基于大数据的煤矿违规行为分析识别系统研究
2022-05-23张洪亮
张洪亮
(1.中煤科工集团沈阳研究院有限公司,辽宁 抚顺 113122;2.煤矿安全技术国家重点实验室,辽宁 抚顺 113122)
在大数据技术流行的今天,我国也加快了对大数据相关技术应用的进程,大数据技术与行业进行了深度融合,同时也推动了各行业的产业智能化升级。2019 年10 月底,国家煤矿安全监察局印发煤安监办[2019]42 号《国家煤矿安全监察局关于加快推进煤矿安全风险预警系统建设的指导意见》[1-2],要求“建设覆盖国家、省、煤矿企业多个层面的安全生产风险监测预警系统,打通从企业向上至煤矿安全监管部门、省级煤监机构、国家煤矿安监局系统的数据采集、传输、共享渠道。”。同时应对煤矿安全生产形势依然严峻,如何利用信息化手段提高煤矿安全执法,降低煤矿安全生产事故,保障煤矿安全生产是急需解决的问题。因此,急需研究建设煤矿安监执法相关数据分析平台,对煤矿企业的相关违规行为进行识别、报警,并及时消除安全隐患。基于先进信息化技术,不断推进信息化建设,满足煤矿企业自身的安全管理要求,提高煤矿企业的安全生产管理水平,避免重特大安全事故发生,保障企业安全生产的总体目标。
1 系统关键技术
大数据技术是一系列复杂技术的总称,基础的技术包含数据采集、数据仓库、数据存储、数据挖掘、机器学习、多线程、可视化等。其主要核心关键技术包括Hadoop 大数据技术和Hive 数据仓库技术。大数据技术架构如图1。

图1 大数据技术架构Fig.1 Big data technology architecture
1)Hadoop 技术。Hadoop 技术框架是一个依托于Apache 基金会的分布式系统基础架构。Hadoop 适合应用于大数据存储和大数据分析的应用,是以一种可靠、高效、可伸缩的方式进行处理的。还可以构建于公共社区服务器,这样大大降低了用户的使用、开发成本。用户可以方便地在Hadoop 公共社区服务器上设计、开发、运行和处理海量数据的应用程序。Hadoop 还支持Java 语言编写的技术框架,能够完美地运行在Linux 操作系统上。同时,Hadoop 也支持其他编程语言。Hadoop 最核心的技术架构是HDFS和MapReduce。HDFS 为海量数据提供分布式存储,MapReduce 为海量数据提供了分布式计算能力。
2)Hive 数据仓库技术。Hive 是基于Hadoop 的一个数据仓库工具,用来进行海量数据的提取、转化和加载,即ETL 操作。Hive 数据仓库相关工具能够将结构化的、有序的数据文件转化为关系型数据库中的数据表,并能够进行SQL 语句查询,能将SQL语句转变成MapReduce 任务来执行。Hive 的优势是使用成本低,可通过类似关系型数据库的SQL 语句实现快速MapReduce 计算,使对MapReduce 使用变得更简单,不必开发复杂的MapReduce 模块程序。
2 系统设计
2.1 煤矿常见违规操作行为
煤矿违规行为存在于企业生产、经营的方方面面,但与安全息息相关的违规操作行为还是存在于安全生产的过程之中,主要有变换传感器接入位置、遮挡传感器探头、篡改上传数值、人为下调传感器安装位置、中断传感器数据、无计划删除测点、传感器假标校等违规行为。
1)传感器接入位置信息违规场景。井下实际检测传感器已安装,但是不接信号或在中心站软件不定义,使其数据不传到中心站,用别的地方的传感器信号代替此位置传感器的信号,迷惑检查人员或上级人员。如将传感器放置于甲烷气体体积分数比较低的进风巷内,导致监测的数据远远低于实际值。
2)传感器传感头被遮挡违规场景。将传感器的传感头部分使用塑料口袋等进行捆扎,让外界中的环境气体无法进入传感器的感应室内,导致传感器无法对环境中的甲烷等气体进行检测,即使瓦斯气体超限,传感器也无法进行监测,或者检测到的甲烷气体体积分数值严重偏低。
3)传感器数值上传违规场景。当传感器的气体体积分数值将要超限或已超限时,在数据上传服务器前将原始数据进行修改来防止系统发出报警。数据会存在突增点、突减点和窄幅震荡的异常,且在突增异常点、突降异常点之后会伴随出现数据窄幅震荡异常,即数据整体表现比较平稳,但变化频率较快。
4)下调传感器安装位置违规场景。相关安全规程要求,甲烷传感器应垂直悬挂,距顶板(顶梁、屋顶)不得大于300 mm,距巷道侧壁(墙壁)不得小于200 mm。瓦斯的密度比空气小,所以瓦斯易在巷道上部积聚。人为下调传感器安装位置或者修改传感器量程,将导致甲烷传感器测量值与实际瓦斯体积分数值相比整体缩倍偏低。
5)传感器中断违规场景。地面或井下人员在发现传感器有上升超限趋势后,对该分站主通讯进行中断或将传感器拔掉、或将传感器设置为不巡检状态、或者出现异常情况后中止上传,使超限后的数据无法正常传输到地面中心站,待瓦斯体积分数值恢复正常后恢复通讯。
6)无计划删除测点异常场景。地面监控人员将已经出现的超限(或预计将会出现超限)测点删除,致使数据上传中断。
7)传感器标校周期违规场景,传感器需按标校周期定期标校,并按标校气样标校。矿井标校不规范行为有:在上传的数据中,将传感器的正常状态修改为标校,导致传感器标校状态持续时间过长;未按标校周期对传感器进行标校;1 次标校持续时长过短。
2.2 大数据分析模型抽象
通过分析煤矿违规操作行为的各种场景,找出每种违规行为内在的数据发展变化规律。抽象出每种违规行为的算法分析模型。研究煤矿传感器接入位置信息、传感器探头被遮挡、传感器数值不正常、人为下调传感器安装位置、传感器中断、无计划删除测点、传感器标校周期等违规操作场景的异常数据特征,分析数据的变化趋势,构建数据分析模型。
例如:当工作面在采煤时,由于开采导致大量瓦斯涌出,上隅角传感器T0、工作面传感器T1、回风巷传感器T2的瓦斯体积分数值均比较高;在非采煤时,瓦斯不再涌出,传感器T1、传感器T2的瓦斯体积分数值会在快速下降之后保持比较低的水平,而传感器T0则由于上隅角容易积聚瓦斯,瓦斯体积分数值呈缓慢下降的趋势。因此在整个生产过程中,传感器T1、传感器T2的瓦斯数据呈一致变化趋势,传感器T0则与之不同。
利用上述各传感器的数据变化特征,从数据变化幅度是否剧烈、数值同时上升/下降的占比、1 d 内数值变化频率方面,对传感器T0、传感器T1、传感器T2连续计算多天的数据,如果每天的数据都异常,则认为该传感器的位置异常,以此判断传感器T0、传感器T1、传感器T2的安装位置是否正确,或以此来判断是否存在违规操作行为。每种违规场景都抽象出相应的判断算法,为大数据分析识别模块的开发做准备。
2.3 数据的清洗与转换
以煤矿安全监测联网数据为基础,通过大数据的手段对可能出现的违规操作行为场景进行分析。首先通过对集团联网平台原始数据文件进行实时记录留存,类似飞机黑匣子的功能,实时记录所有监控系统运行原始数据,作为以上违规操行行为分析的数据来源。实现与基于大数据的煤矿违规行为分析识别系统的数据对接。
该过程将使用Hive 工具对海量数据进行数据提取、转换与加载[3-4],即ETL 操作。Hive 定义了简单的类似SQL 的查询语言,即HiveSql。论其本质,Hive其实针对SQL 语句进行翻译、解释,它能够将用户输入的HiveSql 语句转换成MapReduce 作业,并在Hadoop 集群上运行。一般情况下,数据仓库分为ODS、DW 2 部分。通常的做法是从业务系统到ODS做数据清洗,将脏数据和不完整数据处理掉,再从ODS 到DW 的过程中做数据转换,进行不同业务规则数据的计算和整合。数据ETL 处理过程如图2。

图2 数据ETL 处理过程Fig.2 Data ETL processing process
2.3.1 数据清洗
数据清洗的目的是处理掉那些不满足计算统计要求的各类数据,主要包括残缺的数据、错误的数据和冗余的数据3 大类。
1)残缺的数据。即信息不完整,存在局部数据缺失的数据,如监测值、采集时间等。需要将这一类数据过滤出来,处理掉。
2)错误的数据。产生原因是业务系统不够健全,比如超量程数据、日期格式不正确、日期越界等。
3)冗余的数据。数据时间相同、值相同的数据记录,需将重复的数据的记录去除,只保留1 条。
数据清洗是一个不断持续的过程,不可能在短时间内完成,而是随着数据的采集,不断地发现问题,处理问题。对于清洗之后的数据,可写入文本文件或数据库,以做日志存储备份,也可以作为将来验证、改进数据来源的依据。
2.3.2 数据转换
数据转换主要是对数据格式、数据密度、业务规则不一致的数据进行一些格式转换、密度调节、规则转换的处理。
1)数据格式转换。数据格式不一致的数据转换主要是一个格式统一的过程,将不同业务系统的相同类型的数据按照规定的统一格式进行转换处理,本系统只抽取煤矿安全监控系统的联网数据,不存在不一致数据的转换。
2)数据密度转换。安全监控联网系统数据一般存储非常详细的数据,而数据仓库中的数据是用来做分析、统计的,不需要非常详细的数据,所以,需将安全监控联网系统数据按照数据仓库设定的密度进行聚合。
3)业务规则不同的数据类型转换。这个类型的转换有时不是简单的加减操作就能完成,需要在ETL 操作中将各业务规则数据进行计算,然后存储在数据仓库中,最后为MapReduce 阶段的计算、分析做准备。本系统数据来源、业务规则单一,不需要进行业务规则的数据类型转换。
2.4 分析识别模块
基于hadoop 的MapReduce 进行分布式运算程序的开发[5-8],实现海量数据的分析、统计。MapReduce 编程模型只能包含1 个Map 阶段和1 个Reduce 阶段。第1 个阶段的MapTask 并发实例,完全并行运行,互不相干;第2 个阶段的ReduceTask 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask 并发实例的输出。MapReduce 关系图如图3。
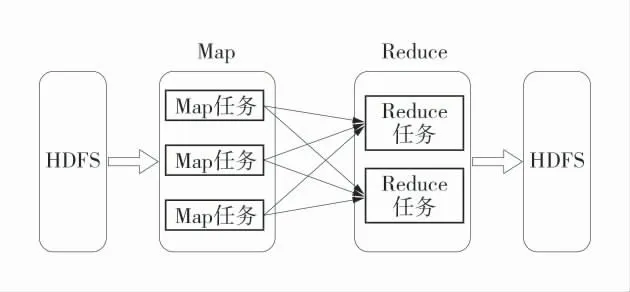
图3 MapReduce 关系图Fig.3 MapReduce diagram
1)Map 任务开发。首先基于JAVA 技术定义1个数据读取类MonitorDataReadMapper,并实现Mapper 接口map 方法,用于逐行读取清洗转换好的仓库里的海量安全监测联网数据。

2)Reduce 任务开发。类似与Map 开发,首先定义1 个JAVA 类MonitorDataReduce,并实现Reduce接口的reduce 方法,对Map 阶段处理之后的数据根据抽象出来的算法模型进行统计分析,找出各种违规场景风险点,并进行统计结果的输出持久化,供可视化展示。

3 分布式运行设计与计算
首先,准备3 台客户机,在每台客户机上安装JDK1.8,并配置环境变量。再安装Hadoop,并配置相应的环境变量,最后配置集群[9-10]。启动集群上的每个数据节点,保证整个集群的正常运行。集群节点关系图如图4。

图4 集群节点关系图Fig.4 Cluster node diagram
将2 开发好的MapReduce 程序放在集群里运行。前提需开发1 个驱动类MonitorDataDriver。public class MonitorDataDriver{

最后通过Maven 生成JAR 包,并拷贝该JAR 包到Hadoop 集群。执行[syccri@hadoop102 software]$hadoop jar MonitorData.jar com.syccri.monitordaaa.MonitorDataDriver 命令,最终生成想要的分析统计,计算结果。
4 结 语
通过对大数据技术、算法模型、仓库技术、分布式技术的研究,建立大数据开发、分析环境。通过对变换传感器接入位置、遮挡传感器探头、篡改上传数值、人为下调传感器安装位置、中断传感器数据、无计划删除测点、传感器假标校等违规操作行为所产生异常数据的内在规律性进行分析,建立大数据数学分析模型,开发大数据分析模块加以分析、识别,是行之有效的技术手段,能够助力安监部门监察煤矿企业违规、违法操作行为,现场精准取证,消除安全隐患。
