基于预聚类主动半监督的作战体系效能评估
2022-05-23杨镜宇
马 骏, 杨镜宇, 吴 曦
(1. 国防大学研究生院, 北京 100091; 2. 国防大学联合作战学院, 北京 100091)
0 引 言
作战体系,是“由各种作战系统按照一定的指挥关系、组织关系和运行机制构成的有机整体”。作战体系的效能指标,是衡量作战体系在作战环境中完成任务的能力,是对作战体系达到军事行动目标程度的评价标准。对作战体系效能指标的度量和计算,是评估作战体系效能的基础。
作战仿真实验,是研究作战体系的有效手段。目前,基于作战实验结果对作战体系效能评估通常采用定性定量相结合的方法。为了达到对作战体系分析的目的,通常需要作战仿真实验产生大量仿真实验数据,而后依靠专家在实验数据的基础上结合自身认知做出评估。但是,单纯依靠专家对作战体系效能进行评估需要耗费巨大的人力和物力,通过计算机辅助是高效度量作战体系效能指标、评估体系效能的重要途径。
半监督学习(semi-supervised learning, SSL)是给定未知分布的样本集=∪,其中包括有标签样本集={(,),(,),…,(,)}和无标签样本集={+1,+2,…,+},求解:→,以到达通过预测标签的目的。其中,∈是维向量,∈是的标签,为样本集包含的样本数,为样本集包含的样本数。在求解算法模型的过程中,充分利用有标签样本和无标签样本,使得该算法模型比仅使用有标签样本获得更好的性能。
主动学习(active learning, AL)是一种构造训练数据集的方法,其基本思想是,由学习算法主动选择包含信息量较高、对学习任务贡献度较大的未标记样本提供给专家进行标注,将标注后的样本加入训练样本集,并进行下一轮迭代运算,从而大幅减少训练样本规模并提高模型性能。
SSL和AL所要解决的问题具有相似性,都是在少量有标记样本基础上,通过利用大量无标记样本提高学习器的准确率,减少专家标记样本的工作量。SSL和AL结合形成主动SSL,是提高学习器泛化性能、减少人工标记成本的有效方法。
应用AL和SSL的方法解决作战体系效能指标评估问题主要存在以下问题:一是评估作战体系效能指标的初始训练阶段,通常没有有效的训练样本,使用AL构建数据集时,一般采用随机的方式选取部分未标记样本进行标记,选取的数据缺乏代表性,难以完整反映所有数据样本的特征,影响训练效率;二是目前关于主动SSL的研究,都是在流程方面对两种机器学习方法进行结合,但训练数据时仍单独训练各自的学习器,增加了训练开销。本文针对上述问题,提出一种基于预聚类主动SSL的作战体系效能指标评估方法,并将其应用于作战体系效能指标评估。
1 相关概念
1.1 SSL
SSL依赖以下假设:① 平滑假设,两个位于稠密数据区域且距离很近的样本具有相似的标签;② 聚类假设,两个位于同一聚类簇的样本很大概率具有相同的标签;③ 流行假设,将高维数据嵌入到低维流形中,当两个样本位于低维流形中的一个局部邻域内时具有相似的标签。当模型假设正确时,无标签样本能够促进学习性能。
SSL按照应用场景可以分为:半监督分类、半监督回归、半监督聚类、半监督降维。基于作战仿真实验的体系效能评估结果,是军事专家根据实验数据并结合自身认知做出的量化判断,本文第2部分提出了自顶向下的体系效能评估模式和二值化的评估标准,因此本文主要涉及SSL的分类方法。
半监督分类主要有基于分歧的方法、生成式方法、判别式方法和基于图的方法等。由于性能优越,基于分歧的半监督分类方法得到了广泛的应用,并出现了大量变形。文献[7]在协同训练的基础上,提出了Tri-training方法,该方法同时训练3个学习器,以投票的方式获得标签的置信度(如果两个学习器对同一个无标签样本的预测结果相同,则认为该标签有较高的置信度,并将该数据及标签加入第3个学习器的训练样本中),在一定程度上放宽了协同训练方法要求的视图充分冗余假设和条件独立假设,并证明了该方法能够有效利用无类标签样本提高学习器的性能。
1.2 AL
AL的算法模型可表示为
AL=(,,,,)
(1)
式中:表示学习器;为有标签样本;为无标签样本;为查询策略,用于在无标签样本中查找信息量大的样本;为督导者,能够对无标签样本进行标记。
如图1所示,AL的过程可以分为两个阶段:第一阶段是初始化阶段,首先利用有标签样本训练一个或多个学习器;第二阶段为循环查询阶段,使用查询策略从无标签样本中选择一批样本交由督导者进行标记,标记后加入样本中,并利用新的更新学习器,依照此步骤不断迭代更新,直至到达停止条件。
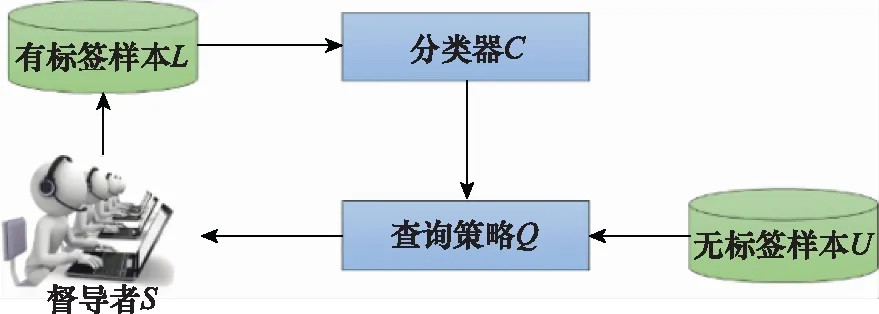
图1 AL的一般过程
查询策略是AL的核心,由于查询策略的不同,演变出多种AL算法。用于分类问题的AL算法包括:基于委员会的查询(query by committee, QBC)方法、基于边缘的查询方法、基于后验概率的查询方法等。其中,基于QBC是一种有效的AL方法,并成功应用于多种分类问题,该方法通过训练一组学习器组成委员会,利用委员会中每个成员对未标记样本进行预测,选取预测结果中最具差异性的样本交由专家标记。
1.3 主动SSL方法
SSL和AL所要解决的问题具有相似性,都是在尽量减少样本的情况下提高学习器的准确率,但两者存在着一定差别:一是对无标记样本选择的标准不同,SSL选择置信度最高的无标签样本进行标记,AL则选择差异最大的样本进行标记;二是对无标记样本的标记方法不同,SSL对未标记样本进行自动标记,AL则需要人工标记。
SSL和AL结合形成主动SSL方法,是提高学习器泛化性能、减少人工标记成本的有效方法,并在各领域得到了广泛应用。文献[11-13]等在SSL的迭代过程中引入AL,通过人工标记增加SSL样本;文献[14-16]等在SSL中引入AL的思想,用以指导SSL过程中新增样本的选择过程,这类方法不需要对主动选取的样本进行人工标记而是对其进行自动标记。
2 作战体系效能的评估思路
2.1 基本评估流程
对作战体系效能的评估通常是在仿真实验产生的大量结果数据基础上,通过专家的定性定量分析,针对每次仿真实验的方案和结果做出评估,如图2上半部分所示,其过程单纯依靠专家进行,代价较大。
本文提出的基于预聚类主动SSL的作战体系效能评估方法,专家仅需在大量仿真实验结果中评估少量样本,通过这些样本训练评估方法,在评估方法达到预期的评估准确率等指标后,使用训练好的评估方法对剩余大量样本进行评估,极大地减少了专家的工作量,使用该方法进行作战体系效能评估的过程如图2下半部分所示。

图2 作战体系效能评估流程图
2.2 自顶向下的体系效能评估模式
对作战体系效能的评估是一种总体的、综合的评估,是运用系统的、定量的研究方法搜集证据、分析资料,依据实验结果判断预期军事目的完成的程度。该过程表示为
=(,,…,,…,)
(2)
式中:是通过作战仿真实验获取的各类实验结果数据;是对作战体系效能的评估结果;过程(·)是通过实验结果数据得到体系效能评估结果的具体方法。从(·)产生评估结论的思维模式看,可将其分为自底向上的评估模式和自顶向下的评估模式。
(1) 自底向上的评估模式。该模式是一种由部分到整体的评价思维。首先,需要根据实验目的和研究重点,建立评价的指标体系;而后,根据仿真实验数据,计算得到对这些指标的度量;最后,通过各种聚合方式将这些指标综合形成总体评估结果。
(2) 自顶向下的评价模式。该模式是一种由整体到部分的评价思维。专家根据实验结果并结合自身的感性认知首先形成整体“印象”,即评价结论,在此基础上分析造成这一结果的具体原因以支撑后续实验。
自底向上的评估模式是基于统计学知识的评价模式,通过专家知识建立评估指标体系和各类指标的综合方法,这种模式下,(·)是显性的,得到体系评估结论的主要工作在于合理的构建指标体系和指标综合方法。
自顶向下的评估模式是基于人类认知规律和思维习惯的评价模式,通过该模式获得的评估结论中“隐含”信息更为丰富,它不仅包含了实验方案中打击情况、毁伤情况等各类“硬”指标,也包含了专家通过作战态势形成的宏观认知等信息。这种模式下(·)是隐性的,得到评估结论的主要工作在于建立合理的(·)。本文提出的基于预聚类主动的作战体系效能评估方法,即在该模式下根据实验数据和少量专家评估结果,通过机器学习的方法构建(·)的过程。
2.3 二值化的评估标准
采取自顶向下评估模式产生的整体评估结论是定性的,例如,实验方案的“好”“不好”“一般”等,这种定性的结论难以用于定量的计算。评价系统是将评价结论从定性转化为定量的有效方式。随着互联网商业的发展,评价系统已经得到了广泛的应用,评价系统中,用户将自己的感受以分值的形式进行量化。
评价的量化有连续和离散两种方式:连续的方式是将用户感受对应到某一数值区间中的任意可行值,如,将最佳状态定义为10分,最差状态定义为0分,用户可以根据自身感受给出[0,10]区间内任意分值。离散的方式是将用户的感受对应到若干评价等级,常用的是“星级评分”的方法和“点赞”的方法。
相比于其他方法,点赞的方法有以下优势:一是去除了评价的模糊区,使机器学习算法更有效。例如“3颗星”之类的中庸评价使机器学习的效率很低,而“非黑即白”的评价标准可以有效消除评价中的模糊地带。二是有效降低了用户评价的成本。2选1的方式相对于5颗星的方式或0~10分的打分模式更容易做出判断。
本文在对作战仿真实验结果进行评估时,采取二值化的评估标准,专家将其满意的仿真实验结果评价为“1”,将不满意的评价为“0”,以减轻专家评价难度并提升机器学习效率。
3 预聚类主动SSL方法
3.1 算法思路
本文将Tri-training SSL方法与QBC AL方法结合起来,并根据作战仿真实验数据的特点,提出一种基于预聚类的主动SSL的实验结果评价方法,主要解决了以下问题:
(1) 主动SSL算法在作战仿真实验应用中的“冷启动”问题。主动SSL需要一定数量的有标签样本L作为初始条件,而作战仿真实验数据在专家评定前都是无标签数据,对于使用主动半监督方法来说是“冷启动”问题。通常基于QBC的方法通过首轮随机取样的方式,从无标签样本中选择若干交由专家标记,但是在随机挑选数量有限的情况下,往往难以挑选出能够完整反映数据所有类别属性的样本。例如,在组作战仿真实验结果中挑选组样本(≪)由专家评定,若专家对这组样本都不满意,给出相同的标签,那么初始样本集就无法反映出专家满意情况下的样本数据特征。本文采取聚类的方法,首先对实验结果数据进行聚类处理,在每类中选取一定数量的样本作为初始训练样本交专家评定,在一定程度上解决了由于随机取样造成的首轮询问样本特征不完整的情况,提高了学习器初始训练的性能。
(2) 主动SSL算法的改进。文献[14]通过对样本密度计算,改进基于投票熵(vote entropy,VE)的QBC算法,并与SSL相结合;文献[16]基于Tri-training和熵优先采样提出了一种主动SSL算法。从研究情况看,都是在算法流程上将AL与SSL进行了结合,而对两种学习算法中的学习器都是进行单独训练。本文将Tri-training算法和QBC算法的学习器同时进行训练,优化学习流程、提高训练效率。
基于预聚类的主动SSL算法基本流程如图3所示。主要步骤可分为3部分:第1部分是基于聚类的数据初始化;第2部分是基于VE的QBC AL,得到基于AL的新标记样本;第3部分是基于Tri-training的SSL得到基于SSL的新样本。

图3 预聚类的主动SSL算法流程图
3.2 基于聚类的数据初始化
基于聚类的数据初始化是为了高效挑选初始化样本集进行专家标注,并利用已标注样本训练SSL和AL算法的公用学习器,其过程描述如算法1所示。

算法 1 基于聚类的数据初始化算法输入 初始未标记数据集U={x1,x2,…,xu},聚类数目k,每类中选取的样本个数m,专家对km个样本的标注y。输出 初始化后的学习器H,有标签样本集L。步骤 1 聚类运算。将数据集U分别对应到k个聚类Ck中。步骤 2 计算聚类簇Ci的簇中心Ri(i=1,2,…,k)。步骤 3 计算各聚类中,样本到聚类中心Ri的距离:r(x)=distance(x,Ri)其中,distance(·)代表样本间的欧氏距离。步骤 4 在每种聚类中,选取距离簇中心Ri最近的m个样本,组成初始待标记样本集:U'={xC11,xC12,…,xC1m,xC21,xC22,…,xC2m,…,xCk1,xCk2,…,xCkm}步骤 5 专家对U'进行标注,形成初始标记样本集L':L'={(xC11,yC11),(xC12,yC12),…,(xC1m,yC1m),(xC21,yC21),(xC22,yC22),…,(xC2m,yC2m),…,(xCk1,yCk1),(xCk2,yCk2),…,(xCkm,yCkm)}步骤 6 将L'加入有标签样本集L。步骤 7 使用L'训练学习器H。
3.3 基于VE的QBC AL算法
基于VE的QBC AL算法,首先利用有标签样本训练两个或多个学习器组成委员会,而后利用委员会对未标记样本进行预测,计算委员会各成员对未标记样本的预测结果的VE,对某一样本投票的不一致性越大,则VE越大,说明该样本具有更丰富的信息量。因此,选取VE最大的样本交由专家标注,并将专家标注后的样本加入有标签的训练样本集,对委员会进行更新训练。
VE的计算公式为
()=

(3)
式中:()为委员会对样本的VE;(,)为样本属于类别的投票数;为学习器的个数(委员会成员个数);||为样本的类别个数。1logmin (,||)为归一化系数,使()的值在[0,1]之间。当||=1时,即所有学习器对样本投票一致,此时()=0。
3.4 基于Tri-training的SSL算法



(4)



(5)
可通过式(5)推出:

(6)


(7)
式中:-1需要满足下式,即保证仍大于|-1|:

(8)
3.5 算法步骤
为了使基于VE的QBC算法与Tri-training算法公用学习器,将QBC算法中委员会个数设置为3个,即=3。在使用该算法之前,根据应用的需要设置合理的终止条件,比如,算法的分类精度达到某一阈值、询问专家的次数或询问样本数达到一定限制、对未标记样本已完全标记等,在此基础上进行迭代计算。算法的整体步骤描述如算法2所示。

算法 2 基于预聚类主动SSL的实验结果评价算法输入 未标记数据集U,每轮询问专家的样本数量batch_size_AL,每轮由SSL标记的样本数batch_size_SSL,专家对询问数据进行的标记,算法终止条件。输出 学习器H,有标签样本集L。步骤 1 执行聚类初始化程序。得到初始化之后有标签样本集L={(x1,y1),(x2,y2),…,(xl,yl)},无标签样本集U={xl+1,xl+2,…,xl+u},以及初始训练后3个学习器H1、H2、H3。步骤 2 执行AL算法。

步骤 2.1 用3个学习器分别预测未标记数据集U的标签。步骤 2.2 用式(3)计算U中各样本的VE E={Exl+1,Exl+2,…,Exl+u}。步骤 2.3 选出E中VE最大的batch_size_AL个样本XAL(XAL∈U)交由专家标注,形成专家标注样本集LAL。同时选出VE最小的batch_size_SSL个样本XSSL(XSSL∈U,XSSL∩XAL=⌀)交由SSL标记。步骤 2.4 更新L和U,使L=L∪LAL,U=U-XAL。步骤 3 执行Tri-training算法。步骤 3.1 初始化,分别对3个学习器采取如下操作:步骤 3.1.1 按照Bootstrap对L进行采样,得到样本Si。步骤 3.1.2 用Si训练学习器Hi。步骤 3.1.3 将Hi的初始分类错误上限e'i赋值0.5,l'i赋值0。步骤 3.2 执行如下操作,直至3个学习器都不再变化:步骤 3.2.1 判断每个学习器Hi(i∈{1,2,3})是否需要更新。① 用Hj和Hk的预测结果计算分类错误率ei,其中j,k≠i。② 如果ei
通过上述过程,使实验结果数据与专家的评价信息形成了有效映射,将专家对实验结果的评价知识融入到了训练后的学习器中。在针对同一案例或相似案例的后续应用中,可以使用已训练好的学习器,对实验数据进行快速评定,为大规模仿真实验提供方案评价的基础。
4 实验与分析
4.1 数据获取
411 想定背景
以红方某区域防空预警能力的分析任务为背景,评估红方防空预警体系在不同防御方案下对蓝方多种入侵策略的整体效果。实验依托“体系仿真试验床系统”进行,红方部署任务区域相关的作战力量,主要包括相关预警装备、拦截装备,并建立完善的指挥控制体系;蓝方主要包括各型空中入侵装备。
412 想定方案
红方在现有预警体系基础上,共设计3种防御方案;蓝方为达成入侵目的,共设计4种入侵策略,如表1所示。为分析红方预警体系在各防御方向上的整体情况,蓝方每种入侵策略共选择100个入侵参数。共形成1 200组想定方案。

表1 实验方案描述
在通过仿真系统获取每组想定方案的仿真结果数据后,使用本文提出的方法,在专家标注部分样本的基础上对所有方案的实验结果进行标注。
4.1.3 数据描述
仿真实验结果数据主要选取评价防空预警体系能力相关的以下数据(总计18项),包括:对目标首次探测数据(共5项,包括探测到目标的经度、维度、高度等3项位置信息,和速度、方向等2项运动信息)、对目标的首次识别数据(共7项,包括识别目标的位置信息、运动信息,以及目标的敌我、识别型号等信息)、对目标的首次拦截数据(共6项,包括目标被打击时位置信息、运动信息,以及目标的毁伤情况)。
评估数据共1项,专家借助态势回放、数据监控等手段,根据对仿真实验结果的满意程度给出“满意”或“不满意”两类标签。本次实验共选择6名在校军事学研究生、2名专业领域教员组成专家组,并在标注开始前对评价标准进行了统一。每名专家对50个实验结果进行标注,共形成有标签数据400个。按照75%的训练集与测试集的划分比例,选择其中300个样本作为训练集,其余100个作为测试集。
4.2 实验设计
4.2.1 评价标准
对算法在作战体系效能评估中的效率指标和准确率指标进行分析。效率指标一是比较各算法在本实验数据中的询问次数;二是分析标注速度,计算标注每个样本的平均使用时间,比较机器与专家的标注效率。准确率指标以标注结果的认可度进行分析,认可度是专家对机器标注样本的认可程度,通过挑选部分机器标注样本由专家评判,计算专家认可的样本数占样本总数的比例。
4.2.2 实验方案
分别对比AL、基于AL的Tri-training算法(AL-Tri-training, ALTT)以及基于预聚类的主动SSL算法(pre-clustering ALTT, PCALTT),在相同初始化条件和相同AL模式下的效率指标,以及PCALTT算法的准确率指标。
4.2.3 预聚类算法选择
聚类算法有较多类型,其中-means由于简单、运算速度快等优点得到广泛应用,但-means需要在聚类前指定将样本分为几类,即值。在作战仿真实验的应用中,可知评估数据有2种类型,可以明确将仿真实验数据分为2类。因此,采用-means算法对数据做预聚类。
4.2.4 分类器选择
原始Tri-training算法通过在初始化时采用Bootstrap可重复采样,使3个相同的分类器产生差异,文献[18]通过实验证明了使用分类效果接近且分类算法不同的分类器组合能获得较高的分类准确率。本文使用2个决策树分类器和一个由决策树集成的随机森林分类器的组合验证算法的有效性,各分类器算法基于Scikit-Learn实现。
4.3 实验分析
4.3.1 效率分析
(1) 各算法询问次数对比分析
比较AL、ALTT、PCALTT 3种算法在本实验数据集中的询问次数差别。初始化时,以数据类别数作为聚类的簇中心个数,每个聚类簇选择与数据属性数等量的距离簇中心最近的样本点进行标注,即算法1中=数据类别数×数据属性数,选择2×18=36个样本进行训练。每轮迭代中询问专家的样本数、以及SSL标记的样本数均等于数据的类别数2,即基于算法2中,batch_size_AL=batch_size_SSL=2。设置预期分类精度为90%。对数据集进行100次重复实验,统计数据如表2所示。

表2 询问次数实验结果
从表2中可知,在某区域防空预警能力的分析任务中,达到相同预设精度的条件下,本文提出的PCALTT算法与AL算法和ALTT算法相比可以有效减少AL的询问次数,询问次数减少率超过30%。从其询问次数的分布来看(见图4),在多次重复实验中,PCALTT询问次数的方差也较其他算法有一定改善。

图4 询问次数分布
(2) 标注速度对比分析
用计算机统计专家对单个任务评价所用的时间(从选取某实验结果开始计时至给出评价结论为止),各位专家评价时间统计情况如图5所示,可见各位专家在评价前7~10个左右任务后,评价效率趋于稳定并随着评价任务的增多逐渐提高,最终每个任务平均用时在36 s左右。

图5 专家标注时间统计
在已训练好的模型基础上,利用PC机(配置CPU:Intel i7-8700,内存:16 G,显卡:NVIDIA GeForce GTX 1050 Ti)对剩余800个未标记样本进行自动标记,用时均小于1 s,效率远远高于人工标注。
通过上述实验说明基于预聚类主动SSL方法能够在保证标注精确度达到90%以上的前提下,极大提高标注效率。
4.3.2 准确率分析
用基于实验数据训练好的PCALTT模型对剩余的800个未标记实验数据进行预测,随机选择其中400个数据,将数据按照50个为一组分给8位专家进行判断,各位专家对数据的认可度如表3所示。各位专家对算法预测结果的平均认可度为92.3%,与训练模型时设置的准确率门限相似并高于训练准确率。证明了该方法在作战仿真实验结果评估应用中的有效性。

表3 对实验结果认可度
5 结 论
评估作战体系效能是作战实验的重要环节,是对作战行动、作战方案等进行实验分析和优化的基础,有着十分重要的意义。通常,对作战体系的效能评估依靠专家建立指标体系、并根据专家认知对指标进行综合计算,这种方法难以适用于大规模的探索性仿真实验。本文提出一种基于预聚类主动SSL的作战体系效能评估方法,通过机器学习的方法建立仿真实验数据与专家评估结果之间的关系,在机器与专家交互迭代的过程中获取专家知识,使计算机通过学习少量有标注样本完成对大量仿真实验数据的自动标注,解决依靠专家评估代价昂贵的问题。通过防空预警能力分析任务的仿真实验数据,验证了本文提出的方法在作战仿真实验数据中的有效性,具有一定实用价值。
