在线协同研讨知识建构行为的自动分析研究*
2022-05-20何皓怡刘清堂关雪敏覃伟华
何皓怡 刘清堂 张 思 关雪敏 覃伟华
在线协同研讨知识建构行为的自动分析研究*
何皓怡1刘清堂2张 思2关雪敏1覃伟华3[通讯作者]
(1.广西民族师范学院 数理与电子信息工程学院,广西崇左 532200;2.华中师范大学教育信息技术学院,湖北武汉 430079;3.广西大学公共管理学院,广西南宁 530004)
为实现对在线协同研讨知识建构过程的动态跟踪与分析,文章采用文本分类方法,设计了“在线协同研讨知识建构行为自动分析实施流程”。以此流程为指导,文章以网络研修社区中教师工作坊的协同研讨活动为例开展实验,主要内容包括创建“教师工作坊知识建构行为编码表”、采集与整理交互文本数据、选择和提取文本特征、对训练集数据进行预处理、训练和评价分类模型、对分析结果的应用情况进行描述和解读。实验结果表明,在线协同研讨知识建构行为自动分析方法可为利益相关者深入理解协同知识建构过程并为此过程进行实时干预和调节提供支持。
在线协同研讨;知识建构;文本分类;学习分析

在线协同研讨是一种重要的协作学习活动。在在线协同研讨的过程中,学习者通过分享、提问、协商等交互活动共同建构公共知识,同时实现个人知识的增长。当前,对在线协同研讨过程中的知识建构行为进行分析,常基于相应的编码系统,采用内容分析方法,以人工编码的方式把学习活动过程中产生的交互文本数据映射为相应的知识建构行为类型再进行分析研究。但人工编码方法主观性较强且费时、费力,分析结果反馈滞后,不利于进行实时的教学监测和干预。若能基于文本分类方法实现对文本数据的自动分析,将会极大地提高数据分析的效率,且在教学过程的实时监控方面也将发挥极大的应用潜力。
一 相关研究
对协同研讨过程中产生的交互文本进行内容分析,可推断出文本中的潜在性内容(如元认知、认知行为等[1]),这些内容能为协同知识建构过程提供更有意义的解释。随着文本分类技术的快速发展,研究者开始将此技术应用于内容分析研究,以提高分析的效率。例如,McKlin[2]采用人工神经网络的方法,基于描述协同知识建构过程的认知存在编码方案,对学习社区中学生的讨论文本进行分类;Lämsä等[3]基于学生的协作交互文本,采用词嵌入和具有注意力机制的深度学习方法构建分类模型,自动编码分析学生协作探究学习的过程;Neto等[4]基于学生在线讨论文本,利用相关工具提取文本特征并结合部分与情境相关的自定义特征,采用随机森林算法编码分析协作交互文本的认知存在阶段,取得了较高的准确率(Accuracy=67%),之后还基于实验结果解释、探讨了相关特征对认知存在不同阶段的预测作用。而在中文交互文本的自动编码研究方面,甄园宜等[5]基于深度神经网络算法,构建了面向在线协作学习交互文本的分类模型,取得了较高的准确率(Accuracy=77.42%),但此实验采用的交互文本编码方案还较难适用于协同知识建构过程的分析。
综上可知,现有研究多为对英文文本的自动编码分析,而如何针对中文文本进行知识建构行为的自动编码分析还有待进一步研究。另外,当前人工智能系统中存在的“黑箱”、数据偏见、算法偏见等问题,使得可解释AI日益受到关注[6]。因此,将智能技术融入在线协同研讨情境中,实现知识建构行为的自动分析,还要综合考虑教育领域的应用需求、协同知识建构的过程特征、可用的数据资源、AI算法的适用性等问题,在此基础上设计适切的分析方法,构建一个可解释、可信任的教育AI系统。
二 在线协同研讨知识建构行为自动分析实施流程的设计
综合前人的相关研究成果和本研究团队的相关教学实践,本研究设计了在线协同研讨知识建构行为自动分析实施流程,如图1所示。

图1 在线协同研讨知识建构行为自动分析实施流程
①编码系统的选择与构建。编码系统用于确定分析单元的归属类型,而实现自动编码分析,需要综合考虑分析目标与实际的应用需求,将人工智能技术与教育教学理论有机融合,创建一个适应于具体教学情境的编码方案,在有效反映分析目标特征的同时,又能为计算机实现自动分类提供更为友好的信息,从而达到较好的应用效果。
②数据的采集和整理。本环节可采用网络爬虫方法采集网络平台上的文本数据,并存入相应的数据库中;之后,可通过数据清洗对“脏数据”进行有效的检测和修复,以提升数据质量,为后续的数据处理和分析做好准备。
③特征选择和提取。本环节需着重考虑在线协同研讨具有的多主题、跨学科特点,以及协同知识建构过程具有的阶段性和交互性特点。因此,文本特征的选择和提取可考虑从文本数据中获取语义、语法特征与研讨情境特征等——这些特征与研讨内容无关,既具有较好的跨情境性,也能为文本分类提供较好的区分性信息。
④数据预处理。本环节需着重解决数据集的类别样本不平衡问题。为避免因训练集样本不平衡而产生分类误差,需要对数据进行相应处理,以实现数据集中各类别样本的平衡。
⑤分类模型选择与评价。分类模型的选择,应考虑特定领域的风险和需求、可用的数据资源和现有的领域知识、机器学习模型的适用性是否满足待处理计算任务的要求等因素。结合教育领域对可解释AI的需求[7],本环节应优先选择标准的可解释模型。分类模型的训练需要经过反复调试与比较,以提升其计算性能和精度。分类模型的检验与评价,可从分类准确率(Accuracy)、与人工分析的一致性和跨情境性等方面来进行。
⑥结果的应用及解释。本环节重在应用分析结果解释特征变量与知识建构行为类别的关系,增强使用者对模型的信任度并深化其对协同知识建构过程的认知,让使用者能够理解、信任和有效管理整个过程。另外,自动分析方法提升了分析的效率,可与相关工具软件结合,及时、可视化地呈现教学的过程或状态等,从而为协同知识建构过程的干预和调节提供支持。
需说明的是,当在线协同研讨知识建构行为自动分析进行到第六个环节时,应根据具体的应用效果,于必要时返回到之前的环节并对相关环节进行优化与调整,以满足实际的应用需求。
三 实验与结果讨论
本研究按照在线协同研讨知识建构行为自动分析实施流程,以网络研修社区中教师工作坊的协同研讨活动为例开展实验,旨在基于教师在线协同研讨过程中产生的交互文本,来探讨对知识建构行为进行自动分析的实现过程。
1 编码系统的选择与构建
本研究在选择与构建编码系统时,着重考虑了以下三个方面的问题:
(1)网络研修协同研讨活动的相关特点
在网络研修协同研讨活动中,教师研讨的话题多为其在教学实践过程中关注的问题。教师通过在线协作,推动问题的解决;同时,教师在吸纳彼此思想的基础上共同构建一种新的理解,这种理解对教学实践可能具有重要的参考价值。此外,教师在此过程中进行自我反思,不断发展其实践性知识,进一步提升了个人的专业知识和能力。因此,应将教师的教学反思和共同体新知识的构建作为网络研修协同研讨活动的关注重点。
(2)对IAM的认识
交互分析模型(Interaction Analysis Model,IAM)是一个可靠而友好的模型[8],它将协同知识建构的过程划分为分享观点、认知冲突、意义协商、检验修正、达成应用等五个阶段。在应用过程中,IAM可通过分析低阶、高阶心智功能行为的出现频率,来评价小组的交互能力和质量。而要促进协作过程中高阶心智功能行为的出现,阶段1(分享观点)和阶段2(认知冲突)帖子的出现是关键。在阶段1中,经过分享、比较、澄清所达成的共同理解有利于协作意义的生成和学习[9]。在阶段2中,参与者认知的不协调、观点间的不一致可以促进交互的深度[10]。
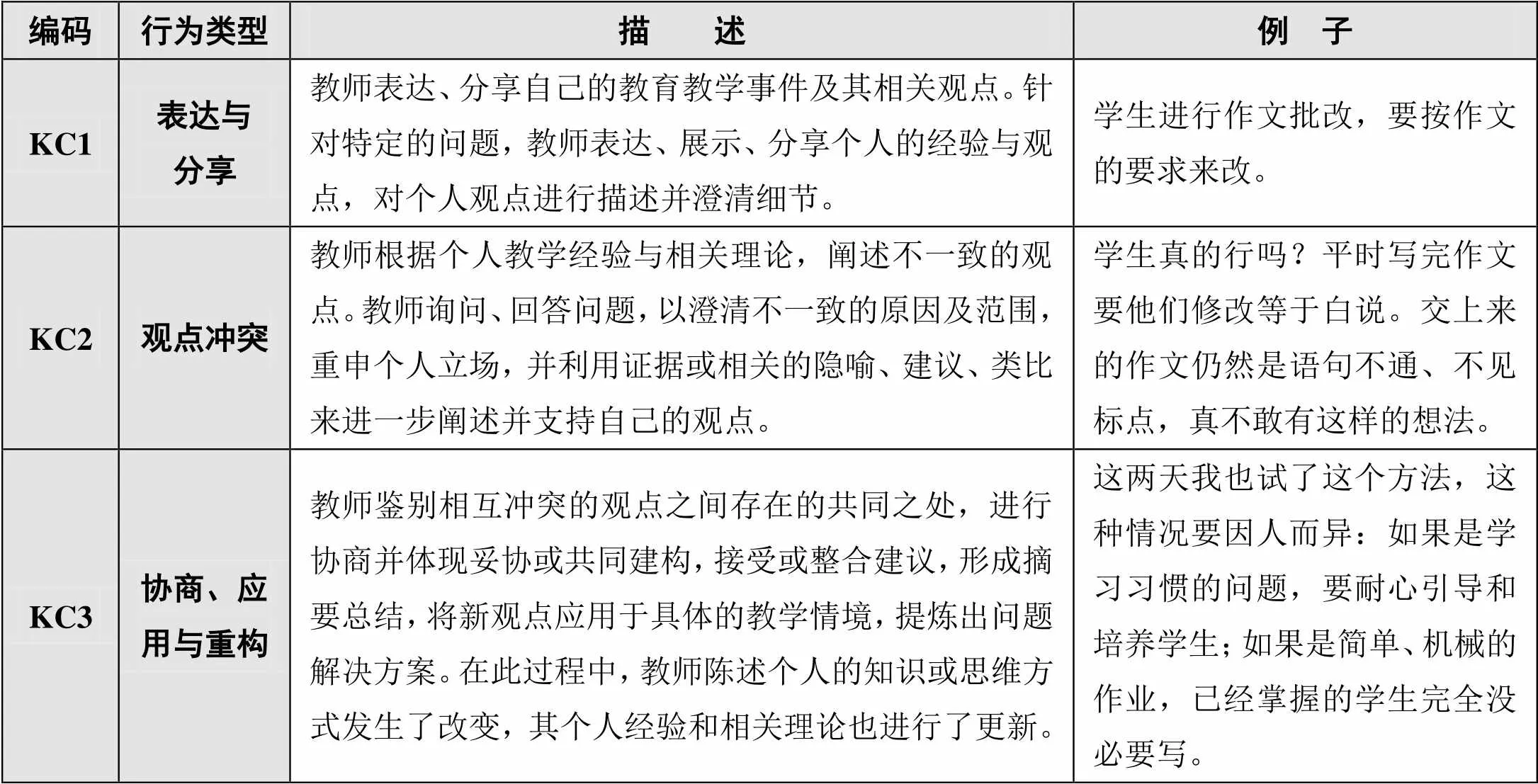
表1 教师工作坊知识建构行为编码表
(3)人工智能技术的相关特征
目前,人工智能技术还属于弱人工智能,其应用仅适用于规则十分明确的、定义十分清晰的任务[11]。因此,在编码方案中对类别的划分和描述应具有良好的区分性,如此才有利于机器算法提取各类别样本的相关文本特征,从而提升文本分类模型的准确率。另外,训练集类别样本分布的平衡性也是影响文本分类模型准确率的重要因素。
考虑到上述问题,结合分析目标和实际的应用需求,本研究邀请10名相关专家参与构建“教师工作坊知识建构行为编码表”的访谈,并结合访谈反馈进行综合分析。参考IAM,指导者在协同研讨过程中应重点监控阶段1和阶段2帖子的出现情况,以促进学习者高阶心智功能行为的出现,并据此对交互过程及其质量进行分析、评价,由此得到最终的编码表,如表1所示。
2 数据的采集和整理
本研究采集了网络研修社区中A小学语文教师工作坊中的评论数据作为训练集。该教师工作坊中有1名坊主、2名辅导教师和92名学员,其网络研修活动持续了3个多月。具体的活动分三个阶段实施:①案例研习阶段,教师通过观摩教学案例,确定此次活动的研讨主题为“学生参与作文批改,效果是不是更好些?”②实践探究阶段,教师在线下验证相关观点和方法、在线上分享实践的体会与疑惑,大家共同协商推动问题的解决。③总结反思阶段,教师反思自己的教学实践,分享研修心得。本研究采集了此次网络研修活动中的过程数据,得到1773条文本评论;同时,还采集了D小学数学教师工作坊中的评论数据作为测试集,研讨主题为“怎样对待不完成作业的学生?”,得到651条文本评论。之后,按照“教师工作坊知识建构行为编码表”,以消息为分析单元,对上述训练集和测试集进行编码,得到数据分布情况,如表2所示。

表2 对训练集、测试集进行编码后的数据分布情况
3 特征选择和提取
教师工作坊中研讨的主题多样,这就对文本分类模型的泛化能力和情境迁移能力提出了要求。另外,还需考虑文本特征对目标类型的可解释性,以加深对知识建构行为的认识和理解。基于此,本研究拟选择和提取交互文本的语言探索与词计数(Linguistic Inquiry and Word Count,LIWC)特征和研讨情境特征作为分类算法的输入变量。
(1)LIWC特征
LIWC特征是指使用LIWC工具来抽取的交互文本的语言心理特征。本研究通过“文心”(TextMind)中文心理分析系统[12],从上述训练集和测试集中获取到102个中文语言心理特征。
(2)研讨情境特征
研讨情境特征可理解为一个帖子在整个讨论线程情境中的位置特征,主要包含——
①帖子深度:取一个整数值,代表帖子在整个讨论线程中的时间顺序位置。
②回复帖类型:取一个布尔值,标识该帖是对主题帖的回复还是对其他帖的回复。若是对主题帖的回复,则取值为0;若是对其他帖的回复,则取值为1。
③回复数:取一个整数值,代表一个帖子所获得的回复消息数。
④回复帖与主帖的相似度:是指回复帖内容与所回复的主帖内容经计算取得的余弦相似度值。通过本特征可以判断,回复帖在多大程度上建构在主帖的信息之上。
⑤严格时间顺序帖与上一帖的相似度:将每个帖子放置在一条时间线上,然后严格按照其创建时间进行排序,而不考虑其引用及其与其他帖子的关系,如图2所示。排序完成后,计算帖子与其上一帖的余弦相似度值。通过本特征可以判断,帖子在多大程度上建构在上一帖的信息之上。
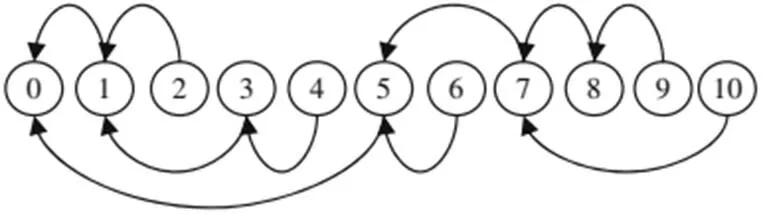
图2 按严格的时间顺序进行排序的帖子
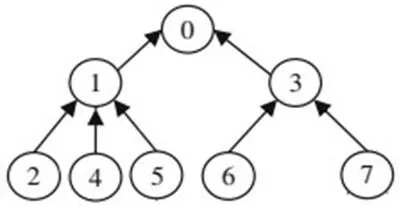
图3 按语义时间顺序进行排序的帖子
⑥语义时间顺序帖与上一帖的相似度:语义时间顺序跟踪共享思想的讨论,靠讨论线程将相关帖子组织起来,再依据时间顺序对相同层级的帖子进行排序。如图3所示,2、4、5号帖在同一讨论线程内处于同一回复层级(都是对1号帖的回复),在此可按创建时间对这三个帖子进行排序。帖子的语义时间顺序,反映了子话题随着时间推移的发展情况。排序完成后,计算该序列内帖子与其上一帖的余弦相似度值。
4 数据预处理
由于训练集中三种类型的样本在数量上存在较大差异,为避免因训练集样本不平衡而产生的分类误差,需要对数据进行预处理。本研究中的训练集帖子总数为1773条,平均分布在各行为类型中的帖子数量应有591条。为此,本研究采用SMOTE算法[13],过采样分别增加KC2、KC3的样本数452条、203条;欠采样则减少KC1的样本数655条,以实现各行为类型最终帖子数量的平衡,如表3所示。

表3 训练集数据预处理
5 分类模型选择与评价
(1)模型选择
建立分类模型时,本研究选用随机森林(Random Forest)算法,它是以决策树为基本分类器的一种集成学习方法,在文本分类领域应用广泛。该算法是一种白盒算法,可度量特征的重要性[14];此算法中,平均精度下降(Mean Decrease Accuracy,MDA)利用置换袋外数据(Out-Of-Bag,OOB)计算变量的重要性,MDA值越大,说明变量越重要。实验中使用R语言的randomForest包来运行随机森林算法,并结合importance()函数来度量并输出变量的重要性值。
(2)模型训练与评价
在应用随机森林算法构建分类模型的过程中,有两个待确定的重要参数:决策树数量ntree和随机分割变量数mtry,它们都对模型的分类精准度有一定的影响。参考Geurts等[15]的研究成果,本研究将ntree值设为1000。而对于mtry值,本研究通过逐一比较其不同取值,选取OOB误差值最小时的mtry值作为最佳取值。据此,本研究选取了17个不同的mtry值(即1、3、5、7、9、11、13、15、21、32、43、54、65、76、87、95、108)用于实验计算,结果如图4所示。图4显示,在训练集中最佳模型所获得的准确率是0.887、Kappa值为0.830,此时mtry值为9。一般认为,如果Kappa值>0.75,则编码结果间具有极好的一致性[16]。综上可知,当ntree参数取值1000、mtry参数取值为9时,训练得出的随机森林模型自动分类结果的信度较高。
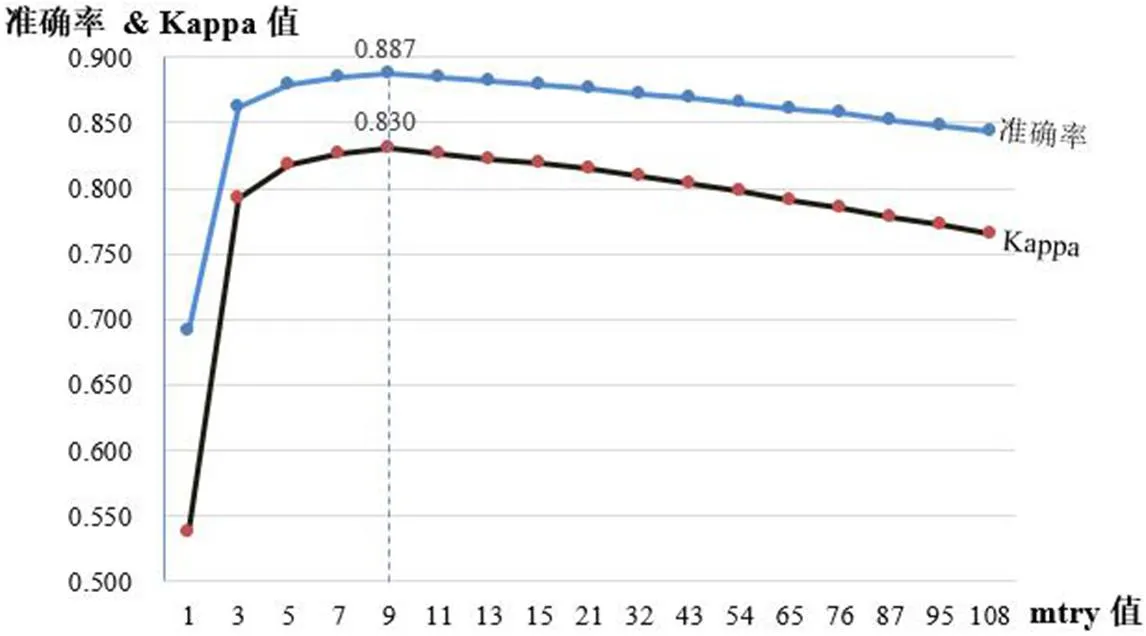
图4 随机森林mtry值选择的实验计算结果
此外,本研究还应用跨情境的测试数据集来评估训练得出的分类模型的泛化能力。该模型在测试集上的分类准确率为0.756、Kappa值为0.502。一般认为,如果Kappa值处于0.40~0.75之间,则编码结果间具有良好的一致性[17]。由此可以推断,该模型能较好地适用于跨情境分类。
6 结果的应用及解释
(1)特征重要性分析
依据随机森林算法中MDA值的大小,本研究排列出影响知识建构行为分类的重要特征变量,得到MDA值排在前3位的LIWC特征,如表4所示。
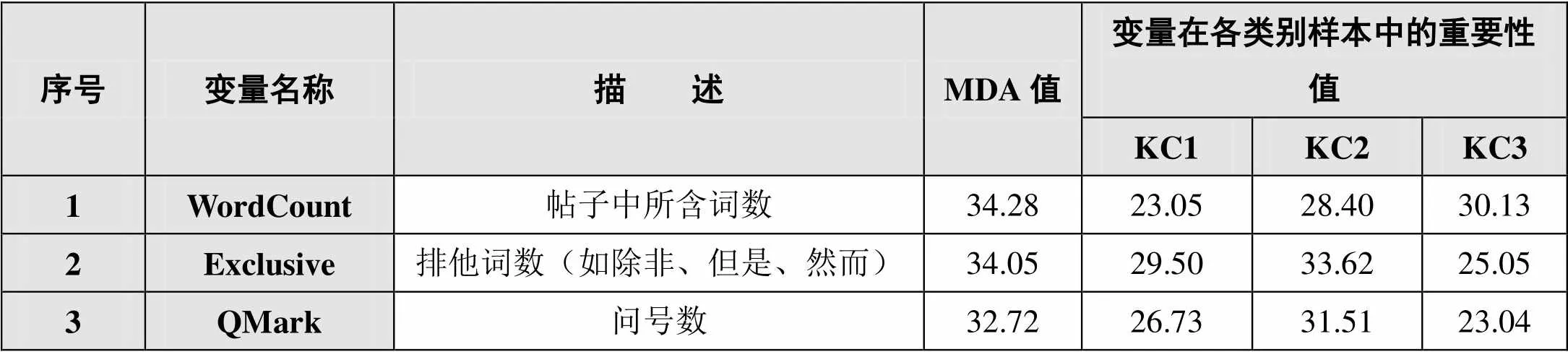
表4 MDA值排在前3位的LIWC特征
①帖子中所含词数(WordCount)特征:与KC3(协商、应用与重构)行为紧密相关。Joksimovic等[18]的研究表明,该特征体现出了帖子语言结构的复杂性,可推断出认知探究和认知加工的增长。②排他词数(Exclusive)特征:与KC2(观点冲突)行为紧密相关。通过在训练语料中查看相关帖子,可以发现排他词的使用能反映说话者尝试发表具有区分性的观点,或者表明说话者发表了不一致的观点。③问号数(QMark)特征:与KC2(观点冲突)行为紧密相关。问号多出现在问句当中,结合训练语料的分析可以发现:问号的出现,体现了该帖子是针对相关观点提出质疑或提出问题。以上分析结果能为协同知识建构活动的角色脚本设计提供参考[19],有利于相关角色或参与者准确表达各自观点,进而促进在线协作学习的有效性。
依据随机森林算法中MDA值的大小,本研究得到排在前3位的研讨情境特征如表5所示。
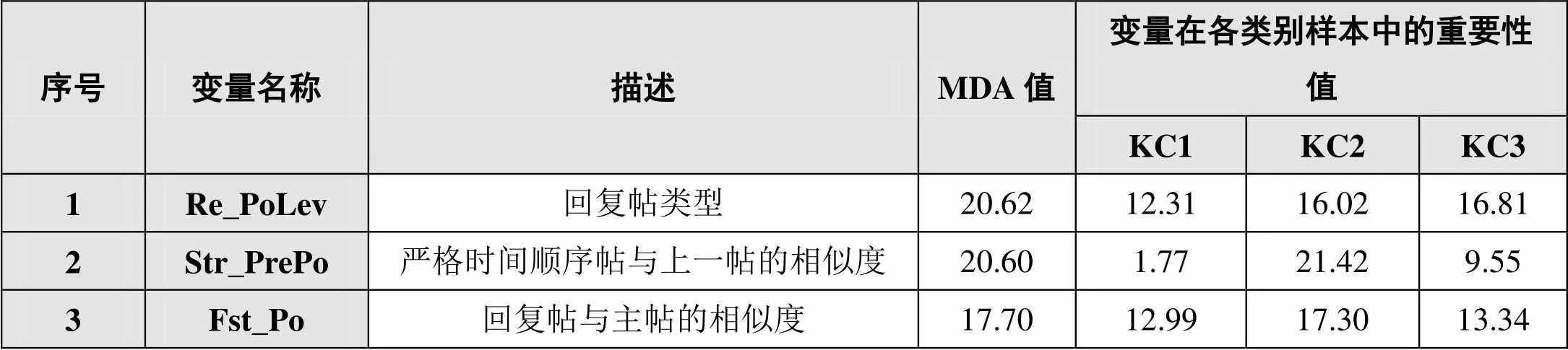
表5 MDA值排在前3位的研讨情境特征
①回复帖类型(Re_PoLev)特征:与KC3(协商、应用与重构)、KC2(观点冲突)行为有较高的相关度。查看训练语料可以发现,回复帖若是对非主题帖的回复,则该帖大概率属于KC2、KC3类别;若是对主题帖的回复,则该帖很有可能属于KC1类别。由此可以推断,教师在进行协同研讨知识建构的过程中能基于研讨主题分享观点,能针对他人的观点提出不一致意见或进行协商建构新知识。②严格时间顺序帖与上一帖的相似度(Str_PrePo)特征:与KC2(观点冲突)行为紧密相关。查看训练语料可以发现,当本特征值较小时,该帖属于KC2类别的可能性较大;而当本特征值较大时,该帖属于KC1、KC3类别的可能性较大。由此可以推断,教师常引用按严格时间顺序的上一帖的相关内容,来分享观点或协商建构知识。③回复帖与主帖的相似度(Fst_Po)特征:与KC2(观点冲突)行为紧密相关。查看训练语料可以发现,当本特征值较大时,该帖属于KC2类别的可能性较大。由此可以推断,教师常通过直接回复他人帖子并引用该帖子中的相关内容来发表不一致的观点,体现出教师在发表不一致观点时有较强的针对性。引用异议帖子中的相关内容并直接回复,这种谨慎而有针对性地发表不一致观点的方式,有利于学习共同体中良好协作氛围的营造,进而促进知识的意义建构。通过以上分析可知,研讨情境特征在知识建构行为分类中具有一定的重要性,因此对帖子进行编码分析时,结合上下文情境是非常有必要的,这有利于提升编码的信度和效度。
(2)知识建构行为的序列分析
基于自动编码获得的结果,利益相关者可以便捷地使用滞后序列分析法(Lag Sequential Analysis,LSA),对交互行为序列及模式进行分析,进一步探究学习者认知水平与互动行为之间的关系,为研修过程的干预和调节提供支持。本研究利用滞后序列分析软件GESQ 5.1,计算出交互行为类型的调整残差值(Z-Score)。一般来说,如果Z-Score值>1.96(<0.05),则表示从起始行为到目的行为之间的转换具有显著意义[20]。

图5 网络研修各阶段的知识建构行为转换情况
本实验中A小学语文教师工作坊中开展的网络研修活动经历了三个阶段,各阶段的知识建构行为转换情况如图5所示。此次网络研修活动始于案例研习阶段,教师通过观摩案例对相关教学问题进行探讨,并讨论解决问题的理论和方法;当有教师提出不一致的观点和意见时,他们会反复探讨、辩解与协商(KC2→KC2,KC3→KC3)。在实践探究阶段,教师在线下开展实践、线上提出疑惑并分享观点,教师就分享的教学事件及其相关观点进行探讨、询问或辩解(KC1→KC2);通过观点的“碰撞”,教师提出协商、接受或整合建议,在具体教学情境中修正、提炼问题解决方案等(KC2→KC3,KC3→KC3);在交互过程中,教师的知识建构水平逐步提升(KC1→KC2→KC3)。而在总结反思阶段,教师对整个研修活动进行总结,积极分享自己的研修心得,交流、反思、总结自己的教学实践和研修收获(KC1→KC1,KC3→KC3)。
四 结语
为了实现对在线协同研讨知识建构过程的动态跟踪与分析,本研究首先设计了“在线协同研讨知识建构行为自动分析实施流程”;然后,基于此流程实现了对网络研修社区中教师工作坊协同研讨过程知识建构行为的自动编码分析,并将分类模型应用于跨情境的测试数据集中,取得了较好的分类效果(分类准确率为0.756、Kappa值为0.502);最后,对实验结果的应用情况进行了探讨。本研究发现,交互文本的语言心理特征和研讨情境特征在知识建构行为的不同类别样本中具有不同的表现形式,这可为利益相关者深入理解协同知识建构过程并对此过程进行实时干预和调节提供支持。后续研究将增大在线协同研讨知识建构行为自动分析方法的应用范围,进一步对分类模型的泛化能力进行验证,以提升其应用价值。
[1]Henri F. Computer conferencing and content analysis[A]. Collaborative Learning Through Computer Conferencing[C]. Berlin: Springer, 1992:117-136.
[2]McKlin T. Analyzing cognitive presence in online courses using an ANN[D]. Atlanta: Georgia State University, 2004:40-80.
[3]Lämsä J, Uribe P, Jiménez A, et al. Deep networks for collaboration analytics: Promoting automatic analysis of face-to-face interaction in the context of inquiry-based learning[J]. Journal of Learning Analytics, 2021,(8):113-125.
[4]Neto V, Rolim V, Pinheiro A, et al. Automatic content analysis of online discussions for cognitive presence: A study of the generalizability across educational contexts[J]. IEEE Transactions on Learning Technologies, 2021,(3): 299-312.
[5]甄园宜,郑兰琴.基于深度神经网络的在线协作学习交互文本分类方法[J].现代远程教育研究,2020,(3):104-112.
[6][7]王萍,田小勇,孙侨羽.可解释教育人工智能研究:系统框架、应用价值与案例分析[J].远程教育杂志,2021,(6):20-29.
[8]Gunawardena C N, Anderson T. Analysis of a global online debate and the development of an interaction analysis model for examining social construction of knowledge in computer conferencing[J]. Journal of Educational Computing Research, 1997,(4):397-431.
[9]Dama C I, Ludvigsen S. Learning through interaction and the co-construction of knowledge objects in teacher education[J]. Learning, Culture and Social Interaction, 2016,(11):1-18.
[10]Kanuka H, Anderson T. Online social interchange, discord, and knowledge construction[J]. Journal of Distance Education, 1998,(1):57-74.
[11]郑勤华,熊潞颖,胡丹妮.任重道远:人工智能教育应用的困境与突破[J].开放教育研究,2019,(4):10-17.
[12]Gao R, Hao B, Li H, et al. Developing simplified Chinese psychological linguistic analysis dictionary for microblog[A]. International Conference on Brain & Health Informatics (BHI’13)[C]. Tokyo: Springer, 2013:359-368.
[13]Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002,(16):321-357.
[14]Louppe G, Wehenkel L, Sutera A, et al. Understanding variable importances in forests of randomized trees[A]. Advances in Neural Information Processing Systems 26 (NIPS 2013)[C]. Cambridge: The MIT Press, 2013:1-9.
[15]Geurts P, Ernst D, Wehenkel L. Extremely randomized trees[J]. Machine Learning, 2006,(1):3-42.
[16][17]Wever B D, Schellens T, Valcke M, et al. Content analysis schemes to analyze transcripts of online asynchronous discussion groups: A review[J]. Computers & Education, 2006,(1):6-28.
[18]Joksimovic S, Gasevic D, Kovanovic V, et al. Psychological characteristics in cognitive presence of communities of inquiry: A linguistic analysis of online discussions[J]. The Internet and Higher Education, 2014,22:1-10.
[19]Radkowitsch A, Vogel F, Fischer F. Good for learning, bad for motivation? A meta-analysis on the effects of computer- supported collaboration scripts[J]. International Journal of Computer-Supported Collaborative Learning, 2020,15:5-47.
[20]杨现民,王怀波,李冀红.滞后序列分析法在学习行为分析中的应用[J].中国电化教育,2016,(2):17-23、32.
Research on Automatic Analysis of Knowledge Construction Behaviors in Online Collaborative Discussion
HE Hao-yi1LIU Qing-tang2ZHANG Si2GUAN Xue-min1QIN Wei-hua3[Corresponding Author]
In order to realize the dynamic tracking and analysis of the knowledge construction process of online collaborative discussion, this paper used the text classification method to design the “implementation process of automatic analysis of knowledge construction behavior of online collaborative discussion”. Guided by this process, this paper took the collaborative discussion activities of teachers’ workshops in the e-learning community as an example to carry out the experiment, and the main contents include creating a “teacher workshop knowledge construction behavior coding scheme”, collecting and sorting interactive text data, selecting and extracting text features, preprocessing training set data, training and evaluating classification model, and describing and explaining the application situation of analysis results. The results showed that the automatic analysis method of knowledge construction behavior in an online collaborative discussion can provide support for stakeholders to deeply understand the collaborative knowledge construction process and to intervene and adjust the process in real time.
online collaborative discussion; knowledge construction; text classification; learning analysis
G40-057
A
1009—8097(2022)05—0093—09
10.3969/j.issn.1009-8097.2022.05.011
基金项目:本文受国家自然科学基金项目“面向大规模在线教育的学习者协作会话能力评估模型及干预机制研究”(项目编号:62077016)、广西高等教育本科教学改革工程一般A类项目“基于创新实践能力培养的SPOC翻转课堂混合型教学模式研究——以管理沟通课程为例”(项目编号:2018JGA115)、广西民族师范学院2021年校级科研项目“混合学习过程的多模态分析及归因研究”(项目编号:2021BS006)资助。
何皓怡,高级工程师,博士,研究方向为学习分析,邮箱为he_haoyi@163.com。
2021年8月31日
编辑:小米
