闭项集挖掘算法研究综述
2022-05-20刘文杰秦伟德张晓蝶
刘文杰,秦伟德,张晓蝶
(兰州财经大学,甘肃 兰州 620020)
1 引言
频繁项集挖掘算法和高效用项集挖掘算法是数据挖掘关联规则领域非常重要的两个分支,可以从数量和效用角度出发发现项之间隐藏的关联性。频繁项集挖掘旨在挖掘频繁地同时出现在数据库中的项,假定事务中每个项的价值都相同并且仅考虑项集在交易事务中出现的总次数。但在现实中,项集的出现次数并不能完全表达出数据的所有有用信息。高效用项集挖掘是在频繁项集挖掘的基础上发展而来的,其不仅考虑项集的出现次数,还考虑用户偏好、重要性、利润等因素对项集“有效性”影响。
然而,频繁项集和高效用项集挖掘的结果通常是很大的集合,尤其是当数据集很密集或者阈值ɛ很小时,因此闭项集的概念被提出,其中闭频繁项集CFIs和闭高效用项集CHUIs就是为了解决这个问题而提出的,生成的CFIS、CHUIs集合中的元素数量明显少于FIs、HUIs,但不会丢失任何信息,并且可以从所有挖掘出的闭频繁项集和闭高效用项集恢复到全集频繁项集和高效用项集。因此,可以挖掘闭项集而不是全集项集,以最大限度地减少存储空间和内存使用。
2 基本概念
闭项集的概念是基于以下两个函数提出来的:
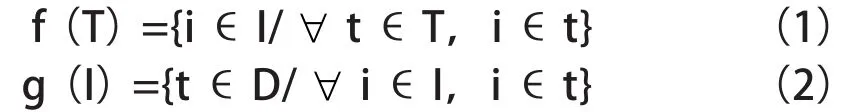
其中函数f返回所有事务中共同包含的项集,函数g返回包含项集i的所有事务。
定义1 闭项集。当一个项集称之为闭项集,当且仅当满足:

其中fog(I)混合函数也被称作伽罗瓦操作或者闭包[dci]操作。
定理1 对项集X和项集Y,如果满足X ⊆Y以及 SC(X)=SC(Y)(|g(X)|=|g(Y)|, 则 X的闭包和Y的闭包相同,即C(X)=C(Y)。
定理2 对于一个项集X和一个项i,如果满足g(X)⊆g(i),则项i是X的一个闭包,即i∈c(X)。
定义2 闭频繁项集。如果项集X同时满足在数据库中不存在X的超集Y且与X的支持度相同且X的支持度不小于最小支持度阈值即SC(X)≥minsup,则称X为闭频繁项集。
定义3 闭高效用项集。闭高效用项集。如果项集X同时满足在数据库中不存在X的超集Y和与X的支持度相同和X的效用值不小于最小效用阈值即 U(X)≥mutil,则称X为闭高效用项集。
3 闭频繁项集挖掘算法
现有的经典的闭频繁项集挖掘算法和频繁项集挖掘算法一样,大致分成基于水平层级机制、基于模式增长机制和基于垂直数据格式机制三种类型。
A-CLOSE采用Apriori算法的水平层级机制,延续了自底向上、广度优先的搜索策略。首先通过Apriori策略逐层浏览频繁项集格,挖掘每个等价类的最小元素。在第二步中,A-CLOSE计算之前找到的所有最小生成器的闭包。由于单个等价类可能有多个最小项集,因此可能会计算冗余闭包。此外,A-CLOSE性能受到离线闭包计算高成本和大量子集搜索的影响。
为了解决水平层级机制算法项集连接成本昂贵的问题,一些闭频繁项集挖掘算法也采用了模式增长的机制。CLOSET+使用了FP-tree结构,但与CLOSET算法不同之处体现在以下几方面:①采用混合树投影方法,对稠密数据集使用自下而上的物理树投影,对稀疏数据集使用自上而下的物理树投影,有效提高了空间效率。②使用项集跳过技术来修剪搜索空间。③使用高效的子集检查方法确保新发现的项集是闭项集。实验表明,就运行时间、内存使用和可扩展性而言,CLOSE+相对于现有挖掘算法具有一定优势。FPClose使用FP-tree结构的另一种变体——CFI树,用于检查频繁项集的闭合性。此外,采用一种新的FP-array技术,来提高在CFI-tree上的操作性能。实验结果表明,FPClose闭项集检测方法比CLOSET+方法更有效。
以上算法的数据格式均为水平的,一些算法将数据格式进行转换,采用了垂直的数据格式。CHARM使用了一些创造性的思想:①不同于之前算法只探索项目集空间,CHARM通过IT-tree(itemset-tidset search Tree)结构同时探索项目集空间和事务空间。②使用一种混合搜索方法,可以跳过IT-tree的许多层级,提高搜索效率。③使用纵向数据表示diffsets技术减少TID交集计算的内存占用。④使用一种快速的基于散列的方法来移除在计算过程中发现的任何“非封闭”集合,显著压缩候选项集。在大量真实和合成数据库上进行的广泛实验评估表明,CHARM明显优于以前的方法,在事务数量上也是可线性扩展的。DCI-Closed的中心思想是引入两个变量:PRE_SET和POST_SET。其中POST_SET用于构建所有可能的生成器,PRE_SET用于进行生成器重复检查。实验证明,DCI-Closed算法优于CLOSE+和FPClose。
近几年,国内外学者在闭频繁项集挖掘算法问题上积极探索创新,取得不错的研究成果。党红恩等人提出一种基于数据变换与并行运算的DTPC算法,该算法利用质数对数运算的方法,将大量数据转换成简单的数字,在Spark平台上进行闭频繁项集的挖掘。实验证明,DTPC算法在挖掘效率上得到显著提升,并且节约了计算资源成本。Aryabarzan等人提出一种快速挖掘的NECLATCLOSED算法,该算法使用项目集搜索树来表示搜索空间。对数据库扫描以识别包含1-项集的TSets,基于TSets识别出所有的频繁1-项集作为根目录的子目录。此外,算法还提出一种快速包容检查的技术,使用一个hashmap结构将闭频繁项集的有序列表与支持度关联起来进行快速检查。实验证明NECLATCLOSED算法在大多数情况下都优于以上主流算法,尤其是在运行时间上。
4 闭高效用项集挖掘算法
现有的闭高效用项集挖掘算法可分为一阶段算法和两阶段算法。
两阶段算法指的是在第一阶段利用TWU值和最小效用阈值生成候选项集,第二阶段利用候选项集真实效用值和最小效用阈值生成高效用项集,如 AprioriCH、EFIM-Closed。AprioriCH 在Apriori的基础上进行扩展,利用横向扩展数据库和广度优先搜索方式挖掘闭高效用项集。EFIMClosed使用新的子树效用值和本地效用值上界,有效地修剪搜索空间。还提出了数据库投影和事务合并技术来挖掘闭高效用项集,降低了数据库扫描的成本。此外,采用了新的 CJ、FCC 和 BCC剪枝策略来删除非闭合的高效用项集。实验结果表明,与 CHUD相比,EFIM-Closed 速度可以提高一个数量级以上,消耗的内存可以减少一个数量级以上。
一阶段算法直接比较项集的效用和最小阈值,不生成候选项集,如CHUI-Miner、CLS-Miner、IncCHUI。CHUI-Miner是首次用一阶段方法挖掘闭高效用项集的算法。该算法提出了用于事务中维护项集效用信息的新结构扩展效用列表 EU-List,该结构可以在一阶段中有效地计算项集效用和效用单元数组。该算法在不产生候选项的情况下,可以在数据库中发现完整的 CHUIs。实验结果表明,与 CHUD 算法相比时间快了两个数量级以上。CLS-Miner利用效用列表结构直接计算项集效用而不产生候选;采用Chain-EUCP、LBP和 Coverage三种新的搜索空间剪枝策略,引入了子集检查的高效方法,进一步减少了发现闭高效用项集所需的时间。实验结果表明,在运行时间方面,CLS-Miner 比 CHUD和CHUIMiner 算法快几个数量级。IncCHUI从增量数据库中挖掘闭高效用项集。该算法采用了增量效用列表结构,只需要扫描一次数据库就可以构建和更新数据;使用基于散列的方法来更新或插入找到的新的闭高效用项集。实验结果表明,就速度而言,它明显优于之前提出的以批处理模式运行的算法,并且在事务数量方面是可扩展的。
5 总结与未来研究方向
闭项集可以有效地减少大量冗余的项集,从而减少算法的搜索空间提高算法效率,是全集项集一种精简高效且无损的模式。文章主要从闭频繁项集和闭高项集这两部分进行算法性质的归纳,未来也会在更多闭项集算法比如闭序列或者在数据流上的闭项集上进行研究。
