基于日前披露数据相似性的电力市场出清价格预测方法
2022-05-21杨乘胜张世超朱海东赵竟张永涵张庭玉
杨乘胜,张世超,朱海东,赵竟,张永涵,张庭玉
(1.南京华盾电力信息安全测评有限公司,江苏 南京 210000;2.中国华电集团有限公司,北京 100031;)
随着国内电力市场的有序推进,我国的电力市场已初具规模。在电力市场现货交易的场景中,市场出清价是整个电力市场的核心要素之一,是直接影响发电侧利润与竞标策略的重要参数。
当前电力市场出清价格预测研究中一个经典的预测方法就是使用历史连续序列进行预测[1]。基于电力市场的模糊性以及动态变化的随机性,灰色系统理论也常被应用于负荷预测和电价预测中[2],文献[3]提出了一种基于数据挖掘与支持向量机的出清价格预测方法。文献[4]应用多日机组数据和日前出清环节数据,提出了一种组合模型优化安排系统机组开机方式。文献[5]则是采取了奇异值分析结合机器学习方法进行预测的方法。
随着深度学习的发展,一系列时间序列预测的深度学习模型也开始应用于电力市场中。文献[6]提出了一种基于经验模式分解与LSTM的序列电价预测模型。文献[7]采用最大信息系数相关性和改进多层级门控的方法对LSTM模型进行改进,提升了短期电价的预测精度。此外,还有使用DeepESN[8],Attention-GRU[9]等深度神经网络模型进行电价预测的研究方法,也都在相应的场景中取得了不错的效果。
然而,国内的电力市场起步较晚,各区域电力市场政策不统一,难以形成统一的标准的数据集。此外,国内电力市场的历史数据普遍不公开,导致现有的数据量较少。因此很多基于大数据的电力市场出清价格预测模型难以在这类小样本数据上达到良好的效果。为了实现小样本和不连续数据上的出清价格预测,本文提出了一种基于日前披露数据相似性的电力市场出清价格预测方法,并在某区域电力市场交易的试运行数据上进行了测试,通过实验证明了本文方法的有效性。
1 日前披露数据分析
1.1 指标相关性分析与数据筛选
在电力市场出清价格预测问题中,日前披露数据信息对于市场报价预期有着重要的影响,如负荷预测、装机容量、停运预测等供需信息的披露能够对当前的市场环境有较为准确的判断[10-11]。然而,在数据量有限的情况下,机器学习和深度学习算法难以对数据的规律进行无偏差的估计[12]。国内的电力市场交易普遍处于试运行阶段,不仅数据量有限,而且通常在运行一段时间后就会暂停运行,使获得的数据集出现时间不连续的情况[13],因此一些基于时序分析的预测算法也不能达到很好的预测效果。
相比于机器学习和深度学习等方法,基于日前披露数据相似性的预测方法对于数据量的要求相对较低,只要相似度算法得当,就可以达到较好的预测结果,不会出现因为训练数据不平衡而导致过拟合或者欠拟合问题。
在日前披露数据中会公布每日的负荷、电价、需求值等相关数据,组成一个y= (x1,x2,……,xn)的向量用于描述当日的特征。如图1所示,本文计算电力市场交易日前披露数据各指标间的相关性,通过相关性矩阵可以发现日前出清价格与各项指标数据之间具有不同的相关性程度。而在日前披露数据中,某日各项指标数据与待预测数据各项指标数据相似的情况下,日前出清价格也具有一定的相似性。

图1 相关性分析图Fig.1 Correlation analysis chart
由于某些指标数据与日前出清价格的相关性较弱,在预测时引入这些因素,反而可能会影响预测的精度。根据统计学中的相关性原则[14-15],当相关性的绝对值小于0.4时,则可以认为二者的相关性较弱甚至不具备相关性;当相关性的绝对值大于0.4且小于0.6时,说明二者具有一定的相关性;当相关性的绝对值大于0.6且小于0.8时,说明二者具有较为明显的相关性;当相关性的绝对值大于0.8时,说明二者已经具有很明显的强相关性。因此本文在进行日前出清价格预测前,预先对日前披露数据进行了处理,只选择了相关性大于0.4的指标数据用于相似性的计算,以降低无关指标数据对于预测的影响。
通过相关性分析的结果可以看出,日前出清价格与多项指标都具有一定的相关性,并且日前出清价格与各项指标数据间也并非是一种单一的线性对应关系[16-17]。简单的用某项单一的影响因素来预测日前出清价格就会出现很大的局限性,因此单一的模型就难以实现准确的预测效果[18]。而电厂中存在的指标数据类型繁多,各项指标数据对于日前出清价格的影响也各不相同,盲目地将所有指标作为日前出清价格的影响因素会降低强相关指标数据对于日前出清价格的影响权重,从而导致预测效果受到干扰。
1.2 历史披露数据分析
相比于机器学习和深度学习等算法,尽管基于日前披露数据相似性的预测算法对于数据量的依赖要更小,但历史数据的质量同样会影响预测结果,若数据过少或涵盖范围过于局限,难以找到与待预测数据近似情况或能够查找到的最近似数据与待预测数据的结果差距过大,这些情况都会影响最终的预测效果。
为了保证算法的可行性,确定历史披露数据能否足够支撑预测工作,本文通过层次聚类方法对历史披露数据进行聚类分析,将历史数据按照日前出清价格分为若干个组。日前披露数据每15分钟进行一次测点记录,每天产生96条测点数据。由于数据存在不完全连续的情况,本文使用了2020年8月、11月和12月三个月的数据进行了分析,并用前71个自然日的测点数据模拟历史数据,以12月后21个自然日的测点数据模拟待预测数据。如表1、表2所示,分别统计了模拟历史数据和模拟待预测数据的出清价格分布情况。

表1 模拟历史数据出清价格区间分布情况Tab.1 Distribution of clearing price range of simulated historical data

续表1

表2 模拟预测数据出清价格区间分布情况Tab.2 Distribution of clearing price range of simulated forecast data
通过聚类分析可以发现,日前出清价格多集中在中低价格段,价格极高的极端情况相对较为少见。在模拟历史数据中,价格高于400的数据占比仅为2.6%。在模拟的测试数据中,高于400的数据占比仅为1.9%。因此根据聚类分析的结果可知,2020年8月、11月和12月三个月中前71个自然日的模拟历史数据基本已经能够涵盖模拟预测数据中的绝大部分情况。尽管当前的试运行数据较少并且不连续,但是历史数据仍然对日前出清价格的预测有着较为重要的意义。
尽管模拟历史数据中某些情况较为少见,如日前出清价格在800-900、1035-1200以及1248-1400等区间段时,缺少可用的历史数据进行支持,因此若待预测数据出现在这些区间时,算法就不能准确地预测出日前出清价格。但是通过观察模拟的待预测数据可以发现,在这些区间内分布的数据同样不常见,出清价格高于800的情况,在模拟历史数据占比仅为1.1%,而在模拟预测数据中占比甚至不超过1%。即使出现了类似的情况也可以在这类情况发生后将该情况添加到历史数据中,为后续的预测提供经验。从数据的分布情况上可以看出两个月左右的历史数据基本可以满足预测的需要。
为了增强算法的预测能力,每当出清价格结果更新时就将该条记录加入到历史数据库中,这样即使某一天的待预测数据中出现了历史数据中没有的情况,也可以及时将这种情况记录下来,为后续的预测提供指导。随着历史数据库的扩充,历史数据中涵盖的数据指标的组合情况也会更加丰富,预测的精度和准确性也就进一步提高。
2 基于日前披露数据相似性的出清价格预测
2.1 相关系数确定
传统的相似日法中需要对各影响因素相似度的权重进行赋值[19]。在电力市场出清价格预测问题中,人工赋值的方式极大地依赖于研究者的市场经验,若研究者的市场经验不足,那么设置的参数就可能不合理。并且不同市场情况存在差异,某一地区的市场难以适应其他地区的市场,尤其在面对复杂市场情况时,已有经验也很有可能出现偏差。
本文使用皮尔森相关系数来衡量各指标与日前出清价格之间的相关性程度,以确定各指标数据对日前出清价格的影响[20]。使用相关系数分析方法确定的参数值能够根据市场的实际情况进行动态调整,通过自适应的求解参数可以增强算法的准确性和通用性,避免了人为经验赋值对预测结果造成的偏差,将不同的指标类型对于日前出清价格的影响程度进行量化,并且参与到实际的相似性计算之中。

(1)
为了解决各项指标数据与日前出清价格之间相关性程度不同的问题,本文将各指标数据与日前出清价格的相关性进行了量化处理并作为相关系数参与到了相似性的计算当中。
由公式(1)可知,相关性的计算结果取值范围处于[-1,1]之间,当指标数据与日前出清价格的相关性绝对值越接近1时,说明该指标对日前出清价格的影响程度就越大。由于指标数据与日前出清价格的相关性程度会影响到数据之间相似性的计算,因此在计算相似性时就需要将各指标数据与日前出清价格的相关性考虑在内。
当某项指标数据与日前出清价格的相关性越高时,该指标数据的计算结果对相似性的影响要高于与日前出清价格的相关性较低的指标。当待预测数据与历史数据中两种指标的距离相同的情况下,与日前出清价格相关性更强的指标对两条数据相似性程度的决定权重更高。
ξ(x,y)=1-|r|
(2)
本文基于指标数据与日前出清价格的相关性,建立了一种相关系数计算方法。如公式(2)所示,ξ(x,y)为指标数据与日前出清价格间的影响系数,r为指标数据与日前出清价格间的相关性计算结果。当历史数据与待预测数据中的某项指标具有较强的相关性时,其相关系数越小。在指标数据的差值上乘以该相关系数会使两个数据在该指标上计算出的距离变得更小,最终会认定相关性更强的指标对相似性的影响要更大。
2.2 相似性计算方法
本文提出的相似性计算方法是在对应指标数据上计算均方误差并乘以对应相关系数的方式,以此来衡量待预测数据与历史数据的差异程度。计算的结果越小就说明两个数据之间的相似性越强,日前出清价格也就越接近。
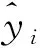

表3 相关系数样例Tab.3 Example of correlation coefficient
(3)
在进行预测时,算法会按照公式3给出的计算公式将待预测数据与历史数据库中的数据进行一一比对,并找到相似距离最低的历史数据,将该日期的日前出清价格作为预测结果。同样以上文中表3的情况为例,历史数据A与待预测数据的计算结果Sa就会变为ξa·(100-120)2+ξb·(50-50)2,最终的相似性距离Sa=400ξa。采用相同的计算方法,历史数据B与待预测数据的相似性距离Sb=400ξb。假设此处指标A与日前出清价格的相关性ra要强于指标B与日前出清价格的相关性rb。由本文2.1节可知,计算指标与日前出清价格的相关性程度越高,相关性系数越小,因此ξa<ξb,最终使得Sa 在进行计算的过程中,可能会出现多条历史记录与待预测数据的计算结果相似的情况,这时应当选取时间最接近待预测数据的历史数据作为最终结果。这是因为物理量的变化趋势更多地取决于历史时段中近期的发展规律,相比之下,远期的历史数据与待预测数据的相关性比近期数据更弱。尤其在试运行及电力市场探索阶段,由于交易规则、运营模式等情况的变动,交易用户会根据市场情况不断的调整各自的交易策略,这就导致不同时间段的市场交易情况都有所不同,而每个时间段内的交易情况会更加相似,因此近期的交易数据参考价值更高。 尽管直接采用历史日前出清价格作为预测结果会存在一定的误差,即使在两个数据极其相似的情况下,日前出清价格也会存在差异,但从聚类分析时可知,相似数据的存在的区域较为狭窄,基本都处在一个较小的值域之内,因此该方法还是能预测出一个较为准确的结果。并且随着交易数据量增多,历史数据的数量也会不断进行累积,在进行长期的预测时,实际的出清价格会不断地更新到历史数据库中,历史数据中包含的日前出清价格的涵盖范围也会增加,预测结果会不断得到修正,使最终得到的结果更加准确。 本文选取了某区域电力市场交易试运行数据上2020年8月、11月和12月三个月的数据进行了测试,以8月、11月以及12月前10天的数据模拟历史出清数据,对之后21天的出清价格进行预测。日前披露数据中包括了日前出清价格、负荷预测情况、机组容量情况、输送电情况等31项指标的情况,指标数据每15分钟进行一次更新记录,每天共有96条测点数据。经过相关性分析和历史披露数据分析等分析后,在原始数据的基础上,选取了与日前出清数据相关性绝对值大于0.4的指标项作为实验的样本。 本文在92天共计8832条测点数据上进行了实验,将前6816条测点数据模拟为历史数据,对后续2016个测点进行了预测,得到了如图2所示的结果。 图2 预测值与实际值对比图Fig.2 Comparison of predicted value and actual value 从图2中可以看出,本文提出的方法在实际的运用中具有较为准确的效果,尤其是在大多数较为规律的周期中,预测的结果都较为准确。但同样也有一些不准确的预测存在,如在一些含有突变点的测点位置,预测的结果会存在着少量的偏差。这是因为相比于具有较强规律性和周期性的负荷预测,电力市场交易还会在很大程度上受到竞争、供求关系等人为因素以及输电阻塞、网损或线损等环境因素的影响,进而产生“价格钉”的问题,表现出价格的随机波动性和突然跳跃性[21],尤其在风电[22-23]、水电[24]、光伏[25]等一些受环境影响因素较大的能源上表现更为明显,当发电负荷产生较大的波动时,就会直接反应在价格波动上[26-28]。当这些数据存在于历史数据中时,就会导致算法预测出的部分结果产生一定的偏差,将部分正常的日前出清价格预测为价格较高的价格钉。但与整体的预测结果相比,价格钉的情况本身就是一个较为少数的情况,在数据量较少的情况下,价格钉出现的频率也就更低,尽管可以通过人工合成样本增加价格钉出现的频率以提高对于价格钉的预测准确率,但伴随着人工合成样本比重的增加,这些样本会影响其他类型样本的预测准确率。 此外,本文搭建了一个SVR模型[29](支持向量回归, support vector regression)以及一个具有4个隐藏层的LSTM模型(长短期记忆网络, Long Short-Term Memory)用于算法效果的对比。其中LSTM模型的批尺寸为64,迭代次数为50次,采用adam作为优化器。 如表3所示,展示了三种算法在21天共计2016个测点数据上的均方根误差结果。 通过表4可以看出,在数据量少且数据中间存在时间不连续的情况下,基于日前披露数据的相似性的预测方法要明显优于其他两种方法。由于数据量和数据条件的限制,在实验的过程中SVR对于价格钉的预测出现了很大偏差,在数据波动和跳跃过大时,均不能准确的进行预测;而在LSTM模型中则出现了较为明显的过拟合现象,随着训练的进行,训练集的损失会逐渐减少,但用模拟的待预测数据的损失反而会增大,最终导致了预测结果的不佳。因此在国内现有电力市场数据较为缺乏的情况下,通过相似性模型来预测日前出清价格是一种较为合适的预测方法。 表4 三种算法比较结果Tab.4 Comparison results of three algorithms 本文运用了一种基于日前披露数据相似性的出清价格预测算法,通过在日前披露数据中寻找相似条件的历史数据,对出清价格进行预测。首先计算各指标数据与出清价格的相关性确定各指标对出清价格的影响权重,选出相关性大于0.4的指标作为影响因素。通过计算待预测数据各指标与历史数据各指标之间距离,结合之前计算出的各指标数据的权重,搜索到相似性最高的历史数据,最终给出预测结果。通过在某区域电力市场的交易数据上的实验结果,证明本文提出的方法在实际的区域电力市场交易应用中具有较好的精度和可行性。本文提出的方法基于统计原理,无需进行大量训练的过程,对于设备的性能要求较低,在工程实践中也有较好的应用和参考价值。2.3 实验与分析


3 结论
