型推荐性能的提升幅度。
表4 CVABPR模型与主流基线性能结果比较(MovieLens-1M-WMI)
Tab. 4 Performance comparisons between CVABPR and state-of-the-art baselines (MovieLens-1M-WMI)
模型 P@3 P@5 NDCG@3 NDCG@5 MAP MLE[25] 0.278 4 0.266 4 0.299 7 0.287 8 0.203 4 BPR[5] 0.289 5 0.269 1 0.303 7 0.288 6 0.204 7 GraphGAN[15] 0.358 1 0.329 7 0.369 1 0.349 1 0.211 4 LambdaFM[26] 0.362 2 0.344 3 0.390 2 0.384 2 0.233 7 IRGAN[14] 0.380 8 0.368 2 0.418 5 0.406 1 0.250 4 DMF[27] 0.386 9 0.371 1 0.420 4 0.409 7 0.254 5 UPM-GAN[23] 0.394 7 0.381 9 0.428 6 0.417 3 0.260 1 VBPR[6] 0.398 4 0.385 3 0.434 7 0.408 2 0.261 4 NMF[24] 0.399 1 0.385 7 0.432 9 0.420 2 0.262 4 APR[17] 0.410 4 0.397 3 0.447 2 0.437 8 0.271 2 CVBPR 0.408 2 0.394 9 0.442 5 0.415 3 0.266 1 CVABPR 0.428 5 0.414 5 0.463 7 0.434 4 0.283 7 Improve6/% 4.410 4.329 3.690 -0.777 4.609
如表3、4所示,CVABPR模型获得最佳性能,与协同过滤式推荐模型MLE、BPR和LambdaFM相比 ,可观察到最大的推荐性能差距。因为传统模型仅使用“用户-评分”矩阵完成推荐,该矩阵只包含用户对电影的评分,数据稀疏问题非常严重(参见表1的稠密度)。与DMF和NMF等深度学习类推荐模型相比,CVABPR模型的优势也十分显著。CVABPR模型提供全新的视觉特征接口,该接口可以将外部语义(如聚类典型相关性)集成到推荐模型中,然后配合“用户-评分”矩阵完成推荐。显然,引入图像信息能更好地刻画待推荐电影,实现高质量用户建模,以准确描述其偏好,即从视觉内容角度有效缓解推荐中的数据稀疏问题。与IRGAN、GraphGAN、UPM-GAN和APR等对抗学习类推荐模型相比,CVABPR也表现优异。不同于这些GAN模型,CVABPR模型引入了异构特征间的深层语义(聚类典型相关性),能更好地描述待推荐电影。同时,CVABPR中还加入扰动因子,使视觉特征潜语义描述能更好地应对外部干扰,从而完成更稳定的推荐并获得更优的推荐性能。
表3 CVABPR模型与主流基线性能结果比较(MovieLens-100k-WMI)
Tab. 3 Performance comparisons between CVABPR and state-of-the-art baselines (MovieLens-100k-WMI)
模型 P@3 P@5 NDCG@3 NDCG@5 MAP MLE[25] 0.336 9 0.301 3 0.346 1 0.323 6 0.200 5 BPR[5] 0.328 9 0.300 4 0.341 0 0.324 5 0.200 9 GraphGAN[15] 0.355 1 0.331 3 0.372 8 0.358 2 0.213 5 LambdaFM[26] 0.384 5 0.347 4 0.398 6 0.374 9 0.222 2 IRGAN[14] 0.407 2 0.375 0 0.422 2 0.400 9 0.241 8 DMF[27] 0.410 7 0.379 1 0.425 7 0.407 7 0.242 7 UPM-GAN[23] 0.419 6 0.390 7 0.433 7 0.412 3 0.254 0 VBPR[6] 0.421 9 0.396 2 0.437 5 0.398 7 0.254 6 NMF[24] 0.421 3 0.398 1 0.438 3 0.417 9 0.257 1 APR[17] 0.436 4 0.407 2 0.455 1 0.431 7 0.265 7 CVBPR 0.431 4 0.403 8 0.444 9 0.410 8 0.261 8 CVABPR 0.450 2 0.423 2 0.464 9 0.425 8 0.276 2 Improve5/% 3.065 3.780 2.108 -1.386 3.802
表4中:相比于MovieLens-100k-WMI数据集,CVABPR模型在稀疏度更高的MovieLens-1M-WMI数据集上获取了更大的性能提升,对于NDCG@5和MAP指标, CVABPR模型在MovieLens-1M-WMI数据集上的性能明显优于MovieLens-100k-WMI数据集。这表明所提的CVABPR模型在更稀疏的数据集上能更好地应对数据稀疏问题。同时,CVABPR模型在这两个数据集上相对于APR模型的平均性能提升幅度分别是2.273%、3.252%,显然,CVABPR模型在更稀疏的数据集上获得了更大的平均性能提升。这可能是因为:MovieLens-1M-WMI数据集包含更丰富的图像数据,改进的CCCA模型能挖掘出判别性更强的聚类典型相关性,为描述用户隐含偏好奠定坚实基础。因此,CVABPR模型在聚类典型相关性分析基础上获取了更多有价值的语义信息,更准确地刻画了待推荐电影,从视觉内容角度可有效地应对数据稀疏问题。
2.3 消融分析实验
通过消融分析实验来分别检验CVABPR模型各部件,包括视觉接口(V)、聚类典型相关性(C)、对抗学习策略(A)等在推荐中的有效性。构造3个CVABPR模型的变种(VABPR、CVBPR、BPR),完成消融分析实验,计算P@3、MAP、NDCG@3这3类指标及各类指标均值Mean,结果见表5。
表5 CVABPR模型消融分析实验结果
Tab. 5 Ablation analysis results of CVABPR
%数据集 算法 P@3下降幅度NDCG@3下降幅度MAP下降幅度Mean下降幅度MovieLens-100k-WMI VABPR 1.947 1.773 3.077 2.266 CVBPR 4.358 3.564 5.500 4.474 BPR 27.972 28.093 26.730 27.598 MovieLens-1M-WMI VABPR 2.219 1.934 3.616 2.589 CVBPR 4.870 4.791 6.614 5.425 BPR 37.271 38.805 27.700 34.592
1)VABPR :从CVABPR模型中移除聚类典型相关性分析(C),获取VABPR模型。表5中,VABPR对应行的值表示VABPR模型相对CVABPR模型的性能下降幅度,故其着力评价聚类典型相关性的重要性;
2)CVBPR :从CVABPR模型中移除对抗学习策略(A),获取CVBPR模型。表5中,CVBPR对应行的值表示CVBPR模型相对CVABPR模型的性能下降幅度,故其着力评价对抗学习策略的重要性;
3)BPR:从VBPR模型中移除视觉接口(V),获取BPR模型。表5中,BPR对应行的值表示BPR模型相对VBPR模型的性能下降幅度,故其着力评价视觉接口的重要性。
由表5可知:当移除视觉接口后,推荐模型性能出现最大幅度下降;移除对抗学习策略也会导致较大幅度下降;而移除聚类典型相关性,推荐模型的性能下降幅度相对较小。因此,基于平均值(Mean)可得到CVABPR模型各部件重要性的降序排列:视觉接口(V)重要性>对抗学习(A)重要性>聚类典型相关性(C)重要性。CVABPR模型充分利用电影海报图像中蕴含的聚类典型相关性来提升模型推荐性能,即充分挖掘并利用异构SENet图像特征之间的深层视觉语义;而对抗学习则使推荐模型更趋稳定且鲁棒,并获取更优推荐性能。由表5 还发现:基于MovieLens-1M-WMI数据集建立的模型性能下降幅度更大,即CVABPR模型能在更稀疏的数据集上获取更大的性能提升,数据稀疏问题得到一定解决。该实验结论与表3、4吻合。
3 结论与展望
为解决推荐中的数据稀疏、未有效利用深层视觉语义、模型鲁棒性较低等问题,提出相关性视觉对抗贝叶斯个性化排序推荐模型CVABPR,它从SENet特征提取、聚类典型相关性分析和对抗学习等角度积极应对上述问题。实验结果表明:CVABPR模型在MovieLens-100k-WMI和 MovieLens-1M-WMI两个数据集上都取得较好推荐效果,已具备较强鲁棒性。
未来工作展望:1)运用其他特征学习方法,如Transformer,获取更有效的图像特征;2)基于Unicoder-VL和LXMERT等模型更好地挖掘异构图像特征间的相关性。
